Диагностика локальных сетей и Интернет
5 Диагностика локальных сетей и Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)
Читатели неизбежно делятся на две категории:
а. Администраторы сети, которые формируют сетевую среду (подавляющее меньшинство).
б. Пользователи сети, кто вынужден эту среду осваивать и в ней жить.
Вторая категория, в силу своего численного превосходства, способна задать столько вопросов, на которые первая, даже будучи столь же многочисленной, не смогла бы ответить. Вопросы бывают простые, например:
"Почему не работает электронная почта?" (хотя известно, что вторые сутки за неуплату обесточен весь вычислительный центр). Бывают и сложные: "Как уменьшить задержку отклика, если канал перегружен?"
Число компьютерных сетей увеличивается лавинообразно, растет число больших (>10 ЭВМ) и многопротокольных сетей (Novell, DECnet, TCP/IP, AppleTalk и т.д.). По мере увеличения сети усложняется ее обслуживание и диагностика, с чем сталкивается администратор при первом же отказе. Наиболее сложно диагностировать многосегментные сети, где ЭВМ разбросаны по большому числу помещений, далеко отстоящих друг от друга. По этой причине сетевой администратор должен начинать изучать особенности своей сети уже на фазе ее формирования и готовить себя и сеть к будущему ремонту. При возникновении нештатной ситуации администратор должен суметь ответить на ряд вопросов:
связана проблема с оборудованием или программным обеспечением;
отказ вызван повреждением программы, неверным выбором конфигурации или ошибочными действиями оператора.
Начинать надо с исчерпывающего документирования аппаратной и программной части сети. Администратор всегда должен иметь под рукой схему сети, отвечающую реальному положению на текущий момент, и подробное описание конфигурации программного обеспечения с указанием всех параметров (физические и IP-адреса всех интерфейсов, маски, имена ЭВМ, маршрутизаторов, значения MTU, MSS, TTL и других системных переменных, типовые значения RTT и других параметров сети, измеренных в разных режимах.).
В пределах локальной сети поиск неисправности возможен с помощью временного деления ее на части. По мере интеграции сети в Интернет такие простые меры становятся недостаточными или недопустимыми. Но не следует пренебрегать такими простыми средствами, как отсутствие обрыва или закоротки сетевого кабеля. Нужно помнить, что сопротивление сегмента толстого коаксиального кабеля не должно превышать 5 Ом, тонкого - 10 Ом, а скрученные пары не должны иметь сопротивление больше 11,8 Ом (22AWG) и соответственно 18,8 Ом (24AWG) из расчета на 100 м.
Следует помнить, что сетевая диагностика является основой сетевой безопасности. Только администратор, знающий все о том, что происходит в сети, может быть уверен в ее безопасности.
Ниже будет предполагаться, что сеть на физическом уровне использует стандарт Ethernet, а для межсетевой связи протокол TCP/IP (Интернет). Этим перечнем разнообразие сетевых сред не исчерпывается, но многие приемы и программные диагностические средства с успехом могут использоваться и в других случаях. Большинство из рассматриваемых программ работают в среде UNIX, но существуют их аналоги и для других ОС. Сложные (дорогостоящие, но весьма эффективные) аппаратно-программные диагностические комплексы здесь не рассматриваются. Проблемы маршрутизации и конфигурирования системы также выходят за рамки данного рассмотрения.
В Интернет имеется немало общедоступных специализированных диагностических программных продуктов: Etherfind, Tcpdump (lss:os2warez@merlin.itep.ru
ftp.ee.lbl.gov/tcpdump.tar.Z, для SUN или BSD 4.4; ftp.ee.lbl.gov.libpcap.tar.Z), netwatch (windom.ucar.edu), snmpman (http://www.smart.is/pub/mirror-indstate/snmp), netguard (oslo-nntp.eunet.no/pub/msdos/winsock/apps), ws_watch (bwl.bwl.th-harmstadt.de /windows/util). Программа tcpdump создана в университете Калифорнии и доступна по адресу ftp.ee.lbl.gov. Эта программа переводит интерфейс ЭВМ в режим приема всех пакетов, пересылаемых по данному сетевому сегменту. Такой режим доступен и для многих интерфейсов IBM/PC (например, популярный NE2000 Eagle, mode=6), но tcpdump на этих машинах не работает. Tcpdump написана на СИ, она отбирает и отображает на экране пакеты, посылаемые и получаемые данным интерфейсом. Критерии отбора могут варьироваться, что позволяет проанализировать выполнение различных сетевых процедур. В качестве параметров при обращении к программе могут использоваться наименования протоколов, номера портов и т.д., например, tcpdump TCP port 25. Существует довольно большое число модификаторов программы (опций). К сожалению для рядовых пользователей программа не доступна - требуются системные привилегии. Описание применения программы можно найти по указанному выше адресу, а также в [10]. Другой полезной служебной программой является sock (socket или sockio). Эта программа способна посылать TCP и UDP пакеты, она может работать в четырех режимах.
Программа устанавливает канал клиент-сервер и переадресует стандартный ввод серверу, а все полученные пакеты от сервера переправляет на стандартный вывод. Пользователь должен специфицировать имя сервера или его адрес и наименование операции или номер порта, ей соответствующий.
Работа в режиме диалогового сервера (опция -s). В этом режиме параметром операции является ее имя или номер порта (или комбинация IP-адреса и номера порта), например: sock -s 100. После установления связи с клиентом программа переадресовывает весь стандартный ввод клиенту, а все что посылается клиентом, отправляет на стандартный вывод.
Режим клиента-отправителя (опция -i). Программа выдает в сеть заданное число раз (по умолчанию 1024) содержимое буфера с объемом в 1024 байта. Опции -n и -w позволяют изменить число и размер посылок.
Режим приема и игнорирования данных из сети (опция –i и -s).
Такие средства входят также и в комплекты поставки большинства стандартных сетевых пакетов для ОС MS-DOS, UNIX, Windows NT, VMS и других: ping, tracetoute, netstat, arp, snmpi, dig (venera.isi.edu /pub), hosts, nslookup, ifconfig, ripquery. Перечисленные выше диагностические программы являются необходимым инструментом для отладки программ, передающих и принимающих пакеты. Сводный перечень конфигурационных и диагностических команд набора протоколов TCP/IP представлен в таблице 5.1.
Таблица 5.1.
Название команды |
Назначение |
| arp | Отображает или модифицирует таблицу протокола ARP (преобразование IP в MAC-адреса) |
| chnamsv | Служит для изменения конфигурации службы имен на ЭВМ (для TCP/IP) |
| chprtsv | Изменяет конфигурацию службы печати на ЭВМ-клиенте или сервере |
| gettable | Получает таблицы ЭВМ в формате NIC |
| hostent | Непосредственно манипулирует записями адресного соответствия ЭВМ в конфигурационной базе данных системы |
| hostid | Устанавливает или отображает идентификатор данной ЭВМ |
| hostname | Устанавливает или отображает имя данной ЭВМ |
| htable | Преобразует файлы ЭВМ в формат, используемый программами сетевой библиотеки |
| ifconfig | Конфигурирует или отображает параметры сетевых интерфейсов ЭВМ (для протоколов TCP/IP) |
| ipreport | Генерирует сообщение о маршруте пакета на основе специфицированного маршрутного файла |
| iptrace | Обеспечивает отслеживание маршрута движения пакетов на интерфейсном уровне для протоколов Интернет |
| lsnamsv | Отображает информацию базы данных DNS |
| lsprtsv | Отображает информацию из базы данных сетевой службы печати |
| mkhost | Создает файл таблицы ЭВМ |
| mknamsv | Конфигурирует службу имен клиента (для TCP/IP) |
| mkprtsv | Конфигурирует службу печати ЭВМ (для TCP/IP) |
| mktcpip | Устанавливает требуемые величины для запуска TCP/IP на ЭВМ |
| namerslv | Непосредственно манипулирует записями сервера имен для локальной программы DNS в базе данных конфигурирования системы |
| netstat | Отображает состояние сети |
| no | Конфигурирует сетевые опции |
| rmnamsv | Удаляет TCP/IP службу имен из ЭВМ |
| rmprtsv | Удаляет службу печати на машине клиента или сервере |
| route | Служит для ручного манипулирования маршрутными таблицами |
| ruptime | Отображает состояние каждой ЭВМ в сети |
| ruser | Непосредственно манипулирует записями в трех отдельных системных базах данных, которые регулируют доступом внешних ЭВМ к программам |
| securetcpip | Активизирует сетевую безопасность |
| setclock | Устанавливает время и дату для ЭВМ в сети |
| slattach | Подключает последовательные каналы в качестве сетевых интерфейсов |
| timedc | Присылает информацию о демоне timed |
| trpt | Выполняет отслеживание реализации протокола для TCP-сокетов |
/p> Для того чтобы диагностировать ситуацию в сети, необходимо представлять себе взаимодействие различных ее частей в рамках протоколов TCP/IP и иметь некоторое представление о работе Ethernet [4]. Сети, следующие рекомендациям Интернет, имеют локальный сервер имен (DNS, RFC-1912, -1886, -1713, -1706, -1611-12, -1536-37, -1183, -1101, -1034-35; цифры, напечатанные полужирным шрифтом, соответствуют кодам документов, содержащим описания стандартов), служащий для преобразования символьного имени сетевого объекта в его IP-адрес. Обычно эта машина базируется на ОС UNIX. DNS-сервер обслуживает соответствующую базу данных, которая хранит много другой полезной информации. Многие ЭВМ имеют SNMP-резиденты (RFC-1901-7, -1446-5, -1418-20, -1353, -1270, -1157, -1098), обслуживающие управляющую базу данных MIB (RFC-1792, -1748-49, -1743, -1697, -1573, -1565-66, -1513-14, -1230, -1227, -1212-13), содержимое которой поможет также узнать много интересного о состоянии вашей сети. Сама идеология Интернет предполагает богатую диагностику (протокол ICMP, RFC-1256, 1885, -1788, -792).
Протокол ICMP используется в наиболее популярной диагностической программе ping входит в поставку практически всех сетевых пакетов). Возможная форма вызова этой программы имеет вид:
ping <имя или адрес ЭВМ или другого объекта> [размер пакета] [число посылок]
размер пакета задается в байтах (по умолчанию равно 56). Процедура выполнения ping может быть прервана нажатием клавиш ctrl-C. В различных реализациях программа ping имеет много различных опций, которые позволяют измерять статистические характеристики канала (например, потери), определение задержки в канале (RTT), отображение посылаемых пакетов и получаемых откликов, а также определение маршрута до интересующего объекта. Ping используется для определения доступности сервис-провайдера и т.д. Иногда ping является составной частью более мощной диагностической программы (например, netwatch). Ниже приведен пример использования команды tracetoute, которая во многом эквивалентна ping (но базируется непосредственно на IP, используя соответствующие опции):
traceroute kirk.Bond.edu.au
(посмотрим, как идут пакеты до этого сервера в Австралии)
(IP-адрес=131.244.1.1 узнан, зондирование начинается, допустимо не более 30 шагов)
traceroute to kirk.Bond.edu.au (131.244.1.1) 30 hops max, 40 byte packets
1 ITEP-FDDI-BBone (193.124.224.50) 2 ms 2 ms 2 ms
2 MSU-Tower-2.Moscow.RU.Radio-MSU.net (194.67.80.65) 3 ms 3 ms 3 ms
3 NPI-MSU.Moscow.RU.Radio-MSU.net (194.67.80.5) 4 ms 3 ms 3 ms
4 NPI-P.Moscow.RU.Radio-MSU.net (194.67.80.18) 4 ms 5 ms 4 ms
5 DESY-P.Hamburg.DE.Radio-MSU.net (194.67.80.14) 317 ms 310 ms 329 ms
6 DESY.Hamburg.DE.Radio-MSU.net (194.67.82.17) 312ms 320ms 312ms (маршрут через Германию)
7 188.1.56.5 (188.1.56.5) 321 ms 357 ms 327 ms
8 188.1.56.10 (188.1.56.10) 347 ms 467 ms 356 ms
9 DE-f0-0.eurocore.bt.net (194.72.24.193) 331 ms 337 ms 331 ms
10 NL-s1-1.eurocore.bt.net (194.72.24.202) 355 ms 435 ms 343 ms
11 NL-f0.dante.bt.net (194.72.24.2) 367 ms 353 ms 573 ms
12 New-York2.dante.net (194.72.26.10) 497ms 493ms 489ms (пересекли Атлантический океан)
13 f1-0.t32-0.New-York.t3.ans.net (204.149.4.9) 546 ms 501 ms 490 ms
14 h5-0.t36-1.New-York2.t3.ans.net (140.223.33.10) 540 ms 506 ms 571 ms
15 * f2.t36-0.New-York2.t3.ans.net (140.223.36.221) 503 ms 505 ms
16 h13.t40-0.Cleveland.t3.ans.net (140.223.37.10) 802 ms 795 ms 523 ms
17 h14.t24-0.Chicago.t3.ans.net (140.223.25.9) 537 ms 509 ms 526 ms
18 h13.t96-0.Denver.t3.ans.net (140.223.25.18) 545 ms 531 ms 545 ms
19 h12.t8-0.San-Francisco.t3.ans.net (140.223.9.17) 853 ms 584 ms 592 ms
20 border2-fddi1-0.SanFrancisco.mci.net (206.157.77.1) 563 ms 591 ms 753 ms
21 telstra-ds3.SanFrancisco.mci.net (204.70.33.10) 691 ms * 691 ms
22 telstra.SanFrancisco.mci.net (204.70.204.6) 759 ms 815 ms 753 ms (достигли Тихого океана)
23 Fddi0-0.pad-core2.Sydney.telstra.net (139.130.249.227) 766 ms 1054 ms 837 ms (океан позади - Австралия!)
24 Serial4-4.cha-core1.Brisbane.telstra.net (139.130.249.202) 781 ms 776 ms 810 ms
25 qld-new.gw.au (139.130.247.227) 836 ms 917 ms 806 ms
26 139.130.5.2 (139.130.5.2) 816 ms 796 ms 811 ms
27 203.22.86.241 (203.22.86.241) 800 ms 787 ms 838 ms
28 203.22.86.194 (203.22.86.194) 850 ms 790 ms 768 ms
29 kirk.Bond.edu.au (131.244.1.1) 781 ms (ttl=226!) 918 ms (ttl=226!) 799 ms (ttl=226!)
Цель достигнута за 29 шагов! (Путь бывает и длиннее, но редко).
Программа traceroute посылает по три пакета с нарастающими значениями TTL, если отклик на пакет не получен печатается символ *. Большие задержки (RTT) в приведенном примере определяются спутниковыми каналами связи (время распространения сигнала до спутника!).
Для того чтобы правильно реагировать на нештатные ситуации, надо хорошо представлять себе, как сеть должна работать в нормальных условиях. Для этого надо изучить сеть, ее топологию, внешние связи, конфигурацию программного обеспечения центральных серверов и периферийных ЭВМ. Следует иметь в виду, что изменение конфигурации является обычно привилегией системного администратора и в любых сомнительных случаях нужно обращаться к нему. Неквалифицированные действия при реконфигурировании системы могут иметь катастрофические последствия.
Сетевое оборудование, имеющееся в BSD UNIX-системе, описано в документации intro(4), которая доступна через справочную систему man, например:
man - 4 intro | grep Ether (
Выделенная строка представляет собой команду, введенную с клавиатуры, следующий за ней текст - отклик ЭВМ на эту команду)
a network interface for the 10-Megabit Ethernet, along with
SunOS supports the 10-Megabit Ethernet as its primary net-
ie ie(4S) Intel 10 Mb/s Ethernet interface
le le(4S) LANCE 10Mb/s Ethernet interface
Для того чтобы получить дополнительную информацию об этих интерфейсах, можно выдать команду dmesg (или просмотреть файл /usr/adm/messages):
dmesg | grep le0
le0 at SBus slot f 0xc00000 pri 6 (onboard)
le0: AUI Ethernet
Работа сетевого обеспечения базируется на нескольких резидентных программах (демонах): routed и gated (маршрутизация), named (сервер имен), inetd (Интернет услуги). Перечень демонов базовых услуг представлен в таблице 5.2.
Таблица 5.2. Основные TCP/IP демоны
Название демона |
Назначение |
| fingerd | Предоставляет информацию об удаленном пользователе |
| ftpd | Реализует функции сервера передачи файлов (протокол FTP) |
| gated | Реализует функции маршрутизации шлюза для протоколов RIP, HELLO, EGP, BGP и SNMP |
| inetd | Реализует управление сетевыми услугами Интернет |
| named | Реализует услуги сервера имен (DNS) |
| rexecd | Реализует серверные функции для команд rexec (удаленное исполнение) |
| rlogind | Реализует серверные функции для команд rlogin (авторизация) |
| routed | Управляет сетевыми маршрутными таблицами |
| rshd | Реализует серверные функции для команд удаленного исполнения |
| rwhod | Реализует серверные функции для команд rwho и ruptime |
| syslogd | Читает и записывает в журнал сообщения |
| talkd | Реализует серверные функции для команд talk |
| telnetd | Реализует серверные функции для протокола TELNET |
| tftpd | Реализует серверные функции для протокола TFTP |
| timed | При загрузке системы устанавливает демон timeserver |
head -16 /etc/inetd.conf
# @(#)inetd.conf 1.24 92/04/14 SMI
# Configuration file for inetd(8). See inetd.conf(5).
# To re-configure the running inetd process, edit this file, then
# send the inetd process a SIGHUP.
# Internet services syntax:
# <service_name> <socket_type> <proto> <flags> <user> <server_pathname> <args>
# Ftp and telnet are standard Internet services.
| #ftp | stream | tcp | nowait | root | /usr/etc/in.ftpd | in.ftpd |
| #ftp | stream | tcp | nowait | root | /usr/etc/wrapper.3.9.4/tcpd | in.ftpd -dl |
Строки, начинающиеся с символа #, являются комментариями. В данном примере представлена одна информативная строка (их может быть много больше), характеризующая файловый обмен. Каждая строка в этом файле начинается с имени ресурса (в приведенном примере ftp). Далее следует поле типа соединителя (socket): stream (TCP поток байтов); dgram - передача данных в виде UDP-дейтограмм. Следующее поле характеризует протокол, используемый данным видом сервиса (TCP или UDP). За ним идет поле, которое описывает способ реализации процедуры (wait/nowait; для поточных серверов nowait). Следующее поле представляет собой идентификатор пользователя (UID), но обычно пользователем является системный администратор - root. Встречается два исключения. Процедура finger выполняется с UID=nobody или daemon, а uucp использует реальное имя пользователя. За полем uid следует поле сервера (в примере /usr/etc/wrapper.3.9.4/tcpd /usr/local/etc/ftpd). В это поле заносится полное описание пути к программе-серверу, запускаемой inetd. Завершающим полем является поле аргументы, куда записывается строка, передаваемая программе-серверу. Содержимое файла inetd.conf должно быть предметом особой заботы администратора, так как от содержимого этого файла зависит эффективная работа сети и ее безопасность.
Как уже отмечалось выше, одним из важнейших частей любого узла Интернет является сервер имен (DNS). Конфигурация DNS-сервера определяется тремя файлами: named.boot, named.ca и named.local. Зонная информация содержится в файле named.rev, а данные о локальном домене в файле named.hosts. Отладка, контроль и диагностика DNS-сервера осуществляется с использованием программ nslookup (или dig). Рассмотрим пример использования процедуры nslookup (здесь выполнены запросы по серверам имен, по почтовым серверам и по параметрам зоны ответственности):
Nslookup
(запуск сервера)
Default Server: ns.itep.ru
Address: 193.124.224.35
set type=NS (запрос данных о серверах имен)
> > Server: ns.itep.ru
Address: 193.124.224.35
eunet.fi |
(определяем имя запрашиваемого узла) |
| eunet.fi | nameserver = ns1.EUNET.FI |
| eunet.fi | nameserver = ns2.EUNET.FI |
| eunet.fi | nameserver = ns3.eunet.fi |
| eunet.fi | nameserver = ns.eu.net |
| eunet.fi | nameserver = ns0.EUNET.FI |
| eunet.fi | nameserver = ns1.EUNET.FI |
set type=ANY
(запрос всей информации)
..........................................
Non-authoritative answer:
| eunet.fi | nameserver = ns1.EUNET.FI |
| eunet.fi | nameserver = ns2.EUNET.FI |
| eunet.fi | nameserver = ns3.eunet.fi |
| eunet.fi | nameserver = ns.eu.net |
| origin = ns1.eunet.fi | |
| mail addr = hostmaster.eunet.fi | |
| serial = 199607235 | |
| refresh = 28800 (8 hours) | |
| retry = 7200 (2 hours) | |
| expire = 604800 (7 days) | |
| minimum ttl = 86400 (1 day) | |
| eunet.fi | preference = 10, mail exchanger = pim.eunet.fi (Основной почтовый сервер) |
| eunet.fi | preference = 50, mail exchanger = mail.eunet.fi |
| eunet.fi | nameserver = ns0.EUNET.FI |
| eunet.fi | nameserver = ns1.EUNET.FI |
| eunet.fi | nameserver = ns2.EUNET.FI |
| eunet.fi | nameserver = ns3.eunet.fi |
| eunet.fi | nameserver = ns.eu.net |
| eunet.fi | nameserver = ns0.EUNET.FI |
| ns1.EUNET.FI | internet address = 192.26.119.7 |
| ns2.EUNET.FI | internet address = 192.26.119.4 |
| ns3.eunet.fi | internet address = 192.26.119.4 |
| ns.eu.net | internet address = 192.16.202.11 |
| pim.eunet.fi | internet address = 193.66.4.30 |
| mail.eunet.fi | internet address = 192.26.119.7 |
| ns0.EUNET.FI | internet address = 192.26.119.1 |
set type=MX |
(запрос информации о почтовых серверах) |
/p> ...................................
Non-authoritative answer:
| eunet.fi | preference = 50, mail exchanger = mail.eunet.fi | (имена почтовых серверов) |
| eunet.fi | preference = 10, mail exchanger = pim.eunet.fi |
Authoritative answers can be found from:
| eunet.fi | nameserver = ns1.EUNET.FI |
| eunet.fi | nameserver = ns2.EUNET.FI |
| eunet.fi | nameserver = ns3.eunet.fi |
| eunet.fi | nameserver = ns.eu.net |
| eunet.fi | nameserver = ns0.EUNET.FI |
| mail.eunet.fi | internet address = 192.26.119.7 |
| pim.eunet.fi | internet address = 193.66.4.30 |
| ns1.EUNET.FI | internet address = 192.26.119.7 |
| ns2.EUNET.FI | internet address = 192.26.119.4 |
| ns3.eunet.fi | internet address = 192.26.119.4 |
| ns.eu.net | internet address = 192.16.202.11 |
| ns0.EUNET.FI | internet address = 192.26.119.1 |
set type=SOA
(запрос параметров, зоны сервера имен, см. RFC-1034-35)
.......................................
Non-authoritative answer (см. документы RFC-1034-35):
| origin = ns1.eunet.fi | |
| mail addr = hostmaster.eunet.fi | |
| serial = 199607235 | |
| refresh = 28800 (8 часов) | |
| retry = 7200 (2 часа) | |
| expire = 604800 (7 дней) | |
| minimum ttl = 86400 (1 день) |
| eunet.fi | nameserver = ns1.EUNET.FI |
| eunet.fi | nameserver = ns2.EUNET.FI |
| eunet.fi | nameserver = ns3.eunet.fi |
| eunet.fi | nameserver = ns.eu.net |
| eunet.fi | nameserver = ns0.EUNET.FI |
| ns1.EUNET.FI | internet address = 192.26.119.7 |
| ns2.EUNET.FI | internet address = 192.26.119.4 |
| ns3.eunet.fi | internet address = 192.26.119.4 |
| ns.eu.net | internet address = 192.16.202.11 |
| ns0.EUNET.FI | internet address = 192.26.119.1 |
| >exit | (команда выхода из nslookup) |
Программа dig функционально является аналогом nslookup, но в прикладном плане имеет определенные отличия, она снабжена рядом полезных опций (таблица 5.3):
Таблица 5.3 Опции программы dig
Тип запроса |
Запись DNS-сервера |
a |
Адресная запись |
any |
Любой тип записи |
axfr |
Все записи, относящиеся к зоне |
hinfo |
Записи, характеризующие ЭВМ |
mx |
Записи, определяющие почтовый обмен |
ns |
Записи сервера имен |
soa |
Начало записей для зоны ответственности DNS-сервера |
txt |
Текстовые записи |
dig @vxdesy.desy.de ns
; <<>> DiG 2.0 <<>> @vxdesy.desy.de ns
; (3 servers found)
;; res options: init recurs defnam dnsrch
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10
;; flags: qr rd ra; Ques: 1, Ans: 9, Auth: 9, Addit: 9
;; QUESTIONS:
;;., type = NS, class = IN
;; ANSWERS:
| . | 185470 | NS | A.ROOT-SERVERS.NET. |
| . | 185470 | NS | H.ROOT-SERVERS.NET. |
| . | 185470 | NS | B.ROOT-SERVERS.NET. |
| . | 185470 | NS | C.ROOT-SERVERS.NET. |
| . | 185470 | NS | D.ROOT-SERVERS.NET. |
| . | 185470 | NS | E.ROOT-SERVERS.NET. |
| . | 185470 | NS | I.ROOT-SERVERS.NET. |
| . | 185470 | NS | F.ROOT-SERVERS.NET. |
| . | 185470 | NS | G.ROOT-SERVERS.NET. |
| . | 185470 | NS | A.ROOT-SERVERS.NET. |
| . | 185470 | NS | H.ROOT-SERVERS.NET. |
| . | 185470 | NS | B.ROOT-SERVERS.NET. |
| . | 185470 | NS | C.ROOT-SERVERS.NET. |
| . | 185470 | NS | D.ROOT-SERVERS.NET. |
| . | 185470 | NS | E.ROOT-SERVERS.NET. |
| . | 185470 | NS | I.ROOT-SERVERS.NET. |
| . | 185470 | NS | F.ROOT-SERVERS.NET. |
| . | 185470 | NS | G.ROOT-SERVERS.NET. |
| A.ROOT-SERVERS.NET. | 531366 | A | 198.41.0.4 |
| H.ROOT-SERVERS.NET | 531366 | A | 128.63.2.53 |
| B.ROOT-SERVERS.NET. | 531366 | A | 128.9.0.107 |
| C.ROOT-SERVERS.NET. | 578733 | A | 192.33.4.12 |
| D.ROOT-SERVERS.NET. | 578733 | A | 128.8.10.90 |
| E.ROOT-SERVERS.NET. | 547664 | A | 192.203.230.10 |
| I.ROOT-SERVERS.NET. | 578733 | A | 192.36.148.17 |
| F.ROOT-SERVERS.NET. | 531366 | A | 192.5.5.241 |
| G.ROOT-SERVERS.NET. | 531366 | A | 192.112.36.4 |
/p> ;; FROM: ns.itep.ru to SERVER: vxdesy.desy.de 131.169.30.46
;; WHEN: Thu Jul 25 12:07:54 1996
;; MSG SIZE sent: 17 rcvd: 429
Программа ifconfig служит для контроля состояния сетевых интерфейсов, их конфигурирования и проверки. С помощью этой команды интерфейсу присваивается IP-адрес, субсетевая маска и широковещательный адрес. Примером использования ifconfig для получения информации об интерфейсе может служить:
ifconfig le0
le0: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST>
inet 193.124.224.35 netmask ffffffe0 broadcast 193.124.224.32
Флаг UP означает, что интерфейс готов к использованию, DOWN указывает на необходимость перевода интерфейса в состояние UP с помощью команды ifconfig le0 up. Если эта команда не проходит, следует проверить соединительный кабель или сам интерфейс. Флаг RUNNING говорит о том, что интерфейс работает. При отсутствии этого флага следует проверить правильность инсталляции. Флаг BROADCAST указывает на то, что интерфейс поддерживает широковещательный режим адресации (MULTICAST - допускает многоадресное обращение). Флаг NOTRAILERS - показывает, что интерфейс не поддерживает trailer-инкапсуляцию (Ethernet). Вторая строка отклика на команду начинается с ключевого слова inet (Интернет) и содержит IP-адрес, маску субсети и широковещательный адрес. На ошибку в задании маски субсети указывает факт доступности удаленных ЭВМ и машин локальной субсети при недоступности ЭВМ соседних субсетей. При неверном задании IP-адреса возможны самые разные ошибки. При неверной сетевой части адреса команда Ping будет вызывать ошибку типа “no answer”. Ошибка же в части адреса, характеризующей ЭВМ, может быть не замечена в течение длительного времени, если носителем ошибочного адреса является персональная ЭВМ, обращений к которой извне не происходит. Определенное время можно использовать и чужой IP-адрес. Такого рода ошибки не могут быть выявлены с помощью ifconfig, здесь хорошую службу может оказать программа arp (см. описание протокола в RFC-826). Эта программа позволяет анализировать преобразование IP-адресов в физические (Ethernet). Она имеет несколько полезных опций (возможны вариации для разных реализаций и ОС):
-a |
отображает содержимое всей ARP-таблицы |
-d <имя ЭВМ> |
удаляет запись из ARP-таблицы |
-s <имя ЭВМ> <Ethernet-адрес> |
добавляет новую запись в таблицу |
/p> Ниже приведен пример исполнения команды arp, которая печатает имя объекта, его IP- и физический адреса (следует иметь в виду, что содержимое ARP-таблиц изменяется со временем, время хранения записи задается администратором сети):
arp -a
| itepgw.itep.ru | (193.124.224.33) at 0:0:c:2:3a:49 |
| ITEP-FDDI-BBone.ITEP.RU | (193.124.224.50) at 0:0:c:2:fb:c5 |
| RosNET-Gw.ITEP.Ru | (193.124.224.37) at 0:c0:14:10:1:cd |
| nb.itep.ru | (193.124.224.60) at 0:80:ad:2:24:b7 |
Одной из наиболее информативных команд является netstat (за исчерпывающим описанием опций и методов применения отсылаю к документации на ваше сетевое программное обеспечение). Эта команда может вам дать информацию о состоянии интерфейсов на ЭВМ, где она исполнена:
netstat -i
| Name | Mtu | Net/Dest | Address | Ipkts | Ierrs | Opkts | Oerrs | Collis | Queue |
| le0 | 1500 | 193.124.224.32 | ns | 966204 | 0 | 584033 | 0 | 846 | 0 |
| lo0 | 1536 | 127.0.0.0 | 127.0.0.1 | 4191 | 0 | 4191 | 0 | 0 | 0 |
netstat -nr
Маршрутная таблица
| Место назначения | Маршрутизатор | Флаги | Refcnt | Use | Интерфейс |
| 192.148.166.185 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.161 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.97 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.177 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.129 | 193.124.224.33 | UGHD | 1 | 192 | le0 |
| 192.148.166.145 | 193.124.224.33 | UGHD | 0 | 72 | le0 |
| 192.148.166.170 | 193.124.224.33 | UGHD | 0 | 4 | le0 |
| 192.148.166.26 | 193.124.224.60 | UGHD | 0 | 19 | le0 |
| 192.148.166.131 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.140 | 193.124.224.33 | UGHD | 0 | 0 | le0 |
| 192.148.166.173 | 193.124.224.33 | UGHD | 0 | 2 | le0 |
| 192.148.166.182 | 193.124.224.33 | UGHD | 0 | 20 | le0 |
| 192.148.166.142 | 193.124.224.33 | UGHD | 0 | 300 | le0 |
Возможности netstat не ограничиваются локальной сетью или автономной системой, с помощью ее можно получить некоторую информацию об удаленных ЭВМ или маршрутизаторах. Например:
netstat -r 194.85.112.34
| input packets | (le0) errs | output packets | errs | colls | input packets | Total errs | Output packets | errs | colls |
| 7636610 | 0 | 4578719 | 0 | 5918 | 7674851 | 0 | 4616960 | 0 | 5918 |
/p> Это может быть полезно при экспресс диагностике внешних каналов связи, когда простого ping или traceroute оказалось недостаточно. Если возникло подозрение относительно маршрутизации пакетов, можно сначала проверить работает ли программа gated, для этого выдайте команду:
ps ‘cat /etc/gated.pid’
после чего обратитесь к системному администратору :-).
Если нужно получить информацию о смонтированных файловых системах, вы можете воспользоваться командой:
showmount -e ns
(ns - имя ЭВМ)
export list for ns.itep.ru:
/u1/SunITEP saturn.itep.ru,suncom.itep.ru
Крайне полезна для контроля конфигурации системы команда host, она имеет много опций и с ее помощью можно узнать о доступных типах услуг, об именах и IP-адресах почтовых серверов и серверов имен, о кодах их предпочтения и т.д..
host -a vitep5
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=6
| vitep5.itep.ru | 86400 | IN | WKS | 192.148.166.198 tcp ftp telnet | |
| vitep5.itep.ru | 86400 | IN | HINFO | VAX-8530 | VMS 5.3 |
| vitep5.itep.ru | 86400 | IN | MX | 15 | mx.itep.ru |
| vitep5.itep.ru | 86400 | IN | MX | 200 | relay1.kiae.su |
| vitep5.itep.ru | 86400 | IN | MX | 210 | relay2.kiae.su |
| vitep5.itep.ru | 86400 | IN | A | 192.148.166.198 |
| relay1.kiae.su | 18938 IN | A | 193.125.152.6 |
| relay1.kiae.su | 18938 IN | A | 193.125.152.1 |
| relay2.kiae.su | 18938 IN | A | 193.125.152.1 |
В последнее время появилось несколько комплексных (общедоступных) пакетов диагностики (NetWatch, WS_watch, SNMPMAN, Netguard и др.). Некоторые из этих пакетов позволяют построить графическую модель тестируемой сети, выделяя цветом или с помощью вариации картинок работающие ЭВМ. Программы, использующие протокол SNMP, проверяют наличие посредством специального запроса доступность SNMP-демона, с помощью ICMP-протокола определяют работоспособность ЭВМ, после чего отображают переменные и массивы данных из управляющей базы данных MIB (если эта база имеет уровень доступа public). Это может делаться автоматически или по запросу оператора. SNMP-протокол позволяет мониторировать вариации загрузки отдельных сегментов сети пакетами UDP, TCP, ICMP и т.д., регистрируя количество ошибок по каждому из активных интерфейсов. Для решения этой задачи можно использовать соответствующую программу, которая регулярно опрашивает MIB интересующих вас ЭВМ, а полученные числа заносятся в соответствующий банк данных. При возникновении нештатной ситуации администратор сети может просмотреть вариации потоков в сегментах сети и выявить время и причину сбоя в системе. Аналогичные данные можно получить с помощью программы, переводящей интерфейс Ethernet в режим приема всех пакетов (mode=6). Такая программа допускает получение данных по всем типам пакетов, циркулирующих в данном кабельном сегменте. Введя в программу определенные фильтры (отбор по IP-адресам отправителей, получателей, по широковещательным запросам или определенным протоколам) можно узнать много полезного о своей сети. К сожалению, этот метод пригоден только в отношении логического сегмента, к которому подключена ваша ЭВМ. Такие программы могут использоваться для контроля сетевых ресурсов, если ЭВМ размещена на соответствующем сегменте, что может оказаться актуально в связи с коммерциализацией сетевых услуг. По этой причине метод диагностики через SNMP-резидентов более универсален. Упомянутые в начале программы Tcpdump и Etherfind крайне полезны для отладки программ, работающих с сетевыми пакетами. Они позволяют отображать все входящие и посылаемые пакеты. Следует иметь в виду, что эти программы потенциально опасны с точки зрения несанкционированного доступа и, поэтому их применение часто возможно только для привилегированных пользователей. Работа интерфейса в режиме перехвата всех пакетов также представляет угрозу безопасности сети (возможность получения чужих паролей). С учетом этого обстоятельства должно приветствоваться использование программного обеспечения, где содержимое пакетов терминального обмена подвергается шифрованию-дешифрованию.
Определенный интерес может представлять диагностическая программа ttcp, которая позволяет измерять некоторые характеристики TCP- или UDP-обменов между двумя узлами (ftp.sgi.com, каталог sgi/src/ttcp или vgr.brl.mil ftp/pub/ttcp.c).
Перечисленные режимы работают в рамках протокола TCP, для исследования процессов, требующих UDP, следует использовать опцию -u. Существует множество других опций, обеспечивающих реализацию самых разнообразных режимов работы (см. [10] и справочные руководства на вашей ЭВМ).
Конфигурация сети и режимы ее работы определяются системными переменными, которые задаются администратором сети. Имена этих сетевых переменных для разных ЭВМ и программных пакетов варьируются. Ниже будут перечислены основные переменные, определяющие работу TCP/IP протоколов для SunOS 4.1.3.
IPFORWARDING
- значение этой константы инициализирует системную переменную ip_forwarding. Если она равна -1, IP-дейтограммы никогда не переадресуются, а переменная уже никогда не меняется. Если же она равна 0 (значение по умолчанию), IP-дейтограммы не переадресуются. Переменная принимает значение 1, когда доступны несколько интерфейсов. При значении константы, равном 1, переадресация всегда разрешена.
SUBNETSARELOCAL
- константа, определяющая начальное значение переменной ip_subnetsarelocal. Если она равна 1 (по умолчанию), то IP-адрес места назначения с идентификатором сети, идентичным с тем, что имеет ЭВМ- отправитель, считается локальным вне зависимости от идентификатора субсети. Если константа равна нулю, то локальным будет считаться только адрес, принадлежащий данной субсети (при совпадении идентификаторов сети и субсети).
IPSENDREDIRECTS
- константа, используемая для определения стартового значения переменной ip_sendredirects. Если константа равна 1, (по умолчанию) ЭВМ при выполнении процедуры forward посылает ICMP-сообщения о переадресации. При равенстве нулю ICMP-сообщения не посылаются.
DIRECTED_BROADCAST
- константа, определяющая начальное значение переменной ip_dirbroadcast. Если константа равна 1 (по умолчанию), получаемые дейтограммы, адрес места назначения которых является широковещательным адресом интерфейса, переадресуются на канальный широковещательный уровень. При равенстве нулю такие дейтограммы ничтожаются.
Ряд системных переменных содержится в файле in_proto каталога /usr/kvm/sys/netinet. При изменении этих переменных система должна быть перезагружена.
tcp_default_mss
значение MSS протокола TCP для нелокальных адресатов, по умолчанию равна 512.
tcp_keepidle
определяет число 500 мс тактов между посылками запросов о работоспособности. По умолчанию равна 14400 (2 час.).
tcp_keepintvl
определяет число 500 мс тактов между посылками запросов о работоспособности, когда не получено никакого отклика. По умолчанию эта переменная равна 150 (75сек).
tcp_keeplen
используется для обеспечения совместимости с ранними версиями (4.2BSD), должна равняться 1.
tcp_nodelack
при неравенстве нулю требует отправки немедленного отклика (ACK), по умолчанию равна нулю.
tcp_recvspace
определяет размер входного TCP-буфера и влияет на величину окна. По умолчанию эта переменная равна 4096.
tcp_sendspace
определяет размер выходного TCP-буфера, по умолчанию равна 4096.
tcp_ttl
задает значение поля TTL в TCP-сегменте, по умолчанию имеет значение 60.
udp_cksum
при неравенстве нулю требует вычисления контрольной суммы для отправляемых UDP-дейтограмм и проверки контрольных сумм для получаемых UDP-дейтограмм, если поле контрольной суммы не равно нулю. По умолчанию переменная равна нулю.
udp_recvspace
определяет размер входного UDP-буфера, по умолчанию равна 18000, что соответствует двум 9000-байтным дейтограммам.
udp_sendspace
задает объем выходного UDP-буфера, ограничивая предельную длину посылаемой дейтограммы. По умолчанию переменная равна 9000.
udp_ttl
определяет значение поля TTL для UDP-дейтограмм, значение по умолчанию - 60.
Для изменения значений этих переменных необходимо иметь системные привилегии.
Диагностика на базе ICMP
5.2 Диагностика на базе ICMP
Семенов Ю.А. (ГНЦ ИТЭФ)
Безусловно SNMP предоставляет наиболее мощные и универсальные возможности диагностики. Но этот протокол не дает решить все проблемы. Не все объекты в Интернет имею активные SNMP-агенты. Как было описано в разделе Ping, протокол ICMP позволяет проверить доступность пути от машины оператора до любой ЭВМ, включенной в Интернет. При этом может быть измерено время пакета в пути и вероятность потери пакета. Проводя такое зондирование периодически и сравнивая результаты для разных моментов времени и разных путей, можно получить важную диагностическую информацию. Время пакета в пути может стать важным параметром для тестирования внешних каналов, ведь задержка может расти из-за потерь пакетов на некоторых этапах.
Потеря пакета может произойти как по пути туда, так и по пути обратно. Кроме того, отсутствие отклика может произойти из-за перегрузки буфера или процессора ЭВМ-адресата. В локальных сетях при нормальных условиях потеря может случиться только из-за переполнения буферов в переключателях или ЭВМ (объекты mac-уровня). Если сеть правильно сконфигурирована, реализуются только так называемые “короткие” столкновения, когда столкновение происходит не позднее, чем при передаче 64-го байта. Но если при построении сети допущены ошибки, возможны более поздние столкновения, что становится дополнительной причиной потери пакетов. Тогда может проявиться зависимость вероятности столкновения от длины пакета.
Следует учитывать, что если столкновение зафиксировано передающей стороной до завершения посылки пакета, то потери пакета не произойдет, так как передача будет повторена на физическом уровне. Потеря из-за столкновения может произойти только для короткого пакета при слишком больших задержках в логическом сегменте.
Понятно, что вероятность столкновений пропорциональна плотности вероятности потока запросов от активных узлов логического сегмента (зоны столкновений). По этой причине, зондируя определенный удаленный логический сегмент можно оценить вариации загрузки.
Более информативным может стать сочетание зондирования с помощью пакетов ICMP и контроль втекающих и вытекающих потоков сегмента посредством SNMP-протокола.
При использовании процедуры ping (с необходимыми опциями) для зондирования внешних каналов можно выявить как циклы пакетов, так и осцилляции маршрутов.
Протокол ICMP при круглосуточном мониторинге позволяет контролировать активность всех узлов локальной сети. Кроме того, такая программа в случае выхода из строя какого-то сегмента позволяет оперативно локализовать неисправный сетевой элемент (см. рис. 5.2.1). Сканирующая программа должна использовать в качестве исходной информации базу данных всех узлов локальной сети, куда должны быть помещены IP- и MAC-адреса всех сетевых узлов, их имена, географическое положение, фамилия хозяина и другая необходимая информация, например, суммарная задержка от какой-то точки в сети до данной рабочей станции. Результаты работы этой диагностической программы заносится в файлы, доступные для диагностического WWW-сервера. Такие данные упрощают поиск причины в случае аварии, так как позволяют проконтролировать активность в сети накануне появления отказа. Если такая программа одновременно измеряет все основные информационные потоки, она поможет выявить самые слабые участки в сети, выявить источники слишком частых широковещательных запросов. Теоретически это позволяет даже динамически реконфигурировать потоки в локальной сети, устраняя узкие места.

Рис. 5.2.1. Схема, поясняющая диагностические возможности протокола ICMP
Пусть диагностическая ЭВМ занимает положение в сети, помеченное буквой D. Сканирующая программа, позволяя проверить доступность любой из ЭВМ, может выявить неисправный вход/выход любого из повторителей, хотя сами эти приборы пассивны и на пакеты ICMP откликов не присылают. Это определяется по наличию или отсутствию отклика от хотя бы одной ЭВМ, подключенной к исследуемому входу/выходу. Так, если ни одна ЭВМ сегмента Б не откликается, то можно сделать вывод, что выход 3 повторителя 2 не исправен (предполагается, что хотя бы одна машина сегмента Б включена). Аналогичным образом можно проверить выходы повторителя 1. Если же не откликаются ЭВМ сегментов А и Б, то весьма вероятен отказ моста. Если же ни одна из ЭВМ, показанных на рисунке, не присылает отклика, а известно, что они включены, то не исправен повторитель 1. Конечно, эту задачу можно решить и с помощью стандартной программы PING, но это займет много больше времени. Администраторы, обслуживающие многомашинные сети, размещенные во многих зданиям, безусловно оценят преимущества сканирующей программы.
Сканируя всю сеть периодически в течение суток и регистрируя процент потерь пакетов в сети, можно выявить и неисправные сетевые интерфейсы. Такой интерфейс при включении может портить условия распространения пакетов по сегменту. Обнаружив корреляцию между повышением вероятности потерь пакетов и включением определенной ЭВМ, можно сделать именно такой вывод и позднее независимо исследовать именно этот сетевой интерфейс.
Протокол ICMP можно использовать и для измерения размера зоны столкновений, что крайне важно для успешной работы локальной сети, ведь превышение предельного размера зоны приводит к резкому росту числа столкновений. Вычислить размер зоны бывает затруднительно, так как для повторителей и концентраторов довольно часто время задержки не указывается. Разумеется, что оно должно быть меньше предельно допустимого, разрешенного документом 802.3, но кто может дать гарантию? Для решения поставленной задачи следует использовать ICMP пакеты минимальной длины. Программа посылает пакеты ICMP и воспринимает отклики, регистрируя долю потерянных пакетов. Для зондирования выбирается самая удаленная рабочая станция или сервер (см. рис. 5.2.2). Программа должна уметь посылать ICMP-пакеты, не дожидаясь отклика. Пакеты посылаются парами с зазором между ними t. Далее варьируем t и добиваемся максимума вероятности потери пакетов. Зазор t, при котором будет достигнут максимум потерь, соответствует реальному значению задержки, характеризующей зону столкновений для данного логического сегмента сети. Периодическая посылка пакетов слишком сильно перегрузит сеть, именно по этой причине следует периодически посылать пары пакетов. При этом период посылки таких пар должен быть достаточно велик, чтобы исключить влияние процессов восстановления после столкновения (> 1сек).

Рис. 5.2.2. Схема зондирования
RTT в данном случае равно 2Т+t, где t - время задержки отклика в зондируемой ЭВМ. Зазор между пакетами t должен быть больше t. Если t больше Т, то точность измерения будет невелика. Можно подумать, что при t Ј t вероятность столкновения будет равна 100%, но это не так. В этом случае столкновения не будет, ведь интерфейс обнаружит несущую у себя на входе и передачу не начнет. Передача отклика может начаться не ранее 9,6 мксек после завершения первого пакета-зонда (IPG). Если t < 9,6 мксек, передача отклика начнется через 9,6 мксек, если же больше, то через t. На практике 100% потери за счет столкновений будут реализовываться при t < t < Т+t (при t > 9,6 мксек). При t > t+t столкновения не будет, так как до измерительной машины дойдет пакет от исследуемой ЭВМ и передача не начнется из-за обнаружения интерфейсом несущей в кабельном сегменте. Следует иметь в виду, что при детектировании столкновения обе ЭВМ попытаются через некоторое время повторить попытку. Эта попытка вероятнее всего увенчается успехом, ведь они начнут ее не одновременно. Для извлечения нужных данных надо считывать содержимое регистра интерфейса, где записывается число случаев столкновений. Определив диапазон временных зазоров между пакетами-зондами, при которых происходят столкновения со 100% вероятностью, мы получим значение Т. Здесь требуются достаточно точные часы с разрешающей способностью лучше 10 мксек. Если таких часов нет, можно использовать время исполнения команд, предварительно прокалибровав это время при достаточно большом числе их исполнения.
Ниже на рисунке 5.2. 3 показан результат круглосуточного мониторинга в сети ГНЦ ИТЭФ. Программа позволяет не только отображать такого рода диаграммы но и измеряет относительные потери для различных сегментов сети (написана Сергеем Тимохиным). Предусмотрена возможность вывода списка машин активных в любой заданный интервал времени. По горизонтали отложено время суток 0-24 часа, а по вертикали - число ЭВМ, присылающих отклики на icmp-запросы. Нетрудно видеть, что днем активных ЭВМ больше, чем ночью. :-)

Рис. 5.2.3. Пример круглосуточного мониторинга активности в сети с использованием ICMP-зондирования
Другим примером такого мониторинга могут служить программы, контроля внешних каналов ИТЭФ и связей в пределах локальной сети. Смотри страницы:
http://saturn.itep.ru/trace/intern/start.htm
и
http://saturn.itep.ru/trace/extern/start_trace.htm
Диалог в локальных сетях и в Интернет
4.5.15 Диалог в локальных сетях и в Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)

Команды Talk (для SUN), Phone (для VAX/VMS) и другие служат для переговоров двух человек, работающих на одной и той же ЭВМ с удаленных терминалов в реальном масштабе времени. Хотя эти команды и не используют протоколы TCP/IP, они весьма удобны при работе, в частности при отладке новых телекоммуникационных каналов. Вызов осуществляется в соответствии с форматами: Talk bobyshev@ns.itep.ru или Phone <ID>, где <ID> - имя партнера (его ID, используемое при входе в ЭВМ), с которым вы хотите поговорить. При использовании этих процедур экран делится на две части по вертикали, верхняя часть предназначена для печати текста вызывающего, нижняя часть для его партнера.
Существует версия и Internet-Phone, которая обеспечивает голосовую двухстороннюю связь между пользователями сети. Этот вид услуг примыкает скорее к разновидностям сервиса, описанным в следующей главе. Для обеспечения работы такого канала связи достаточно ЭВМ PC-486SX с частотой 25МГц, памятью 8Мбайт и стандартной аудио-картой. Программы, поддерживающие этот вид сервиса, работают в рамках Windows, Winsock 1.1. При этом вы займете полосу канала шириной 7.7Кбит/c. При установке звуковой VC-платы c сжатием аудио-информации можно ограничить требования на полосу до уровня 6.72Кбит/c. Следует ожидать появления программ и на других платформах и в других средах. Общедоступное программное обеспечение для работы с аудио-версией Phone можно получить через анонимное FTP по адресу ftp.volcaltec.com (используйте ID-пользователя=ftp). Разговаривать можно только с одним партнером одновременно. Возможно совмещение разговора с другими процедурами Internet, что особенно привлекательно при диагностике и отладке каналов и сетевых программ. Internet-Phone контактирует с IRC (Internet Relay Chat, смотри подробнее в следующей главе), что позволяет получить необходимую справочную информацию. Используя возможности IRC, можно выбрать мышкой нужного вам партнера и начать беседовать с ним, если он конечно сидит у ЭВМ, которая оснащена необходимым аппаратным и программным обеспечением. В рамках этого вида сервиса вы можете обсудить какой-то документ, отображенный на экране терминалов, отмечая нужные места с помощью манипуляторов мышь. Это дает возможность согласовать в реальном масштабе времени текст документа, обсудить элементы конструкции или схемы, не тратя деньги на командировку или на дорогостоящее оборудование для видеоконференций. Бесплатно поболтать с вашим приятелем в Рио-де-Жанейро - это ли не мечта многих россиян?
Если же специального оборудования в вашем распоряжении нет, можно воспользоваться текстовой версией Talk или Phone. Обращение к Talk имеет форму:
talk имя_пользователя [ ttyname ]
Если вы хотите поговорить с кем-то на вашей ЭВМ, достаточно в качестве параметра ввести имя_пользователя (login ID). Если же ваш партнер работает на другой машине, имя адресата может иметь вид: host!пользователь или host.пользователь, или host:пользователь, или пользователь@host, где host - это имя ЭВМ, на которой работает ваш партнер. Последняя форма используется чаще. При необходимости переговорить с человеком, работающем на определенном терминале, следует ввести имя этого терминала (ttyname). При получении запроса Talk выдает на экран следующее сообщение:
Message from TalkDaemon@his_machineattime...
talk: connection requested by ваше_имя@ваша_ЭВМ.
talk: respond with: talk ваше_имя@ваша_ЭВМ
Пользователь, желающий участвовать в диалоге, должен ответить:
talk ваше_имя@ваша_ЭВМ
Когда связь установлена, оба участника диалога могут печатать текст одновременно с отображением обоих текстов в верхней и нижней частях экрана. Нажатие комбинации СTRL-L переписывает заново содержание экрана. Для завершения диалога следует нажать CTRL-Y. Имя ЭВМ адресата можно найти в файле /etc/hosts, а имя терминала в файле /etc/utmp. В процессе общения с использованием терминала возникает проблема - "пальцы не поспевают за мыслью". Традиция англоязычного общения выработала некоторые общепринятые сокращения часто используемых слов и выражений, которые могут облегчить диалог:
Таблица 4.5.15.1. Общепринятые сокращения, используемые при диалоге
IRC - (Internet Relay Chat, RFC-1459) представляет собой систему переговоров в реальном времени. Она аналогична команде talk, которая используется на многих ЭВМ в Интернет. IRC делает все, что может talk, но позволяет также переговариваться более чем двум лицам одновременно. IRC предоставляет и много других удобных услуг.
Когда вы печатаете текст в IRC, все что вы напечатали будет немедленно передано другим пользователям, кто подключен к разговору. Причем они при желании могут вам ответить в реальном масштабе времени. Темы обсуждений в IRC варьируются в широких пределах. Обычно разговор идет по-английски, но существуют каналы для немецкого, японского, финского и других языков (русский язык здесь не является исключением, какой-же русский откажет себе в удовольствии поболтать, особенно в рабочее время). Клиенты и серверы для IRC доступны через анонимное FTP по адресу: cs.bu.edu. Некоторые узлы позволяют доступ к IRC через telnet, например, wbrt.wb.psu.edu и irc.demon.co.uk. В обоих узлах вход в систему осуществляется (login) как IRC.
В таблице 4.5.15.2 приведены основные команды IRC.
Таблица 4.5.15.2. Основные команды IRC
| Команда IRC | Описание |
| /a | Отбрасывание оставшегося выхода для текущей команды |
| /help | Отобразить список IRC-команд |
| /help команда | Выдает описание команды |
| /help intro | Отображает введение в IRC |
| /help newuser | Отображает информацию о новых пользователях |
| /join канал | Подключиться к соответствующему каналу |
| /leave канал | Покинуть соответствующий канал |
| /list | Выдать информацию о всех каналах. |
| /list канал | Отобразить информацию о конкретном канале |
| /list -min n | Отобразить каналы, которые имеют как минимум n человек |
| /list –max n | Отобразить каналы, в которых не более n человек |
| /me операция | Отобразить определенную операцию |
| /mode * +p | Делает текущий канал личным |
| /msg псевдоним текст | Посылка частного сообщения указанному человеку |
| /msg , текст | Посылка сообщения последнему корреспонденту, кто вам что-то прислал |
| /msg . текст | Посылка сообщения последнему корреспонденту |
| /nick | Отобразить ваш псевдоним |
| /nick псевдоним | Изменить ваш псевдоним |
| /query псевдонимы | Послать все ваши сообщения указанным лицам |
| /query | Прекратить посылку частных сообщений |
| /quit | Прервать работу IRC (quit). |
| /set novice off | Позволить некоторые операции, например, подключение ко многим каналам |
| /who канал | Определяет, кто подключен к определенному каналу |
| /who псевдоним | Выдает информацию о конкретном человеке |
| /who * | Определяет, кто подключен к каналу |
| /whois псевдоним | Выдает всю информацию об определенном человеке |
| /whois * | Выдает всю информацию о всех |
/p> Многие серверы системы IRC для соединения друг с другом используют древовидную схему. Некоторые серверы, взаимодействуя друг с другом, передают информацию о существовании других серверов, пользователей или других ресурсов. Фундаментальной для IRC является концепция канала. Все пользователи, когда они в системе IRC, находятся на одном канале. Сначала вы входите в нулевой канал. Вы не можете послать сообщение, пока вы не вошли в канал и не задали параметры этого канала. Число каналов не ограничено.
Когда вы находитесь в системе IRC и нуждаетесь в помощи, выдайте команду /help. При возникновении проблем можно контактировать с Кристофером Девисом (Christopher Davis, ckd@eff.org) или с Еленой Роуз (Helen Rose, hrose@eff.org). Можно запросить помощь у оператора каналов IRC, например, #twilight_zone и #eu-opers. Различные документы по IRC и архивы списков рассылки IRC доступны через анонимное FTP по адресу ftp.kei.com, cs.bu.edu irc/support/alt-irc-faq или dorm.rutgers.edu pub/Internet.documents/irc.basic.guide. Группа новостей:
alt.irc, alt.irc.recovery. Имеется возможность доступа к материалам по IRC и через WWW: www.kei.com irc.html; eru.dd.chalmers.se home/f88jl/Irc; mistral.enst.fr ~pioch/IRC; alpha.acast.nova.edu IRC; www.infosystems.com cgi-bin/www2irc.
RELAY
RELAY представляет собой систему серверов в глобальной сети Bitnet/EARN, которая ретранслирует интерактивные сообщения от одного пользователя к другим, кто подписан на данный "канал" системы RELAY. Пользователь, подписанный на ближайший RELAY, виртуально подписан на всю систему RELAY. Большинство узлов RELAY отключаются в часы пик. Только некоторые из них работают 24 часа в сутки. Каждый RELAY-сервер обслуживает ограниченное число узлов, называемых сферой обслуживания. RELAY - это программа, которая позволяет нескольким людям общаться через сеть в реальном масштабе времени. Для того чтобы начать, вы должны подписаться на RELAY, для чего поместить ваш ID в текущий список пользователей. Взаимодействие с RELAY осуществляется также, как с обычным пользователем. Команды RELAY начинаются с символа /, все что не начинается с / считается сообщением и пересылается всем текущим пользователям.
RELAY доступна по следующим адресам EARN/Bitnet. В скобках приведено условное имя RELAY-ЭВМ.
| RELAY@AUVM (Wash_DC) | RELAY@PURCCVM (Purdue) |
| RELAY@BEARN (Belgium) | RELAY@SEARN (Stockholm) |
| RELAY@ITESMVF1 (Mexico) | RELAY@TAUNIVM (Israel) |
| RELAY@CEARN (Geneva) | RELAY@TECMTYVM (Monterrey) |
| RELAY@CZHRZU1A (Zurich) | MASRELAY@UBVM (Buffalo) |
| RELAY@DEARN (Germany) | RELAY@UFRJ (RioJaneiro) |
| RELAY@DKTC11 (Copenhagen) | RELAY@UIUCVMD (Urbana_IL) |
| RELAY@FINHUTC (Finland) | RELAY@USCVM (LosAngeles) |
| RELAY@GITVM1 (Atlanta) | RELAY@UTCVM (Tennessee) |
| RELAY@GREARN (Hellas) | RELAY@UWAVM (Seattle) |
| RELAY@HEARN (Holland) | RELAY@VILLVM (Philadelph) |
| RELAY@JPNSUT00 (Tokyo) | RELAY@YALEVM (Yele) |
| RELAY@NDSUVM1 (No_Dakota) | RELAY@WATDCS (Waterloo) |
При регистрации клиенту посылаются файлы RELAY INFO и RELAY USERGUIDE, которые содержат подробное описание RELAY.
Краткое руководство по применению RELAY доступно из списка файлов документов EARN. Пошлите e-mail по адресу LISTSERV@EARNCC.BITNET. В теле сообщения напечатайте: GET RELAY MEMO.
DNS (структура, обработка запросов, ресурсные записи)
4.4.12 DNS (структура, обработка запросов, ресурсные записи)
Семенов Ю.А. (ГНЦ ИТЭФ)

Рис. 4.4.12.1. Структура взаимодействия с серверами имен
База имен является распределенной, так как нет такой ЭВМ, где бы хранилась вся эта информация. Как уже отмечалось имя содержит несколько полей (длиной не более 63 символов), разделенных точками. Имя может содержать не более 255 октетов, включая байт длины. Анализ имени производится справа налево. Самая правая секция имени характеризует страну (двухсимвольные национальные коды смотри в приложении), или характер организации образовательная, коммерческая, правительственная и т.д.).
Следующие 3-х символьные коды в конце Internet-адреса означают функциональную принадлежность узла:
Таблица 4.4.12.1. Стандартизованные суффиксы имен
Маленький фрагмент интернетовской иерархии имен показан на рис. 4.4.12.2. Число уровней реально больше, но обычно не превышает 5.

Рис. 4.4.12.2. Иерархия имен в Интернет-DNS (I – домен первого уровня; II – второго уровня)
Каждому узлу (прямоугольнику на рисунке) соответствует имя, которое может содержать до 63 символов. Только самый верхний, корневой узел не имеет имени. При написании имени узла строчные и прописные символы эквивалентны. Имя домена, завершающееся точкой называется абсолютным или полным именем домена (например, itep.ru.). В некоторых странах создана структура имен сходная с com/edu/org. Так в Англии можно встретить адреса .ac.uk для академических учреждений и .co.uk - для коммерческих. Если имя домена не завершено символом точки, DNS может попытаться его дополнить, например имя ns может быть преобразовано в ns.itep.ru. На приведенной схеме каждому объекту трех верхних уровней соответствуют серверы имен, которые могут взаимодействовать друг с другом при решении задачи преобразования имени в IP-адрес. Можно было бы построить схему, при которой в любом сервере имен имелись адреса серверов .com, .edu, .ru и т.д. и при необходимости он мог бы послать туда запрос. Реальная схема серверов не столь идеальна и стройна - существуют серверы nsf.gov, oakland.edu и т.д., которые непосредственно связаны с базовым сервером имен. Каждый сервер содержит лишь часть дерева имен. Эта часть называется зоной ответственности сервера. DNS-сервер может делегировать ответственность за часть зоны другим серверам, создавая субзоны. Когда в зоне появляется новая ЭВМ или субдомен, администратор зоны записывает ее имя и IP-адреса в базу данных сервера. Администратор зоны определяет, какой из DNS-серверов имен является для данной зоны первичным. Число вторичных серверов не лимитировано. Первичный и вторичный серверы должны быть независимыми и работать на разных ЭВМ, так чтобы отказ одного из серверов не выводил из строя систему в целом. Отличие первичного сервера имен от вторичного заключается в том, что первичный загружает информацию о зоне из файлов на диске, а вторичный получает ее от первичного. Администратор вносит любые изменения в соответствующие файлы первичного сервера, а вторичные серверы получают эту информацию, периодически (раз в 3 часа) запрашивая первичный сервер. Пересылка информации из первичного во вторичные серверы имен называется зонным обменом. Как будет вести себя сервер, если он не имеет запрашиваемой информации? Он должен взаимодействовать с корневыми серверами. Таких серверов насчитывается около десяти и их IP-адреса должны содержаться в конфигурационных файлах.
Список корневых серверов вы можете получить с помощью анонимного ftp по адресам: nic.ddn.mil или ftp.rs.internic.net . Корневые серверы хранят информацию об именах и адресах всех серверов доменов второго уровня. Существует два вида запросов: рекурсивные и итеративные. Первый вид предполагает получение клиентом IP-адреса, а второй - адреса сервера, который может сообщить адрес. Первый вид медленнее, но дает сразу IP-адрес, второй эффективнее - в вашем сервере копится информация об адресах серверов имен. Одним из способов повышения эффективности трансляции имен в адреса является кэширование, то есть хранение в оперативной памяти имен-адресов, которые использовались последнее время особенно часто. Рассмотрение процесса обмена между ЭВМ-клиентом и сервером имен может прояснить работу системы в целом. Прежде чем использовать протоколы UDP или TCP прикладная программа должна узнать IP-адрес объекта, куда она хочет послать дейтограмму. Для решения этой проблемы программа посылает запрос в локальный сервер имен. В Unix-системах имеются специальные библиотечные процедуры gethostbyname и gethostbyaddr, которые позволяют определить IP-адрес по имени ЭВМ и наоборот. В одном запросе может содержаться несколько вопросов. Если сервер не сможет ответить на вопросы, он пришлет отклик, где содержатся адреса других серверов, способных решить эту задачу. Ниже на рисунке 4.4.12.3 представлен формат таких сообщений (в качестве транспорта используется UDP или TCP, порт 53).

Рис. 4.4.12.3. Формат dns-сообщений
Каждое сообщение начинается с заголовка, который содержит поле идентификация, позволяющее связать в пару запрос и отклик. Поле флаги определяет характер запрашиваемой процедуры, а также кодировку отклика. Поля число... определяют число записей соответствующего типа, содержащихся в сообщении. Так число вопросов задает число записей в секции вопросов, где записаны запросы, требующие ответов. Каждый вопрос состоит из символьного имени домена, за которым следует тип запроса и класс запроса. Значения битов поля флаги в сообщении сервера имен отображены в таблице 4.4.12.2. Разряды пронумерованы слева направо, начиная с нуля рис. 4.4.12.4.

Рис. 4.4.12.4. Назначение битов поля флаги.
Таблица 4.4.12.2. Коды поля флаги
| Код поля флаги | Описание | |
| 0 (qr) | Операция: |
0 Запрос 1 Отклик |
| 1…4 | Тип запроса (opcode): |
0 стандартный 1 инверсный 2 запрос состояния сервера |
| 5 (aa) | Равен 1 при ответе от сервера, в ведении которого находится домен, упомянутый в запросе. | |
| 6 (tc) | Равен при укорочении сообщения. Для UDP это означает, что ответ содержал более 512 октетов, но прислано только первые 512. | |
| 7 (rd) | Равен 1, если для получения ответа желательна рекурсия. | |
| 8 (ra) | Равен 1, если рекурсия для запрашиваемого сервера доступна. | |
| 9…11 | Зарезервировано на будущее. Должны равняться нулю. | |
| 12…15 | Тип отклика (rcode): |
0 нет ошибки 1 ошибка в формате запроса 2 сбой в сервере 3 имени не существует |

Рис. . 4.4.12.5. Формат секции вопросов dns-запроса.

Поле символьное имя домена имеет переменную длину, содержит одно или более субполей, начинающихся с байта длины (0-63). Поле завершается 0. Например, для ns.itep.ru (цифры представляют собой октеты длины):
В реальной нотации байты длины субполя могут иметь два старших бита равные 1, что преобразует интервал значений из 0-63 в 192-255. Такой байт в поле означает, что это не мера длины секции, а 16-битный указатель, 14 бит которого являются смещением от начала DNS-сообщения, указывающим на место продолжения секции. Смещение для первого байта поля идентификации равно нулю. Эти ухищрения придуманы для сокращения длины сообщений, так как одно и то же имя домена в отклике может повторяться много раз. Поле тип запроса характеризует разновидность запроса:
Таблица 4.4.12.3.. Разновидности полей тип запроса и их коды
| Тип запроса | Код запроса | Описание |
| A | 1 | IP-адрес |
| NS | 2 | Сервер имен. |
| CNAME | 5 | Каноническое имя. |
| SOA | 6 | Начало списка серверов. Большое число полей, определяющих часть иерархии имен, которую использует сервер. |
| MB | 7 | Имя домена почтового ящика. |
| WKS | 11 | well-known service - стандартная услуга. |
| PTR | 12 | Запись указателя. |
| HINFO | 13 | Информация об ЭВМ. |
| MINFO | 14 | Информация о почтовом ящике или списке почтовых адресов. |
| MX | 15 | Запись о почтовом сервере. |
| TXT | 16 | Не интерпретируемая строка ASCII символов. |
| AXFR | 252 | Запрос зонного обмена |
| * или ANY | 255 | Запрос всех записей. |
/p> ( Пропущенные коды являются устаревшими или экспериментальными).
Последние две строки в таблице 4.4.12.3 относятся только к вопросам. Поле класс запроса позволяет использовать имена доменов для произвольных объектов (все официальные имена Интернет относятся к одному классу [IN] - 1). В сообщении DNS-сервера каждая из секций (дополнительной информации, ответов или узловых серверов имен) состоит из набора ресурсных записей, которые описывают имена доменов и некоторую другую информацию (например, их адреса). Появление ресурсных полей в DNS базе данных придают ей новые качества. Каждая запись описывает только одно имя, формат этих записей отображен на рис. 4.4.12.6.

Рис. 4.4.12.6. Формат ресурсных записей в DNS
Имя домена в этой записи может иметь произвольную длину. Поля тип и класс характеризуют тип и класс данных, включенных в запись (аналогичны используемым в запросах). Поле время жизни (TTL) содержит время (в секундах), в течение которого запись о ресурсах может храниться в буферной памяти (в кэше). Обычно это время соответствует двум дням. Формат информации о ресурсах зависит от кода в поле тип, так для тип=1 - это 4 байта IP-адреса. Сервер имен может обслуживать и другие запросы, например, по IP-адресу определять символьное имя домена или преобразовать имя домена в адрес почтового сервера. Когда организация присоединяется к Интернет, она получает в свое распоряжение не только определенную DNS-область, но и часть пространства в in-addr.arpa, соответствующую ее IP-адресам. Домен in-addr.arpa предназначен для определения имен по их IP-адресам. Такая схема исключает процесс перебора серверов при подобном преобразовании.
Имена в домене IN-ADDR.ARPA могут иметь до четырех субполей помимо суффикса IN-ADDR.ARPA. Каждое субполе представляет собой октет IP-адреса, и содержит последовательность символов, отображающую коды в диапазоне 0-255. Так имя для IP-адреса 192.148.166.137 (если оно существует) содержится в домене с именем 137.166.148.192.IN-ADDR.ARPA. Запись адреса задом наперед диктуется общими принципами записи имен доменов (корневая часть имени находится справа). Направив несколько запросов в домен IN-ADDR.ARPA относительно имен объектов с интересующими вас IP-адресами, можно получить следующий результат:
| IP_address | Hard-addr | Delay | Date | Host_name |
| 128.141.202.101 | 00.00.0c.02.69.7d | 440 | 10/10/95 | na48-1.cern.ch |
| 192.148.166.102 | 00.00.a7.14.41.c2 | 5 | 10/10/95 | |
| 192.148.166.237 | 00.00.0c.02.69.7d | 5 | 10/10/95 | ITEP-M9.Relcom.ITEP.RU |
/p> где в левой колонке записаны IP-адреса, имена которых ищутся, во второй - записаны аппаратные адреса интерфейсов, через которые доступны искомые объекты. Поскольку первая и третья строки относятся к внешним по отношению к узлу ITEP объектам, здесь записан адрес интерфейса пограничного маршрутизатора. В третьей колонке содержится значение RTT в мсек, а в оследней - имена объектов. IP-адресу 192.148.166.102 не соответствует никакого имени.
Задержка при выполнении команды telnet между выдачей команды и появлением на экране IP-адреса связана с доступом и работой DNS-сервера. Пауза между появлением надписи Trying и Connected to определяется временем установления TCP-связи между клиентом и сервером. База данных имен может содержать и другую информацию. Типы такой информации представлены в таблице 4.4.12.3. Для извлечения информации из этой распределенной базы данных можно воспользоваться программой host (SUN или другая ЭВМ, работающая под UNIX). Рассмотрим несколько примеров (курсивом выделены команды, выданные с терминала).
host -t cname cernvm.cern.ch
cernvm.cern.ch is a nickname for crnvma.cern.ch
Напомним, что CNAME - каноническое имя узла или ЭВМ, иногда называемое также псевдонимом (alias).
host -t hinfo ns.itep.ru
ns.itep.ru HINFO SparcStation-1 SunOS-4.1.3
HINFO - информация об ЭВМ. Это обычно две последовательности символов, которые характеризуют ЭВМ и ее операционную систему. Много полезной информации можно узнать о почтовом сервере узла посредством команды:
host -t mx cl.itep.ru
cl.itep.ru is a nickname for r02vax.itep.ru
r02vax.itep.ru mail is handled by relay1.kiae.su
r02vax.itep.ru mail is handled by relay2.kiae.su
r02vax.itep.ru mail is handled by mx.itep.ru
r02vax.itep.ru mail is handled by x4u2.desy.de
host -v info.cern.ch
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=2
| info.cern.ch | 86400 | IN | CNAME | www6.cern.ch |
| www6.cern.ch | 86400 | IN | A | 128.141.202.119 |
/p> Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=1
The following answer is not authoritative:
| www6.cern.ch | 86400 | IN | A | 128.141.202.119 |
| CERN.CH | 52256 | IN | NS | dxmon.cern.ch |
| CERN.CH | 52256 | IN | NS | ns.eu.net |
| CERN.CH | 52256 | IN | NS | sunic.sunet.se |
| CERN.CH | 52256 | IN | NS | scsnms.switch.ch |
dxmon.cern.ch 79157 IN A 192.65.185.10
ns.eu.net 56281 IN A 192.16.202.11
sunic.sunet.se 85087 IN A 192.36.125.2
sunic.sunet.se 85087 IN A 192.36.148.18
scsnms.switch.ch 72545 IN A 130.59.1.30
scsnms.switch.ch 72545 IN A 130.59.10.30
Опция -v, используемая совместно с командой host позволяет получить более полную информацию об узле. Во второй колонке данной выдачи указано время жизни (TTL) в секундах. Значение TTL в первых строках соответствует суткам (24x60x60=86400). IN в следующей колонке указывает на принадлежность к классу Интернет. В четвертой колонке проставлены указатели типов запроса (см. табл. 4.4.12.3). В пятой колонке идут названия серверов имен и IP-адреса ЭВМ. Далее следуют коды предпочтения. MX-записи активно используются почтовыми серверами. Обмен MX-записями производится в следующих случаях:
Локальная сеть или ЭВМ не имеет непосредственной связи с Интернет, но желает участвовать в почтовом обмене (например, через UUCP-протокол).
Адресат не доступен и предпринимается попытка доставить почтовое сообщение альтернативной ЭВМ.
Создание виртуальных ЭВМ, куда можно пересылать почту.
MX-записи снабжены 16-битными кодами предпочтения. Если для адреса имеется несколько MX-записей, они используются в порядке нарастания этого кода. Если вы хотите узнать список доступных услуг на той или иной ЭВМ, вы можете напечатать команду (WKS - Well Known Services, сюда не входят услуги прикладного уровня, например, услуги NEWS-сервера и пр.):
host -tv wks ns.itep.ru
ns.itep.ru WKS 193.124.224.35 udp domain tftp
ns.itep.ru WKS 193.124.224. 35 tcp echo ftp telnet smtp time finger
Если вам нужно узнать IP-адреса того или иного узла можно также воспользоваться командой host:
host vxdesy.desy.de
vxdesy.desy.de has address 131.169.35.78
vxdesy.desy.de has address 131.169.35.79
vxdesy.desy.de has address 131.169.35.76
vxdesy.desy.de has address 131.169.35.77
Большая часть данных относится к типу "А".
Выше уже говорилось, что для транспортировки DNS-запросов применяются протоколы UDP и TCP. Когда же следует использовать эти протоколы? Обычно используется UDP. Когда в ответ на запрос программа получает отклик с битом флагов TC=1 (сообщение укорочено), программа повторяет запрос, но уже с использованием протокола TCP. Этот протокол применяется также для зонных обменов между первичным и вторичным DNS-серверами.
Обычно реализация сервера имен (версия BIND – Berkeley Internet Name Domain) предполагает наличие трех конфигурационных файлов:
named.boot - файл начальной загрузки сервера имен;
named.local - стартовый файл клиента DNS;
named.ca - исходный буфер имен и адресов.
Это текстовые файлы, строки и фрагменты, начинающиеся с точки с запятой, представляют собой комментарии. В первом из перечисленных файлов строка, начинающаяся со слова sortlist, указывает на порядок присылки адресов при условии, что отклик на запрос содержит несколько адресов. Строка, начинающаяся со слова directory, содержит название каталога, где хранятся конфигурационные файлы (по умолчанию /etc). Строка cache сообщает имя файла-буфера имен и адресов (по умолчанию named.ca). Далее обычно следует несколько строк, начинающихся со слова primary. Эти строки указывают имена файлов (например, named.hosts или named.local), где содержится информация о соответствии имен и адресов для определенных субдоменов. Вместо имени файла может быть указан IP-адрес. Укладка данных в файле соответствует требованиям документа RFC-1033. Для вторичного (secondary) DNS файл named.boot имеет схожую структуру. Вместо строк со словом primary в этом файле присутствуют строки secondary. Эти строки содержат помимо имен субдоменов и файлов IP-адрес первичного DNS. Последний выполняет и функцию переадресации запросов вышестоящим серверам. Вторичный DNS-сервер при невозможности выполнить запрос переадресует его первичному серверу, а не вышестоящему. Первичный сервер может создавать большой кэш-буфер для локального обслуживания часто поступающих запросов.
Файл named. local служит для спецификации интерфейса сервера имен и содержит в себе запись SOA (Start of Authority) и две ресурсных записи. Запись SOA определяет начало зоны. Символ @ в начале первой строки файла определяет имя зоны. Здесь же указываются опционные параметры:
номер версии файла (увеличивается каждый раз при внесении любых изменений, этот параметр отслеживается вторичным сервером);
время обновления данных (период запросов, посылаемых вторичным сервером первичному) в секундах;
длительность периода повторных попыток (retry) вторичного сервера в случае неудачи;
продолжительность пригодности данных (expiration time) в секундах, по истечении этого времени вторичный сервер считает всю базу данных устаревшей.
значение TTL по умолчанию.
Запись может выглядеть как (RFC-1033):
@ IN SOA SRI-NIC.ARPA. HOSTMASTER.SRI-NIC.ARPA. (
45 ;serial
3600 ;refresh
600 ;retry
3600000 ;expire
86400 ) ;minimum
В файле приводится имя первичного сервера имен для данного субдомена (флаг NS) и имя администратора с указанием адреса его электронной почты. Последняя запись в файле содержит указатель на местную ЭВМ. Первая цифра в строке этой записи содержит суффикс IP-адреса этой машины.
Файл named.ca используется для заполнения кэша при первичной загрузке DNS. Примером, иллюстрирующим возможное содержимое файла можно считать следующее (взято из RFC-1033):
;list of possible root servers
. 1 IN NS SRI-NIC.ARPA.
NS C.ISI.EDU.
NS BRL-AOS.ARPA.
NS C.ISI.EDU.
;and their addresses
SRI-NIC.ARPA. A 10.0.0.51
A 26.0.0.73
C.ISI.EDU. A 10.0.0.52
BRL-AOS.ARPA. A 192.5.25.82
A 192.5.22.82
A 128.20.1.2
A.ISI.EDU. A 26.3.0.103
Первое поле представляет собой имя домена или субдомена, второе поле – значение TTL, третье - поле класс (Internet), четвертое – тип записи (NS для сервера имен или A для адреса), и последнее поле характеризует имя ЭВМ или IP-адрес. Если какие-то поля пусты, это означает, что они тождественны приведенным выше. Точка в начале первой строки указывает на корневой домен.
Для администраторов, обслуживающих DNS, весьма полезно ознакомиться с документом RFC-1536 (“Common DNS Implementation Errors and Suggested Fixes”). Ошибки при конфигурации DNS-сервера могут привести к досадным ошибкам и отказам системы. Обычно, при получении запроса DNS сначала определяется его зона и просматривается кэш. Если запрос не может быть выполнен, просматривается список вышестоящих DNS-серверов, которые могут содержать необходимую информацию, и запрос пересылается одному из них. Если клиент прислал рекурсивный запрос и сервер поддерживает рекурсию, запрос пересылается соответствующим серверам. Если рекурсия не поддерживается, сервер возвращает клиенту список DNS-серверов, предоставляя ему решать свои проблемы самостоятельно. Однако в некоторых случаях DNS-сервер по ошибке может включить себя в такой список серверов. Если программное обеспечение клиента не проверяет список, запрос может быть послан этому серверу повторно, что вызовет бесконечный цикл запросов.
Возможна и другая схема возникновения циклов запросов. Предположим, что сервер содержит в своем списке внешних DNS сервер , а последний в свою очередь содержит в своем списке сервер . Такого рода перекрестные ссылки трудно обнаружить особенно, если в перечне фигурирует большое число серверов. Иногда возникает ситуация, когда клиент, получив список DNS-серверов, не знает, что с ним делать и посылает запрос повторно тому же серверу. Идентифицировать такого рода ошибки весьма трудно, особенно когда в это вовлечены внешние серверы, содержимое конфигурационных файлов которых недоступно.
Иногда DNS-сервер в ответ на запрос не присылает сообщений об ошибке и никаких-либо данных клиенту. Это случается когда запрашиваемое имя вполне корректно, но записей нужного типа не найдено. Например, запрошен адрес почтового сервера домена xxx.com. Домен этот существует, но рекорда типа MX не обнаружено. Дальнейшие события зависят от характера программного обеспечения клиента. Если клиент считает такого рода “отклик” некорректным, он может послать запрос повторно и т.д. и т.д. По этой причине в случае, если программное обеспечение это позволяет, рекомендуется ограничить число повторных запросов клиента. Приведенные примеры показывают, насколько актуальна корректная конфигурация DNS клиента и сервера.
В системах Windows часто используется своя служба имен WINS (Windows Internet Naming Service, см. RFC-2136 и RFC-2137). Эта служба совместима с системой динамического конфигурирования сети DHCP (Dynamic Host Configuration Protocol, использует динамическое распределение IP-адресов). В WINS, также как и в DHCP, имеются части, работающие у клиента и на сервере. WINS автоматически устанавливается и конфигурируется при установке системы DHCP. Эта система имеет удобную встроенную диагностику, позволяющую контролировать процесс обработки запросов к службе имен. WINS осуществляет преобразование NETBIOS-имен в IP-адреса. Эта техника предполагает использование протокола NetBIOS поверх TCP/IP (NetBT). В ОС WINDOWS 2000 технология WINS заменена DDNS (Dynamic Domain Name Service).
WINS-запросы обычно транспортируются в UDP-дейтограммах. При этом используется порт отправителя=137. В поле данных размешается 2-октетное поле идентификатора, позволяющего связать запрос с откликом. Далее следует 2 байта флагов, в случае запроса туда записывается 0. За ним размещается два октета, содержащие число вопросов, 2 октета числа ответов и еще 4 нулевых октетов. Завершается кадр запроса двумя октетами поля типа (00 21 -> статус узла NetBIOS) и полем класса (для Интернет 00 01 -> (IN,1)). Такие запросы позволяют получить дополнительные данные (имя узла, его MAC-адрес, NetBIOS-имя, имя группы) об ЭВМ с заданным IP-адресом. Причем эта ЭВМ может находиться где угодно в Интернет, но непременно работать в OS Windows. Формат поля данных UDP-дейтограммы запроса показан на рис. 4.4.12.7.

В поле данных UDP-дейтограммы отклика располагается 2-байтовое поле идентификатора, идентичного содержащемуся в пакете запроса. Далее следует поле флагов с длиной в два октета. Формат поля данных UDP-дейтограммы отклика показан на рис. 4.4.12.8.

Поле флаги имеет следующую структуру:
| 0 _ _ _ | _ _ _ _ | Команда |
| _ 000 | 0 _ _ _ | Запрос |
| _ _ _ _ | _ _ 0 _ | Не укорочено |
| _ _ _ _ | _ _ _ 0 | Рекурсия нежелательна |
/p>
| 1 _ _ _ | _ _ _ _ | Отклик |
| _ 000 | 0 _ _ _ | Запрос |
| _ _ _ _ | _ _ 0 _ | Не укорочено |
| _ _ _ _ | _ 1 _ _ | Официальный ответ |
| 0 _ _ _ | _ _ _ _ | Уникальное имя NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ | Активное имя |
| _ _ _ _ | _ _ 0 _ | Временное имя |
| 1 _ _ _ | _ _ _ _ | Имя группы NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ | Активное имя |
| _ _ _ _ | _ _ 0 _ | Временное имя |
Еще одной проблемой, связанной со службой имен, являются атаки, которые сопряжены с имитацией DNS. Для преодоления таких атак разработан метод транзакционных подписей TSIG (Transaction SIGnarure).
Ethernet (IEEE
4.1.1 Ethernet (IEEE 802.3)
Семенов Ю.А. (ГНЦ ИТЭФ)
Сеть Ethernet разработана в 1976 году Меткальфом и Боггсом (фирма Ксерокс). Ethernet совместно со своей скоростной версией Fast Ethernet занимает в настоящее время абсолютно лидирующую позицию (а на подходе еще и гигабитный Ethernet). Единственным недостатком данной сети является отсутствие гарантии времени доступа к среде (и механизмов, обеспечивающих приоритетное обслуживание), что делает сеть малоперспективной для решения технологических проблем реального времени. Определенные проблемы иногда создает ограничение на максимальное поле данных, равное ~1500 байт.
Fast Ethernet
4.1.1.2 Fast Ethernet
Семенов Ю.А. (ГНЦ ИТЭФ)

100-мегагерцную сеть ethernet дешевле создать на базе скрученных пар. Существует несколько версий 100-мегагерцного ethernet (100base-T4, 100base-TX, 100base-FX, стандарт 100VG-anylan - IEEE 802.12).
TX и RX передатчики и приемники входных/выходных оптоволоконных трансиверов, соответственно. FOMAU - (fiber optic media attachment unit) оптоволоконный трансивер (см. рис. 4.1.1.1.9).
Сегменты T4 (100base-T4) используют четыре скрученные пары телефонного качества (экранированные и неэкранированные скрученные пары проводов категории 3, 4 или 5) длиной до 100м. Провода должны быть скручены по всей длине, скрутка может быть прервана не далее как в 12мм от разъема (это требование справедливо и для сегментов типа TX).
Сегменты TX (100base-TX, стандарт ANSI TP-PMD) состоят из двух скрученных пар проводов информационного качества (волновое сопротивление 100-150 Ом, экранированные и неэкранированные скрученные пары проводов категории 5, длина до 100м).
FX-сегменты (100base-FX) представляют собой оптоволоконные кабели, отвечающие требованиям стандарта ANSI. Мультимодовое волокно 62,5/125 m (см. выше) работает в инфракрасном диапазоне 1350нм. Максимальная длина сегмента составляет 412 метров, ограничение определяется соображениями допустимых задержек. Предельное ослабление сигнала в волокне не должно превышать 11 дБ, стандартный кабель имеет 1-5 дБ/км. Оптические разъемы должны отвечать тем же требованиям, что и разъемы, используемые в FDDI-сетях (MIC- Media Interface Connector).
Для того, чтобы выявить, к какой модификации относится тот или иной сегмент, разработан специальный протокол распознавания, позволяющий строить сети, которые содержат оборудование и кабельные сегменты, отвечающие разным требованиям.
Универсальная схема подключения ЭВМ или любого другого оборудования (например, сетевого принтера) к 100-мегагерцному ethernet показана на рис. 4.1.1.2.1.
Физическая среда служит для передачи сигналов Ethernet от одной ЭВМ к другой. Выше были перечислены три вида физических сред, используемых 100-мегагерцным Ethernet (T4, TX и FX). Здесь используется 8-контактный разъем (RJ-45) для скрученных пар или специальный оптоволоконный соединитель. Блок PHY выполняет ту же функцию, что и трансивер в 10-мегагерцном Ethernet. Он может представлять собой набор интегральных схем в сетевом порту или иметь вид небольшой коробочки на MII-кабеле. Интерфейс MII является опционным, он может поддерживать работу с 10- и 100-мегагерцным ethernet. Задачей MII является преобразование сигналов, поступающих от PHY, в форму, приемлемую для стандартного набора ИС Ethernet. Соединительный кабель не должен быть длиннее 0,5м. PHY и MII могут быть объединены на одной интерфейсной плате, вставляемой в ЭВМ.

Рис. 4.1.1.2.1 Блок-схема подключения оборудования к 100-мегагерцному Ethernet
В сетях 100- мегагерцного Ethernet используются повторители двух классов (I и II). Задержки сигналов в повторителях класса I больше (~140нс), зато они преобразуют входные сигналы в соответствии с регламентациями применяемыми при работе с цифровыми кодами. Такие повторители могут соединять каналы, отвечающие разным требованиям, например, 100base-TX и 100base-T4 или 100base-FX. Преобразование сигнала может занимать время, соответствующее передаче нескольких бит, поэтому в пределах одного логического сегмента может быть применен только один повторитель класса I, если кабельные сегменты имеют предельную длину. Повторители часто имеют встроенные возможности управления с использованием протокола SNMP.
Повторители класса II имеют небольшие задержки (~90нс или даже меньше), но никакого преобразования сигналов здесь не производится, и по этой причине они могут объединять только однотипные сегменты. Логический сегмент может содержать не более двух повторителя класса II, если кабели имеют предельную длину. Повторители класса II не могут объединять сегменты разных типов, например, 100base-TX и 100base-T4. Согласно требованиям комитета IEEE время задержки сигнала jam в повторителе Fast Ethernet (TX и FX) не должно превышать 460 нсек, а для 100base-T4 – 670 нсек. Для повторителей класса I эта задержка не должна быть больше 1400 нсек. Значения предельных длин сегментов для различных конфигураций сети приведены в таблице 4.1.1.2.1.
Таблица
4.1.1.2.1. Максимальные размеры логического кабельного сегмента
Скрученные пары
[м]
Оптическое волокно
[м]
Таблица 4.1.1.2.2
| Сетевое устройство |
Задержка [нсек] |
| Повторитель класса I | 700 |
| Повторитель класса II (порты T4 и TX/FX) | 460 |
| Повторитель класса II (все порты T4) | 340 |
| Сетевая карта T4 | 345 |
| Сетевая карта ТХ или FX | 250 |
/p> Вариант построения 100- мегагерцной сети ethernet показан на рис. 4.1.1.2.2.
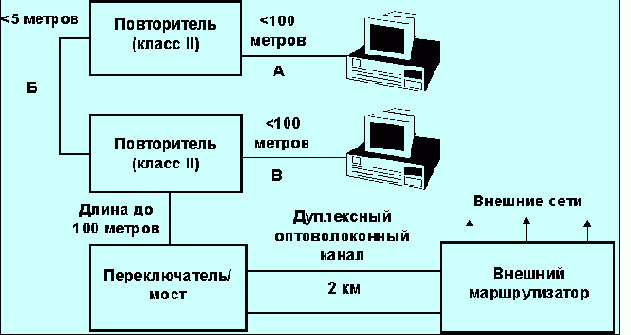
Рис. 4.1.1.2.2. Возможная схема 100-мегагерцной сети ethernet.
Из рисунка видно, что максимальная длина логического сегмента не может превышать А+Б+В = 205 метров (см. табл. 4.1.1.2.3.). Предельно допустимые длины кабелей А и В приведены в табл. 4.1.1.2.3.
Таблица 4.1.1.2.3. Максимально допустимые длины кабелей для сети, показанной на рис. 4.1.1.2.2
(Таблица взята из книги Лаема Куина и Ричарда Рассела Fast Ethernet, bhv, Киев, 1998.).
| Тип кабеля А (категория) | Тип кабеля В (категория) | Класс повторителя | Макс. длина кабеля А [м] | Макс. длина кабеля В [м] | Макс. диаметр сети [м] |
| 5,4,3 (TX, FX) | 5,4,3 (TX, FX) | I или II | 100 | 100 | 200 |
| 5 (TX) | Оптоволокно | I | 100 | 160,8 | 260,8 |
| 3 или 4 (T4) | Оптоволокно | I | 100 | 131 | 231 |
| Оптоволокно | Оптоволокно | I | 136 | 136 | 272 |
| 5 (TX) | Оптоволокно | II | 100 | 208,8 | 308,8 |
| 3 или 4 (T4) | Оптоволокно | II | 100 | 204 | 304 |
| Оптоволокно | Оптоволокно | II | 160 | 160 | 320 |
|
Номер контакта |
Назначение сигнала |
Номер контакта |
Назначение сигнала |
| 1 | Передача + | 5 | Не используется |
| 2 | Передача - | 6 | Прием - |
| 3 | Прием + | 7 | Не используется |
| 4 | Не используется | 8 | Не используется |
| Контакт 1 | Прием + |
| Контакт 5 | Передача + |
| Контакт 6 | Прием - |
| Контакт 9 | Передача - |
Таблица 4.1.1.2.4. Разъем MDI (media dependant interface) кабеля 100base-t4
| Номер контакта | Назначение сигнала |
Цвет провода |
| 1 | tx_d1 + (передача) | Белый/оранжевый |
| 2 | tx_d1 - | Оранжевый/белый |
| 3 | rx_d2 + (прием) | Белый/зеленый |
| 4 | bi_d3 + (двунаправленная) | Голубой/белый> |
| 5 | bi_d3 - | Белый/голубой |
| 6 | rx_d2 - | Зеленый/белый |
| 7 | bi_d4 + | Белый/коричневый> |
| 8 | bi_d4 - | Коричневый/белый |
/p> Как видно из таблицы, одна пара предназначена для передачи (TX), одна для приема (RX) и две для двунаправленной передачи (BI). Знак полярности сигналов обозначен соответственно + и -. Уровень логической единицы +3,5 В (CS1), нуля – 0 В (CS0), а –1 соответствует –3,5 В (CS-1). Стандарт 100base-T4 предполагает применение схемы кодирования 8B6T. Алгоритм 8B6T преобразует октет данных в 6-битовый тернарный символ, который называется кодовой группой 6Т. Эти кодовые группы передаются параллельно по трем скрученным парам сетевого кабеля, что позволяет осуществлять обмен лишь со скоростью 33,33Мбит/с. Скорость же передачи тернарных символов по каждой из пар проводов равна 6/8 от 33,33 Мбит/с, что эквивалентно 25 МГц. Шесть тернарных символов позволяют отобразить 36=729 различных кодов. Это позволяет отобрать для отображения 256 восьмибитовых кодов те тернарные символы, которые обеспечивают не менее 2 перепадов уровня сигнала. Схема подключения и передачи сигналов в сетях 100base-T4 показана на рис 4.1.1.2.3.
Пары 2 и 3 также как и в ТХ предназначены для приема и передачи данных. Пары 1 и 4 используются в двух направлениях, преобразуя канал между узлом и повторителем в полудуплексную. В процессе передачи узел использует пары 1, 2 и 4, а повторитель – пары 1, 3 и 4. Следует заметить, что схема Т4, в отличие от ТХ, может работать только в полудуплексном режиме.

Рис. 4.1.1.2.3. Схема подключения и передачи сигналов в сетях 100base-T4 (буквы К с цифрами обозначают номера контактов разъема)
В сетях Fast Ethernet максимальное значение окна коллизий равно 5,12 мксек и называется временем канала (slot time). Это время в точности соответствует минимальной длине пакета в 64 байта. Для более короткого пакета коллизия может быть не зафиксирована. Окно коллизий представляет собой время от начала передачи первого бита кадра до потери возможности регистрации коллизии с любым узлом сегмента, это время равно удвоенной задержке распространения сигнала между узлами (RTT). Конфигурация сети Fast Ethernet, для которой значение окна коллизий превышает время канала, не верна. Время канала задает величину минимального размера кадра и максимальный диаметр сети. Для пояснения этих взаимозависимостей рассмотрим сеть, показанную на рис. 4.1.1.2.4.

Рис. 4.1.1.2.4
Задержка повторителя складывается из задержек физического уровня обоих портов и собственно задержки повторителя. Задержка на физическом уровне сетевого интерфейса считается равной 250 нсек. Рассмотрим задержки сигнала для всех пар узлов (a, b и c) изображенной на рисунке сети:
| a ® b | 250+110+700+11+250 | = 1321 нсек |
| a ® c | 250+110+700+495+250 | = 1805 нсек |
| b ® c | 250+11+700+495+250 | = 1706 нсек |

Рис. 4.1.1.2.5 Временная диаграмма, поясняющая возникновение коллизий (все времена в наносекундах)
Узел В начинает передачу сразу после срабатывания его IPG-таймера, а через 484 наносекунды передачу начнет и узел С, так как канал с его точки зрения свободен. Но коллизии еще не происходит, так как их кадры еще не “столкнулись”. Для того чтобы первый бит от узла В достиг узла С, требуется 1706 наносекунд. Узел С зарегистрирует столкновение первым, это произойдет в момент 3987нсек. После этого С будет продолжать передачу еще в течение 320 нсек (сигнал jam). Сигнал jam гарантирует регистрацию коллизии повторителем. Только спустя 484 нсек коллизию обнаружит узел В, начнет передачу своего сигнала jam после чего прекратит передачу. При этом предполагается, что jam не является контрольной суммой передаваемого пакета.
Стандарт IEEE предусматривает возможность полнодуплексной связи при использовании скрученных пар или оптоволокна. Реализуется это путем выделения для каждого из направлений передачи независимого канала. Такая схема осуществляет связь типа точка-точка и при определенных условиях позволяет удвоить пропускную способность сети. Здесь нет нужды в стандартном механизме доступа к сетевой среде, невозможны здесь и столкновения. Дуплексную схему могут поддерживать все три модификации 100-мегагерцного Ethernet (100base-TX, 100base-T4 и 100base-FX). Для оптоволоконной версии дуплексной связи предельная длина сегмента может достигать 2 км (для полудуплексного варианта предельная длина сегмента может достигать 412 м). Следует иметь в виду, что для локальных сетей целесообразнее применение мультимодового оптоволокна (дешевле и больше коэффициент захвата света, но больше удельное поглощение).
В настоящее время разрабатываются новые еще более скоростные варианты Ethernet IEEE 802.3z (гигабитный Ethernet утвержден в качестве стандарта в 1998 году; 1000base-FX; ftp:/stdsbbs.ieee.org/pub, смотри также www.gigabit-rethernet.org/technology/faq.html). Эти сети ориентированы на применения 4-х скрученных пар категории 5 (до 100м) и оптоволоконных кабелей. Применяется кодировка 8В/10b. Сетевые интерфейсы используют шину PCI.
10-Гигабитный Ethernet
Хотя Ethernet на 1 Гбит/с и не использовал все свои возможности, реализован уже 10Гбитный Ethernet (IEEE 802.3ae, 10GBase-LW или 10GBase-ER). Этот стандарт утвержден в июне 2002 года и соответствует для в случае использования для построения региональных каналов спецификациям OC-192c/SDH VC-4-46c (WAN). Опробован канал длиной 200 км с 10 сегментами. Существует серийное сетевое оборудование обеспечивающее надежную передачу на скорости 10Гбит/с при длине одномодового кабеля 10 км ( l=1310 nm). Эти данные взяты из журнала "LANline" (www.lanline.de) N7, Juli 2002. При работе с оптическими волокнами могут применяться лазеры с вертикальными резонаторами и поверхностным излучением VCSEL (Vertical Cavity Surface Emitting Laser). В случае мультимодовых вариантов используются волокна с градиентом коэффициента преломления. В протоколе 10Гбит/c Ethernet предусмотрен интерфейс chip-to-chip (802.3ae-XAUI - вуквы ае означают здесь Ethernet Alliance - www.10gea.org). Такие каналы могут использоваться и в LAN для соединения переключателей сетевых кластеров. Соединение организуется по схеме точка-точка. Эта технология удобна для использования в фермах ЭВМ. Стандартизованы порты: 10Gbase-LR (до 10 км по одномодовому волокну - для высокопроизводительных магистральных и корпоративных каналов), 10Gbase-ER (до 40 км по одномодовому волокну), 10Gbase-SR (до 28 м по мультимодовому волокну - для соединений переключателей друг с другом), а также 10Gbase-LХ4 (до 300 м по мультимодовому волокну стандарта FDDI - для сетей в пределах одного здания). Обсуждается возможность построения 100Гбит/c Ethernet. В 10Gbase для локальных сетей применяется кодирование 64В/66B (вместо 8В/10B, используемого в обычном гигабитном Ethernet), так как старая схема дает 25% увеличение паразитного трафика. Следует обратить внимание, что такое решение делает непригодными существующие оптоволоконные технологии SDH/SONET. В версии 10Gbase-X4 используется кодирование 8В/10B. Там формируется 4 потока по 3,125Гбит/с, которые передаются по одному волокну (1310нм) с привлечением техники мультиплексирования длин волн (WWDM). В случае 10Gbase-W на уровне МАС вводится большая минимальная длина IPG.

Рис. 4.1.1.2.6. Схема уровней для 10Gbase Ethernet
MDI Medium Dependent Interface
XGMII 10 Gigabit Media Independent Interface
PCS Physical Coding Sublayer
PMA Physical Medium Attachment
PMD Physical Medium Dependent
WIS WAN Interface Sublayer
Таблица 4.1.1.2.5. Классификация категорий оптических волокон для сетевых приложений (данные взяты из журнала "LAN line Special" за июль-август 2002 года; www.lanline.de). Согласно принятым сокращениям буквы в конце обозначения канала (например, 10Gbase-LX) характеризуют оптическое волокно [E - Extended (для WAN или MAN, длина волны 1550нм), L - Long (для расстояний
мод
модa
10Base-FL, FPb & FBf
4 & 16 Мбит/c, Token Ringf
Fibre Channel (FC-PH)@ 133Мбит/cc,f
Fibre Channel (FC-PH)@ 266Мбит/cc,g
Fibre Channel (FC-PH)@ 531Мбит/cc,g
Fibre Channel (FC-PH)@ 1062Мбит/ce,g
1.8(OM-2)
2.6(OM-3)
Приложение в настоящее время промышленностью не поддерживается
Приложение в настоящее время не поддерживается разрабатывавшей его группой
Приложение в стадии разработки
Приложение с ограниченной полосой пропускания для указанных длин канала. Использование для каналов с более высокими требованиями в случае применения компонентов с меньшим ослаблением, не рекомендуется.
Длина канала может быть ограничена для волокон с диаметром 50 мкм.
Длина канала для одномодового волокна может быть больше, но это находится вне пределов регламентаций стандарта.
Таблица 4.1.1.2.6. Максимальные длины каналов с мультимодовыми волокнами
волны [нм]
Максимальное ослабление на км (850/130нм): 3.5/1.5 дБ/км; минимальная полоса пропускания для длин волн (850/130нм): 500МГцкм
Максимальное ослабление на км (850/130нм): 3.5/1.5 дБ/км; минимальная полоса пропускания для длин волн (850/130нм): 200МГцкм/500МГцкм
Эти приложения ограничены по полосе. Использование компонентов с меньшим поглощением для получения каналов с улучшенными параметрами, не рекомендуется.
Всякая, даже гигантская сеть была когда-то маленькой. Обычно сеть начинается с одного сегмента типа 1, 3 или 4 (рис. 4.1.1.2.1). Когда ресурсы одного сегмента или концентратора (повторители для скрученных пар) исчерпаны, добавляется повторитель. Так продолжается до тех пор, пока ресурсы удлинения сегментов и каналы концентраторов закончатся и будет достигнуто предельное число повторителей в сети (4 для 10МГц-ного Ethernet). Если при построении сети длина кабельных сегментов и их качество не контролировалось, возможен и худший сценарий - резкое увеличение числа столкновений или вообще самопроизвольное отключение от сети некоторых ЭВМ. Когда это произошло, администратор сети должен понять, что время дешевого развития сети закончилось - надо думать о приобретении мостов, сетевых переключателей, маршрутизаторов, а возможно и диагностического оборудования. Применение этих устройств может решить и проблему загрузки некоторых сегментов, ведь в пределах одного логического сегмента потоки, создаваемые каждым сервером или обычной ЭВМ, суммируются. Не исключено, что именно в этот момент сетевой администратор заметит, что топология сети неудачна и ее нужно изменить. Чтобы этого не произошло, рекомендуется с самого начала тщательно документировать все элементы (кабельные сегменты, интерфейсы, повторители и пр.). Хорошо, если уже на первом этапе вы хорошо представляете конечную цель и те возможности, которыми располагаете. Бухгалтерская сеть и сеть, ориентированная на выход в Интернет, будут иметь разные структуры. Прокладывая кабели, рекомендуется учитывать, что положение ЭВМ время от времени меняется, и это не должно приводить к изменению длины сегмента или к появлению дополнительных “сросток”. Следует также избегать применения в пределах сегмента кабелей разного типа и разных производителей. Если сеть уже создана, научитесь измерять информационные потоки в сегментах и внешние потоки (если ваша сеть соединена с другими сетями, например с Интернет), это позволит осмысленно намечать пути дальнейшей эволюции сети. Если возможности позволяют, избегайте использования дешевых сетевых интерфейсов, их параметры часто не отвечают требованиям стандарта. Сетевая архитектура требует немалых знаний и это дело лучше поручить профессионалам.
Когда потоки данных в сети достигают уровня, при котором использование мостов и сетевых переключателей уже недостаточно, можно подумать о внедрении маршрутизаторов или оптоволоконных сегментов сети FDDI или быстрого (100 Мбит/с) Ethernet. Эти субсети будут играть роль магистралей, по которым идет основной поток данных, ответвляясь в нужных местах в субсети, построенные по традиционной технологии (см. раздел FDDI). Сеть FDDI для этих целей предпочтительнее, так как она не страдает от столкновений и у нее не падает пропускная способность при перегрузке. Если в вашей сети имеются серверы общего пользования, их рекомендуется подключить к быстродействующим сегментам и организовать несколько узлов доступа к FDDI-кольцу. Остальные потребители будут соединены с FDDI через эти узлы доступа (мосты/шлюзы). Аналогичную функцию могут выполнять и сегменты быстрого Ethernet (особенно хороши для этого схемы дуплексного обмена, см. выше).
Особую проблему составляют переходы 100 Мбит/с ®10 Мбит/с (рис. 4.1.1.2.7). Дело в том, что на MAC-уровне нет механизмов понижения скорости передачи для согласования возможностей отправителя и приемника. Такие возможности существуют только на IP-уровне (ICMP-congestion). Если функцию шлюза исполняет, например, переключатель, то исключить переполнение его буфера невозможно. Такое переполнение неизбежно приведет к потере пакетов, повторным передачам и, как следствие, к потере эффективной пропускной способности канала. Решить проблему может применение в качестве шлюза маршрутизатора (здесь работает ICMP-механизм ”обратного давления”).

Рис. 4.1.1.2.7 Схема переходов 10-100-10 Мбит/с
Если любые 2 или более каналов справа попытаются начать работу с одним из каналов слева, или наоборот, потери пакетов неизбежны. Проблема исчезает, когда SW работают на IP-уровне.
Одной из наиболее популярных сетей,
|
4.1.6 Сети FDDI Семенов Ю.А. (ГНЦ ИТЭФ) |
Одной из наиболее популярных сетей, использующих оптическое волокно, (не считая fast ethernet) является FDDI. FDDI (fiber distributed data interface, ISO 9314-1, rfc-1512, -1390, -1329, -1285 - смотри также http://iquest.com/~nmaller/fddi.htm) стандарт американского института стандартов (ansi), принятый без изменения ISO. Протокол рассчитан на физическую скорость передачи информации 100 Мбит/с и предназначен для сетей с суммарной длиной до 100км (40 км для мультимодовых волокон) при расстоянии между узлами 2 км или более. Частота ошибок в сети не превышает 10-9. В FDDI используется схема двойного кольцевого счетчика (рис. 4.1.6.1; буквами a,b,c,d и e обозначены станции-концентраторы). Кольцевая схема единственно возможное решение для оптического волокна (не считая схемы точка-точка). Для доступа к сети используется специальный маркер (развитие протокола IEEE 802.5 - Token Ring). Сети FDDI не имеют себе равных при построении опорных магистралей (backbone) локальных сетей, позволяя реализовать принципиально новые возможности – удаленную обработку изображений и интерактивную графику. Обычно устройства (DAS - dual attached station) подключаются к обоим кольцам одновременно. Пакеты по этим кольцам движутся в противоположных направлениях. В норме только одно кольцо активно (первичное), но при возникновении сбоя (отказ в одном из узлов) активизируется и второе кольцо, что заметно повышает надежность системы, позволяя обойти неисправный участок (схема соединений внутри станций-концентраторов на рис. 4.1.6.1 является сильно упрощенной). Предусмотрена возможность подключения станций и только к одному кольцу (SAS - single attached station), что заметно дешевле. К одному кольцу можно подключить до 500 das и 1000 sas. Сервер и клиент имеют разные типы интерфейсов. Рис. 4.1.6.1. Схема связей в двойном кольце FDDI Топология связей в FDDI устроена таким образом, что отказ в любом из узлов из-за выхода из строя оборудования или отключения питания не приведет к разрыву кольца, поток кадров автоматически пойдет в обход поврежденного участка. FDDI позволяет работать с кадрами размером 4500 октетов, за вычетом места, занимаемого преамбулой, остается 4470 октетов для передачи данных. RFC-1188 резервирует 256 октетов для заголовков, оставляя для данных 4096 октетов. Маршрутизатор, поддерживающий протокол FDDI должен быть способен принимать такие длинные пакеты. Посылаться же должны дейтограммы не длиннее 576 октетов, если не ясно, сможет ли адресат принимать длинные кадры. Услуги информационного канала (data link service) реализуются через протокол IEEE 802.2 logical link control (LLC). В результате мы имеем следующий стек протоколов (рис. 4.1.6.2): |
/p>
|
IP/ARP |
|
802.2 llc |
|
FDDI MAC |
|
FDDI PHY |
|
FDDI PMD |
Уровень MAC ( media access control) определяет доступ к сетевой среде, включая формат кадров, адресацию, алгоритм вычисления crc и механизм исправления ошибок. Уровень PHY (physical layer protocol) задает процедуру кодирования/декодирования, синхронизацию, формирование кадров и пр. В качестве базовой используется кодировка 4b/5b (преобразование 4-битного кода в 5-битный), а в канале - NRZI. Уровень PMD (physical layer medium) определяет характеристики транспортной среды, включая оптические каналы, уровни питания, регламентирует частоту ошибок, задает требования к оптическим компонентам и разъемам. Блок схема интерфейса между уровнями MAC и PHY показана на рис. 4.1.6.3.

Рис. 4.1.6.3. Схема физического интерфейса FDDI
ip-дейтограммы, ARP-запросы и отклики, пересылаемые по сети FDDI, должны инкапсулироваться в пакеты 802.2 LLC и SNAP (subnetwork access protocol; см. рис. 4.1.6.4 и 4.1.6.5), а на физическом уровне в FDDI MAC. Протокол snap должен использоваться с организационными кодами, указывающими, что SNAP-заголовок содержит код Ethertype. 24-битовый организационный код (organization code) в snap должен быть равен нулю, а остальные 16 бит должны соответствовать Ethertype (см. assigned numbers, RFC-1700; IP=2048, ARP=2054).
Все кадры должны пересылаться в соответствии со стандартом 802.2 LLC тип 1 (формат ненумерованной информации, с полями DSAP (destination service access point) и SSAP (source service access point) заголовка 802.2, равными предписанным значениям SAP (service access point) для SNAP.

Рис. 4.1.6.4. Структура некоторых полей заголовков пакетов
Полная длина LLC- и SNAP-заголовков составляет 8 октетов.
Десятичное значение k1 равно 170 .
k2 равно 0.
Управляющий код равен 3 (ненумерованная информация).
Для преобразования 16- или 48-разрядного FDDI-адреса в 32-разрядный IP-адрес используется протокол ARP. Операционный код равен 1 для запроса и 2 для отклика. Спецификация FDDI MAC определяет максимальный размер кадра равным 4500 октетам, включая 16-октетную преамбулу. Преамбула состоит из кодов 11111, стартовый разделитель имеет вид 1100010001, а оконечный разделитель - 0110101101 (во всех случаях применена 5-битовая нотация). Контрольная сумма CRC вычисляется для полей, начиная с поля управление
по данные включительно.

Рис. 4.1.6.5. Формат пакета протокола FDDI
Вычитая 8 байт LLC/ SNAP заголовка, получаем значения максимального размера пакета (MTU) 4470 (4478) октетов. Для совместимости размер пакетов для IP-дейтограмм и ARP-пакетов согласуется с требованиями конкретной сети. FDDI реализует маркерный доступ, формат пакета-маркера имеет вид, показанный на рис. 4.1.6.6. В зависимости от размера кольца в нем могут циркулировать несколько маркеров.

Рис. 4.1.6.6. Формат кадра-маркера
802.2 класс I LLC требует поддержки команд ненумерованная информация
(UI), команд и откликов exchange identification (XID), а также test. Станции не обязаны уметь передавать команды XID и test, но должны быть способны посылать отклики.
Командные кадры идентифицируются по нулевому младшему биту SSAP-адреса. Кадры-отклики имеют младший бит SSAP-адреса равный 1. UI-команды содержат в управляющем поле LLC код 3.
Команды/отклики XID имеют код поля LLC, равный 175 (значение десятичное) при значении бита poll/final=0 или 191 при poll/final=1. Код управления LLC для команд/откликов test равен 227, если poll/final=0, и 243 при poll/final=1.
Отклики и команды UI при poll=1 игнорируются. Команды UI, имеющие отличные от snap sap в DSAP- или SSAP-полях, не считаются пакетами IP или ARP.
При получении команд XID или test должен быть послан соответствующий отклик. Отклик посылается, когда DSAP равен SNAP SAP (170), null SAP (0), или при global SAP (255). При других DSAP отклики не посылаются.
При посылке отклика на команды XID или test, значение бита final отклика должно быть равно значению бита poll команды. Кадр отклика XID должен включать в себя информационное поле 802.2 XID 129.1.0, указывающее на класс услуг 1 (не требующих установления связи).
Кадры отклика test должны соответствовать информационному полю кадра команды test.
Для начала передачи станция должна получить в свое распоряжение маркер. Если станция находится в пассивном состоянии, она передает маркер следующей станции. Но из-за большой протяженности колец FDDI время задержки здесь заметно больше, чем в случае Token Ring. В кольце FDDI может находиться несколько кадров одновременно. Станция сама удаляет кадры из кольца, посланные ей самой. Все станции должны иметь таймер вращения маркера (TRT – token rotation time), который измеряет время с момента, когда станция последний раз принимала этот пакет. Имеется переменная TTRT (target token rotation time). Значение TRT сравнивается с TTRT и только приоритетные кадры могут быть переданы при TRT> TTRT. Обычная передача данных контролируется таймером THT (token hold timer). Когда станция получает маркер, она заносит TRT в таймер THT, который начинает обратный отсчет. Станция может посылать кадры до тех пор, пока THT остается больше TTRT. В действительности THT определяет максимальное число октетов (символов), которое может быть послано станцией в рамках одного кадра (THT задает предельное время, в течение которого станция может передавать данные).
IEEE специфицирует числа как последовательности бит, где младший бит передается первым. В протоколах Интернет порядок бит другой, что может вызывать ошибки. Ниже приведена краткая таблица (4.1.6.1) соответствия для некоторых из чисел.
Таблица 4.1.6.1
|
Число |
ieee двоичное |
Интернет двоичное |
Интернет десятичное |
|
UI |
11000000 |
00000011 |
3 |
|
SAP для SNAP |
01010101 |
10101010 |
170 |
|
global SAP |
11111111 |
11111111 |
255 |
|
null SAP |
00000000 |
00000000 |
0 |
|
XID |
11110101 |
10101111 |
175 |
|
XID poll/final |
11111101 |
10111111 |
191 |
|
XID info |
129.1.0 |
||
|
test |
11000111 |
11100011 |
227 |
|
test poll/final |
11001111 |
11110011 |
243 |
FDDI- кадры используют заголовки, определяемые стандартом IEEE 802.2 (LLC - logical link control), который не имеет поля тип, присутствующий в Ethernet-заголовке. FDDI и ethernet имеют разный порядок передачи битов, поэтому мосты и маршрутизаторы между FDDI и Ethernet должны уметь выполнять соответствующие преобразования. В силу особенностей маршрутизаторов не все протоколы могут быть реализованы на стыке FDDI и Ethernet (например, DEC LAT работать не будет). Для решения проблемы созданы гибридные приборы (brouter), которые для одних протоколов работают как маршрутизаторы, являясь мостами для других. Эти приборы для одних пакетов прозрачны, другие же пересылаются с использованием инкапсуляции. Учитывая то, что FDDI может пересылать до 400000 пакетов в секунду, схемы распознавания адресов моста должна иметь соответствующее быстродействие.
Нетрадиционным для других сетей является концентратор, используемый в FDDI. Он позволяет подключить несколько приборов SAS-типа к стандартному FDDI-кольцу, создавая структуры типа дерева. Но такие структуры несут в себе определенные ограничения на длины сетевых элементов, так при использовании повторителя удаление не должно превышать 1,5 км, а в случае моста 2,5 км (одномодовый вариант). Несмотря на эти ограничения и то, что базовой топологией сетей FDDI является кольцо, звездообразные варианты также имеют право на жизнь, допустимы и комбинации этих топологий. В пределах одного здания подключение целесообразно делать через концентратор, отдельные же здания объединяются по схеме кольцо. К кольцу FDDI могут также легко подключаться и субсети Token Ring (через мост или маршрутизатор).
Концентраторы бывают двух типов: DAS и SAS. Такие приборы повышают надежность сети, так как не вынуждают сеть при отключении отдельного прибора переходить в аварийный режим обхода. Применение концентраторов снижает и стоимость подключения к FDDI. Концентраторы могут помочь при создании небольших групповых субсетей, предназначенных для решения специфических задач (например, CAD, CAM или обработка изображений).
Новым устройством, используемым в FDDI-узлах, являются межузловые процессоры (internetwork nodal processor - INP), которые являются развитием идей front end processor (FEP). INP, благодаря модульности, может помочь пользователю адаптироваться к изменениям, постоянно происходящим в сетях, где он работает. INP может выполнять функции многопротокольного моста или маршрутизатора. Управление FDDI-оборудованием производится с помощью протокола SNMP и базы данных MIB. Предусмотрены некоторые дополнительные диагностические средства, которые выявляют не только аппаратные сбои, но и некоторые программные ошибки. Применение мостов для объединения FDDI-сетей позволяет обеспечить высокую степень сетевой безопасности и решить многие топологические проблемы, снять ограничения с предельного числа DAS-подключений (
На рис. 4.1.6.7 показан пример использования сети FDDI для доступа нескольких субсетей к общему серверу без взаимного влияния потоков данных. Сегменты 1 и 2 представляют собой субсети Ethernet (10 Мбит/с). Учитывая то, что FDDI имеет пропускную способность 100 Мбит/с, даже при подключении 10 субсетей взаимовлияние их будет практически отсутствовать. Два кольца FDDI, показанные на рис. 4.1.6.7, могут быть объединены друг с другом через мост или маршрутизатор. Сетям FDDI благодаря маркерному доступу не знакомы столкновения в том виде, в каком они существуют в Ethernet и это дает им определенное преимущество перед сетями равного быстродействия, например перед быстрым Ethernet (также 100 МГц). Существует версия FDDI приспособленная для передачи мультимедийной информации. Возможна реализация FDDI на скрученных парах проводов.

Рис. 4.1.6.7. Схема использования кольца FDDI для расширения пропускной способности локальной сети
При обрывах оптоволокна возможно частичное (при двух обрывах) или полное (при одном обрыве) восстановление связности сети.

Рис. 4.1.6.8. Варианты связей в случае обрывов волокон
Finger
4.5.2 Finger
Семенов Ю.А. (ГНЦ ИТЭФ)

Finger является простым протоколом (RFC-1288), который служит для получения информации о пользователях узлов Internet. Протокол использует TCP-порт 79. Команда Finger может дать вам данные о списке пользователей, которые работают в данный момент на интересующей вас ЭВМ, о конкретном пользователе (дата последнего сеанса входа в систему и т.д.), о списке загруженных задач, о типах интерфейсов (например, терминалов). Данный протокол обеспечивает интерфейс для удаленной информационной программы пользователя (RUIP – Remote User Information Program).
Первоначальная версия такой программы была написана Les Earnest. Окончательная версия протокола была подготовлена Earl Killian из Мессачусетского Технологического Института и Brian Harvey (SAIL).
Протокол Finger базируется на TCP. Локальная ЭВМ осуществляет TCP-соединение с удаленным узлом через указанный порт. После этого становится доступной программа RUIP и пользователь может посылать ей свои запросы. Каждый запрос представляет собой строку текста. RUIP, получив запрос, анализирует его и присылает ответ, после чего соединение закрывается.
Любые пересылаемые данные должны иметь формат ASCII, не иметь контроля по четности и каждая строка должна завершаться последовательностью CRLF (ASCII 13, за которым следует ASCII 10).
Программа RUIP должна воспринимать любые запросы Finger. Такие запросы могут иметь следующий формат:
{Q1} ::= [{W}|{W}{S}{U}]{C}
{Q2} ::= [{W}{S}][{U}]{H}{C}
где {U} ::= имя_пользователя
{H} ::= @hostname | @hostname{H}
{W} ::= /W
{S} ::= | {S}
{C} ::=
{H}, является рекурсивным, по этой причине не существует каких-либо ограничений на число лексем типа @hostname в запросе. В примере спецификации {Q2}, число лексем @hostname не может превышать двух.
Следует иметь в виду, что в случае запросов "finger user@host". Программа RUIP в действительности получит "user".
Запрос {Q2} требует переадресации запроса другой программе RUIP. Программа RUIP может либо осуществить эту процедуру, либо отказать в переадресации. В случае выполнения запроса она должна это подтвердить:
Сообщая, что:
ЭВМ <H1> открывает соединение Finger <F1-2> с RUIP на ЭВМ <H2>.
<H1> выдает <H2> RUIP запрос <Q1-2> типа {Q2} (например, FOO@HOST1@HOST2).
При этом следует извлечь информацию о том, что:
ЭВМ <H2> является самой правой ЭВМ в запросе <Q1-2> (например, HOST2)
Запрос <Q2-3> является остатком запроса <Q1-2> после удаления правой части "@hostname" (например, FOO@HOST1)
Таким образом:
<H2> RUIP должна открыть соединение <F2-3> с <H3>, используя <Q2-3>.
<H2> RUIP должна прислать любую информацию, посланную от <F2-3> к <H1> через <F1-2> .
<H2> RUIP должна закрыть <F1-2> в нормальных обстоятельствах только когда <H3> RUIP закрывает <F2-3> .
По большей части вывод RUIP не следует каким-либо жестким регламентациям, так как он предназначен для чтения людьми, а не программами. Главное требование – информативность может ограничиваться только соображениями безопасности.
Запрос {C} требует выдачи списка всех работающих пользователей. RUIP должна либо ответить, либо активно отказаться. Если она отвечает, тогда она должна выдать, по крайней мере, полные имена пользователей. Системный администратор может включить в выдачу и другую полезную информацию, такую как:
Положение терминала
Расположение офиса
Рабочий номер телефона
Должность
Время пребывания в пассивном состоянии (число минут с момента ввода последнего символа или со времени завершения последней сессии).
Запрос {U}{C} является требованием присылки информации о статусе определенного пользователя {U}. Если вы не хотите выдавать такую информацию, тогда следует заблокировать работу Finger.
Ответ должен включать в себя полное имя пользователя. Если пользователь активно работает в сети, то присылаемые данные должны включать, по крайней мере, тот же объем информации что и при запросе {C}.
Так как это запрос информации об отдельном пользователе, администратор может добавить определенную информации об этом человеке, например:
Расположение офиса
Рабочий номер телефона
Номер домашнего телефона
Статус работы в системе ( not logged in, logout time, и т.д.)
Информационный файл пользователя
Информационный файл пользователя может содержать короткое сообщение, которое оставляет пользователь для передачи по запросу Finger. (Это иногда называется "plan" файлом). Это легко реализуется путем поиска программой в корневом каталоге (или в специально выделенном каталоге) пользователя файла с заданным именем. Системному администратору должно быть разрешено включать и выключать эту опцию.
При запросе Finger существует возможность запуска определенной программы пользователя. Если такая опция предусмотрена, системному администратору должно быть позволено запрещать эту процедуру. Данная опция, создавая определенные угрозы, практически беспредельно расширяет возможности Finger (см. примеры в конце раздела).
В командной строке допустимо имя пользователя или имя, под которым он входит в систему. Если имя неопределенно, реакция системы определяется системным администратором.
Лексема /W в запросе типа {Q1} или {Q2} в лучшем случае интерпретируется последней RUIP и означает требование выдачи максимально возможной информации о пользователе, в худшем случае она игнорируется.
Продающие автоматы должны реагировать на запрос {C} выдачей списка всех предметов, предлагаемых для продажи в данный момент Продающие автоматы должны откликаться на запросы {U}{C}, сообщая число различных продуктов или отделений для размещения продуктов.
Корректная реализация Finger крайне важна. В частности, RUIP должна защищать себя от некорректного ввода. Конкретная реализация программы должна проходить столь же тщательную проверку, как Telnet, FTP или SMTP.
Следует учитывать, что Finger раскрывает информацию о пользователях. Лица, ответственные за сетевую безопасность, должны решить разрешать или нет работу Finger, и какую информацию о пользователях следует рассылать.
Сетевой администратор должен иметь возможность разрешать и запрещать прохождение запросов {Q2}. Если обработка запросов {Q2} RUIP заблокировано, программа должна отсылать соответствующее сообщение (например, "Finger forwarding service denied"). По умолчанию обработка запросов {Q2} должна быть запрещена.
Программа RUIP при отправке данных должна отфильтровывать все символы вне диапазона (ASCII 32 - ASCII 126), за исключением TAB (ASCII 9) и CRLF. Такая мера обезопасит получателя.
Примеры реализации запросов.
Узел: elbereth.rutgers.edu
Командная строка: <CRLF>
Login Name TTY Idle When Office
rinehart Mark J.Rinehart p0 1:11 Mon 12:15 019 Hill x3166
greenfie Stephen J.Greenfiel p1 Mon 15:46 542 Hill x3074
rapatel Rocky - Rakesh Patel p3 4d Thu 00:58 028 Hill x2287
pleasant Mel Pleasant p4 3d Thu 21:32 019 Hill 908-932-
dphillip Dave Phillips p5 021: Sun 18:24 265 Hill x3792
dmk David Katinsky p6 2d Thu 14:11 028 Hill x2492
cherniss Cary Cherniss p7 5 Mon 15:42 127 Psychol x2008
harnaga Doug Harnaga p8 2:01 Mon 10:15 055 Hill x2351
brisco Thomas P.Brisco pe 2:09 Mon 13:37 h055 x2351
laidlaw Angus Laidlaw q0 1:55 Mon 11:26 E313C 648-5592
cje Chris Jarocha-Ernst q1 8 Mon 13:43 259 Hill x2413
Узел: dimacs.rutgers.edu
Командная строка: pirmann<CRLF>
Login name: pirmann In real life: David Pirmann
Office: 016 Hill, x2443 Home phone: 989-8482
Directory: /dimacs/u1/pirmann Shell: /bin/tcsh
Last login Sat Jun 23 10:47 on ttyp0 from romulus.rutgers.
No unread mail
Project:
Plan:
Work Schedule, Summer 1990
Rutgers LCSR Operations, 908-932-2443
Monday 5pm - 12am
Tuesday 5pm - 12am
Wednesday 9am - 5pm
Thursday 9am - 5pm
Saturday 9am - 5pm
larf larf hoo hoo
Login name: surak In real life: Ron Surak
Office: 000 OMB Dou, x9256
Directory: /u2/surak Shell: /bin/tcsh
Last login Fri Jul 27 09:55 on ttyq3
No Plan.
Login name: etter In real life: Ron Etter
Directory: /u2/etter Shell: /bin/tcsh
Never logged in.
No Plan.
Узел: dimacs.rutgers.edu
Командная строка: hedrick@math.rutgers.edu@pilot.njin.net
[pilot.njin.net]
[math.rutgers.edu]
Login name: hedrick In real life: Charles Hedrick
Office: 484 Hill, x3088
Directory: /math/u2/hedrick Shell: /bin/tcsh
Last login Sun Jun 24 00:08 on ttyp1 from monster-gw.rutge
No unread mail
No Plan.
Формат применения команды Finger:
finger [ опции ] имя...
По умолчанию finger отображает информацию обо всех активно работающих пользователях, включая имя-идентификатор, полное имя, имя терминала и т.д. В качестве имени может использоваться имя-идентификатор, фамилия или имя пользователя. Ниже приводится краткий перечень допустимых опций.
-l
-s
-q
-i
-w
-h
-p
Ниже приведен пример отклика на команду finger –l (запрос подробной информации, ЭВМ SUN):
| Login name: Ivanov | In real life: Andrey Bobyshev |
| Directory: /u1/SunITEP/bobyshev | Shell: /bin/csh |
1 minute 37 seconds Idle Time
Mail last read Thu Aug 10 12:06:20 1995
| No Plan. | (Никаких планов) |
| Login name: Petrov | In real life: Yuri Semenov |
On since Aug 10 12:14:19 on ttyp3 from semenov.itep.ru
33 seconds Idle Time
No unread mail
No Plan.
| Login name: Sidorov In real life: UU | Ekatirin |
/usr/local/lib/uucp/uucico
On since Aug 10 12:16:04 on ttyy01 57 minutes Idle Time
Mail last read Wed Nov 16 18:17:50 1994
No Plan.
В общем случае при обращении к finger может использоваться символьный Интернет-адрес:
Finger @Internet_адрес.
Возможности команды Finger варьируются в широких пределах в зависимости от конкретной реализации. Так команда (PCTCP): finger semenov@vxdesy.desy.de выдаст на экран:
[vxdesy.desy.de]
SEMENOV Semenov, Yuri SEMENOV not logged in (и это истинная правда)
Last login Thu 5-Jan-95 2:35PM-CET
[No plan]
Дополнительную информацию о команде finger можно получить:
| Описание протокола | ftp nic.merit.edu | documents/rfc/rfc1288.txt |
| ftp.csd.uwm.edu | pub/fingerinfo | |
| Информация по электронной почте | dlangley@netcom.com | в поле subject:"#finger USER@HOST.DOMAIN" |
| Через удаленный доступ | telnet rpi.edu :79 | |
| Через WWW |
http www.dlr.de cgi-greving/mfinger http sundae.triumf.ca fingerinfo.html |
|
| Через finger | finger help@dir.su.oz.au |
[extra.ucc.su.OZ.AU]
**** This is an experimental service offered free of charge by ****
**** The University Computing Service, University of Sydney. ****
**** Please mail support@is.su.edu.au if you have any queries. ****
Finger offers these additional services (Finger предлагает некоторые дополнительные возможности):
Access to a database facility (доступ к базе данных)
Usage (использование): finger %@dir.su.edu.au
is usually an "egrep" regular expression and can be (в качестве обычно используется стандартное "egrep"-выражение, а вместо можно записать):
| Aarnet | resources available on AARNet (ресурсы AARNet) |
| Buildings | buildings and their codes at Sydney Uni (коды зданий сиднейского университета) |
| Archie | query anonymous FTP databases (анонимный поиск по FTP-депозитариям) |
| Internet | resources available on the Internet (ресурсы Internet) |
| Library | library access available via AARNet (доступ к библиотечным базам данных) |
| Newsgroups | find NetNews newsgroups (поиск новостей) |
| Phone | The Sydney Uni Phone Book (телефонная книга Сиднейского университета) |
| Postcodes | Australian Postcodes (австралийские почтовые коды) |
| Shop | prices at the UCS shop (цены в университетском магазине) |
/p> Usage (использование):
| Finger help@dir.su.edu.au | this help (данный справочный материал) |
| Finger help%@dir.su.edu.au | on a particular database facility |
| Finger copyright@dir.su.edu.au | please read this copyright notice |
| Finger egrep@dir.su.edu.au | a manual on egrep regular expressions (справочные материалы по допустимым egrep-выражениям). |
Выдав команду:
| Finger 2%AArnet@dir.su.edu.au | (запрос содержимого второй раздела базы данных aarnet); |
[extra.ucc.su.oz.au]
Index for Chapter 2 (список библиотек):
Australian Defense Force Academy Library
The Australian National University Library
Curtin University Of Technology T.L. Robertson Library
Deakin University Library
Griffith University, Division of Information Services
La Trobe University Library
Macquarie University Library
Murdoch University Library
R.M.I.T. Library - MATLAS Library Catalogue.
Swinburne Library
The University of Adelaide, Barr Smith Library
The University of Melbourne Baillieu Library
The University of New England Library
The University of New South Wales
The University of Newcastle Libraries
The University of Queensland Libraries
The University of Western Australia, Reid Library
The University of Wollongong Library
University College of Central Queensland Library
University of South Australia Library Systems Dept
Victoria University of Wellington
Таким образом, даже с помощью Finger можно организовать доступ к базам данных. Finger не сработает для узлов, не имеющих IP-адресов (например, электронный почтовый адрес). Эта команда всегда позволит руководителю проекта узнать, например, когда последний раз тот или иной участник проекта работал на ЭВМ. :-)
FRED
4.5.8.2 FRED
Семенов Ю.А. (ГНЦ ИТЭФ)
"@c=RU@o=Institute for Theoretical and Experimental Physics@cn=Director"
Так как в системе WHOIS пользователи идентифицируются короткими ключами, содержащими, например, три символа, система FRED использует в процессе своей работы список цифровых псевдонимов.
Доступ к системе осуществляется, напимер, командой: telnet wp.psi.net. В качестве имени-идентификатора нужно ввести слово FRED. После этого появляется приглашение FRED> и вы можете приступать к работе. Система имеет удобную систему команд, основная из которых whois имеет несколько модификаций:
whois "semenov" -area "@c=RU@o=Institute for Theoretical and Experimental Physics команда используется, когда название "area" (место) известно.
| whois semenov@itep | Идентична предшествующей команде; | ||
| whois semenov@cl.itep.ru | Поиск записей с указанным почтовым адресом. | ||
| whois -title operator | Поиск записей, относящихся к операторам. | ||
| whois -org * | Выдача списка всех зарегистрированных организаций (для данной области поиска). | ||
| whois -org * -geo @c=US | Выдача списка зарегистрированных организаций для домена US. |
Сначала FRED считывает файл fredrc в системном каталоге ISODE (обычно /usr/etc/). Затем FRED читает файл .fredrc в каталоге пользователя. В этих файлах, если они присутствуют, содержатся описания предпочтений пользователя. После этого система выдает приглашение для ввода команд поиска. Команда INTR, выданная на базовом уровне, не вызывает никаких последствий, выдача ее дважды подряд вызовет завершение работы FRED (аналог QUIT). На других уровнях работы FRED команда INTR прерывает выполнение процедуры. Приведем перечень служебных команд.
| alias имя | При отсутствии аргументов печатает все псевдонимы, описанные в ходе данной сессии, если же аргумент имеется, определяет числовой псевдоним для данного имени. | ||
| Help команда ... | Выдает справочную информацию о командах. | ||
| Manual | Распечатывает подробное руководство по применению FRED. | ||
| Quit | Уход из системы FRED. | ||
| report subject | Позволяет вам ввести текст сообщения, которое по почте будет передано вашему местному менеджеру справочной системы "белые страницы". | ||
| set переменная значение | Производит присвоение нужных значений системным переменным FRED. | ||
| version –fred | Сообщает версию программного обеспечения. |
/p> Список системных переменных FRED представлен в таблице:
| Переменная FRED | Описание |
| debug | Отладка FRED |
| manager | Почтовый адрес местного менеджера "белых страниц". |
| namesearch | Тип имени, используемый при поиске, "fullname", "surname" или "frandly". |
| pager | Программа, используемая для разбивки текста на терминале на страницы |
| query | Подтверждение двух-шаговых операций |
| server | IP-адрес вспомогательного сервера |
| timelimit | Максимальное число секунд, которое может быть потрачено на поиск |
| verbose | Интерактивный режим с полной выдачей диагностической информации |
| ufn | Тип фильтрации при поиске: "none", "approx" или "wild". |
входное_поле тип_записи признак_области_поиска управление_выводом
Эти четыре компоненты могут встречаться в любом порядке и только входное_поле должно присутствовать обязательно. Это поле характеризует то, что вы желаете найти. Поле тип_записи говорит о том, какой вид записи в банке данных вас интересует. Поле признак_области_поиска может содержать ключи: -org (сокращение от "организация"); -unit или -locality, за которыми следует имя. Поле управление_выводом может содержать следующие ключи:
* |
выдача детальной информации со ссылками; |
~ |
выдача минимальной информации; |
% |
выдача результатов поиска в одну строку и ссылок; |
| |
выдача полной информации. |
telnet nic.switch.ch
Trying 130.59.1.40 ...
Connected to nic.switch.ch.
Escape character is '^]'.
После установления связи сервер выдаст на экран:
SWITCH (Swiss Academic and Research Network)
SunOS UNIX (nic) (ttyp9)
login: dua
SWITCHdirectory main menu (choose desired service)
| [ 1 ] | Query the Directory, select a User Interface |
| [ 2 ] | Information about the User Interfaces |
| [ 3 ] | Terminal/X Window Configuration |
| [ 4 ] | Send Message to Administrator |
| [ 5 ] | Information about the Directory Project |
| [ 6 ] | Acknowledgement |
| [ 0 ] | Leave this Menu (back to previous Menu) |
/p> Выберем пункт 1 ( с другими видами сервиса читателям предлагается познакомиться самостоятельно):
SWITCHdirectory User Interfaces
| [ 1 ] | de (simple interface to find persons) |
| [ 2 ] | fred (simple white pages interface ('whois') |
| [ 3 ] | sd (menu oriented, only read functionality) |
| [ 4 ] | Dish (command line, full X.500 functionality) |
| [ 5 ] | Xdi (X window interface) |
| [ 6 ] | Xlu (X window interface) |
| [ 7 ] | XT-DUA (Commercial X window interface) |
| [ 0 ] | Leave this Menu (back to previous Menu) |
invoking interface "fred", please wait....
fred> whois -org cern
CERN (1) +41 22
767 6111
aka: European Laboratory for Particle Physics
CERN CH-1211 Geneve 23
FAX: +41 22 767 6555
Mailbox information:
X.400: /S=postmaster/O=CERN/PRMD=CERN/ADMD=ARCOM/C=CH/
High Energy Physics research
Business: Research Laboratory Research Lab
Locality: Geneve
Name: CERN, CH (1)
Modified: Wed Aug 31 09:03:59 1994
by: DSAmanager, SWITCHdirectory, SWITCH, CH (2)
20 imprecise matches for '*', select from them [y/n] ? y
После ряда ответов на вопросы (Y/N) получаем:
7 matches found.
| 1. | CERN +41 22 767 6111 |
| 4. | Hochschule St. Gallen +41 71 30 2111 |
| 5. | IDIAP +41 26 22 7664 |
| 6. | Ingenieurschule HTL Biel +41 32 273 111 |
| 7. | Paul Scherrer Institute +41 56 992111 |
| 8. | Schweizerische Hochschulkonferenz +41 31 302 55 33 |
| 10. | SWITCH +41 1 268 1515 |
100 matches found. (найдено 100 записей)
| 16. BASF-AG | +49 621-600 |
| 21. Berufsakademie Stuttgart | +49 711 6673-6965 |
| 29. Competence Center Informatik | +49-5931-805-0 |
| 30. Computer-Communication Networks | +49 211 905828 |
| 40. Deutsche Fernkabel Gesellschaft mbH | +49 30 54686-256 |
| 41. Deutsche Forschungsgemeinschaft | +49 228/885-2485 |
| 44. Deutsches Forschungsnetz | +49 30 884299-20 |
| 51. DKRZ Hamburg | +49 40-41173-0 |
| 53. ECRC | +49 89 92 69 90 |
| 54. ERNO Raumfahrttechnik GmbH | +49 421 539 - 0 |
| 55. EUnet Deutschland GmbH | +49 231 972-00 |
| 58. European Space Agency | +49 6151-90-0 |
| 63. Fachhochschule Darmstadt | +49 6151-168876 |
| 64. Fachhochschule Dortmund | +49 231 9112-0 |
| 71. Fachhochschule Fulda | +49 661 9640-0 |
| 83. Fachhochschule Nuernberg | +49/911/58800 |
| 85. Fachhochschule Rheinland-Pfalz | +41 6131 23920 |
| 87. Fachhochschule Schweinfurt | (049) 9721 940 5 |
| 96. Fraunhofer-Gesellschaft | +49 89 1205 x01 |
| 97. Freie Universitaet Berlin | +49 30 838-1 |
| 105. GMD | +49 2241 14-0 |
fred> q (до свидания FRED!).
Гипертекстный протокол HTTP
4.5.6.1 Гипертекстный протокол HTTP
Семенов Ю.А. (ГНЦ ИТЭФ)
Протокол HTTP использован при построении глобальной информационной системы World-Wide Web (начиная с 1990).
Первые версии, такие как HTTP/0.9, представляли собой простые протоколы для передачи данных через Интернет. Версия HTTP/1.0, описанная в RFC-1945 [6], улучшила протокол, разрешив использование сообщений в формате MIME, содержащих метаинформацию о передаваемых данных, и модификаторы для запросов/откликов. Дальнейшее развитие сетей WWW-серверов потребовало новых усовершенствований, которые вряд ли являются последними.
Реальные информационные системы требуют больших возможностей, чем простой поиск и доставка данных. Для описания характера, наименования и места расположения информационных ресурсов введены: универсальный идентификатор ресурса URI (Uniform Resource Identifier), универсальный указатель ресурса URL и универсальное имя ресурса URN. Формат сообщений сходен с используемыми в электронной почте и описанный в стандарте MIME (Multipurpose Internet Mail Extensions).
HTTP используется также в качестве базового протокола для коммуникации пользовательских агентов с прокси-серверами и другими системами Интернет, в том числе и использующие протоколы SMTP, NNTP, FTP, Gopher и Wais. Последнее обстоятельство способствует интегрированию различных служб Интернет. Ниже описаны базовые понятия и термины протокола HTTP.
Прокси
Промежуточная программа, которая выполняет функции, как сервера, так и клиента. Такая программа предназначена для обслуживания запросов так, как если бы это делал первичный сервер. Запросы обслуживаются внутри или переадресуются другим серверам.
Туннель
Промежуточная программа, которая работает как ретранслятор между двумя объектами. Туннель закрывается, когда обе стороны, соединенные им прерывают сессию. Туннель может быть активирован с помощью HTTP-запроса.
Время пригодности объекта (expiration time)
Время, при котором исходный сервер требует, чтобы объект не посылался более кэшем без перепроверки пригодности.
Эвристическое значение времени жизни (heuristic expiration time)
Время пригодности, присваиваемое объекту в кэше, если это время не задано явно.
Возраст
Возраст отклика – время с момента его посылки или проверки его пригодности исходным сервером.
Время жизни (freshness lifetime)
Продолжительность времени с момента генерации отклика до истечения его пригодности.
Свежий
Отклик считается свежим, если его возраст не превысил времени его пригодности.
Устаревший
Отклик считается устаревшим, когда его возраст превысил время жизни.
Семантическая прозрачность
Кэш по отношению к конкретному отклику функционирует в “семантически прозрачном” режиме, когда его использование не имеет последствий ни для исходного сервера, ни для запрашивающего клиента. Когда кэш семантически прозрачен, клиент получает в точности тот же отклик (за исключением транспортных заголовков), какой он бы получил при непосредственном обращении к исходному серверу.
Валидатор
Протокольный элемент (например, метка объекта или время last-modified), который используется для выяснения того, является ли запись в кэше эквивалентной копией объекта.
Метод
Процедура, выполняемая над ресурсом (get, put, head, post, delete, trace и т.д.).

Рис. 4.5.6.1.1. Взаимодействие клиента, кэша и исходного сервера в протоколе HTTP
Кэш может находиться в ЭВМ клиента или агента пользователя, но может размещаться на соседнем континенте. Число прокси между клиентом и исходным сервером может варьироваться и ограничивается сверху только здравым смыслом.

Рис. 4.5.6.1.2. Структура ресурса и объекта
Протокол HTTP представляет собой протокол запросов-откликов. Клиент посылает запрос серверу в форме, определяющей метод, URI и версию протокола. В конце запроса следует MIME-подобное сообщение, содержащее модификаторы, информацию о клиенте и, возможно, другие данные. Сервер откликается, посылая статусную строку, которая включает в себя версию протокола, код результата (успех/неудача) и MIME-подобное сообщение, в котором содержатся данные о сервере и метаинформация.
Большинство HTTP-обменов инициируются пользователем и состоят из запросов ресурсов, имеющихся на определенном сервере. В простейшем случае такой запрос может быть реализован путем соединения пользовательского агента (UA) и базового сервера.
Более сложная ситуация возникает, когда присутствует один или более посредников в цепочке обслуживания запроса/отклика. Существует три стандартные формы посредников: прокси, туннель и внешний порт (gateway). Прокси представляет собой агент переадресации, получающий запрос для URI, переписывающий все сообщение или его часть и отправляющий переделанный запрос серверу, указанному URI. Внешний порт (gateway) представляет собой приемник, который работает на уровень выше некоторых других серверов и транслирует, если необходимо, запрос нижележащему протоколу сервера. Туннель действует как соединитель точка-точка и не производит каких-либо видоизменений сообщений. Туннель используется тогда, когда нужно пройти через какую-то систему (например, Firewall) в условиях, когда эта система не понимает (не анализирует) содержимое сообщений.
Запрос -------------------------------------->
UA -----v----- A -----v----- B -----v----- C -----v----- O
Рис. 4.5.6.1.3. UA – агент пользователя
На рисунке показаны три промежуточные ступени (A, B, и C) между агентом пользователя (UA) и базовым сервером (O). Запрос или отклик, двигаясь по этой цепочке, должен пройти четыре различных соединительных сегмента. Это обстоятельство крайне важно, так как некоторые опции HTTP применимы только для ближайших соединений. Хотя схема линейна, на практике узлы могут участвовать в большом числе других взаимодействий. Например, B может получать запросы от большого числа клиентов помимо A, и переадресовывать запросы к другим серверам кроме C.
Любой участник обмена, который не используется в качестве туннеля, может воспользоваться кэшем для запоминания запросов. Буфер может сократить длину цепочки в том случае, если у одного из участников процесса имеется в буфере отклик для конкретного запроса, что может, кроме прочего, заметно снизить требования к пропускной способности канала. Не все запросы могут записываться в кэш, некоторые из них могут содержать модификаторы работы с кэшем.
В действительности имеется широкое разнообразие архитектур и конфигураций буферных запоминающих устройств и прокси, разрабатываемых в настоящее время или уже доступных через World Wide Web. Эти системы включают иерархии прокси-серверов национального масштаба, задачей которых является сокращение трансокеанского трафика, системы, которые обслуживают широковещательные и мультикастинговые обмены, организации, распространяющие фрагменты информации с CD-ROM, занесенной в кэши и т. д.. HTTP-системы, используются в корпоративных сетях Интранет с большими пропускными способностями и перемежающимися соединениями. Целью HTTP/1.1 является поддержка широкого разнообразия уже существующих систем и расширение возможностей будущих приложений в отношении надежности и адаптируемости.
Коммуникации HTTP обычно реализуются через соединения TCP/IP. Порт по умолчанию имеет номер 80, но и другие номера портов вполне допустимы. Это не исключает использования HTTP поверх любого другого протокола в Интернет, или других сетей. HTTP предполагает надежное соединение; применим любой протокол, который может гарантировать корректную доставку сообщений.
В HTTP/1.0, большинство приложений используют новое соединение для каждого обмена запрос/отклик. В HTTP/1.1, соединение может быть использовано для одного или более обменов запрос/отклик, хотя соединение может быть разорвано по самым разным причинам.
4.5.6.1.1. Соглашения по нотации и общая грамматика
1.1. Расширенные BNF
Все механизмы, специфицированные в данном документе, описаны с использованием обычного текста и расширенных форм Бахуса-Наура BNF (Backus-Naur Form; см. RFC 822). Пользователи должны быть знакомы с этой нотацией для понимания данной спецификации. Расширение BNF включает в себя следующие конструкции:
name = definition
Имя правила не требует помещения в угловые скобки. Некоторые базовые правила записываются прописными буквами, например, SP, LWS, HT, CRLF, DIGIT, ALPHA и пр.
"literal"
Двойные кавычки используются для выделения символьного текста.
rule1 | rule2
Элементы, разделенные вертикальной чертой, ("|") являются альтернативными, например, "yes | no" допускает yes или no (да или нет).
(rule1 rule2)
Элементы, помещенные в круглые скобки, рассматриваются как один элемент. Так, "(elem (foo | bar) elem)" допускают последовательности "elem foo elem" и "elem bar elem".
*rule
Символ "*", предшествующий элементу, указывает на повторение. Полная форма "*element" указывает как минимум на и как максимум повторений элемента. Значения по умолчанию равны 0 и бесконечности, так что "*( элемент)" позволяет любое число, включая ноль; "1*element" требует по меньшей мере один; а "1*2element" допускает один или два.
[rule]
В квадратные скобки заключаются опционные элементы; "[foo bar]" эквивалентно "*1(foo bar)".
N rule
Специальный повтор: "(элемент)" эквивалентно "*(элемент)"; то есть, точно (element). Таким образом, 2DIGIT является 2-значным числом, а 3ALPHA представляет собой строку из трех буквенных символов.
#rule
Конструкция "#" определена подобно "*", для описания списка элементов. Полная форма имеет вид "#element ", отмечая, по меньшей мере и по большей элементов, отделенных друг от друга одной или более запятыми (",") и опционно строчным пробелом (LWS – Linear White Space). Это делает обычную форму списков очень простой. Запись "( *LWS элемент *( *LWS "," *LWS элемент)) " может быть представлена как "1#element". Всюду, где используется эта конструкция, допускаются нулевые элементы, но они не учитываются при подсчете элементов. То есть, допускается запись "(элемент), (элемент) ", но число элементов при этом считается равным двум. Следовательно, там, где необходим хотя бы один элемент, должен присутствовать, по крайней мере, один ненулевой элемент. Значениями по умолчанию являются 0 и бесконечность, таким образом "#элемент" позволяет любое число, включая нуль; "1#элемент" требует, по меньшей мере один, а "1#2элемент" допускает один или два.
; комментарий
Точка с запятой, смещенная вправо от линейки текста, открывает комментарий, который продолжается до конца строки. Это простой способ включения замечаний в текст спецификаций.
implied *LWS
Грамматика, описанная в данной спецификации, ориентирована на слова. Если не оговорено обратное, строчный пробел (LWS) может быть заключен между любыми двумя соседними словами (лексема или заключенная в кавычки строка), и между смежными лексемами (token) и разделителями (TSpecials) без изменения интерпретации поля. По крайней мере один разграничитель (TSpecials) должен присутствовать между любыми двумя лексемами, так как они иначе будут интерпретироваться как одна.
1.2. Основные правила
Следующие правила используются практически во всей спецификации для описания основных конструкций разбора (парсинга).
| OCTET | = |
| CHAR | = |
| UPALPHA | = |
| LOALPHA | = < любая строчная буква US-ASCII "a".."z"> |
| ALPHA | = UPALPHA | LOALPHA (строчная или прописная буква) |
| DIGIT | = |
| CTL | = |
| CR | = |
| LF | = |
| SP | = |
| HT | = |
| = |
| CRLF | = CR LF |
| LWS | = [CRLF] 1*( SP | HT ) |
| TEXT | = |
| HEX | = "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" | DIGIT |
| Token | = 1* |
| Tspecials | = "(" | ")" | "" | "@" |
| | "," | ";" | ":" | "\" | | |
| | "/" | "[" | "]" | "?" | "=" | |
| | "{" | "}" | SP | HT |
/p> Комментарии могут быть включены в некоторые поля HTTP заголовков, при этом текст комментария заключается в скобки. Комментарии допустимы только для полей, содержащих "comment", как часть описания поля. В других полях скобки рассматриваются как элемент содержимого поля.
| Комментарий | = "(" *( ctext | комментарий) ")" |
| ctext | = |
| quoted-string | = ( *(qdtext) ) |
| qdtext | = > |
| quoted-pair | = "\" CHAR |
2.1. Версия HTTP
HTTP использует схему нумерации "." для отображения версии протокола. Политика присвоения версии протоколу ориентирована на то, чтобы позволить отправителю указать формат сообщения и его емкость. Номер версии не меняется при добавлении компонент сообщения, которые не влияют на характер обмена.
Число увеличивается, когда в протокол внесены изменения, которые не изменили общий алгоритм разбора сообщений, но которые изменили семантику сообщений и добавили новые возможности отправителю. Число увеличивается в случае, когда изменен формат протокольного сообщения.
Версия HTTP-сообщения указывается в поле HTTP-Version в первой строке сообщения.
| HTTP | Version = "HTTP" "/" 1*DIGIT "." 1*DIGIT |
Приложения, посылающие запросы или отклики, так как это определено в спецификации, должны включать HTTP-Version "HTTP/1.1". Использование этого номера версии указывает, что посылающее приложение совместимо с этой спецификацией.
Версия HTTP приложения является верхней, совместимость с которой гарантируется. Приложения прокси-серверов и сетевых портов должны проявлять осторожность при переадресации сообщений с протокольной версией, отличной от поддерживаемой ими. Так как версия протокола указывает на возможности отправителя, прокси никогда не должны пересылать сообщения с версией больше, чем их собственная; если получено сообщение более высокой версии, прокси/порт должен либо понизить версию запроса, либо послать отклик об ошибке или переключиться в режим туннеля. Запросы с версией ниже, чем у прокси/порта могут быть повышены при переадресации, при этом major часть версии сервера и запроса должны совпадать.
Замечание: Преобразование между версиями может включать модификацию полей заголовка.
2.2. Универсальные идентификаторы ресурсов (URI)
URI известен под многими именами: WWW адрес, универсальный идентификатор документа (Universal Document Identifiers), универсальный идентификатор ресурса (Universal Resource Identifiers), и, наконец, универсальный локатор ресурса URL (Uniform Resource Locators; тождество URI и URL сомнительно, так как URL является частным случаем URI (примечание переводчика)) и универсальное имя ресурса (URN). Что касается HTTP, универсальный идентификатор ресурса представляет собой форматированную строку символов, которая идентифицирует имя, положение или какие-то еще характеристики ресурса.
2.2.1. Общий синтаксис
URI в HTTP может быть представлен в абсолютной или относительной форме по отношению к некоторому известному базовому URI, в зависимости от контекста его использования. Эти две формы отличаются тем, что абсолютный URI всегда начинается с имени схемы, за которым следует двоеточие (например HTTP: или FTP:).
| URI | = ( absoluteURI | relativeURI ) [ "#" фрагмент ] |
| AbsoluteURI | = схема ":" *( uchar | reserved ) |
| RelativeURI | = net_path | abs_path | rel_path |
| net_path | = "//" net_loc [ abs_path ] |
| abs_path | = "/" rel_path |
| rel_path | = [ проход ] [ ";" params ] [ "?" query ] |
| path | = fsegment *( "/" сегмент ) |
| fsegment | = 1*pchar |
| segment | = *pchar |
| params | = param *( ";" param ) |
| param | = *( pchar | "/" ) |
| scheme | = 1*( ALPHA | DIGIT | "+" | "-" | "." ) |
| net_loc | = *( pchar | ";" | "?" ) |
| query | = *( uchar | reserved ) |
| fragment | = *( uchar | reserved ) |
| pchar | = uchar | ":" | "@" | "&" | "=" | "+" |
| uchar | = unreserved | escape |
| unreserved | = ALPHA | DIGIT | safe | extra | national |
| escape | = "%" HEX HEX |
| reserved | = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" |
| extra | = "!" | "*" | "'" | "(" | ")" | "," |
| safe | = "$" | "-" | "_" | "." |
| unsafe | = CTL | SP | | "#" | "%" | "" |
| national | = |
/p> Более детальную информацию о синтаксисе и семантике URL можно найти в RFC-1738 [4] и RFC-1808 [11]. Приведенные выше BNF включают в себя национальные символы, недопустимые в URL, так как это специфицировано в RFC 1738, так как серверам HTTP не запрещено использование любых наборов символов, допустимых в rel_path частях адресов, HTTP-прокси могут получить запросы URI, не определенные в рамках RFC-1738.
Протокол HTTP не устанавливает каких-либо ограничений на длину URI. Серверы должны быть способны обрабатывать URI любых ресурсов, имеющих любую длину. Сервер должен выдать отклик 414 (Request-URI Too Long – URI запроса слишком длинен), если URI длиннее, чем может обработать сервер (см. раздел 9.4.15).
Замечание: Серверы должны избегать использования URI длиннее 255 байт, так как некоторые старые клиенты или прокси-приложения не могут корректно работать с такими длинами.
2.2.2. HTTP URL
Схема "HTTP" используется для локализации сетевых ресурсов с помощью протокола HTTP. Далее определены синтаксис и семантика HTTP URL, зависящие от схемы.
| http_URL | = "http:" "//" host [ ":" port ] [ abs_path ] |
| host | = |
| port | = *DIGIT |
2.2.3. Сравнение URI
При сравнении двух URI с целью проверки их идентичности, клиент должен использовать по октетное сравнение с учетом регистра, в котором напечатаны символы. Допускаются следующие исключения:
Номер порта не указан, тогда для данного URI берется значение по умолчанию;
Сравнение имен ЭВМ и схем не должно быть чувствительным к строчным/прописным буквам;
Пустой abs_path эквивалентен abs_path "/".
Символы, отличные от типов "reserved" и "unsafe" устанавливаются равными их эквивалентам в кодировке ""%" HEX HEX".
Например, следующие три URI являются эквивалентными:
http://abc.com:80/~smith/home.html
http://ABC.com/%7Esmith/home.html
http://ABC.com:/%7Esmith/home.html
3.3. Форматы даты/времени
3.3.1. Полная дата
HTTP приложения допускают три различных формата для представления метки времени и даты:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC-822, актуализировано в RFC-1123
Sunday, 06-Nov-94 08:49:37 GMT ; RFC-850, объявлено устаревшим в RFC-1036
Sun Nov 6 08:49:37 1994 ; ANSI C's ASCtime() format
Первый формат предпочтительнее, как стандарт Интернет и представляет собой форму фиксированной длины, определенную RFC-1123. Второй формат используется достаточно широко, но базируется на устаревшем документе RFC-850 [12], формат даты не имеет 4 цифр года. Клиенты и серверы HTTP/1.1, которые анализируют дату, должны уметь работать со всеми тремя форматами (для совместимости с HTTP/1.0), хотя они должны сами генерировать время/дату согласно формату RFC-1123.
Замечание: Получатели значений даты должны быть готовы принять коды, которые посланы не приложениями HTTP, что случается, когда данные поступают через прокси/порты или по почте в SMTP- или NNTP-форматах.
Все марки времени/даты HTTP должны соответствовать времени по Гринвичу (GMT). Это указано в первых двух форматах путем включения строки "GMT" и должно предполагаться во всех прочих случаях.
| HTTP-date | = RFC-1123-date | rRFC-850-date | asctime-date | |
| RFC-1123-date | = wkday "," SP date1 SP time SP "GMT" | |
| RFC-850-date | = weekday "," SP date2 SP time SP "GMT" | |
| asctime-date | = wkday SP date3 SP time SP 4DIGIT | |
| date1 | = 2DIGIT SP month SP 4DIGIT | ; day month year (e.g., 02 Jun 1982) |
| date2 | = 2DIGIT "-" month "-" 2DIGIT | ; day-month-year (e.g., 02-Jun-82) |
| date3 | = month SP ( 2DIGIT | ( SP 1DIGIT )) | ; month day (e.g., Jun 2) |
| time | = 2DIGIT ":" 2DIGIT ":" 2DIGIT | ; 00:00:00 - 23:59:59 |
| wkday | = "Mon" | "Tue" | "Wed" | "Thu" | "Fri" | "Sat" | "Sun" | |
| weekday | = "Monday" | "Tuesday" | "Wednesday" | "Thursday" | "Friday" | "Saturday" | "Sunday" | |
| month | = "Jan" | "Feb" | "Mar" | "Apr" | "May" | "Jun" | "Jul" | "Aug" | "Sep" | "Oct" | "Nov" | "Dec" |
/p> Замечание: HTTP требования для формата метки даты/времени применимы только для использования в рамках реализации самого протокола. Клиенты и сервера не требуют применения этих форматов для пользовательских презентаций, протоколирования запросов и т.д..
2.3.2. Интервалы времени в секундах
Некоторые поля заголовка HTTP допускают спецификацию значения времени в виде целого числа секунд, представленного в десятичной форме и равного времени с момента получения сообщения.
delta-seconds = 1*DIGIT
2.4. Наборы символов
HTTP использует то же определение термина "набор символов", что дано для MIME:
Термин "набор символов", используемый в данном документе, относится к методу, который с помощью одной или более таблиц преобразует последовательность октетов в последовательность символов. Заметьте, что не требуется безусловное обратное преобразование, при этом не все символы могут быть доступны и одному и тому же символу может соответствовать более чем одна последовательность октетов. Это определение имеет целью допустить различные виды кодировок символов, от простых однотабличных, таких как US-ASCII, до сложных - таблично переключаемых методов, используемых, например, в ISO 2022. Однако, определение, связанное с набором символов MIME, должно полностью специфицировать схему соответствия октетов и символов. Использование внешних профайлов для определения схемы шифрования не допустимо.
Замечание. Здесь "набор символов" ближе к понятию "кодирование символов". Однако так как HTTP и MIME используют один и тот же регистр, важно, чтобы терминология также была идентичной.
Наборы символов HTTP идентифицируются лексемами, которые не чувствительны к использованию строчных или прописных букв. Полный набор лексем определен регистром наборов символов IANA [19].
charset = token
Несмотря на то, что HTTP позволяет использовать произвольную лексему в качестве значения charset, любая лексема, значение которой определено в рамках регистра набора символов IANA, должна представлять символьный набор, определенный этим регистром. Приложение должно ограничить использование символьных наборов только теми, которые определены регистром IANA.
2.5. Кодировки содержимого
Значения кодировки содержимого указывают на кодовое преобразование, которое было или может быть выполнено над объектом. Кодировки содержимого первоначально применены для того, чтобы иметь возможность архивировать документ или преобразовать его каким-то другим способом без потери идентичности или информации. Часто объект запоминается закодированным, передается и только получателем декодируется.
content-coding = token
Все значения кодировок содержимого не зависят от того, используются строчные или прописные символы. HTTP/1.1 использует значения кодировок содержимого в полях заголовка Accept-Encoding (раздел 13.3) и Content-Encoding (раздел 13.12). Хотя значение описывает кодирование содержимого, более важным является то, что оно определяет механизм декодирования.
Комитет по стандартным числам Интернет IANA (Internet Assigned Numbers Authority) выполняет функции регистра для значений лексем кодирования содержимого, этот регистр хранит следующие лексемы:
gzip
Формат кодирования, реализуемый программой архивации файлов "gzip" (GNU zip), как описано в RFC 1952 [25]. Этот формат соответствует кодированию Lempel-Ziv (LZ77) с 32 битным CRC.
compress
Формат кодирования, реализуемый стандартной программой UNIX для архивации файлов "compress". Этот формат соответствует адаптивному методу кодирования Lempel-Ziv-Welch (LZW).
Замечание: Использование имен программ для идентификации форматов кодирования не является желательным и будет в будущем заменено. Их использование здесь является следствием исторической практики. Для совместимости с предшествующими реализациями HTTP, приложения должны считать "x-gzip" и "x-compress" эквивалентными "gzip" и "compress" соответственно.
deflate
Формат "zlib" определен документом RFC 1950 [31] в комбинации с механизмом сжатия "deflate", описанным в RFC 1951 [29].
Новые значения лексем кодирования содержимого должны регистрироваться. Для обеспечения взаимодействия между клиентами и серверами спецификации алгоритмов кодирования содержимого должны быть общедоступны.
2.6. Транспортное кодирование
Значения транспортного кодирования используются для определения кодового преобразования, которому был подвергнут или желательно подвергнуть объект для того, чтобы гарантировать безопасную его транспортировку через сеть. Этот вид преобразования отличен от кодирования содержимого, так как относится к сообщению, а не исходному объекту.
| Transfer-coding | = "chunked" | transfer-extension |
| Transfer-extension | = token |
Транспортные кодировки аналогичны используемым значениям Content-Transfer-Encoding MIME, которые были введены для обеспечения безопасной передачи двоичных данных через 7-битную транспортную среду. Однако безопасная транспортировка имеет другие аспекты в рамках 8-битного протокола передачи сообщений. В HTTP, единственной небезопасной характеристикой тела сообщения является неопределенность его длины (раздел 6.2.2), или желание зашифровать данные при передаче по общему каналу.
Блочное кодирование фрагментов модифицирует тело сообщения для того, чтобы передать его в виде последовательности пакетов, каждый со своим индикатором размера, за которым следует опционная завершающая запись (footer), содержащая поля заголовка объекта. Это позволяет передать динамически сформированное содержимое, снабдив его необходимой информацией для получателя, который, в конце концов, сможет восстановить все сообщение.
| Chunked | Body = *chunk "0" CRLF footer CRLF |
| Chunk | = chunk-size [ chunk-ext ] CRLF chunk-data CRLF |
| Hex-no-zero | = |
| Chunk-size | = hex-no-zero *HEX |
| Chunk-ext | = *( ";" chunk-ext-name [ "=" chunk-ext-value ] ) |
| Chunk-ext-name | = token |
| Chunk-ext-val | = token | quoted-string |
| Chunk-data | = chunk-size(OCTET) |
| footer | = *entity-header |
Все приложения HTTP/1.1 должны быть способны получать и декодировать получаемые фрагменты ("chunked"-кодирование), и должны игнорировать расширения транспортного кодирования, которые они не понимают. Сервер, получающий тело объекта с транспортной кодировкой, которую он не понимает, должен отослать отклик c кодом 501 (Unimplemented – не применимо), и закрыть соединение. Сервер не должен использовать транспортное кодирование при посылке данных клиенту HTTP/1.0.
2.7. Типы среды
HTTP использует типы среды Интернет (Internet Media Types) в полях заголовка Content-Type (раздел 13.18) и Accept (раздел 13.1) для того, чтобы обеспечить широкий и открытый обмен с самыми разными типа среды.
| Media-type | = type "/" subtype *( ";" parameter ) |
| type | = token |
| subtype | = token |
| Parameter | = attribute "=" value | |
| attribute | = token | |
| value | = token | quoted-string |
Замечание. Некоторые старые приложения HTTP не узнают параметры типа среды. При посылке данных старому HTTP-приложению, программы должны использовать параметры типа среды, только когда они необходимы по описанию типа/субтипа. Значения типа среды регистрируются IANA (Internet Assigned Number Authority). Процесс регистрации типа среды описан в RFC 2048 [17]. Использование незарегистрированных типов среды настоятельно не рекомендуется.
2.7.1. Канонизация и текст по умолчанию
Типы среды Интернет регистрируются каноническим образом. Вообще, тело объекта, передаваемого с помощью HTTP сообщений, должно быть представлено соответствующим каноническим способом, прежде чем будет послано, исключение составляет тип "text", как это описано в следующем параграфе.
В случае канонической формы субтип среды "text" использует CRLF для завершения строки текста. HTTP ослабляет это требование и позволяет передавать текст, используя просто CR или LF, представляющие разрыв строки. HTTP приложения должны воспринимать CRLF, “голое” CR и LF как завершение строки для текстовой среды полученной через HTTP. Кроме того, если текст представлен в символьном наборе, где нет октетов 13 и 10 для CR и LF соответственно, как это имеет место в случае мультибайтных символьных наборов, HTTP позволяет использовать соответствующие символьные представления для CR и LF. Эта гибкость в отношении разрыва строк относится только к текстовой среде в теле объекта; CR или LF не должны подставляться вместо CRLF в любые управляющие структуры HTTP (такие как поля заголовка).
Если тело объекта закодировано с помощью Content-Encoding, исходные данные, прежде чем подвергнуться кодированию должны были иметь форму, указанную выше.
Параметр "charset" используется с некоторыми типами среды, чтобы определить символьный набор (раздел 2.4). Когда параметр charset не задан отправителем явно, субтип среды "text" определяется так, что используется символьный набор по умолчанию "ISO-8859-1". Данные с набором символов, отличным от "ISO-8859-1" или его субнабора, должны помечаться соответствующим значением charset.
Некоторые программы HTTP/1.0 интерпретируют заголовок Content-Type без параметра charset, неправильно предполагая, что "получатель должен решить сам, какой это набор". Отправители, желающие заблокировать такое поведение, могут включать параметр charset, даже когда charset равен ISO-8859-1 и должны делать так, когда известно, что это не запутает получателя.
К сожалению, некоторые старые HTTP/1. 0 клиенты не обрабатывают корректно параметр charset. HTTP/1.1 получатели должны учитывать метку charset, присланную отправителем, и те агенты пользователя, которые умеют делать предположение относительно символьного набора, должны использовать символьный набор из поля content-type, если они поддерживают этот набор, а не набор, предпочитаемый получателем.
2.7.2. Составные типы
MIME обеспечивает нескольких составных типов – инкапсуляция одного или более объектов в общее тело сообщения. Все составные типы имеют общий синтаксис, как это определено в MIME [7], и должны включать граничный параметр, являющийся частью значения типа среды. Тело сообщения является само протокольным элементом и, следовательно, должно использовать только CRLF для обозначения разрывов строки. В отличии от MIME, завершающая часть любого составного cообщения должна быть пустой. HTTP приложения не должны передавать завершающую часть (даже если исходное составное сообщение содержит такую завершающую часть (эпилог-подпись).
В HTTP, составляющие части тела могут содержать поля заголовка, которые существенны для значения этих частей. Рекомендуется, чтобы поле заголовка Content-Location (раздел 13.15) было включено в часть тела каждого вложенного объекта, который может быть идентифицирован URL.
Вообще, рекомендуется, чтобы агент пользователя HTTP имел идентичное или схожее поведение с агентом пользователя MIME при получении составного типа. Если приложение получает неузнаваемый составной субтип, оно должно обрабатывать его также как "multipart/mixed".
Замечание: Тип "multipart/form-data" специально определен для переноса данных совместимого с методом обработки почтовых запросов, как это описано в RFC 1867 [15].
2.8. Лексемы (token) продукта
Лексемы продукта служат для того, чтобы позволить взаимодействующим приложениям идентифицировать себя с помощью имени и версии программного продукта. Большинство полей, использующих лексемы продукта допускают также включение в список субпродуктов, которые образуют существенную часть приложения, их лексемы отделяются пробелом. По договоренности, продукты перечисляются в порядке их важности для идентификации приложения.
| Product | = token ["/" product-version] |
| Product-version | = token |
/p> Примеры:
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Server: Apache/0.8.4
Лексемы продукта должны быть короткими и, кроме того, использование их для оповещения или передачи маловажной информации абсолютно запрещено. Хотя любой символ лексемы может присутствовать в версии продукта, рекомендуется, чтобы эта лексема использовалась только для идентификации версии (то есть, последовательные версии одного и того же продукта должны отличаться только в части версии продукта).
2.9. Значения качества (Quality values)
HTTP согласование параметров содержимого (раздел 12) использует короткие числа с плавающей запятой для указания относительной важности (веса) различных согласуемых параметров. Вес нормализуется на истинное число в диапазоне 0 - 1, где 0 равен минимальному, а 1 максимальному значению. Приложения HTTP/1.1 не должны генерировать более трех чисел после запятой. Рекомендуется, чтобы конфигурация пользователя для этих значений удовлетворяла тем же ограничениям.
qvalue = ( "0" [ "." 0*3DIGIT ] ) | ( "1" [ "." 0*3("0") ] )
"Quality values" (значения качества) является неверным названием, так как эти значения в большей степени отражают относительную деградацию желательного качества.
2.10. Языковые метки
Языковая метка идентифицирует естественный язык. Компьютерные языки в этот перечень не входят. HTTP использует языковые метки в полях Accept-Language и Content-Language.
Синтаксис и регистр языковых меток HTTP тот же, что и определенный в RFC 1766 [1]. Языковая метка содержит одну или более частей: первичная языковая метка и последовательность субметок, которая может и отсутствовать:
| language-tag | = primary-tag *( "-" sub-tag ) |
| primary-tag | = 1*8ALPHA |
| sub-tag | = 1*8ALPHA |
en, en-US, en-cockney, i-cherokee, x-pig-latin
где любые две буквы первичной метки представляют собой языковую аббревиатуру ISO 639 и две буквы исходной субметки соответствуют коду страны ISO 3166 (последние три метки не являются зарегистрированными; все кроме последней могут быть зарегистрированы в будущем).
2.11. Метки объектов
Метки объектов служат для сравнения двух или более объектов из одного и того же запрошенного ресурса. HTTP/1.1 использует метки объектов в полях заголовков ETag (раздел 13.20), If-Match (раздел 13.25), If-None-Match (раздел 13.26) и If-Range (раздел 13.27). Метки объекта состоят из строк, заключенных в кавычки, перед ней может размещаться индикатор слабости.
| entity-tag | = [ weak ] opaque-tag |
| Weak | = "W/" |
| opaque-tag | = quoted-string |
"Слабая метка объекта " (weak entity tag) отмечается префиксом "W/", может относиться к двум объектам ресурса, только если объекты эквивалентны и могут быть взаимозаменяемы. Слабая метка объекта может использоваться для "слабого" сравнения.
Метка объекта должна быть уникальной для всех версий всех объектов, сопряженных с конкретным ресурсом. Значение данной метки объекта может использоваться для объектов, полученных в результате запросов для различных URI без использования данных об эквивалентности этих объектов.
2.12. Структурные единицы
HTTP/1.1 позволяет клиенту запросить только часть объекта (диапазон). HTTP/1.1 использует структурные единицы, определяющие выделение части объекта, в полях заголовка Range (раздел 13.36) и Content-Range (раздел 13.17). Объект может быть разбит на фрагменты с использованием различных структурных единиц.
| range-unit | = bytesunit | other-range-unit |
| bytes-unit | = "bytes" |
| other-range-unit | = token |
4.5.6.1.3. HTTP сообщение
3.1. Типы сообщений
Сообщения HTTP включают в себя запросы клиента к серверу и отклики сервера клиенту.
HTTP-message = Request | Response ; HTTP/1.1 messages
Сообщения запрос (раздел 5) и отклик ( раздел 6) используют общий формат сообщений RFC-822 [9] для передачи объектов (поле данных сообщения). Оба типа сообщений состоят из стартовой строки, одного или более полей заголовка (также известные как "заголовки"), пустой строки (то есть, строка, содержащая CRLF), отмечающей конец полей заголовка, а также опционного тела сообщения.
generic-message = start-line
*message-header
CRLF
[ message-body ]
start-line = Request-Line | Status-Line
В интересах надежности, рекомендуется серверам игнорировать любые пустые строки, полученные, когда ожидается Request-Line (строка запроса). Другими словами, если сервер читает протокольный поток в начале сообщения и получает сначала CRLF, он должен игнорировать CRLF.
Замечание: Определенные не корректные реализации HTTP/1.0 клиентов генерируют дополнительные CRLF после запроса POST. Клиент HTTP/1.1 не должен посылать CRLF до или после запроса.
3.2. Заголовки сообщений
Поля заголовка HTTP, которые включают в себя поля общего заголовка (раздел 3.5), заголовка запроса (раздел 4.3), заголовка отклика (раздел 6.2), и заголовка объекта (раздел 6.1), следуют тому же общему формату, что дан в разделе 3.1 RFC 822 [9]. Каждое поле заголовка состоит из имени, за которым следует двоеточие (":"), и поля значения. Поля имен безразличны в отношении использования строчных и прописных букв. Поле значения может начинаться с любого числа LWS, хотя один SP предпочтительнее. Поля заголовка могут занимать несколько строк, каждая новая строка должна открываться, по крайней мере, одним SP или HT. Рекомендуется, чтобы приложения следовали общему формату, если они создаются конструкциями HTTP, так как могут существовать некоторые реализации, которые не могут воспринимать ничего кроме общих форматов.
| Message-header | = field-name ":" [ field-value ] CRLF |
| field-name | = token |
| field-value | = *( field-content | LWS ) |
/p> field-content = < OCTET’ы образуют значения поля и состоят из * TEXT или комбинаций лексем, tspecials и закавыченных строк >
Порядок, в котором приходят поля заголовка с отличающимися именами, не играет значения. Однако, хорошей практикой считается посылка сначала поля общего заголовка, за которым следует заголовок запроса или отклика, а в заключение поля заголовка объекта.
Множественные поля заголовка сообщения с идентичными именами могут присутствовать тогда и только тогда, когда значение поля определяется как список из элементов, разделенных запятыми [то есть, #(значения)]. Должна быть предусмотрена возможность объединять множественные поля заголовка в одну пару "имя_поля: значение_поля", без изменения семантики сообщения, путем добавления каждой последующей пары поле-значение, отделенных друг от друга запятыми. Порядок, в котором следуют поля заголовка с идентичными именами, влияет на последующую интерпретацию значения комбинированного поля, по этой причине прокси-сервер не должен менять порядок значений этих полей при переадресации сообщения.
3.3. Тело сообщения
Тело сообщения HTTP (если имеется) используется для переноса тела объекта, сопряженного с запросом или откликом. Тело сообщения отличается от тела объекта, только когда используется транспортное кодирование, как это указано в поле заголовка Transfer-Encoding (раздел 13.40).
message-body = entity-body
|
Transfer-Encoding должно использоваться для указания любого транспортного кодирования, реализованного приложением с целью гарантированной неискаженной доставки сообщения. Транспортное кодирование лежит в зоне ответственности сообщения, а не объекта и по этой причине может быть реализовано любым приложением в цепочке запрос/отклик.
Присутствие тела сообщения в запросе отмечается с помощью включения полей заголовка Content-Length или Transfer-Encoding в заголовки сообщений-запросов. Тело сообщения может быть включено в запрос, только когда метод запроса допускает наличие тела объекта (раздел 4.1.1).
Для сообщений-откликов включение в них тела сообщения зависит от метода запроса и статусного кода отклика (раздел 5.1.1). Все отклики в случае метода запроса HEAD не должны включать тела сообщения, даже если присутствуют поля заголовка объекта, позволяющие предположить его присутствие. Все отклики 1xx (информационные), 204 (никакого содержимого) и 304 (не модифицировано) не должны включать тела сообщения. Все другие отклики включают в себя тело сообщения, хотя оно может иметь и нулевую длину.
3.4. Длина сообщения
Когда тело включено в сообщение, его длина определяется следующим образом (в порядке приоритета):
Любое сообщение-отклик, которое не должно включать в себя тело сообщения (такое как отклик 1xx, 204 и 304, а также любые отклики на запрос HEAD) всегда завершаются первой пустой строкой после полей заголовка, вне зависимости от присутствующих в сообщении полей заголовка объекта.
Если присутствует поле заголовка Transfer-Encoding (раздел 13.40) и указано, что использовано по фрагментное ("chunked") транспортное кодирование, тогда длина тела определяется выбранной схемой кодирования (раздел 2.6).
Если присутствует поле заголовка Content-Length (раздел 13.14), его значение в байтах и определяет длину тела сообщения.
Если сообщение использует тип cреды "multipart/byteranges", который является самоограничивающим, тогда он и определяет длину. Этот тип среды не должен использоваться, если отправитель не знает, может ли получатель разобрать его. Присутствие в запросе заголовка Range с множественными спецификаторами диапазона подразумевает, что клиент может разобрать отклики типа multipart/byteranges.
Определяется сервером при закрытии связи. (Закрытие соединения не может использоваться для обозначения конца тела запроса, так как это не оставит возможности для сервера послать отклик.)
Для совместимости с приложениями HTTP/1.0, запросы HTTP/1.1, содержащие тело запроса, должны включать корректное поле заголовка Content-Length. Если запрос содержит тело сообщения, а поле Content-Length отсутствует, рекомендуется, чтобы сервер реагировал откликом 400 (плохой запрос), если он не может определить длину сообщения, или 411 (необходима длина), если он настаивает на получении корректного поля Content-Length.
Все приложения HTTP/1.1, которые получают объект (entity) должны понимать блочное ("chunked") транспортное кодирование (раздел 2.6), таким образом, разрешая использование этого механизма для сообщений, когда длина сообщения не может быть определена заранее.
Сообщения не должны включать поле заголовка Content-Length и блочное транспортное кодирование одновременно. Если такое сообщение получено, поле Content-Length должно игнорироваться.
Когда в сообщении присутствует поле Content-Length и разрешено наличие тела сообщения, его значение поля должно строго соответствовать числу октетов в теле сообщения. Агенты пользователя HTTP/1.1 должны оповещать пользователя, если получено сообщение некорректной длины.
3.5. Общие поля заголовка
Существует несколько полей заголовка, которые имеют применимость, как для запросов, так и откликов, но которые не используются для передачи объектов. Эти поля заголовков служат только для пересылаемых сообщений.
| general-header | = Cache-Control | ; Раздел 13.9 |
| | Connection | ; Раздел 13.10 | |
| | Date | ; Раздел 13.19 | |
| | Pragma | ; Раздел 13.32 | |
| | Transfer-Encoding | ; Раздел 13.40 | |
| | Upgrade | ; Раздел 13.41 | |
| | Via | ; Раздел 13.44 |
4.5.6.1.4. Запрос
Сообщение-запрос от клиента к серверу включает в себя, в пределах первой строки сообщения, метод, который должен быть использован для ресурса, идентификатор ресурса и код версии используемого протокола.
| Request | = Request-Line | |
| *( generalheader | ||
| | requestheader | ||
| | entityheader ) | ||
| CRLF | ||
| [ messagebody ] |
Строка запроса начинается с лексемы метода, за которой следует Request-URI, версия протокола, завершается строка последовательностью CRLF. Элементы разделяются символами SP. Символы CR или LF запрещены кроме завершающей последовательности CRLF.
| Request | Line = Method SP Request-URI SP HTTP-Version CRLF |
/p> 4.1.1. Метод
Лексема Method указывает на метод, который должен быть применен к ресурсу, обозначенному Request-URI. При записи метода использование строчных или прописных букв не безразлично.
| Method | = "OPTIONS" | ; Раздел 9.2 |
| | "GET" | ; Раздел 9.3 | |
| | "HEAD" | ; Раздел 9.4 | |
| | "POST" | ; Раздел 9.5 | |
| | "PUT" | ; Раздел 9.6 | |
| | "DELETE" | ; Раздел 9.7 | |
| | "TRACE" | ; Раздел 9.8 | |
|
| extension-method extension-method = token |
Методы GET и HEAD должны поддерживаться всеми серверами общего назначения. Все другие методы являются опционными; однако, если применены вышеназванные методы, они должны быть применены с той же семантикой, что специфицирована в разделе 8.
5.1.2 URI запроса
URI запроса является универсальным идентификатором ресурса (раздел 2.2) и идентифицирует ресурс, который запрашивается.
Request-URI = "*" | absoluteURI | abs_path
Три опции для Request-URI зависят от природы запроса. Звездочка "*" означает, что запрос приложим не к заданному ресурсу, но к самому серверу, и допустим только, когда используемый метод не обязательно приложим к ресурсу. Примером может служить
OPTIONS * HTTP/1.1
Форма абсолютного URI необходима, когда запрос адресован к прокси-серверу. Прокси-серверу посылается запрос переадресации с целью получения отклика. Заметьте, что прокси может переадресовать запрос другому прокси или серверу, указанному абсолютным URI. Для того, чтобы избежать петель запросов прокси-сервер должен быть способен распознавать все имена серверов, включая любые псевдонимы, локальные вариации и численные IP-адреса. Пример строки запроса представлен ниже:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
Для того чтобы разрешить передачу абсолютных URI в запросах будущих версий HTTP, все серверы HTTP/1.1 должны уметь работать с запросами абсолютных форм URI.
Наиболее общей формой Request-URI является та, которая используется для идентификации ресурса на исходном сервере или внешнем порту сети. В этом случае абсолютный проход к URI должен быть занесен в abs_path (см. раздел 2.2.1) как Request-URI, а сетевой адрес URI (net_loc) должен быть занесен в поле заголовка Host. Например, клиент, желающий извлечь ресурс из выше приведенного примера непосредственно с базового сервера, установит TCP-соединение через порт 80 с ЭВМ "www.w3.org" и пошлет строки:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
за которыми следует остальная часть запроса. Заметьте, что абсолютный проход не может быть пустым; если его нет в исходном URI, он должен быть задан в виде "/" (корневой каталог сервера).
Если прокси получает запрос без какого-либо прохода в Request-URI, а метод, специфицирован так, чтобы быть способным поддерживать форму “*” запросов, тогда последний прокси в цепочке запроса должен переадресовать запрос с "*" в качестве финального Request-URI. Например, запрос
OPTIONS http://www.ics.uci.edu:8001 HTTP/1.1
будет переадресован прокси как
OPTIONS * HTTP/1.1
Host: www.ics.uci.edu:8001
после подключения к порту 8001 ЭВМ "www.ics.uci.edu".
Request-URI передается в формате, описанном в разделе 3.2.1. Исходный сервер должен декодировать Request-URI, для того чтобы правильно интерпретировать запрос. Серверам рекомендуется откликаться на некорректный запрос Request-URI соответствующим статусным кодом.
В запросах, которые они переадресуют, прокси-серверы не должны переписывать "abs_path" часть Request-URI каким-либо способом, за исключением случая, описанного выше, когда нулевой abs_path заменяется на "*".
Замечание: Правило "no rewrite" препятствует прокси изменить смысл запроса, когда исходный сервер некорректно использует незарезервированный URL символ для зарезервированных целей. Следует остерегаться того, что некоторые предшествующие варианты прокси-серверов HTTP/1.1 допускали перезапись Request-URI.
4.2. Ресурс, идентифицируемый запросом
Исходному серверу HTTP/1.1 рекомендуется заботиться о точном определении ресурса, идентифицированного Интернет-запросом путем анализа Request-URI и поля заголовка Host.
Исходный сервер, который не разделяет ресурсы по запрашиваемого ЭВМ, может игнорировать значение поля заголовка Host. (См. раздел 16.5.1 по поводу других требований по поддержке Host в HTTP/1.1.)
Исходный сервер, который различает ресурсы с использованием имени ЭВМ, должен использовать следующие правила для определения ресурса в запросе HTTP/1.1:
Если Request-URI является absoluteURI, ЭВМ определена частью Request-URI. Любое значение поля заголовка Host в запросе должно игнорироваться.
Если Request-URI не является absoluteURI, а запрос содержит поле заголовка Host, ЭВМ определяется значением поля заголовка Host.
Если ЭВМ, так как это определено правилами 1 или 2, не является ЭВМ сервера, откликом должно быть сообщение об ошибке с кодом 400 (Плохой запрос - Bad Request).
Получатели HTTP/1.0-запроса, где отсутствует поле заголовка Host, могут попытаться использовать эвристику (напр., рассмотрение прохода URI на предмет уникальной конкретной ЭВМ) для того, чтобы определить, какой конкретный ресурс запрошен.
4.3. Поля заголовка запроса
Поля заголовка запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте. Эти поля действуют как модификаторы запроса, с семантикой, эквивалентной параметрам, характеризующими метод языка программирования.
| Request-header | = Accept | ; Раздел 13.1 |
| | Accept-Charset | ; Раздел 13.2 | |
| | Accept-Encoding | ; Раздел 13.3 | |
| | Accept-Language | ; Раздел 13.4 | |
| | Authorization | ; Раздел 13.8 | |
| | From | ; Раздел 13.22 | |
| | Host | ; Раздел 13.23 | |
| | If-Modified-Since | ; Раздел 13.24 | |
| | If-Match | ; Раздел 13.25 | |
| | If-None-Match | ; Раздел 13.26 | |
| | If-Range | ; Раздел 13.27 | |
| | If-Unmodified-Since | ; Раздел 13.28 | |
| | Max-Forwards | ; Раздел 13.31 | |
| | Proxy-Authorization | ; Раздел 13.34 | |
| | Range | ; Раздел 13.36 | |
| | Referer | ; Раздел 13.37 | |
| | User-Agent | ; Раздел 13.42 |
/p> Поля имен заголовка запроса могут быть безопасно расширены в сочетании с изменением версии протокола. Однако новым или экспериментальным полям может быть придана семантика полей заголовка запроса, если все участники обмена способны их распознать. Не узнанные поля заголовка рассматриваются как поля заголовка объекта.
4.5.6.1.5. Отклик
После получения и интерпретации сообщения-запроса, сервер реагирует, посылая HTTP сообщение отклик.
| Response | = Status-Line | ; Раздел 5.1 |
| *( general-header | ; Раздел 3.5 | |
| | response-header | ; Раздел 5.2 | |
| | entity-header ) | ; Раздел 6.1 | |
| CRLF | ||
| [ message-body ] | ; Раздел 6.2 |
Первая строка сообщения-отклика является статусной строкой, состоящей из кода версии протокола, за которым следует числовой статусный код и его текстовое представление, все элементы разделяются символами SP (пробел). Никакие CR или LF не допустимы, за исключением завершающей последовательности CRLF.
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
5.1.1. Статусный код и словесный комментарий
Элемент Status-Code представляет собой 3-значный цифровой результирующий код попытки понять и исполнить запрос. Эти коды полностью определены в разделе 9. Словесный комментарий (Reason-Phrase) предназначен для того, чтобы дать краткое описание статусного кода. Статусный код служит для использования автоматами, а словесный комментарий для пользователей. Клиент не обязан рассматривать или отображать словесный комментарий.
Первая цифра статусного кода определяет класс отклика. Последние две цифры не имеют четко определенной функции. Существует 5 значений первой цифры:
1xx: Информационный – Запрос получен, процесс продолжается
2xx: Успех (Success) – Запрос успешно получен, понят и воспринят
3xx: Переадресация (Redirection) – Нужны дополнительные действия для завершения выполнения запроса
4xx: Ошибка клиента (Client Error) – Запрос содержит синтаксическую ошибку или не может быть выполнен
5xx: Ошибка сервера (Server Error) – Сервер не смог выполнить корректный запрос
Индивидуальные значения числовых статусных кодов определены в HTTP/1.1, а набор примеров, соответствующих причинам, представлен ниже. Комментарии причин, предлагаемые здесь, являются лишь рекомендательными – они могут быть заменены местными аналогами без последствий для протокола.
| Status-Code | = "100" | ; Continue |
| | "101" | ; Switching Protocols | |
| | "200" | ; OK | |
| | "201" | ; Created | |
| | "202" | ; Accepted | |
| | "203" | ; Non-Authoritative Information | |
| | "204" | ; No Content | |
| | "205" | ; Reset Content | |
| | "206" | ; Partial Content | |
| | "300" | ; Multiple Choices | |
| | "301" | ; Moved Permanently | |
| | "302" | ; Moved Temporarily | |
| | "303" | ; See Other | |
| | "304" | ; Not Modified | |
| | "305" | ; Use Proxy | |
| | "400" | ; Bad Request | |
| | "401" | ; Unauthorized | |
| | "402" | ; Payment Required | |
| | "403" | ; Forbidden | |
| | "404" | ; Not Found | |
| | "405" | ; Method Not Allowed | |
| | "406" | ; Not Acceptable | |
| | "407" | ; Proxy Authentication Required | |
| | "408" | ; Request Time-out | |
| | "409" | ; Conflict | |
| | "410" | ; Gone | |
| | "411" | ; Length Required | |
| | "412" | ; Precondition Failed | |
| | "413" | ; Request Entity Too Large | |
| | "414" | ; Request-URI Too Large | |
| | "415" | ; Unsupported Media Type | |
| | "500" | ; Internal Server Error | |
| | "501" | ; Not Implemented | |
| | "502" | ; Bad Gateway | |
| | "503" | ; Service Unavailable | |
| | "504" | ; Gateway Time-out | |
| | "505" | ; HTTP Version not supported | |
| | extension-code |
/p>
| Extension-code | = 3DIGIT |
| Reason-Phrase | = * |
5.2 Поля заголовка отклика
Поля заголовка отклика позволяют серверу передавать дополнительную информацию об отклике, который не может быть помещен в статусную строку. Эти поля заголовка дают информацию о сервере и доступе к ресурсу, идентифицированному Request-URI.
| Response-header | = Age | ; Раздел 13.6 |
| | Location | ; Раздел 13.30 | |
| | Proxy-Authenticate | ; Раздел 13.33 | |
| | Public | ; Раздел 13.35 | |
| | Retry-After | ; Раздел 13.38 | |
| | Server | ; Раздел 13.39 | |
| | Vary | ; Раздел 13.43 | |
| | Warning | ; Раздел 13.45 | |
| | WWW-Authenticate | ; Раздел 13.46 |
4.5.6.1.6. Объект (Entity)
Сообщения запрос и отклик могут нести в себе объект, если это не запрещено методом запроса или статусным кодом отклика. Объект состоит из полей заголовка объекта и тела объекта, хотя некоторые отклики включают в себя только заголовки объектов.
В данном разделе, как отправитель, так и получатель соотносятся к клиенту или серверу, в зависимости от того, кто отправляет и кто получает объект.
6.1. Поля заголовка объекта
Поля заголовка объекта определяют опционную метаинформацию о теле объекта или, если тело отсутствует, о ресурсе, идентифицированном в запросе.
| Entity-header | = Allow | ; Раздел 13.7 |
| | Content-Base | ; Раздел 13.11 | |
| Entity-header | | Content- | ; Раздел 13.12 |
| Entity-header | | Content-Language | ; Раздел 13.13 |
| Entity-header | | Content-Length | ; Раздел 13.14 |
| Entity-header | | Content-Location | ; Раздел 13.15 |
| Entity-header | | Content-MD5 | ; Раздел 13.16 |
| Entity-header | | Content-Range | ; Раздел 13.17 |
| Entity-header | | Content-Type | ; Раздел 13.18 |
| Entity-header | | Etag | ; Раздел 13.20 |
| Entity-header | | Expires | ; Раздел 13.21 |
| Entity-header | | Last-Modified | ; Раздел 13.29 |
| Entity-header | | extension-header |
Механизм расширения заголовка позволяет определить дополнительные полязаголовка объекта без изменения версии протокола, но эти поля не могут считаться заведомо распознаваемыми получателем. Неузнанные поля заголовка рекомендуется получателю игнорировать и переадресовывать прокси-серверам.
6.2. Тело объекта
Тела объекта (если они имеются), пересылаемые HTTP-запросом или откликом, имеют формат и кодировку, определенную полями заголовка объекта.
| entity-body | = *OCTET |
6.2.1. Тип
Когда тело объекта включено в сообщение, тип данных этого тела определяется полями заголовка Content-Type и Content-Encoding. Они определяют два слоя, заданных моделью кодирования:
entity-body := Content-Encoding( Content-Type( данные ) )
Content-Type специфицирует тип среды данных.
Content- Encoding может использоваться для индикации любого дополнительного кодирования содержимого поля данных, обычно для целей архивации, которая является особенностью запрашиваемого ресурса. По умолчанию никакого кодирования не используется.
Любое HTTP/1.1 сообщение, содержащее тело объекта, должно включать поле заголовка Content-Type, определяющее тип среды для данного тела. Только в случае, когда тип среды не задан полем Content-Type, получатель может попытаться предположить, каким является тип среды, просмотрев содержимое и/или расширения имен URL, использованного для идентификации ресурса. Если тип среды остается неизвестным, получателю следует рассматривать его как "application/octet-stream" (поток октетов).
6.2.2. Длина
Длина тела объекта равна длине тела сообщения, после того как произведено транспортное декодирование. Раздел 4.4 определяет то, как определяется длина тела сообщения.
4.5.6.1.7. Соединения
7.1. Постоянные соединения
7.1.1. Цель
Прежде чем установить постоянную связь должно быть реализовано отдельное TCP соединение с тем, чтобы получить URL. Это увеличивает нагрузку HTTP серверов и вызывает перегрузку каналов Интернет. Использование изображений и другой связанной с этим информации часто требует от клиента множественных запросов, направленных определенным серверам за достаточно короткое время. Анализ этих проблем содержится в [30][27], а результаты макетирования представлены в [26].
Постоянное HTTP соединение имеет много преимуществ:
При открытии и закрытии TCP соединений можно сэкономить время CPU и память, занимаемую управляющими блоками протокола TCP.
HTTP запросы и отклики могут при установлении связи буферизоваться (pipelining), образуя очередь. Буферизация позволяет клиенту выполнять множественные запросы, не ожидая каждый раз отклика на запрос, используя одно соединение TCP более эффективно и с меньшими потерями времени.
Перегрузка сети уменьшается за счет сокращения числа пакетов, сопряженных с открытием и закрытием TCP соединений, предоставляя достаточно времени для детектирования состояния перегрузки.
HTTP может функционировать более эффективно, так как сообщения об ошибках могут доставляться без потери TCP связи. Клиенты, использующие будущие версии HTTP, могут испытывать новые возможности, взаимодействуя со старым сервером, они могут после неудачи попробовать старую семантику. HTTP реализациям следует пользоваться постоянными соединениями.
7.1.2. Общие процедуры
Заметным различием между HTTP/1.1 и более ранними версиями HTTP является постоянное соединение, которое в HTTP/1.1 является вариантом, реализуемым по умолчанию. Поэтому, если не указано обратное, клиент может предполагать, что сервер будет поддерживать постоянное соединение.
Постоянное соединение обеспечивает механизм, с помощью которого клиент и сервер могут сигнализировать о закрытии TCP-соединения. Эта система сигнализации использует поле заголовка Connection. Как только поступил сигнал о закрытии канала, клиент не должен посылать какие-либо запросы по этому каналу.
7.1.2.1. Согласование
HTTP/1.1 сервер может предполагать, что HTTP/1.1 клиент намерен поддерживать постоянное соединение, если только в поле заголовка Connection не записана лексема "close". Если сервер принял решение закрыть связь немедленно после посылки отклика, ему рекомендуется послать заголовок Connection, включающий лексему связи close.
Клиент HTTP/1.1 может ожидать, что соединение останется открытым, но примет решение оставлять ли его открытым на основе того, содержит ли отклик сервера заголовок Connection с лексемой close.
Если клиент или сервер посылает лексему close в заголовке Connection, этот запрос становится последним для данного соединения.
Клиентам и серверам не следует предполагать, что соединение будет оставаться постоянным для версий HTTP, меньше 1.1, если только не получено соответствующее уведомление.
7.1.2.2. Буферизация
Клиенты, которые поддерживают постоянное соединение, могут буферизовать свои запросы (то есть, посылать несколько запросов не дожидаясь отклика для каждого из них). Серверы должны посылать свои отклики на эти запросы в том же порядке, в каком они их получили.
Клиенты, которые предполагают постоянство соединения и буферизацию немедленно после установления соединения должны быть готовы совершить повторную попытку установить связь, если первая буферизованная попытка не удалась. Если клиент совершает повторную попытку установления связи, он не должен выполнять буферизацию запросов, пока не получит подтверждения об установления постоянного соединения. Клиенты должны также быть готовы послать повторно свои запросы, если сервер закрывает соединение прежде, чем пришлет соответствующие отклики.
7.1.3. Прокси-серверы
Особенно важно то, чтобы прокси-серверы корректно использовали свойства поля заголовка Connection, как это специфицировано в 13.2.1.
Прокси-сервер должен сигнализировать о постоянном соединении отдельно своему клиенту и исходному серверу (origin server) или другому прокси, с которым связан. Каждое постоянное соединение устанавливается только для одной транспортной связи.
Прокси-сервер не должен устанавливать постоянное соединение с HTTP/1.0 клиентом.
7.1.4. Практические соображения
Серверы обычно имеют некоторое значение таймаута, за пределами которого они уже не поддерживают более неактивное соединение. Прокси-серверы могут сделать эту величины больше, так как весьма вероятно, что клиент создаст больше соединений через один и тот же сервер. Использование постоянных соединений не устанавливает никаких требований на величину этого таймаута для клиента или сервера.
Когда клиент или сервер хочет прервать связь по таймауту, ему следует послать корректное оповещение о закрытии соединения. Клиенты и серверы должны постоянно следить, не выдала ли противоположная сторона сигнал на закрытие канала и соответственно реагировать на него. Если клиент или сервер не зафиксирует сигнал противоположной стороны, то будут бессмысленно тратиться ресурсы сети.
Клиент, сервер или прокси могут закрыть транспортный канал в любое время. Например, клиент может послать новый запрос во время, когда сервер решит закрыть "пассивное" соединение. С точки зрения сервера, состояние которое предлагается закрыть, является пассивным, но с точки зрения клиента идет обработка запроса.
Это означает, что клиенты, серверы и прокси должны быть способны восстанавливаться после случаев асинхронного закрытия. Программа клиента должна заново открыть транспортное соединение и повторно передать неисполненный запрос без вмешательства пользователя (см. раздел 1.2), хотя агент пользователя может предложить оператору выбор, сопряженный с повторением запроса. Однако эта повторная попытка не должна повторяться при повторной неудаче.
Серверам следует всегда реагировать, по крайней мере, на один запрос при соединении, если это возможно. Серверам не следует закрывать соединение в процессе передачи отклика, если только не имеет место отказ в сети или выключение клиента.
Клиенты, которые используют постоянные соединения, должны ограничивать число одновременных связей, которые они поддерживают с конкретным сервером. Однопользовательскому клиенту рекомендуется поддерживать не более двух соединений с любым сервером или прокси. Прокси следует использовать до 2*N соединений с другим сервером или прокси, где N равно числу активных пользователей. Эти рекомендации призваны улучшить время отклика HTTP и исключить перегрузки Интернет и других сетей.
7.2. Требования к передаче сообщений
Общие требования:
HTTP/1.1 серверам следует поддерживать постоянные соединения и использовать TCP механизмы контроля информационного потока для преодоления временных перегрузок, а не разрывать соединение в расчете на то, что клиент совершит повторную попытку. Последнее может усугубить сетевую перегрузку.
Клиент HTTP/1.1 (или позднее), посылая тело сообщения, должен мониторировать сетевое соединение на наличие сигнала ошибки. Если клиент обнаружил состояние ошибки, он должен немедленно прервать передачу. Если тело передается с использованием блочной кодировки ("chunked" encoding, раздел 2.6), возможно применение фрагмента нулевой длины и пустой завершающей секции для обозначения преждевременного конца сообщения. Если телу предшествовал заголовок Content-Length, клиент должен разорвать соединение.
Клиент HTTP/1.1 (или позднее) должен быть готов принять код статуса 100 (Continue - продолжить), за которым следует обычный отклик.
Сервер HTTP/1.1 (или позднее), который получает запрос от клиента HTTP/1.0 (или ранее), не должен передавать отклик 100 (continue - продолжение), ему следует или ждать нормального завершения запроса (таким образом, избегая его прерывания) или преждевременно разрывать соединение.
Клиентам следует запомнить номер версии, по крайней мере, сервера, с которым проводилась работа последним, если клиент HTTP/1.1 получил отклик от сервера HTTP/1.1 (или позднее) и обнаружил разрыв соединения до получения какого-либо статусного кода, клиенту следует повторно попытаться направить запрос без участия пользователя (см. раздел 9.1.2). Если клиент действительно повторяет запрос, то клиент:
Должен сначала послать поля заголовка запроса, а затем
Должен ждать, того, что сервер пришлет отклик 100 (Continue), тогда клиент продолжит работу, или код статуса, сигнализирующего об ошибке.
Если клиент HTTP/1.1 не получил отклика от сервера HTTP/1.1 (или более поздней версии), ему следует считать, что сервер поддерживает версию HTTP/1.0 или более раннюю и не использует отклик 100 (Continue). Если в этом случае клиент обнаруживает закрытие соединения до получения какого-либо статусного кода от сервера, клиенту следует повторить запрос. Если клиент повторил запрос серверу HTTP/1.0, ему следует использовать следующий алгоритм получения надежного отклика:
Инициировать новое соединение с сервером
Передать заголовок запроса
Инициализировать переменную R для оценки задержки отклика сервера (round-trip time) (напр., на основе времени установления соединения), если RTT не доступно, ему присваивается значение 5 секунд.
Вычислить T = R * (2**N), где N равно числу предыдущих попыток запроса.
Ждать в течение Т секунд или до прихода статуса ошибки (что наступит раньше)
Если не получен сигнал ошибки, после T секунд передается тело запроса.
Если клиент обнаруживает преждевременное прерывание связи, повторяется шаг 1 до тех пор, пока запрос не будет принят или будет получен сигнал ошибки, или пока нетерпеливый пользователь не завершит процесс посылки повторных запросов.
Вне зависимости от версии сервера, если получен статус ошибки, то клиент
Не должен продолжать операции и
Должен прервать соединение, если процедура не завершена посылкой сообщения.
Клиент HTTP/1.1 (или позднее), который обнаруживает разрыв соединения после получения флага 100 (Continue), но до получения какого-либо статусного кода, должен повторить запрос и не должен ждать отклика 100 (Continue), но может и делать это, если это упрощает реализацию программы.
4.5.6.1.8. Метод определений
Набор общих методов для HTTP/1.1 определен ниже. Хотя этот набор может быть расширен, нельзя предполагать, что дополнительные методы следуют той же семантике для разных клиентов и серверов. Поле заголовка запроса Host (раздел 13.23) должно присутствовать во всех запросах HTTP/1.1.
8.1. Безопасные и Idempotent методы
8.1.1. Безопасные методы
Программисты должны заботиться о том, чтобы избегать операций, которые могут иметь неожиданное значение для них самих или их соседей по сети Интернет.
В частности, установлено соглашение, что методы GET и HEAD никогда не должны выполнять какие либо функции помимо доставки информации. Эти методы должны рассматриваться как вполне безопасные. Это позволяет агентам пользователя представлять другие методы, такие как POST, PUT и DELETE, особым способом, так что пользователь сам будет заботиться о возможности опасных операций, которые могут быть выполнены в результате реализации запроса.
Естественно, невозможно гарантировать, что сервер не будет вызывать побочные эффекты, как следствие выполнения запроса GET; в действительности, некоторые динамические ресурсы предусматривают такую возможность. Важным отличием здесь является то, что пользователь не запрашивал побочные эффекты и, следовательно, не может нести ответственность за них.
8.1.2. Подобные методы
Методы могут также иметь свойство "idempotence", при котором (помимо ошибок и таймаутов) побочный эффект от N > 0 идентичных запросов является таким же, как и от одного запроса. Методы GET, HEAD, PUT и DELETE имеют это свойство.
8.2. Опции
Метод OPTIONS представляет собой запрос информации о коммуникационных опциях, доступных в цепочке запрос/отклик, идентифицированной Request-URI. Этот метод позволяет клиенту определить опции и/или требования, связанные с ресурсами, или возможности сервера, не прибегая к операциям по извлечению и пересылке каких-либо файлов.
Если отклик сервера не сигнализирует об ошибке, отклик не должен включать никакой информации об объекте, отличной оттого, что считается коммуникационными опциями (напр., Allow подходит под эту категорию, а Content-Type нет). Отклики на этот метод не должны кэшироваться.
Если Request-URI тождественен символу звездочка ("*"), то запрос OPTIONS будет относиться ко всему серверу. Отклик 200 должен включать в себя любые поля заголовка, которые указывают на опционные характеристики используемого сервера (например, Public), включая любые расширения неопределенные в данной спецификации, в дополнение к любым общим используемым полям заголовка. Как описано в разделе 4.1.2, запрос "OPTIONS *" может быть реализован через прокси путем спецификации сервера места назначения в Request-URI без указания прохода. Если Request-URI не равен звездочке, запрос OPTIONS относится только к опциям, которые доступны при обмене с данным ресурсом. Отклик 200 должен включать любые поля заголовка, которые указывают опционные характеристики используемого сервера и применимы к данному ресурсу (напр., Allow), включая любые расширения, не описанные в данной спецификации. Если запрос OPTIONS проходит через прокси, то он должен редактировать отклик и удалять те опции, которые не доступны для реализации через данный прокси-сервер.
8.3 Метод GET
Метод GET предполагает извлечение любой информации (в форме объекта), заданной Request-URI. Если Request-URI относится к процессу, генерирующему данные, то в результате в виде объекта будут присланы эти данные, а не исходный текст самого процесса, если только этот текст не является результатом самого процесса.
Семантика метода меняется на "условный GET", если сообщение-запрос включает в себя поля заголовка If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match или If-Range. Метод условного GET запрашивает, пересылку объекта только при выполнении требований, описанных в соответствующих полях заголовка. Метод условного GET имеет целью уменьшить ненужное использование сети путем разрешения актуализации кэшированых объектов без посылки множественных запросов или пересылки данных, которые уже имеются у клиента. Семантика метода GET меняется на "частичный GET", если сообщение запроса включает в себя поле заголовка Range. Запросы частичного GET, которые предназначены для пересылки лишь части объекта, описаны в разделе 13.36. Метод частичного GET ориентирован на уменьшение ненужного сетевого обмена, допуская пересылку лишь части объекта, которая нужна клиенту, и не пересылая уже имеющихся частей.
Отклик на запрос GET буферизуется, тогда и только тогда, когда это согласуется с требованиями буферизации, рассмотренными в разделе 12.
8.4. Метод HEAD
Метод HEAD идентичен GET за исключением того, что сервер не должен присылать тело сообщения. Метаинформация, содержащаяся в заголовках отклика на запрос HEAD должна быть идентичной информации посланной в отклик на запрос GET. Этот метод может использоваться для получения метаинформации об объекте, указанном в запросе, без передачи тела самого объекта. Этот метод часто используется для тестирования гипертекстных связей на корректность, доступность и актуальность.
Отклик на запрос HEAD может кэшироваться в том смысле, что информация, содержащаяся в отклике, может использоваться для актуализации кэшированных ранее объектов данного ресурса. Если новые значения поля указывают на то, что кэшированный объект отличается от текущего объекта (как это индицируется изменением Content-Length, Content-MD5, ETag или Last-Modified), тогда запись в кэше должна рассматриваться как устаревшая.
8.5. Метод POST
Метод POST используется при заявке серверу принять вложенный в запрос объект в качестве нового вторичного ресурса, идентифицированного Request-URI в Request-Line. POST создан для обеспечения однородной схемы реализации следующих функций:
Аннотация существующего ресурса;
Помещение сообщения на электронную доску объявлений, в группу новостей, почтовый список или какую-то другую группу статей;
Выдача блока данных, такого как при передаче формы процессу ее обработки;
Расширение базы данных с помощью операции добавления (append).
Реальная операция, выполняемая методом POST, определяется сервером и обычно зависит от Request-URI. Присланный объект является вторичным по отношению к URI в том же смысле, в каком файл является вторичным по отношению к каталогу, в котором он находится, а статья новостей - вторичной по отношению к группе новостей, куда она помещена, или запись – по отношению к базе данных.
Операция, выполняемая методом POST, может не иметь последствий для ресурса, который может быть идентифицирован URI. В этом случае приемлемым откликом является 200 (OK) или 204 (No Content – никакого содержимого), в зависимости от того, включает ли в себя отклик объект, описывающий ресурс.
Если ресурс был создан на исходном сервере, отклик должен быть равен 201 (Created - создан) и содержать объект, который описывает статус запроса и относится к новому ресурсу и заголовку Location (см. раздел 13.30).
Отклики на этот метод не могут кэшироваться, если только не содержат поля заголовка Cache-Control или Expires. Однако отклик 303 (см. Other) может быть использован для того, чтобы направить агента пользователя для извлечения кэшируемого ресурса.
Запросы POST должны подчиняться требованиям, предъявляемым к передаче сообщений, рассмотренным в разделе 7.2.
8.6. Метод PUT
Метод PUT требует, чтобы вложенный объект был запомнен с использованием Request-URI. Если Request-URI относится к уже существующему ресурсу, то вложенный объект следует рассматривать как модифицированную версию объекта на исходном сервере. Если Request-URI не указывает на существующий ресурс и запрашивающий агент пользователя может определить этот URI как новый ресурс, исходный сервер может создать ресурс с этим URI. Если новый ресурс создан, исходный сервер должен информировать об этом агента пользователя, послав код отклик 200 (OK) или 204 (No Content – никакого содержимого) и тем самым, объявляя об успешно выполненном запросе. Если ресурс не может быть создан или модифицирован с помощью Request-URI, должен быть послан соответствующий код отклика, который отражает характер проблемы. Получатель объекта не должен игнорировать любой заголовок Content-* (например, Content-Range), который он не понял или не использовал, а должен в таком случае вернуть код отклика 501 (Not Implemented – не использовано).
Если запрос проходит через кэш и Request-URI идентифицирует один или более кэшированных объектов, эти объекты должны рассматриваться как устаревшие. Отклики этого метода не должны кэшироваться.
Фундаментальное отличие между запросами POST и PUT отражается в различных значениях Request-URI. URI в запросе POST идентифицирует ресурс, который будет работать со вложенным объектом. Этот ресурс может быть процессом приемки данных, шлюзом к другому протоколу или отдельным объектом, который воспринимает аннотации. Напротив, URI в запросах PUT идентифицируют объекты, заключенные в запросе, – агент пользователя знает, какой URI применить и сервер не должен пытаться посылать запрос другому ресурсу. Если сервер хочет, чтобы запрос был направлен другому URI, он должен послать отклик 301 (Moved Permanently). Агент пользователя может принять свое собственное решение относительно того, следует ли переадресовывать запрос.
Один и тот же ресурс может быть идентифицирован многими URI. Например, статья может иметь URI для идентификации "текущей версии", которая отличается от URI, идентифицирующей каждую конкретную версию. В этом случае запрос PUT на общий URI может дать в результате несколько других URI, определенных исходным сервером. HTTP/1.1 не определяет то, как метод PUT воздействует на состояние исходного сервера. Запросы PUT должны подчиняться требованиям передачи сообщения, заданным в разделе 7.2.
8.7. Метод DELETE
Метод DELETE требует, чтобы исходный сервер уничтожил ресурс, идентифицируемый Request-URI. Этот метод на исходном сервере может быть отвергнут вмешательством человека (или каким-то иным путем). Клиент не может гарантировать, что операция была выполнена, даже если возвращенный статусный код указывает, что операция завершилась успешно. Однако, сервер не должен сообщать об успехе, если за время отклика он не намерен стереть ресурс или переместить его в недоступное место.
Сообщение об успехе должно иметь код 200 (OK), если отклик включает объект, описывающий статус; 202 (Accepted - принято), если операция еще не произведена или 204 (No Content – Никакого содержимого), если отклик OK, но объекта в нем нет.
Если запрос проходит через кэш, а Request-URI идентифицирует один или более кэшированных объектов, эти объекты следует считать устаревшими (stale). Отклики на этот метод не кэшируемы.
8.8. Метод TRACE
Метод TRACE используется для того, чтобы запустить удаленный цикл сообщения-запроса на прикладном уровне. Конечный получатель запроса должен отослать полученное сообщение назад клиенту в виде тела объекта (код = 200 (OK)). Конечным получателем является либо исходный сервер, либо первый прокси или шлюз для получения значения Max-Forwards (0) в запросе (см. раздел 13.31). Запрос TRACE не должен включать в себя объект.
TRACE позволяет клиенту видеть, что получено на другом конце цепи запроса и использовать эти данные для тестирования или диагностики. Значение поля заголовка Via (раздел 13.44) представляет особый интерес, так как оно позволяет отследить всю цепочку запроса. Использование поля заголовка Max-Forwards позволяет клиенту ограничить длину цепи запроса, которая полезна для тестирования цепи прокси, переадресующих сообщения по замкнутому кругу.
В случае успеха отклик должен содержать все сообщение-запрос с Content-Type = "message/http". Отклики этого метода не должны кэшироваться.
4.5.6.1.9. Определения статусных кодов
Ниже описаны статусные коды, включая то, каким методам они соответствуют, и какая метаинформация должна присутствовать в откликах.
9.1. Информационный 1xx
Этот класс статусного кода индицирует информационный отклик, состоящий только из статусной строки и опционных заголовков с пустой строкой в конце. Так как HTTP/1.0 не определяет каких-либо статусных кодов 1xx, серверы не должны посылать отклики 1xx клиентам HTTP/1.0 за исключением случаев отладки экспериментальных протокольных версий.
9.1.1. 100 Continue (продолжение)
Клиент может продолжать работу, получив этот отклик. Этот промежуточный отклик используется для информирования клиента о том, что начальная часть запроса получена и пока не отклонена сервером. Клиенту следует продолжить отправлять оставшуюся часть запроса, если же запрос уже отправлен, то игнорировать этот отклик. Сервер должен послать окончательный отклик по завершении реализации запроса.
9.1.2. 101 Switching Protocols (Переключающие протоколы)
Сервер оповещает клиента о том, что он понял и принял к исполнению запрос. С помощью поля заголовка сообщения Upgrade (раздел 13.41) клиент уведомляется об изменении прикладного протокола для данного соединения. Сервер переходит на протокол, определенный в поле заголовка отклика Upgrade, немедленно после получения пустой строки, завершающей отклик 101.
Протокол следует изменять лишь в случае, если он предоставляет существенные преимущества. Например, переключение на новую версию HTTP предоставляет преимущества по отношению к старой версии, а переключение на синхронный протокол реального времени может иметь преимущество, когда ресурс использует это свойство.
9.2. Successful 2xx (Успешная доставка)
Этот класс статусного кода индицирует, что запрос клиента благополучно получен, понят и принят к исполнению.
9.2.1. 200 OK
Запрос успешно исполнен. Информация, возвращаемая вместе с откликом, зависит от метода, использованного запросом, например:
GET - в качестве отклика посылается объект, соответствующий запрошенному ресурсу;
HEAD – в качестве отклика посылаются поля заголовка объекта (без какого-либо тела), соответствующего запрошенному ресурсу;
POST - объект, описывающий или содержащий результат операции;
TRACE – объект, содержащий сообщение-запроса, в виде, полученном оконечным сервером.
9.2.2. 201 Created (Создано)
Запрос исполнен и в результате создан новый ресурс. Вновь созданный ресурс может быть доступен через URI, присланный в объекте отклика, со значащей частью URL ресурса в поле заголовка Location. Исходный сервер должен создать ресурс до отправки статусного кода 201. Если операция не может быть выполнена немедленно, сервер вместо этого должен откликнуться статусным кодом 202 (Accepted).
9.2.3. 202 Accepted (Принято)
Запрос был принят для исполнения, но обработка запроса не завершена. Запрос может обрабатываться или нет, так как он был блокирован в процессе исполнения. Не существует механизма повторной посылки статусного кода для асинхронных операций вроде этой.
Целью отклика 202 является разрешить серверу принять запрос для некоторого другого процесса (возможно процесса, запускаемого раз в день), не требуя того, чтобы соединение агента пользователя с сервером сохранялось до завершения процесса. Объект, возвращаемый этим откликом должен включать в себя текущий статус запроса и указатель на статус-монитор или некоторую оценку того, когда пользователь может ожидать завершения реализации запроса.
9.2.4. 203 Non-Authoritative Information (Не надежная информация)
Присылаемая в ответ метаинформация в заголовке объекта не идентифицируется, как полученная от исходного сервера, ее следует скорее считать косвенной, полученной опосредовано. Например, включение местной аннотационной информации о ресурсе может иметь последствия для мета информации, известной исходному серверу. Использование данного кода отклика не является обязательным и целесообразно лишь в случае, когда отклик мог бы быть равен 200 (OK).
9.2.5. 204 No Content (Никакого содержимого)
Сервер исполнил запрос, но нет никакой новой информации для отсылки. Этот отклик первоначально предназначался для разрешения ввода, не вызывая изменения активного документа агента пользователя. Отклик может включать новую метаинформацию в форме заголовков объектов, которая должна быть передана для документа, отображаемого агентом пользователя.
Отклик 204 не должен включать тела сообщения и всегда завершается пустой строкой после полей заголовка.
9.2.6. 205 Reset Content (Сброс содержимого)
Сервер исполнил запрос и агент пользователя должен вернуть документ к виду, который он имел в момент посылки запроса. Этот отклик первоначально предназначался для обеспечения ввода при выполнении пользователем операции, за которой следует очистка формы, в которую произведен ввод, так что пользователь может начать другую операцию ввода. Отклик не должен включать в себя объект.
9.2.7. 206 Partial Content (Частичное содержимое)
Сервер исполнил частично запрос GET для заданного ресурса. Запрос должен включать поле заголовка Range (раздел 13.36), указывающее на желательный интервал (range). Отклик должен включать поле заголовка Content-Range (раздел 13.17), указывающее диапазон данных, включенных в отклик, или множественные байтные интервалы (multipart/byteranges) Content-Type, включающие поля Content-Range для каждой из частей. Если множественные байтные интервалы не используются, поле заголовка Content-Length в отклике должно соответствовать действительному числу октетов в теле сообщения. Кэш, который не поддерживает заголовки Range и Content-Range, не должен кэшировать отклики 206 (Partial).
9.3. Redirection 3xx (Переадресация)
Этот класс статусных кодов указывает, что для выполнения запроса, нужны дальнейшие действия агента пользователя. Необходимые действия могут быть выполнены агентом пользователя без взаимодействия с пользователем, тогда и только тогда, когда используемый метод соответствует GET или HEAD. Агент пользователя не должен автоматически переадресовывать запрос более чем 5 раз, так как такая переадресация обычно свидетельствует о зацикливании запроса.
9.3.1. 300 Multiple Choices (Множественный выбор)
Запрошенный ресурс соответствует какому-то представлению из имеющегося набора представлений, каждое со своим адресом. Имеется информация (раздел 11), полученная в результате согласования под управлением агента пользователя, так что пользователь (или агент пользователя) может выбрать предпочтительное представление и переадресовать свой запрос по соответствующему адресу.
Если это только не был запрос HEAD, отклик должен включать объект, содержащий список характеристик ресурсов и их адресов, из которых пользователь или агент пользователя может выбрать наиболее подходящий. Формат объекта специфицируется типом среды, заданным полем заголовка Content-Type. В зависимости от формата и возможностей агента пользователя, выбор наиболее подходящего варианта может быть выполнен автоматически. Однако, эта спецификация не определяет какого-либо стандарта для такого автоматического выбора.
Если сервер имеет предпочтительный вариант представления, ему следует включить соответствующий URL этого представления в поле Location. Агент пользователя может использовать значение поля Location для реализации автоматического выбора. Этот отклик может кэшироваться, если не указано обратного.
9.3.2. 301 Moved Permanently (Постоянно перемещен)
Запрошенному ресурсу был приписан новый постоянный URI и любая будущая ссылка на этот ресурс должна делаться с использованием одного из присланных URI. Клиенты с возможностью редактирования связей должны, где возможно, автоматически менять связи для ссылок Request-URI на одну или более новых ссылок, присланных сервером. Этот отклик можно кэшировать, если не указано обратного.
Если новый URI является адресом (location), его URL должен быть задан в поле Location отклика. Если метод запроса не HEAD, объект отклика должен содержать короткое гипертекстное замечание с гиперсвязью, указывающей на новый URI.
Если получен статусный код 301 в ответ на запрос, отличный от GET или HEAD, агент пользователя не должен автоматически переадресовывать запрос, если только это не может быть подтверждено пользователем, так как такая переадресация может изменить условия, при которых направлен запрос.
Замечание: При автоматической переадресации запроса POST, получив статусный код 301, некоторые существующие агенты пользователя HTTP/1.0 ошибочно меняют его на запрос GET.
9.3.3. 302 Moved Temporarily (Временно перемещен)
Запрошенный ресурс размещается временно под различными URI. Так как переадресация может быть случайно изменена, клиент должен продолжать использовать Request-URI для будущих запросов. Этот отклик допускает кэширование, если имеются соответствующие указания в полях заголовка Cache-Control или Expires.
Если новый URI является адресом (location), его URL должен задаваться полем Location отклика. Если запрошенный метод не HEAD, объект отклика должен содержать короткое гипертекстное замечание с гиперсвязью, указывающей на новый URI.
Если в ответ на запрос, отличный от GET или HEAD, получен статусный код 302, агент пользователя не должен автоматически переадресовывать запрос, если это не может быть подтверждено пользователем, так как это может изменить условия, при которых был выдан запрос.
Замечание: Когда после получения статусного кода 302 автоматически переадресуется запрос POST, некоторые существующие агенты пользователя HTTP/1.0 ошибочно меняют его на запрос GET.
9.3.4. 303 See Other (смотри другие)
Отклик на запрос может быть найден под разными URI. Его следует извлекать с помощью метода GET. Этот метод первоначально создан для того, чтобы позволить переадресацию агента пользователя на выбранный ресурс при запуске скрипта с помощью POST. Новый URI не является заменой ссылки для первоначально запрошенного ресурса. Отклик 303 не кэшируется, но отклик на второй (переадресованный) запрос может кэшироваться.
Если новый URI является адресом (location), его URL должно быть задано в поле Location отклика. Если метод запроса не HEAD, объект отклика должен содержать гипертекстовую ссылку на новый URI.
9.3.5. 304 Not Modified (Не модифицировано)
Если клиент выполнил условный запрос GET и получил доступ, а документ не был модифицирован, сервер должен реагировать этим статусным кодом. Отклик не должен содержать тела сообщения.
Отклик должен включать поля заголовка:
Дата
ETag и/или Content-Location, если заголовок был послан в рамках отклика 200 на тот же самый запрос
Expires, Cache-Control и/или Vary, если значение поля может отличаться от посланного в каком-либо предыдущем отклике того же типа
Если условный GET использовал строгий валидатор кэша (см. раздел 12.8.3), отклик не должен содержать других заголовков объекта. В противном случае (напр., условный GET использовал слабый валидатор), отклик не должен включать в себя другие заголовки. Это предотвращает несогласованности между кэшированными телами объектов и актуализованными заголовками (updated headers).
Если отклик 304 указывает на то, что объект не кэширован, тогда кэш должен
игнорировать отклик и повторить запрос уже в безусловном режиме.
Если кэш использует полученный отклик 304 для актуализации записи в кэше, то кэш должен выполнить актуализацию с учетом новых значений полей, присланных в отклике.
Отклик 304 не должен включать в себя тело сообщения и, по этой причине всегда завершается пустой строкой после полей заголовка.
9.3.6. 305 Use Proxy (Используйте прокси)
Запрошенный ресурс должен иметь доступ через прокси-сервер, указанный в поле Location. Поле Location задает URL прокси-сервера. Предполагается, что получатель повторит запрос через прокси.
9.4. Client Error 4xx (Ошибка клиента)
Класс статус кодов 4xx предназначен для случаев, когда клиент допустил ошибку. За исключением случая отклика на запрос HEAD, серверу следует включить объект, содержащий объяснение ошибочной ситуации, а также указать, является ли ситуация временной или постоянной. Эти статусные коды применимы к любому методу запросов. Агенту пользователя следует отобразить все объекты.
Замечание. Если клиент посылает данные, реализация сервера, использующая протокол TCP, должна позаботиться о том, чтобы клиент получил пакет, содержащий отклик, до того как сервер закроет данное соединение. Если клиент продолжает посылку данных серверу после закрытия связи, TCP-уровень сервера должен послать клиенту пакет reset (сброс), который может стереть содержимое входного буфера клиента до того, как оно будет прочитано и интерпретировано приложением HTTP.
9.4.1. 400 Bad Request (Плохой запрос)
Запрос может быть не понят сервером из-за ошибочного синтаксиса. Клиенту не следует повторять запрос без модификации.
9.4.2. 401 Unauthorized (Не авторизован)
Запрос требует авторизации пользователя. Отклик должен включать в себя поле заголовка WWW-Authenticate (раздел 13.46), содержащее требование (challenge), применимое к запрошенному ресурсу. Клиент может повторить запрос с соответствующим содержимым поля заголовка Authorization (раздел 13.8). Если запрос уже включал допуск в поле Authorization, тогда отклик 401 указывает на то, что данный допуск не работает. Если отклик 401 содержит то же требование, что и предшествующий отклик, а агент пользователя уже пробовал пройти идентификацию по крайней мере хотя бы раз, тогда пользователю следует предоставить объект, содержащийся в отклике, так как он может содержать полезную диагностическую информацию. Идентификация доступа HTTP описана в разделе 10.
9.4.3. 402 Необходима оплата
Этот код зарезервирован для использования в будущем.
9.4.4. 403 Forbidden (Запрещено)
Сервер понял запрос, но отказался его исполнить. Авторизация не поможет и повторять запрос не следует. Если метод запроса не HEAD, а сервер желает открыто объявить причину неисполнения запроса, то ему следует описать соображения, по которым запрос отклонен Этот статусный код обычно используется, когда сервер не хочет показывать, почему запрос отклонен, или когда другой отклик не подходит.
9.4.5. 404 Not Found (Не найдено)
Сервер не нашел ничего, отвечающего Request-URI. Не приводится никаких данных о том, являются ли эта ситуация временной или постоянной.
Если сервер не хочет сделать эту информацию открытой для клиента, вместо этого может использоваться статусный код 403. Статусный код 410 (Gone - Утрачен) следует использовать, если сервер знает за счет некоторого внутреннего механизма конфигурации, что старый ресурс постоянно недоступен и не имеет нового адреса его размещения.
9.4.6. 405 Method Not Allowed (Метод не разрешен)
Метод, специфицированный в Request-Line, не разрешен для ресурса, указанного Request-URI. Отклик должен включать заголовок Allow, содержащий список разрешенных методов для запрошенного ресурса.
9.4.7. 406 Not Acceptable (Не приемлемо)
Ресурс, идентифицированный запросом, способен только генерировать объекты откликов, которые имеют характеристики, неприемлемые согласно заголовкам accept, присланным в запросе.
Если это не запрос HEAD, отклик должен включать объект, содержащий список доступных характеристик объекта и адреса, где пользователь или агент пользователя может выбрать нечто наиболее подходящее. Формат объекта специфицируется типом среды, приведенным в поле заголовка Content-Type. В зависимости от формата и возможностей агента пользователя, оптимальный выбор может быть сделан автоматически. Однако данная спецификация не определяет какого-либо стандарта для такого автоматического выбора.
Замечание. HTTP/1.1 серверам разрешено присылать отклики, которые неприемлемы согласно заголовкам accept, присланным в запросе. В некоторых случаях, может оказаться предпочтительнее послать отклик 406. Агенты пользователя могут просматривать заголовки приходящих откликов с тем, чтобы определить, являются ли они приемлемыми. Если отклик не может быть воспринят, агенту пользователя следует временно прервать прием данных и запросить пользователя принять решение о дальнейших действиях.
9.4.8. 407 Proxy Authentication Required (Необходима идентификация прокси)
Этот статусный код подобен 401 (Unauthorized), но указывает, что клиент должен сначала авторизоваться на прокси-сервере. Прокси должен прислать в ответ поле заголовка Proxy-Authenticate (раздел 13.33), содержащего требования, реализуемые на прокси для запрошенного ресурса. Клиент может повторить запрос с подходящим полем заголовка Proxy-Authorization (раздел 13.34). Авторизация доступа HTTP описана в разделе 10.
9.4.9. 408 Request Timeout (Таймаут запроса)
Клиент не выдал запрос в пределах временного интервала, в течение которого сервер его ожидал. Клиент может повторить запрос без модификаций в любое время.
9.4.10. 409 Conflict (Конфликт)
Выполнение запроса не может быть завершено из-за конфликта с текущим состоянием ресурса. Этот статусный код разрешен в ситуациях, где предполагается, что пользователь может разрешить конфликт и повторно послать запрос. Тело отклика должно включать достаточно информации, чтобы пользователь мог понять причину конфликта. В идеале, объект отклика должен был бы включать достаточно информации для пользователя или агента пользователя для того, чтобы уладить конфликт, однако это невозможно и необязательно.
Конфликты наиболее вероятно происходят в результате запроса PUT. Если задействована версия и объект операции PUT вызывает изменение ресурса, которые конфликтуют с изменениями внесенными запросом, выполненным ранее, сервер может использовать отклик 409 для того, чтобы указать на невозможность завершить выполнение запроса. В этом случае объект отклика должен содержать список отличий между двумя версиями формата, определенном откликом Content-Type.
9.4.11. 410 Gone (Исчез)
Запрошенный ресурс не является более доступным на сервере и не известен указатель переадресации. Это условие следует считать постоянным. Клиенты с возможностями редактирования связей должны ликвидировать ссылки на Request-URI после подтверждения пользователем. Если сервер не знает или не имеет возможности определить, является ли данное условие постоянным или временным, следует использовать отклик со статусным кодом 404 (Not Found). Этот отклик можно кэшировать, если не указано обратного.
Отклик 410 первоначально предназначался для того, чтобы помочь работе задач в WWW-среде путем сообщения получателю о том, что ресурс заведомо недостижим и владелец сервера хотел бы, чтобы связи с этим ресурсом были удалены. Такое событие является типичным для ограниченного периода времени и для ресурсов, принадлежащих частным лицам, которые не работают более с данным сервером. Не обязательно отмечать все постоянно недоступные ресурсы, как исчезнувшие (Gone) или сохранять такую пометку произвольное время – это оставлено на усмотрение собственника сервера.
9.4.12. 411 Length Required (Необходима длина)
Сервер отказывается принять запрос без определенного значения Content-Length. Клиент может повторить запрос, если он добавит корректное значение поля заголовка Content-Length, содержащего длину тела сообщения.
9.4.13. 412 Precondition Failed (Предварительные условия не выполнены)
Предварительные условия, заданные в одном или более полях заголовка запроса, воспринимаются как не выполненные, когда это проверено сервером. Этот код отклика позволяет клиенту установить предварительные условия для метаинформации (данные поля заголовка) текущего ресурса и, таким образом, предотвратить возможность использования запрошенного метода для ресурса, отличного от указанного.
9.4.14. 413 Request Entity Too Large (Объект запроса слишком велик)
Сервер отказывается обрабатывать запрос, потому что объект запроса больше, чем сервер способен обработать. Сервер может закрыть соединение, чтобы помешать клиенту продолжать посылать запросы.
Если условие является временным, серверу следует включить поле заголовка Retry-After, чтобы указать на временность этого условия, что означает возможность повторения запроса некоторое время спустя.
9.4.15. 414 Request-URI Too Long (URI запроса слишком велик)
Сервер отказывается обслужить запрос, потому что Request-URI длиннее, чем сервер способен интерпретировать. Это редкое обстоятельство может возникнуть только, когда клиент не корректно преобразует запрос POST в GET с длинной информацией запроса. При этом клиент ныряет в "черную дыру" переадресаций. Примером может служить преадресованный URL префикс, который указывает на свой суффикс, или случай атаки сервера клиентом, который пытается использовать дыры в системе безопасности, имеющиеся у клиентов с фиксированной емкостью буферов для работы с Request-URI.
9.4.16. 415 Unsupported Media Type (Неподдерживаемый тип среды)
Сервер отказывается обслужить запрос, потому что объект запроса имеет формат, неподдерживаемый запрашиваемым ресурсом для указанного метода.
9.5. Сервер ошибок 5xx
Статусный код отклика, начинающийся с цифры "5", указывает на случаи, когда сервер опасается, что он ошибся или не может реализовать запрос. За исключением случаев, когда обрабатывается запрос HEAD, серверу следует включить объект, содержащий объяснение создавшейся ошибочной ситуации и указывающей на то, является ли ситуация временной или постоянной. Агенту пользователя следует отобразить пользователю любой объект, включенный в отклик. Эти коды откликов применимы для любых методов запроса.
9.5.1. 500 Internal Server Error (Внутренняя ошибка сервера)
Сервер столкнулся с непредвиденными условиями, которые мешают ему исполнить запрос.
9.5.2. 501 Not Implemented (Не применимо)
Сервер не поддерживает функцию, которая должна быть реализована в ходе исполнения запроса. Это адекватный отклик, когда сервер не распознает метод запроса и не способен поддерживать его для данного ресурса.
9.5.3. 502 Bad Gateway (Плохой шлюз)
Сервер при работе в качестве шлюза или прокси получил неверный отклик от вышестоящего сервера, к которому он обратился, выполняя запрос.
9.5.4. 503 Service Unavailable (Услуга не доступна)
Сервер в данный момент не может обработать запрос в связи с временной перегрузкой или другими сложившимися обстоятельствами.
Замечание. Существование статусного кода 503 не предполагает, что сервер должен использовать его, когда оказывается перегруженным. Некоторые серверы могут захотеть просто отказаться устанавливать соединение.
9.5.5. 504 Gateway Timeout (Таймаут шлюза)
Сервер при работе в качестве внешнего шлюза или прокси-сервера не получил своевременно отклик от вышестоящего сервера, к которому он обратился, пытаясь исполнить запрос.
9.5.6. 505 HTTP Version Not Supported (Версия не поддерживается)
Сервер не поддерживает или отказывается поддерживать версию протокола HTTP, которая была использована в сообщении-запросе. Сервер индицирует, что он не способен или не хочет завершать обработку запроса в рамках главной версии клиента, как это описано в разделе 2.1, в отличие от сообщения об ошибке. Отклику следует содержать объект, описывающий, почему эта версия не поддерживается и какие другие протоколы поддерживаются сервером.
4.5.6.1.10. Идентификация доступа
HTTP предлагает простой механизм аутентификации с помощью отклика, который может использоваться сервером, чтобы потребовать от клиента прислать запрос, содержащий аутентификационную информацию. Для определения схемы идентификации он использует лексему произвольной длины, не зависящую от применения строчных или прописных символов, за ней следует список пар атрибут-значение. Элементы списка отделяются друг от друга запятыми. Атрибуты представляют собой параметры, которые определяют аутентификацию в рамках выбранной схемы.
| Auth-scheme | = token |
| auth-param | = token "=" quoted-string |
| Challenge | = auth-scheme 1*SP realm *( "," auth-param ) |
| Realm | = "realm" "=" realm-value |
| realm-value | = quoted-string |
Агент пользователя, который хочет идентифицировать себя на сервере, после получения отклика 401 или 411 может сделать это, включив в запрос поле заголовка Authorization. Значение поля Authorization состоит из записей, содержащих идентификационную информацию агента пользователя для области (realm) запрошенного ресурса.
credentials = basic-credentials
| auth-scheme #auth-param
Домен, в пределах которого может автоматически использоваться идентификационная информация, определяется зоной защиты. Если предыдущий запрос был авторизован, та же идентификационная информация может быть использована для всех других запросов в пределах зоны защиты и во временных рамках, заданных схемой идентификации, параметрами и/или предпочтениями пользователя. Если не определено обратного схемой авторизации, одна зона защиты не может быть распространена за пределы ее сервера.
Если сервер не хочет принимать идентификационную информацию, присланную в запросе, он должен прислать отклик 401 (Unauthorized). Отклик должен включать поле заголовка WWW-Authenticate, содержащее требование (возможно новое), применимое для запрошенного ресурса, и объект, объясняющий причину отказа.
Протокол HTTP не ограничивает приложения только этим простым механизмом авторизации (требование-отклик). Может быть применен дополнительный механизм, такой как шифрование на транспортном уровне или использование инкапсуляции сообщений. Однако в данной спецификации эти дополнительные механизмы не определены.
Прокси-серверы должны быть полностью прозрачны по отношению авторизации агентов пользователя. То есть, они должны переадресовывать в неприкосновенном виде заголовки WWW-Authenticate и Authorization, согласно правилам описанным в разделе 13.8.
HTTP/1.1 позволяет клиенту передать идентификационную информацию в прокси и обратно с использованием заголовков Proxy-Authenticate и Proxy-Authorization.
10.1 Базовая схема идентификации (Authentication)
Базовая схема авторизации базируется на модели, в которой агент пользователя должен идентифицировать себя с помощью имени пользователя и пароля, необходимого для каждой области (realm). Значение атрибута realm должно рассматриваться в виде неотображаемой строки символов, которая может сравниваться с другим значение realm на этом сервере.
Сервер обслужит запрос только в случае, если убедится в корректности имени и пароля пользователя для данной зоны защиты Request-URI. Не существует каких-либо опционных параметров авторизации.
При получении неавторизованного запроса для URI в пределах зоны защиты (protection space), сервер может реагировать посылкой требования в виде:
WWW-Authenticate: Basic realm="WallyWorld"
где "WallyWorld" – строка присвоенная сервером для идентификации зоны защиты Request-URI.
Чтобы получить авторизацию клиент посылает свое имя и пароль, разделенные символом двоеточие (":"), и закодированные согласно base64.
basic-credentials = "Basic" SP basic-cookie
basic-cookie =
user-pass = userid ":" password
userid = *
password = *TEXT
Идентификационная информация может быть чувствительной к применению строчных или прописных букв.
Если агент пользователя хочет послать имя пользователя "Aladdin" и пароль "Сезам открой", он использует следующее поле заголовка:
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Смотри раздел 14 по поводу соображений безопасности, связанных с базовой авторизацией.
10.2 Краткое изложение схемы авторизации
Краткое изложение идей авторизации для HTTP представлено в документе RFC-2069 [32].
4.5.6.1.11. Согласование содержимого
Большинство HTTP откликов включают в себя объекты, которые содержат информацию для интерпретации человеком-пользователем. Естественно, желательно обеспечить пользователя наилучшим объектом, соответствующим запросу. К сожалению для серверов и кэшей не все пользователи имеют одни и те же предпочтения и не все агенты пользователя в равной степени способны обрабатывать все типы объектов. По этой причине, HTTP имеет несколько механизмов обеспечения согласования содержимого – процесс выбора наилучшего представления для данного отклика, когда доступны несколько возможностей.
Замечание. Это не называется "согласование формата " потому, что альтернативные представления могут принадлежать к одному и тому же типу среды, но использовать различные возможности этого типа, например, различные иностранные языки.
Любой отклик, содержащий тело объекта может быть предметом согласования, включая отклики об ошибках. Существует два вида согласования содержимого, которые возможны в HTTP: согласование под управлением сервера и под управлением агента пользователя. Эти два сорта согласования могут использоваться по отдельности или в сочетании. Один из методов, называемый прозрачным согласованием, реализуется, когда кэш использует информацию, полученную от исходного сервера в результате согласования под управлением агента пользователя. Эта информация используется для последующих запросов, где осуществляется согласование под управлением сервера.
11.1 Согласование, управляемое сервером
Если выбор наилучшего представления для отклика выполнен с использованием некоторого алгоритма на сервере, такая процедура называется согласованием под управлением сервера. Выбор базируется на доступных представлениях отклика (размеры, в пределах которых он может варьироваться, язык, кодировка и т.д.) и на содержимом конкретных полей заголовка в сообщении-запросе или другой информации, имеющей отношение к запросу (например, сетевой адрес клиента).
Согласование, управляемое сервером предпочтительнее, когда алгоритм выбора из числа доступных представлений трудно описать агенту пользователя. Согласование под управлением сервера привлекательно тогда, когда сервер хочет послать свои “наилучшие предложения” клиенту вместе с первым откликом (надеясь избежать задержек RTT последующих запросов, если предложение удовлетворит пользователя). Для того чтобы улучшить предложения сервера, агент пользователя может включить в запрос поля заголовка (Accept, Accept-Language, Accept-Encoding, и т.д.), которые описывают его предпочтения для данного запроса. Согласование под управлением сервера имеет следующие недостатки:
Для сервера трудно определить, что является ”лучшим” для любого заданного пользователя, так как это потребовало бы полного знания как возможностей агента пользователя, так конкретного назначения отклика (напр., хочет ли пользователь видеть отклик на экране или отпечатать на принтере?).
Заставлять агента пользователя описывать свои возможности при каждом запросе крайне неэффективно (ведь лишь небольшой процент запросов имеют несколько вариантов представления) и потенциально нарушает конфиденциальность пользователя.
Это усложняет реализацию исходного сервера и алгоритм генерации откликов на запросы.
Это может ограничить возможность общедоступного кэша использовать один и тот же отклик для запросов многих пользователей.
HTTP/1.1 включает в себя следующие поля заголовка запроса для активации согласования, управляемого сервером, через описание возможностей агента пользователя и предпочтений самого пользователя: Accept (раздел 13.1), Accept- Charset (раздел 13.2), Accept-Encoding (раздел 13.3), Accept-Language (раздел 13.4) и User-Agent (раздел 13.42). Однако, исходный сервер не ограничен этими рамками и может варьировать отклик, основываясь на свойствах запроса, включая информацию помимо полей заголовка запроса или используя расширения полей заголовка нерассмотренные в данной спецификации.
Исходные серверы HTTP/1.1 должны включать соответствующие, управляемом сервером. Поле Vary описывает пределы, в которых может варьироваться отклик (то есть, пределы, в которых исходный сервер выбирает свои “наилучшие предложения” отклика из многообразия редставлений).
HTTP/1.1 общедоступный кэш должен распознавать поле заголовка Vary, когда оно включено в отклик и подчиняется требованиям, описанным в разделе 12.6, где рассматриваются взаимодействия между кэшированием и согласованием содержимого.
11.2. Согласование, управляемое агентом (Agent-driven Negotiation)
При согласовании, управляемом агентом, выбор наилучшего представления для отклика выполняется агентом пользователя после получения стартового отклика от исходного сервера. Выбор базируется на списке имеющихся представлений отклика, включенном в поля заголовка (эта спецификация резервирует имя поля Alternates, как это описано в приложении 16.6.2.1,) или в тело объекта исходного отклика, при этом каждое представление идентифицируется своим собственным URI. Выбор из числа представлений может быть выполнен автоматически (если агент пользователя способен на это) или вручную пользователем, выбирая вариант из гипертекстного меню.
Согласование, управляемое агентом, имеет преимущество тогда, когда отклик варьируется в определенных пределах (таких как тип, язык или кодирование), когда исходный сервер не способен определить возможности агента пользователя, проанализировав запрос, и вообще, когда общедоступные кэши используются для распределения нагрузки серверов и для снижения сетевого трафика.
Согласование под управлением агента имеет тот недостаток, что требуется второй запрос для получения наилучшего альтернативного представления. Этот второй запрос эффективен только тогда, когда используется кэширование. Кроме того, эта спецификация не определяет какого-либо механизма поддержки автоматического выбора, хотя она и не препятствует применению любого такого механизма в рамках расширения HTTP/1.1.
HTTP/1.1 определяет статусные коды 300 (Multiple Choices – множественный выбор) и 406 (Not Acceptable – Не приемлем) для активации согласования под управлением агента, когда сервер не хочет или не может обеспечить свой механизм согласования.
11.3 Прозрачное согласование (Transparent Negotiation)
Прозрачное согласование представляет собой комбинацию управления сервера и агента. Когда кэш получает форму списка возможных представлений откликов (как в согласовании под управлением агента) и кэшу полностью поняты пределы вариации, тогда кэш становится способным выполнить согласование под управлением сервера для исходного сервера при последующих запросах этого ресурса.
Прозрачное согласование имеет преимущество распределения работы согласования, которое в противном случае было бы выполнено исходным сервером. При этом удаляется также задержка, сопряженная со вторым запросом при схеме согласования под управлением агента, когда кэш способен правильно прогнозировать отклик.
Эта спецификация не определяет какого-либо механизма для прозрачного согласования, хотя она и не препятствует использованию таких механизмов в будущих версиях HTTP/1.1. Выполнение прозрачного согласования кэшем HTTP/1.1 должно включать в отклик поле заголовка Vary (определяя пределы его вариаций), обеспечивая корректную работу со всеми клиентами HTTP/1.1.
4.5.6.1.12 Кэширование в HTTP
HTTP обычно используется для распределенных информационных систем, где эксплуатационные характеристики могут быть улучшены за счет применения кэширования откликов. Протокол HTTP/1.1 включает в себя много элементов, предназначенных для оптимизации такого кэширования. Благодаря тому, что эти элементы завязаны с другими аспектами протокола и из-за их взаимодействия друг с другом, полезно описать базовую схему кэширования в HTTP отдельно от детального рассмотрения методов, заголовков, кодов откликов и т.д.
Кэширование представляется бесполезным, если оно значительно не улучшит работу. Целью кэширования в HTTP/1.1 является исключение во многих случаях необходимости посылать запросы, а в некоторых других случаях - полные отклики. При этом уменьшается число необходимых RTT для многих операций. Для этих целей используется механизм “истечения срока” (expiration) (см. раздел 12.2). Одновременно снижаются требования к полосе пропускания сети, для чего применяется механизм проверки пригодности (см. раздел 12.3).
Требования к рабочим характеристикам, доступности и работе без соединения заставляют нас несколько снизить семантическую прозрачность. Протокол HTTP/1.1 позволяет исходным серверам, кэшам и клиентам снизить прозрачность, когда необходимо. Так как непрозрачность операций может поставить в тупик недостаточно опытных пользователей, а также привести к определенной несовместимости для некоторых серверных приложений (таких как торговля по заказу), протокол рекомендует не убирать прозрачность полностью, а лишь несколько ослабить.
Следовательно, протокол HTTP/1.1 обеспечивает следующие важные моменты:
Протокольные особенности, которые гарантируют полную семантическую прозрачность, когда это требуется всеми участниками процесса. Протокольные особенности, которые позволяют исходному серверу или агенту пользователя запросить и управлять непрозрачными операциями. Протокольные особенности, которые позволяют кэшу присоединить предупреждения к откликам, которые не сохраняют запрошенный уровень семантической прозрачности.
Базовым принципом является возможность для клиентов детектировать любое ослабление семантической прозрачности.
Замечание. Разработчики серверов, кэшей или клиентов могут столкнуться с решениями, которые не обсуждались в данной спецификации. Если решение может повлиять на семантическую прозрачность, разработчик может ошибаться относительно прозрачной работы, не проведя детального анализа и не убедившись, что нарушение такой прозрачности дает существенные преимущества.
12.1 Корректность кэша
Корректный кэш должен реагировать на запрос откликом новейшей версии, которой он владеет. Разумеется, отклик должен соответствовать запросу (см. разделы 12.5, 12.6, и 12.12) и отвечать одному из следующих условий:
Он был проверен на эквивалентность с тем, который бы прислал исходный сервер при соответствующем запросе (раздел 12.3); Он достаточно нов (см. раздел 12.2). В варианте по умолчанию это означает, что он отвечает минимальным требованиям клиента, сервера и кэша по новизне (см. раздел 13.9). Если исходный сервер задает такие требования, то это только его требования на новизну.
Он включает в себя предупреждение, о нарушении требований новизны клиента или исходного сервера (см. разделы 12.5 и 13.45).
Это сообщение-отклик 304 (Not Modified), 305 (Proxy Redirect), или ошибка (4xx или 5xx).
Если кэш не может осуществлять обмен с исходным сервером, он должен реагировать в соответствии с вышеприведенными правилами, если отклик может быть корректно обслужен, в противном случае он должен отослать сигнал ошибки или предупреждения, указывающий, что имел место отказ в системе коммуникаций.
Если кэш получает отклик (полный отклик или код 304 (Not Modified)), который уже не является свежим, кэш должен переадресовать его запросившему клиенту без добавления нового предупреждения, и не удаляя существующего заголовка Warning. Кэшу не следует пытаться перепроверить отклик, так как это может привести к бесконечному зацикливанию. Агент пользователя, который получает устаревший отклик без Warning, может отобразить предупреждение для пользователя.
12.2 Предупреждения
Когда кэш присылает опосредованный отклик, который “недостаточно свеж” (с точки зрения условия 2 раздела 12.1), к нему должно быть присоединено предупреждение об этом с использованием заголовка Warning. Это предупреждение позволяет клиентам предпринять соответствующие действия.
Предупреждения могут использоваться для других целей, как кэшами так и другими системами. Использование предупреждения, а не статусного кода ошибки, отличает эти отклики от действительных отказов в системе.
Предупреждения всегда допускают кэширование, так как они никогда не ослабляют прозрачности отклика. Это означает, что предупреждения могут передаваться HTTP/1.0 кэшам без опасения, что такие кэши просто передадут их как заголовки объектов отклика.
Предупреждениям приписаны номера в интервале от 0 до 99. Данная спецификация определяет номера кодов и их значения для каждого из предупреждений, позволяя клиенту или кэшу обеспечить во многих случаях (но не во всех) автоматическую обработку ситуаций.
Предупреждения несут в себе помимо кода и текст. Текст может быть написан на любом из естественных языков (предположительно базирующемся на заголовках Accept клиента) и включать в себя опционное указание того, какой набор символов используется.
К отклику может быть присоединено несколько предупреждений (исходным сервером или кэшем), включая несколько предупреждений с идентичным кодом. Например, сервер может выдать одно и то же предупреждение на английском и мордовском.
Когда к отклику присоединено несколько предупреждений, не будет практичным и разумным отображать их все на экране для пользователя. Эта версия HTTP не специфицирует строгих правил приоритета для принятия решения, какие предупреждения отображать и в каком порядке, но предлагает некоторые эвристические соображения.
Заголовок Warning и определенные в настоящий момент предупреждения описаны в разделе 13.45.
12.3 Механизмы управления кэшем
Базовым механизмом кэша в HTTP/1.1 (времена таймаутов и валидаторы) являются неявные директивы кэша. В некоторых случаях серверу или клиенту может потребоваться выдать прямую директиву кэшу. Для этих целей используется заголовок Cache-Control.
Заголовок Cache-Control позволяет клиенту или серверу передать большое число директив через запросы или отклики. Эти директивы переписывают указания, которые действуют по умолчанию при реализации алгоритма работы кэша. Если возникает явный конфликт между значениями заголовков, то используется наиболее регламентирующее требование (то есть, то, которое наиболее вероятно сохраняет прозрачность семантики).
Однако в некоторых случаях директивы Cache-Control сформулированы так, что явно ослабляют семантическую прозрачность (например, "max-stale" или "public"). Директивы Cache-Control подробно описаны в разделе 13.9.
12.4 Прямые предупреждения агента пользователя
Многие агенты пользователя позволяют переписывать базовый механизм кэширования. Например, агент пользователя может специфицировать то, какие кэшированные объекты (даже явно старые) не проверять на новизну. Или агент пользователя может всегда добавлять "Cache-Control: max-stale=3600" к каждому запросу.
Если пользователь переписал базовый механизм кэширования, агент пользователя должен явно указать всякий раз, когда это важно, что отображаемая информация не отвечает требованиям прозрачности (в частности, если отображаемый объект известен как устаревший). Так как протокол обычно разрешает агенту пользователя определять, является ли отклик устаревшим, такая индикация нужна только тогда, когда это действительно случится. Для такой индикации не нужно диалоговое окно; это может быть иконка (например, изображение гнилой рыбы) или какой-то иной визуальный индикатор.
Если пользователь переписал механизм кэширования таким образом, что он непомерно понизил эффективность кэша, агент пользователя должен непрерывно отображать индикацию (например, изображение горящих денег), так чтобы пользователь, беспечно расходующий ресурсы, страдал от заметной задержки откликов на его действия.
12.5 Исключения для правил и предупреждений
В некоторых случаях оператор кэша может выбрать такую конфигурацию, которая возвращает устаревшие отклики, даже если клиенты этого не запрашивали. Это решение не должно приниматься легко, но может быть необходимо по причинам доступности или эффективности, особенно когда кэш имеет плохую связь с исходным сервером. Всякий раз, когда кэш возвращает устаревший отклик, он должен пометить его соответствующим образом (используя заголовок Warning). Это позволяет клиентскому программному обеспечению предупредить пользователя о возможных проблемах.
Такой подход позволяет также агенту пользователя предпринять шаги для получения “свежего” отклика или информации из первых рук. По этой причине кэшу не следует присылать устаревшие отклики, если клиент запрашивает информацию из первых рук, если только невозможно это сделать по техническим или политическим причинам.
12.6 Работа под управлением клиента
Когда основным источником устаревшей информации является исходный сервер (и в меньшей мере промежуточные кэши), клиенту может быть нужно контролировать решение кэша о том, следует ли присылать кэшированный отклик без его проверки. Клиенты выполняют это, используя несколько директив заголовка Cache-Control.
Запрос клиента может специфицировать максимальный возраст, который он считает приемлемым для не верифицированного отклика. Клиент может также специфицировать минимальное время, в течение которого отклик еще считается пригодным для использования. Обе эти опции увеличивают ограничения, накладываемые на работу кэша.
Клиент может также специфицировать то, что он будет воспринимать устаревшие отклики с возрастом не более заданного. Это ослабляет ограничения, налагаемые на работу кэшей и, таким образом, может привести к нарушению семантической прозрачности, заданной исходным сервером, хотя это может быть необходимо для поддержания автономной работы кэша в условиях плохой коннективности.
12.7. Модель истечения срока годности
12.7. 1 Определение срока годности под управлением сервера
Кэширование в HTTP работает наилучшим образом, когда кэши могут полностью исключить запросы к исходному серверу. Другими словами, кэш должен возвращать “свежий” отклик без обращения к серверу.
Предполагается, что серверы припишут в явном виде значения времени пригодности (expiration time) откликам в предположении, что объекты вряд ли изменятся семантически значимым образом до истечения этого времени. Это сохраняет семантическую прозрачность при условии, что время жизни выбрано корректно.
Механизм времени пригодности (expiration) применим только к откликам, взятым из кэша, а не к откликам, полученным из первых рук и переадресованных запрашивающему клиенту.
Если исходный сервер хочет усилить семантическую прозрачность кэша, тогда он может установить время истечения действия в прошлое, чтобы проверялся каждый запрос. Это означает, что всякий запрос изначально будет считаться устаревшим, и кэш будет вынужден проверить его прежде чем использовать для последующих запросов. О более жестких методах вынуждения проверки действенности отклика смотри раздел 13.9.4.
Если исходный сервер хочет заставить любой HTTP/1.1 кэш, вне зависимости от его конфигурации проверять каждый запрос, он может использовать директиву Cache-Control "must-revalidate” (см. раздел 13.9).
Серверы определяют реальные времена сроков пригодности, используя заголовок Expires, или директиву максимального возраста заголовка Cache-Control.
Время пригодности (expiration time) не может использоваться для того, чтобы заставить агента пользователя обновить картинку на дисплее или перезагрузить ресурс; его семантика применима только для механизма кэширования, а такой механизм нуждается только в контроле истечения времени жизни ресурса, когда инициируется новый запрос доступа к этому ресурсу.
12.7.2 Эвристический контроль пригодности
Так как исходные сервера не всегда предоставляют значение времени пригодности в явном виде, HTTP кэши присваивают им значения эвристически, используя алгоритмы, которые привлекают для оценки вероятного значения времени пригодности другие заголовки (такие как Last-Modified time). Спецификация HTTP/1.1 не предлагает каких-либо специальных алгоритмов, но налагает предельные ограничения на полученный результат. Так как эвристические значения времени жизни могут подвергнуть риску семантическую прозрачность, они должны использоваться с осторожностью. Предпочтительнее, чтобы исходные серверы задавали время пригодности явно.
12.7.3. Вычисление возраста
Для того чтобы узнать является ли запись в кэш свежей, кэшу нужно знать превышает ли его возраст предельное время жизни. То, как вычислить время пригодности, обсуждается в разделе 12.7.4. Этот раздел описывает метод вычисления возраста отклика или записи в кэше.
В этом обсуждении используется термин “сейчас” для обозначения “текущего показания часов на ЭВМ, выполняющей вычисление". ЭВМ, которая использует HTTP, и в особенности ЭВМ, работающие в качестве исходных серверов и кэшей, должны использовать NTP [28] или некоторый схожий протокол для синхронизации их часов с использованием общего точного временного стандарта.
Следует обратить внимание на то, что HTTP/1.1 требует от исходного сервера посылки в каждом отклике заголовка Date, сообщая время, когда был сгенерирован отклик. Мы используем термин "date_value" для обозначения значения заголовка Date, в форме, приемлемой для арифметических операций.
HTTP/1.1 использует заголовок отклика Age для того, чтобы облегчить передачу информации о возрасте объектов между кэшами. Значение заголовка Age равно оценке отправителя времени, прошедшего с момента генерации отклика исходным сервером. В случае кэшированного отклика, который был перепроверен исходным сервером, значение Age базируется на времени перепроверки, а не на времени жизни оригинального отклика.
По существу значение Age равно сумме времени, в течение которого отклик был резидентен в каждом из кэшей вдоль пути от исходного сервера, плюс время распространения данных по сети.
Мы используем термин "age_value" для значения поля заголовка Age, в удобном для выполнения арифметических операций формате. Возраст отклика может быть вычислен двумя совершенно независимыми способами.
Текущее время минус date_value, если местные часы синхронизованы с часами исходного сервера. Если результат отрицателен, он заменяется на нуль.
age_value, если все кэши вдоль пути отклика поддерживают HTTP/1.1.
Таким образом, мы имеем два независимых способа вычисления возраста отклика при его получении, допускается их комбинирование, например:
corrected_received_age = max(now - date_value, age_value)
и, поскольку мы имеем синхронизованные часы, или все узлы вдоль пути поддерживают HTTP/1.1, получается надежный (консервативный) результат.
Заметьте, что поправка применяется в каждом кэше HTTP/1.1 вдоль пути так, что, если встретится на пути кэш HTTP/1.0, правильное значение возраста будет получено потому, что его часы почти синхронизованы. Нам не нужна сквозная синхронизация (хотя ее не плохо бы иметь).
Из-за задержек, вносимых сетью, значительное время может пройти с момента генерации отклика сервером и получением его следующим кэшем или клиентом. Если не внести поправки на эту задержку, можно получить неправдоподобные значения возраста отклика.
Так как запрос, который определяет возвращаемое значение Age, должен быть инициирован до генерации этого значения Age, мы можем сделать поправку на задержки, вносимые сетью путем записи времени, когда послан запрос. Затем, когда получено значение Age, оно должно интерпретироваться относительно времени посылки запроса, а не времени когда был получен отклик. Этот алгоритм выдает результат, который не зависит от величины сетевой задержки. Таким образом, вычисляется:
corrected_initial_age = corrected_received_age + (now - request_time)
где "request_time" равно времени (согласно местным часам), когда был послан запрос, вызвавший данный отклик.
Резюме алгоритма вычисления возраста при получении отклика кэшем:
/*
* age_value
* date_value
* request_time
* response_time
* now
*/
apparent_age = max(0, response_time - date_value);
corrected_received_age = max(apparent_age, age_value);
response_delay = response_time - request_time;
corrected_initial_age = corrected_received_age + response_delay;
resident_time = now - response_time;
current_age = corrected_initial_age + resident_time;
Когда кэш посылает отклик, он должен добавить к corrected_initial_age время, в течение которого отклик оставался резидентно локальным. Он должен ретранслировать этот полный возраст, используя заголовок Age, следующему кэшу-получателю.
Заметьте, что клиент не может надежно сказать, что отклик получен из первых рук, но присутствие заголовка Age определенно указывает на то, что это не так. Кроме того, если значение в отклике соответствует более раннему времени, чем местное время запроса клиента, отклик, вероятно, получен не из первых рук (в отсутствие серьезного сбоя часов).
12.4 Вычисление времени жизни (Expiration)
Для того, чтобы решить, является ли отклик свежим или устаревшим, нам нужно сравнить его время жизни с возрастом. Возраст вычисляется так, как это описано в разделе 12.3. Этот раздел описывает то, как вычисляется время жизни, и как определяется, истекло ли время жизни отклика. В обсуждении, приведенном ниже, величины могут быть представлены в любой форме, удобной для выполнения арифметических операций.
Мы используем термин "expires_value" для обозначения содержимого заголовка Expires. Для обозначения числа секунд, определенного директивой максимального возраста заголовка Cache-Control отклика (см. раздел 13.9), используется термин "max_age_value".
Директива максимального возраста имеет приоритет перед Expires, так если max-age присутствует в отклике, вычисление производится просто:
freshness_lifetime = max_age_value
В противном случае, если в отклике присутствует Expires, то вычисления осуществляются следующим образом:
freshness_lifetime = expires_value - date_value
Заметьте, ни одно из этих вычислений не зависит от синхронизации и корректной работы местных часов, так как вся исходная информация получается от исходного сервера.
Если ни Expires, ни Cache-Control: max-age не определяют максимальный возраст отклика, а отклик не содержит других ограничений на кэширование, кэш может вычислить время жизни, используя эвристику. Если эта величина больше 24 часов, кэш должен присоединить к отклику Warning 13, если такое предупреждение еще не добавлено.
Кроме того, если отклик имеет время Last-Modified, эвристическое значение времени жизни должно быть не больше некоторой доли времени, прошедшего со времени модификации. Типичное значение этой доли может составлять 10%.
Расчет того, истекло ли время жизни отклика, достаточно прост:
response_is_fresh = (freshness_lifetime > current_age)
12.5 Устранение неопределенности значений времени жизни
Из-за того, что значения времени жизни часто назначаются оптимистически, может так случиться, что два кэша содержат две “свежих” записи одного и того же ресурса, которые различаются.
Если клиент, выполняя извлечение ресурса, получает отклик не из первых рук на запрос, который был свежим в своем собственном кэше, а заголовок Date в его кэше новей, чем Date нового отклика, тогда клиент может игнорировать этот отклик. Если это так, он может
повторить запрос с директивой "Cache-Control: max-age=0" (см. раздел 13.9), чтобы усилить контроль со стороны исходного сервера.
Если кэш имеет два свежих отклика для одного и того же представления с различными указателями корректности (validator), он должен использовать тот, который имеет современный заголовок Date. Эта ситуация может возникнуть, когда кэш извлекает отклик из других кэшей, или потому, что клиент запросил перезагрузку или повторную проверку корректности заведомо свежего объекта.
12.6 Неопределенность из-за множественных откликов
Из-за того, что клиент может получать отклики по большому числу различных маршрутов, так что некоторые отклики проходят через одну последовательность кэшей, а другие, через другую, клиент может получить их не в той последовательности в какой они были посланы исходным сервером. Хотелось бы, чтобы клиент использовал наиболее свежие оклики, даже если срок годности старых еще не истек.
Ни метка объекта, ни значение времени жизни не могут определять порядок откликов, так как возможно, что более поздний отклик имеет срок годности, который истекает раньше. Однако, спецификация HTTP/1.1 требует передачи заголовка Date в каждом отклике, а значения Date должны быть кратны одной секунде.
Когда клиент пытается перепроверить запись в кэше, а отклик, который он получает, содержит заголовок Date, который оказывается старше, чем у другой уже существующей записи, тогда клиенту следует безусловно повторить запрос и включить
Cache-Control: max-age=0
Чтобы заставить некоторые промежуточные кэши сверить свои копии непосредственно с исходным сервером, или
Cache-Control: no-cache
Чтобы заставить любые промежуточные кэши получит новые копии от исходного сервера.
Если значения Date равны, тогда клиент может использовать любой отклик (или может, если он особенно осторожен, затребовать новый отклик). Серверы не должны зависеть от возможности клиентов четкого выбора между откликами, сгенерированными в пределах одной и той же секунды, если их сроки пригодности перекрываются.
12.8 Модель проверки пригодности
Когда кэш имеет устаревшую запись, которую бы он хотел использовать в качестве отклика на запрос клиента, он сначала должен произвести сверку с базовым сервером (или возможно промежуточным кэшем, содержащим свежий отклик), чтобы убедиться, что кэшированная запись все еще применима. Мы это называем проверкой пригодности записи кэша ("validating"). Так как мы не хотим пересылки всей записи, если с ней все в порядке, и мы не хотим тратить лишнее время из-за RTT в случае, если запись более не пригодна, протокол HTTP/1.1 поддерживает использование условных методов.
Ключевой особенностью протокола для поддержки условных методов являются так называемые “валидаторы” кэша. Когда исходный сервер генерирует полный отклик, он подключает к нему некоторые виды валидаторов, которые хранятся вместе с самой записью в кэше. Когда клиент (агент пользователя или прокси-кэш) выполняет условный запрос ресурса, для которого он имеет запись в кэше, он добавляет соответствующий валидатор к запросу.
Сервер сверяет полученный валидатор с текущим валидатором объекта и, если они совпадают, посылается отклик с соответствующим статусным кодом (обычно, 304 (Not Modified)) и без тела объекта. В противном случае он возвращает полный отклик (включая тело объекта). Таким образом, мы избегаем передачи полного отклика, если валидаторы взаимно согласованы.
Замечание. Функции сравнения, используемые при решении, согласуются ли между собой валидаторы, определены в разделе 12.8.3.
В HTTP/1.1 условный запрос выглядит точно также как и обычный запрос того же самого ресурса, за исключением того, что он несет в себе специальный заголовок (который содержит валидатор), и неявно меняет метод (обычный GET) на условный.
Протокол предусматривает как положительное, так и отрицательное значения условий проверки пригодности записей кэша. То есть, можно запросить, чтобы был реализован этот метод тогда и только тогда, когда валидатор подходит, или тогда и только тогда, когда ни один валидатор не подходит.
Замечание. Отклик, который не имеет валидатора, может кэшироваться и использоваться до истечения его срока годности, если только это явно не запрещено директивой Cache-Control. Однако, кэш не может выполнить условную доставку ресурса, если он не имеет валидатора для запрашиваемого объекта, что означает отсутствие возможности его актуализации после истечения срока годности.
12.8.1 Даты последней модификации
Значение поля заголовка объекта Last-Modified часто используется кэшем в качестве валидатора. Иными словами, запись в кэше рассматривается как пригодная, если объект не был модифицирован с момента, указанного в Last-Modified.
12.8.2 Валидаторы кэша для меток объектов (Entity Tag Cache Validators)
Значение поля заголовка объекта ETag (Entity Tag - метка объекта), представляет собой “непрозрачный” валидатор кэша. Это может гарантировать большую надежность при контроле пригодности в ситуациях, когда неудобно запоминать модификации дат, где недостаточно односекундного разрешения для значения даты HTTP или где исходный сервер хочет избежать определенных парадоксов, которые могут возникнуть от использования дат модификации.
Метки объекта обсуждаются в разделе 3.10. Заголовки, используемые с метками объектов, рассмотрены в разделах 13.20, 13.25, 13.26 и 13.43.
12.8.3 Слабые и сильные валидаторы
Так как исходные серверы и кэши будут сравнивать два валидатора, чтобы решить, представляют ли они один и тот же объект, обычно подразумевается, что, если объект (тело объекта или любой заголовок) изменяется каким-либо образом, то и сопряженный валидатор изменится. Если это так, такой валидатор называется "сильным ".
Однако могут встретиться случаи, когда сервер предпочитает изменять валидатор только при семантически существенных изменениях. Валидатор, который не изменяется всякий раз при изменении ресурса, называется "слабым".
Метки объекта обычно являются "сильными валидаторами", но протокол предлагает механизм установки "слабой" метки объекта. Можно считать, что сильный валидатор это такой, который изменяется, если меняется хотя бы один бит в объекте, в то время как значение слабого изменяется при вариации значения объекта. Альтернативой можно считать точку зрения, при которой сильный валидатор является частью идентификатора конкретного объекта, в то время как слабый валидатор является частью идентификатора набора семантически эквивалентных объектов.
Замечание. Примером сильного валидатора является целое число, которое увеличивается на единицу всякий раз, когда в объект вносится какое-либо изменение.
Время модификации объекта при односекундном разрешении может быть лишь слабым валидатором, так как имеется возможность того, что ресурс может быть модифицирован дважды в течение одной и той же секунды.
Поддержка слабых валидаторов является опционной. Однако слабый валидатор позволяет более эффективно кэшировать эквивалентные объекты.
Валидатор используется либо, когда клиент генерирует запрос и включает валидатор в поле заголовка проверки годности, или когда сервер сравнивает два валидатора.
Сильные валидаторы могут использоваться в любом контексте. Слабые валидаторы применимы только в контексте, который не зависит от точной эквивалентности объектов. Например, как один, так и другой вид валидаторов применим для условного GET. Однако, только сильный валидатор применим для фрагментированного извлечения ресурсов, так как в противном случае клиент может прервать работу с внутренне противоречивым объектом.
Единственной функцией протокола HTTP/1.1, определенной для валидаторов, является сравнение. Существует две функции сравнения валидаторов, в зависимости от того, допускает ли контекст использование слабых валидаторов или нет:
Функция сильного сравнения. Для того, чтобы считаться равными оба валидатора должны быть идентичными, и не один из них не должен быть слабым.
Функция слабого сравнения. Для того, чтобы считаться равными оба валидатора должны быть идентичными, но либо оба, либо один из них могут иметь метку "слабый" без какого-либо воздействия на результат.
Функция слабого сравнения может быть использована для простых (non-subrange – не фрагментных) GET-запросов. Функция сильного сравнения должна быть использована во всех прочих случаях.
Метка объекта является сильной, если она не помечена явно как слабая. В разделе 2.11 рассматривается синтаксис меток объектов.
Параметр Last-Modified time, при использовании в качестве валидатора запроса, является неявно (подразумевается) слабым, если не возможно установить, что он сильный, используя следующие правила:
Валидатор сравнивается исходным сервером с текущим рабочим валидатором для данного объекта и,
Исходный сервер твердо знает, что соответствующий объект не изменялся дважды за секунду, к которой привязан настоящий валидатор. Или
Валидатор предполагается использовать клиентом в заголовке If-Modified-Since или If-Unmodified-Since, так как клиент имеет запись в кэше для соответствующего объекта, и
Эта запись в кэш включает в себя значение Date, которое определяет время, когда исходный сервер послал оригинал запроса, и
Предлагаемый параметр Last-Modified time соответствует моменту времени, по крайней мере, на 60 секунд раньше значения Date.
или
Валидатор сравнивается промежуточным кэшем с валидатором, запомненным в записи для данного объекта, и
Эта запись в кэше включает в себя значение Date, которое определяет время, когда исходный сервер послал оригинал запроса, и
Предлагаемый параметр Last-Modified time соответствует моменту времени, по крайней мере, на 60 секунд раньше значения Date.
Этот метод базируется на том факте, что, если два различных отклика были посланы исходным сервером в пределах одной и той же секунды, но оба имеют одно и то же время Last-Modified, тогда, по крайней мере, один из этих откликов имеет значение Date равное его времени Last-Modified. Произвольный 60-секундный лимит предохраняет против возможности того, что значения Date и Last-Modified сгенерированы с использованием различных часов или в несколько разные моменты времени при подготовке отклика. Конкретная реализация может использовать величину больше 60 секунд, если считается, что 60 секунд слишком мало.
Кэш или исходный сервер, получающий условный запрос кэша, отличный от GET-запроса, должен использовать функцию сильного сравнения, чтобы оценить условие.
Эти правила позволяют кэшам HTTP/1.1 и клиентам безопасно произвести фрагментный доступ к ресурсам на глубину, которая получена от серверов HTTP/1.0.
12.8.4 Правила того, когда использовать метки объекта и даты последней модификации
Мы принимаем набор правил и рекомендаций для исходных серверов, клиентов и кэшей относительно того, когда должны использоваться различные типы валидаторов и для каких целей.
Исходный сервер HTTP/1.1:
Должен послать валидатор метки объекта, если только возможно его сгенерировать.
Может послать слабую метку объекта вместо сильной, если рабочие соображения поддерживают использования слабых меток объекта или если невозможно послать сильную метку объекта.
Должен послать значение Last-Modified, когда это возможно сделать, если только риск нарушения семантической прозрачности, которое может явиться следствием использования этой даты в заголовке, не приведет к серьезным проблемам.
Другими словами предпочтительным поведением для исходного сервера HTTP/1.1 является посылка сильной метки объекта и значения Last-Modified.
Для сохранения легальности сильная метка объекта должна изменяться всякий раз, когда каким-либо образом меняется ассоциированное значение объекта. Слабую метку объекта следует менять всякий раз, когда соответствующий объект изменяется семантически значимым образом.
Замечание. Для того, чтобы обеспечить семантически прозрачное кэширование, исходный сервер должен избегать повторного использования специфических, сильных меток для двух разных объектов, или повторного использования специфических, слабых меток для двух семантически разных объектов. Записи в кэш могут существовать сколь угодно долгое время вне зависимости от времени годности. Таким образом, может оказаться неразумным ожидать, что кэш никогда вновь не попытается перепроверить запись, используя валидатор, который он получил в какой-то момент в прошлом.
Клиенты HTTP/1.1:
Если метка объекта была прислана исходным сервером, эта метка должна быть использована в любом условном запросе кэша (с If-Match или If-None-Match).
Если только значение Last-Modified было прислано исходным сервером, оно должно использоваться в нефрагментных, условных запросах кэша (с использованием If-Modified-Since).
Если только значение Last-Modified было прислано исходным сервером HTTP/1.0, оно может использоваться в фрагментных, условных запросах кэша (с использованием If-Unmodified-Since:). Агенту пользователя следует обеспечить способ блокировки этого в случае возникновения трудностей.
Если и метка объекта и значение Last-Modified были присланы исходным сервером, в условных запросах кэша следует использовать оба валидатора. Это позволяет корректно реагировать кэшам, поддерживающим как HTTP/1.0, так и HTTP/1.1.
Кэш HTTP/1.1 при получении запроса должен использовать наиболее регламентирующий валидатор, когда проверяется, соответствуют ли друг другу запись в буфере клиента и собственная запись в кэше. Это единственный выход, когда запрос содержит как метку объекта, так и валидатор last-modified-date (If-Modified-Since или If-Unmodified-Since).
Базовым принципом всех этих правил является то, что HTTP/1.1 серверы и клиенты должны пересылать как можно больше надежной информации в своих запросах и откликах. HTTP/1.1 системы, принимая эту информацию, используют наиболее консервативное предположение относительно валидаторов, которые они получают.
Клиенты HTTP/1.0 и кэши будут игнорировать метки объектов. Вообще, значения времени последней модификации, полученные или используемые этими системами, будут поддерживать прозрачное и эффективное кэширование и, по этой причине, исходные серверы HTTP/1.1 должны присылать значения параметров Last-Modified. В тех редких случаях, когда в качестве валидатора системой HTTP/1.0 используется значение Last-Modified, могут возникнуть серьезные проблемы, и тогда исходные серверы HTTP/1.1 присылать их не должны.
12.8.5 Условия пригодности
Принцип использования меток объектов базируется на том, что только автор услуг знает семантику ресурсов достаточно хорошо, чтобы выбрать подходящий механизм контроля кэширования. Спецификация любой функции сравнения валидаторов более сложна, чем сравнение байтов. Таким образом, для целей проверки пригодности записи в кэше никогда не используется сравнение любых других заголовков кроме Last-Modified, для совместимости с HTTP/1.0.
12.9. Кэшируемость отклика
Если только нет специального ограничения директивой Cache-Control (раздел 13.9), система кэширования может всегда запоминать отклик (см. раздел 12.8) в качестве записи в кэш, может прислать его без проверки пригодности, если он является свежим, и может послать его после успешной проверки пригодности. Если нет ни валидатора кэша ни времени пригодности, ассоциированного с этим откликом, мы не ожидаем, что такой отклик будет кэширован, но некоторые кэши могут нарушить это правило (например, когда имеется плохая коннективность или она вообще отсутствует). Клиент обычно может детектировать, что такой отклик был взят из кэша после сравнения заголовка Date с текущим временем.
Заметьте, что некоторые кэши HTTP/1.0 нарушают эти правила, даже не присылая предупреждения.
Однако, в некоторых случаях может быть неприемлемо для кэша сохранять объект или присылать его в ответ на последующие запросы. Это может быть потому, что автор сервиса полагает необходимой абсолютную семантическую прозрачность по соображениям безопасности или конфиденциальности. Определенные директивы Cache-Control предназначены для того, чтобы сервер мог указать, что некоторые объекты ресурсов или их части не могут кэшироваться ни при каких обстоятельствах.
Заметьте, что раздел 13.8 в норме препятствует кэшу запоминать и отсылать отклик на предыдущий запрос, если этот запрос включает в себя заголовок авторизации.
Отклик, полученный со статусным кодом 200, 203, 206, 300, 301 или 410, может быть запомнен кэшем и использован в ответе на последующие запросы, если директива не препятствует кэшированию. Однако, кэш, который не поддерживает заголовки Range и Content-Range не должен кэшировать отклики 206 (Partial Content).
Отклик, полученный с любым другим статусным кодом, не должен отсылаться в ответ на последующие запросы, если только нет директив Cache-Control или других заголовков, которые напрямую разрешают это. К таким, например, относятся: заголовок Expires (раздел 13.21); "max-age", "must-revalidate", "proxy-revalidate", "public" или "private" директива Cache-Control (раздел 13.9).
12.10 Формирование откликов кэшей
Целью кэша HTTP является запоминание информации, полученной в откликах на запросы, для использования в ответ на будущие запросы. Во многих случаях, кэш просто отсылает соответствующие части отклика отправителю запроса. Однако, если кэш содержит объект, базирующийся на предшествующем отклике, он может быть вынужден комбинировать части нового отклика с тем, что хранится в объекте кэша.
12.10.1 Заголовки End-to-end (точка-точка) и Hop-by-hop (шаг-за-шагом)
Для целей определения поведения кэшей и некэшурующих прокси-серверов заголовки HTTP делятся на две категории:
Заголовки End-to-end, которые должны быть пересланы конечному получателю запроса или отклика. Заголовки End-to-end в откликах должны запоминаться как часть объекта кэша и пересылаться в любом отклике, полученном из записи кэша.
Заголовки Hop-by-hop, которые имеют смысл только для одноуровневого транспортного соединения, они не запоминаются кэшем и не переадресуются прокси-серверами.
Следующие заголовки HTTP/1.1 относятся к категории hop-by-hop:
Connection
Keep-Alive
Public
Proxy-Authenticate
Transfer-Encoding
Upgrade
Все другие заголовки, определенные HTTP/1.1 относятся к категории end-to-end.
Заголовки Hop-by-hop, вводимые в будущих версиях HTTP, должны быть перечислены в заголовке Connection, как это описано в разделе 13.10.
12.10.2 Немодифицируемые заголовки
Некоторые черты протокола HTTP/1.1, такие как Digest Authentication, зависят от значения определенных заголовков end-to-end. Кэш или некэширующий прокси не должны модифицировать заголовок end-to-end, если только определение этого заголовка не требует или не разрешает этого.
Кэш или некэширующий прокси не должны модифицировать любое из следующих полей запроса или отклика или добавлять какие-либо поля, если они еще не существуют:
Content-Location
Etag
Expires
Last-Modified
Кэш или некэширующий прокси не должны модифицировать или добавлять следующие поля в любых запросах и в откликах, которые содержат директиву no-transform Cache-Control:
Content-Encoding
Content-Length
Content-Range
Content-Type
Кэш или некэширующий прокси могут модифицировать или добавлять эти поля в отклик, который не включает директиву no-transform. Если же он содержит эту директиву, следует добавить предупреждение 14 (Transformation applied), если оно еще не занесено в отклик.
Предупреждение. Ненужная модификация заголовков end-to-end может вызвать отказы в авторизации, если в поздних версиях HTTP использован более строгий механизм. Такие механизмы авторизации могут использовать значения полей заголовков не перечисленных здесь.
12.10.3 Комбинирование заголовков
Когда кэш делает запрос серверу о пригодности ресурса и сервер выдает отклик 304 (Not Modified), кэш должен подготовить и отправить отклик, чтобы послать клиенту. Кэш использует тело объекта из записи в кэше при формировании отклика. Заголовки end-to-end записанные в кэше, используются для конструирования отклика. Исключение составляют любые end-to-end заголовки, поступившие в рамках отклика 304, они должны заместить соответствующие заголовки из записи в кэше. Если только кэш не решил удалить запись, он должен также заменить end-to-end заголовки своей записи соответствующими заголовками из полученного отклика.
Другими словами, набор end-to-end заголовков, полученный вместе откликом переписывает все соответствующие end-to-end заголовки, из записи в кэше. Кэш может добавить к этому набору заголовки предупреждений (см. раздел 13.45).
Если имя поля заголовка приходящего отклика соответствует более чем одной записи в кэше, все старые заголовки заменяются.
Замечание. Это правило позволяет исходному серверу использовать отклик 304 (Not Modified) для актуализации любого заголовка, связанного с предыдущим откликом для того же объекта, хотя это может не всегда иметь смысл. Это правило не позволяет исходному серверу использовать отклик 304 (not Modified) для того, чтобы полностью стереть заголовок, который был прислан предыдущим откликом.
12.10.4 Комбинирование байтовых фрагментов
Отклик может передать только субдиапазон байтов тела объекта, либо потому, что запрос включает в себя один или более спецификаций Range, либо из-за преждевременного обрыва соединения. После нескольких таких передач кэш может получить несколько фрагментов тела объекта.
Если кэш запомнил не пустой набор субфрагментов объекта, а входящий отклик передает еще один фрагмент, кэш может комбинировать новый субфрагмент с уже имеющимся набором, если для обоих выполняются следующие условия:
Оба приходящие отклика и запись в кэше должны иметь валидатор кэша.
Оба валидатора кэша должны соответствовать функции сильного сравнения (см. раздел 12.8.3).
Если любое из условий не выполнено, кэш должен использовать только наиболее поздний частичный отклик и отбросить другую частичную информацию.
12.11. Кэширование согласованных откликов
Использование согласования содержимого под управлением сервера (раздел 11), что индицируется присутствием поля заголовка Vary в отклике, изменяет условия и процедуру, при которой кэш может использовать отклик для последующих запросов.
Сервер должен использовать поле заголовка Vary (раздел 13.43), чтобы информировать кэш о том, какие пределы для поля заголовка используются при выборе представления кэшируемого отклика. Кэш может использовать выбранное представление для ответов на последующие запросы, только когда они имеют те же или эквивалентные величины полей заголовка, специфицированных в заголовке отклика Vary. Запросы с различными значениями одного или нескольких полей заголовка следует переадресовывать исходному серверу.
Если представлению присвоена метка объекта, переадресуемый запрос должен быть условным и содержать метки в поле заголовка If-None-Match всех его кэшированных записей для Request-URI. Это сообщает серверу набор объектов, которые в настоящее время хранятся в кэше, так что, если любая из этих записей соответствует запрашиваемому объекту, сервер может использовать заголовок ETag в своем отклике 304 (Not Modified), чтобы сообщить кэшу, какой объект подходит. Если метка объекта нового отклика соответствует существующей записи, новый отклик должен быть использован для актуализации полей заголовка существующей записи, а результат должен быть прислан клиенту.
Поле заголовка Vary может также информировать кэш, что представление было выбрано с использованием критериев помимо взятых из заголовков запросов. В этом случае, кэш не должен использовать отклик в ответ на последующий запрос, если только кэш не передает исходному серверу условный запрос. Сервер при этом возвращает отклик 304 (Not Modified), включая метку объекта или поле Content-Location, которые указывают, какой объект должен быть использован.
Если какая-то запись кэша содержит только часть информации для соответствующего объекта, его метка не должна содержаться в заголовке If-None-Match, если только запрос не лежит в диапазоне, который полностью покрывается этим объектом.
Если кэш получает позитивный отклик с полем Content-Location, соответствующим записи в кэше для того же Request-URI, с меткой объекта, отличающейся от метки существующего объекта, и датой современнее даты существующего объекта, данная запись не должна использоваться в качестве отклика для будущих запросов и должна быть удалена из кэша.
12.12. Кэши коллективного и индивидуального использования
По причинам безопасности и конфиденциальности необходимо делать различие между кэшами совместного и индивидуального использования. Индивидуальные кэши доступны только для одного пользователя. Доступность в этом случае должна определяться соответствующим механизмом, обеспечивающим безопасность. Все другие кэши рассматриваются как коллективные. Другие разделы этой спецификации накладывают определенные ограничения на работу совместно используемых кэшей, для того, чтобы предотвратить потерю конфиденциальности или управления доступом.
12.13. Ошибки и поведение кэша при неполном отклике
Кэш, который получает неполный отклик (например, с меньшим числом байтов, чем специфицировано в заголовке Content-Length) может его запомнить. Однако, кэш должен воспринимать эти данные как частичный отклик. Частичные отклики могут компоноваться, как это описано в разделе 12.5.4. Результатом может быть полный или частичный отклик. Кэш не должен
возвращать частичный отклик клиенту без явного указания на то, что он частичный, используя статусный код 206 (Partial Content). Кэш не должен возвращать частичный отклик, используя статусный код 200 (OK).
Если кэш получает отклик 5xx при попытке перепроверить запись, он может переадресовать этот отклик запрашивающему клиенту или действовать так, как если бы сервер не смог ответить на запрос. В последнем случае он может вернуть отклик, полученный ранее, если только запись в кэше не содержит директиву Cache-Control "must-revalidate" (см. раздел 13.9).
12.14. Побочные эффекты методов GET и HEAD
Если исходный сервер напрямую не запрещает кэширование своих откликов, методы приложения GET и HEAD не должны давать каких-либо побочных эффектов, которые вызывали бы некорректное поведение, если эти отклики берутся из кэша. Они все же могут давать побочные эффекты, но кэш не обязан рассматривать такие побочные эффекты, принимая решение о кэшировании. Кэши контролируют лишь прямые указания исходного сервера о запрете кэширования.
Обратим внимание только на одно исключение из этого правила: некоторые приложения имеют традиционно используемые GET и HEAD с запросами URL (содержащими "?" в части rel_path) для выполнения операций с ощутимыми побочными эффектами. Кэши не должны
обрабатывать отклики от таких URL, как свежие, если только сервер не присылает непосредственно значение времени жизни. Это в частности означает, что отклики от серверов HTTP/1.0 для этих URI не следует брать из кэша. Дополнительную информацию по смежным темам можно найти в разделе 8.1.1.
12.15 Несоответствие после актуализации или стирания
Воздействие определенных методов на исходный сервер может вызвать то, что одна или более записей, имеющихся в кэше, становятся неявно непригодными. То есть, хотя они могут оставаться "свежими", они не вполне точно отражают то, что исходный сервер пришлет в ответ на новый запрос.
В протоколе HTTP не существует способа гарантировать, что все такие записи в кэше будут помечены как непригодные. Например, запрос, который вызывает изменение в исходном сервере не обязательно проходит через прокси, где в кэше хранится такая запись. Однако несколько правил помогает уменьшить вероятность некорректного поведения системы.
В этом разделе, выражение " пометить объект как непригодный" означает, что кэш должен либо удалить все записи, относящиеся к этому объекту из памяти или должен пометить их, как непригодные ("invalid"), что будет вызывать обязательную перепроверку пригодности перед отправкой в виде отклика на последующий запрос.
Некоторые методы HTTP могут сделать объект непригодным. Это либо объекты, на которые осуществляется ссылка через Request-URI, или через заголовки отклика Location или Content-Location (если они имеются). Это методы:
PUT
DELETE
POST
12.16. Обязательная пропись (Write-Through Mandatory)
Все методы, которые предположительно могут вызвать модификацию ресурсов исходного сервера должны быть прописаны в исходный сервер. В настоящее время сюда входят все методы кроме GET и HEAD. Кэш не должен отвечать на такой запрос от клиента, прежде чем передаст запрос встроенному (inbound) серверу, и получит соответствующего отклик от него. Это не препятствует кэшу послать отклик 100 (Continue), прежде чем встроенный сервер ответит.
Альтернатива, известная как "write-back" или "copy-back" кэширование, в HTTP/1.1 не допускается, из-за трудности обеспечения согласованных актуализаций и проблем, связанных с отказами сервера, кэша или сети до осуществления обратной записи (write-back).
12.17. Замещения в кэше
Если от ресурса получен новый кэшируемый отклик (см. разделы 13.9.2, 12.5, 12.6 и 12.8), в то время как какой-либо отклик для того же ресурса уже записан в кэш, кэшу следует использовать новый отклик для ответа на текущий запрос. Он может ввести его в память кэша и может, если он отвечает всем требованиям, использовать в качестве отклика для будущих запросов. Если он вводит новый отклик в память кэша, он должен следовать правилам из раздела 12.5.3.
Замечание. Новый отклик, который имеет значение заголовка Date старше, чем кэшированные уже отклики, не должен заноситься в кэш.
12.18. Списки предыстории
Агенты пользователя часто имеют механизмы "исторического" управления, такие как кнопки "Back" и списки предыстории, которые могут использоваться для повторного отображения объекта, извлеченного ранее в процессе сессии. Механизмы предыстории и кэширования различны. В частности механизмы предыстории не должны пытаться показать семантически прозрачный вид текущего состояния ресурса. Скорее, механизм предыстории предназначен для того, чтобы в точности показать, что видел пользователь, когда ресурс был извлечен. По умолчанию время годности не приложимо к механизмам предыстории. Если объект все еще в памяти, механизм предыстории должен его отобразить, даже если время жизни объекта истекло и он объявлен непригодным, если только пользователь не сконфигурировал агента так, чтобы обновлять объекты, срок годности которых истек. Это не запрещает механизму предыстории сообщать пользователю, что рассматриваемый им объект устарел.
Замечание. Если механизмы предыстории излишне мешают пользователю просматривать устаревшие ресурсы, то это заставит разработчиков избегать пользоваться контролем времени жизни объектов. Разработчикам следует считать важным, чтобы пользователи не получали сообщений об ошибке или предупреждения, когда они пользуются навигационным управлением (например, таким как клавиша BACK).
4.5.6.1.13. Определения полей заголовка
Этот раздел определяет синтаксис и семантику всех стандартных полей заголовков HTTP/1.1. Для полей заголовков объекта, как отправитель, так и получатель могут рассматриваться клиентом или сервером в зависимости от того, кто получает объект.
13.1. Поле Accept
Поле заголовка запроса Accept может использоваться для спецификации определенных типов среды, которые приемлемы для данного ресурса. Заголовки Accept могут использоваться для индикации того, что запрос ограничен в рамках определенного набора типов, как в случае запросов отображения в текущей строке.
| Accept | = "Accept" ":" |
| #( media-range [ accept-params ] ) | |
| media-range | = ( "*/*" |
| | ( type "/" "*") | |
| | ( type "/" subtype ) | |
| ) *( ";" parameter ) |
accept-extension = ";" token [ "=" ( token | quoted-string ) ]
Символ звездочка "*" используется для того, чтобы группировать типы среды в группы с "*/*", указывающим на все типы, и "type/*", указывающим на все субтипы данного типа. Группа сред может включать в себя параметры типа среды, которые применимы. За каждой группой сред может следовать один или более параметров приема (accept-params), начинающихся с "q" параметра для указания фактора относительного качества. Первый "q" параметр (если таковой имеется) отделяет параметры группы сред от параметров приема. Факторы качества позволяют пользователю или агенту пользователя указать относительную степень предпочтения для данной группы сред, используя шкалу значений q от 0 до 1 (раздел 2.9). Значение по умолчанию соответствует q=1.
Замечание. Использование имени параметра "q" для разделения параметров типа среды от параметров расширения Accept связано с исторической практикой. Это мешает присвоения параметру типа среды имени "q". Пример Accept: audio/*; q=0.2, audio/basic.
Должно интерпретироваться, как "Я предпочитаю audio/basic, но шлите мне любые типы аудио, если это лучшее, что имеется после 80% понижения качества". Если поле заголовка Accept отсутствует, тогда предполагается, что клиент воспринимает все типы среды. Если поле заголовка Accept присутствует и, если сервер не может послать отклик, который является приемлемым, согласно комбинированному значению поля Accept, тогда сервер должен послать отклик 406 (not acceptable). Более сложный пример.
Accept: text/plain; q=0.5, text/html,
text/x-dvi; q=0.8, text/x-c
Это будет интерпретироваться следующим образом: "text/html и text/x-c являются предпочтительными типами сред, но, если их нет, тогда следует слать объект text/x-dvi, если он отсутствует, следует присылать объект типа text/plain".
Группы сред могут быть заменены другими группами или некоторыми специальными типами среды. Если используется более одного типа среды для данного типа, предпочтение отдается наиболее специфичному типу. Например,
Accept: text/*, text/html, text/html;level=1, */*
имеет следующие предпочтения:
1) text/html;level=1
2) text/html
3) text/*
4) */*
Фактор качества типа среды, ассоциированный с данным типом определен путем нахождения группы сред с наивысшим предпочтением, который подходит для данного типа. Например,
Accept: text/*;q=0.3, text/html;q=0.7, text/html;level=1,
text/html;level=2;q=0.4, */*;q=0.5
в результате будут установлены следующие величины:
| text/html;level=1 | = 1 |
| text/html | = 0.7 |
| text/plain | = 0.3 |
| image/jpeg | = 0.5 |
| text/html;level=2 | = 0.4 |
| text/html;level=3 ; | = 0.7 |
13.2. Поле Accept-Charset
Поле заголовка запроса Accept- Charset может быть использовано для указания того, какой символьный набор приемлем для отклика. Это поле позволяет клиентам, способным распознавать более обширные или специальные наборы символов, сигнализировать об этой возможности серверу, который способен представлять документы в рамках этих символьных наборов. Набор символов ISO-8859-1 может считаться приемлемым для всех агентов пользователя.
Accept-Charset = "Accept-Charset" ":"
1#( charset [ ";" "q" "=" qvalue ] )
Значения символьных наборов описаны в разделе 2.4. Каждому символьному набору может быть поставлено в соответствие значение качества, которое характеризует степень предпочтения пользователя для данного набора. Значение по умолчанию q=1. Например Accept-Charset: ISO-8859-5, unicode-1-1;q=0.8. Если заголовок Accept-Charset отсутствует, по умолчанию это означает, что приемлем любой символьный набор. Если заголовок Accept-Charset присутствует, и, если сервер не может послать отклик, который приемлем с точки зрения заголовка Accept-Charset, тогда он должен послать сообщение об ошибке со статусным кодом 406 (not acceptable), хотя допускается посылка и отклика "unacceptable".
13.3. Поле Accept-Encoding
Поле заголовка запроса Accept-Encoding сходно с полем Accept, но регламентирует кодировку содержимого (раздел 13.12), которая приемлема в отклике.
Accept-Encoding = "Accept-Encoding" ":"
#( content-coding )
Ниже приведен пример его использования Accept-Encoding: compress, gzip
Если заголовок Accept-Encoding в запросе отсутствует, сервер может предполагать, что клиент воспримет любую кодировку информации. Если заголовок Accept-Encoding присутствует и, если сервер не может послать отклик, приемлемый согласно этому заголовку, тогда серверу следует послать сообщение об ошибке со статусным кодом 406 (Not Acceptable). Пустое поле Accept-Encoding указывает на то, что не приемлемо никакое кодирование.
13.4. Поле Accept-Language
Поле заголовка запроса Accept-Language сходно с полем Accept, но регламентирует набор естественных языков, которые предпочтительны в отклике на запрос.
| Accept-Language | = "Accept-Language" ":" |
| 1#( language-range [ ";" "q" "=" qvalue ] ) | |
| language-range | = ( ( 1*8ALPHA *( "-" 1*8ALPHA ) ) | "*" ) |
Accept-Language: da, en-gb;q=0.8, en;q=0.7
будет означать: "Я предпочитаю датский, но восприму британский английский и другие типы английского". Список языков согласуется с языковой меткой, если он в точности равен метке или, если он в точности равен префиксу метки, такому как первый символ метки, за которым следует символ "-". Специальный список "*", если он присутствует в поле Accept-Language, согласуется с любой меткой.
Замечание. Это использование префикса не предполагает, что языковые метки присвоены языкам таким образом, что, если пользователь понимает язык с определенной меткой, то он поймет все языки, имеющие метки с одним и тем же префиксом. Правило префикса просто позволяет использовать префиксные метки для случаев, когда это справедливо.
Фактор качества, присваиваемый языковой метке с помощью поля Accept-Language, равен значению качества самого длинного списка языков в поле. Если в поле отсутствует список языков, фактору качества присваивается значение нуль. Если в запросе отсутствует заголовок Accept-Language, серверу следует предполагать, что все языки приемлемы в равной мере. Если заголовок Accept-Language имеется, тогда все языки, которым присвоен фактор качества больше нуля, приемлемы.
Посылка заголовка Accept-Language с полным списком языковых предпочтений пользователя в каждом запросе может восприниматься как нарушение принципов конфиденциальности. Обсуждение этой проблемы смотри в разделе 14.7.
Замечание. Так как степень интеллигентности в высшей степени индивидуальна, рекомендуется, чтобы приложения клиента делали выбор языковых предпочтений доступным для пользователя. Если выбор не сделан доступным, тогда поле заголовка Accept-Language не должно присутствовать в запросе.
13.5. Поле Accept-Ranges
Поле заголовка отклика Accept-Ranges позволяет серверу указать доступность широкодиапазонных запросов к ресурсу:
Accept-Ranges = "Accept-Ranges" ":" acceptable-ranges
acceptable-ranges = 1#range-unit | "none"
Исходные серверы, которые воспринимают байт-диапазонные запросы, могут послать
Accept-Ranges: bytes
но делать это необязательно. Клиенты могут выдавать байт-диапазонные запросы, не получив этот заголовок отклика для запрашиваемого ресурса. Серверы, которые не могут работать с какими-либо диапазонными запросами, могут послать
Accept-Ranges: none,
чтобы посоветовать клиенту, не пытаться посылать такие запросы.
13.6. Поле Age
Поле заголовка отклика Age передает оценку отправителем времени с момента формирования отклика исходным сервером (или перепроверки его пригодности). Кэшированный отклик является свежим, если его возраст не превышает его времени жизни. Значения Age вычисляются согласно рекомендациям представленным разделе 12.2.3.
| Age | = "Age" ":" age-value |
| age-value | = delta-seconds |
Если кэш получает величину больше, чем наибольшее положительное число, которое он может себе представить или, если вычисление возраста вызвало переполнение, он должен передать заголовок Age со значением 2147483648 (231). Кэши HTTP/1.1 должны
посылать заголовки Age в каждом отклике. Кэшам следует использовать арифметический тип чисел не менее 31 бита.
13.7. Поле Allow
Поле заголовка объекта Allow перечисляет набор методов, поддерживаемых ресурсом, идентифицированным Request-URI. Целью этого поля является точное информирование получателя о рабочих методах данного ресурса. Поле заголовка Allow должно быть представлено в отклике 405 (Method Not Allowed).
Allow = "Allow" ":" 1#method
Пример использования:
Allow: GET, HEAD, PUT
Это поле не препятствует клиенту испытать другие методы. Однако указания, данные в значение поля заголовка Allow, следует выполнять. Действительный набор методов определяется исходным сервером во время каждого запроса.
Поле заголовка Allow может быть прислано запросом PUT, чтобы рекомендовать методы, которые будут поддерживаться новым или модифицированным ресурсом. Серверу не обязательно поддерживает эти методы, но ему следует включить заголовок Allow в отклик, чтобы сообщить действительно поддерживаемые методы.
Прокси не должен модифицировать поле заголовка Allow, даже если он не понимает все специфицированные методы, так как агент пользователя может иметь другие средства связи с исходным сервером.
Поле заголовка Allow не указывают на то, что методы реализованы на уровне сервера. Серверы могут использовать поле заголовка отклика Public (раздел 13.35), чтобы описать, какие методы реализованы на сервере.
13.8. Авторизация
Агент пользователя, который хочет авторизовать себя на сервере может сделать это после получения отклика 401, включив в запрос поле заголовка Authorization. Значение поля Authorization состоит из идентификационной информации агента пользователя для области (realm) запрошенных ресурсов.
Authorization = "Authorization" ":" credentials
Авторизация доступа HTTP описана в разделе 10. Если запрос идентифицирован и область специфицирована, та же самая идентификационная информация может быть использована для других запросов в пределах данной области.
Когда кэш коллективного пользования (см. раздел 12.7) получает запрос, содержащий поле Authorization, он не должен присылать соответствующий отклик в качестве ответа на какой-либо другой запрос, если только не выполняется одно из следующих условий:
Если отклик включает в себя директиву Cache-Control "proxy-revalidate", кэш может использовать этот отклик при последующих запросах, но прокси-кэш должен сначала перепроверить его пригодность с помощью исходного сервера, используя заголовки нового запроса для того, чтобы исходный сервер мог идентифицировать новый запрос.
Если отклик содержит в себе директиву Cache-Control "must-revalidate", кэш может использовать этот отклик при ответах на последующие запросы, но все кэши должны сначала перепроверить пригодность откликов с помощью исходного сервера, используя заголовки нового запроса для того, чтобы сервер мог идентифицировать новый запрос.
Если отклик содержит директиву Cache-Control "public", то этот отклик может быть отослан в ответ на любой последующий запрос.
13.9. Поле Cache-Control
Поле общего заголовка Cache-Control используется для спецификации директив, которые должны исполняться всеми механизмами кэширования вдоль цепочки запрос/отклик. Директивы определяют поведение, которое, как предполагается, должно предотвратить нежелательную интерференцию откликов или запросов в кэше. Эти директивы обычно переписывают алгоритм кэширования, используемый по умолчанию. Директивы кэша являются однонаправленными, присутствие директивы в запросе не предполагает, что та же директива будет присутствовать и в отклике.
Заметьте, что кэши HTTP/1.0 могут не реализовывать управление (Cache-Control), а могут использовать только директиву Pragma: no-cache (см. раздел 13.32).
Директивы кэша должны пропускаться через приложения прокси или внешнего шлюза (gateway), вне зависимости от их значения для этого приложения, так как директивы могут быть применимы для всех получателей в цепочке запрос/отклик. Невозможно специфицировать директивы для отдельных кэшей.
| Cache-Control | = "Cache-Control" ":" 1#cache-directive |
| cache-directive | = cache-request-directive |
| | cache-response-directive | |
| cache-request-directive | = "no-cash" ["=" 1#field-name] |
| | "no-store" | |
| | "max-age" "=" delta-seconds | |
| | "max-stale" [ "=" delta-seconds ] | |
| | "min-fresh" "=" delta-seconds | |
| | "only-if-cached" | |
| | cache-extension | |
| cache-response-directive | = "public" |
| | "private" [ "=" 1#field-name ] | |
| | "no-cache" [ "=" 1#field-name ] | |
| | "no-store" | |
| | "no-transform" | |
| | "must-revalidate" | |
| | "max-age" "=" delta-seconds | |
| | cache-extension; | |
| cache-extension | = token [ "=" ( token | quoted-string ) ] |
/p> Если директива появляется без какого-либо параметра 1#field-name, она воздействует на весь запрос или отклик. Когда такая директива приходит с параметром 1#field-name, она воздействует только на именованное поле или поля и не имеет никакого действия на остальную часть запроса или отклика. Этот механизм поддерживает расширяемость. Реализации будущих версий протокола HTTP могут использовать эти директивы для полей заголовка, неопределенных в HTTP/1.1.
Директивы управления кэшем могут быть разделены на следующие категории:
Ограничения на то, что можно кэшировать. Они налагаются только исходным сервером.
Ограничения на то, что можно записывать в память кэша. Они определяются исходным сервером или агентом пользователя.
Модификации базового механизма контроля годности записей. Они вносятся либо исходным сервером, либо агентом пользователя.
Управление процессом перепроверки годности записей и перезагрузкой осуществляется только агентом пользователя.
Управление преобразованием объектов.
Расширения системы кэширования.
13.9.1. Что допускает кэширование?
По умолчанию отклик допускает кэширование, если требования метода запроса, поля заголовка запроса и код статуса отклика указывают на то, что кэширование не запрещено. Раздел 12.4 обобщает эти рекомендации для кэширования. Следующие Cache-Control директивы отклика позволяют исходному серверу переписать стандартные требования по кэшируемости:
public
Указывает, что отклик может кэшироваться любым кэшем, даже если он в норме не кэшируем или кэшируем только в кэшах индивидуального пользования. (См. также об авторизации в разделе 13.8.)
private
Указывает, что весь или часть сообщения отклика предназначена для одного пользователя и не должна быть записана кэшем коллективного пользования. Это позволяет исходному серверу заявить о том, что специфицированные части отклика предназначены только для одного пользователя, и он не может отсылаться в ответ на запросы других пользователей. Частный кэш может кэшировать такие отклики.
Замечание. Это использование слова частный (private) определяет только возможность кэширования и не гарантирует конфиденциальности для содержимого сообщения.
no-cache
Указывает, весь или фрагмент сообщения-отклика не должны кэшироваться, где бы то ни было. Это позволяет исходному серверу предотвратить кэширование даже для кэшей, сконфигурированных для рассылки устаревших откликов.
Замечание. Большинство кэшей HTTP/1.0 не распознают и не исполняют эту директиву.
13.9.2. Что может быть записано в память кэша?
Целью директивы no-store (не запоминать) является предотвращение ненамеренного распространения или записи конфиденциальной информации (например, на backup ленты). Директива no-store применяется для всего сообщения и может быть послана как в отклике, так и в запросе. При посылке в запросе кэш не должен запоминать какую-либо часть этого запроса или присланного в ответ отклика. При посылке в отклике, кэш не должен запоминать какую-либо часть отклика или запроса, его вызвавшего. Эта директива действует как для индивидуальных кэшей, так и кэшей коллективного пользования. "Не должно запоминаться" в данном контексте означает, что кэш не должен заносить отклик в долговременную память и должен сделать все от него зависящее для того, чтобы удалить эту информацию из временной памяти после переадресации этих данных.
Даже когда эта директива ассоциирована с откликом, пользователи могут непосредственно запомнить такой отклик вне системы кэширования (например, с помощью диалога "Save As"). Буферы предыстории могут запоминать такие отклики как часть своей нормальной работы.
Цель этой директивы обеспечение выполнения определенных требований пользователей и разработчиков, кто связан с проблемами случайного раскрытия информации за счет непредвиденного доступа к структуре данных кэша. При использовании этой директивы можно в некоторых случаях улучшить конфиденциальность, но следует учитывать, что не существует какого-либо надежного механизма для обеспечения конфиденциальности. В частности, некоторые кэши могут не распознавать или не выполнять эту директиву, а коммуникационные сети могут прослушиваться.
13.9.3. Модификации базового механизма контроля времени жизни
Время пригодности объекта (entity expiration time) может быть специфицировано исходным сервером с помощью заголовка Expires (см. раздел 13.21). Другой возможностью является применение директивы max-age в отклике.
Если отклик включает в себя как заголовок Expires, так и директиву max-age, более высокий приоритет имеет директива max-age, даже если заголовок Expires накладывает более жесткие ограничения. Это правило позволяет исходному серверу обеспечить для заданного отклика большее время жизни в случае объектов кэша HTTP/1.1 (или более поздней версии), чем в HTTP/1.0. Это может быть полезным, если кэш HTTP/1.0 некорректно вычисляет возраст объекта или его время пригодности, например, из-за не синхронности часов.
Замечание. Большинство старых кэшей, несовместимых с данной спецификацией, не поддерживают применение директив управления кэшем. Исходный сервер, желающий применить директиву управления кэшем, которая ограничивает, но не запрещает кэширование в системах, следующих регламентациям HTTP/1.1, может использовать то, что директива max-age переписывает значение, определенное Expires.
Другие директивы позволяют агенту пользователя модифицировать механизм контроля времени жизни объектов. Эти директивы могут быть специфицированы в запросе max-age.
Этот запрос указывает, что клиент желает воспринять отклик, чей возраст не больше времени, заданного в секундах. Если только не включена также директива max-stale, клиент не воспримет устаревший отклик.
Запрос min-fresh указывает, что клиент желает воспринять отклик, чье время жизни не меньше, чем его текущий возраст плюс заданное время в секундах. То есть, клиент хочет получит отклик, который будет еще свежим, по крайней мере, заданное число секунд.
Запрос max-stale указывает, что клиент желает воспринять отклик, время жизни которого истекло. Если max-stale присвоено конкретное значение, тогда клиент хочет получить отклик, время жизни которого не ранее, чем заданное число секунд тому назад. Если значения max-stale в директиве не указано, тогда клиент готов воспринять отклики любого возраста.
Если кэш присылает устаревший отклик, из-за наличия в запросе директивы max-stale, либо потому, что кэш сконфигурирован таким образом, что переписывает время жизни откликов, кэш должен присоединить заголовок предупреждения к отклику, используя Warning 10 (Response is stale - отклик устарел).
13.9.4. Управление перепроверкой пригодности и перезагрузкой
Иногда агент пользователя может потребовать, чтобы кэш перепроверил пригодность своих записей с помощью исходного сервера (а не соседнего кэша по пути к исходному серверу), или перезагрузил свой кэш из исходного сервера. Может потребоваться перепроверка End-to-end, если и кэш и исходный сервер имеют завышенные оценки времени жизни кэшированных откликов. Перезагрузка End-to-end может потребоваться, если запись в кэше оказалась по какой-то причине поврежденной.
Перепроверка типа End-to-end может быть запрошена в случае, когда клиент не имеет своей локальной копии, этот вариант мы называем "не специфицированная перепроверка end-to-end", или когда клиент имеет локальную копию, такой вариант называется "специфической перепроверкой end-to-end."
Клиент может потребовать три вида действий, используя в запросе директивы управления кэшем:
End-to-end reload
Запрос включает в себя директиву управления кэшем "no-cache" или, для совместимости с клиентами HTTP/1.0, "Pragma: no-cache". В запросе с директивой no-cache может не быть никаких имен полей. Сервер не должен использовать кэшированную копию при ответе на этот запрос.
Specific end-to-end revalidation
Запрос включает в себя директиву управления кэшем "max-age=0", которая вынуждает каждый кэш вдоль пути к исходному серверу сверить свою собственную запись, если она имеются, с записью следующего кэша или сервера. Исходный запрос включает в себя требования перепроверки для текущего значениея валидатора клиента.
Unspecified end-to-end revalidation
Запрос включает в себя директиву управления кэшем "max-age=0", которая вынуждает каждый кэш вдоль пути к исходному серверу сверить свою собственную запись, с записью следующего кэша или сервера. Исходный запрос не включает в себя требований перепроверки. Первый кэш по пути (если таковой имеется), который содержит запись данного ресурса, подключает условия перепроверки со своим текущим валидатором.
Когда промежуточный кэш вынуждается с помощью директивы max-age= 0 перепроверить свои записи, присланный клиентом валидатор может отличаться от того, что записан в данный момент в кэше. В этом случае кэш может воспользоваться в своем запросе любой из валидаторов, не нарушая семантической прозрачности.
Однако выбор валидатора может влиять на результат. Наилучшим подходом для промежуточного кэша является использование в запросе своего собственного валидатора. Если сервер присылает отклик 304 (Not Modified), тогда кэш должен отправить свою уже проверенную копию клиенту со статусным кодом 200 (OK). Если сервер присылает отклик с новым объектом и валидатором кэша, промежуточный кэш должен сверить, тем не менее, полученный валидатор с тем, что прислал клиент, используя функцию сильного сравнения. Если валидатор клиента равен присланному сервером, тогда промежуточный кэш просто возвращает код 304 (Not Modified). В противном случае он присылает новый объект со статусным кодом 200 (OK).
Если запрос включает в себя директиву no-cache, в нем не должно быть min-fresh, max-stale или max-age.
В некоторых случаях, таких как периоды исключительно плохой работы сети, клиент может захотеть возвращать только те отклики, которые в данный момент находятся в памяти, и не перезагружать или перепроверять записи из исходного сервера. Для того чтобы сделать это, клиент может включить в запрос директиву only-if-cached. При получении такой директивы кэшу следует либо реагировать, используя кэшированную запись, которая соответствует остальным требованиям запроса, либо откликаться статусным кодом 504 (Gateway Timeout). Однако если группа кэшей работает как унифицированная система с хорошей внутренней коннективностью, тогда такой запрос может быть переадресован в пределах группы кэшей
Так как кэш может быть сконфигурирован так, чтобы игнорировать времена жизни, заданные сервером, а запрос клиента может содержать директиву max-stale, протокол включает в себя механизм, который позволяет серверу требовать перепроверки записей в кэше для любого последующего применения. Когда в отклике, полученном кэшем, содержится директива must-revalidate, этот кэш не должен использовать эту запись для откликов на последующие запросы без сверки ее на исходном сервере. Таким образом, кэш должен выполнить перепроверку end-to-end каждый раз, если согласно значениям Expires или max-age, кэшированный отклик является устаревшим.
Директива must- revalidate необходима для поддержания надежной работы для определенных функций протокола. При любых обстоятельствах HTTP/1.1 кэш должен выполнять директиву must-revalidate. В частности, если кэш по какой-либо причине не имеет доступа к исходному серверу, он должен генерировать отклик 504 (Gateway Timeout).
Серверы должны посылать директиву must-revalidate, тогда и только тогда, когда неудача запроса перепроверки объекта может вызвать нарушение работы системы, например, не выполнение финансовой операции без оповещения об этом. Получатели не должны осуществлять любые автоматические действия, которые нарушают эту директиву, и не должны посылать непригодную копию объекта, если перепроверка не удалась.
Хотя это и не рекомендуется, агенты пользователя, работающие в условиях очень плохой коннективности, могут нарушать эту директиву, но, если это происходит, пользователь должен быть предупрежден в обязательном порядке, что присланный отклик возможно является устаревшим. Предупреждение должно посылаться в случае каждого непроверенного доступа, при этом следует требовать подтверждения от пользователя.
Директива proxy-revalidate имеет то же значение, что и must-revalidate, за исключением того, что она не применима для индивидуальных кэшей агентов пользователя. Она может использоваться в отклике на подтвержденный запрос, чтобы разрешить кэшу пользователя запомнить и позднее прислать отклик без перепроверки (так как он был уже подтвержден однажды этим пользователем), в то же время прокси должен требовать перепроверки всякий раз при обслуживании разных пользователей (для того чтобы быть уверенным, что каждый пользователь был авторизован). Заметьте, что такие авторизованные отклики нуждаются также в директиве управления кэшем public для того, чтобы разрешить их кэширование.
13.9.5. Директива No-Transform
Разработчики промежуточных кэшей (прокси) выяснили, что полезно преобразовать тип среды для тел определенных объектов. Прокси может, например, преобразовать форматы изображения для того, чтобы сэкономить место в памяти кэша или чтобы уменьшить информационный поток в тихоходном канале. HTTP должен датировать такие преобразования, выполняемые без оповещения.
Серьезные операционные проблемы происходят, однако, когда такие преобразования производятся над телами объектов, предназначенных для определенного сорта приложений. Например, использующих медицинские изображения, предназначенные для анализа научных данных, а также тех, которые применяют авторизацию end-to-end, или требуют побитной совместимости с оригиналом.
Следовательно, если отклик содержит директиву no-transform, промежуточный кэш или прокси не должны изменять те заголовки, которые перечислены в разделе 12.5.2, так как они могут содержать директиву no-transform. Это предполагает, что кэш или прокси не должны изменять любую часть тела объекта, который имеет такие заголовки.
13.9.6. Расширения управления кэшем
Поле заголовка Cache-Control может быть расширено за счет использования одной или более лексем расширения, каждой из которых может быть присвоено определенное значение. Информационные расширения (те которые не требуют изменений в работе кэша) могут быть добавлены без изменения семантики других директив. Поведенческие расширения спроектированы для того, чтобы выполнять функции модификаторов существующих директив управления кэшем. Новые директивы и стандартные директивы устроены так, что приложения, которые не воспринимают новую директиву, по умолчанию исполнят стандартную процедуру. Те же приложения, которые распознают новую директиву, воспринимают ее как модификацию стандартной процедуры. Таким путем расширения директив управления кэшем могут быть сделаны без изменения базового протокола.
Этот механизм расширений зависит от того, выполняет ли кэш все директивы управления, определенные для базовой версии HTTP. Предполагается, что кэш реализует определенные расширения и игнорирует все директивы, которые не может распознать.
Например, рассмотрим гипотетическую, новую директиву, названную "community", которая действует как модификатор директивы "private". Мы определяем эту новую директиву так, что в дополнение к стандартным возможностям индивидуальных кэшей, кэши, которые обслуживают группу (community), могут кэшировать их отклики. Исходный сервер, желающий позволить группе "UCI" использовать частные отклики на их общем кэше, может решить эту проблему, включив директиву управления кэшем: private, community="UCI".
Кэш, получив это поле заголовка, будет действовать корректно, если даже не понимает расширение "community", так как он видит и понимает директиву "private" и, таким образом, по умолчанию обеспечит безопасное функционирование.
Не распознанная директива управления должна игнорироваться. Предполагается, что любая директива, в том числе и не узнанная кэшем HTTP/1.1, имеет по умолчанию стандартную директиву-подмену, которая обеспечивает определенный уровень функциональности, когда директива-расширение не распознается.
13.10. Соединение
Поле общего заголовка Connection позволяет отправителю специфицировать опции, которые желательны для конкретного соединения. Заголовок Connection имеет следующую грамматику:
Connection-header = "Connection" ":" 1#(connection-token)
connection-token = token
Прокси-серверы HTTP/1.1 должны выполнить разбор поля заголовка Connection, прежде чем выполнить переадресацию, и для каждой лексемы соединения в этом поле убрать любые поля заголовка в сообщении с именами, совпадающими с этими лексемами. Опции Connection отмечаются присутствием лексем соединения в поле заголовка Connection, а не какими-либо дополнительными полями заголовка, так как дополнительное поле заголовка может быть не послано, если нет параметров, ассоциированных с данной опцией соединения. HTTP/1.1 определяет опцию "close" (закрыть) для отправителя, чтобы сигнализировать о том, что соединение будет закрыто после завершения передачи отклика. Например, наличие
Connection: close
как в полях запроса, так и в полях отклика указывает на то, что соединение не следует рассматривать как "постоянное" (раздел 7.1) после завершения передачи данного запроса/отклика.
Приложения HTTP/1.1, которые не поддерживают постоянные соединения, должны содержать опцию соединения "close" в каждом сообщении.
13.11. Content-Base
Поле заголовка объекта Content-Base может быть использовано для спецификации базового URI, которое позволяет работать с относительными URL в пределах объекта. Это поле заголовка описано как Base в документе RFC 1808, который, как ожидается, будет пересмотрен.
Content-Base = "Content-Base" ":" absoluteURI
Если поле Content- Base отсутствует, базовый URI объекта определяется его Content-Location (если это Content-Location URI является абсолютным) или URI используется для инициации запроса. Заметьте, однако, что базовый URI содержимого в пределах тела объекта может быть переопределен.
13.12. Кодирование содержимого
Поле заголовка объекта Content-Encoding используется в качестве модификатора типа среды. Если это поле присутствует, его значение указывает, что тело объекта закодировано, и какой механизм декодирования следует применить, чтобы получить массив данных, ориентированный на тип среды, указанный в поле Content-Type. Поле Content-Encoding первоначально предназначалось для того чтобы архивировать документ без потери его идентичности с учетом типа среды, на которую он ориентирован.
Content-Encoding = "Content-Encoding" ":" 1#content-coding
Кодировки содержимого определены в разделе 2.5. Пример его использования приведен ниже
Content-Encoding: gzip
Content-Encoding (кодирование содержимого) является характеристикой объекта, задаваемой Request-URI. Обычно тело объекта заносится в память в закодированном виде и декодируется перед отображением или другим аналогичным использованием.
Если было применено множественное кодирование объекта, кодирование содержимого должно быть перечислено в том порядке, в котором оно было выполнено.
13.13. Язык содержимого
Поле заголовка объекта Content-Language описывает естественный язык(и) потенциальных читателей вложенного объекта. Заметьте, что это может быть совсем не эквивалентно всем языкам, использованным в теле объекта.
Content-Language = "Content-Language" ":" 1#language-tag
Языковые метки определены в разделе 2.10. Первоначальной целью поля Content-Language является предоставление пользователю возможности дифференцировать объекты согласно языковым предпочтениям. Таким образом, если содержимое тела предназначено только для аудитории, говорящей на датском языке, подходящим содержимым поля Content-Language может быть
Content-Language: da
Если поле Content- Language не задано, по умолчанию считается, что содержимое ориентировано на любую аудиторию. Это может значить, что отправитель не выделяет какой-либо естественный язык конкретно, или что отправитель не знает, какой язык предпочесть.
Список языков может быть предложен для текста, который предназначен для многоязыковой аудитории. Например, перевод "Treaty of Waitangi," представленный одновременно в оригинальной версии на маори и на английском, может быть вызван с помощью
Content-Language: mi, en
Однако только то, что в поле объекта перечислено несколько языков не означает, что объект предназначен для многоязыковой аудитории. Примером может быть языковый курс для начинающих, такой как "A First Lesson in Latin," который предназначен для англо-говорящей аудитории. В этом случае поле Content-Language должно включать только "en".
Поле Content-Language может быть применено к любому типу среды – оно не ограничено только текстовыми документами.
13.14. Длина содержимого
Содержимое поля заголовка объекта Content-Length указывает длину тела сообщения в октетах (десятичное число), посылаемое получателю, или в случае метода HEAD, размер тела объекта, который мог бы быть послан при запросе GET.
Content-Length = "Content-Length" ":" 1*DIGIT
Например
Content-Length: 3495
Приложениям следует использовать это поле для указания размера сообщения, которое должно быть послано вне зависимости от типа среды. Получатель должен иметь возможность надежно определить положение конца запроса HTTP/1.1, содержащего тело объекта, например, запрос использует Transfer-Encoding chunked или multipart body.
Любое значение Content-Length больше или равное нулю допустимо. Раздел 3.4 описывает то, как определить длину тела сообщения, если параметр Content-Length не задан.
Замечание. Значение этого поля заметно отличается от соответствующего определения в MIME, где оно является опционным, используемым в типе содержимого "message/external-body". В HTTP его следует посылать всякий раз, когда длина сообщения должна быть известна до начала пересылки.
13.15. Поле Content-Location
Поле заголовка объекта Content- Location может быть использовано для определения положения ресурса для объекта, вложенного в сообщение. В случае, когда ресурс содержит много объектов, и эти объекты в действительности имеют разные положения, по которым может быть осуществлен доступ, сервер должен предоставить поле Content-Location для конкретного варианта, который должен быть прислан. Кроме того сервер должен предоставить Content-Location для ресурса, соответствующего объекту отклика.
Content-Location = "Content-Location" ":"
( absoluteURI | relativeURI )
Если поле заголовка Content-Base отсутствует, значение Content-Location определяет также базовый URL для объекта (см. раздел 13.11).
Значение Content-Location не является заменой для исходного запрашиваемого URI, это лишь объявление положения ресурса, соответствующего данному конкретному объекту в момент запроса. Будущие запросы могут использовать Content-Location URI, если нужно идентифицировать источник конкретного объекта.
Кэш не может предполагать, что объект с полем Content-Location, отличающимся от URI, который использовался для его получения, может использоваться для откликов на последующие запросы к этому Content-Location URI. Однако Content-Location может использоваться для того, чтобы отличить объекты, полученные из одного общего, как это описано в разделе 12.6.
Если Content-Location является относительным URI, URI интерпретируется с учетом значения Content-Base URI, присланного в отклике. Если значения Content-Base не предоставлено, относительный URI интерпретируется по отношению к Request-URI.
13.16. Content-MD5
Поле заголовка объекта Content-MD5, как это определено в RFC 1864 [23], является MD5-дайджестом тела объекта для целей обеспечения проверки end-to-end целостности сообщения MIC (message integrity check). Замечание. MIC привлекательна для регистрации случайных модификаций тела объекта при транспортировке, но не является гарантией против преднамеренных действий.)
| Content | MD5 = "Content-MD5" ":" md5-digest |
| md5digest | = |
/p> Поле заголовка Content- MD5 может генерироваться исходным сервером с целью проверки целостности тел объектов. Только исходные серверы могут генерировать поле заголовка Content-MD5. Прокси и внешние шлюзы его генерировать не должны, так как это сделает невозможными проверку целостности end-to-end. Любой получатель тела объекта, включая внешние шлюзы и прокси, могут проверять то, что значение дайджеста в этом поле заголовка согласуется с полученным телом объекта.
Дайджест MD5 вычисляется на основе содержимого тела сообщения, с учетом любых кодировок содержимого, но исключая любые транспортные кодировки (Transfer-Encoding), которые могли быть использованы. Если сообщение получено в закодированном виде с использованием Transfer-Encoding, это кодирование должно быть удалено перед проверкой значения Content-MD5 для полученного объекта.
Это означает, что дайджест вычисляется для октетов тела объекта в том порядке, в каком они будут пересланы, если не используется транспортное кодирование.
HTTP расширяет RFC 1864 с тем, чтобы разрешить вычисление дайджеста для MIME-комбинации типов среды (например, multipart/* и message/rfc822), но это никак не влияет на способ вычисления дайджеста, описанного выше.
Замечание. Существует несколько следствий этого. Тело объекта для комбинированных типов может содержать много составных частей, каждая со своими собственными MIME и HTTP заголовками (включая заголовки Content-MD5, Content-Transfer-Encoding и Content-Encoding). Если часть тела имеет заголовок Content-Transfer-Encoding или Content-Encoding, предполагается, что содержимое этой части закодировано и она включается в дайджест Content-MD5 как есть. Поле заголовка Transfer-Encoding не применимо для частей тела объекта.
Замечание. Так как определение Content-MD5 является в точности тем же для HTTP и MIME (RFC 1864), существует несколько вариантов, в которых применение Content-MD5 к телам объектов HTTP отличается от случая MIME. Один вариант связан с тем, что HTTP, в отличие от MIME, не использует Content-Transfer-Encoding, а использует Transfer-Encoding и Content-Encoding. Другой - вызван тем, что HTTP чаще, чем MIME, использует двоичный тип содержимого. И, наконец, HTTP позволяет передачу текстовой информации с любым типом разрыва строк, а не только с каноническим CRLF. Преобразование всех разрывов строк к виду CRLF не должно делаться до вычисления или проверки дайджеста: тип оформления разрыва строк при расчете дайджеста должен быть сохранен.
13.17. Отрывок содержимого
Заголовок объекта Content-Range посылается с частью тела объекта и служит для определения того, где в теле объекта должен размещаться данный фрагмент. Он также указывает полный размер тела объекта. Когда сервер присылает клиенту частичный отклик, он должен описать как длину фрагмента, так и полный размер тела объекта.
| Content-Range | = "Content-Range" ":" content-range-spec |
| Content-range-spec | = byte-content-range-spec |
| byte-content-range-spec | = bytes-unit SP first-byte-pos "-" |
| entity-length | = 1*DIGIT |
Некорректной считается спецификация byte-content-range-spec, чье значение last-byte-pos меньше, чем его значение first-byte-pos, или значение длины объекта меньше или равно last-byte-pos. Получатель некорректной спецификации byte-content-range-spec должен игнорировать ее и любой текст, переданный вместе с ней. Примеры спецификации byte-content-range-spec, предполагающей, что объект содержит 1234 байт, приведены ниже:
The first 500 bytes: bytes 0-499/1234
The second 500 bytes: bytes 500-999/1234
All except for the first 500 bytes: bytes 500-1233/1234
The last 500 bytes: bytes 734-1233/1234
Когда сообщение HTTP включает в себя содержимое одного фрагмента (например, отклик на запрос одного фрагмента, или на запрос набора фрагментов, которые перекрываются без зазоров), это содержимое передается с заголовком Content-Range, а заголовок Content-Length несет в себе число действительно переданных байт. Например,
HTTP/1.1 206 Partial content
Date: Wed, 15 Nov 1995 06:25:24 GMT
Last-modified: Wed, 15 Nov 1995 04:58:08 GMT
Content-Range: bytes 21010-47021/47022
Content-Length: 26012
Content-Type: image/gif
Когда сообщение HTTP несет в себе содержимое нескольких фрагментов (например, отклик на запрос получения нескольких, не перекрывающихся фрагментов), они передаются как многофрагментное MIME-сообщение. Многофрагментный тип данных MIME используемый для этой цели, определен в этой спецификации как "multipart/byteranges". (Смотри приложение 16.2).
Клиент, который не может декодировать сообщение MIME multipart/byteranges, не должен запрашивать несколько байт-фрагментов в одном запросе.
Когда клиент запрашивает несколько фрагментов байт в одном запросе, серверу следует присылать их в порядке перечисления.
Если сервер игнорирует спецификацию byte-range-spec, из-за того, что она некорректна, сервер должен воспринимать запрос так, как если бы некорректного заголовка Range не существовало вовсе. (В норме это означает посылку отклика с кодом 200, содержащего весь объект). Причиной этого является то, что клиент может прислать такой некорректный запрос, только когда объект меньше чем объект, полученный по предыдущему запросу.
13.18. Тип содержимого
Поле заголовка объекта Content-Type указывает тип среды тела объекта, посланного получателю, или, в случае метода HEAD, тип среды, который был бы применен при методе GET.
Content-Type = "Content-Type" ":" media-type
Типы среды определены в разделе 2.7. Примером поля может служить
Content-Type: text/html; charset=ISO-8859-4
Дальнейшее обсуждение методов идентификации типа среды объекта приведено в разделе 6.2.1.
13.19. Дата
Поле общего заголовка Date представляет дату и время формирования сообщения, имеет ту же семантику, что и orig-date в RFC 822. Значение поля равно HTTP-date, как это описано в разделе 2.3.1.
Date = "Date" ":" HTTP-date
Пример
Date: Tue, 15 Nov 1994 08:12:31 GMT
Если сообщение получено через непосредственное соединение с агентом пользователя (в случае запросов) или исходным сервером (в случае откликов), дата может считаться текущей датой конца приема. Однако так как дата по определению является важной при оценке характеристик кэшированных откликов, исходный сервер должен включать поле заголовка Date в каждый отклик. Клиентам следует включать поле заголовка Date в сообщения, которые несут тело объекта запросов PUT и POST, но даже здесь это является опционным. Полученному сообщению, которое не имеет поля заголовка Date, следует присвоить дату. Это может сделать один из получателей, если сообщение будет кэшировано им, или внешним шлюзом.
Теоретически дата должна представлять момент времени сразу после генерации объекта. На практике поле даты может быть сформировано в любое время в процессе генерации сообщения.
Формат поля Date представляет собой абсолютную дату и время так, как это определено для даты HTTP в разделе 2.3. Оно должно быть послано в формате, описанном в документе RFC-1123 [8].
13.20. Поле ETag
Поле заголовка объекта ETag определяет метку объекта. Заголовки с метками объектов описаны в разделах 13.20, 13.25, 13.26 и 13.43. Метка объекта может использоваться для сравнения с другими объектами того же самого ресурса (см. раздел 12.8.2).
ETag = "ETag" ":" entity-tag
Примеры:
ETag: "xyzzy"
ETag: W/"xyzzy"
ETag: ""
13.21. Поле Expires
Поле заголовка объекта Expires содержит дату/время с момента, когда отклик может считаться устаревшим. Устаревшая запись в кэше в норме не должна посылаться кэшем (а также прокси кэшем и кэшем агента пользователя), если только она не будет сначала перепроверена с помощью исходного сервера (или с помощью промежуточного кэша, который содержит свежую копию объекта). Дальнейшее обсуждение модели контроля пригодности записей содержится в разделе 12.2. Присутствие поля Expires не предполагает, что исходный ресурс изменит или удалит объект по истечении указанного времени.
Формат абсолютной даты и времени описан в разделе 2.3. Он должен следовать рекомендациям документа RFC1123:
Expires = "Expires" ":" HTTP-date
Примером реализации формата даты может служить
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Замечание. Если отклик содержит поле Cache-Control с директивой max-age, то эта директива переписывает значение поля Expires.
Клиенты HTTP/1.1 и кэши должны рассматривать некорректные форматы даты, в особенности те, что содержат нули, как относящиеся к прошлому (то есть, как "уже истекшие").
Для того, чтобы пометить отклик, как "уже с истекшим сроком", исходный сервер должен использовать дату Expires, которая равна значению заголовка Date. (Правила вычисления времени истечения пригодности записи смотри в разделе 12.2.4.)
Для того, чтобы пометить отклик как "всегда пригодный", исходный сервер должен использовать дату Expires приблизительно на один год позже момента посылки отклика. Серверы HTTP/1.1 не должны посылать отклики с датами в поле Expires, которые устанавливают время жизни более одного года.
Присутствие поля заголовка Expires со значением даты, относящейся к будущему, означает, что они могут быть занесены в кэш, если только не указано обратного в поле заголовка Cache-Control (раздел 13.9).
13.22. Поле From
Поле заголовка запроса From (если присутствует) должно содержать интернетовский e-mail адрес пользователя. Адрес должен иметь формат, описанный в документе RFC-822 (и дополненный в RFC-1123):
From = "From" ":" mailbox
Пример:
From: webmaster@w3.org
Это поле заголовка может быть использовано для целей регистрации процедур и как средство идентификации источников некорректных и нежелательных запросов. Не следует использовать его как ненадежную систему защиты доступа. Это поле предоставляет информацию о том, кто является ответственным за метод, использованный в данном запросе. В частности, агенты-роботы должны содержать этот заголовок, так чтобы с лицом, ответственным за работу робота, можно было связаться, в случае возникновения проблем на принимающем конце.
Интернетовский e-mail адрес в этом поле может не совпадать с Интернет-адресом ЭВМ, пославшей запрос. Например, когда запрос прошел через прокси, следует использовать адрес первичного отправителя.
Замечание. Клиенту не следует посылать поле заголовка From без одобрения пользователя, так как это может вызвать конфликт с интересами конфиденциальности пользователя или нарушить политику безопасности сети отправителя. Настоятельно рекомендуется, чтобы пользователь мог дезактивировать, активировать и модифицировать значение этого поля в любое время до запроса.
13.23. Поле Host
Поле заголовка запроса Host специфицирует ЭВМ в Интернет и номер порта запрашиваемого ресурса в виде, полученном из исходного URL, который выдал пользователь или который получен из указанного ресурса (в общем случае из HTTP URL, как это описано в разделе 2.2.2). Значение поля Host должно определять положение в сети исходного сервера или шлюза, заданное исходным URL. Это позволяет исходному серверу или шлюзу различать внутренние URL, такие как корневые "/" URL сервера для ЭВМ, которым поставлен в соответствие один IP адрес.
Host = "Host" ":" host [ ":" port ] ; Раздел 2.2.2
Имя "ЭВМ" без последующего номера порта предполагает значение порта по умолчанию для заданного вида сервиса (напр., "80" для HTTP URL). Например, запрос исходного сервера должен включать в себя:
GET /pub/WWW/ HTTP/1.1
Host: www.w3.org
Клиент должен включать поле заголовка Host во все сообщения-запросы HTTP/1.1 в Интернет (т.е., в любое сообщение, соответствующее запросу URL, который включает в себя Интернет-адрес ЭВМ, услуги которой запрашиваются). Если поле Host отсутствует, прокси HTTP/1.1 должен добавить его в сообщение-запрос до того, как переадресует запрос дальше в Интернет. Все серверы HTTP/1.1, которые базируются в Интернет, должны откликаться статусным кодом 400 на любое сообщение-запрос HTTP/1.1, в котором отсутствует поле Host.
О других требованиях относительно поля Host смотри раздел 4.2 и 16.5.1.
13.24. Поле If-Modified-Sinc
Поле заголовка запроса If-Modified-Since используется с методом GET, для того чтобы сделать его условным. Если запрошенный объект не был модифицирован со времени, указанного в этом поле, объект не будет прислан сервером, вместо этого будет послан отклик 304 (not modified) без какого-либо тела сообщения.
If-Modified-Since = "If-Modified-Since" ":" HTTP-date
Пример поля:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Метод GET с заголовком If-Modified-Since и без заголовка Range требует, чтобы идентифицированный объект был передан, только в случае его модификации после даты, указанной в заголовке If-Modified-Since. Алгоритм определения этого включает в себя следующие шаги.
Если запрос приводит к чему-то отличному от статусного отклика 200 (OK), или если переданная дата If-Modified-Since некорректна, отклик будет в точности тот же, что и для обычного GET. Дата раньше текущего времени сервера является некорректной.
Если объект был модифицирован после даты If-Modified-Since, отклик будет в точности тем же, что и для обычного GET.
Если объект не был модифицирован после корректно указанной даты If-Modified-Since, сервер должен прислать отклик 304 (Not Modified).
Целью этой функции является эффективная актуализация кэшированной информации с минимальными издержками.
Заметьте, что поле заголовка запроса Range модифицирует значение If-Modified-Since. Более детально эта проблема рассмотрена в разделе 13.36.
Заметьте, что время If-Modified-Since интерпретируются сервером, чьи часы могут быть не синхронизованы с часами клиента.
Если клиент использует произвольную дату в заголовке If-Modified-Since вместо даты взятой из заголовка Last-Modified для текущего запроса, тогда клиенту следует остерегаться того, что эта дата интерпретируется согласно представлениям сервера о временной шкале. Клиенту следует учитывать не синхронность часов и проблемы округления, связанные с различным кодированием времени клиентом и сервером. Это предполагает возможность быстрого изменения условий, когда документ изменяется между моментом первого запроса и датой If-Modified-Since последующего запроса, а также возможность трудностей, связанных с относительным сбоем часов, если дата If-Modified-Since получена по часам клиента (без поправки на показания часов сервера). Поправки для различных временных базисов клиента и сервера желательно делать с учетом времени задержки в сети.
13.25. Поле If-Match
Поле заголовка запроса If-Match используется с методом, для того чтобы сделать его условным. Клиент, который имеет один или более объектов, полученных ранее из ресурса, может проверить, является ли один из этих объектов текущим, включив список связанных с ним меток в поле заголовка If-Match. Целью этой функции является эффективная актуализация кэшированной информации с минимальными издержками. Она используется также в запросах актуализации с целью предотвращения непреднамеренной модификации не той версии ресурса что нужно. Значение "*" соответствует любому текущему объекту ресурса.
If-Match = "If-Match" ":" ( "*" | 1#entity-tag )
Если какая-то метка объекта совпадает с меткой объекта, который прислан в отклике на аналогичный запрос GET (без заголовка If-Match), или если задана "*" и какой-то текущий объект существует для данного ресурса, тогда сервер может реализовать запрошенный метод, как если бы поля заголовка If-Match не существовало.
Сервер должен использовать функцию сильного сравнения (см. раздел 2.11) для сопоставления меток объекта в If-Match.
Если ни одна из меток не подходит, или если задана "*" и не существует никакого текущего объекта, сервер не должен реализовывать запрошенный метод, а должен прислать отклик 412 (Precondition Failed). Это поведение наиболее полезно, когда клиент хочет помешать актуализующему методу, такому как PUT, модифицировать ресурс, который изменился после последнего доступа к нему клиента.
Если запрос без поля заголовка If-Match выдает в результате нечто отличное от статуса 2xx, тогда заголовок If-Match должен игнорироваться.
"If-Match: *" означает, что метод должен быть реализован, если представление, выбранное исходным сервером (или кэшем, возможно с привлечением механизма Vary, см. раздел 13.43), существует, и не должен быть реализован, если выбранного представления не существует.
Запрос, предназначенный для актуализации ресурса (напр., PUT) может включать в себя поле заголовка If-Match, чтобы сигнализировать о том, что метод запроса не должен быть применен, если объект, соответствующий значению If-Match (одиночная метка объекта), не является более представлением этого ресурса. Это позволяет пользователям указывать, что они не хотят, чтобы запрос прошел успешно, если ресурс был изменен без их уведомления. Примеры:
If-Match: "xyzzy"
If-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-Match: *
13.26. Поле If-None-Match
Поле заголовка запроса If-None-Match используется для формирования условных методов. Клиент, который имеет один или более объектов, полученных ранее из ресурса, может проверить, что ни один из этих объектов не является текущим, путем включения списка их ассоциированных меток в поле заголовка If-None-Match. Целью этой функции является эффективная актуализация кэшированной информации с минимальной избыточностью. Она также используется при актуализации запросов с тем, чтобы предотвратить непреднамеренную модификацию ресурса, о существовании которого не было известно.
Значение "*" соответствует любому текущему объекту ресурса.
If-None-Match = "If-None-Match" ":" ( "*" | 1#entity-tag )
Если какая- либо метка объекта соответствует метке объекта, который был прислан в отклике на аналогичный запрос GET (без заголовка If-None-Match) или если задана "*" и существует какой-то текущий объект данного ресурса, тогда сервер не должен реализовывать запрошенный метод. Вместо этого, если методом запроса был GET или HEAD, серверу следует реагировать откликом 304 (Not Modified), включая поля заголовков объекта, ориентированные на кэш (в частности ETag). Для всех других методах запроса сервер должен откликаться статусным кодом 412 (Precondition Failed).
По поводу правил того, как определять соответствие двух меток объектов смотри раздел 12.8.3. С запросами GET и HEAD должна использоваться только функция слабого сравнения.
Если не подходит ни одна из меток объекта или если задана "*" и не существует ни одного текущего объекта, сервер может выполнить запрошенный метод так, как если бы поля заголовка If-None-Match не существовало.
Если запрос без поля заголовка If-None-Match, даст результат отличный от статусного кода 2xx, тогда заголовок If-None-Match должен игнорироваться.
"If-None-Match: *" означает, что метод не должен реализовываться, если представление, выбранное исходным сервером (или кэшем, возможно использующим механизм Vary, см. раздел 13.43), существует, и должен быть реализован, если представления не существует. Эта функция может быть полезной для предотвращения конкуренции между операциями PUT.
Примеры:
If-None-Match: "xyzzy"
If-None-Match: W/"xyzzy"
If-None-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-None-Match: W/"xyzzy", W/"r2d2xxxx", W/"c3piozzzz"
If-None-Match: *
13.27. Заголовок If-Range
Если клиент имеет частичную копию объекта в своем кэше и хочет иметь полную свежую копию объекта, он может использовать заголовок запроса Range с условным GET (используя If-Unmodified-Since и/или If-Match.) Однако если условие не выполняется, из-за того, что объект был модифицирован, клиенту следует послать второй запрос, чтобы получить все текущее содержимое тела объекта.
Заголовок If- Range позволяет клиенту заблокировать второй запрос. По существу это означает, что "если объект не изменился, следует посылать мне часть, которой у меня нет, в противном случае пришлите мене всю новую версию объекта".
If-Range = "If-Range" ":" ( entity-tag | HTTP-date )
Если клиент не имеет метки объекта, но имеет дату Last-Modified, он может использовать эту дату в заголовке If-Range. Сервер может отличить корректную дату HTTP от любой формы метки объекта, рассмотрев не более двух символов. Заголовок If-Range следует использовать только совместно с заголовком Range, и его следует игнорировать, если запрос не содержит в себе этот заголовок, или если сервер не поддерживает операции с фрагментами.
Если метка объекта, представленная в заголовке If-Range, соответствует текущей метке, тогда сервер должен обеспечить специфицированный фрагмент объекта, используя отклик 206 (Partial content). Если метка объекта не подходит, сервер должен прислать полный объект со статусным кодом 200 (OK).
13.28. Поле If-Unmodified-Since
Поле заголовка запроса If-Unmodified-Since используется для того, чтобы формировать условные методы. Если запрошенный ресурс не был модифицирован с момента, указанного в поле, сервер должен произвести запрошенную операцию, так как если бы заголовок If-Unmodified-Since отсутствовал.
Если запрошенный объект был модифицирован после указанного времени, сервер не должен выполнять запрошенную операцию и должен прислать отклик 412 (Precondition Failed).
If-Unmodified-Since = "If-Unmodified-Since" ":" HTTP-date
Примером поля может служить:
If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT
Если запрос завершается чем-то отличным от статусного кода 2xx (т.е., без заголовка If-Unmodified-Since), заголовок If-Unmodified-Since следует игнорировать. Если специфицированная дата некорректна, заголовок также игнорируется.
13.29. Поле Last-Modified
Поле заголовка объекта Last-Modified указывает на дату и время, при которых, по мнению исходного сервера, данный объект был модифицирован.
Last-Modified = "Last-Modified" ":" HTTP-date
Пример его использования
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
Точное значение этого заголовка зависит от реализации исходного сервера и природы ресурса. Для файлов, это может быть дата последней модификации файловой системы. Для объектов с динамическими встроенными частями это может время последней модификации одной из встроенных компонент. Для шлюзов баз данных это может быть метка последней модификации рекорда. Для виртуальных объектов это может быть время последнего изменения внутреннего состояния.
Исходный сервер не должен посылать дату Last-Modified, которая позже, чем время формирования сообщения сервера. В таких случаях, когда последняя модификация объекта указывает некоторое на время в будущем, сервер должен заменить дату на время формирования сообщения.
Исходный сервер должен получить значение Last-Modified объекта как можно ближе по времени к моменту генерации значения Date отклика. Это позволяет получателю выполнить точную оценку времени модификации объекта, в особенности, если объект был изменен буквально накануне формирования отклика.
Серверы HTTP/1.1 должны посылать поле Last-Modified всякий раз, когда это возможно.
13.30. Поле Location
Поле заголовка отклика Location используется для переадресации запроса на сервер, отличный от указанного в Request-URI, или для идентификации нового ресурса. В случае отклика 201 (Created), поле Location указывает на новый ресурс, созданный в результате запроса. Для откликов 3xx поле Location должно указывать предпочтительные URL сервера для автоматической переадресации на ресурс. Значение поля включает одинарный абсолютный URL.
Location = "Location" ":" absoluteURI
Например
Location: http://www.w3.org/pub/WWW/People.html
Замечание. Поле заголовка Content-Location (раздел 13.15) отличается от поля Location в том, что Content-Location идентифицирует исходное положение объекта, заключенное в запросе. Следовательно, отклик может содержать поля заголовка как Location, так и Content-Location. Требования некоторых методов изложены также в разделе 12.10.
13.31. Поле Max-Forwards
Поле заголовка запроса Max-Forwards может использоваться с методом TRACE (раздел 13.31) , чтобы ограничить число прокси или шлюзов, которые могут переадресовывать запрос. Это может быть полезным, когда клиент пытается отследить путь запроса в случае возникновения различных проблем.
Max-Forwards = "Max-Forwards" ":" 1*DIGIT
Значение Max-Forwards представляет собой целое десятичное число, которое указывает сколько еще раз запрос можно переадресовать.
Каждый прокси или шлюз получатель запроса TRACE, содержащего поле заголовка Max-Forwards, должен проверить и актуализовать его величину прежде, чем переадресовывать запрос. Если полученная величина равна нулю, получателю не следует переадресовывать запрос. Вместо этого, ему следует откликнуться как конечному получателю статусным кодом 200 (OK), содержащим полученное сообщение-запрос в качестве тела отклика (как это описано в разделе 8.8). Если полученное значение больше нуля, тогда переадресованное сообщение должно содержать актуализованное значение поля Max-Forwards (уменьшенное на единицу).
Поле заголовка Max-Forwards следует игнорировать для всех других методов определенных в данной спецификации и для всех расширений методов, для которых это не является частью определения метода.
13.32. Поле Pragma
Поле общего заголовка Pragma используется для включения специальных директив (зависящих от конкретной реализации), которые могут быть применены ко всем получателям вдоль цепочки запрос/отклик. Все директивы pragma специфицируют с точки зрения протокола опционное поведение. Однако некоторые системы могут требовать, чтобы поведение соответствовало директивам:
| Pragma | = "Pragma" ":" 1#pragma-directive |
| pragma-directive | = "no-cache" | extension-pragma |
| extension-pragma | = token [ "=" ( token | quoted-string ) ] |
Нельзя специфицировать директиву pragma для какого-то отдельного получателя. Однако любая директива pragma неприемлемая для получателя должна им игнорироваться.
Клиенты HTTP/1.1 не должны посылать заголовок запроса Pragma. Кэши HTTP/1.1 должны воспринимать "Pragma: no-cache", как если бы клиент послал "Cache-Control: no-cache". Никаких новых директив Pragma в HTTP определено не будет.
13.33. Поле Proxy-Authenticate
Поле заголовка отклика Proxy-Authenticate должно быть включено в качестве части отклика 407 (Proxy Authentication Required). Значение поля состоит из вызова, который указывает схему идентификации, и параметров, применимых в прокси для данного Request-URI.
Proxy-Authenticate = "Proxy-Authenticate" ":" challenge
Процесс авторизованного доступа HTTP описан в разделе 10. В отличие от WWW-Authenticate, поле заголовка Proxy-Authenticate применимо только к текущему соединению и не может быть передано другим клиентам. Однако, промежуточному прокси может быть нужно получить свои собственные авторизационные параметры с помощью запроса у ниже расположенного клиента, который при определенных обстоятельствах может проявить себя как прокси, переадресующий поле заголовка Proxy-Authenticate.
13.34. Поле Proxy-Authorization
Поле заголовка запроса Proxy-Authorization позволяет клиенту идентифицировать себя (или его пользователя) прокси, который требует авторизации. Значение поля Proxy-Authorization состоит из автризационных параметров, содержащих идентификационную информацию агента пользователя для прокси и/или области (realm) запрошенного ресурса.
Proxy-Authorization = "Proxy-Authorization" ":" credentials
Процесс авторизации доступа HTTP описан в разделе 10. В отличие от Authorization, поле заголовка Proxy-Authorization применимо только к следующему внешнему прокси, который требует авторизации с помощью поля Proxy-Authenticate. Когда работает несколько прокси, объединенных в цепочку, поле заголовка Proxy-Authorization используется первым внешним прокси, который предполагает получение авторизационных параметров. Прокси может передать эти параметры из запроса клиента следующему прокси, если существует механизм совместной авторизации при обслуживании данного запроса.
13.35. Поле Public
Поле заголовка отклика Public содержит список методов, поддерживаемых сервером. Задачей этого поля является информирование получателя о возможностях сервера в отношении необычных методов. Перечисленные методы могут быть, а могут и не быть применимыми к Request-URI. Поле заголовка Allow (раздел 13.7) служит для указания методов, разрешенных для данного URI.
| Public | = "Public" ":" 1#method |
Public: OPTIONS, MGET, MHEAD, GET, HEAD
Это поле заголовка применяется для серверов, непосредственно соединенных с клиентом, (т.е., ближайших соседей в цепи соединения). Если отклик проходит через прокси, последний должен либо удалить поле заголовка Public или заменить его полем, характеризующим его собственные возможности.
13.36. Фрагмент
13.36.1. Фрагменты байт
Так как все объекты HTTP в процессе передачи представляют собой последовательности байт, концепция фрагментов является существенной для любого объекта HTTP. Однако не все клиенты и серверы нуждаются в поддержке операций с фрагментами.
Спецификации байтовых фрагментов в HTTP относятся к последовательностям байт в теле объекта не обязательно то же самое что и тело сообщения.
Операция с байтовыми фрагментами может относиться к одному набору байт или к нескольким таким наборам в пределах одного объекта.
| ranges-specifier | = byte-ranges-specifier |
| byte-ranges-specifier | = byte-sunit "=" byte-range-set |
| byte-range-set | = 1#( byte-range-spec | suffix-byte-range-spec ) |
| byte-range-spec | = first-byte-pos "-" [last-byte-pos] |
| first-byte-pos | = 1*DIGIT |
| last-byte-pos | = 1*DIGIT |
Если присутствует значение last-byte-pos, оно должно быть больше или равно значению first-byte-pos в спецификации byte-range-spec, в противном случае спецификация byte-range-spec не корректна. Получатель некорректной спецификации byte-range-spec должен ее игнорировать.
Если значение last-byte- pos отсутствует, или если значение больше или равно текущей длине тела объекта, значение last-byte-pos берется на единицу меньше текущего значения длины тела объекта в байтах.
При выборе last-byte-pos, клиент может ограничить число копируемых байт, если не известна длина объекта.
suffix-byte-range-spec = "-" suffix-length
suffix-length = 1*DIGIT
Спецификация suffix-byte-range-spec используется для задания суффикса тела объекта с длиной, заданной значением suffix-length. (То есть, эта форма специфицирует последние N байтов тела объекта.) Если объект короче заданной длины суффикса, то в качестве суффикса используется все тело объекта.
Примеры значений byte-ranges-specifier (предполагается, что длина тела объекта равна 10000):
Первые 500 байтов (относительные позиции 0-499, включительно): bytes=0-499
Вторые 500 байтов (относительные позиции 500-999, включительно): bytes=500-999
Последние 500 байтов (относительные позиции 9500-9999, включительно): bytes=-500
или
bytes=9500-
Первые и последние байты (байты 0 и 9999): bytes=0-0,-1
Несколько легальных, но неканонических спецификаций вторых 500 байт (относительные позиции 500-999, включительно): bytes=500-600,601-999; bytes=500-700,601-999
13.36.2. Запросы получения фрагментов
Информационные запросы HTTP, использующие условные или безусловные методы GET могут заказывать один или более субфрагментов объекта, а не целый объект, используя заголовок запроса Range:
| Range | = "Range" ":" ranges-specifier |
Если сервер поддерживает заголовки Range и специфицированный фрагмент или фрагменты подходят для данного объекта, то:
Присутствие заголовка Range в безусловном GET допускает модификацию того, что прислано. Другими словами отклик может содержать статусный код 206 (Partial Content) вместо 200 (OK).
Присутствие заголовка Range в условном GET (запрос использует If-Modified-Since, If-None-Match, If-Unmodified-Since и/или If-Match) модифицирует то, что прислано GET в случае успешного завершения при выполнении условия (TRUE). Это не влияет на отклик 304 (Not Modified), если условие не выполнено (FALSE).
В некоторых случаях более удобно использовать заголовок If-Range (см. раздел 13.27).
Если прокси, который поддерживает фрагменты, получает запрос Range, переадресует запрос внешнему серверу и получает в ответ весь объект, ему следует прислать запрашиваемый фрагмент клиенту. Он должен запомнить весь полученный отклик в своем кэше, если отклик совместим с политикой записи в его кэш.
13.37. Поле Referer
Поле заголовка запроса Referer позволяет клиенту специфицировать (для пользы сервера) адрес (URI) ресурса, из которого был получен Request-URI. Заголовок запроса Referer позволяет серверу генерировать список обратных связей с ресурсами для интереса, ведения дневника, оптимизации кэширования и т.д.. Он позволяет также заставить работать устаревшие или дефектные связи. Поле Referer не должно посылаться, если Request-URI был получен от источника, который не имеет своего собственного URI, такого, например, как ввод с пользовательского терминала.
| Referer | = "Referer" ":" ( absoluteURI | relativeURI ) |
Referer: http://www.w3.org/hypertext/DataSources/Overview.html
Если значением поля является частичный URI, его следует интерпретировать относительно Request-URI. URI не должен включать фрагментов.
Замечание. Так как первоисточник связи может быть конфиденциальной информацией или может раскрывать другой источник частной информации, настоятельно рекомендуется, чтобы пользователь имел возможность решать, посылать поле Referer или нет. Например, клиент-броузер может иметь кнопку-переключатель для открытого или анонимного просмотра, которая управляет активацией/дезактивацией посылки информации Referer и From.
13.38. Поле Retry-After
Поле заголовка отклика Retry-After может использоваться с кодом статуса 503 (Service Unavailable) с тем, чтобы указать, как еще долго данная услуга предполагается быть недоступной для запрашивающего клиента. Значением этого поля может быть либо дата HTTP либо целое число секунд (в десятичном исчислении) после отправки отклика.
| Retry-After | = "Retry-After" ":" ( HTTP-date | delta-seconds ) |
/p> Два примера использования поля
Retry-After: Fri, 31 Dec 1999 23:59:59 GMT
Retry-After: 120
В последнем примере задержка равна двум минутам.
13.39. Поле Server
Поле заголовка отклика Server содержит информацию о программном обеспечении, используемым исходным сервером для обработки запросов. Поле может содержать коды многих продуктов (раздел 2.8), комментарии, идентифицирующие сервер, и некоторые важные субпродукты. Коды программных продуктов перечисляются в порядке важности приложений.
| Server | = "Server" ":" 1*( product | comment ) |
Server: CERN/3.0 libwww/2.17
Если отклик переадресуется через прокси, приложение прокси не должно модифицировать заголовок отклика сервера. Вместо этого ему следует включить в отклик поле Via (как это описано в разделе 13.44).
Замечание. Раскрытие конкретной версии программного обеспечения сервера может облегчить атаки против программных продуктов, для которых известны уязвимые места. Разработчикам серверов рекомендуется сделать это поле конфигурируемой опцией.
13.40. Поле Transfer-Encoding (Транспортное кодирование)
Поле общего заголовка Transfer-Encoding указывает, какой тип преобразования (если таковое использовано) применен к телу сообщения, для того чтобы безопасно осуществить передачу между отправителем и получателем. Это поле отличается от Content-Encoding тем, что транспортное кодирование является параметром сообщения, а не объекта.
Transfer-Encoding = "Transfer-Encoding" ":" 1#transfer-coding
Транспортное кодирование определено в разделе 2.6. Например:
Transfer-Encoding: chunked
Многие старые приложения HTTP/1.0 не воспринимают заголовок Transfer-Encoding.
13.41. Заголовок Upgrade (Актуализация)
Общий заголовок Upgrade позволяет клиенту специфицировать то, какие дополнительные коммуникационные протоколы он поддерживает и хотел бы использовать, если сервер найдет их подходящими. Сервер должен использовать поле заголовка Upgrade в отклике 101 (Switching Protocols) для указания того, какие протоколы активны.
| Upgrade | = "Upgrade" ":" 1#product |
/p> Например:,
Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11
Поле заголовка Upgrade предназначено для обеспечения простого механизма перехода от протокола HTTP/1.1 к некоторым другим. Это достигается путем разрешения клиенту объявлять о намерении использовать другой протокол, например, более позднюю версию HTTP с большим старшим кодом версии, даже если текущий запрос выполнен с использованием HTTP/1.1. Это облегчает переходы между несовместимыми протоколами за счет разрешения клиенту инициировать запрос в более широко поддерживаемом протоколе, в то же время, указывая серверу, что он предпочел бы использовать протокол "получше", если таковой доступен (где слово "получше" определяется сервером, возможно согласно природы метода и/или запрашиваемого ресурса).
Поле заголовка Upgrade воздействует только на переключающий протокол прикладного уровня транспортного слоя существующег соединения. Upgrade не может быть использовано для требования изменения протокола, его восприятие и использование сервером является опционным. Совместимость и природа прикладного уровня коммуникаций после смены протокола зависит исключительно от нового выбранного протокола, хотя первым действием после такой замены должен быть отклик на исходный запрос HTTP, содержащий поле заголовка Upgrade.
Поле Upgrade применимо только к текущему соединению. Следовательно, ключевое слово upgrade должно содержаться в поле заголовка Connection (раздел 13.10) всякий раз, когда поле Upgrade присутствует в сообщении HTTP/1.1.
Поле заголовка Upgrade не может использоваться для указания смены протокола в другом соединении. Для этой цели более приемлемы отклики переадресации с кодами 301, 302, 303 или 305.
Эта спецификация определяет протокол с именем "HTTP" при работе с семейством протоколов для передачи гипертекста (Hypertext Transfer Protocols), как это определено в правилах работы с версиями HTTP раздела 2.1 и для будущих усовершенствований этой спецификации. В качестве имени протокола может использоваться любая лексема, однако она будет работать, только если клиент и сервер ассоциируют это имя с одним и тем же протоколом.
13.42. Поле User-Agent (Агент пользователя)
Поле заголовка отклика User- Agent содержит информацию об агенте пользователя, инициировавшем запрос. Это нужно для целей сбора статистических данных, отслеживания нарушений протокола и автоматического распознавания агентов пользователя. Агентам пользователя рекомендуется включать это поле в запросы. Поле может содержать несколько кодов продуктов (раздел 2.8), комментарии, идентифицирующие агента и любые субпродукты, которые образуют существенную часть агента пользователя. Согласно договоренности коды программных продуктов перечисляются в порядке их важности для идентифицируемого приложения.
| User-Agent | = "User-Agent" ":" 1*( product | comment ) |
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
13.43. Поле Vary
Поле заголовка отклика Vary используется сервером для того, чтобы сигнализировать о том, что отклик выбран из числа имеющихся представлений с помощью механизма согласования под управлением сервера (раздел 11). Имена полей, перечисленные в заголовках Vary, являются такими заголовками запроса. Значение поля Vary указывает на то, что данный набор полей заголовка ограничивает пределы, в которых могут варьироваться представления, или что пределы вариации не специфицированы ("*") и, таким образом, могут модифицироваться в широких пределах для будущих запросов.
| Vary | = "Vary" ":" ( "*" | 1#field-name ) |
Набор полей заголовка, перечисленных в поле Vary известен как "выбирающие" заголовки запроса.
Когда кэш получает последующий запрос, чей Request-URI специфицирует одну или более записей кэша, включая заголовок Vary, кэш не должен использовать такую запись для формирования отклика на новый запрос. Он это должен делать, если только все заголовки, перечисленные в кэшированном заголовке Vary, присутствуют в новом запросе и все заголовки отбора предшествующих запросов совпадают с соответствующими заголовками нового запроса.
Сортирующие заголовки от двух запросов считаются соответствующими, тогда и только тогда, когда сортирующие заголовки первого запроса могут быть преобразованы в сортирующие заголовки второго запроса с помощью добавления или удаления строчных пробелов LWS (Linear White Space) в местах, где это допускается соответствующими правилами BNF (Backus-Naur Form) и/или, комбинируя несколько полей заголовка согласно требованиям на построение сообщения из раздела 3.2.
Vary "*" означает, что не специфицированные параметры, возможно отличающиеся от содержащихся в полях заголовка (напр., сетевой адрес клиента), играют роль при выборе представления отклика. Последующие запросы данного ресурса могут быть правильно интерпретированы только исходным сервером, а кэш должен переадресовать запрос (возможно условно), даже когда он имеет свежий кэшированный отклик для данного ресурса. Об использовании заголовка кэшами см. раздел 12.6.
Значение поля Vary, состоящее из списка имен полей сигнализирует о том, что представление, выбранное для отклика, базируется на алгоритме выбора, который рассматривает только значения перечисленные в поле заголовка запроса. Кэш может предполагать, что тот же выбор будет сделан для будущих запросов с теми же значениями имен полей, для периода времени, в течение которого отклик остается свежим.
Имена полей не ограничены набором стандартных полей заголовков запросов, определенных в данной спецификации. Имена полей могут быть записаны строчными или прописными буквами.
13.44. Поле Via
Поле общего заголовка Via должно быть использовано шлюзами или прокси для указания промежуточных протоколов и получателей на пути от агента пользователя к серверу, которому адресован запрос, и между исходным сервером и клиентом в случае отклика. Это аналогично полю "Received" документа RFC 822 и предназначено для использования при трассировке переадресаций сообщений, исключения петель запроса и идентификации протокольных возможностей всех отправителей вдоль цепочки запрос/отклик.
| Via | = "Via" ":" 1#( received-protocol received-by [ comment ] ) |
| received-protocol | = [ protocol-name "/" ] protocol-version |
| protocol-name | = token |
| protocol-version | = token |
| received-by | = ( host [ ":" port ] ) | pseudonym |
| pseudonym | = token |
Запись "protocol-name" является опционной, тогда и только тогда, когда это "HTTP". Поле "received-by" обычно соответствует ЭВМ и номеру порта сервера получателя или клиента, который переадресует сообщение. Однако, если настоящее имя ЭВМ считается конфиденциальной информацией, оно может быть заменено псевдонимом. Если номер порта не задан, можно предполагать, что используется значение по умолчанию для данного протокола (received-protocol).
Значения поля Via представляет каждый прокси или шлюз, который переадресовывал сообщение. Каждый получатель должен присоединить свою информацию так, что конечный результат оказывается упорядоченным согласно последовательности переадресующих приложений.
Комментарии могут быть использованы в поле заголовка Via для идентификации программ получателя прокси или шлюза аналогично полям User-Agent и Server header. Однако, все комментарии в поле Via являются опционными и могут быть удалены любым получателем перед тем, как переадресовать сообщение.
Например, сообщение- запрос может быть послано от агента пользователя HTTP/1.0 программе внутреннего прокси с именем "fred", которая использует HTTP/1.1 для того, чтобы переадресовать запрос общедоступному прокси с именем nowhere.com, который завершает процесс переадресации запроса исходному серверу www.ics.uci.edu. Запрос, полученный www.ics.uci.edu будет тогда иметь следующее поле заголовка Via:
Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1)
Прокси и шлюзы, используемые как средства сетевой защиты (firewall) не должны по умолчанию переадресовывать имена ЭВМ и портов в пределах области firewall. Эта информация может передаваться, если это непосредственно позволено. Если это не разрешено, запись "received-by" для ЭВМ в зоне действия firewall должна быть заменена соответствующим псевдонимом.
Для организаций, которые имеют жесткие требования к защите конфиденциальности и сокрытию внутренней структуры, прокси может комбинировать субпоследовательность поля заголовка Via с идентичными значениями "received-protocol" в единую запись. Например,
Via: 1.0 vanya, 1.1 manya, 1.1 dunya, 1.0 sonya
Приложениям не следует комбинировать несколько записей, если они только не находятся под единым административным контролем и имена ЭВМ уже заменены на псевдонимы. Приложения не должны комбинировать записи, которые имеют различные значения "received-protocol".
13.45. Поле Warning (Предупреждение)
Поле заголовка отклика Warning используется для переноса дополнительной информации о состоянии отклика, которая может отражать статусный код. Эта информация обычно служит для предупреждения о возможной потере семантической прозрачности из-за операций кэширования. Заголовки Warning посылаются с откликами, используя:
| Warning | = "Warning" ":" 1#warning-value |
| warning-value | = warn-code SP warn-agent SP warn-text |
| warn-code | = 2DIGIT |
| warn-agent | = ( host [ ":" port ] ) | pseudonym |
| warn-text | = quoted-string |
/p> Отклик может нести в себе более одного заголовка Warning.
Запись warn-text производится на естественном языке и с применением символьного набора, приемлемого для принимающего отклик лица. Это решение может базироваться на какой-то имеющейся информации, такой как положение кэша или пользователя, поле запроса Accept-Language, поле отклика Content-Language и т.д. Языком по умолчанию является английский, а символьным набором - ISO-8859-1.
Если используется символьный набор отличный от ISO-8859-1, он должен быть закодирован в warn-text с использованием метода, описанного в RFC-1522 [14].
Любой сервер или кэш может добавить заголовки Warning к отклику. Новые заголовки Warning должны добавляться после любых существующих заголовков Warning. Кэш не должен уничтожать какие-либо заголовки, которые он получил в отклике. Однако, если кэш успешно перепроверил запись, ему следует удалить все заголовки Warning, присоединенные ранее, за исключением специальных кодов Warning. Он должен добавить к записи новые заголовки Warning, полученные с откликом перепроверки. Другими словами заголовками Warning являются те, которые были бы получены в отклике на запрос в данный момент.
Когда к отклику подключено несколько заголовков Warning, агенту пользователя следует отображать их столько, сколько возможно, для того чтобы они появились в отклике. Если невозможно отобразить все предупреждения, агент пользователя должен следовать следующим эвристическим правилам:
Предупреждения, которые появляются в отклике раньше, имеют приоритет перед теми, что появляются позже.
Предупреждения, с предпочитаемым пользователем символьным набором имеют приоритет перед предупреждениями с другими наборами, но с идентичными warn-codes и warn-agents.
Системы, которые генерируют несколько заголовков Warning, должны упорядочить их с учетом ожидаемого поведения агента пользователя.
Далее представлен список определенных в настоящее время кодов предупреждений, каждый из которых сопровождается рекомендуемым текстом на английском языке и описанием его значения.
10 Response is stale (отклик устарел)
Должно включаться всякий раз, когда присылаемый отклик является устаревшим. Кэш может добавить это предупреждение к любому отклику, но не может удалить его до тех пор, пока не будет установлено, что отклик является свежим.
11 Revalidation failed (перепроверка пригодности неудачна)
Должно включаться, если кэш присылает устаревший отклик, потому что попытка перепроверить его пригодность не удалась, из-за невозможности достичь сервера. Кэш может добавить это предупреждение к любому отклику, но никогда не может удалить его до тех пор, пока не будет успешно проведена перепроверка пригодности отклика.
12 Disconnected operation (работа в отключенном от сети состоянии)
Следует включать, если кэш намерено отключен от остальной сети на определенный период времени.
13 Heuristic expiration (эвристическое завершение периода пригодности)
Должно включаться, если кэш эвристически выбрал время жизни больше 24 часов, а возраст отклика превышает эту величину.
14 Transformation applied (применено преобразование)
Должно добавляться промежуточным кэшем или прокси, если он использует какое-либо преобразование, изменяющее кодировку содержимого (как это специфицировано в заголовке Content-Encoding) или тип среды (как это описано в заголовке Content-Type) отклика, если только этот код предупреждения не присутствует уже в отклике.
99 Разные предупреждения
Текст предупреждения включает в себя любую информацию, которая может быть представлена человеку-оператору или может быть занесена в дневник операций. Система, получающая это предупреждение, не должна предпринимать каких-либо действий автоматически.
13.46. Поле WWW-Authenticate
Поле заголовка отклика WWW-Authenticate должно включаться в сообщения откликов со статусным кодом 401 (Unauthorized). Значение поля содержит, по крайней мере, одно требование, которое указывает на схему идентификации и параметры, применимые для Request-URI.
WWW-Authenticate = "WWW-Authenticate" ":" 1#challenge
Процесс авторизации доступа HTTP описан в разделе 10. Агенты пользователя должны проявлять особую тщательность при разборе значения поля WWW-Authenticate, если оно содержит более одного требования, или если прислан более чем одно поле заголовка WWW-Authenticate, так как содержимое требования может само содержать список параметров идентификации, элементы которого разделены запятыми.
14. Соображения безопасности
Этот раздел предназначен для того, чтобы проинформировать разработчиков приложений, поставщиков информации и пользователей об ограничениях безопасности в HTTP/1.1, как это описано в данном документе. Обсуждение не включает определенные решения данных проблем, но рассматриваются некоторые предложения, которые могут уменьшить риск.
14.1. Аутентификация клиентов
Базовая схема идентификации не предоставляет безопасного метода идентификации пользователя, не обеспечивает она и какох-либо средств защиты объектов, которые передаются открытым текстом по используемым физическим сетям. HTTP не мешает внедрению дополнительных схем идентификации и механизмов шифрования или других мер, улучшающих безопасность системы (например, SSL или одноразовых паролей).
Наиболее серьезным дефектом базового механизма идентификации является то, что пароль пользователя передается по сети в незашифрованном виде.
Так как базовая идентификация предусматривает пересылку паролей открытым текстом, она никогда не должна использоваться (без улучшения) для работы с конфиденциальной информацией.
Обычным назначением базовой идентификации является создание информационной (справочной) среды, которая требует от пользователя его имени и пароля, например, для сбора точной статистики использования ресурсов сервера. При таком использовании предполагается, что не существует никакой опасности даже в случае неавторизованного доступа к защищенному документу. Это правильно, если сервер генерирует сам имя и пароль пользователя и не позволяет ему выбрать себе пароль самостоятельно. Опасность возникает, когда наивные пользователи часто используют один и тот же пароль, чтобы избежать необходимости внедрения многопарольной системы защиты.
Если сервер позволяет пользователям выбрать их собственный пароль, тогда возникает опасность несанкционированного доступа к документам на сервере и доступа ко всем аккаунтам пользователей, которые выбрали собственные пароли. Если пользователям разрешен выбор собственных паролей, то это означает, что сервер должен держать файлы, содержащие пароли (предположительно в зашифрованном виде). Многие из этих паролей могут принадлежать удаленным пользователям. Собственник или администратор такой системы может помимо своей воли оказаться ответственным за нарушения безопасности сохранения информации.
Базовая идентификация уязвима также для атак поддельных серверов. Когда пользователь связывается с ЭВМ, содержащей информацию, защищенную с использованием базовой системой идентификации, может так получиться, что в действительности он соединяется с сервером-злоумышленником, целью которого является получение идентификационных параметров пользователя (например, имени и пароля). Этот тип атак не возможен при использовании идентификации с помощью дайджестов [32]. Разработчики серверов должны учитывать возможности такого рода атак со стороны ложных серверов или CGI-скриптов. В частности, очень опасно для сервера просто прерывать связь со шлюзом, так как этот шлюз может тогда использовать механизм постоянного соединения для выполнения нескольких процедур с клиентом, исполняя роль исходного сервера, так что это незаметно клиенту.
14.2. Предложение выбора схемы идентификации
Сервер HTTP/1.1 может прислать несколько требований с откликом 401 (Authenticate) и каждое требование может использовать разную схему. Порядок присылки требований соответствует шкале предпочтений сервера. Сервер должен упорядочит требования так, чтобы наиболее безопасная схема предлагалась первой. Агент пользователя должен выбрать первую понятную ему схему.
Когда сервер предлагает выбор схемы идентификации, используя заголовок WWW-Authenticate, безопасность может быть нарушена только за счет того, что злонамеренный пользователь может перехватить набор требований и попытаться идентифицировать себя, используя саму слабую схему идентификации. Таким образом, упорядочение служит более для защиты идентификационных параметров пользователя, чем для защиты информации на сервере.
Возможна атака MITM (man-in-the-middle – "человек в середине"), которая заключается в добавлении слабой схемы идентификации к списку выбора в надежде на то, что клиент выберет именно ее и раскроет свой пароль. По этой причине клиент должен всегда использовать наиболее строгую схему идентификации из предлагаемого списка.
Еще эффективнее может быть MITM-атака, при которой удаляется весь список предлагаемых схем идентификации, и вставляется вызов, требующий базовой схемы идентификации. По этой причине агенты пользователя, обеспокоенные таким видом атак, могут запомнить самую строгую схему идентификации, которая когда-либо запрашивалась данным сервером, и выдавать предупреждение, которое потребует подтверждения пользователя при использовании более слабой схемы идентификации. Особенно хитроумный способ реализации MITM-атаки является предложение услуг "свободного" кэширования для доверчивых пользователей.
14.3. Злоупотребление служебными (Log) записями сервера
Сервер должен оберегать информацию о запросах пользователя, о характере его интересов (такая информация доступна в дневнике операций сервера). Эта информация является, очевидно, конфиденциальной по своей природе и работа с ней во многих странах ограничена законом. Люди, использующие протокол HTTP для получения данных, являются ответственными за то, чтобы эта информация не распространялась без разрешения лиц, кого эта информация касается.
14.4. Передача конфиденциальной информации
Подобно любому общему протоколу передачи данных, HTTP не может регулировать содержимое передаваемых данных, не существует методов определения степени конфиденциальности конкретного фрагмента данных в пределах контекста запроса. Следовательно, приложения должны предоставлять как можно больше контроля провайдеру информации. Четыре поля заголовка представляют интерес с этой точки зрения: Server, Via, Referer и From. Раскрытие версии программного обеспечения сервера может привести к большей уязвимости машины сервера к атакам на программы с известными слабостями. Разработчики должны сделать поле заголовка Server конфигурируемой опцией. Прокси, которые служат в качестве сетевого firewall, должны предпринимать специальные предосторожности в отношении передачи информации заголовков, идентифицирующей ЭВМ, за пределы firewall. В частности они должны удалять или замещать любые поля Via, созданные в пределах firewall. Хотя поле Referer может быть очень полезным, его мощь может быть использована во вред, если данные о пользователе не отделены от другой информации, содержащейся в этом поле. Даже когда персональная информация удалена, поле Referer может указывать на URI частных документов, чья публикация нежелательна. Информация, посланная в поле From, может вступать в конфликт с интересами конфиденциальности пользователя или с политикой безопасности его домена, и, следовательно, она не должна пересылаться и модифицироваться без прямого разрешения пользователя. Пользователь должен быть способен установить содержимое этого поля, в противном случае оно будет установлено равным значению по умолчанию. Мы предлагаем, хотя и не требуем, чтобы предоставлялся удобный интерфейс для пользователя, который позволяет активировать и дезактивировать посылку информации полей From и Referer.
14.5. Атаки, основанные на именах файлов и проходов
Реализации исходных серверов HTTP должна быть тщательной, чтобы ограничить список присылаемых HTTP документов теми, которые определены для этого администратором сервера. Если сервер HTTP транслирует HTTP URI непосредственно в запросы к файловой системе, сервер должен следить за тем, чтобы не пересылать файлы клиентам HTTP, для этого не предназначенные. Например, UNIX, Microsoft Windows и другие операционные системы используют ".." как компоненту прохода, чтобы указать уровень каталога выше текущего. В такой системе сервер HTTP должен запретить любую подобную в Request-URI, если она позволяет доступ к ресурсу за пределами того, что предполагалось. Аналогично, файлы, предназначенные только для внутреннего использования сервером (такие как файлы управления доступом, конфигурационные файлы и коды скриптов) должны быть защищены от несанкционированного доступа, так как они могут содержать конфиденциальную информацию. Практика показала, что даже незначительные ошибки в реализации сервера HTTP могут привести к рискам безопасности.
14.6. Персональная информация
Клиентам HTTP небезразличнен доступ к некоторым данным (например, к имени пользователя, IP-адресу, почтовому адресу, паролю, ключу шифрования и т.д.). Система должна быть тщательно сконструирована, чтобы предотвратить непреднамеренную утечку информации через протокол HTTP. Мы настоятельно рекомендуем, чтобы был создан удобный интерфейс для обеспечения пользователя возможностями управления распространением такой информации.
14.7. Аспекты конфиденциальности, связанные с заголовками Accept
Заголовок запроса Accept может раскрыть информацию о пользователе всем серверам, к которым имеется доступ. В частности, заголовок Accept-Language может раскрыть информацию, которую пользователь, возможно, рассматривает как конфиденциальную. Так, например, понимание определенного языка часто строго коррелируется с принадлежностью к определенной этнической группе. Агентам пользователя, которые предлагают возможность конфигурирования содержимого заголовка Accept-Language, настоятельно рекомендуется посылать сообщение пользователю о том, что в результате может быть потеряна конфиденциальность определенных данных. Подходом, который ограничивает потерю конфиденциальности для агента пользователя, может быть отказ от посылки заголовков Accept-Language по умолчанию. Предполагается при этом каждый раз консультироваться с пользователем относительно возможности посылки этих данных серверу. Пользователь будет принимать решение о посылке Accept-Language, лишь убедившись на основании содержимого заголовка отклика Vary в том, что такая посылка существенно улучшит качество обслуживания.
Для многих пользователей, которые размещены не за прокси, сетевой адрес работающего агента пользователя может также использоваться как его идентификатор. В среде, где прокси используются для повышения уровня конфиденциальности, агенты пользователя должны быть достаточно консервативны в предоставлении опционного конфигурирования заголовков доступа конечным пользователям. В качестве крайней меры обеспечения защиты прокси могут фильтровать заголовки доступа для передаваемых запросов. Главной целью агентов пользователя, которые предоставляют высокий уровень конфигурационных возможностей, должно быть предупреждение пользователя о возможной потере конфиденциальности.
14.8. Фальсификация DNS
Клиенты, интенсивно использующие HTTP обмен со службой имен домена (Domain Name Service), обычно предрасположены к атакам, базирующимся на преднамеренном некорректном соответствии IP адресов и DNS имен. Клиенты должны быть осторожны относительно предположений, связанных с ассоциаций IP адресов и DNS имен.
В частности, клиенту HTTP следует полагаться на его сервер имен для подтверждения соответствия IP адресов и DNS имен, а не слепо кэшировать результаты предшествующих запросов. Многие платформы могут кэшировать такие запросы локально и это надо использовать, конфигурируя их соответствующим образом. Такие запросы должны кэшироваться, однако только на период, пока не истекло время жизни этой информации.
Если клиенты HTTP кэшируют результат DNS-запроса для улучшения рабочих характеристик, они должны отслеживать пригодность этих данных с учетом времени жизни, объявляемого DNS-сервером.
Если клиенты HTTP не следуют этому правилу, они могут быть мистифицированы, когда изменится IP-адрес доступного ранее сервера. Так как смена адресов в сетях будет в ближайшее время активно развиваться (Ipv6 !), такого рода атаки становятся все более вероятными.
Данное требование улучшает работу клиентов, в том числе с серверами, имеющими идентичные имена.
14.9. Заголовки Location и мистификация
Если один сервер поддерживает несколько организаций, которые не доверяют друг другу, тогда он должен проверять значения заголовков Location и Content-Location в откликах, которые формируются под управлением этих организаций. Это следует делать, чтобы быть уверенным, что они не пытаются провести какие-либо операции над ресурсами, доступ к которым для них ограничен.
16. Библиография
| [1] | Alvestrand, H., " Tags for the identification of languages", RFC 1766, UNINETT, March 1995. |
| [2] | Anklesaria, F., McCahill, M., Lindner, P., Johnson, D., Torrey, D., and B. Alberti. "The Internet Gopher Protocol: (a distributed document search and retrieval protocol)", RFC 1436, University of Minnesota, March 1993 |
| [3] | Berners-Lee, T., "Universal Resource Identifiers in WWW", A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web", RFC 1630, CERN, June 1994 |
| [4] | Berners-Lee, T., Masinter, L., and M. McCahill, "Uniform Resource Locators (URL)", RFC 1738, CERN, Xerox PARC, University of Minnesota, December 1994 |
| [5] | Berners-Lee, T., and D. Connolly, "HyperText Markup Language Specification - 2.0", RFC 1866, MIT/LCS, November 1995 |
| [6] | Berners-Lee, T., Fielding, R., and H. Frystyk, "Hypertext Transfer Protocol -- HTTP/1.0.", RFC 1945 MIT/LCS, UC Irvine, May 1996 |
| [7] | Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC 2045, Innosoft, First Virtual, November 1996. |
| [8] | Braden, R., "Requirements for Internet hosts - application and support", STD3, RFC 1123, IETF, October 1989 |
| [9] | Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC 822, UDEL, August 1982 |
| [10] | Davis, F., Kahle, B., Morris, H., Salem, J., Shen, T., Wang, R., Sui, J., and M. Grinbaum. "WAIS Interface Protocol Prototype Functional Specification", (v1.5), Thinking Machines Corporation, April 1990 |
| [11] | Fielding, R., "Relative Uniform Resource Locators", RFC 1808, UC Irvine, June 1995 |
| [12] | Horton, M., and R. Adams. "Standard for interchange of USENET messages", RFC 1036, AT&T Bell Laboratories, Center for Seismic Studies, December 1987 |
| [13] | Kantor, B., and P. Lapsley. "Network News Transfer Protocol." A Proposed Standard for the Stream-Based Transmission of News", RFC 977, UC San Diego, UC Berkeley, February 1986 |
| [14] | Moore, K., "MIME (Multipurpose Internet Mail Extensions) Part Three: Message Header Extensions for Non-ASCII Text", RFC 2047, University of Tennessee, November 1996 |
| [15] | Nebel, E., and L. Masinter. "Form-based File Upload in HTML", RFC 1867, Xerox Corporation, November 1995. |
| [16] | Postel, J., "Simple Mail Transfer Protocol", STD 10, RFC 821, USC/ISI, August 1982 |
| [17] | Postel, J., "Media Type Registration Procedure", RFC 2048, USC/ISI, November 1996 |
| [18] | Postel, J., and J. Reynolds, "File Transfer Protocol (FTP)", STD 9, RFC 959, USC/ISI, October 1985 |
| [19] | Reynolds, J., and J. Postel, "Assigned Numbers", STD 2, RFC1700, USC/ISI, October 1994 |
| [20] | Sollins, K., and L. Masinter, "Functional Requirements for Uniform Resource Names", RFC 1737, MIT/LCS, Xerox Corporation, December 1994 |
| [21] | US-ASCII. Coded Character Set - 7-Bit American Standard Code for Information Interchange. Standard ANSI X3.4-1986, ANSI, 1986 |
| [22] | ISO-8859. International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets |
| Part 1: Latin alphabet No. 1, ISO 8859-1:1987 | |
| Part 2: Latin alphabet No. 2, ISO 8859-2, 1987 | |
| Part 3: Latin alphabet No. 3, ISO 8859-3, 1988 | |
| Part 4: Latin alphabet No. 4, ISO 8859-4, 1988 | |
| Part 5: Latin/Cyrillic alphabet, ISO 8859-5, 1988 | |
| Part 6: Latin/Arabic alphabet, ISO 8859-6, 1987 | |
| Part 7: Latin/Greek alphabet, ISO 8859-7, 1987 | |
| Part 8: Latin/Hebrew alphabet, ISO 8859-8, 1988 | |
| Part 9: Latin alphabet No. 5, ISO 8859-9, 1990 | |
| [23] | Meyers, J., and M. Rose "The Content-MD5 Header Field", RFC1864, Carnegie Mellon, Dover Beach Consulting, October, 1995 |
| [24] | Carpenter, B., and Y. Rekhter, "Renumbering Needs Work", RFC 1900, IAB, February 1996. |
| [25] | Deutsch, P., "GZIP file format specification version 4.3." RFC1952, Aladdin Enterprises, May 1996 |
| [26] | Venkata N. Padmanabhan and Jeffrey C. Mogul. Improving HTTP Latency. Computer Networks and ISDN Systems, v. 28, pp. 25-35, Dec. 1995. Slightly revised version of paper in Proc. 2nd International WWW Conf. '94: Mosaic and the Web, Oct. 1994, which is available at http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/DDay/ mogul/HTTPLatency.html. |
| [27] | Joe Touch, John Heidemann, and Katia Obraczka, "Analysis of HTTP Performance", , USC/Information Sciences Institute, June 1996 |
| [28] | Mills, D., "Network Time Protocol, Version 3, Specification, Implementation and Analysis", RFC 1305, University of Delaware, March 1992 |
| [29] | Deutsch, P., "DEFLATE Compressed Data Format Specification version 1.3." RFC 1951, Aladdin Enterprises, May 1996 |
| [30] | Spero, S., "Analysis of HTTP Performance Problems" . |
| [31] | Deutsch, P., and J-L. Gailly, "ZLIB Compressed Data Format Specification version 3.3", RFC 1950, Aladdin Enterprises, Info-ZIP, May 1996 |
| [32] | Franks, J., Hallam-Baker, P., Hostetler, J., Leach, P., Luotonen, A., Sink, E., and L. Stewart, "An Extension to HTTP : Digest Access Authentication", RFC 2069, January 1997 |
/p> 16. Приложения
16.1. Интерентовский тип среды "message/http"
В дополнение к определению протокола HTTP/1.1, данный документ является спецификацией для типов среды Интернет "message/http". Ниже приведенный список является официальным для IANA.
| Media Type name: | message |
| Media subtype name: | http |
| Required parameters: | none |
| Optional parameters: | version, msgtype |
msgtype: Тип сообщения -- "запроса" или "отклика". Если отсутствует, тип может быть определен по первой строке тела сообщения.
Соображения кодирования: разрешено только "7bit", "8bit" или "binary" (двоичное).
16.2. Тип среды Интернет "multipart/byteranges"
Когда сообщение HTTP содержит несколько фрагментов (ranges) (например, отклик на запрос нескольких не перекрывающихся фрагментов), они пересылаются как многофрагментное сообщение MIME. Тип среды multipart для этих целей носит название "multipart/byteranges".
Тип среды multipart/byteranges содержит в себе две или более части, каждая из которых со своими полями Content-Type и Content-Range. Отдельные части разделяются с использованием пограничного параметра MIME.
| Media Type name: | multipart |
| Media subtype name: | byteranges |
| Required parameters: | boundary |
| Optional parameters: | none |
Например:
HTTP/1.1 206 Partial content
Date: Wed, 15 Nov 1995 06:25:24 GMT
Last-modified: Wed, 15 Nov 1995 04:58:08 GMT Content-type: multipart/byteranges; boundary=THIS_STRING_SEPARATES--THIS_STRING_SEPARATES
Content-type: application/pdf
Content-range: bytes 500-999/8000
...первый фрагмент ...
--THIS_STRING_SEPARATES
Content-type: application/pdf
Content-range: bytes 7000-7999/8000
...второй фрагмент...
--THIS_STRING_SEPARATES--
16.3. Толерантные приложения
Хотя этот документ специфицирует требования к генерации HTTP/1.1 сообщений, не все приложения будут корректны. Мы, следовательно, рекомендуем, чтобы рабочие приложения были толерантны (терпимы) к некоторым отклонениям от требований, при условии, что эти отклонения можно однозначно интерпретировать. Клиенту следует быть толерантным при разборе Status-Line, а серверу – при разборе Request-Line. В частности, им следует воспринимать любое число символов SP или HT между полями, хотя требуется только один пробел (SP). Терминатором строки полей заголовков сообщения является CRLF. Однако рекомендуется, чтобы приложение при разборе таких заголовков распознавало в качестве терминатора строки одиночный символ LF и игнорировала предыдущий символ CR. Символьный набор тела объекта должен быть снабжен меткой. Метка не нужна только для набора US-ASCII или ISO-8859-1. Правила разбора и кодирования дат и пр. включают в себя предположение, что HTTP/1.1 клиенты и кэши должны предполагать, что даты, следующие документу RFC-850 и относящиеся ко времени 50 лет в будущем, на самом деле относятся к прошлому (это помогает решить проблему "2000-го года").
Приложение HTTP/1.1 может внутри представлять время истечения годности раньше, чем истинное значение, но не должно представлять его позднее истинного значения.
Все вычисления, относящиеся ко времени пригодности должны выполняться в шкале GMT (по Гринвичу). Местные временные зоны не должны оказывать влияния на вычисления и сравнение возраста и времени пригодности.
Если заголовок HTTP несет в себе некорректное значение даты с временной зоной отличной от GMT, значение должно быть преобразовано в GMT.
16.4. Различие между объектами HTTP и MIME
HTTP/1.1 использует много конструкций, определенных для электронной почты Интернет (RFC 822) и MIME (Multipurpose Internet Mail Extensions), для обеспечения пересылки объектов в различных представлениях. MIME [7] обслуживает электронную почту, а HTTP имеет лишь ряд черт, которые отличают его от MIME. Эти отличия тщательно подобраны, чтобы оптимизировать работу в условиях двоичных соединений, с тем чтобы достичь большей свободы в использовании новых типов сред. Прокси и шлюзы должны по возможности исключать такие отличия и обеспечивать соответствующие преобразования там, где это нужно.
16.4.1. Преобразование к канонической форме
MIME требует, чтобы почтовый объект Интернет перед посылкой был преобразован в каноническую форму. Раздел 2.7.1 описывает формы, допустимые для подтипов типа среды "text" при пересылке с использованием HTTP. MIME требует, чтобы содержимое типа "text" представляло разрывы строк в виде последовательности символов CRLF и запрещает использование CR или LF отдельно. Для обозначения разрыва строки HTTP позволяет использовать CRLF, одиночный CR и одиночный LF. Всюду где возможно, прокси и шлюзы между средами HTTP и MIME должны преобразовать все разрывы строк для текстовых типов среды, как это описано в разделе 2.7.1. Заметьте однако, что это может вызвать сложности в присутствии кодирования содержимого, а также вследствие того, что HTTP допускает применение символьных наборов, которые не используют октеты 13 и 10 для представления CR и LF, так как для этих целей здесь служат многобайтовые последовательности.
16.4.2. Преобразование форматов даты
Для того чтобы упростить сравнение, HTTP/1.1 использует ограниченный набор форматов даты (раздел 2.3.1). Прокси и шлюзы должны позаботиться о преобразовании полей заголовков даты в один из допустимых форматов всякий раз, когда это необходимо (при получении данных от других протоколов).
16.4.3. Введение кодирования содержимого
MIME не содержит какого-либо эквивалента полю заголовка Content-Encoding HTTP/1.1. Так как это поле работает как модификатор типа среды, прокси и шлюзы между HTTP и MIME протоколами должны или изменить значение поля заголовка Content-Type или декодировать тело объекта, прежде чем переадресовывать сообщение. Некоторые экспериментальные приложения Content-Type для почты Интернет используют параметр типа среды ";conversions=" для выполнения операции, аналогичной Content-Encoding. Однако, этот параметр не является частью MIME.
16.4.4. No Content-Transfer-Encoding
HTTP не использует поле MIME CTE (Content-Transfer-Encoding). Прокси и шлюзы от MIME к HTTP должны удалять любую не идентичность CTE ("quoted-printable" или "base64") кодирования, прежде чем доставлять сообщение-отклик клиенту HTTP.
Прокси и шлюзы от HTTP к MIME ответственны за то, чтобы сообщения имели корректные форматы и кодировки для безопасной транспортировки, (где безопасная транспортировка определяется ограничениями используемого протокола). Такие прокси и шлюзы должны помечать информацию согласно Content-Transfer-Encoding, поступая так, мы улучшаем вероятность безопасной транспортировки с использованием протокола места назначения.
16.4.5. Поля заголовка в многофрагментных телах
В MIME, большинство полей заголовка в многофрагментных частях игнорируются, если только имя поля не начинается с "Content-". В HTTP/1.1, многофрагментные части тела могут содержать любые поля заголовков HTTP, которые имеют смысл для этой части.
16.4.6. Введение транспортного кодирования
HTTP/1.1 вводит поле заголовка Transfer-Encoding (раздел 13.40). Прокси/шлюзы должны удалять любое транспортное кодирование перед переадресацией сообщения через протокол MIME.
Процесс декодирования транспортного кода (раздел 2.6) может быть представлен в виде псевдо-программы:
length := 0
read chunk-size, chunk-ext (if any) and CRLF
while (chunk-size > 0) {
read chunk-data and CRLF
append chunk-data to entity-body
length := length + chunk-size
read chunk-size and CRLF
}
read entity-header
while (entity-header not empty) {
append entity-header to existing header fields
read entity-header
}
Content-Length := length
Remove "chunked" from Transfer-Encoding
16.4.7. MIME-Version
HTTP не является протоколом, совместимым с MIME (смотри приложение 16.4). Однако HTTP/1.1 сообщения могут включать поле общего заголовка MIME-Version, для того чтобы указать, какая версия протокола MIME была использована для конструирования сообщения. Использование заголовка поля MIME-Version отмечает, сообщение полностью соответствует протоколу MIME. Прокси/шлюзы несут ответственность за полную совместимость (где возможно), когда осуществляется передача HTTP сообщений в среду MIME.
MIME-Version = "MIME-Version" ":" 1*DIGIT "." 1*DIGIT
HTTP/1. 1 использует по умолчанию версию MIME "1.0". Однако разбор сообщений HTTP/1.1 и семантика определяются данным документом, а не спецификацией MIME.
16.5. Изменения по отношению HTTP/1.0
Этот раздел обобщает основные отличия между версиями HTTP/1.0 и HTTP/1.1.
16.5.1. Изменения с целью упрощения распределенных WWW-сервером и экономии IP адресов
Требование того, чтобы клиенты и серверы воспринимали абсолютные URI (раздел 4.1.2) и поддерживали заголовки Host, откликались кодами ошибки при отсутствии заголовка Host (раздел 13.23) в запросе HTTP/1.1, являются наиболее важными изменениями, внесенными данной спецификацией.
Более старые HTTP/1.0 клиенты предполагают однозначное соответствие IP адресов и серверов. Изменения, описанные выше, позволяют Интернет поддерживать несколько WWW узлов с помощью одного IP-адреса. Высокая скорость роста WWW-сети, большое число уже существующих серверов делают крайне важным, чтобы реализации HTTP (включая усовершенствования существующих HTTP/1.0 приложений) корректно следовали перечисленным ниже требованиям:
Как клиент, так и сервер должны поддерживать заголовки запроса Host.
Заголовки Host необходимы в запросах HTTP/1.1.
Серверы должны откликаться кодом ошибки 400 (Bad Request), если запрос HTTP/1.1 не содержит заголовка Host.
Серверы должны воспринимать абсолютные URI.
16.6. Дополнительные функции
Это приложение документирует протокольные элементы, используемые некоторыми существующими реализациями HTTP, но не вполне корректно совместимыми с большинством HTTP/1.1 приложений.
16.6.1. Дополнительные методы запросов
16.6.1.1. Метод PATCH
Метод PATCH подобен PUT, за исключением того, что объект содержит список отличий между оригинальной версией ресурса, идентифицированного Request-URI, и желательной версией ресурса после операции PATCH. Список отличий записывается в формате, определенном типом среды объекта (например, "application/diff"), и должен включать достаточную информацию, чтобы позволить серверу выполнить изменения по преобразованию ресурса из исходной версии в заказанную.
Если запрос проходит через кэш и Request-URI идентифицирует объект в кэше, этот объект должен быть удален из кэша. Отклики для этого метода не кэшируются.
Реальный метод определения того, как разместится скорректированный ресурс и что случится с его предшественником, определяется исключительно исходным сервером. Если оригинальная версия ресурса, который предполагается скорректировать, включает в себя поле заголовка Content-Version, объект запроса должен включать поле заголовка Derived-From, соответствующее значению оригинального поля заголовка Content-Version. Приложениям рекомендуется использовать эти поля для работы с версиями с целью разрешения соответствующих конфликтов. Запросы PATCH должны подчиняться требованиям к передаче сообщений, установленным в разделе 7.2. Кэши, которые реализуют PATCH, должны объявить кэшированные отклики недействительными, как это описано в разделе 12.10 для PUT.
16.6.1.2. Метод LINK
Метод LINK устанавливает один или более связей между ресурсами, идентифицированными Request-URI, и другими существующими ресурсами. Отличие между LINK и другими методами, допускающими установление связей между ресурсами, заключается в том, что метод LINK не позволяет послать в запросе любое тело сообщения и не вызывает непосредственно создания новых ресурсов. Если запрос проходит через кэш и Request-URI идентифицирует кэшированный объект, этот объект должен
быть удален из кэша. Отклики на этот метод не кэшируются. Кэши, которые реализуют LINK, должны объявить кэшированные отклики непригодными, как это определено в разделе 12.10 для PUT.
16.6.1.3. Метод UNLINK
Метод UNLINK удаляет одну или более связей между ресурсами, идентифицированными Request-URI. Эти связи могут быть установлены с использованием метода LINK или каким-либо другим методом, поддерживающим заголовок Link. Удаление связи с ресурсом не подразумевает, что ресурс перестает существовать или становится недоступным. Если запрос проходит через кэш и Request-URI идентифицирует кэшированный объект, этот объект должен быть удален из кэша. Отклики на этот метод не кэшируются. Кэши, которые реализуют UNLINK, должны объявить кэшированные отклики непригодными, как это определено в разделе 12.10 для PUT.
16.6.2. Определения дополнительных полей заголовка
16.6.2.1. Поле Alternates
Поле заголовка отклика Alternates было предложено в качестве средства исходного сервера для информирования клиента о других доступных представлениях запрошенного ресурса. При этом выдается информация об их специфических атрибутах, все это образует более надежное основание агенту пользователя для выбора представления, которое лучше соответствует желаниям пользователя (описано как согласование под управлением агента пользователя в разделе 11). Поле заголовка Alternates является ортогональным по отношению к полю заголовка Vary, вместе с тем они могут сосуществовать в сообщении без последствий для интерпретации отклика или доступных представлений. Ожидается, что поле Alternates предоставит заметное улучшение по сравнению с согласованием под управлением сервера, предоставляемым полем Vary для ресурсов, которые варьируются в общих пределах подобно типу и языку. Поле заголовка Alternates будет определено в будущей спецификации.
16.6.2.2. Поле Content-Version
Поле заголовка объекта Content-Version определяет метку версии, ассоциированную с отображением объекта. Вместе с полем Derived-From, 16.6.2.3, это позволяет группе людей вести разработку в интерактивном режиме.
Content-Version = "Content-Version" ":" quoted-string.
Примеры использования поля Content-Version:
Content-Version: "2.1.2"
Content-Version: "Fred 19950116-12:26:48"
Content-Version: "2.5a4-omega7"
16.6.2.3. Поле Derived-From
Поле заголовка объекта Derived-From может использоваться для индикации метки версии ресурса, из которого был извлечен объект до модификации, выполненной отправителем. Это поле используется для того, чтобы помочь управлять процессом эволюции ресурса, в частности, когда изменения выполняются в параллель многими субъектами.
Derived-From = "Derived-From" ":" quoted-string.
Пример использования поля:
Derived-From: "2.1.1".
Поле Derived-From необходимо для запросов PUT и PATCH, если посланный объект был перед этим извлечен из того же URI и заголовок Content-Version был включен в объект, когда он последний раз извлекался.
16.6.2.4. Поле Link
Поле заголовка объекта Link предоставляет средства для описания взаимоотношений между ресурсами. Объект может включать много значений поля Link. Связи на уровне метаинформации обычно указывают на отношения типа структуры иерархии и пути прохода. Поле Link семантически эквивалентно элементу в HTML[5].
Запись значений отношения не зависит от использования строчных или прописных букв и может быть расширена в рамках синтаксиса имен sgml. Параметр заголовка может быть использован для пометки места назначения связи, такой как используется при идентификации в рамках меню для пользователя. Параметр типа якорь может использоваться для индикации источника якоря, отличного от всего текущего ресурса, такого как фрагмент данного ресурса. Примеры использования:
Link: ; rel="Previous"
Link: ; rev="Made"; title="Tim Berners-Lee"
Первый пример указывает, что глава 2 предшествует данному ресурсу с точки зрения логического прохода. Второй указывает, что лицо, ответственное за данный ресурс, имеет приведенный адрес электронной почты.
16.6.2.5. Поле URI
Поле заголовка URI использовалось в прошлых версиях данной спецификации как комбинация существующих полей заголовка Location, Content-Location и Vary. Его первоначальной целью являлось включение списка дополнительных URI для ресурса, включая имена и положение зеркал. Однако, стало ясно, что комбинация многих различных функций в пределах одного поля мешает эффективной их реализации. Более того, мы полагаем, что идентификация имени положения зеркал лучше осуществлять через поле заголовка Link. Поле заголовка URI было признано менее удобным, чем эти поля.
URI-header = "URI" ":" 1#( "" )
16.7. Совместимость с предыдущими версиями
HTTP/1. 1 был специально спроектирован так, чтобы обеспечить совместимость с предыдущими версиями. Следует заметить, что на фазе разработки этой спецификации мы предполагали, что коммерческие HTTP/1.1 серверы будут следовать следующим правилам:
распознают формат Request-Line для запросов HTTP/0.9, 1.0 и 1.1;
воспринимают любой корректный запрос в формате HTTP/0.9, 1.0 или 1.1;
корректно откликаются сообщениями с той же версией, что использовал клиент.
Мы также ожидаем, что клиенты HTTP/1.1:
распознают формат откликов Status-Line для HTTP/1.0 и 1.1;
воспринимают любой корректный отклик в формате HTTP/0.9, 1.0 или 1.1.
Для большинства реализаций HTTP/1.0, каждое соединение устанавливается клиентом до посылки запроса и закрывается сервером после посылки отклика. Некоторые реализации используют версию Keep-Alive постоянного соединения, описанную в разделе 16.7.1.1.
16.7.1. Совместимость с постоянными соединениями HTTP/1.0
Некоторые клиенты и серверы могут пожелать быть совместимыми с некоторыми предшествующими реализациями HTTP/1.0 постоянных соединений клиента и сервера. Постоянные соединения в HTTP/1.0 должны согласовываться в явном виде, так как это не является вариантом по умолчанию. Экспериментальные реализации постоянных соединений в HTTP/1.0 не лишены ошибок. Проблема была в том, что некоторые существующие клиенты 1.0 могут посылать Keep-Alive прокси-серверу, которые не понимает Connection, и ошибочно переадресует его ближайшему серверу. Последний установит соединение Keep-Alive, что приведет к повисанию системы, так как прокси будет ждать close для отклика. В результате клиентам HTTP/1.0 должно быть запрещено использование Keep-Alive, когда они работают с прокси. Однако, взаимодействие с прокси является наиболее важным использованием постоянных соединений, по этой причине подобный запрет является не приемлемым. Следовательно, нам нужен какой-то другой механизм для индикации намерения установить постоянное соединение. Этот механизм должен быть безопасным даже при взаимодействии со старыми прокси, которые игнорируют Connection. Постоянные соединения для сообщений HTTP/1.1 работают по умолчанию; мы вводим новое ключевое слово (Connection: close) для декларации непостоянства соединения. Ниже описана оригинальная форма постоянных соединений для HTTP/1.0. Когда HTTP клиент соединяется с исходным сервером, он может послать лексему соединения Keep-Alive в дополнение к лексеме соединения Persist:
Connection: Keep-Alive.
Сервер HTTP/1.0 откликнется лексемой соединения Keep-Alive и клиент сможет установить постоянное (или Keep-Alive) соединение с HTTP/1.0. Сервер HTTP/1.1 может также установить постоянное соединение с клиентом HTTP/1.0 по получении лексемы соединения Keep-Alive. Однако, постоянное соединение с клиентом HTTP/1.0 не может быть использовано для по-фрагментного кодирования и, следовательно, должно использовать Content-Length для пометки конца каждого сообщения. Клиент не должен посылать лексему соединения Keep-Alive прокси-серверу, так как прокси-сервера HTTP/1.0 не следуют правилам HTTP/1.1 при разборе поля заголовка Connection.
16.7.1.1. Заголовок Keep-Alive
Когда лексема соединения Keep-Alive передана в рамках запроса или отклика, поле заголовка Keep-Alive может также присутствовать. Поле заголовка Keep-Alive имеет следующую форму:
Keep-Alive-header = "Keep-Alive" ":" 0# keepalive-param
keepalive-param = param-name "=" value.
Заголовок Keep-Alive является опционным и используется, если передается параметр. HTTP/1.1 не определяет каких-либо параметров. Если посылается заголовок Keep-Alive, должна быть передана соответствующая лексема соединения. Заголовок Keep-Alive без лексемы соединения должен игнорироваться.
Gopher
4.5.11 Gopher
Семенов Ю.А. (ГНЦ ИТЭФ)

GOPHER (RFC-1436) представляет собой систему для поиска и доставки документов, хранящихся в распределенных хранилищах-депозитариях. Система разработана в университете штата Миннесота (на гербе этого штата изображен хомяк, по-английски gopher). Программа Gopher предлагает пользователю последовательность меню, из которых он может выбрать интересующую его тему или статью. Объектом поиска может быть текст или двоичный файл (во многих депозитариях даже текстовые файлы хранятся в архивированном, а следовательно, двоичном виде), графический или звуковой образ. Gopher кроме того предлагает шлюзы в другие поисковые системы WWW, Wais, Archie, Whois, а также в сетевые утилиты типа telnet или FTP. Gopher может предложить больше удобств для работы с оглавлением файлов (directory), чем FTP. Для доступа в глобальную сеть Gopher использует модель клиент-сервер. Система Gopher в настоящее время устарела, многие ее серверы интегрированы в сеть WEB. Но gopher явился прототипом современных интерфейсов WWW и именно делает его интересным.
Для реализации доступа пользователь должен работать в рамках протоколов TCP/IP и иметь на своей машине программу-клиент одной из версий gopher. Существуют версии Gopher на IBM/PC (MS-DOS), VMS, UNIX, X-Windows и т.д. Многие версии публично доступны с помощью анонимного FTP в различных депозитариях, например, boombox.micro.umn.edu секция /pub/gopher. При постановке программы-клиента необходимо среди прочего указать адрес сервера-gopher. Для России можно использовать серверы (при равных условиях предпочтительнее серверы, отстоящие на меньшее число шагов; многие серверы gopher в настоящее время уже закрыты):
Большинство программ-клиентов позволяют пользователю делать "закладки" (bookmarks), которые содержат информацию о месте хранения объекта и пути доступа к нему. Закладки сохраняются и при выходе из Gopher, что облегчает продолжение поиска или нахождение объекта, найденного ранее. Набор функций программы-клиента зависит от ее конкретной реализации и от программного обеспечения ЭВМ, на которой она работает. Gopher обеспечивает простой и удобный интерфейс (лучше чем в обычном www с использованием меню, но хуже чем в MS internet explorer или netscape), позволяя работать с мышкой и предельно упрощая копирование найденных файлов.
Обычно gopher имеет также автоматическую систему поиска объектов по ключевым словам в более чем 500 меню. Это крайне важно, так как пользователь не может знать все адреса серверов. Система носит имя Veronica (Very Easy Rodent-Oriented Net-wide Indexed Computerized Archives). Ключевое слово может быть набрано строчными или заглавными буквами. Veronica-сервер возвращает результат поиска в виде gopher-меню, где содержатся записи, в текстах которых присутствуют искомые ключевые слова. Доступ к Veronica возможен либо из базового меню или из из рубрики Other gopher servers... Для того чтобы ваш сервер стал известен окружающему миру, он должен быть зарегистрирован в сервере университета Миннесоты (США) или в любом другом уже зарегистрированном сервере.
Объекты в меню обычно снабжаются символами-признаками, которые позволяют судить о типе объекта. Так, например, "<?>" означает полнотекстный индексный поиск, "/" - subdirectory, "<picture>" - указывает, что здесь хранится изображение, отсутствие какого-либо символа означает, что это текстовый файл.
Если вы располагаете рабочей версией gopher, вызов программы можно выполнить командой Gopher или, например, gopher gopher.micro.umn.edu 70. В последнем случае обращение будет произведено к конкретному серверу, имя которого указано в качестве параметра команды. Число 70 указывает на номер порта (стандартное значение для gopher). Ниже приводится пример меню gopher:
Internet gopher information client v2.0.12 information about gopher
1. about gopher.
2. search gopher news <?>
3. gopher news archive/
4. comp.infosystems.gopher (usenet newsgroup)/
5. gopher software distribution/
6. gopher protocol information/
7. university of minnesota gopher software licensing policy.
8. frequently asked questions about gopher.
9. gopher93/
10. gopher example server/
11. how to get your information into gopher.
--> 12. new stuff in gopher.
13. reporting problems or feedback.
14. big ann arbor gopher conference picture.gif <Picture>
Press ? for Help, q to Quit, u to go up a menu Page: 1/1
Выбор пункта из меню может выть выполнен мышкой, путем печатания номера соответствующей строки и последующего нажатия клавиши <Enter>, или путем движения курсора с помощью клавишей стрелок с последующим нажатием клавиши <Enter>. В приведенном выше примере курсор указывает на пункт меню с номером 12. Если в такой ситуации нажать клавишу <Enter>, обращение произойдет именно сюда. Звуковые и графические файлы имеют формат uuencode.
Существует возможность доступа к GopherMail-серверам, которые пересылают заказчику текст базового меню. GopherMail включат в себя следующие возможности (что-то вроде игры в шахматы по переписке):
Разбиение сообщений, если они слишком велики.
Деление меню на части, если его число строк слишком велико.
Повторное использование связей, записанных в файлах-закладок (bookmarks).
Запрос меню Gopher заданной ЭВМ.
Пометка выбранного пункта меню символом "X" (или Xn, где n - номер строки меню).
Запрос help-файла.
Запрос записей из архива Info-Mac.
Запрос записей Gopher с их аннотациями.
Вы можете задать предельные размеры сообщения и меню, включив в текст сообщения команды, например:
Split=25K
Menu=75
Для работы с Gopher через электронную почту вы можете выбрать ближайший GopherMail-сервер из предлагаемого списка:
| gopher@earn.net | France |
| gopher@ftp.technion.ac.il | Israel |
| gopher@join.ad.jp | Japan |
| gopher@nig.ac.jp | Japan |
| gopher@nips.ac.jp | Japan |
| gopher@solaris.ims.ac.jp | Japan |
| gophermail@ncc.go.jp | Japan |
| gopher@dsv.su.se | USA |
gopher@boombox.micro.umn.edu. При проблемах с VERONICA можно написать письмо ее разработчикам Steve Foster и Fred Barrie в университет Невады по адресу:
gophadm@futique.scs.unr.edu. Но не злоупотребляйте этим, у них есть и свои заботы.
IDEA - международный алгоритм шифрования данных
6.4.7 IDEA - международный алгоритм шифрования данных
Семенов Ю.А. (ГНЦ ИТЭФ)
IDEA является блочным алгоритмом шифрования данных, запатентованным швейцарской фирмой Ascom (http://fn2.freenet.edmonton.ab.ca/~jsavard/co0404.html). Фирма, правда, разрешила бесплатное некоммерческое использование своего алгоритма (применяется в общедоступном пакете конфиденциальной версии электронной почты PGP). Здесь в отличие от алгоритма DES не используются S-блоки или таблицы просмотра. В IDEA применяются 52 субключа, каждый длиной 16 бит. Исходный текст в IDEA делится на четыре группы по 16 бит. Для того чтобы комбинировать 16 битные коды, используется три операции: сложение, умножение и исключающее ИЛИ. Сложение представляет собой обычную операцию по модулю 65536 с переносом. При составлении таблицы умножения принимаются специальные меры для того, чтобы операция была обратимой. По этой причине вместо нуля используется код 65536. Рассмотрим алгоритм IDEA.
Пусть четыре четверти исходного текста имеют имена A, B, C и D, а 52 субключа – К(1), К(2),…, К(52). Перед реализацией алгоритма выполняются операции:
А = А*К(1); B = B + K(2); C = C + K(3); D = D * K(4);
Первый цикл вычислений включает в себя:
E = A XOR C; F = B XOR D
E = E * K(5)
F = F + E
F = F * K(6)
E = E + F
A = A XOR F
C = C XOR F
B = B XOR E
D = D XOR E
Меняем местами В и С.
Повторяем это всё 8 раз, используя К(7) – К(12) для второго раза и, соответственно, К(43) – К(48) - для восьмого. После восьмого раза В и С местами не меняются. Выполняем после этого операции:
A = A * K(49)
B = B + K(50)
C = C + K(51)
D = D * K(52)
В результате закодированный текст имеет ту же длину, что и исходный. Схема этого весьма запутанного алгоритма может быть пояснена на рис. 6.4.7.1. По своему характеру алгоритм напоминает процедуры вычисления хэш-функции.

Рис. 6.4.7.1. Схема реализации алгоритма шифрования IDEA
При дешифровке используется тот факт, что A XOR B не изменяется, если C A и B будет произведена операция XOR C использованием любого числа. Это утверждение справедливо для любых значений А и В. Операции сложения (слагаемые заменяются их дополнением по модулю 2) и умножения (множители заменяются из обратными величинами по модулю 65537) также допускают инверсию. Первые четыре ключа дешифровки (KD) определяются несколько иначе, чем остальные.
KD(1) = 1/K(49);
KD(2) = -K(50);
KD(3) = -K(51);
KD(4) = 1/K(52);
Последующие операции производятся восемь раз с добавлением 6 к индексу ключей дешифрования и вычитанием 6 из индекса ключей шифрования.
KD(5) = K(47)
KD(6) = K(48)
KD(7) = 1/K(43)
KD(8) = -K(45)
KD(9) = -K(44)
KD(10) = 1/K(46)
Субключи IDEA генерируются следующим образом. 128-битовый ключ IDEA определяет первые восемь субключей (128=8*16). Последующие ключи (44) получаются путем последовательности циклических сдвигов влево этого кода на 25 двоичных разрядов.
SKIPJACK
Skipjack – секретный в прошлом блочный алгоритм, который ассоциируется с микросхемой Clipper (описание стало открытым в июне 1989 года). Алгоритм представляет собой альтернативу решениям, предлагаемым в алгоритмах IDEA и Safer (развитие идей DES, Lucifer и Blowfish). Блок исходных данных также как и в idea разбиваются на четыре группы. Алгоритм легко реализуется на обычной ЭВМ. Skipjack включает в себя 32 цикла шифрования. Эти циклы имеют две разновидности (А и В). Цикл А выполняет следующие операции.
Первая группа бит исходного текста подвергается шифрованию с использованием G-перестановок (четырех цикличный шифр Файстела – специальный класс блочных шифров, где зашифрованный текст получается из исходного путем многократного использования одного и того же преобразования, напоминает шифр DES. Исходный текст разделяется на две части. Функция преобразования f и ключ используются для преобразования одной из половин а результат объединяется со второй частью исходного кода с помощью операции исключающее ИЛИ. После этого части меняются местами и процедура повторяется и т.д.). Для полученного результата и номера цикла (RN = 1-32) и четвертой группы исходного текста (W4) выполняется операция XOR. После этого производится перенос: W1 -> W2; W2 -> W3; W3 -> W4; W4 -> W1.
Цикл В осуществляет следующие преобразования.
Для второй группы бит исходного текста (W2) выполняется операция XOR с номером цикла и первой группой бит исходного текста (W2 = (W2 XOR RN) XOR W1). Затем первая группа блока (W1) подвергается шифрованию с использованием G-перестановок. После этого производится перенос данных: W1 -> W2; W2 -> W3; W3 -> W4; W4 -> W1.
Последовательность выполнения алгоритма Skipjack предполагает выполнение 8 циклов типа А, 8 циклов В, 6 циклов А и 8 циклов В.

Рис. 6.4.7.2. Блок-схема алгоритма шифрования Skipjack
G-перестановки включают в себя разделение группы из 16 бит на две подгруппы по 8 бит. Подобно DES левая половина кода не изменяется в процессе реализации цикла шифрования, а используется в качестве входного параметра F-функции, для результата которой и правой части кода выполняется операция XOR. В отличии от DES половины кода меняются местами лишь после завершающего цикла.
F-функция G-перестановок достаточно проста: входные данные и субключ цикла объединяются операцией XOR, а результат заменяется кодом из таблицы просмотра (lookup-таблица - F). Субключи для G имеют длину 8 бит и являются первыми четырьмя байтами 80-битового исходного ключа. Первые 4 байта используются в первом цикле, следующие 4 – во втором, последние 2 байта вместе с первыми двумя – в третьем и т.д. 12 первых циклов реализации алгоритма шифрования Skipjack показаны на рис. 6.4.7.2. Первый цикл типа А отображен вместе со схемой реализации G-функции. Для следующих 7 циклов типа А G-функция отмечена квадратиком с буквой G. Цифрами (1-12) отмечен ввод данных для цикла с соответствующим номером. При реализации F-функции используется таблица (16*16) перестановок кодов 0-255.
В случае дешифровки циклы выполняются в обратном порядке. Аналогом цикла А при дешифровке является последовательность операций:
Для групп бит W1 и W2 и номера цикла выполняется операция XOR (циклы здесь нумеруются, начиная с 32 до 1). Затем W2 подвергается обратной G-перестановке, после чего выполняется перенос: W1 -> W4; W2 -> W1; W3 -> W2; W4 -> W3. Аналог цикла типа В при дешифровке включает в себя следующие операции:
Группа бит W2 подвергается обратной G-перестановке. W3 объединяется с номером цикла и группой бит W2 с помощью операции исключающее ИЛИ. После чего производится перемещение: W1 -> W4; W2 -> W1; W3 -> W2; W4 -> W3.
Идентификатор доступа к сети
6.10 Идентификатор доступа к сети
Семенов Ю.А. (ГНЦ ИТЭФ)
Бизнесмены хотели бы предложить своим служащим пакет услуг Интернет на глобальной основе. Эти услуги могут включать помимо традиционного доступа к Интернет, также безопасный доступ к корпоративным сетям через виртуальные частные сети (VPN), используя туннельные протоколы, такие как PPTP, L2F, L2TP и IPSEC в туннельном режиме.
Для того чтобы улучшить взаимодействие роуминга и сервиса туннелирования, желательно иметь стандартизованный метод идентификации пользователей. Ниже предлагается синтаксис для идентификаторов доступа к сети NAI (Network Access Identifier). Примеры приложений, которые используют NAI, и описания семантики можно найти в [1].
Здесь используются следующие определения:
Для того чтобы обеспечить большой объем роуминга, одним из требований является способность идентифицировать “домашний” аутентификационный сервер пользователя. Эта функция в сети выполняется с помощью идентификатора NAI, посылаемого пользователем серверу NAS в процессе первичной PPP-аутентификации. Ожидается, что NAS будет использовать NAI как часть процесса открытия нового туннеля, с целью определения конечной точки этого туннеля.
Идентификатор доступа к сети имеет форму user@realm (но это не обязательно почтовый адрес). Заметьте, что в то время как пользовательская часть NAI согласуется с BNF, описанной в [5], BNF строки описания области допускает использования в качестве первого символа цифры, что не разрешено BNF, описанной в [4]. Это изменение было сделано с учетом сложившейся в последнее время практикой, FQDN, такое как 3com.com вполне приемлемо.
Заметьте, что хозяева NAS могут быть вынуждены модифицировать свое оборудование, чтобы обеспечить поддержку рассмотренного формата NAI. Оборудование, работающее с NAI должно работать с длиной кодов, по крайней мере, в 72 октета.
Формальное определение NAI
Грамматика для NAI представленная ниже, описана в ABNF, как это представлено в [7]. Грамматика для имен пользователей взята из [5], а грамматика имен областей является модифицированной версией [4].
| nai | = username / ( username "@" realm ) |
| username | = dot-string |
| realm | = realm "." label |
| label | = let-dig * (ldh-str) |
| ldh-str | = *( Alpha / Digit / "-" ) let-dig |
| dot-string | = string / ( dot-string "." string ) |
| string | = char / ( string char ) |
| char | = c / ( "\" x ) |
| let-dig | = Alpha / Digit |
| Alpha | = %x41-5A / %x61-7A ; A-Z / a-z |
| Digit | = %x30-39 ;0-9 |
| c | = < any one of the 128 ASCII characters, but not any special or SP > |
| x | = %x00-7F ; all 127 ASCII characters, no exception |
| SP | = %x20 ; Space character |
| special | = "" / "(" / ")" / "[" / "]" / "\" / "." / "," / ";" / ":" / "@" / %x22 / Ctl |
| Ctl | = %x00-1F / %x7F ; the control characters (ASCII codes 0 through 31 inclusive and 127) |
/p> Примеры правильных идентификаторов сетевого доступа:
fred@3com.com
fred@foo-9.com
fred_smith@big-co.com
fred=?#$&*+-/^smith@bigco.com
fred@bigco.com
nancy@eng.bigu.edu
eng!nancy@bigu.edu
eng%nancy@bigu.edu
Примеры неправильных идентификаторов сетевого доступа:
fred@foo
fred@foo_9.com
@howard.edu
fred@bigco.com@smallco.com
eng:nancy@bigu.edu
eng;nancy@bigu.edu
@bigu.edu
В данном разделе определено новое пространство имен, которое должно администрироваться (NAI-имена областей). Для того чтобы избежать создания каких-либо новых административных процедур, администрирование именных областей NAI возлагается на DNS.
Имена областей NAI должны быть уникальными и право их использование для целей роуминга оформляется согласно механизму, применяемому для имен доменов FQDN (fully qualified domain name). При намерении использовать имя области NAI нужно сначала послать запрос по поводу возможности применения соответствующего FQDN.
Заметьте, что использование FQDN в качестве имени области не предполагает обращения к DNS для локализации сервера аутентификации. В настоящее время аутентификационные серверы размещаются обычно в пределах домена, а маршрутизация этой процедуры базируется на локальных конфигурационных файлах. Реализации, описанные в [1], не используют DNS для поиска аутентификационного сервера в пределах домена, хотя это и можно сделать, используя запись SRV в DNS, что описано в [6]. Аналогично, существующие реализации не используют динамические протоколы маршрутизации или глобальную рассылку маршрутной информации.
Ссылки
IEEE (Маркерная шина)
4.1.3 IEEE 802.4 (Маркерная шина)
Семенов Ю.А. (ГНЦ ИТЭФ)

Стандарт IEEE 802.4 описывает свойства сетей, известных под названием маркерная шина. С точки зрения правил предоставления доступа этот стандарт схож с token ring (см. [13], а также RFC-1042 и -1230). В качестве физической среды используется 75-омный кабель. При необходимости построения сети типа дерева, а также для увеличения длины сети используются повторители. Сеть способна обеспечить пропускную способность до 10 Мбит/с при полосе пропускания кабеля 12 МГц.
Для доступа к сетевой среде станция должна получить пакет-маркер. Получив маркер, сетевое устройство может начать передачу данных, а завершив эту процедуру, устройство должно переслать маркер следующей сетевой станции. Передача маркера происходит до тех пор, пока он не достигнет младшей станции, после чего он возвращается первой станции. Формат кадра, пересылаемого по маркерной шине, имеет вид, представленный на рис. 4.1.3.1.

Рис. 4.1.3.1. Формат кадров 802.4.
SD - (Start Delimiter) - стартовый байт-разделитель =**0**000, где * - символ, кодируемый неманчестерским кодом; FC - (Frame Control) поле управления кадром = FFxxxxxx, где FF - субполе формата кадра, а xxxxxx - биты типа кадра, SA и DA адреса отправителя и получателя, соответственно. FSC - (Frame Control Sequence) контрольная сумма (4 байта). ED - (End Delimiter) оконечный разграничитель =**1**11E (правый бит является 8-ым). MMM=000 - запрос, не требующий подтверждения; MMM=001 - запрос, требующий подтверждения, MMM=010 - отклик на запрос. PPP - биты приоритета (111 - высший приоритет, а 000 - низший). Значения кодов поля FC приведены в таблицах 4.1.3.1 и 4.1.3.2 (цифрами обозначен порядок передачи разрядов).
Таблица 4.1.3.1. Коды поля FC
12
xxxxxx
345678
Назначение
Станции получают доступ к шине в результате соревновательной процедуры, называемой “окно откликов”. Окно откликов представляет собой временной интервал, равный по длительности одному системному такту, который в свою очередь равен времени распространения сигнала по шине. Это время отсчитывается от момента окончания передачи кадра управления. В течение этого времени станция-инициатор ожидает отклика от других станций. Любая станция сети, будучи владельцем маркера, может запустить этот процесс с помощью посылки кадра поиск следующей станции. Запросы на подключение осуществляются путем отправки пакета установка следующей станции, в поле данных которого записывается адрес станции, запрашивающей доступ к шине. Адрес следующей соседней станции меньше адреса станции-отправителя (маркер движется в направлении убывания адресов). Обычно посылается кадр с одним окном откликов. При этом запросы могут посылать станции с адресами не меньше, чем адрес ближайшего соседа. Если процесс инициализирован станцией с наименьшим номером, то посылается пакет с двумя окнами откликов, одно для станции с номером меньше, чем у предшественника, другое с адресом больше чем у предшественника. После этого станция ждет ответа в течение одного такта. Если ответа нет, маркер передается следующей станции. Если же получен один ответ, инициализируется подключение станции с помощью пакета установка следующей станции. При получении более одного отклика возникает конфликт, для разрешения которого посылается пакет разрешение конфликта с четырьмя окнами. Станции заносят свои запросы в окна в соответствии с первыми двумя битами своего адреса. Если попытка разрешить конфликт при этом не удалась, пакет осылается повторно. В новой попытке участвуют только станции, участвовавшие в первом раунде, а для сравнения используются уже следующие два бита адреса. Процедура может завершиться подключением одной из станций или исчерпыванием числа попыток.
Станция может отключиться от сети в любое время, но это вызовет инициализацию системы и временное нарушение работы сети. Поэтому для отключения от сети станция должна дождаться получения маркера, после чего она шлет пакет типа установка следующей станции, в поле данных которого находится адрес ее преемника. Если держатель маркера получит пакет, показывающий наличие в сети еще одного владельца маркера, он уничтожает свой маркер и переходит в режим ожидания. Получив маркер, станция должна начать передачу данных или передать его следующей станции. После передачи маркера станция в течение одного цикла прослушивает сеть, чтобы убедиться в активности своего преемника. Если преемник не посылает ничего в течении секунды, станция повторяет передачу маркера. Если и это не помогает, то посылается пакет кто следующий? с адресом преемника в поле данных и тремя окнами откликов. Если станция обнаруживает в поле данных адрес своего предшественника, она посылает кадр типа установка следующей станции по адресу отправителя. В отсутствии кадра установка следующей станции станция посылает такой пакет самой себе с двумя окнами для выявления активных сетевых устройств.
При обнаружении потери маркера запускается процедура инициализации сети, при этом посылается пакет требование маркера. Станция, пославшая запрос, прослушивает шину и при обнаружении сетевой активности выбывает из соревнования (имеется станция с большим, чем у нее адресом). В сети определено 4 класса обслуживания (6, 4, 2, 0). Станция может передавать данные класса 6 в течение допустимого времени удержания маркера THT (для класса 6). При M станций в сети максимальное время ожидания будет равно THT*M. По завершении передачи данных класса 6 (или если они не передавались вовсе) можно передавать данные класса 4. Аналогично определено время обращения маркера для классов 4, 2 и 0.
Таблица 4.1.3.2. Коды поля FC и типы кадров
Код поля FC |
Тип кадра |
Поле данных |
| 0x0 | Запрос маркера | Код арбитража |
| 0x1 | Поиск следующей станции (1 окно откликов) | Отсутствует |
| 0x2 | Поиск следующей станции (два окна откликов) | Адрес следующей станции |
| 0x3 | Кто следующий? (три окна откликов) | Отсутствует |
| 0x4 | Разрешение конфликта (4 окна откликов) | Отсутствует |
| 0x8 | Маркер | Отсутствует |
| 0xD | Установка следующей станции | Адрес следующей станции |
/p> Сети все шире внедряются в промышленность, науку, а в последнее время можно ожидать появления сетей и в наших жилищах (первые опыты по созданию информационных сетей на основе систем кабельного телевидения в США и Канаде уже успешно проведены). Для сбора измерительной информации уже более десятилетия используется магистрально-модульный стандарт GPIB (IEC-625, IEEE-488 или ГОСТ 26.003-80). Но этот стандарт ограничивает размер сети, имеет дорогостоящий интерфейс, недостаточно надежен и гибок. Применение для этой цели RS-232 не слишком перспективно, так как этот интерфейс предполагает соединение по схеме точка-точка. Возникла необходимость создания сетей с дешевой магистралью и интерфейсом с пропускной способностью 128-1024 Кбит/c. Примером такой сети можно считать CAN. Кто знает, возможно спустя несколько лет какая-то модификация этой сети будет использована для сетевого управления бытовой техникой в вашей квартире. Аппаратная реализация узлов комплексного управления бытовой техникой уже появились в продаже.
IEEE (Token Ring)
4.1.2 IEEE 802.5 (Token Ring)
Семенов Ю.А. (ГНЦ ИТЭФ)
В отличие от сетей с csma/cd доступом (например, Ethernet) в IEEE 802.5 гарантируется стабильность пропускной способности (нет столкновений). Сети Token Ring имеют встроенные средства диагностики, они более приспособлены для решения задач реального времени, но в то же время более дороги.
Маркер содержит лишь поля стартового разделителя(sdel), управления доступом (AC) и оконечного разделителя (EDEL, всего 3 байта). Если узел получил маркер, он может начать передачу информации, в противном случае он просто передает маркер следующему узлу. Каждая станция может захватить маркер на определенное время. Станция, намеревающаяся что-то передать, захватывает маркер, меняет в нем один бит, который преобразует маркер во флаг начала кадра, вносит в кадр информацию, подлежащую пересылке, и посылает его следующей станции. Передающая станция ответственна за изъятие из кольца переданных ею кадров (станция не ретранслирует собственные кадры). Введенный в сеть кадр будет двигаться по сети, пока не попадет в узел, которому он адресован и который скопирует необходимую информацию. При этом устанавливается флаг копирования (FCI), что свидетельствует об успешной доставке кадра адресату. Кадр продолжает движение, пока не попадет в узел отправитель, где он будет уничтожен. При этом проверяется, подключена ли к сети станция-адресат. Это делается путем контроля API (индикатора распознавания кадра адресатом). Сеть Token Ring идеальна для приложений, где задержка получения информации должна быть предсказуемой, и требуется высокая надежность.
Сетевые станции подключаются к MSAU, которые объединяются друг с другом, образуя кольцо. Если станция отключилась, MSAU шунтирует ее, обеспечивая проход пакетов. Стандарт Token Ring использует довольно сложную систему приоритетов, которая позволяет некоторым станциям пользоваться сетью чаще остальных. Кадры Token Ring имеют два поля, которые управляют доступом приоритет и резервирование. Только станции с приоритетом равным или выше, чем приоритет маркера, могут им завладеть. Если маркер уже захвачен и преобразован в информационный кадр, только станции с приоритетом выше, чем у станцииё отправителя, могут зарезервировать маркер на следующий цикл. Станции, которые подняли приоритет маркера, должны его восстановить после завершения передачи.
Сети Taken Ring имеют несколько механизмов для обнаружения и предотвращения влияния сетевых сбоев и ошибок. Например, пусть одна из станций выбрана в качестве активного монитора. Эта станция работает как центральный источник синхронизации для других станций сети и выполняет ряд других функций. Одной из таких функция является удаление из кольца бесконечно циркулирующих кадров (маркеров). Если отправитель ошибся, установив, например ошибочный адрес места назначения, это может привести к зацикливанию кадра. Ведь кадр может быть поврежден в пути и отправитель его уже не узнает. А это в свою очередь блокирует работу остальных станций. Активный монитор должен обнаруживать такие кадры, удалять их и генерировать новый маркер. Функции активного монитора часто выполняют MSAU. Попутно msau может контролировать, какая из станций является источником таких дефектных кадров, и вывести ее из кольца. Если станция обнаружила серьезную неполадку в сети (например, обрыв кабеля), она посылает сигнальный кадр (beacon). Такой кадр несет в себе идентификатор отправителя и имя соседа-предшественника (NAUN - nearest active upstream neighbour). Такой кадр инициализирует процедуру автореконфигурации, при которой узлы в районе аварии пытаются реконфигурировать сеть так, чтобы ликвидировать влияние поломки. Топологическая схема сети ieee 802.5 представлена на рис. 4.1.2.1.

Рис. 4.1.2.1 Топология сети Token Ring
Периферийные ЭВМ подключаются к блокам msau по схеме звезда, а сами MSAU соединены друг с другом по кольцевой схеме. Возможна реализация схемы звезда и иным способом, показанным на рис. 4.1.2.2. Здесь объединяющую функцию выполняет блок концентратора.

Рис. 4.1.2.2. Реализация Token Ring по схеме звезда
Концентратор может шунтировать каналы, ведущие к ЭВМ, с помощью специальных реле при ее отключении от питания. Аналогичную операцию может выполнить и блок msau. Управление сетью возлагаются на пять функциональных станций, определенных протоколом. Некоторые контрольные функции выполняются аппаратно, другие реализуются с помощью загружаемого программного обеспечения. Каждая из функциональных станций имеет свои логические (функциональные) адреса. Функциональные станции должны реагировать как на эти функциональные, так и на свои собственные аппаратные адреса. Ниже в таблице представлен список функциональных станций и их функциональных адресов (таблица 4.1.2.1).
Таблица 4.1.2.1 Типы и адреса функциональных станций
Функциональная станция
Адрес

Рис. 4.1.2.3. Формат информационного кадра для IEEE 802.5
В начале поля данных может размещаться LLC-заголовок, который содержит в себе 3-8 байт. Собственно этот заголовок, да поле управления кадром и отличают информационный кадр от кадра управления доступом (см. рис. 4.1.2.4).

Рис. 4.1.2.4. Формат кадра управления доступом для IEEE 802.5 (цифрами обозначены размеры полей в байтах)
Вслед за адресом отправителя следует информация управления доступом к среде. Кадры управления доступом служат исключительно для целей управления сетью и не передаются через бриджи и маршрутизаторы. Управляющая информация включает в себя основной вектор и несколько субвекторов. Основной вектор задает тип УДС-кадра (или команду) и типы (или классы) станций отправителя и получателя, всего 4 байта. Субвекторы содержат информацию об адресе соседа-предшественника, номер физического отвода кабеля и пр. (3 и более байт). На рис. 4.1.2.5. представлен формат основного вектора.

Рис. 4.1.2.5. Формат основного вектора
Субполе длина определяет полную протяженность информационного поля УДС-кадра и равна сумме длин основного вектора и всех субвекторов. Субполе класс характеризует станции отправителя и получателя. Каждой из станций выделено по 4 двоичных разряда, которые описывают типы этих станций. Ниже в таблице 4.1.2.2 представлены эти коды и их значения.
Таблица 4.1.2.2 Таблица кодов класса
| Код класса |
Функциональный тип станции |
| 0x0 | Рабочая станция кольца |
| 0x1 | Администратор канального уровня |
| 0x4 | Администратор сети или сервер конфигурации |
| 0x5 | Сервер параметров кольца |
| 0x6 | Сервер ошибок |

Рис. 4.1.2.6. Формат субвектора
Поля длина определяет длину субвектора (ведь она переменная). Поля тип содержит код типа субвектора. Поле значение хранит данные, например, код 0x0b характеризует номер отвода и т.д..
Разряды начального и конечного разделителей кадра содержат как обычные нули и единицы, так и закодированные дифференциальным манчестерским кодом. На рис. 4.1.2.7 приведен формат начального разделителя SDEL.

Рис. 4.1.2.7. Формат начального разделителя SDEL
“e” и “Н” - представляет собой единицу и нуль, закодированные манчестерским кодом. Оконечный разделитель (EDEL) имеет формат, показанный на рис. 4.1.2.8.

Рис. 4.1.2.8. Формат оконечного разделителя EDEL
Бит - индикатор промежуточного кадра (IF) равен нулю, если кадр является последним или единственным кадром в последовательности. Единица в этом бите указывает на то, что этот кадр не является последним. Бит индикатор обнаруженной ошибки (ED) устанавливается равным единице первой станцией, которая выявила ошибку в контрольной последовательности кадра (CRC). Таким образом, crc контролируется всеми станциями, через которые проходит пакет. crc - гарантирует корректность пересылке части кадра, начиная от поля управление кадром кончая полем данные. Последним полем кадра является октет состояния (рис. 4.1.2.9). Первые и последние четыре бита этого поля должны повторять друг друга, что повышает достоверность записанной там информации.

Рис. 4.1.2.9. Формат поля состояния кадра
Бит распознавания адреса
(ARI) служит в качестве флага распознавания получателем своего адреса. Если распознавание произошло, получатель перед ретрансляцией кадра далее устанавливает этот бит в единичное состояние.
Бит- индикатор копирования кадра (FCI) служит для индикации успешного копирования информации из полученного кадра. Если получатель распознал свой адрес, имеет достаточно место в буфере и благополучно скопировал туда информацию из полученного пакета, он устанавливает этот бит в единичное состояние. Биты ARI и FCI активно используются управляющими станциями кольца. Для отправителя они носят второстепенный характер, ибо решение о повторной пересылке при утере кадра принимается обычно на транспортном (более высоком) уровне. При недостатке буферного пространства в памяти станция не всегда может скопировать кадр, повторная же передача сокращает пропускную способность сети. Если же перегружающаяся станция является частью инфраструктуры сети (сервер), это может ухудшить свойства сети в целом. Улучшению ситуации может способствовать увеличение числа буферов на плате сетевого адаптера, увеличение быстродействия канала и расширения объема буферной памяти в самой ЭВМ.
Флаг начала потока (SSD - start of stream delimiter) позволяет сетевому уровню, независящему от физической среды (PMI - physical media independent) детектировать начало потока кодов. Получение неверного SSD не прерывает прием данных, а передает сигнал ошибки субуровням MAC или RMAC.
| SSD высокого приоритета: | 0101 111100 000011 |
| SSD обычного приоритета: | 0101 100000 111110 |
Правильный флаг окончания потока (ESD):
| esd высокого приоритета: | 111111 000011 000001 |
| esd обычного приоритета: | 000000 111100 111110 |
| Маркер неправильного пакета: | 110000 011111 110000 |
010101 010101 010101 010101 010101 010101 010101 010101

Рис. 4.1.2.10. Формат поля управления доступом
Поле управления доступом служит для определения приоритета кадра, это единственное поле, которое присутствует в маркере (помимо SDEL и EDEL). Субполе приоритета (PPP) указывает на приоритет маркера в 802.5. Предусмотрено восемь уровней приоритета, начиная с 000 (низший) до 111 (высший). В 802.12 здесь записывается всегда 000. Субполе бит маркера позволяет отличить обычный кадр от маркера. Для маркера поле несет в себе 0, а для кадра 1 (802.5). Так как в 100VG-anylan передаются только маркерные кадры, этот бит всегда равен 1. Бит мониторинга препятствует бесконечной циркуляции кадра по кольцу. В исходный момент все кадры и маркеры имеют этот бит равный 0. Приемник игнорирует этот бит. Биты rrr разрешают приоритетным пакетам запрашивать маркер того же уровня приоритета. Стандарт 802.12 не использует непосредственно октет управления доступом, а для обеспечения совместимости с 802.5 по умолчания записывает туда 0001000.

Рис. 4.1.2.11. Формат поля управления кадра
Значения кодов субполя тип кадра представлено в таблице 4.1.2.3, они определяют формат данных информационного поля кадра. Для обычной передачи поле равно 01000yyy.
Таблица 4.1.2.3 Коды типа кадра
Код поля типа |
Функция |
| 00 | MAC-кадр (УДС) |
| 01 | LLC-кадр (данные) |
| 1x | Резерв на будущее |
Таблица 4.1.2.4 Коды поля pcf
| Описание | Код поля pcf |
| Нормальный буфер | 0 |
| Экспресс буфер | 1 |
| Очистка кольца | 2 |
| Требование маркера | 3 |
| Аварийная сигнализация | 4 |
| Наличие активного монитора | 5 |
| Наличие резервного монитора | 6 |

Рис. 4.1.2.12. Формат адреса места назначения
I/G =0 индивидуальный адрес (I); I/G=1 групповой адрес (g).
U/L=0 универсальный адрес (U); U/L=1 локальный адрес (L).
Индивидуальный адрес
- адрес конечного узла, уникальный для данной локальной сети (в случае локального администрирования) или отличный от любого другого адреса в глобальной сети в случае универсального администрирования. Существует две разновидности индивидуального адреса: уникастный и нулевой. Уникастный адрес - индивидуальный адрес, идентифицирующий один из узлов сети. Нулевой адрес равен нулю и означает, что кадр не адресован ни одному из узлов сети. Такой адрес не может быть присвоен ни одному из оконечных узлов сети. Описываемые далее разновидности адресов используются только в полях адреса места назначения.
Групповой
адрес ассоциируется с (нулем или более) некоторым числом оконечных узлов данной сети, обычно это группа логически связанных узлов. Широковещательные и мультикастинг-адреса относятся к групповым адресам.
Широковещательный адрес подразумевает обращение ко всем узлам данной сети, такой адрес содержит 1 во всех своих разрядах. Мультикастинг-адрес подразумевает обращение к некоторой, выделенной группе адресов данной локальной сети. Существуют также функциональные адреса (FA), которые идентифицируют некоторые известные функциональные объекты с помощью групповых адресов. Формат функционального адреса представлен на рис. 4.1.2.13.

Рис. 4.1.2.13. Структура функционального адреса
Ниже приведена таблица 4.1.2.5 некоторых зарезервированных функциональных адресов.
Таблица 4.1.2.5. Зарезервированные функциональные адреса
| 6-октетный адрес (fa) | Назначение |
| С0 00 00 00 00 01 | Активный монитор |
| С0 00 00 00 00 02 | Кольцевой сервер параметров (rps) |

Рис. 4.1.2.14. Формат адреса отправителя
Субполе RII является индикатором маршрутной информации, функция субполя U/L идентична с вариантом формата адреса получателя. Если RII=1, в поле данных содержится маршрутная информация.
Формат поля маршрутной информации отображен на рис. 4.1.2.15.

Рис. 4.1.2.15. Формат поля маршрутной информации (RI)
Разновидности сетей, не использующие маршрутную информацию, берут код из субполя LTH (длина), чтобы обойти поле RI. Субполе RT (код типа маршрутизации) имеет 3 бита и говорит о том, должен ли данный кадр быть переадресован. Ниже приведена таблица (4.1.2.6) возможных значений кода rt.
Таблица 4.1.2.6. Значения кола rt
Код rt |
Описание |
| 0xx | Передача по определенному маршруту |
| 10x | Широковещательная передача по всем маршрутам |
| 11x | Широковещательная передача по одному маршруту |
Таблица 4.1.2.7. Возможные значения поля LF
| Код поля lf | Длина кадра в байтах |
| 000 | 516 |
| 001 | 1500 |
| 010 | 2052 |
| 011 | 4472 |
| 100 | 8144 |
| 101 | 11407 |
| 110 | 17800 |
При построении больших сетей token ring приходится использовать большое число колец. Отдельные кольца связываются друг с другом, как и в других сетях, с помощью мостов (рис. 4.1.2.16). Мосты бывают “прозрачными” (IEEE 802.1d) и с маршрутизацией от источника. Последние позволяют связать в единую сеть несколько колец, использующих общий сетевой IPX- или IP-адрес.

Рис. 4.1.2.16 Соединение колец с помощью прозрачного моста
Использование мостов позволяет преодолеть и ограничение на число станций в сети (260 для спецификации ibm и 255 для IEEE). Мосты могут связывать между собой фрагменты сетей, использующих разные протоколы, например, 802.5, 802.4 и 802.3. Пакеты из кольца 1 адресованные объекту этого же кольца никогда не попадут в кольцо 2 и наоборот. Через мост пройдут лишь пакеты, адресованные объектам соседнего кольца. Фильтрация пакетов осуществляется по физическому адресу и номеру порта. На основе этих данных формируется собственная база данных, содержащая информацию об объектах колец, подключенных к мосту. Схема деления сети с помощью мостов может способствовать снижению эффективной загрузки сети.
Мосты с маршрутизацией от источника могут объединять только сети token ring, а маршрутизация пакетов возлагается на все устройства, посылающие информацию в сеть (отсюда и название этого вида мостов). Это означает, что в каждом из сетевых устройств должно быть загружено программное обеспечение, позволяющее маршрутизировать пакеты от отправителя к получателю (в случае netware это route.com). Эти мосты не создают собственных баз данных о расположении сетевых объектов и посылают пакет в соседнее кольцо на основе маршрутного указания, поступившего от отправителя самого пакета. Таким образом, база данных о расположении сетевых объектов оказывается распределенной между станциями, хранящими собственные маршрутные таблицы. Программы маршрутизации используют сетевой драйвер адаптера. Мосты с маршрутизацией от источника просматривают все поступающие кадры и отбирают те, которые имеют индикатор информации о маршруте RII=1. Такие кадры копируются, и по информации о маршруте определяется, следует ли их посылать дальше. Мосты с маршрутизацией от источника могут быть настроены на широковещательную передачу по всем маршрутам, либо на широковещательную передачу по одному маршруту. Формат информации о маршруте показан на рис. 4.1.2.15.
В сетях со сложной топологией маршруты формируются согласно иерархическому протоколу STP (spanning tree protocol). Этот протокол организует маршруты динамически с выбором оптимального маршрута, если адресат достижим несколькими путями. При этом минимизируется транзитный трафик. Для решения задачи мосты обмениваются маршрутной информацией. Формат этих пакетов показан на рис. 4.1.2.17.

Рис. 4.1.2.17. Формат кадра маршрутных данных, рассылаемых мостом
Поле идентификатор протокола характеризует используемый мостом протокол (для STP это код равен 0x000). Поле версия протокола хранит текущую версию протокола. Поле тип протокольного блока данных моста может принимать следующие значения:
| 0x00 | протокольный блок данных моста конфигурации; |
| 0x80 | протокольный блок данных моста объявления об изменении топологии. |
| 0x01 | флаг изменения топологии; |
| 0x80 | флаг подтверждения изменения топологии. |
Длина поля данных ограничивается временем, на которое станция может захватить маркер и не превышает 4502 октетов. Поле CRC служит для контроля целостности кадра при транспортировке. При расчете CRC используется образующий полином вида:
x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1
Алгоритм вычисления аналогичен тому, что используется в сетях Ethernet, контрольное суммирование охватывает поля адрес места назначения, адрес отправителя, управление кадром, маршрутная информация и данные.
Стартовый разделитель должен иметь уникальную сигнатуру, которая не может встретиться ни в одном из последующих полей. Оконечный разделитель нужен для того, чтобы обозначить конец кадра (или маркера), ведь длина пакетов переменна.
На физическом сетевом уровне используется дифференциальный манчестерский код с уровнями сигналов положительной и отрицательной полярности в диапазоне 3,0-4,5 В (сравните с +0,85 и -0,85 В для IEEE 802.3).
Имена временных зон
10.22 Имена временных зон
Семенов Ю.А. (ГНЦ ИТЭФ)
Временная зона
Сокращение
Интегрированные сети ISDN
4.3.3 Интегрированные сети ISDN
Семенов Ю.А. (ГНЦ ИТЭФ)
Ожидается, что к 2000 году в США будет 10000000 пользователей ISDN. Число же телефонных аппаратов в мире приближается к миллиарду. Существует около 10 разновидностей протоколов ISDN (national ISDN-1 (США); at&t custom; euro-ISDN (Net3) и т.д.
ISDN предполагает, что по телекоммуникационным каналам передаются цифровые коды, следовательно аналоговые сигналы в случае телефона или факса должны быть преобразованы соответствующим образом, прежде чем их можно будет передать. При передаче цифровых сигналов используется кодово-импульсная модуляция (cм. раздел
“Преобразование, кодирование и передача информации”), впервые примененная во время второй мировой войны. Широкое внедрение этого метода передачи относится к началу 60-х годов.
Чтобы обеспечить пропускную способность 64 Кбит/с по имеющимся телефонным проводам, не нарушая теоремы Шеннона, надо ставить ретрансляторы на расстоянии 2 км друг от друга (ведь ослабление сигнала в стандартном кабеле составляет около 15дБ/км). Последние достижения в телекоммуникационных технологиях существенно ослабили это ограничение.). Унификация скоростей передачи данных в ISDN способствует уменьшению объема оборудования, так как исключает необходимость межсетевых интерфейсов, согласующих быстродействие отдельных частей сети. Одной из наиболее массовых приложений ISDN является цифровая телефония. Человеческий голос можно удовлетворительно закодировать, используя лишь 6 бит, но вариации уровня входного сигнала приводит к тому, что нужно не менее 8 бит (с учетом логарифмической характеристики аналого-цифрового преобразователя - АЦП). Значения кодов, полученных в результате последовательных преобразований звука человеческой речи, сильно коррелированны, а это открывает дополнительные возможности для сжатия информации.
Сети ISDN дали толчок развитию сетевой технологии. На очереди интеграция Интернет с кабельным телевидением, а там, глядишь, появятся квартирные сети, объединяющие телевизор, ЭВМ, бытовую технику и телефон. Это неудивительно, когда цена хорошего телевизора почти сравнялась с ценой персональной ЭВМ, а многие бытовые устройства имеют встроенные процессоры. Здесь должно быть решено несколько проблем. С одной стороны телевизионные кабели имеют полосу пропускания достаточную для передачи как аналогового (заведомо более 10 каналов), так и цифрового телевидения. Проблема возникает при совмещении передачи телевизионного сигнала и цифрового (или PCM) канала Интернет (кабельные модемы пока достаточно дороги). Современные телевизионные системы обеспечивают порядка 50 каналов одновременно, что накладывает весьма жесткие требования на кабельную разводку между локальным распределительным узлом и оконечными пользователями. Распределительные узлы сегодня объединяются с помощью ATM-каналов (~150 Мбит/с, широкополосный ISDN), что уже сегодня недостаточно. По мере удешевления можно ожидать, что в ближайшем будущем в квартиры конечных пользователей будет осуществлен ввод оптоволоконных кабелей, что решит проблему радикально (не нужен не только телевизионный, но и телефонный кабель). Попутно это решит проблему и видеотелефона. На очереди разработка новых стандартов, которые позволят осуществить такую интеграцию.
Так как первоначально ISDN создавалась для передачи голоса и изображения (факс), начнем именно с этих приложений. Для факсов сети ISDN особенно привлекательны, так как может обеспечить высокое разрешение (до 16 линий/мм и лучше) при разумном времени передачи.
Для иллюстрации взаимодействия различных частей ISDN рассмотрим рис. 4.3.3.1.
4.3.3.1 Традиционная схема сети ISDN
Network termination 1 (NT-1) представляет собой прибор, который преобразует 2-проводную ISDN-линию (от телефонной компании), называемую u-интерфейсом, в 8-проводный S/T-интерфейс. Как правило, к точке Т может быть подключено только одно оконечное устройство. NT2 же предназначено для подключения большого числа разнотипного оборудования (функции NT1 и NT2 могут быть совмещены в одном приборе). Допускается объединение интерфейсов NT2 и TA; возможна работа нескольких NT1 с одним NT2. Интерфейс NT2 может обеспечивать внутриофисный трафик, образуя шину, к которой может подключаться несколько терминалов. Терминальное оборудование (TE) в режиме точка-точка может быть подключено к системе кабелем длиной до 1 км, реальным ограничением служит ослабление в 6 дБ на частоте 96 кГц. В режиме точка-мультиточка (до 8 терминалов) подсоединение производится параллельно, но длина шины в этом случае не должна превышать 200 м (по временным ограничениям). Терминалы, чтобы не вносить искажений, должны иметь входное сопротивление не ниже 2500 Ом. Шина согласуется 100 омным сопротивлением, как со стороны NT1, так с противоположного удаленного конца (это справедливо для принимающих и передающих пар проводов). Оборудование, следующее рекомендациям ISDN, может подключаться в точках S и T. Схемы кабелей, объединяющих интерфейсы ISDN с оконечным оборудованием, показаны на рис. 4.3.3.2.

Рис. 4.3.3.2. Кабели и разъемы в каналах ISDN
Точки s и t обеспечивают доступ к канальным услугам ISDN. В точке R (на рис. 4.3.3.2 TA - терминальный адаптер), в зависимости от типа терминального адаптера, доступны некоторые другие стандартные CCITT услуги (X.21 или X.25, V.35, RS-232 или V.24). Входы TE1 и TE2 предназначены для удаленных телекоммуникационных услуг. Все виды услуг могут быть разделены на три группы по форме доступа к 64кбит/с:
Услуги, для которых меняется лишь скорость исполнения (например, файловый обмен или электронная почта).
Принципиально новые услуги, которые недоступны при низких скоростях обмена, например, факсимильная передача со скоростью 3-4 секунды на страницу (против 20-30 сек при низких скоростях); видеотекст (напр., Prestel в Англии, Minitel во Франции или Bildschirmtext в Германии).
Услуги, абсолютно невозможные при скоростях ниже 64кб/с. Например, видеотелефон или высококачественная передача звука (G.722; ADPCM - adaptive differential pulse code modulation). Телефония часто использует каналы со скоростью передачи 32кбит/с (G.721). Полоса звукового сигнала равна 50 Гц - 20 кГц.
Эталонная конфигурация системы передачи и приема сигналов, а также подачи питания на терминальное оборудование показана на рис. 4.3.3.3. Передаваемая по проводам мощность составляет 1-0.5 Вт. Дополнительная пара проводов питания является в настоящее время опционной.

Рис. 4.3.3.3 Эталонная конфигурация системы передачи и приема сигналов, а также подачи питания на терминальное оборудование
(*) Относится к полярности кадровых сигналов. (**) относится к полярности питающего напряжения. Используется напряжение питания V= 40 v, которое (если требуется для питания управляющей электроники) преобразуется в 5 В.
Логика взаимодействия различных частей сети isdn показана на рис. 4.3.3.4.

Рис. 4.3.3.4 Взаимодействие основных протоколов ISDN
Процессом передачи информации между узлами управляет сигнальная система общего канала (CCS - common channel signaling system). В ISDN используется 7-я сигнальная система CCITT (рис. 4.3.1.1). Ее уровни сходны, но не идентичны OSI. На нижних уровнях используется MTP (message transfer part - система передачи сообщений), задачей которой является надежная пересылка сигнальных пакетов по сети. Пользовательские (прикладные) сообщения иерархически расположены над MTP, которая имеет три уровня.
Терминальное оборудование подключается к NT через трансформатор (см. рис. 4.3.3.5). На входе трансиверов используются схемы защиты от переходных процессов в линиях связи.

Рис. 4.3.3.5 Терминальный ISDN-интерфейс
Нормальная амплитуда сигнала составляет 750 мВ. Формат кадра первого уровня показан на рис. 3.5.3.6, он содержит 48 бит и имеет длительность 250 мксек. Физическая скорость обмена составляет 192 Кбит/с (~5,2 мксек на бит). Блок-схема терминального ISDN-интерфейса показана на рис. 4.3.3.5. Питание интерфейса осуществляется через 4-проводный выходной кабель. На вход интерфейса подается импульсно-кодовый модулированный сигнал (ИКМ). Интерфейс обеспечивает доступ к B- и D-каналам. Номинальное смещение в начале кадра в случае обмена терминал-сеть, как показано на рис. 4.3.3.6, составляет 2 бита. В некоторых случаях оно может оказаться больше из-за задержек в кабеле. Кадр включает в себя несколько l-битов, которые служат для балансировки цуга по постоянному току. Для направления NT -> TE (связь сетевого оборудования с терминальным) первыми битами кадра являются F/L-пары (см. начало и конец диаграмм; временная ось направлена слева направо), нарушающие AMI-правила (чередование полярности сигнала при передаче логической единицы). Раз чередование нарушено, до завершения кадра должно присутствовать еще одно такое нарушение. Бит FA реализует это второе нарушение чередования полярности. A-бит используется в процедуре активации для того, чтобы сообщить терминалу о том, что система синхронизована. Активация может проводиться по инициативе терминала или сетевого оборудования, а деактивация может быть выполнена только сетью. Помимо B1, B2 (байты выделены стрелками) и D-каналов формируются также виртуальные E- и A-каналы. E-канал служит для передачи эхо от NT1 к TE в D-канале. Существует 10-битовое смещение (задержка) между D-битом, посылаемым терминалом, и E-битом эхо (отмечено стрелкой на рис. 4.3.3.6). M-бит используется для выделения мультифреймов (эта услуга недоступна в Европе). M-бит идентифицирует некоторые FA-биты, которые могут быть изъяты для того, чтобы сформировать канал управления (например, при проведении видеоконференций). S-бит является резервным. Назначения различных вспомогательных каналов собраны в таблице А.
Таблица А
B
C
D
E
H
На первом уровне протокола разрешаются конфликты доступа терминалов к D-каналу. Активация и деактивация осуществляется сигналом <info>. info=0 означает отсутствие сигнала в линии. info=1 передает запрос активации от терминала к NT. info=2 передается от NT к TE с целью запроса активации или указывает, что NT активировано вследствие появления info=1.

info=3 и info=4 представляют собой кадры, содержащие оперативную информацию, передаваемую из TE и NT, соответственно. nt активирует местную передающую систему, которая информирует коммутатор о начале работы пользователя. NT1 в ответ передает терминалу info=2, которое служит для синхронизации. TE откликаются, посылая пакетом info=3, который содержит оперативную информацию. Все терминалы активируются одновременно.
Второй уровень решает проблему надежной передачи сообщений по схеме точка-точка. К каждому сообщению добавляется 16 контрольных чисел, включающих в себя идентификатор сообщения. Этот уровень описывает HDLC-процедуры (high level data link communication), которые обычно называются процедурами доступа для D-канала (LAP - link access procedure). LAP D базировался первоначально на рекомендациях X.25 слоя 2, но в настоящее время процедуры LAP D функционально обогатились (разрешено много LAP для одного и того же физического соединения, что позволяет 8-ми терминалам использовать один D-канал). Уровень 2 должен передать уровню 3 сообщения, лишенные ошибок. На уровне 2 решается проблема повторной передачи пакетов в случае их потери или доставки с ошибкой. LAP D базируется на LAP B рекомендаций X.25 для уровня 2. Кадры на уровне 2 представляют собой последовательности 8-битных элементов. Формат кадра второго уровня показан на рис. 4.3.3.7.

Рис. 4.3.3. 7 Структура кадра для слоя 2
Стартовый и завершающие флаги передаются так, что к любым 5 единицам подряд добавляется нуль (чтобы избежать имитации сигнатуры в других, в том числе информационных полях). Принимающая сторона эти нули убирает. FSC- вычисляется по методике CRC, описанной в разделе 3.3.1.
Каждый кадр начинается и завершается одной и той же последовательностью (сигнатура начала/конца кадра). Размер управляющего поля зависит от типа кадра (1 или 2 октета). Информационные элементы присутствуют только в кадрах, содержащих данные 3-го уровня. Формат двухбайтного поля адреса для уровня 2 показан на рис. 4.3.3.7. Адрес имеет лишь локальное значение и известен только участникам процедуры обмена. Формат байтов адреса показан на рис. 4.3.3.8.

Рис. 4.3.3.8. Адресное поле кадра слоя 2
| ea | бит расширения адресного поля; |
c/r |
бит поля команда/отклик; |
sapi |
service access point identifier - идентификатор точки доступа, служит для описания характера реализуемого сервиса: |
tei |
terminal endpoint identifier - идентификатор точки подключения терминала. |
SAPI=16 - переключение пакетов согласно протокола X.25;
SAPI=63 административные или управленческие функции (опционно). Точка доступа к услугам представляет собой виртуальный интерфейс между слоем 2 и 3 (см. рис. 4.3.3.9).

Рис. 4.3.3.9 Виртуальный интерфейс между слоями 2 и 3
Как видно из рисунка в системе могут использоваться и идентичные коды TEI, если они относятся к разным видам услуг (несовпадающими должны быть лишь комбинации SAPI-TEI). Для кодирования сигналов в ISDN используется метод 2B1Q (2 binary into 1 quaternary), что соответствует
Код |
Уровень |
10 |
+2.5 v |
11 |
+0.833 v |
01 |
-0.833 v |
00 |
-2.5 v |
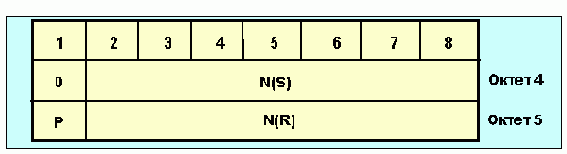
Рис. 4.3.3.10 Формат поля управления информационных кадров
N(S) - номер кадра, посылаемого отправителем (cм. также описание форматов для протокола X.25).
N(R) - номер кадра, получаемого отправителем;
P/F - флаг опроса, если кадр является командой, или флаг окончания, в случае отклика.

Рис. 4.3.5.11 Формат поля управления управляющих кадров
s - разряды кода управляющей функции;
x - зарезервировано, должно быть равно нулю.

Рис. 4.3.3.12 Формат поля управления ненумерованных кадров
m - бит модификатора функции (см. таблицу 4.3.1.2).
Мультиплексирование на уровне 2 осуществляется за счет использования отдельного адреса для каждого LAP (link access procedure) в системе. Адрес содержит два байта и определяет приемник командного кадра и адрес передатчика кадра-отклика. SAPI используется для идентификации типа услуг. Если наряду с цифровым телефоном используется обмен данными, то эти два терминала будут подключены к разным типам сервиса и, вообще говоря, к разным сетям. Для каждого вида услуг фиксируется определенный код SAPI. TEI (terminal endpoint identifier) обычно имеет определенное значение для каждого из терминалов пользователя.
Комбинация SAPI и TEI однозначно описывает LAP (link access procedure) и определяет адрес второго уровня. Так как в системе не может быть двух идентичных TEI, коды TEI распределяются следующим образом:
| 0-63 | коды tei, присваиваемые пользователем |
| 64-126 | коды tei, присваиваемые автоматически (сетью); |
| 127 | глобальный TEI (для широковещательных целей). |
Этот процесс включает в себя передачу команды SET asynchronous balanced mode extended(SABME), адресат при этом должен откликнуться посылкой ненумерованного отклика (UA - unnumbered acknowledgment). После установления канала уровень 2 может передавать информацию для уровня 3. Ниже (рис. 4.3.3.13) приведена последовательность обмена кадрами на уровне 2:

Рис. 4.3.3.13 Последовательность обмена кадрами на уровне 2
Получение каждого информационного кадра (Iframe) должно быть в конце концов подтверждено (прислан пакет RR; см. таблицу 4.3.3.1). Число Iframe, которое может быть послано, не дожидаясь подтверждения получения (размер окна), может лежать в пределах 1-127. В случае телефонии это число равно 1. Если ресурс окна исчерпан, партнер вынужден задержать отправку очередного пакета до подтверждения получения посланного ранее кадра (RR). Для выявления потери кадров используется таймер. Таймер запускается всякий раз при посылке командного кадра и останавливается при получении подтверждения. Этого таймера достаточно, чтобы проконтролировать доставку, как команды, так и отклика. Если произошел таймаут, нельзя определить, какой из этих двух кадров потерян. Кадр, поврежденный на уровне 1, будет принят с неверной FCS (frame check sequence) и по истечении времени, заданного таймером, будет произведена посылка командного кадра с битом poll=1. Партнер при этом вынужден прислать значение системной переменной, характеризующей ситуацию. По этой переменной можно судить, был ли получен исходный кадр.
Таким образом, можно идентифицировать факт потери информационного кадра (нужна ретрансмиссия) или отклика на него. После трех ретрансмиссий считается, что канал разорван, и предпринимается попытка его восстановить. FCS получается путем деления последовательности бит, начиная с адреса и кончая (но не включая) началом fcs, на образующий полином x16+x12+x5+1. Практически это делается с использованием сдвигового регистра, который в исходном состоянии устанавливается в единичное состояние. В конечном результате в регистре оказывается код остатка от деления. Дополнение по модулю 1 этого остатка и есть FCS.

Рис. 4.3.3. 14 Схема вычисления контрольной суммы (FCS/CRC)
Другой возможной ошибкой является получение I-кадра с неверным номером N(S). Это возможно, когда LAP работает при ширине окна более 1. Если потерян кадр с номером N(s)=k, принимающая сторона не должна посылать подтверждение приема кадра k+1. Отклик при этом имеет тип REJ (см. таблица 4.3.3.1) с N(R)=k+1. Это укажет передающей стороне, что все кадры до k получены, но необходимо возобновить передачу, начиная с кадра k. При выявлении ошибки в N(R) связь прерывается, реинициализируются переменные состояния передающей и принимающей сторон, после чего канал восстанавливается, и обмен возобновляется с самого начала.
Таблица 4.3.3.1. (См. также раздел о протоколе X.25)
| Кодировка байтов | |||||||||
| Команда | Отклик | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Информационные кадры | |||||||||
| iframe | - | N(S) | 0 | ||||||
| Iframe | - | N(R | P/td> | ||||||
| Кадры управления (supervisory) | |||||||||
| RR | RR | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| RR | RR | N(R) | P/F | ||||||
| RNR | RNR | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| RNR | RNR | N(R) | P/F | ||||||
| REJ | REJ | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| REJ | REJ | N(R) | P/F | ||||||
| Ненумерованные кадры | |||||||||
| SABME | - | 0 | 1 | 1 | p | 1 | 1 | 1 | 1 |
| - | DM | 0 | 0 | 0 | f | 1 | 1 | 1 | 1 |
| UI | - | 0 | 0 | 0 | p | 0 | 0 | 1 | 1 |
| DISC | - | 0 | 1 | 0 | p | 0 | 0 | 1 | 1 |
| - | UA | 0 | 1 | 1 | f | 0 | 0 | 1 | 1 |
| - | FRMR | 1 | 0 | 0 | f | 0 | 1 | 1 | 1 |
P/F |
poll=1 для команды, в противном случае конечный бит для отклика. |
Iframe |
(information frame) Информационный кадр |
DISC |
(disconnect) Отсоединить |
RR |
(receiver ready) Приемник готов |
UA |
(unnumbered acknowledge) Ненумерованное подтверждение |
RNR |
(receiver not ready) Приемник не готов |
FRMR |
(frame reject) Кадр отвергнут |
REJ |
(reject) Отказ |
DM |
(disconnect mode) Режим отключения |
SABME |
(set asynchronous balanced mode extended) Установка расширенного асинхронного сбалансированного режима |
UI |
(unnumbered information) Ненумерованная информация. |
/p> Ниже на рис. 4.3.3. 15 показана схема алгоритма восстановления после потери кадра RR.

Рис. 4.3.3.15 Восстановление системы после потери кадра RR
Сигнал RNR(получатель не готов) используется для запрета пересылки пакетов партнеру на уровне 2 и может использоваться при реализации приоритетных услуг. Другим пакетом, который специфицирован на уровне 2, является кадр frame reject (FRMR). Этот кадр может быть получен объектом второго уровня, но не может быть послан. При получении этого кадра система сбрасывается в исходное состояние. После завершения процедуры обмена разрыв канала производится путем посылки кадров DISC (disconnect) и отклика UA (unnumbered acknowledgment), с этого момента обмен кадрами I-типа не возможен. Кадр DM(disconnect mode) может выполнять те же функции, что и UA. Он используется в качестве отклика на SABME, если слой 2 не может установить связь, или отклика на disc, если связь уже разорвана.
Для управления и контроля за выделяемыми идентификаторами TEI предназначен специальный драйвер, который имеет возможность выделять и удалять используемые TEI. Все сообщения, связанные с TEI, передаются с помощью пакетов SAPI (service access point identifier). Так как работа с TEI должна выполняться вне зависимости от состояния уровня 2, все TEI-сообщения являются ненумерованными (UI) и не требуют отклика. Надежность достигается путем многократной пересылки пакетов. Пока терминалу не присвоен TEI (terminal endpoint identifier), используется широковещательный метод обмена. Все терминалы пользователя должны воспринимать любые управляющие кадры. Кадры управления в процессе присвоения TEI терминалу рассылаются широковещательно. Схема присвоения TEI и установления связи показана ниже на рис. 4.3.3.16:

Рис. 4.3.3.16 Алгоритм выделения TEI и формирования связи
Третий уровень X.25 служит для доставки управляющих сообщений даже в случае отказа сети, именно здесь выполняется реконфигурация маршрута, если это необходимо. Сигнальный пакет 3-го уровня имеет формат (рис. 4.3.3.17):

Рис. 4.3.3. 17 Формат сигнального пакета уровня 3
Эти пакеты следуют от терминала к коммутатору и наоборот. Первый октет (поле протокольный дискриминатор) дает D-каналу в будущем возможность поддержки нескольких протоколов. Приведенный код соответствует стандартному управляющему запросу пользователя. Третий октет (поле код запроса - call reference value) используется для идентификации запроса вне зависимости от типа коммуникационного канала, где этот запрос может быть реализован. Четвертый байт характеризует назначение пакета (например, Setup - запрос установления канала). Возможные типы сообщений перечислены в таблице 4.3.3.2. Длина сообщения зависит от его типа. Стандарт не регламентирует содержания полей, следующих за полем тип сообщения, и они могут использоваться по усмотрению пользователя для расширения функциональных возможностей системы.
Таблица 4.3.3.2 Коды типов сообщений
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
Значение сообщение |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Переход к определенным типам сообщений: |
| 0 | 0 | 0 | - | - | - | - | - | Сообщения о состоянии: |
| 0 | 0 | 0 | 0 | 1 | Alerting (оповещение) | |||
| 0 | 0 | 0 | 1 | 0 | Call proceeding (состояние запроса) | |||
| 0 | 0 | 0 | 1 | 1 | Progress (прогресс) | |||
| 0 | 0 | 1 | 0 | 1 | Setup (начальная установка) | |||
| 0 | 0 | 1 | 1 | 1 | Connect (соединение) | |||
| 0 | 1 | 1 | 0 | 1 | Setup acknowledge (подтверждение начальной установки) | |||
| 0 | 1 | 1 | 1 | 1 | Connect acknowledge (подтверждение соединения) | |||
| 0 | 0 | 1 | - | - | - | - | - | Сообщения фазы запроса информации: |
| 0 | 0 | 0 | 0 | 0 | User information (пользовательские данные) | |||
| 0 | 0 | 0 | 0 | 1 | Suspend reject (отложенный отказ) | |||
| 0 | 0 | 0 | 1 | 0 | Resume reject (отказ возобновления) | |||
| 0 | 0 | 1 | 0 | 1 | Suspend (откладывание выполнения) | |||
| 0 | 0 | 1 | 1 | 0 | Resume (возобновление) | |||
| 0 | 1 | 1 | 0 | 1 | Suspend acknowledge (подтверждение откладывания) | |||
| 0 | 1 | 1 | 1 | 0 | Resume acknowledge (подтверждение возобновления) | |||
| 0 | 1 | 0 | - | - | - | - | - | Сообщения об устранении дефекта: |
| 0 | 0 | 1 | 0 | 1 | Disconnect (отсоединение) | |||
| 0 | 0 | 1 | 1 | 0 | Restart (повторный старт) | |||
| 0 | 1 | 1 | 0 | 1 | Release (освобождение) | |||
| 0 | 1 | 1 | 1 | 0 | Restart acknowledge (подтверждение повторного старта) | |||
| 1 | 1 | 0 | 1 | 0 | Release complete (освобождения завершено) | |||
| 0 | 1 | 1 | - | - | - | - | - | Прочие сообщения: |
| 0 | 0 | 0 | 0 | 0 | Segment (сегмент) | |||
| 0 | 0 | 0 | 1 | 0 | Facility (возможность) | |||
| 0 | 1 | 1 | 1 | 0 | Notify (обращение внимания) | |||
| 1 | 0 | 1 | 0 | 1 | Status inquiry (запрос состояния) | |||
| 1 | 1 | 0 | 0 | 1 | Congestion control (управление перегрузкой) | |||
| 1 | 1 | 0 | 1 | 1 | Information (информация) | |||
| 1 | 1 | 1 | 0 | 1 | Status (состояние) |
/p> * Цифрами в верхней части таблицы пронумерованы биты кодов
В приведенной ниже таблице 4.3.3.3 представлены информационные элементы, которые могут содержаться в сообщениях Setup (это самый сложный тип сообщений).
Таблица 4.3.3.3. Поля setup-сообщений
Поле в пакете |
Длина (октеты) | Комментарии |
| Дискриминатор протокола | 1 |
|
| Код запроса | 2-3 | |
| Тип сообщения | 1 | |
| Передача завершена | 1 | Опционно, включается, если пользователь или сеть указывает, что вся информация включена в это сообщение Setup |
| Возможности канала | 6-8 | Описывает CCITT телекоммуникационные услуги (BC) |
| Идентификация канала | 2-? | Служит для идентификации канала в пределах isdn-интерфейса, управляемого данными процедурами |
| Специфические возможности сети | 2-? | Опционно |
| Дисплей | 2-82 | Опционно: IA5 (ASCII) символы для отображения на терминале |
| keypad | 2-34 | Альтернатива для пересылки кода вызываемого объекта. keypad может использоваться и для другой информации |
| Номер отправителя | 1-? | Опционно |
| Субадрес отправителя | 2-23 | Опционно |
| Номер адресата | 2-? | В случае направления пользователь-сеть является альтернативой keypad |
| Субадрес адресата | 2-23 | Опционно |
| Выбор транзитной сети | 2-? | Опционно |
| Совместимость с нижним уровнем (llc) | 2-16 | Опционно |
| Совместимость с верхним уровнем (hlc) | 2-4 | Опционно |
| Пользователь-пользователь | 2-131 | Опционно, когда вызывающий пользователь хочет передать информацию вызываемому |
| BC= | speech | Означает, что используется обычная для этого вида услуг маршрутизация - может быть задействовано не более двух спутников, (G.711); |
| 3.1khz audio | Не должно использоваться эхо-подавление и dcme - (digital circuit multiplication equipment - оборудование уплотнения), необходим m/a-адаптер | |
| 7 khz | Высококачественная телефония (рекомендации CCITT G.722/G.725), требует 64 Кбит/с; | |
| 64kbit/s unrestricted | Скоростной информационный обмен |
/p> Услуги типа speech или 3.1 khz audio возможны и через общественную коммутируемую телефонную сеть (PSTN), остальные из перечисленных требуют 64-килобитного цифрового канала. Схема формирования запроса, получения доступа к определенному виду услуг показана ниже на рисунке 4.3.3.18. Помимо названных услуг существуют и другие, например, видео-телефония, видеоконференции и пр., список этот постоянно расширяется. При реализации 7кГц-телефонии должны быть выполнены следующие требования:
Должно использоваться терминальное оборудование, рассчитанное для работы с 3.1кГц, и обычные сетевые телефонные каналы.
Время реализации вызова должно быть приемлемо малым.
Система должна выдавать сообщение в случае, если в результате диалога реализуется 3.1кГц вместо 7.
Видео телефония использует один или два B-канала. В Европе приняты следующие нормы (normes europeennes de telecommunication-net):
| Net3 | isdn с обычной (базовой) скоростью обмена |
| Net5 | isdn с первичной скоростью обмена (64кбит/с) |
| Net7 | терминальные адаптеры |
| Net33 | цифровая телефония. |

Рис. 4.3.3.18 Последовательность сообщений при реализации стандартного вызова
Вызываемый партнер получает setup-сообщение через широковещательное обращение. Все терминалы, соединенные с NT1 могут анализировать Setup-сообщение с тем, чтобы определить, соответствуют ли они вызывающей стороне. Соответствие определяется по возможностям канала и по совместимости информационных элементов нижнего уровня. Если терминал соответствует требованиям запроса, он посылает сети сообщение alerting (Оповещение). В то же время, если необходимо, терминал должен сформировать локальный сигнал вызова (напр. звонок). После получения всей необходимой информации сеть выдает сообщение call proceeding, которое указывает на то, что начата установка связи с объектом вызова. Когда терминал обнаружил, что на запрос получен отклик, он переадресует connect-сообщение сети. Сеть регистрирует запрос и выдает команду терминалу соединиться с соответствующим B-каналом, послав пакет connect acknowledge, содержащий код B-канала. В любой момент времени к В-каналу может иметь доступ только один терминал. Все остальные терминалы, которые откликнулись на запрос, получат от сети сообщение release, которое переводит их в пассивное состояние. Пользователь может отменить запрос в любое время, послав три сообщения: disconnet, release и release complete (см. рис. 4.3.3.19 и таблица 4.3.3.2).

Рис. 4.3.3. 19 Обмен сообщениями при разрыве связи
Возможна временная пассивация терминала посредством сообщения suspend с последующим возобновлением прерванного режима с помощью сообщения resume. Каждое из этих сообщений требует подтверждения получения (suspend acknowledge и resume acknowledge, соответственно). При вызове может оказаться несколько терминалов, отвечающих запрашиваемым требованиям (например, телефонных аппаратов). Вызывающая сторона может выбрать один из них (зная, например, их положение). Существует два механизма обращения к заданному терминалу. Первый использует вспомогательную службу direct dialling-in (DDI), которая в случае реализации обычного доступа к ISDN называется multiple subscriber number (MSN). В DDI и MSN номер сети используется для целей маршрутизации в пределах локальной сети пользователя. Каждому терминалу в сети должен быть присвоен уникальный MSN-номер. Именно этот номер используется для идентификации при Setup-процедуре.
Второй механизм адресации к заданному терминалу базируется на субадресации (subaddressing - SUB). В этом варианте дополнительная адресная информация передается от источника запроса к адресату. Этот адрес не является частью ISDN-номера, который используется для целей маршрутизации. Этот адрес может быть применен для обращения к некоторому процессу внутри терминала (не следует забывать, терминалом может быть ЭВМ) или к приложениям, которые не следуют стандартам OSI. Каждый терминал, подсоединенный к пассивной шине, нуждается в присвоении ему субадреса.
Принципиальное различие между DDI/MSN и SUB методами адресации заключается в том, что для DDI/MSN адрес является частью ISDN номера, в то время как для SUB это не так.
В этом случае каждому терминалу, подключенному к пассивной шине, должен быть присвоен такой субадрес. Процедура Setup должна содержать информацию о субадресе. Для выбора типа услуг и проверки терминальных возможностей используется обмен сообщениями alerting-connect.
Для максимального удовлетворения запросов потребителей isdn должна поддерживать самые разные дополнительные виды услуг. Чтобы решить эти задачи на уровне 3 для интерфейса пользователь-сеть разработаны два протокола - функциональная и стимулирующая сигнальные процедуры. В случае стимулирующей сигнальной процедуры терминал не должен иметь какой-либо информации о вспомогательных видах услуг. Работа терминала контролируется сетью с помощью сигнальных сообщений уровня 3. Сеть и терминал работают по схеме клиент-сервер и от терминала не требуется особых аналитических способностей. Базовый формат управляющих сообщений соответствует типу information. Существуют две разновидности этого протокола: один использует управляющие последовательности символов, заключенные между * и #, для второго - сеть должна хранить специальный профайл для каждого терминала. Такой профайл может переопределять функцию некоторых клавиш терминала. Нажатие такой клавиши осуществляет вызов определенного вида услуг.
В случае функциональной сигнальной процедуры терминал должен знать все о вспомогательном виде услуг и хранить всю необходимую информацию о них. Функциональный протокол использует информационные элементы facility (возможность, см. таблицу 4.3.5.4). Для пересылки этих информационных элементов используются сообщения типа register (см. описание протокола X.25). Функциональный протокол базируется на протоколе ROSE (remote operations service element). Этот протокол служит для поддержки приложений, где необходим интерактивный контроль сетевых объектов. Протокол ROSE обеспечивает запуск процесса, поддерживает процедуры подтверждения и последующее управление процессом. В таблице 4.3.5.4 приведен перечень дополнительных услуг, предоставляемых ISDN и поддерживаемых функциональным протоколом.
Таблица 4.3.5.4. Дополнительные услуги сети ISDN
Определение вызывающего номера (более эффективный аналог АОН);
Ограничение (запрет) по вызывающим номерам;
Ожидание вызова;
Прямой набор номера;
Субадресация;
Переносимость терминала;
Телефонные конференции;
Безусловная переадресация вызовов;
Переадресация, если номер занят;
Переадресация вызова при отсутствии ответа;
Групповые номера (по одному и тому же номеру к серверу могут дозваниваться несколько модемов)
Реально это лишь ядро списка, разные сети могут предоставлять и многие другие услуги.
При установлении телефонного канала используется сообщение TUP (telephony user part). В ISDN определены также сообщения ISUP (integrated services user part), которые должны стать основой всех будущих разработок. Примерами ISUP могут служить следующие сообщения:
IAM |
(initial address message) используется для инициализации канала, передачи маршрутной информации и параметров запроса. |
SAM |
(subsequent address message) посылается вслед за iam, когда необходимо передать дополнительную информацию о предстоящей сессии. |
INR |
(information request message) посылается коммутатором для получения информации по текущей сессии. |
INF |
(information message) передает информацию, запрошенную inr. |
ACM |
(address complete message) подтверждает получение всей необходимой маршрутной информации. |
CPG |
(call progress message) посылается адресатом вызывающей стороне и информирует о том, что имело место какое-то событие. |
ANM |
(answer message) подтверждает получение запроса, используется для начала измерения времени обработки запроса, для контроля информационного потока и доступа пользователей. |
FAR |
(facility request message) посылается одним коммутатором другому для активации его состояния. |
FAA |
(facility accepted message) является позитивным откликом на запрос far. |
FRJ |
(facility reject message) отклик на запрос far, если он не может быть выполнен. |
USR |
(user-to-user information message) используется для обмена информацией между пользователями (помимо сигнальной информации). |
CMR |
(call modification request message) сообщение, которое может быть послано в любом направлении, для модификации сессии, например, для перехода от передачи данных к передаче голоса. |
CMC |
(call modification completed message) сообщение-отклик на запрос CMR, подтверждающее его исполнение. |
CMRJ |
(call modification reject message) сообщение-отклик на запрос cmr, оповещающее об отклонении этого запроса. |
REL |
(release message) сообщение, посылаемое в любом направлении и оповещающее о том, что система свободна и готова перейти в пассивное состояние при получении сообщения о завершении процедуры release. |
RLC |
(release complete message) - посылается в ответ на REL. |
/p> В ISDN используются базовая (B-канал, 64 Кбит/с) и первичная (1,544/2,048 Мбит/с) скорости передачи информации. Сигнальный D-канал формируется на основе 24-го временного домена (timeslot) в случае 1,544 Мбит/с и 16-го для 2,048 Мбит/с. Характеристики первичных каналов ISDN приведены в таблице 4.3.3.5.
Таблица 4.3.3.5. Характеристики первичных каналов ISDN
Быстродействие первичного канала |
Кодировка |
Импеданс линии |
Временной домен d-канала |
Уровень сигнала |
| 1,544 Мбит/с | B8ZS | 100 Ом | 24 | 3 В |
| 2,048 Мбит/с | HDB3 | 120 Ом | 16 | 3 В |
Для первичной скорости не предусматривается интерфейс многоточечного обмена в локальной сети пользователя; связь устанавливается между сетью и одним из PABX (public automatic branch exchange) или другим терминалом.
В случае первичной скорости отсутствуют какие-либо средства для деактивации связи с целью экономии энергии. Для пользователя желательно иметь доступ, как к базовым, так и первичным каналам
Для базовой скорости передачи работает сигнальная цифровая система доступа DASS (digital access signaling system). Формат кадра при этом имеет вид (DASS2/DPNSS - digital private network signaling system):

Рис. 4.3.3.20 DASS2/DPNSS-кадр уровня 2
Этот формат не отличается от общепринятого для уровня 2 ISDN, за исключением числа байт управления (см. рис. 4.3.3.20 и 4.3.3.7), что допускается регламентирующими документами. Использование местной ISDN-АТС открывает дополнительные возможности. Помимо высококачественной локальной связи появляются коллективные (групповые) номера, что снимает ограничение на число пользователей, подключенных к узлу через обычные аналоговые модемы. Все пользовательские модемы дозваниваются по одному и тому же номеру, а коммутатор выполняет функцию пакетного мультиплексора. Емкость таких АТС легко наращивается, отдельные АТС могут объединяться друг с другом. Схема взаимодействия такой АТС (PTNX) с терминальным пользовательским оборудованием, другими ptnx и основной сетью ISDN показана на рис. 4.3.3.21. Местная АТС может предоставлять те же услуги, что и традиционная сеть ISDN, плюс запрограммированные локально виды сервиса (диалог между пользователями локальной сети, услуга типа “не беспокоить” и т.д.).

Рис. 4.3.3.21 Связи местной ISDN-АТС
Взаимодействие между ISDN и PSPDN регулируется стандартом ccitt x.31 (и i.462). x.31 позволяет использовать ISDN с существующими сетями x.25. Схема взаимодействия периферийного оборудования, ISDN и PSPDN показана на рисунке 4.3.3.22 (ISDN-коммутатор может и отсутствовать).

Рис. 4.3.3.22 Схема взаимодействия сетей ISDN и X.25
TA - терминальный адаптер; TE - терминальное оборудование; NT - сетевое терминальное оборудование
Доступ к программам обработки пакетов возможен через B- или D-каналы. В зависимости от вида приложения доступ через D-канал иметь определенные преимущества. D-канал в отличии от B-канала принципиально не может быть заблокирован. Возможна работа одновременно с 8-ю терминалами, подключенными к пассивной ISDN-шине. Кроме того, работа с D-каналом оставляет B-канал свободным для задач, которые не решаемы через D из-за его малого быстродействия (16 Кбит/с). А согласно рекомендациям LAPD быстродействие D-канала не может быть увеличено (по этой же причине максимальная длина пакетов X.25 в данной схеме не может превышать 260 октетов (против 1024 для обычных каналов X.25). К недостаткам использования D-канала можно отнести возможное увеличение задержек из-за низкого быстродействия. Протокол X.25 был разработан довольно давно для “традиционных” приложений и его недостаточная гибкость (большие задержки откликов, таймауты и пр.) приводит к тому, что он совершенно не пригоден для некоторых новых приложений. Это вынудило разработку для ISDN новых режимов работы с пакетами. И первое что было сделано - это четкое разделение управляющих и информационных потоков.
ISDN может рассматриваться как две логически независимые субсети - сигнальную субсеть и коммутируемую информационную сеть (в x.25 информация и управление осуществляется по одним и тем же каналам). В соответствии с этим разделением терминология CCITT различает плоскость управления (C-plane) и пользовательскую информационную плоскость (U-plane, см. рис. 4.3.3.23). В ISDN существует два режима: frame relaying (передача кадров, наиболее простой из режимов) и frame switching (коммутация кадров). Отличительной особенностью режима frame relaying является отсутствие подтверждений получения пакета при обмене данными между ISDN-терминалами (аналог UDP в TCP/IP сетях). Для обоих режимов используется одни и те же сигнальные процедуры (Q.933), но они отличаются протоколами U-плоскости при пересылке информации. Здесь используются протоколы передачи данных, базирующиеся на усовершенствованном стандартном сигнальном протоколе LAPD слоя 2, известном как LAPF - link access procedures for frame mode bearer services (Q.922). Пользователь может установить несколько виртуальных соединений и/или постоянных виртуальных связей одновременно с несколькими адресатами.

Рис. 4.3.3.23 Услуги ISDN в режиме переключения (цифрами помечены уровни протоколов, в скобках приведены ссылки на документы ITU)
На сигнальном уровне C-плоскости используются стандартные LAPD-процедуры слоя 2 (Q.921 или I.441), а для слоя 3 спецификация кадрового режима (Q.933). Но на U-плоскости сеть поддерживает только небольшую часть связного протокола:
разделение кадров с использованием HDLC-флагов;
проверка кадров по длине и контрольной сумме, выбрасывание кадров с ошибками;
мультиплексирование и демультиплексирование кадров, относящихся к разным виртуальным запросам, на основе их адресов слоя 2.
В простейшем случае сеть посредством сигнальных процедур на фазе Setup формирует вход в маршрутную таблицу. На уровне 2 для каждого виртуального запроса выделяется адрес, который остается действительным только на время данного вызова. При пересылке данных сеть просто индексирует маршрутную таблицу, используя адреса слоя 2 поступающих кадров, и ставит их в очередь на передачу по соответствующему маршруту. На фазе передачи информации терминалы используют протоколы более высокого уровня по схеме точка-точка без привлечения сети. Схема протокола коммутации кадров показана ниже на рис. 4.3.3.24, здесь передача кадров происходит с подтверждением получения (до какой-то степени аналог протокола tcp). Сеть детектирует потери и случаи дублирования пакетов.
Здесь на сигнальном уровне все процедуры следуют требованиям связного протокола ISDN в полном объеме в том числе и при передаче данных. Это подразумевает необходимость подтверждения получения каждого информационного кадра, пересылаемого от терминала к терминалу. Cеть контролирует доставку кадров и выявляет ошибки.
Как и в предыдущем случае мультиплексирование и демультиплексирование выполняется с использованием адресов слоя 2. Адрес кадра может содержать 2-4 октетов, а информация занимать от 1 до 262 октетов. Последняя величина может быть и увеличена в результате переговоров между отправителем и получателем при формировании виртуального канала. Рекомендуется не использовать кадров с размером поля данных более 1600 октетов во избежании фрагментации и последующей сборки сообщений.

Рис. 4.3.3.24 Режим переключения кадров
ITU-T делит все канальные услуги на две категории. 8 типов услуг уже определены для случая коммутации каналов и три определены для коммутации пакетов. Три из восьми считаются определяющими и каждый ISDN-переключатель должен их поддерживать (ITU-T рекомендация I.230).
Интернет
4.4 Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)
Виртуальная сеть виртуальных сетей - Интернет является самой большой и самой популярной сетью. Можно смело утверждать, что эта сеть сохранит это лидерство в ближайшие годы. Привлекательность сети не только в том, что это единая среда общения людей, находящихся в разных странах и на разных континентах. Интернет предоставляет все более широкий спектр услуг. Это и информационно-поисковые системы, телефония, аудио и видео письма, доставляемые за считанные секунды в любую точку мира (где имеется Интернет), видеоконференции, электронные журналы, службы новостей, дистанционное обучение, банковские операции и многое, многое другое. Интернету предстоит мучительная процедура перехода на 128-битовые адреса (IPv6), но по ее завершении можно ожидать дальнейшего расширения списка услуг. Уже сегодня Интернет стал средой, предоставляющей возможность целевой рекламы и дистанционной торговли. Уже в начале следующего века сети станут самым мощным средством массовой информации. Но для решения всех этих проблем в этой сфере еще очень много надо сделать. Современные поисковые системы, несмотря на впечатляющие успехи, требуют существенного улучшения эффективности, много надо сделать для того, чтобы Интернет пришел в каждую квартиру.
Сегодня Интернет использует многие десятки протоколов. Если сюда добавить протоколы физического уровня, то их число превысит сотню. На уровне локальных сетей наиболее распространены различные разновидности Ethernet, а также Token Ring и некоторые другие. Особенно велико разнообразие протоколов межсетевого обмена. Здесь помимо PPP используется FDDI, X.25, ISDN, ATM, SDH, Fibre Channel и пр.. На транспортном уровне в Интернет работают протоколы UDP (без установления соединения) и TCP (с установлением соединения). Это два принципиально разных подхода к передаче данных. В обоих случаях и передатчик и приемник имеют индивидуальные IP-адреса и порты. Но в случае TCP они ассоциируются в соединители (socket) - две пары IP-адрес-порт и прием/передача в рамках одной сессии происходит по схеме точка-точка. Для UDP же допускается возможность передачи одновременно нескольким приемникам (мультикастинг) и прием данных от нескольких передатчиков в рамках одной и той же сессии. Протокол TCP используется для поточной передачи данных, при которой доставка гарантируется на протокольном уровне. Это обеспечивается обязательным подтверждением получения каждого пакета TCP. Напротив, протокол UDP не требует подтверждения получения. В этом случае, как правило, исключается также и фрагментация пакетов, так как пакеты при схеме без установления соединения никак не связаны между собой. По этим причинам UDP в основном служит для передачи мультимедийных данных, где важнее своевременность, а не надежность доставки. Протокол TCP используется там, где важна надежная, безошибочная доставка информации (файловый обмен, передача почтовых сообщений и WEB-технология).
Схема без установления соединения привлекательна также тем, что позволяет при передаче данных от исходного источника к большому числу приемников минимизировать общий трафик. Если бы для этой цели использовался протокол TCP, то при N приемниках надо было бы сформировать N виртуальных каналов и транспортировать N идентичных пакетов (рис. 4.4.1). В случае UDP от передатчика до точки разветвления передается только один пакет, что уменьшает загрузку данного участка в N раз (рис. 4.4.2). Причем аналогичная экономия может быть реализована и по пути к очередной точке разветвления (смотри описание протокола мультикастинг-маршрутизации PIM).

Рис.4.4.1

Рис. 4.4.2.
В примере на рисунке 4.4.2 на участке 1 снижение трафика по сравнению с традиционным методом передачи данных происходит в 8 раз, на участке 2 - в 4 раза, а на сегментах 3 - в два раза.
Все множество протоколов Интернет можно поделить на две группы. К первой относятся те, что имеют собственный стандарт на формат пакетов (IP, UDP, TCP, ARP, RARP, RTP, RIP, OSPF, BGP, IGRP, ICMP, SNMP, DNS, PIM, IGMP, BOOTP, IPX/SPX, AAL и др.). Вторую группу образуют протоколы, которые формализуют обмен на уровне сообщений. Они не имеют своих форматов на пакеты, а стандартизуют лишь форму сообщений и алгоритм обмена. Вторая группа использует для передачи своих сообщений протоколы первой группы. К этой группе относятся SMTP, NTP, POP, IMAP, FTP, HTTP, RSVP, Telnet, Finger, NNTP, Whois, SET, SSL и т.д. По существу, вторая группа располагается на прикладном уровне. Первая группа более консервативна и достаточно хорошо структурирована, вторая – динамична и постоянно расширяется. Ко второй группе примыкают некоторые стандартизованные утилиты типа ping, traceroute, а также поисковые системы. В перспективе на подходе протоколы для интерфейсов баз данных и мультимедиа. Особняком стоят алгоритмы обеспечения безопасности.
Интернет в Ethernet
4.1.1.3 Интернет в Ethernet
Семенов Ю.А. (ГНЦ ИТЭФ)

В Интернет не существует иерархии сетей. Локальная сеть на основе Ethernet, две ЭВМ, связанные через последовательный интерфейс, или общенациональная сеть страны - это все сети и по логике Интернет они все равны. Каждая сеть имеет свое имя и как минимум один IP-адрес. Имя привычнее для людей, адреса - для машин. Между именами и адресами существует строгое соответствие.
Для того чтобы пояснить взаимодействие различных систем в сети, рассмотрим сильно упрощенную схему обработки команды telnet vxdesy.desy.de, которая предполагает осуществление удаленного доступа к vx-кластеру в ДЕЗИ, Гамбург (вызов через windows обрабатывается практически аналогично). Сначала ЭВМ выделяет команду telnet и запускает соответствующую программу. Эта программа рассматривает символьный адрес vxdesy.desy.de в качестве параметра команды telnet.

Рис. 4.1.1.3.1. Схема обработки сетевого запроса
Сначала определим, что же нужно сделать для решения стоящей задачи? Чтобы обратиться к нужной ЭВМ, система должна знать ее IP-адрес, маску субсети и адрес маршрутизатора или ЭВМ, через которые можно обратиться с запросом на установление канала связи. Рассмотрим решение проблемы поэтапно. Сначала символьный адрес vxdesy.desy.de пересылается серверу имен (DNS-система может располагаться как в ЭВМ пользователя, так и в другой машине), где преобразуется в цифровой IP-адрес, пересылаемый в отклике на DNS-запрос (предварительно надо узнать его MAC-адрес). Но знания IP-адреса недостаточно, надо выяснить, где находится объект с этим адресом. На IP-адрес накладывается сетевая маска (задается при конфигурации рабочей станции), чтобы определить, не является ли данный адрес локальным. Если адрес локален, IP-адрес должен быть преобразован в Ethernet-адрес (MAC), ведь ваша ЭВМ может оперировать только с Ethernet-адресами. Для решения этой задачи посылается широковещательный (обращенный ко всем участникам локальной сети) ARP-запрос. Если адресат находится в пределах локальной субсети, то он откликнется, прислав Ethernet-адрес своей сетевой карты. Если это не так, что имеет место в приведенном примере, присылается Ethernet-адрес пограничного для данной сети маршрутизатора. Это происходит лишь в случае, если он поддерживает режим proxy-ARP. В противном случае рабочая станция должна воспользоваться IP-адресом маршрутизатора (gateway), заданным при ее конфигурации, и выявить его MAC-адрес с помощью ARP-запроса. Наконец с использованием полученного IP-адреса программа telnet формирует IP-пакет, который вкладывается в Ethernet-кадр и посылается в маршрутизатор узла (ведь именно его адрес она получила в ответ на ARP-запрос в данном примере). Последний анализирует имеющиеся у него маршрутные таблицы и выбирает, по какому из нескольких возможных путей послать указанный пакет. Если адресат внешний, IP-дейтограмма вкладывается в PPP- FDDI- или какой-то другой кадр (зависит от протокола внешнего канала) и отправляется по каналам Интернет. В реальной жизни все бывает сложней. Во-первых, присланный символьный адрес может быть неизвестен локальной dns-системе (серверу имен) и она вынуждена посылать запросы вышестоящим DNS-серверам, во-вторых, пограничный маршрутизатор вашей автономной системы может быть непосредственно не доступен (ваша ЭВМ находится, например, в удаленной субсети) и т.д. и т.п. Как система выпутывается из подобных осложнений, будет описано позднее. Следует иметь в виду, что, например, в системе unix все виды Интернет услуг обслуживает демон inetd. Конкретный запрос (Telnet, FTP, Finger и т.д.) поступает именно к нему, inetd резервирует номер порта и запускает соответствующий процесс, после чего переходит в режим ожидания новых запросов. Такая схема позволяет эффективно и экономно работать со стандартными номерами портов (см. раздел 7). Ну а теперь начнем с фундаментальных положений Интернет.
В Интернет информация и команды передаются в виде пакетов, содержащих как исходящий адрес, так и адрес места назначения (IP-адрес имеет 32 двоичных разряда). Каждой ЭВМ в сети поставлен в соответствие уникальный адрес, появление двух объектов с идентичными IP-адресами может дезорганизовать сеть. IP-адресация поддерживает пять различных классов сетей (практически используется только три) и, соответственно, адресов (версия IPv4). Класс А предназначен в основном для небольшого числа очень больших сетей. Здесь для кода сети выделено только 7 бит, это означает, что таких сетей в мире не может быть больше 127 (27-1). Класс B выделяет 14 бит для кода сети, а класс С - 22 бита. В классе C для кода ЭВМ (host) предназначено 8 бит, поэтому число ЭВМ в сети ограничено. Самые левые биты адреса предназначены для кода класса. ip-адрес характеризует точку подключения машины к сети. Поэтому, если ЭВМ перенесена в другую сеть, ее адрес должен быть изменен. Старшие биты адреса определяют номер подсети, остальные биты задают номер узла (номер ЭВМ). В таблице 4.1.1.3.1 приведено соответствие классов адресов значениям первого октета адреса и указано количество возможных IP-адресов каждого класса.
Таблица. 4.1.1.3.1
Характеристики классов адресов
узлов

Рис. 4.1.1.3.2. Структура IP-адресов (NetID = идентификатор сети)
Для удобства чтения IP-адреса обычно записываются в десятично-точечной нотации, например: 192.148.166.129 (адрес класса C).
Классу A соответствует диапазон адресов 1.0.0.0 - 127.255.255.255.
Классу B соответствует диапазон адресов 128.0.0.0 - 191.255.255.255.
Классу С соответствует диапазон адресов 192.0.0.0 - 223.255.255.255.
Классу D соответствует диапазон адресов 224.0.0.0 - 239.255.255.255.
Классу E соответствует диапазон адресов 240.0.0.0 - 247.255.255.255.
Ряд адресов является выделенными для специальных целей:
0.0.0.0 - обращение к ЭВМ, на которой производится работа;
255.255.255.255 - обращение ко всем машинам локальной сети.
127.xxx.xxx.xxx - помещение пакета во входной поток данной ЭВМ (loopback).
Два другие специальные адреса показаны на рис. 4.1.1.3.2.а.

Рис. 4.1.1.3.2.а. Специальные ip-адреса
IP-адрес имеет Интернет- и местную секции, первая характеризует место (организацию, сеть или даже группу сетей), вторая - конкретную ЭВМ. Местная секция адреса может быть разделена на части, характеризующие локальную сеть и конкретную ЭВМ (рис. 4.1.1.3.3).

Рис. 4.1.1.3.3. Локальная часть IP-адреса
Такая схема обеспечивает необходимую гибкость, дает возможность разделить локальную сеть на субсети. При работе с субсетью необходимо использовать 32-разрядную маску. Разряды маски должны равняться 1, если сеть рассматривает данный бит как часть адреса сети, и 0, если он характеризует адрес ЭВМ в этой сети. Например:
255.255.255.254 (десятично-точечное представление)
11111111 11111111 11111111 11111110 (двоичное представление)
описывает маску субсети, в которой работает автор. Некоторую информацию о масках в работающей сети можно получить с помощью команды ifconfig (SUN):
/usr/etc/ifconfig -a (курсивом здесь и далее выделяются команды, введенные с клавиатуры)
le0: flags=863
inet 193.124.224.35 netmask ffffffe0 broadcast 193.124.224.32
lo0: flags=869
inet 127.0.0.1 netmask ffffff00,
где le0 и lo0 - имена интерфейсов, флаг -a предполагает выдачу данных обо всех интерфейсах.
Во всех схемах IP-адресации адрес со всеми единицами в секции адрес ЭВМ (host) означает широковещательное обращение ко всем ЭВМ сети. Следует помнить, что широковещательные запросы сильно перегружают сеть, и без особой необходимости их использовать не следует. В настоящее время обсуждаются четыре предложения усовершенствования IP-адресации (см. RFC-1454):
IP-адрес безусловно удобный для использования ЭВМ, почему-то плохо запоминается людьми, поэтому они разработали символьную систему имен для узлов Интернет. Эта система (DNS-
domain name system) имеет иерархический характер. Имя содержит несколько полей, разделенных символом "." (точка). В качестве примера можно привести имя домена itepnet - cl.itep.ru. Это имя содержит три поля. Поле ru указывает на принадлежность данного домена России, поле itep определяет принадлежность узла ITEP (Institute for Theoretical and Experimental Physics), cl - характеризует то, что данное конкретное имя относится к кластеру ЭВМ (имя субдомена). Никаких ограничений на число полей в имени, кроме налагаемых здравым смыслом, не существует. Собственно имя домена - это itep.ru. Самое правое поле в имени домена характеризует принадлежность к определенному типу организации или стране. Таблица стандартизованных имен приведена в приложении Национальные коды . Преобразование символьного имени в IP-адрес производится в DNS-сервере узла, который представляет собой базу данных с удаленным доступом. Если искомое имя узла в локальном DNS-сервере отсутствует, он может прислать в качестве ответа адрес другого DNS-сервера, куда следует обратиться, чтобы определить IP-адрес искомого узла. Анализ имени обычно производится справа налево. Более подробно DNS-система описана в документах RFC-822, -823, а также ниже в разделе DNS. О правилах получения IP-адресов и регистрации имен сетей можно прочесть в [8].
При формировании пакетов различного уровня используется принцип инкапсуляции (вложения). Так IP-пакеты вкладываются в Ethernet-пакеты (кадры). Всякий пакет имеет заголовок и тело, некоторые из них снабжены контрольной суммой. Схема такого вложения представлена на рисунках 4.1.1.3.4 и 4.1.1.3.5.
Поле тип определяет используемый в дейтограмме протокол, PAD - пустые биты, дополняющие размер дейтограммы до 48 бит. В случае протокола IEEE 802.3 полю тип (>150010) соответствует поле длина (
Пакетный принцип позволяет передавать информацию от разных источников к различным адресатам по общему телекоммуникационному каналу. Схема вложения пакетов в рамках TCP/IP показана на рис. 4.1.1.3.4.
Принцип вложения (также как и фрагментации) является фундаментальным для любых современных сетей. Этот принцип используется в сетях netware, Apple Talk, TCP/IP т.д.

Рис. 4.1.1.3.4. cхема вложения пакетов в TCP/IP (в данном примере в поле тип Ethernet кадра будет записан код 0800)
Отдельные сети в Интернет соединяются друг с другом через узловые серверы (gateway, их иногда называют пограничными маршрутизаторами - boarder gateway), расстояние между которыми может измеряться метрами или тысячами километров. В межсетевых обменах также используется принцип вложения так пакеты Ethernet могут вкладываться в пакеты FDDI и т.д..
Прикладные программы также как и все протокольное программное обеспечение уровня Интернет и выше работают только с ip-адресами, в то время как уровень сетевого программного обеспечения работает с физическими сетевыми адресами (так Ethernet использует 48-битные адреса).
Обычно при описании сетей используется терминология 7-уровневой модели ISO ("стек протоколов"). Так уж получилось, но Интернет лишь с определенными натяжками можно описать, придерживаясь этой схемы.
Ethernet инкапсуляция (RFC 894) (размеры полей указаны в байтах)

Рис. 4.1.1.3.5. Вложение пакетов Интернет в Ethernet- и IEEE 802 пакеты
LLC
- управление логической связью (logical link control); DSAP = 0xaa (destination service access point) - поле адреса доступа к службе получателя; SSAP = 0xaa (source service access point) - поле адреса доступа к службе отправителя; SNAP - протокол доступа к субсетям (subnetwork access protocol). PAD - поле заполнитель. В общем случае форматы полей DSAP и SSAP имеют вид, показанный на рис. 4.1.1.3.6 I/G = 0 - индивидуальный адрес, I/G =1 - групповой адрес; D - бит адреса службы места назначения, S - бит адреса службы отправителя; C/R =0 - команда, C/R =1 - подтверждение.

Рис. 4.1.1.3.6. Структура адресов DSAP и SSAP
Поле CNTL может иметь длину 1 или 2 байта, а его структура соответствовать I, S или U-форматам (см. разделы "Эталонная модель iso" и "x.25"). В однобайтовых полях DSAP и SSAP записывается код типа протокола сетевого уровня. Для протоколов IPX/SPX это и последующее поле содержат код 0xE0. Поле CNTL=03 обозначает нечисловой формат для уровня ethernet 802.2. Эти три байта часто представляют собой код производителя, как правило, совпадающий с первыми тремя байтами адреса отправителя. Иногда они просто делаются равными нулю. Поле тип (2 байта) характеризует используемую версию Ethernet. Из рисунка 4.1.1.3.5 видно, что первые два поля (адреса получателя и отправителя) и последнее поле (CRC) во всех форматах идентичны. При расчете CRC содержимое кадра рассматривается как двоичный полином. Производится деление этого кода на специальный образующий полином. Полученный остаток от деления дополняется по модулю один, результирующий код и считается контрольной суммой CRC. В поле адрес получателя может быть записан код 0xffffffffffff, что указывает на широковещательную адресацию кадра. Адрес отправителя такой код содержать не может. Третье поле может служить для выявления типа используемого протокола. Если в этом поле содержится число более 1500 (десятичное), это указывает на то, что данный кадр имеет формат Ethernet II, а само поле содержит не длину кадра а тип данных. Теперь, надеюсь, читателю понятно, почему кадр Ethernet 802.3 не может содержать более 1500 байт.
Кадр Ethernet 802. 2 помимо первых трех полей содержит дополнительные три однобайтовые поля, следующие вслед за ними (DSAP, SSAP и CNTL). Кадр Ethernet SNAP является модификацией кадра Ethernet 802.2. Для этого кадра коды полей dsap и ssap равны 0xAA (признак кадра Ethernet SNAP), код CNTL=03 (нечисловой формат), поле код организации
(3 байта, характеризует организацию сети) равен нулю (для IPX/SPX), а двухбайтовое поле тип характеризует протокол высокого уровня. Для протоколов IPX/SPX в этом поле должен быть записан код 0x8138 (для ip - 0x0800, для arp - 0x0806, для rarp - 0x8035, а для Apple Talk - 0x809b). Таблица кодов протоколов приведена в приложении
Базовые протоколы Интернет (см. также RFC-1700). Поля тип протокола и по смыслу и по содержанию идентичны для всех разновидностей кадра Ethernet (кроме ieee 802.3).
Транспортный уровень должен воспринимать данные от нескольких пользовательских программ и пересылать их на более низкий уровень. Многоуровневые протоколы спроектированы так, чтобы слой N по месту назначения получал ту же самую информацию, что была послана слоем N отправителя. Прикладные программы также как и все протокольное программное обеспечение уровня Интернет и выше использует только IP-адреса (32 бита), в то время как уровень сетевого программного обеспечения работает с физическими сетевыми адресами (так Ethernet использует 48-битные адреса).
Когда IP-дейтограмма попадает в ЭВМ, сетевое программное обеспечение передает ее программе IP-уровня. Если адрес места назначения совпадает с IP-адресом ЭВМ, дейтограмма принимается и передается на более высокий уровень для дальнейшей обработки. При несовпадении адресов дейтограмма уничтожается (переадресация дейтограмм для ЭВМ запрещена, это функция маршрутизатора). Хотя можно заставить ЭВМ выполнять задачи маршрутизации, с точки зрения Интернет-философии это плохая идея.
Различные сети и каналы имеют разные скорости обмена и надежность передачи. Это определяет длину пакета, пересылка которого с высокой вероятностью будет осуществлена без ошибки. Так как Интернет объединяет самые разные узлы и сети, использующие разные длины посылок, при реализации связи между такими объектами размер пакета задается наименее надежным узлом и длина пакета выбирается минимальной из двух. Поэтому при передаче длинного пакета через такой участок сети он сегментируется и передается по частям. Размер фрагмента определяется величиной максимального передаваемого блока (MTU - maximum transfer unit, в Ethernet MTU=1500 октетам). Величины MTU для других сред приведены в таблице 4.1.1.3.2:
Таблица 4.1.1.3. 2 Значения mtu для различных сетевых стандартов
Сеть |
MTU (байт) |
| hyperchannel (Сеть с топологией типа шина, с csma/cd-доступом, числом подключений < 256, максимальной длиной сети около 3,5км (93-омный коаксиальный кабель rg59 или оптоволокно)) | 65535 |
| 16 Мбит/с маркерное кольцо (ibm) | 17914 |
| 4 Мбит/с маркерное кольцо (ieee 802.5) | 4464 |
| fddi | 4352 |
| Ethernet II | 1500 |
| IEEE 802.3/802.2 | 1492 |
| x.25 | 576 |
| point-to-point (при малой задержке) | 296 |

Рис. 4.1.1.3.6. Пример фрагментации пакета
Куда будет направлен Ethernet-кадр, указывает значение для типа в заголовке кадра (рис. 4.1.1.3.5). Если IP-пакет попадает в модуль IP, то содержащиеся в нем данные могут быть переданы либо модулю TCP (Transmission Control Protocol), либо UDP, что определяется полем "протокол" в заголовке IP-пакета.
Одним из основополагающих понятий в теории маршрутизации является автономная система (AS). Автономную систему составляет IP-сеть (или система из нескольких IP-сетей), проводящая единую политику внешней маршрутизации и имеющая одного или более операторов. Все AS имеют уникальные номера. Идеология AS позволяет решить проблему безудержного роста размера таблиц маршрутизации. Построение узла Интернет неотделимо от формирования локальной сети, поэтому прежде чем перейти к углубленному описанию протоколов TCP/IP, введем определения некоторых сетевых устройств, без которых построение локальной сети невозможно.
Интернет вчера, сегодня и завтра
10.25 Интернет вчера, сегодня и завтра
Семенов Ю.А. (ГНЦ ИТЭФ)
Если считать началом Интернет реализацию проекта ARPA-Net, то время его существования насчитывает более 31 года. Ведь в 1969 году был подготовлен документ RFC-1. Замечу, что протоколы Ethernet были сформированы лишь в 1973-79 годах. Интернет в РФ на 20 лет моложе. Динамику развития этой технологии можно проследить по темпу выпуска RFC (смотри рис. 1). В 2000 году ожидается не менее 250 публикаций.

Рис. 1. Число выпущенных документов RFC по годам.
К 1979 году полностью сформировался пакет протоколов TCP/IP и их приложений, началось внедрение. К 1989 году выявились некоторые недостатки старых протоколов, возникла необходимость разработки новых. Рост числа публикаций в период 1989-99 в основном определяется разработками в области безопасности (TLS (RFC-2246, -2817), RADIUS (RFC-2058), а также RFC-2817, -2845, -2875 и многие др.), мультимедиа (MIME; RFC-1590, -2045, -2046, -2047, -2048, -2049) и специальных приложений (например, протокол IOTP). Рост числа узлов Интернет за этот же интервал времени (рис. 2) и количества WEB-серверов (рис. 3) также впечатляет.

Рис. 2. Рост числа узлов Интернет в 1989-99 годах

Рис. 3. Рост числа WEB-серверов в период 1994-2000 годы
К числу новейших достижений Интернет следует отнести электронную торговлю (протоколы IOTP, SET, CyberCash и др.), IP-телефонию, мощные поисковые системы, электронную прессу и многое другое. IP-телефония уже сегодня существенно понизила тарифы на международные переговоры. Схема реализации IP-телефонной сети показана на рис. 4.

Рис. 4. Схема IP-телефонной сети
На рисунке MVW-модуль (Multiflex Voice/WAN), включаемый в маршрутизатор, например, CISCO-3662, служит для связи с общедоступной телефонной сетью. Если сеть “А” размещена в Рио-де-Жанейро, а “В” в Москве, то любой клиент нижней сети сможет разговаривать с клиентом в Рио “бесплатно”, а с клиентами телефонных сетей “А” и “B” по локальным тарифам. В левой части рисунка показаны телефонные аппараты, которые подключаются непосредственно к сегменту локальной сети. Такие приборы уже поступили в продажу.
Грядет интеграция цифрового телевидения, телефонии (включая видео-телефонию) и Интернет, звуковые и видео письма уже реальность. Схема построения интерактивной сети цифрового кабельного телевидения показана на рис. 5.

Рис. 5. Схема реализации интерактивного цифрового телевидения
Данная схема, реализованная в США и Канаде несколько лет назад, позволяет клиентам индивидуально заказывать программу телевидения на неделю вперед. Помимо этого в режиме меню можно получить данные о погоде, состоянии дорог, заказать билеты в театр или на самолет, а также вызвать на экран нужную статью какой-то газеты. Заказанные фильмы копятся в сервере буферизации и в требуемое время транслируются для клиента-заказчика. Существующая инфраструктура кабельного телевидения в США вполне пригодна для решения таких задач. В реальном масштабе времени здесь передаются только новости и спортивные соревнования.
Помимо ставшей уже привычной электронной почты Интернет дал нам WEB-технологию, глобальные поисковые системы, электронные журналы, оперативный доступ к прессе, электронную торговлю и многое другое. Молодые люди объясняются в любви по электронной почте, в реальном масштабе времени общаются с людьми на других континентах, играют в шахматы с партнерами из других стран. Все шире внедряются IP- и ISDN видео конференции.
Перспективы
1. IP-телефония
. IP-телефония уже сегодня теснит традиционную не только потому, что может предложить новые разновидности услуг, но и за счет снижения тарифов. В настоящее время внедряются протоколы RTP, RTCP и RSVP, которые вместе с расширением полосы пропускания магистральных каналов уберут последние барьеры на пути внедрения этой технологии. Можно вполне ожидать дальнейшего снижения требований, налагаемых на полосы пропускания, для реализации одного разговора. Там, где достаточно донести до партнера текст сообщения (например, пейджерная связь), можно реализовать распознавание и преобразование сообщения в ASCII-последовательность, что снизит требования к полосе пропускания в сотни раз. Еще большего эффекта можно достичь, используя схему, показанную на рис. 6 (технологии для этого по большей части уже существуют, но схема пока не реализована).

Рис. 6. Схема возможного снижения требуемой полосы пропускания при передаче голоса
Символьное отображение голоса приводит к потере индивидуальных особенностей говорящего и эмоциональной окраски его речи. Системы распознавания людей по голосу уже существуют. Индивидуальные особенности голоса вещь достаточно стабильная. Если произвести анализ голоса конкретного человека и параметризовать эти особенности, то их можно будет использовать в дальнейшем в течение длительного времени. Если набор этих параметров записать на телефонную магнитную карту, то этой картой не сможет воспользоваться никто другой. Передача этих данных принимающей стороне может производиться в процессе установления телефонного соединения. В принципе можно параметризовать и эмоциональную окраску речи говорящего, но в этом случае это нужно делать в реальном масштабе времени. Реализация предлагаемой схемы будет приводить к дополнительным задержкам, но при использовании быстродействующих процессоров эти задержки можно минимизировать. Снижение требуемой полосы пропускания вместе с повсеместным внедрением протоколов RTP и RSVP сделает беседу через Интернет общедоступной.
2. Электронные книги и сфера развлечений
. Если индивидуальные особенности голоса и эмоциональная окраска факторизованы, появляется возможность сделать плейеры, которые будут воспроизводить текст голосом определенного актера. Это потребует разработки специального языка разметки текста (вроде HTML) с учетом требуемой эмоциональной окраски. В этом случае на одном CD можно записать целую библиотеку.
Мало того, что появляется возможность заказывать программу телепередач на неделю вперед, получать различную справочную информацию, в принципе могут стать доступными многосюжетные фильмы, где сценарий адаптируется под вкус и желание зрителя (такие фильмы уже снимаются). Зритель может вмешиваться по ходу фильма и направлять линию сценария по одному из нескольких возможных путей.
Сети Интернет открывают новые возможности для интерактивных сетевых развлечений. Ограничения здесь иногда возникают лишь из-за полосы пропускания каналов. Развитие технологии виртуальной реальности будет еще более разнообразить возможности сетевых развлечений.
Сети в жилых помещениях
. Внедрение бытовой техники со встроенными процессорами создает предпосылку для создания сетей в обычных жилых домах. Появились дешевые сетевые интерфейсы, например типа CAN (Controller Area Network). Помимо удовлетворения мечты о своевременном автоматическом приготовлении утреннего кофе, такая сеть может взять на себя функции обеспечения безопасности, выдавая при пожаре сигнал тревоги в ближайшую пожарную часть, а в случае попытки несанкционированного вторжения, во вневедомственную охрану. Такая система может взять на себя функции экономии энергии, воды и других ресурсов, а также контроля экологической ситуации, предлагая хозяевам закрыть окна, если в воздухе на улице появились вредные примеси в опасных количествах.
Интернет
. Внедрение адресации IPv6 упростит и удешевит маршрутизаторы. Управление и конфигурирование серверов и маршрутизаторов будет осуществляться через базы данных, где описана маршрутная политика и политика безопасности данной автономной системы (см., например, описание языка RPSL; RFC-2280). На очереди разработка стандартных маршрутных протоколов для мобильных объектов (см. RFC-2486). Крайне актуальна раз работка внешних протоколов маршрутизации, базирующихся на “состоянии канала”, а не на “векторах расстояния” (как сегодня в BGP).
Интерактивное телевидение
. Интеграция Интернет и цифрового телевидения позволит сильно повлиять на газетный бизнес. Уже сейчас многие люди читают газеты через Интернет. Но не каждая домохозяйка умеет и хочет иметь дело с ЭВМ. Когда же появится возможность вывода статей газет на экран телевизора, а при наличии дешевого принтера и распечатки их, ситуация резко изменится. В принципе не нужно будет подписываться на какую-то конкретную газету. Можно подписаться на определенный объем данных и по аннотациям вызывать на экран только то, что заинтересовало. Эта технология сэкономит леса (ведь ни один читатель не захочет печатать всю газету), сбережет горючее, расходуемое при доставке газет на дом.
Электронная торговля
. Эта сфера бизнеса начала развиваться и в РФ. Здесь этому препятствует отсутствие широко используемых электронных платежных средств. В этом году IETF опубликовал открытый торговый протокол для Интернет IOTP (RFC-2801). Этот протокол определяет взаимодействие для всех участников торговых сделок (покупателя, продавца, банкира, агента доставки и агента обслуживания). Этот протокол совместим со всеми известными платежными средствами и протоколами, включая протокол SET, гарантирующий неразглашение номера кредитной карточки и наивысший уровень безопасности транзакции.
Интернет в медицине и образовании
. Консультации пациентов через Интернет нельзя переоценить, ведь трудно рассчитывать на высококвалифицированную помощь в удаленных районах РФ. Интернет позволяет в принципе передать эксперту рентгенограмму, кардиограмму или томограмму, не говоря о результатах различных анализов.
Дистанционное обучение может решить проблему учебников и откроет новые возможности в дополнительном образовании, которое крайне важно при массовом перепрофилировании производств. В сочетании с технологией MBONE и IP-видеоконференциями это позволит сделать уроки высококлассных преподавателей доступными в общероссийском масштабе. Хорошие же учителя также редки, как и хорошие врачи. В отличие от телевизионных учебных программ здесь возможно задавание вопросов и получение на них ответов в процессе занятия.
Безопасность
. Решение проблем сетевой безопасности (при тотальном внедрении сетей) это уже сегодня актуальнейшая задача. В эту сферу попадает обеспечение устойчивой работы сети, сохранность информации, противодействие сетевым вирусам и хакерам, гарантия конфиденциальности при передаче данных. Здесь нельзя не упомянуть об отсутствии правовой базы для применения современных методов криптографии, в частности электронной подписи.
Целевая реклама.
Нравится это или нет, но реклама решительно вошла в нашу жизнь. Телевизионная реклама назойлива, временами безвкусна и до крайности не эффективна, прежде всего, потому, что не является целевой. Интернет предлагает виды рекламы, которые не только не раздражают, но и помогают решать наши проблемы. Автор уже давно осуществляет закупку компьютерных компонентов, используя исключительно рекламные и справочные WEB-серверы. Появились и подписные виды рекламы, где информация рассылается подписчикам по электронной почте. Здесь важно, чтобы клиент мог в любой момент воспользоваться командой unsubscribe J
.
Интернет – новое средство массовой информации. Здесь предстоит решить не только технические, финансовые, правовые, но и политические проблемы.
Развитие Интернет впервые предоставляет возможность общения любого гражданина земли с любым, даже с тем, о существовании которого он и не подозревал (многие с этим познакомились через SPAM J). Это качественно меняет современную цивилизацию, создавая невиданные возможности и неведанные до сих пор угрозы.
Темпы технического прогресса зависят от скорости накопления информации об окружающем нас мире и о нас самих. Одним из параметров, определяющих этот процесс, является задержка с момента получения информации (в результате измерения, исследования или обработки уже известных данных) и до получения ее заинтересованными лицами. Последние сто лет эта задержка оставалась почти постоянной. В науке время публикации статьи в журнале занимало до полугода (книги до года). В сфере общественной жизни (газеты) задержка составляла около суток. За последние годы сначала радио и телевидение сократило эту задержку в общественной сфере до часа-двух. Интернет сократил задержку с момента появления научных данных до их опубликования до нескольких часов (в реферируемых журналах до месяца), то есть более чем в 5 раз за десять лет. Это неизбежно скажется на темпах технического прогресса в сторону его существенного ускорения, причем в самое ближайшее время.
Нерешенные пока проблемы:
Сетевая безопасность
. Существующее программное обеспечение пока не может предоставить требуемого уровня конфиденциальности при передаче информации в бизнесе и частной жизни. Постоянная тенденция унификации программных средств, операционных средств и протоколов (тенденция в принципе положительная) таит в себе угрозу создания благоприятных условий для создания компьютерных вирусов с глобальной зоной действия. Требуются более надежные и эффективные программы мониторинга и детектирования вторжения хакеров и сетевых вирусов, нужны также средства для борьбы с нежелательной рекламой (SPAM). В РФ не обеспечены юридические аспекты шифрования (для электронной подписи и сертификатов). Смотри RFC-1704, -2485 и др.
Поиск нужной информации
. Если 6- 8 лет назад люди обменивались адресами узлов, где имеется какая-то полезная информация, то сегодня проблема в выборе узла, где следует искать нужные данные. Все, кто пользуется поисковыми серверами типа Alta-Vista или Rambler, знают, что почти на любой запрос приходят десятки и сотни ссылок на один и тот же документ, лежащий в разных депозитариях. Решение проблемы может быть достигнуто путем автоматического присвоения индивидуальных кодов всем документам в сети (ID-атрибут объекта META в языке HTML). Задача релевантности документа запросу также ждет своего эффективного решения. Внедряются кластерные системы поиска, тезаурусы и многие другие ухищрения, но проблема из-за лавинного роста суммарного объема данных также далека от решения, как и десять лет назад.
Пропускная способность каналов
особенно с учетом мультимедийных требований (например, ТВ высокого разрешения). В новом тысячелетии человечество выроет из земли миллионы тонн медного кабеля и закопает туда соответствующее количество оптических волноводов.
Сетевая диагностика
. Это не только выявление нежелательных вторжений, но и детектирование всплесков широковещательных сообщений, а также дубликатов IP-адресов и их местоположения. Нужны средства для выявления узких мест в сети, до того как они станут реальной проблемой. Смотри, например, RMON (RFC-2613, -2074, -2021, 1757, -1513)
Решение проблемы мультимедийной передачи без потерь по IP
-каналам. Этому может способствовать повсеместное внедрение протоколов RTP и RSVP. Необходимо дальнейшее совершенствование алгоритмов выявления и управления перегрузками в IP-каналах.
Оптимальная маршрутизация.
На очереди создание внешних протоколов маршрутизации, учитывающих состояние каналов (сегодня они используют алгоритм вектора расстояния), а также разработка универсальных алгоритмов вычисления метрики, учитывающей реальную загрузку, пропускную способность, задержку и другие характеристики каналов.
Создание единой сети прокси-серверов,
которая будет гарантировать доставку самой свежей версии документа или программы с самого “близкого” сервера, что может в разы снизить загрузку каналов, сделать сеть более надежной и эффективной. Это предполагает дальнейшее совершенствование протокола HTTP.
Данный список выглядит коротким потому, что проблем всегда видно меньше, чем их есть на самом деле.
Некоторые материалы по рассмотренным в данном сообщении проблемам можно найти на сервере
http://book.itep.ru. В этом году в издательстве “Горячая линия - Телеком” должна выйти моя книга “Протоколы Интернет. Энциклопедия” объемом около 1100 страниц.
Приложение
Предложение по совершенствованию цифровой телефонии
Современные системы цифровой телефонии (например, ISDN) предполагают выделение 32 кбит/с на каждый разговор. Если же перевести все, что говорит человек в символьное представление, то это будет эквивалентно потоку примерно в 64 бит/c (примерно такова же предельная скорость ввода данных с клавиатуры). Разрыв в требуемых пропускных способностях соответствует 5000. Понятно, что символьное представление не содержит индивидуальных особенностей голоса и эмоциональной окраски речи. Современные системы сжатия голосовой информации позволяют сократить требования к полосе пропускания до 7,5 кбит/с, но уже с некоторым ухудшением качества воспроизведения. Наилучшие современные системы (например, VOCODER) позволяют обходиться полосой в 1 кбит/c, при весьма серьезном ухудшении качества (голос неузнаваем и напоминает речь робота). Любое сокращение требования к полосе при сохранении качества передачи голоса крайне желательно. Современная телефония – это высокодоходная отрасль, и любая фирма готова будет заплатить за такого рода разработку, так как это решит конкурентное противостояние в ее пользу. Рост пропускной способности каналов не решает проблемы, так как все телефонные компании используют эту сеть, но преуспеет та, которая сможет предложить более низкие тарифы.
В США планируется выпуск автомобилей с бортовым компьютером, управляемым голосом водителя (руки у него заняты). Таким образом, проблема преобразования голоса в последовательность символов можно считать практически решенной.
Еще большего эффекта можно достичь, используя схему, показанную на рис. 6 (технологии для этого уже существуют, но схема пока не реализована).
Символьное отображение голоса приводит к потере индивидуальных особенностей говорящего и эмоциональной окраски его речи. Системы распознавания людей по голосу уже существуют (например, в системах идентификации). Индивидуальные особенности голоса вещь достаточно стабильная. Если произвести анализ голоса конкретного человека и параметризовать эти особенности, то их можно будет использовать в дальнейшем в течение длительного времени. Если набор этих параметров записать на телефонную магнитную карту, то этой картой не сможет воспользоваться никто другой. Передача этих данных принимающей стороне может производиться в процессе установления телефонного соединения. В принципе можно параметризовать и эмоциональную окраску речи говорящего, но в этом случае это нужно делать в реальном масштабе времени. Реализация предлагаемой схемы будет приводить к дополнительным задержкам, но при использовании быстродействующих процессоров, или аппаратных средств эти задержки можно минимизировать.
На пути реализации проекта надо решить проблему синтеза речи с учетом индивидуальных и эмоциональных особенностей голоса говорящего. Голосовые синтезаторы существуют, но все они крайне не совершенны. Понятно, что все перечисленные проблемы не будут решены сразу. Но вполне реально внедрять систему поэтапно, предоставляя клиенту в этом случае выбор: высокое качество и высокий тариф или низкий тариф при пониженном качестве передачи голоса.
Возможные приложения при частичном или полном успехе проекта:
Организация пейджерной связи без оператора посредника
Снижение телефонных тарифов (особенно для дальней телефонной связи).
Обучение языку, коррекция произношения
Распознавание преступников по голосу
Грубые оценки показывают, что высокого качества передачи голоса методом параметризации можно достичь при полосе 1кбит/c.
