IP-протокол
4.4.1 IP-протокол
Семенов Ю.А. (ГНЦ ИТЭФ)
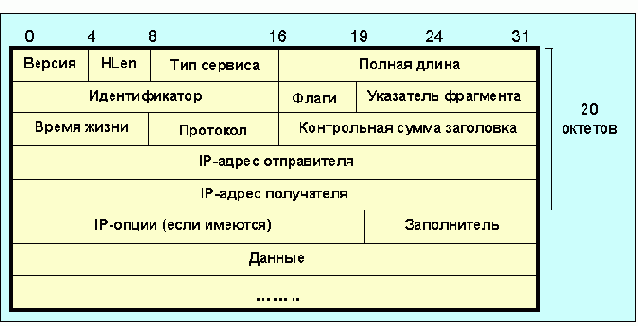
Рис. 4.4.1.1. Формат дейтограммы Интернет
Поле версия характеризует версию IP-протокола (например, 4 или 6). Формат пакета определяется программой и, вообще говоря, может быть разным для разных значений поля версия. Только размер и положение этого поля незыблемы. Поэтому в случае изменений длины IP-адреса слишком тяжелых последствий это не вызовет. Понятно также, что значение поля версия во избежании непредсказуемых последствий должно контролироваться программой. HLEN - длина заголовка, измеряемая в 32-разрядных словах, обычно заголовок содержит 20 октетов (HLEN=5, без опций и заполнителя). Поле полная длина определяет полную длину IP-дейтограммы (до 65535 октетов), включая заголовок и данные. Одно-октетное поле тип сервиса (TOS - type of service) характеризует то, как должна обрабатываться дейтограмма. Это поле делится на 6 субполей:

Субполе Приоритет предоставляет возможность присвоить код приоритета каждой дейтограмме. Значения приоритетов приведены в таблице (в настоящее время это поле не используется).
0 Обычный уровень
1 Приоритетный
2 Немедленный
3 Срочный
4 Экстренный
5 ceitic/ecp
6 Межсетевое управление
7 Сетевое управление
Биты C, D, T и R характеризуют пожелание относительно способа доставки дейтограммы. Так D=1 требует минимальной задержки, T=1 - высокую пропускную способность, R=1 - высокую надежность, а C=1 – низкую стоимость. TOS играет важную роль в маршрутизации пакетов. Интернет не гарантирует запрашиваемый TOS, но многие маршрутизаторы учитывают эти запросы при выборе маршрута (протоколы OSPF и IGRP). В таблице 4.4.1.1 приведены рекомендуемые значения TOS.
Табл. 4.4.1.1. Значения tos для разных протоколов
FTP данные
UDP
tcp
SMTP данные
Поля идентификатор, флаги (3 бита) и указатель фрагмента (fragment offset) управляют процессом фрагментации и последующей "сборки" дейтограммы. Идентификатор представляет собой уникальный код дейтограммы, позволяющий идентифицировать принадлежность фрагментов и исключить ошибки при "сборке" дейтограмм. Бит 0 поля флаги является резервным, бит 1 служит для управления фрагментацией пакетов (0 - фрагментация разрешена; 1 - запрещена), бит 2 определяет, является ли данный фрагмент последним (0 – последний фрагмент; 1 - следует ожидать продолжения). Поле время жизни (TTL - time to live) задает время жизни дейтограммы в секундах, т.е. предельно допустимое время пребывания дейтограммы в системе. При каждой обработке дейтограммы, например в маршрутизаторе, это время уменьшается в соответствии со временем пребывания в данном устройстве или согласно протоколу обработки. Если TTL=0, дейтограмма из системы удаляется. Во многих реализациях TTL измеряется в числе шагов, в этом случае каждый маршрутизатор выполняет операцию TTL=TTL-1. TTL помогает предотвратить зацикливание пакетов. Поле протокол аналогично полю тип в Ethernet-кадре и определяет структуру поля данные (см. табл. 4.4.1.2).
Поле контрольная сумма заголовка вычисляется с использованием операций сложения 16-разрядных слов заголовка по модулю 1. Сама контрольная сумма является дополнением по модулю один полученного результата сложения. Обратите внимание, здесь осуществляется контрольное суммирование заголовка, а не всей дейтограммы. Поле опции не обязательно присутствует в каждой дейтограмме. Размер поля опции зависит от того, какие опции применены. Если используется несколько опций, они записываются подряд без каких-либо разделителей. Каждая опция содержит один октет кода опции, за которым может следовать октет длины и серия октетов данных. Если место, занятое опциями, не кратно 4 октетам, используется заполнитель. Структура октета кода опции отражена на рис. 4.4.1.2.
Таблица 4.4.1.2. Коды протоколов Интернет
| Код протокола Интернет | Сокращенное название протокола | Описание |
| 0 | - | Зарезервировано |
| 1 | ICMP | Протокол контрольных сообщений [rfc792] |
| 2 | IGMP | Групповой протокол управления [rfc1112] |
| 3 | GGP | Протокол маршрутизатор-маршрутизатор [RFC-823] |
| 4 | IP | IP поверх IP (инкапсуляция/туннели) |
| 5 | ST | Поток [rfc1190] |
| 6 | TCP | Протокол управления передачей [RFC-793] |
| 7 | UCL | UCL |
| 8 | EGP | Протокол внешней маршрутизации [RFC-888] |
| 9 | IGP | Протокол внутренней маршрутизации |
| 10 | BBN-MON | BBN-RCC мониторирование |
| 11 | NVP-II | Сетевой протокол для голосовой связи [RFC-741] |
| 12 | PUP | PUP |
| 13 | ARGUS | argus |
| 14 | Emcon | emcon |
| 15 | Xnet | Перекрестный сетевой отладчик [IEN158] |
| 16 | Chaos | Chaos |
| 17 | UDP | Протокол дейтограмм пользователя [RFC-768] |
| 18 | MUX | Мультиплексирование [IEN90] |
| 19 | DCN-MEAS | DCN измерительные субсистемы |
| 20 | HMP | Протокол мониторирования ЭВМ (host [RFC-869]) |
| 21 | PRM | Мониторирование при передаче пакетов по радио |
| 22 | XNS-IDP | Xerox NS IDP |
| 23 | Trunk-1 | Trunk-1 |
| 24 | Trank-2 | Trunk-2 |
| 25 | Leaf-1 | Leaf-1 |
| 26 | Leaf-2 | Leaf-2 |
| 27 | RDP | Протокол для надежной передачи данных [RFC-908] |
| 28 | IRTP | Надежный TP для Интернет [RFC-938] |
| 29 | ISO-TP4 | iso транспортный класс 4 [RFC-905] |
| 30 | Netblt | Массовая передача данных [RFC-969] |
| 31 | MFE-NSP | Сетевая служба MFE |
| 32 | Merit-INP | Межузловой протокол Merit |
| 33 | SEP | Последовательный обмен |
| 34 | не определен | |
| 35 | IDRP | Междоменный протокол маршрутизации |
| 36 | XTP | Xpress транспортный протокол |
| 37 | DDP | Протокол доставки дейтограмм |
| 38 | IDPR-CMTP | IDPR передача управляющих сообщений |
| 39 | TP++ | TP++ транспортный протокол |
| 40 | IL | IL-транспортный протокол |
| 41 | SIP | Простой Интернет-протокол |
| 42 | SDRP | Протокол маршрутных запросов для отправителя |
| 43 | SIP-SR | SIP исходный маршрут |
| 44 | SIP-Frag | SIP-фрагмент |
| 45 | IDRP | Интер-доменный маршрутный протокол |
| 46 | RSVP | Протокол резервирования ресурсов канала |
| 47 | GRE | Общая инкапсуляция маршрутов |
| 49 | BNA | BNA |
| 50 | SIPP-ESP | SIPP ESЗ |
| 52 | I-NLSP | Интегрированная система безопасности сетевого уровня |
| 53 | Swipe | IP с кодированием |
| 54 | NHRP | nbma протокол определения следующего шага |
| 55-60 | не определены | |
| 61 | Любой внутренний протокол ЭВМ | |
| 62 | CFTP | CFTP |
| 63 | Любая локальная сеть | |
| 64 | Sat-Expak | Satnet и Expak |
| 65 | MIT-Subn | Поддержка субсетей MIT |
| 66 | RVD | Удаленный виртуальный диск MIT |
| 67 | IPPC | IPPC |
| 68 | Любая распределенная файловая система | |
| 69 | Sat-Mon | Мониторирование Satnet |
| 70 | не определен | |
| 71 | IPCV | Базовая пакетная утилита |
| 75 | PVP | Пакетный видео-протокол |
| 76 | BRsat-Mon | Резервное мониторирование Satnet |
| 78 | Wb-mon | Мониторирование Expak |
| 79 | Wb-expak | Широкополосная версия Expak |
| 80 | ISO-IP | iso Интернет протокол |
| 88 | IGRP | IGRP (Cisco) - внутренний протокол маршрутизации |
| 89 | OSPFIGP | OSPFIGP - внутренний протокол маршрутизации |
| 92 | MTP | Транспортный протокол мультикастинга |
| 101-254 | не определены | |
| 255 | зарезервировано |
/p>

Рис. 4.4.1.2. Формат описания опций
Флаг копия равный 1 говорит о том, что опция должна быть скопирована во все фрагменты дейтограммы. При равенстве этого флага 0 опция копируется только в первый фрагмент. Ниже приведены значения разрядов 2-битового поля класс опции:
| Значение поля класс опции | Описание |
| 0 | Дейтограмма пользователя или сетевое управление |
| 1 | Зарезервировано для будущего использования |
| 2 | Отладка и измерения (диагностика) |
| 3 | Зарезервировано для будущего использования |
| Класс опции | Номер опции | Длина описания | Назначение |
| 0 | 0 | - | Конец списка опций. Используется, если опции не укладываются в поле заголовка (смотри также поле "заполнитель") |
| 0 | 1 | - | Никаких операций (используется для выравнивания октетов в списке опций) |
| 0 | 2 | 11 | Ограничения,связанные с секретностью (для военных приложений) |
| 0 | 3 | * | Свободная маршрутизация. Используется для того, чтобы направить дейтограмму по заданному маршруту |
| 0 | 7 | * | Запись маршрута. Используется для трассировки |
| 0 | 8 | 4 | Идентификатор потока. Устарело. |
| 0 | 9 | * | Жесткая маршрутизация. Используется, чтобы направить дейтограмму по заданному маршруту |
| 2 | 4 | * | Временная метка Интернет |
Наибольший интерес представляют собой опции временные метки и маршрутизация. Опция записать маршрут создает дейтограмму, где зарезервировано место, куда каждый маршрутизатор по дороге должен записать свой IP-адрес (например, утилита traceroute). Формат опции записать маршрут в дейтограмме представлен ниже на рис. 4.4.1.3:

Рис. 4.4.1.3 Формат опций записать маршрут
Поле код содержит номер опции (7 в данном случае). Поле длина определяет размер записи для опций, включая первые 3 октета. Указатель отмечает первую свободную позицию в списке IP-адресов (куда можно произвести запись очередного адреса). Интересную возможность представляет опция маршрут отправителя, которая открывает возможность посылать дейтограммы по заданному отправителем маршруту. Это позволяет исследовать различные маршруты, в том числе те, которые недоступны через узловые маршрутизаторы. Существует две формы такой маршрутизации: Свободная маршрутизация и Жесткая маршрутизация. Форматы для этих опций показаны ниже:

Рис. 4.4.1.3а. Формат опций маршрутизации
Жесткая маршрутизация означает, что адреса определяют точный маршрут дейтограммы. Проход от одного адреса к другому может включать только одну сеть. Свободная маршрутизация отличается от предшествующей возможностью прохода между двумя адресами списка более чем через одну сеть. Поле длина задает размер списка адресов, а указатель отмечает адрес очередного маршрутизатора на пути дейтограммы.
IP-слой имеет маршрутные таблицы, которые просматриваются каждый раз, когда IP получает дейтограмму для отправки. Когда дейтограмма получается от сетевого интерфейса, IP первым делом проверяет, принадлежит ли IP-адрес места назначения к списку локальных адресов, или является широковещательным адресом. Если имеет место один из этих вариантов, дейтограмма передается программному модулю в соответствии с кодом в поле протокола. IP-процессор может быть сконфигурирован как маршрутизатор, в этом случае дейтограмма может быть переадресована в другой узел сети. Маршрутизация на IP-уровне носит пошаговый характер. IP не знает всего пути, он владеет лишь информацией – какому маршрутизатору послать дейтограмму с конкретным адресом места назначения.
Просмотр маршрутной таблицы происходит в три этапа:
Ищется полное соответствие адресу места назначения. В случае успеха, пакет посылается соответствующему маршрутизатору или непосредственно интерфейсу адресата. Связи точка-точка выявляются именно на этом этапе.
Ищется соответствие адресу сети места назначения. В случае успеха система действует также как и в предшествующем пункте. Одна запись в таблице маршрутизации соответствует всем ЭВМ, входящим в данную сеть.
Осуществляется поиск маршрута по умолчанию и, если он найден, дейтограмма посылается в соответствующий маршрутизатор.
Для того чтобы посмотреть, как выглядит простая маршрутная таблица, воспользуемся командой netstat –rn (ЭВМ Sun. Флаг -r выводит на экран маршрутную таблицу, а -n отображает IP-адреса в цифровой форме. С целью экономии места таблица в несколько раз сокращена).
| routing tables destination | gateway | flags | refcnt | use | interface |
| 193.124.225.72 | 193.124.224.60 | ughd | 0 | 61 | le0 |
| 192.148.166.1 | 193.124.224.60 | ughd | 0 | 409 | le0 |
| 193.124.226.81 | 193.124.224.37 | ughd | 0 | 464 | le0 |
| 192.160.233.201 | 193.124.224.33 | ughd | 0 | 222 | le0 |
| 192.148.166.234 | 193.124.224.60 | ughd | 1 | 3248 | le0 |
| 193.124.225.66 | 193.124.224.60 | ughd | 0 | 774 | le0 |
| 192.148.166.10 | 193.124.224.60 | ughd | 0 | 621 | le0 |
| 192.148.166.250 | 193.124.224.60 | ughd | 0 | 371 | le0 |
| 192.148.166.4 | 193.124.224.60 | ughd | 0 | 119 | le0 |
| 145.249.16.20 | 193.124.224.60 | ughd | 0 | 130478 | le0 |
| 192.102.229.14 | 193.124.224.33 | ughd | 0 | 13206 | le0 |
| default | 193.124.224.33 | ug | 9 | 5802624 | le0 |
| 193.124.224.32 | 193.124.224.35 | u | 6 | 1920046 | le0 |
| 193.124.134.0 | 193.124.224.50 | ugd | 1 | 291672 | le0 |
| u | Маршрут работает (up). |
| g | Путь к маршрутизатору (gateway), если этот флаг отсутствует, адресат доступен непосредственно. |
| h | Маршрут к ЭВМ (host), адрес места назначения является полным адресом этой ЭВМ (адрес сети + адрес ЭВМ). Если флаг отсутствует, маршрут ведет к сети, а адрес места назначения является адресом сети. |
| d | Маршрут возник в результате переадресации. |
| m | Маршрут был модифицирован с помощью переадресации. |

Рис. 4.4.1.4 Формат опции "временные метки"
Смысл полей длина и указатель идентичен тому, что сказано о предыдущих опциях. 4-битовое поле переполнение содержит число маршрутизаторов, которые не смогли записать временные метки из-за ограничений выделенного места в дейтограмме. Значения поля флаги задают порядок записи временных меток маршрутизаторами:
Таблица 4.4.1.3.
| Значение флага | Назначение |
| 0 | Записать только временные метки; опустить ip-адреса. |
| 1 | Записать перед каждой временной меткой ip-адрес (как в формате на предыдущем рисунке). |
| 3 | ip-адреса задаются отправителем; маршрутизатор записывает только временные метки, если очередной IP-адрес совпадает с адресом маршрутизатора |
Взаимодействие других протоколов с IP можно представить из схемы на рис. 4.4.1.5. В основании лежат протоколы, обеспечивающие обмен информацией на физическом уровне, далее следуют протоколы IP, ICMP, ARP, RARP, IGMP и протоколы маршрутизаторов. Чем выше расположен протокол, тем более высокому уровню он соответствует. Протоколы, имена которых записаны в одной и той же строке, соответствуют одному и тому же уровню. Но все разложить аккуратно по слоям невозможно - некоторые протоколы занимают промежуточное положение, что и отражено на схеме, (области таких протоколов захватывают два уровня. Здесь протоколы IP, ICMP и IGMP помещены на один уровень, для чего имеется не мало причин. Но иногда последние два протокола помещают над IP, так как их пакеты вкладываются в IP-дейтограммы. Так что деление протоколов по уровням довольно условно. На самом верху пирамиды находятся прикладные программы, хотя пользователю доступны и более низкие уровни (например, ICMP), что также отражено на приведенном рисунке (4.4.1.5).

Рис. 4.4.1.5. Распределение протоколов Интернет по уровням
Интернет - это инструмент общения, средство доступа к информации и как всякий инструмент требует практики. Из вашего собственного опыта вы знаете, что можно прочесть ворох инструкций о том, как забивать гвозди, но научиться этому можно лишь на практике. Поэтому рекомендую с самого начала, читая данные тексты, чаще садитесь за терминал.
IP - TCP - UDP - ARP - RARP

IP-туннели
4.4.1.2 IP-туннели
Семенов Ю.А. (ГНЦ ИТЭФ)

Особенность IP-протокола (опция принудительной маршрутизации) позволяет переадресовывать IP-дейтограммы определенным узлам сети. На первый взгляд эта возможность может показаться совершенно бесполезной, ведь существуют механизмы динамической маршрутизации, которые несравненно эффективнее и надежней обеспечивают обмен данными. Но тем не менее существуют приложения, где принудительная маршрутизация на IP-уровне представляет возможности недоступные для традиционных решений. Это прежде всего сети, работающие с использованием протоколов IPX/SPX (Novell), где традиционная маршрутизация не предусмотрена. Для подключений удаленных серверов, находящихся вне локальной сети, здесь используется технология так называемых IP-туннелей. При реализации этой технологии IPX-пакеты инкапсулируются в IP-дейтограммы и доставляются в соответствие с протоколами TCP/IP. Процедура инкапсуляции осуществляется специальным драйвером (IPtunnel; использует протокол IPxodi), который работает так, как если бы он был драйвером аппаратного сетевого интерфейса. При этом необходимо модифицировать конфигурационный файл net.cfg (См., например, www2.ncsu.edu/cc-consult/usinglwp/tunnel.html ).
;Техника IP-туннелей может оказаться иногда полезной и при администрировании маршрутизации, так как метрика внешних протоколов маршрутизации может не учитывать пропускную способность каналов и некоторые другие факторы, например, QoS. В этом случае IP-дейтограммы вкладываются в IP-дейтограммы отправителем (начало туннеля) и извлекаются оттуда в конце туннеля. Конец туннеля не обязательно совпадает с местом назначения пакетов. Такая простая схема туннелирования может порождать некоторые проблемы (см. рис. 4.4.1.2.1).

Рис. 4.4.1.2.1 Схема туннелирования пакетов. Квадратными скобками отмечено вложение пакетов. В числителе приводится адрес места назначения, в знаменателе адрес отправителя. Адрес вне скобок – адрес места назначения.
Из рисунка видно, что простой туннель может породить асимметричный маршрут, при котором путь туда и обратно не совпадают. Чтобы такого не произошло, применяется техника “маскарада” (masquerading). Для этого “маршрутизатор конца туннеля” должен извлечь вложенный пакет (как это он делает и на рис. 4.4.1.2.1) и вложить его в пакет с адресом места назначения IP3, указав при этом в качестве отправителя себя (IP3/IP2[IP3/IP1]). Тогда конечный адресат IP3 будет посылать отклики по адресу IP2, а не IP1. А уже маршрутизатор конца туннеля будет пересылать их первоисточнику запроса IP1.
В последнее время техника туннелей нашла применение при построении так называемых прокси-серверов, популярность которых связана с возможностью заметно сократить внешний (часто зарубежный) трафик за счет запоминания в дисковом буфере файлов, наиболее часто запрашиваемых клиентами. Заметно упрощает решение данной задачи многие современные маршрутизаторы, которые могут отфильтровывать запросы по определенным портам и переадресовывать их прокси-серверу (см. рис. 4.4.1.2.2).
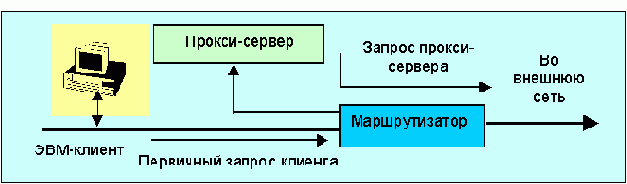
Рис. 4.4.1.2.2. Схема транспортировки запросов при использовании прокси-сервера
Схема с “невидимым” прокси-сервером работает следующим образом. Сначала запрос поступает в маршрутизатор, там он анализируется и, если выясняется что это HTTP или FTP-запросы, переадресуется прокси-серверу. Если запрашиваемый файл находится в буфере сервера, заказ клиента удовлетворяется локально. В противном случае запрос снова посылается маршрутизатору. Запросы прокси-сервера маршрутизатор переправляет во внешнюю сеть. В случае использования персональной ЭВМ в качестве прокси-сервера можно ее снабдить двумя сетевыми интерфейсами для приема и посылки запросов, что сделает работу более эффективной. Если маршрутизатор не поддерживает описанный режим, то при конфигурации сетевого программного обеспечения клиента можно явно прописать адрес прокси-сервера и все соответствующие запросы пойдут непосредственно туда.
Туннели широко используются и при передаче мультимедийных данных.
IPX-протокол
4.2.1.1 IPX-протокол
Семенов Ю.А. (ГНЦ ИТЭФ)
Оригинальный транспортный протокол Novell, на мой взгляд, не способствует успеху этой сети. Не успев своевременно переориентироваться на транспортные и маршрутные протоколы стека TCP/IP этот крайне популярный совсем недавно вид сетей в настоящее время имеет шансы исчезнуть.
IPX-пакеты, передаваемые по сети Ethernet, могут иметь несколько разных форматов. Старейший из них носит в Novell название “802.3” (информацию об интеграции сетей Novell и Интернет можно найти в документах: RFC-1234, -1420, -1553, -1634, -1792) и используется по умолчанию в версиях вплоть до 3.11. В последующих версиях форматом по умолчанию является “802.2”. Применим также и формат, называемый Ethernet II, который наиболее близок идеологии TCP/IP. Сеть в Netware - это логический канал, который используется совместно рядом узлов так, что они могут взаимодействовать друг с другом непосредственно. Так процессы, реализуемые на одном сервере, считаются подключенными к внутренней IPX-сети. Все пользователи сети типа Ethernet II образуют логическую сеть IPX. Все пользователи одной сети типа 802.3 рассматриваются как узлы различных сетей IPX. Сопоставление форматов пакетов для различных сетевых стандартов представлено на рис. 4.2.1.1.

Рис. 4.2.1.1. Форматы сетевых пакетов
Из рисунка видно, что различия непринципиальны и не препятствуют сосуществованию всех перечисленных форматов в пределах одной локальной сети. IPX-заголовок начинается сразу после поля Тип или Длина в зависимости от используемого протокола.
Серверы Netware можно сконфигурировать так, чтобы они воспринимали пакеты разных типов, и поэтому могли иметь непосредственные связи с разными сетями. IPX-сервер может выполнять и функции маршрутизатора. Формат заголовка пакета IPX показан на рис. 4.2.1.2. За заголовком следуют данные, их объем определяется кодом поля Длина пакета (минус 30) и лежит в диапазоне от 0 до 546 байт.

Рис. 4.2.1.2. Формат заголовка IPX-пакета
Поле Контрольная сумма (2 байта) устанавливается ipx-драйвером равным 0xffff, это означает, что контрольного суммирования не производилось. Приложениям разрешено использовать поле контрольной суммы при работе с кадрами Ethernet II, ieee 802.2 и Ethernet SNAP и запрещено для работы с кадрами ieee 802.3. Данное ограничение можно легко понять, обратившись к рис. 4.2.1.1. Контрольная сумма служит лишь для контроля правильности IPX-заголовка и не имеет никакого отношения к полю данных IPX-дейтограммы. Для того чтобы работать с контрольными суммами на NetWare-сервере, следует выдать команду set enable IPX checksum=n, где n указывает на то, что контрольная сумма использована. Возможные значения n и их смысл приведены ниже в таблице 4.2.1.1.
Таблица 4.2.1.1
2 - соединитель протокольных откликов; 3 - обработчик ошибок.
Некоторые номера заняты под нужды Netware:
| 0x451 | Протокол ядра NetWare (NCP - netware core protocol); |
| 0x452 | Протокол NetWare для оповещения об услугах (SAP - service advertising protocol); |
| 0x453 | Маршрутный протокол NetWare (RIP - routing information protocol); |
| 0x455 | Пакет протокола netbios; |
| 0x456 | Диагностический протокол NetWare; |
| 0x457 | Пакет сериализации (serialization). |
Приложение должно устанавливать поля тип пакета и адрес узла назначения, а IPX-драйвер заполняет остальные поля. Возможные значения кода поля тип пакета представлены в таблице 4.2.1.2.
Таблица 4.2.1.2 Коды типа IPX-пакета.
| Тип пакета | Значение |
| 0 | Обычный IPX-пакет |
| 1 | Пакет с маршрутной информацией (RIP - routing information protocol) |
| 2 | Отклик |
| 3 | Ошибка |
| 4 | Информационный пакетный обмен (pep - packet exchange protocol) |
| 5 | Последовательный пакетный обмен (SPX - sequence packet exchange) |
| 17 | Протоколы ядра NetWare (NCP) |
| 20 | Именной пакет netbios (широковещательный) |
Маршрутная информация передается между серверами и маршрутизаторами. Динамический маршрутный протокол RIP (routing information protocol, базируется на стандарте Xerox IP; cм. также RFC-1058) обеспечивает конечные станции информацией, которая необходима для динамического управления оптимизацией маршрутов. Рассылка маршрутной информации производится с помощью широковещательных пакетов. Как видим, сети Novell являются источником значительных потоков широковещательных пакетов. Аналогичным образом объекты сети оповещаются о других изменениях в сетевой среде, например, рассылка информации о доступных услугах (SAP - service advertisement protocol). Протокол SAP позволяет узлам, которые предлагают определенные услуги (например, файл-серверы или принт-серверы), сообщать о своих адресах и видах доступных услуг. Администратор может регулировать поток таких пакетов, задавая постоянные времени для таймеров обновления информации. Маршрутизаторы рассылают маршрутную информацию в пяти случаях:
При инициализации.
В случае, когда необходима исходная маршрутная информация (напр. в случае сбоя или порчи маршрутной таблицы).
Периодически для обновления маршрутных таблиц.
При изменении конфигурации маршрутов.
При отказе или отключении маршрутизатора.
Маршрутизация пакетов в сети достаточно проста. Каждому сетевому сегменту маршрутизатор присваивает номер в пределах от 1 до fffffffe. Каждой группе устройств присваивается “сетевой номер”, который представляет эту группу во всех маршрутизаторах сети. Пакеты, посылаемые от одного члена группы другому, посылаются непосредственно. Пакеты от одного члена группы к объекту из другой группы будут пересланы через маршрутизаторы. Для выбора маршрута в пределах локальной сети используется маршрутный протокол RIP. Формат пакета NetWare RIP показан на рис. 4.2.1.3.

Рис. 4.2.1.3. Формат RIP-пакета в NetWare
Поле тип пакета содержит код 0x0001, если это запрос, и 0x0002, если отклик. В поле адреса сети записывается адрес сети места назначения, если пакет является запросом. Если в поле записан код 0xff ff ff ff, это означает, что запрос относится ко всем известным сетям. Поле число шагов до цели имеет смысл лишь в случае пакетов-откликов. В этом случае сюда заносится число маршрутизаторов, которые должен пройти пакет по дороге к сети назначения. Поле время в тиках имеет смысл для пакетов-откликов и указывает на время, необходимое для достижения сети адресата. Один тик равен 1/18 секунды. Сходный протокол маршрутизации используется в сетях appletalk (RTMP).
Для межсетевой маршрутизации в Novell разработан протокол NLSP (NetWare link services protocol). NLSP базируется на той же идеологии, что и протокол IS-IS (intermediate system-to-intermediate system), созданный для сетей OSI и IP. В NLSP значение метрики маршрута задается вручную. nlsp-маршрутизаторы хранят полную карту сети, по которой принимаются решения о наилучших возможных маршрутах.
На рис. 4.2.1.4 представлена схема соответствия протоколов Novell и 7-уровневой модели osi.

Рис. 4.2.1.4. Схема соответствия протоколов Novell и модели osi
Протокол SAP ( service advertising protocol) служит для получения информации обо всех серверах, имеющихся в сети, и поддерживает следующие виды запросов и функции:
запрос SAP-сервиса;
оповещение об отключении сервера;
мониторинг откликов и некоторые другие.
Каждому серверу NetWare присваивает номер, а некоторые сервера могут иметь и имя. Номер сервера и его имя хранятся в базе данных объектов bindary каждого сервера. Пакет запроса SAP-сервиса содержит 2 байта типа пакета и два байта типа сервера. Поле тип пакета определяет, является ли данный пакет общим запросом сервиса (код=0x0003), или запросом ближайших услуг (код=0x0001). Таблица кодов поля тип сервера приведена ниже (4.2.1.3).
Таблица 4.2.1.3 Коды тип сервера (cм. также
ftp://ftp.isi.edu/in-notes/iana/assignments/novell-sap-numbers)
| Тип сервера | Описание |
| 0x0001 | Пользователь |
| 0x0004 | Файл-сервер |
| 0x0005 | Сервер заданий |
| 0x0006 | Внешний сетевой порт (gateway) |
| 0x0007 | Принт-сервер |
| 0x0009 | Сервер архива |
| 0x000a | Очередь задач |
| 0x0017 | Диагностика |
| 0x0020 | NetBios |
| 0x0021 | NAS SNA порт |
| 0x0027 | TCP/IP сервер порта |
| 0x0028 | Сервер моста x.25 точка-точка |
| 0x02e | Динамический SAP |
| 0x0047 | Оповещающий принт-сервер |
| 0x004b | vap 5.0 |
| 0x004c | SQL VAP |
| 0x007a | TES-NetWare VMS |
| 0x0098 | Сервер доступа к NetWare |
| 0x009a | Сервер именованных труб |
| 0x009e | Портативный NetWare-Unix |
| 0x0107 | NetWare 386 |
| 0x0111 | Тест-сервер |
| 0x0166 | Управление NetWare |
| 0x026a | Управление NetWare |
| 0x026b | Временная синхронизация |
| 0x0278 | Сервер каталогов NetWare |

Рис. 4.2.1.5. Формат пакета SAP
Поле тип пакета принимает значение 0x0002 для SAP-откликов общего обслуживания (General Service Response) и 0x0004 для отклика ближайшего сервера. Запросы о ближайшем сервере используются для поиска в сети сервера конкретной разновидности (пакет запроса содержит лишь первые два поля). Реально отклик будет получен от всех серверов данного типа, а не только от ближайшего. Насколько данный сервер близок, определяется по числу маршрутизаторов до него. Эти запросы/отклики служат для составления списка доступных серверов. Поле тип сервера содержит код доступного вида услуг, а в поле наименование сервиса записывается имя услуги уникальное для данного сервера (длина поля на рис. 4.2.1.5 равна N). Поле адрес сети представляет собой 4-байтовое число, которое идентифицирует адрес сервера. Поле адрес узла характеризует адрес сервера в сети. Службы NetWare указывают адрес 0x00.00.00.00.00.01. Поле дескриптор соединителя характеризует код соединителя, который будет использовать сервер. Последнее поле - число шагов до сервера (число транзитных сетей) характеризует число маршрутизаторов между сервером и клиентом. При отключении сервера от сети он должен широковещательно разослать SAP-уведомление “Останов сервера”. Уведомление содержит код сервера и его полный адрес.
Используемые стандарты
2.9.1 Используемые стандарты
Семенов Ю.А. (ГНЦ ИТЭФ)
112 Кбит/с (64 видео, 48 аудио);
128 Кбит/с (64 видео, 64 - аудио);
128 Кбит/с (96 видео, 32 -аудио);
128 Кбит/с (112 - видео, 16 -аудио);
384 Кбит/с (320 - видео, 64 аудио).
G.711
CCITT рекомендация для импульсно-кодовой модуляции (PCM) голоса с использованием m-закона кодирования при 8 кГц (8000 стробирований в сек)
G.721
CCITT рекомендация для адаптивной дифференциальной импульсно-кодовой модуляции (ADPCM) для кодирования звука с полосой 32 кГц.
G.722
CCITT рекомендация для ADPCM при 64 Кбит/с (7 кГц)
G.723
CCITT рекомендация для ADPCM при 24 Кбит/с
G.728
(CLEP) CCITT рекомендация для ADPCM при 16 Кбит/с (3.1 кГц)
H.221
CCITT рекомендация для структуры кадров аудио-видео каналов при скоростях 64 - 1920 Кбит/с.
H.261
или P*64- CCITT рекомендация для кодирования/декодирования аудио-видео процедур при скоростях p x 64 Кбит/с, где p=1-30, что эквивалентно 64 Кбит/с - 2 Мбит/с. Рекомендации первоначально были разработаны для узкополосного ISDN. Достижимы коэффициенты сжатия от 4:1 до 160:1. Регламентированы форматы:
CIF 352x288 15 кадров/сек.
Quarter CIF (QCIF) 176x144
CIF 704x576
QCIF 352x288
Super CIF 704x576.
H.320
CCITT рекомендации для узкополосных видео-телефонных систем и терминального оборудования со скоростями не более 1920 Кбит/с. Общее описание CODEC.
JPEG
- ISO/CCITT рекомендации объединенной группы фотоэкспертов. В рекомендации определен алгоритм сжатия для стационарных цветных изображений, при котором отбрасываются визуально второстепенные детали изображения, убирается избыточность в пределах кадра, в результате обеспечивается сжатие1:30 при потере качества изображения и 1:15 без потери качества.
JPEG
для движущегося изображения - стандарт JPEG, адаптированный для отображения движущегося изображения, обеспечивает индивидуальный доступ к кадрам и коэффициент сжатия информации 20:1.
MPEG-1
ISO/CCITT рекомендации группы экспертов по движущемуся изображению, определен алгоритм сжатия для движущегося изображения при работе с каналами 1.5 Мбит/с (1.2 Мбит/с видео + 200 Кбит/с для аудио) с коэффициентами сжатия от 50:1 до 200:1 при размере изображения 352x240x24 бит и частоте кадров 30/сек.
MPEG-2
ISO/ CCITT рекомендации группы экспертов по движущемуся изображению, поток данных для видео и аудио лежит в пределах между 4 и 15 Мбит/с, достигаются коэффициенты сжатия от 50:1 до 200:1, размер изображения 728x486, качество соответствует телевидению высокого разрешения стандарта NTSC (National Television Standards Committee US).
Сводные данные по стандартам для видеоконференций представлены в таблице 2.9.1.1. Новым универсальным набором стандартов для реализации видео-телефонии и мультимедийных обменов является H.323.
Таблица 2.9.1.1
V1/V2
ATM
LAT
H.263
G.722
G.728
G.722
G.728
G.722
G.728
G.722
G.728
G.723
G.729
H.242
H.242
H.243
H.243
H.243
I.363
AJM I.361
PHY I.400
TCP/IP
модем
Язык HTML
4.5.6.2 Язык HTML
Семенов Ю.А. (ГНЦ ИТЭФ)
и tbody
и basefont
HTML используется во всемирной информационной системе World Wide Web (WWW) с 1990 года (разработчик Tim Berners-Lee).
В настоящее время существует также простой диалект языка SGML - XML (Extensible Markup Language). Смотри http://win.www.citycat.ru/doc/html/xml/wd-xml-lang или www.w3.org/put/www/tr (первоисточник). Предполагается, что этот язык совместим с SGML и HTML (последнее справедливо лишь частично).
Любое приложение SGML состоит из нескольких частей:
SGML-декларация определяет, какие символы и разделители могут быть использованы в приложении.
dtd (document type definition) определяет стандарт на типы документов и задает синтаксис базовых конструкций.
Спецификация семантики, которая может также включать определенные ограничения на синтаксис, не включенные в DTD и т.д. …
SGML – это система описания языков разметки (markup). HTML – пример такого языка. Каждый язык разметки, определенный в SGML, называется приложением SGML. HTML 4.0 является приложением SGML, соответствующим международному стандарту international standard ISO 8879:1986 -- Standard Generalized Markup Language SGML (определено в [ISO8879]).
Приложение SGML характеризуется:
Декларацией SGML. SGML-декларация специфицирует, какие символы и разграничители могут использоваться в приложении.
Описанием типа документа DTD (Document Type Definition). DTD определяет синтаксис конструкций разметки. DTD может включать в себя дополнительные определения, такие как эталонные символьные объекты (entity).
Спецификацией, которая описывает семантику разметки. Эта спецификация также определяет синтаксические ограничения, которые не могут быть выражены в рамках DTD.
Примерами документов, содержащих данные и разметку. Каждый пример содержит ссылку на DTD, которая используется для его интерпретации.
HTML предоставляет разработчику следующие возможности:
Публиковать в реальном масштабе времени документы с заголовками, текстом, таблицами, рисунками, фотографиями и т.д.
Одним нажатием клавиши мышки извлекать документы через гипертекстные связи.
Конструировать формы (бланки) для осуществления удаленных операций, для заказа продуктов, резервирования билетов или поиска информации.
Включать электронные таблицы (напр. Excel), видеоклипы, звуковые клипы и другие приложения непосредственно в документ.
1. Синтаксис HTML
Символьные объекты (entity) представляют собой цифровые или символьные имена символов, которые могут быть включены в документ HTML. Эти объекты нужны в тех случаях, когда прямой их ввод по каким-либо причинам невозможен. Эти объекты начинаются с символа & и завершаются точкой с запятой (;).
Элементы в SGML представляют собой структуры или описывают требуемое поведение. Элементы начинаются со стартовой метки (TAG), за которой следует содержание, и завершаются конечной меткой. Стартовая метка обычно записывается как <имя_элемента>, а конечная метка, как </имя_элемента>. Некоторые элементы могут не иметь содержания или конечной метки. “Пустые” элементы не имеют конечной метки. Имена элементов обычно записываются прописными буквами, но HTML использование прописных или строчных букв в именах элементов не регламентировано.
Атрибуты. Элементы могут иметь определенные свойства, эти свойства характеризуются атрибутами, которым пользователь может присваивать некоторые значения. Пары атрибут/значение должны быть записаны до появления закрывающей угловой скобки (>) стартовой метки. Если используется несколько атрибутов/значений, они разделяются пробелами. Порядок их записи не играет роли. По умолчанию SGML требует, чтобы значения были помещены в двойные или одинарные кавычки. Для этих же целей могут использоваться символьные объекты " или " для двойной кавычки и ' для одинарной кавычки. Значения могут содержать помимо латинских букв и цифр символы (-) и (.). Имена атрибутов не чувствительны к тому, прописными или строчными буквами они напечатаны (как правило, их имена записываются в HTML строчными буквами).
Агент пользователя HTML – любой прибор, который интерпретирует HTML документы. К агентам пользователей относятся визуальные броузеры (текстовые и графические), не визуальные броузеры (звуковые и Брейля), поисковые роботы и т.д.. Агент пользователя должен игнорировать любые не узнанные атрибуты.
Пользователь – лицо, взаимодействующее с агентом пользователя, для того чтобы тем или иным способом ознакомиться с документом HTML.
URI. Любой ресурс в WWW – HTML документ, изображение, видео-клип, программа и пр. имеют адрес, который может быть представлен в виде универсального идентификатора ресурса (URI).
Комментарии в HTML имеют следующий синтаксис:
<!-- Комментарий -->
<!-- Если комментарий занимает более одной строки,
то он записывается так -->
dtd-комментарии выделяются двумя черточками (--) в начале и в конце текста.
HTML DTD начинается с серии описаний каких-то объектов (entities). Описание объекта представляет собой макрос, который может быть развернут где-либо в DTD(в HTML не применим). Когда макрос вызывается (по имени), он разворачивается в строку.
Описание объекта (entity) начинается с ключевого слова <!entity %, за которым следует имя объекта и помещенная в кавычки строка, которая разворачивается. Описание завершается символом >. Развертываемая строка может содержать другие имена объектов. Конкретные значения объекта начинаются с символа “%” и завершается опционно символом “;”. Эти объекты будут также развернуты (если требуется рекурсивно). Например:
<!entity %fontstyle “tt | i | b | big | small”>
<!entity %inline “#pcdata | %fontstyle; | %phrase; | %formctrl;”>
Большая часть HTML DTD состоит из описаний элементов и их атрибутов. Ключевое слово <!element> открывает описание элемента, а символ > - завершает. Между ними размещается имя элемента, две черточки после имени указывают на то, что стартовая и конечная метки являются обязательными. Одна черточка после имени элемента и последующая буква О указывают на то, что конечная метка может отсутствовать. Две буквы О означают допустимость отсутствия как стартовой, так и конечной метки. После имени может следовать содержимое элемента, которое называется моделью содержимого. Элементы без содержимого называются пустыми (empty). Пустые элементы описываются ключевым словом “empty”. Например, <!element ccc – o empty>. ccc – имя элемента; - О говорит о допустимости отсутствия конечной метки. В сочетании с моделью empty это означает, что конечная метка должна отсутствовать.
Модель содержимого описывает то, что может содержать элемент. Определения содержимого могут включать:
Имена допустимых и запрещенных элементов.
dtd-объекты.
Текст документа, отмеченный SGML-конструкцией “#pcdata”. Текст может содержать цифровые и именные символьные объекты.
Модель содержимого имеет следующий синтаксис.
| (…) | специфицирует группу. |
| А|b | Допускается присутствие А и В в любом порядке. |
| А,В | А должно появиться раньше, чем В. |
| a&b | a и b должны появиться только один раз, но в любом порядке. |
| А? | А может появиться не более одного раза. |
| А* | А может появиться любое число раз, включая 0. |
| А+ | А может появиться один или более раз. |
<!element select - - (option+)>
Элемент select должен содержать один или более элементов option.
<!element dl - - (dt|dd)+>
Элемент dl должен содержать один или более dt или dd элементов в любом порядке.
<!element option – o (#pcdata) *>
Элемент option может содержать только текст и символьные объекты.
2. Описания атрибутов
Описание атрибутов начинается с ключевого слова <!attlist>. Описание атрибута включает в себя:
Имя атрибута.
Тип значения атрибута или набор возможных значений.
Значение атрибута может быть определено тремя способами. Когда значение атрибута по умолчанию задано неявно (ключевое слово “#implied”), оно должно быть задано агентом пользователя или наследуется из определения порождающего элемента. Возможны также ключевые слова “#required” (всегда необходимо) и “#fixed” - присвоено фиксированное значение.
Рассмотрим описание элемента map с опционным атрибутом.
<!attlist map name cdata #implied >, здесь тип допустимого значения задан DATA (тип данных SGML). CDATA – представляет собой текст, который может содержать символьный объекты.
Описания атрибутов могут содержать объекты DTD. Например:
| <!attlist link %attrs; | -- id, class, style, lang, dir, title – |
| bref %url @implied | -- url для подключенного ресурса -- > |
/p> Объект %attrs разворачивается в:
| <!attrlist p | id id #implied -- уникальный идентификатор для данного документа -- | |
| class cdata #implied | -- список значений классов -- | |
| style cdata #implied | -- информация о стиле -- | |
| title cdata #implied | -- рекомендуемые заголовки/расширения -- | |
| lang name #implied | -- [rfc1766] код идентификатор языка -- | |
| dir (ltr|rtl) #implied | -- direction for weak/neutral text -- | |
| align (left|center|right|justified) #implied > |
<!entity % URL “CDATA” -- термин URL означает атрибут, значение которого равно универсальному указателю ресурса URL (uniform resource locator), см. RFC-1808 и RFC-1738 -->
2.1. Булевы атрибуты
Некоторые атрибуты выполняют роль булевых переменных. Их появление в стартовой метке элемента предполагает, что значение атрибута равно “true” (истинно). Их отсутствие означает, что их значение равно “false” (ложно). В HTML допускается сжатая форма записи булевых атрибутов:
<option selected> вместо
<option selected=”selected”>.
3. HTML и URL
World Wide Web (WWW) представляет собой всемирную сеть информационных ресурсов. WWW базируется на трех механизмах, которые обеспечивают доступ к этим ресурсам:
Однородная схема имен для описания положения ресурсов в сети WWW(например, URI).
Протоколы доступа к именованным ресурсам через WWW-сеть (напр., HTTP).
Гипертекст, который обеспечивает простую технику поиска и перемещения (навигации) в сетях WWW (например, HTML).
Каждый ресурс, доступный в WWW (HTML-документ, видео-клип, программа или статическое изображение) имеет адрес, который кодируется с помощью универсального идентификатора ресурса universal resource identifier, или uri. URI состоит из трех частей:
Схема имен механизмов доступа к ресурсам [см. RFC-2068; далее в тексте данного документа ссылки на публикации и сервера, представленные в конце выделены квадратными скобками [].].
Имя машины, где размещается ресурс.
Имя самого ресурса в виде прохода к нему (path).
Примером URI может служить адрес, где размещено описание языка HTML v4.0:
http://www.w3.org/tr/rec-html4/
Этот URI можно воспринимать следующим образом: имеется документ, доступный через протокол HTTP (см. [RFC-2068]), этот документ находится на ЭВМ www.w3.org, проход к нему имеет вид /tr/rec-html4/.
Замечание. Большинство читателей знакомо с термином URL (Universal Resource Locator; [RFC-1738]) URL представляет собой подмножество более общей системы имен URI.
Следует помнить, что запись URL чувствительна к тому, строчные или прописные буквы используются при его написании (это не относится только к имени ЭВМ).
Спецификация URL определяет положение документа в сети, но не позицию внутри документа. По этой причине введено понятие URL-фрагмента, который может указывать на определенную часть документа. URL-фрагмент завершается символом #, за которым следует идентификатор указателя (anchor). Примером такого URL-фрагмента может служить http://store.in.ru/semenov/intro.htm#intr_1, где int_1 - имя метки в тексте документа intro.htm.
Для локальной адресации HTML-документов используется относительные URL, которые не имеют секций протокола и ЭВМ. Относительный URL может содержать компоненты относительного прохода к ресурсу (“..” означает положение порождающего URL). Документ RFC-1808 определяет алгоритм работы с относительными URL. Относительный URL может быть частью полного URL. Полный URL можно определить следующим образом:
Если базовый URL завершается символом (/), то он получен путем добавления относительного URL. Например, если базовый URL http://nosite.com/dir1/dir2/, а относительный – gee.html, то полный URL будет выглядеть как http://nosite.com/dir1/dir2/gee.html.
Если базовый URL не завершается /, последнюю секцию базового URL следует рассматривать как ресурс.
Для связи через электронную почту иногда используется специальная разновидность URL – mailto, которая имеет формат:
mailto:e-mail_адрес.
В HTML, URI используются для:
Связи с другим документом или ресурсом (см. элементы a и link).
Связи с внешним стилевым списком или скриптом (см. элементы link и script ).
Включения изображений объектов или аплетов в страницу (см. элементы img, object, applet и input).
Создания карты изображения (см. элементы map и area).
Предоставления форм (см. form).
Создания рамочных документов (см. элементы frame и iframe).
Цитирования внешних ссылок (см. элементы q, blockquote, ins и del).
Ссылок на соглашения по метаданным, описывающим документ (см. элемент head).
Поскольку люди на Земле пока используют различные языки, в которых применяются совершенно не схожие наборы символов, необходимо как-то управлять процессом описания набора символов, используемого в данном документе. Для документов HTML используется универсальный набор символов UCS (Universal Character Set) [ISO10646; cм. также RFC-2070]. Этот набор эквивалентен Unicode 2.0 [unicode]. Агент пользователя может получить, послать или воспроизвести документ в любой кодировке. Это может быть набор ISO-8859-1 (“latin-1”), ISO-8859-5 (кирилица), shift_jis (японская кодировка) и так далее. Пользователь должен позаботиться, чтобы его документ в конечном итоге был приведен в соответствие с Unicode, тогда у него не будет более проблем с национальным шрифтовым набором.
Для того чтобы облегчить представление полученного документа, можно проанализировать первые несколько байт документа и в процессе пересылки соответствующим образом задать параметр charset поля “content-type”. Например:
content-type: text/html; charset= euc-jp
В качестве значения параметра charset может быть выбрано стандартное имя из документа [RFC-2045]. Но, к сожалению, отнюдь не все сервера присылают информацию об используемом символьном наборе даже в случае несовпадения с ISO-8859-1. Другим способом решить проблему является включение в заголовок документа соответствующего meta-элемента. Например:
<meta http-equiv=”content-type” content=”text/html; charset=euc-jp”>
Здесь крайне важно, чтобы агент пользователя был способен правильно интерпретировать элемент meta-декларации. Если других указаний не распознано, считается, что использован набор ISO-8859-1.
Значение типа атрибута “color” служит для описания цвета. Значение этого атрибута может быть шестнадцатеричным числом, перед которым записывается символ #, или одним из 16 имен цветов:
| black=”#000000” | white=”#ffffff” |
| silver=”#c0c0c0 | gray=”#808080” |
| green=”#008000” | lime=”#00ff00” |
| olive=”#808000” | maroon=”#800000” |
| yellow=”#ffff00” | aqua=”#00ffff” |
| red=”#ff0000” | blue=”#0000ff” |
| purple=”#800080” | teal=”#008080” |
| fuchsia=”#ff00ff” | navy=”#000080” |
HTML-документ состоит из трех частей, строки с информацией о версии, секции заголовка и собственно содержания документа. В первой строке документа должна быть внесена конструкция doctype, описывающая использованную версию HTML. Например:
<!doctype html public “-//w3c//dtd html 4.0 draft//en”>
Последние две буквы этой декларации характеризуют язык HTML dtd, в данном случае английский (“en”). Агент пользователя может игнорировать эту информацию. Слово draft говорит о том, что использована предварительная версия HTML 4.0. В случае работы с окончательной версией html 4.0 это слово должно быть заменено на strict. Часть документа, следующая после описания версии, должна быть оформлена в виде HTML-элемента. Таким образом, HTML-документ имеет следующую структуру:
<!doctype html public -//w3c//dtd html 4.0 draft//en>
<html>
Заголовок, текст документа …
</html>
Рассмотрим возможные варианты HTML-элементов.
<!entity % version “version cdata #fixed ‘%html.version;’”>
<!entity % html.content “head, (fragment|body) “>
<!entity html o o (%html.content)>
<!attlist html %version; %i18n; >
Стартовая и конечная метки являются опционными.
Ниже приведены примеры элементов-заголовков.
<!entity % head.content “title & isindex? & base?”>
<!element head o o (%head.content) +(%head.misc)>
<!attlist head %i18n; profile %url #implied – named directory of meta info -- >
Для элемента title стартовая и конечная метки являются обязательными. Элемент head содержит информацию о документе, он не является частью текста и служит в качестве источника ключевых слов для поисковых систем. HTML-документ должен иметь только один элемент title в секции head.
Не следует путать элемент title с атрибутом title, который предоставляет справочную информацию об элементе, для которого установлен. Атрибут title имеет формат: title=cdata. В отличие от элемента title, который характеризует весь документ в целом и может появиться в пределах документа только раз, атрибуту title позволено аннотировать любое число элементов. Агент пользователя может интерпретировать этот атрибут самым различным способом. Визуальные броузеры могут отобразить его текст в качестве совета, аудио агент может воспроизвести текст, говорящий о ресурсах подключенного сервера. Специфическую роль играет атрибут title при использовании для элемента link.
В html 4.0 программист может использовать метаданные в своем документе следующим способом:
Можно описать свойства метаданных во внешнем профайле. Профайл может определить свойства вспомогательной системы поиска (help), такой как “автор”, “ключевые слова” и т.д..
Программист может установить значения определенных параметров. Это можно сделать внутри документа с помощью meta-элемента. В этом случае профайл определяет имена свойств, которые могут быть заданы с помощью META-элемента. Установить конкретные значения можно и извне, связав метаданные с элементом link. В этом варианте профайл определяет имена соотношений типов, которые может использовать элемент LINK.
Если профайл определен для элемента Head, тот же профайл будет присутствовать во всех элементах META и LINK в заголовке документа. Ниже приведены примеры записи элементов meta.
| <!element meta – o empty | -- Базовая метаинформация --> |
| <!attlist meta %i18n; | -- lang, dir, для использования со строкой содержимого -- |
| http-equiv name #implied | -- имя заголовка http-отклика -- |
| name name #implied | -- Имя метаинформации -- |
| content cdata #required | -- соответствующая информация -- |
| scheme sdata #implied | -- select form of content --> |
/p> Для META-элемента стартовая метка необходима, а конечная не нужна. Атрибуты, их значения и интерпретация зависят от профайла.
| name=Cdata | Этот атрибут определяет имя свойства. |
| content=Cdata | определяет значение свойства. |
| scheme=Cdata | определяет схему интерпретации значения свойства. |
| HTTP-equiv=cdata | может использоваться вместо атрибута name. http-серверы используют этот атрибут при сборе информации для заголовков откликов. |
<meta name=”interpreter” lang=”ru” content=”semenov”>.
Некоторые агенты пользователья используют meta для обновления текущей страницы каждые несколько секунд. При этом страница может обновляться полностью. Например:
<meta name=”refresh” content=”3,http://www.acme.com/intro.html”>
Слово content определяет задержку в секундах, за этим числом следует URL, который должен быть загружен по истечении указанного времени. К сожалению не все агенты пользователя поддерживают такую возможность.
Атрибут HTTP-equiv может использоваться вместо атрибута name. HTTP-серверы могут работать с именами свойств, заданными атрибутом HTTP-equiv, что позволяет им формировать заголовок HTTP-отклика согласно требованиям RFC-822. Декларация <meta http-equiv=”expires” content=”Mon, 17 Aug 1998 16:35:08 GMT”> приведет к формированию следующей строки в HTTP-заголовке: expires: Mon, 17 Aug 1998 16:35:08 GMT. Это позволяет определить время доступности свежей копии документа.
Одним из важных функция элемента meta является описание ключевых слов для поисковых систем. Например:
<meta name=”keywords” content=”information, retrieval, indexing”>
4. Элементы, используемые в тексте документа
<!entity % block “(%blocklevel | %inline)*”>
<!entity % color “cdata” – a color using srgb: #rrggbb as hex values -->
| <!entity % bodycolors “bgcolor | %color #implied | |
| text | %color #implied | |
| link | %color #implied | |
| vlink | %color #implied | |
| alink | %color #implied”> |
<!attlist body
| %attrs; | -- %coreattrs, %i18n, %events – | |
| background %url #implied | -- раскладка текстуры для фона документа -- | |
| %bodycolors; | -- bgcolor, text, link, vlink, alink – | |
| onload %script #implied | -- документ загружен -- | |
| onunload $script #implied | -- документ удален --> |
| Background=URL | указывает на место, где лежит изображение мозаичного образа для фона документа. |
| text=color | устанавливает фоновый цвет для текста. |
| Link=color | определяет цвет не посещенных гипертекстных объектов. |
| vlink=color | определяет цвет посещенных гипертекстных объектов. |
| alink=color | определяет цвет выбранного пользователем объекта. |
id, class, (идентификаторы действуют для всего документа) lang (языковая информация), dir (направление текста/отступ), title, style (текущая стилевая информация), bgcolor (цвет фона), onload, onunload, onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (действительные события).
Презентация документа определяется стилем (использование атрибутов презентации не желательно). Атрибуты презентации могут применяться только для агентов пользователя, не поддерживающих стили. Ниже представлена иллюстрация представления документа, где фон имеет белый цвет, текст черный, гиперсвязи в исходный момент красные, темные при активации и темно бордовые после первого визита.
<html>
<head>
| <title> a study of population dynamics </title> |
<body bgcolor=”white” text=”black” link=”red” alink=”fuschia” vlink=”maroon”>
… текст документа …
</body>
</html>
То же самое с использованием стилевого листа.
<html>
<head>
| <title> a study of population dynamics </title> |
| body { background: white color: black} | |
| a:link { color: red } | |
| a:visited { color: fuschia } |
</head>
<body>
| …текст документа … |
</html>
Использование связанного стилевого листа добавляет гибкости при реализации презентации.
<html>
<head>
| <title> a study of population dynamics </title> |
</head>
<body>
| …текст документа… |
</html>
5. Идентификаторы элементов. ID и атрибуты классов.
Определения атрибутов
ID = name
Этот атрибут присваивает имя элементу, которое действительно в пределах данного документа. Значение ID должно быть уникальным для данного документа.
class = cdata-list
Этот атрибут присваивает некоторому элементу значение класса или набора классов. Одно и тоже имя класса может быть присвоено любому числу элементов. Значение класса позволяет определить или уточнить функцию данного элемента или группы элементов.
Эти атрибуты могут использоваться в следующих случаях:
Атрибут id может использоваться в качестве адреса места назначения гипертекстной связи.
Атрибут id может использоваться скриптами для ссылки на какой-то конкретный элемент.
Стилевые листы могут использовать атрибут ID для того, чтобы определить элемент, на который распространяется действие данного стиля.
Атрибут ID может использоваться для идентификации деклараций object.
Стилевые листы могут использовать атрибут class для идентификации списка элементов, на которые распространяется действие данного стиля.
Атрибуты id и class могут использоваться для целей обработки, например, для идентификации полей при извлечении информации с HTML-страниц в базу данных, при трансляции HTML-документов в другие форматы.
Предположим, что пишется документ о языке программирования. Документ включает в себя некоторое число отформатированных примеров. В этом случае для форматирования используется элемент pre. Пусть также задан цвет фона = green для всех случаев, когда элемент pre принадлежит классу “example”.
<head>
<style pre.example { background : green } </style>
</head>
<body>
<pre class = “example” id = “example-1”>
… текст программы примера …
</pre>
</body>
5.1. Элемент html
<!entity % html.content "head, body">
| <!element html o o (%html.content;) | -- корневой элемент документа --> |
| <!attlist html %i18n; | -- lang, dir -- > |
version = cdata [cn]
Применять не рекомендуется. Значение атрибута специфицирует то, какая версия HTML DTD используется в данном документе. Этот атрибут не рекомендован из-за того, что в качестве стандарта принято определение версии в декларации типа документа.
После декларации типа документа оставшаяся часть документа содержит элемент HTML. Таким образом, HTML-документ имеет структуру:
<!doctype html public "-//w3c//dtd html 4.0//en"
"http://www.w3.org/tr/rec-html40/strict.dtd">
<html>
...Заголовок, тело, и т.д. следует здесь...
</html>
5.2. Группирующие элементы div и span
<!element div - - %block>
Атрибуты определенные где-то еще
id, class (идентификаторы, действующие в пределах документа)
lang (языковая информация), dir (направление текста/отступ)
title (заголовок элемента)
style (текущая стилевая информация)
align (выравнивание)
onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (события)
Элементы div и span в сочетании с атрибутами id и class предлагают обобщенный механизм структурирования документа. Таким образом, сформировав примеры и классы и используя для них стилевые листы, программист может придать HTML-документу необходимую структуру и форму.
Предположим нужно сформировать документ на основе базы данных клиента. Так как HTML не имеет элементов, идентифицирующих такие объекты как “клиент”, “телефонный номер” и т.д., для решения стоящей задачи воспользуемся элементами div и span.
В приведенном примере каждое имя клиента принадлежит классу client-last-name. Присвоим также уникальные идентификаторы каждому клиенту (client-stepanov, client-ivanov).
<div id=”client-stepanov” class=”client”>
<span class=”client-last-name”>last name:</span> stepanov,
<span class=”client-first-name”>first name:</span> stepa
<span class=”client-tel”>telephone:</span> (095) 123-9442
<span class=”client-email”>email:</span> s.s@itep.ru">s.s@itep.ru
</div>
<div id=”client-ivanov” class=”client”>
<span class=”client-last-name”>last name:</span> ivanov,
<span class=”client-first-name”>first name:</span> vanja
<span class=”client-tel”>telephone:</span> (095) 123-5442
<span class=”client-email”>email:</span> s.s@itep.ru">v.i@itep.ru
</div>
Позднее может быть легко добавлена стилевая информация для тонкой настройки представления записей этой базы данных.
span является строчным элементом и его зона ответственности – параграф. span не может быть использован для группирования элементов блочного уровня. div, напротив, предназначен для работы с блочными элементами. div элемент, за которым следует незакрытый p-элемент, завершает параграф. Агент пользователя помещает разрыв строки до и после div-элемента, например строка:
<p>aaaaaa<div>bbbbbb</div><div>ccccc<p>ccccc</div>
обычно развертывается в:
aaaaaa
bbbbbb
ccccc
ccccc
Агент пользователя развернет ее как:
aaaaaabbbbbbccccc
ccccc
5.3. Элементы заголовков h1, h2, h3, h4, h5, h6
<!entity % heading “h1, h2, h3, h4, h5, h6”>
<!-- Существует шесть уровней заголовков, начиная с Н1 (наиважнейший), кончая Н6 -- >
<!element (%heading) - - (%inline;)*>
Элементы заголовка кратко описывают тему раздела, который они открывают. Содержимое заголовка может использоваться агентом пользователя, например, для автоматического формирования оглавления документа.
Визуальные броузеры отображают заголовки более высокого уровня буквами более крупного кегля. Ниже приведен пример использования div-элемента для установления связи заголовка со следующей за ним секцией документа. Это позволяет определить стиль раздела с помощью стилевых листов.
<div class=”section” id=”forest-elephants” >
<h1>forest elephants </h1>
В этом разделе обсуждаются менее известные лесные слоны.
… далее следует продолжение текста …
<div class=”subsection” id=”forest-habitant” >
<h2> habitant </h2>
Лесные слоны живут не на деревьях (:-))
… далее следует рассказ о том, где и как живут лесные слоны …
</div>
</div>
Структура может быть улучшена с помощью стилевой информации, например:
<head>
<style>
div.section { text-align: justify; font-size: 12pt }
div.subsection { text-ident: 2em }
h1 {font-style: italic; color: green }
h2 { color: green }
</style>
</head>
5.4. Элементы address
<!element address - - ((%inline;) | p) *>
Элемент address служит для введения контактного адреса с автором документа, например:
<address>
newsletter editor<br>
j. r. brown<br>
8723 buena vista, smallville, ct 01234<br>
tel: +1 (123) 456 7890
</address>
6. Спецификация языка содержимого документа. Атрибут lang
lang = language-code
Специфицирует базовый язык, на котором написан документ. Значением этого атрибута является код языка (см. RFC-1766). В пределах кода языка пробелы использоваться не должны. Значение этого кода по умолчанию “unknown”. Код языка состоит из базового кода и субкода.
language-code = primary-code *( “-“ subcode )
Атрибуты, определенные где-либо еще.
id, class (идентификаторы, действующие в пределах документа)
lang (языковая информация), dir (направление текста/отступ)
onclick, ondblclick, onmousedown, onmouseup, onmouseover, onmousemove, onmouseout, onkeypress, onkeydown, onkeyup (события)
Ниже приведено несколько примеров кодов языка.
“en”:english
“en-us”:the u.s version of english
Две первые буквы базового кода зарезервированы ISO-639.
| fr | французский |
| de | немецкий |
| it | итальянский |
| nl | голландский |
| el | греческий |
| es | испанский |
| pt | португальский |
| ar | арабский |
| he | еврейский |
| ru | русский |
| zh | китайский |
| ja | японский |
| hi | хинди |
| ur | урду |
7. Наследование языковых кодов
Элемент наследует информацию языкового кода согласно следующим приоритетам (сверху вниз):
Атрибут lang устанавливает значение элемента.
Глобальный элемент, имеющий атрибут lang.
http заголовок “content-language”, устанавливающий значения языка, например,
content-language: en-us.
Задание языкового атрибута извне.
В ниже приведенном примере базовый язык документа является французским. Один параграф декларирован как испанский, после чего базовый язык восстанавливается. Следующий параграф включает встроенную фразу на японском, после чего следует снова текст на французском.
<html lang=”fr”>
<body>
… текст интерпретируется как французский …
<p lang=”es”>… текст интерпретируется как испанский …
<p>… текст интерпретируется снова как французский …
<p> … французский текст интерпретируется с помощью <em lang=”ja”> немного японского </em> далее следует снова текст на французском …
</body>
</html>
8. Спецификация направления текста. Атрибут dir
Описание атрибута
dir = ltr | rtl
Специфицирует направление размещения текста, возможные значения:
ltr: слева направо
rtl: справа налево.
Последнее значение атрибута может быть нужно для случая арабского или еврейского текстов. Агент пользователя не может использовать атрибут lang для определения направления текста.
9. Текст
Пробел
Спецификация SGML делает различие между начальным символом (перевод строки) и концом записи (возврат каретки). Но существует большое разнообразие использования этих символов в различных системах и агент пользователя должен быть способен корректно обрабатывать все варианты. Аналогично меняется от скрипта к скрипту представление о том, что такое разделитель слов. В латинских текстах это пробел (десятичный код 32), в японском и китайском пробел игнорируется, а в тайском используется нуль-сепаратор. Что же касается самого HTML, здесь функции сепаратора выполняет код пробела. Набор символов документа включает в себя широкое разнообразие символов пробела. Многие из них являются типографскими элементами, которые служат для формирования зазоров между словами или буквами. В HTML, определены только следующие символы пробела:
ascii пробел ( )
ascii tab (	)
ascii form feed ()
пробел нулевой ширины (​)
Разрыв строки также является пробелом. Заметьте, что 
 и 
 определенные в [ISO10646] для разделения строк и параграфов, соответственно, не являются разрывами строк в HTML.
Пример текста:
<p>
this example shows a paragraph and a list
</p>
<ul>
the <em>первый</em> item
</li>
this is the <em>второй</em> item
</li>
</ul>
текст может быть переписан с пропуском конечных меток и размещен иначе с использованием меньшего числа пробелов.
<p>this example shows a paragraph and a list
<ul>
</ul>
Элемент pre используется для уже сформатированных фрагментов текста, где важны пробелы.
9.1. Структурированный текст
Элементы фраз: em, strong, dfn, code, samp, kbd, var, cite, acronym
<!entity % phrase “em | strong | dfn | code | samp | kbd | var | citr | acronym”>
<!element (%font|%phrase) - - (%inline) *>
Элементы фраз добавляют структурную информацию к текстовым фрагментам. Элементы фраз имеют следующие значения:
em: |
Подчеркивают значение. |
strong: |
Указывает на еще большую важность (придает выразительность) |
dfn: |
Указывает, что это место определения вложенного термина. |
code: |
Отмечает фрагмент текста программы. |
samp: |
Выделяет пример из текста программы или скрипта. |
kbd: |
Отмечает текст, который должен быть введен пользователем. |
var: |
Отмечает переменную или аргумент программы |
cite: |
Ссылается на фрагмент текста или другой источник. |
acronym: |
Отмечает акроним (напр. HTML, URI, WWW и т.д.). |
“More information can be found in <cite>[ISO-0000]</cite>
“Please refer to the following reference number in future correspondence:
<strong>1-234-55</strong>”
Элемент acronym позволяет упростить работу программ проверки правописания и звуковых синтезаторов речи. Текст элемента acronym позволяет описать сам акроним:
<acronym title=”world wide web”>www</acronym>
<acronym lang=”fr” title =”société nationale de chemins de fer”> sncf
</acronym>
Представление элементов фраз зависит от агента пользователя. Визуальные броузеры отмечают фрагменты текста EM курсивом, а фрагменты strong - полужирным шрифтом. HTML не выделяет аббревиатур и акронимов, по этой причине в текстах, ориентированных на звуковое воспроизведение, следует позаботиться о создании специальных словарей, подключенных к тексту с помощью элементов link в заголовке документа.
9.2. Цитирование. Элементы q и blockquote
<!element blockquote - - %block>
Определения атрибутов
cite=url
Значение этого атрибута равно url, который указывает на первоисточник или сообщение. Аргумент указывает на источник цитаты, заключенной в кавычки. Элемент q служит для использования с короткими цитатами в пределах абзаца, а blockquote предназначен для более длинных. Например:
<blockquote cite=http://www.mycom.com/tolkien/twotpwers.html>
they went in single file, running like hounds on a strong scent, and an eager light was in their eyes.
</blockquote>
9.3. Верхние и нижние индексы. Элементы sub и sup
<!element (sub|sup) - - (%inline) *>
Например, французское “mlle dupont” можно представить в HTML как:
m<sup>lle</sup> dupont
9.4. Строки и параграфы
Любой текст обычно представляется в виде последовательности параграфов. Для определения границ параграфа в HTML используется элемент p. Текст параграфа будет использоваться как единое целое при ряде процедур.
9.4.1. Параграфы и элемент p
<! element p – o (%inline) *>
| <!attlist p %attrs; | -- %coreattrs, %i18n, %events | |
| %align; | -- выравнивание текста -- > |
<p>Это первый параграф.</p>
<p>Это второй </p>
… блочный элемент …
Этот же текст можно переписать эквивалентным образом:
<p>Это первый параграф.
<p>Это второй.
…блочный элемент …
Аналогично параграф может быть сформирован с помощью блочных элементов:
<div>
<p> Это параграф
</div>
Пустой параграф является дурным стилем и должен игнорироваться агентом пользователя. Агент пользователя определяет способ отображения параграфа. Параграфы могут иметь абзацы, а могут отделяться друг от друга пустой строкой. Обычно в процессе отображения строки разрываются по пробелам между словами, но можно ввести принудительные разрывы строк с помощью элемента BR.
9.5. Элемент br
<! element br – o empty |
-- вызывает разрыв строки -- > | |
| <!attlist br %coreattrs; | -- id, class, style, title -- | |
| clear (left|all|right|none) none | -- управление отображением текста -- > |
Помимо принудительного разрыва строки существует элемент, запрещающий разрыв строки между двумя словами. Например entity ( ,  ) действует как пробел, где агент пользователя не должен разрывать строку.
В HTML существует два вида дефисов: мягкий и твердый. Твердый рассматривается как обычный символ, а мягкий воспринимается агентом пользователя как место, где можно разорвать строку. Твердый дефис обозначается символом “-“ (-,-), а мягкий – именованным символом ­ (­,­).
9.6. Предварительно сформатированный текст. Элемент pre.
<!entity % pre.exclusion “img|big|small|sub|sup|font”>
<!element pre - - (%inline) * - (%pre.exclusion)>
| <!attlist pre %attrs; | -- %coreattrs, %i18n, %events -- |
| width number #implied > |
width = integer
Этот атрибут дает информацию агенту пользователя о желательной ширине форматируемого блока. Агент пользователя может использовать эту информацию для выбора шрифта или отступа. Желательная ширина выражается в числе символов.
Элемент pre сообщает визуальному агенту пользователя, что данный фрагмент текста уже сформатирован. Агент пользователя при этом должен сохранить все пробелы, использовать шрифт с фиксированной шириной букв, блокировать автоматический перенос и разрыв строк. Перед и после такого фрагмента обычно вводятся пустые строки (требование SGML). В DTD-фрагменте, приведенном выше, в первой строке содержится список элементов, которые не должны присутствовать в PRE-декларации. Рассмотрим фрагмент из поэмы Шелли “to a skylark”.
<pre>
| higher still and higher | ||
| from the earth thou springest | ||
| like a cloud of fire; | ||
| the blue deep thou wingest, |
</pre>
Этот стих будет представлен агентом пользователя без изменений формата.
Не рекомендуется использовать горизонтальную табуляцию в предварительно отформатированных текстах, агент пользователя не сможет воспроизвести формат фрагмента без искажений.
10. Пометка изменений документа. Элементы ins и del.
<! element (ins|del) - - (%inline) * |
-- (введенный/удаленный текст) -- > | |
| <!attlist (ins|del) %attrs; | -- %coreattrs, %i18n, %events -- | |
| cite %url #implied | -- информация о причине изменения -- | |
| datetime cdata #implied | -- дата изменения в формате ISO -- > |
cite = URL
Значение этого атрибута равно URL, которое указывает на документ-первоисточник. Атрибут служит для пояснения причины изменения документа.
datetime = cdata
Значение этого атрибута определяет дату и время внесения изменения в документ. Формат этого значения должен соответствовать требованиям документа ISO-8601.
Элементы ins и del используются для выделения фрагментов документа, которые были добавлены или удалены из предшествующей версии документа.
11. Формат даты и времени
ISO-8601 допускает много опций и вариаций в представлении дат и времени. Но основным форматом HTML следует считать следующий:
yyyy-mm-ddthh:mm:sstzd
| Где | yyyy | = четыре цифры года |
| mm | = две цифры месяца (01 – январь) | |
| dd | = две цифры дня месяца (01-31) | |
| hh | = две цифры часа (00-23; am/pm запрещены) | |
| mm | = две цифры минут (00-59) | |
| ss | = две цифры секунд (00-59) | |
| tzd | = идентификатор временной зоны |
| z | обозначает utc (coordinated universal time) |
| +hh:mm | указывает местное время в часах и минутах опережающее utc. |
| -hh:mm | указывает местное время в часах и минутах отстающее от utc. |
12. Неупорядоченные (ul) и упорядоченные (ol) списки
<!entity % ulstyle “disc|square|circle”>
<!element ul - - (li) +>
| <!attlist ul | -- неупорядоченный список -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| type (%ulstyle) #implied | -- список, где элементы отмечены жирной точкой в начале строки -- | |
| compact (compact) #implied | -- уменьшенное расстояние между элементами списка -- > | |
| <!entity % olstyle “cdata” | -- определяет стиль нумерации: [1|a|a|i|i] -- > | |
<! element ol - - (li) +> |
||
| <!attlist ol | -- упорядоченный список -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| type (%olstyle) #implied | -- нумерованный список -- | |
| compact (compact) #implied | -- уменьшенное расстояние между элементами списка -- | |
| start number #implied | -- начальный номер элемента списка -- > | |
| <!entity % listyle “cdata” | -- ограничение: “(%ulstyle|%olstyle)” -- > | |
<! element li - o %block |
-- элемент списка -- > | |
| <!attlist li %attrs; | -- %coreattrs, %i18n, %events -- | |
| type %listyle) #implied | -- стиль элемента списка -- | |
| value number #implied | -- сброс счетчика элементов списка -- > |
/p> Определение атрибутов
type = style-information
Этот атрибут определяет стиль элемента списка.
start = integer
Работает только для ol. Устанавливает начальное значение счетчика элементов упорядоченного списка, значение по умолчанию равно единице.
value = integer
Работает только для LI. Устанавливает текущее значение номера элемента списка.
compact
Не рекомендуется использовать. При использовании требует от агента пользователя отображать список в возможно более компактном виде.
Упорядоченные и не упорядоченные списки во многом схожи. Оба типа представляют собой последовательность элементов, описанных элементом LI (конечная метка этого элемента обычно опускается). Ниже приведены примеры списков.
<ul>
</ul>
Списки могут быть вложенными.
<ul>
</ul>
В упорядоченных списках невозможно продолжать нумерацию с предыдущего списка или убрать нумерацию, но можно установить счетчик принудительно с помощью атрибута value. Например:
<ol>
<li value=”30”> присваивает этому элементу списка номер 30.
<li value=”40”> присваивает этому элементу списка номер 40.
<li> этот элемент списка будет иметь номер 41.
</ol>
12.1. Списки, форматируемые визуальным агентом пользователя
Для OL и UL атрибут type определяет опцию отображения визуальным агентом пользователя. Для элемента UL возможны значения атрибута type: disc, square и circle. Значение по умолчанию зависит от уровня вложения текущего списка. Агент пользователя попытается представить “disc” в виде небольшого заполненного кружочка, “circle” – в виде незаполненного кружочка, а “square” – в виде квадратика.
Для элемента ol возможные значения атрибута type представлены в таблице.
| Тип | Стиль нумерации | |
| 1 | Арабские цифры | 1,2,3,… |
| a | Строчные буквы латинского алфавита | a,b,c,… |
| a | Прописные буквы латинского алфавита | a,b,c, … |
| i | Малые римские цифры | i, ii, iii, … |
| i | Большие римские цифры | i, ii, iii, … |
<!element dl - - (dt|dd)+>
<!element dt – o (%inline) *>
<!element dd – o %block>
Список определений отличается слабо от других списков, он состоит из двух частей: начальная этикетка (label) и описание. Этикетка инициируется элементом DT и может содержать только помеченный текст. Описание начинается с элемента DD и может содержать данные блочного уровня. Например:
<dl>
</dl>
Представление списка определений зависит от агента пользователя. Агент пользователя может отобразить представленный список в виде:
daniel
born in france, daniel’s favorite food is foie gras.
in this paragraph we’ll discuss daniel’s girlfriends: audrey, laurie and alice.
tim
born in new york, tim’s favorite food is ice cream.
13. dir и элементы menu
<!element (dir|menu) - - (li)+ - (%blocklevel)>
Элемент DIR предназначен для формирования многоколоночного текста каталога. Элемент Menu предназначен для работы с одноколонными текстами каталогов. Оба элемента имеют структуру, аналогичную UL. Рекомендуется использовать UL вместо DIR и Menu.
14. Таблицы
Модель таблиц в HTML позволяет пользователям создавать достаточно сложные структуры таблиц. В этой модели ряды и колонки можно объединять в группы. При печати больших таблиц заголовки и нижние комментарии могут дублироваться для каждой части.
14.1. Структура таблиц
В HTML таблицы имеют следующую структуру
Допускается одна или более групп строк. Каждая группа состоит из опционной секции заголовка таблицы и опционной нижней секции.
Допускается одна или более групп колонок.
Каждая строка состоит из одной или более ячеек.
Каждая ячейка может содержать заголовок или информацию и занимать более одной строки и более одной колонки.
14.1.1. Элемент table
<!element table - - (caption?, (col*|colgroup*), thead?, tfoot?, tbody+)>
<!attlist table -- элемент таблицы –
Определение атрибутов
align = left | center | right
Этот атрибут определяет положение таблицы в документе. Возможные значения:
left: Таблица сдвинута к левому краю документа.
center: Таблица размещена по центральной оси документа.
right: Таблица сдвинута к правому краю документа.
width = length
Этот атрибут определяет желательную ширину всей таблицы для агента пользователя. В отсутствии этого атрибута размер таблицы определяется агентом пользователя.
cols = integer
Этот атрибут задает число колонок в таблице. Если он задан, агент пользователя разворачивает таблицу по мере получения данных.
14.2. Вычисление числа рядов и колонок в таблице
Число рядов в таблице равно числу tr-элементов в ее содержимом. Агенты пользователя должны игнорировать ряды с номерами за пределами этого числа. Существует несколько путей определения числа колонок.
Сканирование рядов таблицы и определение максимального числа колонок. Если число колонок в таблице превосходит число ячеек, ряд дополняется пустыми ячейками.
Подсчитывается число колонок, как это специфицировано элементами COL и colgroup.
Используется атрибут COLS элемента table
Агент пользователя может предположить, что число колонок в примере, приведенном ниже равно трем.
<table cols= “3”>
… текст таблицы …
</table>
Если число колонок в таблице не задано атрибутом COLS, то визуальный агент пользователя будет ждать прихода всей информации о таблице, прежде чем приступит к ее отображению. Таким образом, атрибут cols позволяет отображать таблицу ряд за рядом по мере поступления данных.
14.3. Ориентация таблиц
Ориентация таблиц определяется атрибутом dir элемента table. Для таблиц, ориентированных слева направо (ориентация по умолчанию), первая колонка расположена слева, а первый ряд сверху. Возможна ориентация таблицы справа налево. Для того чтобы специфицировать таблицу с нумерацией колонок справа налево нужно установить значение атрибута dir.
<table dir=”rtl”>
… содержимое таблицы …
</table>
14.4. Надписи и таблица. Элемент caption
<!element caption - - (%inline;) +>
<!entity % calign “(top|bottom|left|right)”>
Определение атрибута
align = top|bottom|left|right
Этот атрибут определяет положение подписи по отношению к таблице. Возможные значения:
top: подпись над таблицей. Это значение по умолчанию.
bottom: подпись под таблицей.
left: подпись слева от таблицы.
right: подпись справа от таблицы.
Надпись, если она присутствует, должна описывать природу таблицы. Элемент caption должен располагаться непосредственно после начальной метки table. Например:
<table cols=”3”>
<caption> cups of coffee consumed by each senator</caption>
… остальная часть таблицы …
</table>
14.5. Группы рядов. Элементы thead, tfoot и tbody
<!element thead – o (tr+)>
<!element tfoot - o (tr+)>
<!element tbody o o (tr+) >
Таблица должна содержать хотя бы одну группу рядов. Каждая группа рядов делится на три секции: заголовок, собственно таблица и подпись под таблицей. Заголовок и подпись являются опционными. Элемент thead определяет заголовок, tfoot – подпись под таблицей, а элемент tbody - тело таблицы. thead, tfoot и tbody, если они присутствуют, должны содержать один или более рядов. Ниже приведен пример использования элементов thead, tfoot и tbody.
<table>
<thead>
align="justify"></thead>
<tfoot>
</tfoot>
<tbody>
</tbody>
<tbody>
</tbody>
</table>
tfoot в рамках определения table должен появляться до tbody, так чтобы агент пользователя мог осуществлять разбор подписи до получения всех данных таблицы.
14.6. Опционные метки групп рядов
Когда таблица содержит только одно тело и не имеет заголовка и нижней подписи, начальная и конечная метки tbody могут быть опущены. Когда блок таблицы содержит заголовок, начальная и конечная метки элемента thead являются необходимыми. Конечная метка может быть опущена, когда далее следует стартовая метка tfoot или tbody. когда блок таблицы содержит нижняя подпись, необходима начальная метка элемента tfoot. Конечная метка может быть опущена, когда далее следуют начальная метка thead или tbody.
14.7. Группы колонок. Элементы colgroup и col
<!element colgroup - o (col*) >
Определения атрибутов
span = integer
Атрибут в случае своего присутствия определяет число колонок в группе по умолчанию. Агент пользователя должен игнорировать этот атрибут, если текущая группа содержит один или более элементов col. Значение атрибута по умолчанию равно единице.
width = length
Атрибут определяет значение ширины колонки по умолчанию для текущей группы колонок. Кроме того, для стандартных значений пикселя и процента этот атрибут может иметь специальную форму “0*”, которая означает, что ширина каждой колонки в группе должна иметь минимальную ширину для размещения имеющегося текста.
Таблица должна иметь как минимум одну группу колонок. В отсутствии определения группы считается, что таблица имеет одну группу колонок, включающую в себя все колонки таблицы. Атрибут width элемента colgroup определяет ширину по умолчанию каждой из колонок в группе. Формат “0*”, требующий минимальной ширины, может быть отменен элементом col.
Таблица в приведенном ниже примере имеет две группы колонок. Первая группа содержит 10 колонок, а вторая – 5 колонок. Значение ширины колонки по умолчанию для каждой из колонок в первой группе равно 50 пикселей. Для второй группы ширина колонки определяется минимально возможным значением.
<table>
<colgroup span=”10” width=”50”>
<colgroup span=”5” width=”0*”>
<thead>
<tr> ….
</thead>
14.8. Элемент col
<!element col - o empty>
Определение атрибута
width = length
Этот атрибут задает значение по умолчанию для ширины колонок в группе. Атрибут может также принимать значение “0*” (смотри выше) и “i*”, где i - целое. Это называется относительной шириной. Когда агент пользователя выделяет место для таблицы, он сначала определяет габариты, а уже затем делит выделенное пространство, определяя относительные ширины рядов и колонок. Число i при этом определяет относительную долю, выделяемую данной колонке. Значение “*” эквивалентно “1*”.
Каждая группа колонок может содержать нуль или более элементов col. Элемент col не определяет группу колонок в том смысле, как это делает colgroup, он предоставляет способ задать значения атрибутов для всех колонок группы. Атрибут span элемента col имеет следующее значение.
В отсутствии декларации span каждый элемент col представляет одну колонку. Если атрибут span имеет значение n>0, текущий элемент col действует на n колонок таблицы. Если атрибут span равен нулю, текущий элемент col имеет воздействие на все оставшиеся колонки таблицы, начиная с текущей. Что же касается colgroup, атрибут width для col воздействует на ширины колонок, к которым относится этот элемент. Если элемент cal действует на несколько колонок, тогда его атрибут width специфицирует ширину каждой колонки в его зоне ответственности.
Ниже приведен пример таблицы, имеющей две группы колонок. Первая группа содержит три колонки, вторая – две колонки. Доступное место по горизонтали определяется следующим образом. Сначала агент пользователя выделяет 30 пикселей для первой колонки. Затем будет выделено минимально возможное место для второй колонки. Оставшееся место по горизонтали будет поделено на 6 равных частей. Колонка 3 получит 2 такие порции, колонка 4 – одну, а колонка 5 получит 3.
<table>
<colgroup>
<colgroup align=”center”>
<thead>
<tr> …..
</table>
Мы установили значение атрибута align во второй группе колонок равным “center”. Все ячейки в каждой колонке этой группы наследуют это значение. Но оно может быть изменено. В действительности последний элемент col делает это, специфицируя то, что все колонки, которыми он управляет, будут выровнены по символу “:”.
14.9. Ряды таблицы. Элемент tr
<!element tr - o (th|td)+>
Элементы TR действуют как контейнеры рядов ячеек таблицы. Ниже приведен пример таблицы, которая имеет три ряда, каждый из которых открывается элементом TR.
<table>
<caption>cups of coffee consumed by each senator</caption>
<tr> … Ряд заголовка …
<tr> … Первый ряд данных …
<tr> … Второй ряд данных …
… остальная часть таблицы …
</table>
14.10. Ячейки таблицы. Элементы th и td
<!element (th|td) - o %block>
Определения атрибутов
axis = cdata
Атрибут определяет сокращенное имя заголовка ячейки. Имя ячейки по умолчанию – ее содержимое.
axes = cdata-list
Значение этого атрибута представляет собой список имен axis, разделенных запятыми. Эти имена представляют собой заголовки рядов и колонок, принадлежащих данной ячейке. В отсутствии этого атрибута агент пользователя идентифицирует эти имена сам.
rowspan = integer
Этот атрибут специфицирует число рядов в текущей ячейке. Значение этого атрибута по умолчанию равно 1. Значение нуль означает, что ячейка включает в себя все ряды, начиная с текущего, до конца таблицы.
colspan = integer
Этот атрибут специфицирует число колонок в текущей ячейке. Значение этого атрибута по умолчанию равно 1. Значение нуль означает, что ячейка включает в себя все колонки, начиная с текущей, до конца таблицы.
nowrap
Использование не рекомендуется. В случае присутствия этот булев атрибут указывает агенту пользователя заблокировать автоматический разрыв слов при выкладке их в ячейку. Вместо этого атрибута рекомендуется использовать стилевой лист.
Элемент TH запоминает заголовок, в то время как TD – данные. Это позволяет агенту пользователя обрабатывать заголовки и данные по-разному даже в отсутствии стилевого листа. Ячейки могут быть пустыми (не содержать данных). Ниже приведен пример таблицы с четырьмя колонками, имеющими заголовки.
<table>
<caption>Cups of coffee consumed by each senator</caption>
<tr> <th>name <th>Cups <th> Type of coffee <th> Suger?
<tr> <td>T. Sexton <td>10 <td>espresso <td>no
<tr> <td>J. Dinnen <td>5 <td>decaf <td>yes
… остальная часть таблицы …
</table>
Агент пользователя представит верхнюю часть данной таблицы в виде:
Cups of coffee consumed by each senator
Для того чтобы сделать таблицу более выразительной, можно ввести атрибут border в элемент table.
<table border=”border”>
… остальная часть таблицы …
</table>
Тогда агент пользователя отобразит начало данной таблицы следующим образом:
Cups of coffee consumed by each senator
Name |
Cups |
Type of coffee |
Sugar |
| T. Sexton | 10 | espresso | no |
| J. Dinnen | 5 | decaf | yes |
Атрибуты axis и exes предоставляют возможность снабжать ячейки таблицы этикетками (labels). Синтезаторы речи могут использовать эти этикетки для идентификации содержимого и положения каждой ячейки. Программное обеспечение может рассматривать эти этикетки как имена полей базы данных при занесении содержимого таблицы в банк данных. Ниже представлен пример таблицы, где значение атрибута axis представляет собой фамилию сенатора.
<table border=”border”>
<caption>Caps of coffee consumed by each senator</caption>
<tr> <th>Name <th>Cups <th> Type of coffee <th> suger?
<tr> <td axis=”sexton” exes=”name”>T. Sexton <td>10
<td>espresso <td>no
<tr> <td axis=”dinnen” exes=”name”>J. Dinnen <td>5 <td>decaf <td>yes
</table>
14.11. Ячейки, которые занимают несколько рядов или колонок
Ячейки могут охватывать несколько рядов или колонок. Число рядов или колонок в ячейке определяется атрибутами rowspan и colspan для соответственно TH или TD-элементов. В таблице, которая была описана, ячейка в ряду 4 вторая колонка должна занимать три колонки, включая текущий ряд.
<table border=”border”>
<caption>Caps of coffee consumed by each senator</caption>
<tr> <th>Name <th>Cups <th> Type of coffee <th> suger?
<tr> <td>T. Sexton <td>10 <td>espresso <td>no
<tr> <td>J. dinnen <td>5 <td>decaf <td>yes
<tr> <td>A. Soria <td colspan=”3”<em>not available</em>
</table>
Эта таблица будет развернута визуальным агентом пользователя как:
Caps of coffee consumed by each senator
Name |
Cups |
Type of coffee |
Suger? |
| T. Sexton | 10 | espresso | no |
| J. Dinnen | 5 | decaf | yes |
| A. Soria | not available |
/p> Этот пример иллюстрирует как описания ячеек, которые распространяются более чем на один ряд или колонку, влияет на определение последующих ячеек. Рассмотрим следующее описание таблицы.
<table border=”border”>
<tr> <td>1 <td rowspan=”2”>2 <td>3
<tr> <td>4 <td>6
<tr> <td>7 <td>8 <td>9
</table>
Таблица может быть представлена в виде:
| 1 | 2 | 3 |
| 4 | 6 | |
| 7 | 8 | 9 |
14.12. Горизонтальное и вертикальное выравнивание
<!entity % cellhalign “align (left|center|right|justify|char) #implied
char cdata #implied -- выравнивание по символу, напр. char=”:” --
charoff cdata #implied -- смещение выравнивания по символу -- >
<!entity % cellvalign “valign (top|middle|bottom|baseline) #implied” >
Определения атрибутов
align = left|center|right|justify|char
Этот атрибут определяет способ выравнивания текста в ячейке. Возможны следующие значения:
| left: | выравнивание по левому краю (значение атрибута по умолчанию) |
| center: | Выравнивание текста в ячейке по центру (значение по умолчанию для заголовков) |
| right: | выравнивание текста по правому краю ячейки. |
| justify: | выравнивание текста по правой и левой границам. |
| char: | выравнивание текста по некоторому символу. |
Этот атрибут определяет вертикальное позиционирование текста в ячейке таблицы. Возможны следующие значения:
| top: | текст прижимается к верхней границе ячейки. |
| middle: | текст размещается по центру ячейки (значение по молчанию для заголовков) |
| bottom: | текст прижимается к нижней границе ячейки. |
| baseline: | все ячейки в ряду должны быть выровнены по высоте так, чтобы их первые строки были на одной высоте. Это не касается последующих строк. |
Этот атрибут определяет символ в тексте, который будет выполнять роль оси для выравнивания. Значением по умолчанию является точка для английского языка и запятая - для французского (бывает полезно для колонок цифр с долями целого).
charoff = length
Если этот атрибут присутствует, он определяет смещение текста относительно символа выравнивания (рассматривается первый такой символ). Если в строке такого символа нет, то она должна быть сдвинута горизонтально в конец относительно позиции выравнивания.
Рассмотрим пример таблицы с выравниванием по символу точка.
<table border=”border”>
<colgroup>
<col><col align=”char” char=”.”>
<thead>
<tr><th>Vegetable <th>Cost per kilo
<tbody>
<tr> <td> lettuce <td>$1
<tr> <td> silver carrots <td>$10.50
<tr> <td>golden turnips <tr>$100.30
</table>
Отформатированная таблица будет выглядеть как:
| vegetable | cost per kilo |
| lettuce | $1 |
| silver carrots | $10.50 |
| golden turnips | $100.30 |
Следующие атрибуты влияют на рамки таблицы и внутренние линии.
frame = void|above|below|hsides|lhs|rhs|vsides|box|border
Эти атрибуты определяют, какая из сторон рамки, окружающей таблицу, будет видимой.
| void: | Ни одна из сторон. Значение по умолчанию. |
| above: | Только верхняя сторона. |
| below: | Только нижняя сторона. |
| hsides: | Только нижняя и верхняя стороны. |
| vsides: | Только правая и левая стороны. |
| lhs: | Только левая сторона. |
| rhs: | Только правая сторона. |
| box: | Все четыре стороны. |
| border: | Все четыре стороны. |
Этот атрибут определяет, какие линии появится между ячейками в пределах таблицы. Возможные значения:
| none: | Никаких линий, значение по умолчанию. |
| groups: | Линии имеются только между группами рядов и столбцов. |
| rows: | Линии имеются только между рядами. |
| cols: | Линии имеются только между столбцами. |
| all: | Линии имеются между рядами и столбцами. |
Эти атрибуты определяют ширину рамки вокруг таблицы в пикселях. В приведенном ниже примере таблица имеет рамку в 5 пикселей и присутствует с правой и левой сторон таблицы. Разделительные линии имеются между всеми колонками.
<table border=”5” frame=vsides” rules=”cols”>
<tr> <td>1 <td>2 <td>3
<tr> <td>4 <td>5 <td>6
<tr> <td>7 <td>8 <td>9
</table>
Следующие установки должны выполняться агентом пользователя для совместимости. Установка border=”0” подразумевает frame=”void” и, если не специфицировано иного, rules=”none”. Другие установки border подразумевают frame=”border” и, если не оговорено иное, rules=”all”. Значение “border” в стартовой метке элемента table должно интерпретироваться как значение атрибута frame. Это предполагает, что rules=”all” и ненулевое значение атрибута border. Так, например:
<frame border=”2”> у <frame border=”2” frame=”border” rules=”all”>
и
<frame border> <=< frame frame=”border” rules=”all”>
14.14 Поля ячейки
Два атрибута регулируют зазор между и внутри ячеек.
cellspacing = length
Этот атрибут определяет то, какое расстояние должно быть оставлено между рамкой таблицы и начальным или конечным краем ячейки для каждого ряда или колонки, а также между ячейками в таблице.
cellpadding = length
Этот атрибут определяет расстояние между границей ячейки и его содержимым.
Во всех последующих таблицах атрибут cellspacing определяет, что ячейки разделяются друг от друга и от рамки таблицы расстоянием в 20 пикселей. Атрибут cellpadding определяет, что верхняя и нижняя граница ячейки отстоит от его содержимого на 10% доступного пространства по вертикали (всего 20%). Аналогично поля ячейки в горизонтальном направлении составляют 10% от горизонтального размера ячейки.
<table>
<tr cellpadding=”20”> <tr>data1 <td cellpadding=”20%”>data2 <td>data3
</table>
Ниже приведены примеры, где проиллюстрировано взаимодействие различных элементов. Пример 1.
<table border=”border”>
<caption>A test table with merged cells </caption>
/table>
Таблица может быть отображена следующим образом.
A test table with merged cells
Average |
Other category |
misc |
||
height |
weight |
|||
males |
1.9 | 0.003 | ||
females |
1.7 | 0.002 |
Code-page support in Microsoft Window
ID
NT 3.1
NT 3.51
95
1250
1251
1252
1253
1254
1255
1256
1257
1361
windows 3.1 eastern european
windows 3.1 cyrillic
windows 3.1 us (ansi)
windows 3.1 greek
windows 3.1 turkish
hebrew
arabic
baltic
korean
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
**
x
x
x
x
x
x
x
x
x
708
709
710
720
arabic (asmo 708)
arabic (asmo 449+, bcon v4)
arabic (transparent arabic)
arabic (transparent asmo)
x
x
x
x
x
x
x
x
15. Информация о пути. Элемент base
<!element base - o empty>
<!attlist base href %url #required
target cdata #implied -- где развернуть подключенный ресурс -- >
Описание атрибута
href = url
Этот атрибут задает абсолютный url, который используется как базовый при определении относительных url.
В HTML проходы всегда задаются с помощью URL. Относительные URL получаются на основе базового URL, который может быть получен различными путями. Элемент base позволяет описать базовый URL явно. Например:
<html>
<head>
<base href=http://www.barre.fr/fou/intro.html>
</head>
….
</html>
Относительный URL “../gee/foo/html” будет в этом случае получен в виде:
http://www.barre.fr/gee/foo.html
15.1. Связи и якоря
HTML-связь представляет собой соединение одного WWW-ресурса с другим.
Определение связей и якорей
В HTML любая связь имеет два конца и направление. Связь начинается в источнике и завершается в месте назначения. Любое описание связи определяет оба эти конца. Один конец задается местом описания связи, другой – атрибутом этой связи. Связь соответствует какому-то WWW-ресурсу (HTML-документу, изображению, видео-клипу, текущему документу, звуковому файлу и т.д.). Конец связи может быть также задан якорем. Якорь – это именованный указатель на определенную часть документа. Связь устанавливает соответствие между источником и местом назначения. Но помимо этого связь может определять тип информации. Связи могут носить самый разный характер, например, указания “next” или “previous” также задают определенные связи. Связи могут использоваться пользователем и для определения порядка печати документов. Атрибут rel определяет, что связь имеет начало в текущем документе. Атрибут rev указывает, что описанная связь имеет в качестве места назначения текущий документ. В HTML имеется два элемента, определяющие связь, это link и a.
Link может появиться в секции head HTML-документа. Этот элемент определяет взаимоотношение между зоной текущего документа и другим ресурсом.
Элемент A может появиться в теле документа, он устанавливает связь между зоной текущего документа и другим ресурсом. Элемент a в отличие от link может иметь содержимое (текст, изображения и т.д.). Другим важным отличием этих двух элементов является то, что А интерпретируется агентом пользователя как указание “извлечь ресурс, находящийся на другом конце связи”. Извлеченный ресурс может обрабатываться агентом пользователя разными способами:
Открыть новый документ в том же окне, открыть документ в другом окне, запустить новую программу и т.д.
Атрибут title может быть установлен в элементах для выдачи дополнительной информации о природе связи.
15.2. Элементы, определяющие якоря
Существует два способа специфицировать якоря в HTML-документах.
Использовать элемент А (служит для формирования связей и якорей).
Применить атрибут id любого элемента.
Так как документы могут быть написаны на разных языках, link и a поддерживают атрибуты lang, dir и charset.
15.3. Элемент А
<!element a - - (%inline)* -(a)>
<!attlist a
Описания атрибутов
name = cdata
Этот атрибут указывает на то, что элемент использован для описания якоря. Значение этого атрибута является уникальным именем якоря. Это имя действительно в пределах данного документа. Атрибут name работает в том же пространстве имен, что и атрибут ID.
href = url
Этот атрибут указывает на то, что элемент использован для описания связи. Значение атрибута равно положению одного из концов связи (другой конец задан положением этого элемента).
rel = cdata
Этот атрибут указывает на то, что источником связи является текущая позиция в документе. Значение Href в этом случае определяет место назначения связи. Значение rel специфицирует тип связи. Этот атрибут может включать в себя список типов связей, разделенных пробелами.
rev = cdata
Этот атрибут указывает на то, что место назначения связи соответствует текущей позиции в документе. Значение Href в этом случае определяет положение источника. Значение rev специфицирует тип связи. Этот атрибут может включать в себя список типов связей, разделенных пробелами.
charset = cdata
Этот атрибут специфицирует перекодировку символов для данной связи. Значение этого атрибута должно быть именем “charset” описанным в RFC-2045. Значение по умолчанию этого атрибута равно “ISO-8859-1”.
Ниже приведен пример использования А-элемента.
<a href=http://www.3w.org/>w3c web site</a>
Эта ссылка указывает на базовую страницу консорциума WWW. Когда пользователь активирует эту связь, агент пользователя обратится к указанному ресурсу и откроет HTML-документ. Агент пользователя представляет ссылки в документе так, чтобы выделить их из текста (например, подчеркивает их). Чтобы сообщить агенту пользователя в явном виде, какой набор символов следует использовать при отображении, следует установить соответствующее значение атрибута charset.
<a href =http://www.w3.org/ charset=”ISO-8859-1”>w3c web site</a>
Ниже приведен пример, иллюстрирующий описание якоря с именем “anchor-one” в файле “one.html”.
… текст до якоря …
<a name=”anchor-oner”>this is the location of anchor one.</a>
… текст после якоря …
Это определение присваивает якорь зоне документа, содержащей текст “This is the location of anchor one”. Определив якорь, мы можем установить с ним связь из того же или постороннего документа. URL, который указывает на якорь, завершаются символом #, за которым следует имя якоря. Ниже приведены примеры такого URL.
Абсолютный URL: http://www.mycompany.com/one.html">http://www.mycompany.com/one.html#anchor-one
Относительный URL: ../one.html#anchor-one
Когда связь задана в пределах документа: #anchor-one
Таким образом, связь, определенная в файле “two.html”, который находится в том же каталоге, что и “one.html” имеет ссылку на якорь в виде:
<a href=”./one.html#anchor-one” anchor one</a>
Элемент А в следующем примере определяет якорь и связь в одно и то же время.
<a name=”anchor-two” href=”html://wwwsomecompany.com/people/ian/vocation/family.png”>
</a>
Этот пример содержит связь с www-ресурсом другого типа (png-изображение). Активация связи должна извлечь это изображение из сети и отобразить его.
15.4. Связи mailto
Автор может сформировать связи, которые не ведут к какому-либо документу, а реализуют отправку e-mail сообщения по некоторому адресу. Когда такая связь активизируется, агент пользователя вызывает почтовую программу. Для реализации таких связей введено значение mailto атрибута Href.
<a href=”mailto:semenov@ns.itep.ru”> yury semenov</a>
Когда пользователь активизирует эту связь, агент пользователя открывает почтовую программу и заносит в поле “to:” значение “semenov@ns.itep.ru”.
15.5. Вложенные связи
Связи и якоря, описанные элементом А не допускают вложения. Например, ниже приведенная запись недопустима.
<a name=”outer-anchor” href=”next-outer.html”> an outer anchor and link <a name=”inner-anchor” href=”next-inner.html”>an inner anchor and link.</a></a>
15.6. Якоря с атрибутом id
Атрибут id может использоваться для размещения якоря в области начальной метки любого элемента. Ниже приведен пример использования id для размещения якоря в элементе Н2. Якорь подвязан здесь посредством А-элемента.
<h2 id=”section2”>section two</h2>
… позднее в документе …
please refer to <a href=”#section2”>section two</a> above for more details.
Атрибуты ID и name работают в общем пространстве имен (см. ISO10646). Это означает, что они не могут описать якоря с идентичными именами в пределах одного документа.
15.7. Элемент link
<!element link - o empty>
<!attlist link
Этот элемент, который должен использоваться в Head-секции документа (любое число раз), определяет связь, независящую от среды. Хотя Link не имеет содержимого, он предоставляет информацию, обрабатываемую агентами пользователя. Ниже в предлагаемом примере показано как в секции head документа могут появиться несколько определений Link. Атрибуты rel и rev определяют, откуда связь начинается и где кончается.
<html>
<head>
<link rel =”index” href=”../index.html”>
<link rel =”next” href=”chapter_3.html”>
<link rev =”previous” href=”chapter_1.html”>
</head>
……
15.8. Типы связей
Атрибуты rel и rev определяют начало и конец связи, но их значение или значения задают также природу связи. Если для элемента А атрибуты rel и rev не являются обязательными для link, хотя бы один из них присутствовать должен. Агент пользователя может интерпретировать эти атрибуты множеством путей, например, через меню или “клавишу next”. Ниже перечислены некоторые типы связей.
| Содержимое | соединение выполняет функцию оглавления документа. |
| Индекс | соединение предлагает индекс документа. |
| Глоссарий | соединение предлагает глоссарий терминов для данного документа. |
| copyright | соединение воспроизводит заявление о защите авторских прав. |
| Следующий | связь осуществляет переход к следующему документу из списка (next) |
| Предыдущий | связь осуществляет переход к предыдущему документу из списка (previous) |
| Содержание | связь вызывает переход к первому из ряда документов. |
| Справка | связь производит вызов документов, дающих дополнительную информацию по некоторым вопросам (help) |
| Закладка | связь реализует переход в определенную точку документа, часто такой точкой является заголовок главы или раздела (bookmark). |
| Стилевой лист | связь указывает на внешний стилевой лист. |
| Альтернатива | связь указывает на различные версии того же самого документа, например, на переводы данного документа на иностранные языки (alternate). |
Элемент Link может использоваться для решения задач поиска документов по ключевым словам и другим признакам, например, язык или представления документа в виде, допускающем печать. Ниже приведен пример, где сообщается поисковой системе о месте нахождения печатной копии руководства.
<head>
<link media=”print” title=”the manual in postscript”
</head>
А в этом примере мы заставляем поисковую систему найти первую страницу собрания документов.
<head>
<link rel=”start” title=”the first page of the manual”
</head>
16. Элемент object
<!entity % oalign “(texttop|middltextmiddle|baseline|textbottom|left|center|right)”>
<!element object - - (param | %block)*>
<!attlist object
Определения атрибутов
codebase = url
Этот атрибут специфицирует базовый проход для определения относительного URL, описанного classid. Если атрибут не задан, значением по умолчанию является базовый URL данного документа.
classid = URL
Этот атрибут специфицирует положение механизма отображения через url.
codetype = cdata
Этот атрибут специфицирует internet media type данных, ожидаемых механизмом отображения, определенным classid. Атрибут является опционным, но рекомендуемым, когда имеется classid, так как это позволяет агенту пользователя избежать загрузки информации для неподдерживаемого типа среды. Если явно величина не задана, его значение по умолчанию соответствует значению атрибута type.
data = URL
Этот атрибут специфицирует положение данных, которые должны быть отображены.
type = cdata
Этот атрибут специфицирует Internet media type для данных, заданных атрибутом data. Атрибут является опционным, но рекомендуемым, когда задан атрибут data, так как это позволяет агенту пользователя избежать загрузки информации с типом, неподдерживаемым средой.
declare
Если присутствует, этот булев атрибут делает текущее определение object лишь декларацией.
standby = cdata
Этот атрибут специфицирует сообщение, которое агент пользователя может отобразить при загрузке объектных приложений и данных.
align = texttop|middle|textmiddle|baseline|textbottom|left|center|right
Не рекомендуется к использованию. Этот атрибут специфицирует положение объекта по отношению к окружающему контексту.
Большинство агентов пользователей снабжены механизмом для отображения базовых типов информации, таких как текст, картинки в GIF-формате, цвета, шрифты и т.д. В HTML элемент object определяет положение механизма отображения и положение данных, необходимых для механизма отображения. Агент пользователя интерпретирует элемент object согласно следующим правилам.
Агент пользователя должен сначала попробовать механизм отображения, заданный атрибутом элемента. Если агент пользователя не может поддержать этот механизм по какой-либо причине, он должен попытаться работать с содержимым элемента.
Важным следствием конструкции элемента object является то, что он предлагает механизм для описания альтернативного механизма отображения различных объектов. Каждая декларация object может предлагать альтернативный механизм отображения. Если агент пользователя не может воспользоваться имеющимся механизмом, он может обратиться к тексту, который может представлять собой другой элемент object. В ниже приведенном примере использовано несколько деклараций object для иллюстрации альтернативных способов отображения. Агент пользователя сначала попробует отобразить первый элемент object, а далее будет пытаться воспользоваться: аплетом eath, написанным на языке python, mpeg анимацией, изображением земли в формате GIF и, наконец, альтернативным текстом.
<object title=” the earth as seen from space”
classid=”http://www.observer.mars/theearth.py”>
<object data=”theearth.mpeg” type=”application/mpeg”>
the <strong> ”earth"</strong> as seen from space.
Самая внешняя декларация специфицирует аплет, который не требует данных или начальных параметров. Вторая декларация специфицирует MPEG-анимацию и не определяет механизм отображения, предполагая, что с этой работой справится агент пользователя. Здесь установлен атрибут type, таким образом, что в случае если агент пользователя не может отобразить MPEG, он может не копировать “theearth.mpeg” из сети. Третья декларация специфицирует позицию GIF-файла и предлагает альтернативный текст на случай, когда другие механизмы не приведут к успеху.
Отображаемая информация может извлекаться двумя путями: из текущей строки илиb из внешнего источника. Первый способ дает большее быстродействие, но требует много места.
16.1. Инициализация объекта. Элемент param.
| <!element param - empty | -- именованное значение параметра -- > | |
| <!attlist param name cdata #required | -- имя параметра -- | |
| value cdata #implied | -- значение параметра -- | |
| valuetype (data|ref|object) data | -- способ интерпретации значения -- | |
| type cdata #implied | -- internet media type -- > |
name = cdata
value = cdata
Этот атрибут специфицирует значение параметра исполнения, заданного атрибутом name. Значение этого параметра не имеет какого-либо смысла для HTML, он определяется рассматриваемым объектом.
valuetype=data|ref|object
Этот атрибут специфицирует тип значения, определенного атрибутом value. Возможны значения:
| data: | значение, заданное value, после преобразования любых вложенных символов и цифровых объектов будет непосредственно передано механизму отображения в виде строки. Этот тип используется по умолчанию и может появляться в стартовой метке элемента. |
| ref: | значение, заданное value, является url, который определяет ресурс, где записано значение параметра исполнения. URL должно передаваться механизму отображения в не преобразованном виде. |
| object: | значение, заданное value, является фрагментом URL, который определяет декларацию object в том же самом документе. В этом случае определение object должно идентифицироваться его атрибутом ID. |
/p> type = cdata
Этот атрибут специфицирует internet media type ресурса, определенного атрибутом value, только в случае, когда атрибут valuetype = “ref”. Этот атрибут, таким образом, специфицирует для агента пользователя тип значений, которые будут обнаружены в URL, определенном атрибутом value.
Элемент param специфицирует набор значений, которые могут требоваться механизму отображения. В начале декларации object может появиться любое число элементов param. Синтаксис имен и значений предполагается понятным механизму отображения. Имена и значения передаются механизму отображения, как стандартный ввод. Рассмотрим пример. Здесь предполагается, что механизм отображения может воспринять два параметра, которые определяют начальную высоту и ширину (часов). Задаем эти начальные параметры равными 40х40 пикселей.
<object classid=”http://www.miamachina.it/ahalogclock.py”>
<param name=”height” value=”40” valuetype=”data”>
<param name=”width” value=”40” valuetype=”data”>
Этот агент пользователя не может исполнять приложения, написанные на языке python.
</object>
Так как значение по умолчанию valurtype для элемента param равно “data”, мы можем заменить вышеприведенную декларацию следующей:
<param name=”height” value=”40”>
<param name=”width” value=”40”>
или
<param name=”height” value=”40” data>
<param name=”width” value=”40” data>
В следующем исходные данные исполнения для параметра механизма отображения “init_values” заданы как внешний ресурс (GIF-файл). Значение атрибута valuetype установлено равным “ref”, а атрибут value равен URL.
<object classid=”html://www.gifstuff.com/gifappli” standby=”loading elvis…”>
<param name=”init_values” value=”./images/elvis.gif”>
</object>
Здесь установлен также атрибут standby так, что агент пользователя может отобразить сообщение в процессе загрузки механизма отображения. Механизмы отображения локализуются с помощью URL. Первая секция абсолютного URL характеризует протокол, используемый для передачи данных, которые указаны в URL. Для HTML-документов протокол обозначается как HTTP. Но возможны и другие варианты, например, в случае использования механизма отображения java вы можете использовать URL, начинающиеся со слова Java, а для аплетов activex – “clsid”. В предлагаемом примере в HTML-документ введен Java-аплет.
<object classid=”java:program.start”>
</object>
Некоторые схемы отображения требуют дополнительной информации для идентификации их применения и должны сообщить, где можно найти эту информацию. Проход к этой информации для механизма отображения может быть указан с помощью атрибута codebase.
<object codetype=”application/octet-strim” classid=”java:program.start”>
codebase=http://fooo.bar.com/java/myimplement/
</object>
В следующем примере с помощью атрибута classid через URL, который начинается с протокольной информации “clsid”, специфицирован механизм activex.
<object classid=”clsid:663c8fef-1ef9-11cf-a3db-080036f12502”
data=http://www.acme.com/ole/clock.stm>
Это приложение не поддерживается.
</object>
Для декларирования механизма отображения так, чтобы он не запускался в процессе прочтения агентом пользователя, нужно в элементе object установить булеву переменную declare. В то же время вы должны идентифицировать декларацию с помощью атрибута id в элементе object.
В предлагаемом ниже примере декларируется object, который активируется через внешнюю связь. Таким образом, объект можно активировать с помощью мышки, выбрав соответствующий фрагмент текста.
</object>
…далее в документе …
click to see a neat <a href=”#earth_declaration”>
animation of the earth! </a>
Последующий пример иллюстрирует то, как можно специфицировать значения исполнительных параметров, которые являются объектами. В этом примере мы посылаем текст гипотетическому механизму его отображения. Механизм отображения распознает параметр, названный “font”. Значение этого параметра само является объектом, который управляет использованием определенного шрифта. Взаимоотношение этого объекта и механизма отображения устанавливается путем присвоения id “tribune” декларации объекта шрифта и обращением к нему из элемента param.
| <object declare | id=”tribune” |
| type=”application/x-webfont” | |
| data=”tribune.gif”> |
/p> </object>
… здесь отображается текст из файла kublakhan.txt …
<object classid=http://foo.bar.com/poem_viewer
| data=”kublakhan.txt”> |
<p>you’re missing a really cool poem viewer …
</object>
Агент пользователя, который не поддерживает атрибут declare, должен пытаться отображать содержимое декларации object.
Выравнивание объектов
Атрибут align для данного элемента применять не рекомендуется, предпочтительнее использование стилевых листов.
17. Изображения. Элемент img
| <!element img - o empty | -- введение изображения в текст документа -- > | |
| <!attlist img %attrs; | -- %coreattrs, %i18n, %events -- | |
| src %url #required | -- url вводимого рисунка -- | |
| alt cdata #implied | -- описание для чисто текстовых броузеров -- | |
| align %ialign #implied | -- вертикальное или горизонтальное выравнивание -- | |
| height %pixels #implied | -- предлагаемая высота в пикселях -- | |
| width %pixels #implied | -- предлагаемая ширина в пикселях -- | |
| border %pixels #implied | -- предлагаемая толщина рамки в пикселях -- | |
| hspace %pixels #implied | -- предлагаемая ширина горизонтального поля -- | |
| vspace %pixels #implied | -- предлагаемая ширина вертикального поля -- | |
| usemap %url #implied | -- use client-side image map -- | |
| ismap (ismap) #implied | -- use server-side image map -- |
src = URL
Этот атрибут специфицирует положение (указатель на) ресурса, содержащего изображение. Общепринятые форматы: GIF, JPG, PNG.
align = bottomiddle|top|left|right
Применение не рекомендуется. Атрибуты определяют положение изображения по отношению к окружающему тексту.
Элемент IMG вводит изображение в текущий документ в точке его описания. Но тем не менее, рекомендуется вводить рисунок в текст с помощью элемента object. Рассмотрим, как семейное фото может быть включено в документ.
<img src=”html://www.somecompany.com/people/ian/vocation/family.png”
Это же может быть сделано с помощью object следующим образом.
<object data=http://www.somecompany.com/people/ian/vocation/family.png
Фото моей семьи на озере.
</object>
Атрибут alt специфицирует текст, который будет выведен в случае, когда изображение не может быть отображено по какой-либо причине.
18. Введение аплетов. Элемент applet
<!element applet - - (param | %inline) *>
<!attlist applet
| codebase %url #implied | -- опционный базовый url для аплета -- | |
| archive cdata #implied | -- архивный список с элементами, разделенными с помощью запятых -- | |
| code cdata #implied | -- файл класса аплета -- | |
| object cdata #implied | -- специализированный файл аплета -- | |
| alt cdata #implied | -- описание для чисто текстовых броузеров -- | |
| name cdata #implied | -- позволяет аплетам найти друг друга -- | |
| width %pixels #required | -- предлагаемая ширина в пикселях -- | |
| height %pixels #required | -- предлагаемая высота в пикселях -- | |
| align %ialign #implied | -- вертикальное или горизонтальное выравнивание -- | |
| hspace %pixels #implied | -- предлагаемые горизонтальные поля -- | |
| vspace %pixels #implied | -- предлагаемые вертикальные поля -- > |
codebase = URL
Этот атрибут специфицирует базовый URL для аплета. Если этот атрибут отсутствует, в качестве базового URL рассматривается текущий документ.
code = cdata
Этот атрибут специфицирует имя ресурса, который содержит откомпилированный субкласс аплета. Значение атрибута должно представлять собой относительный URL по отношению к базовому URL.
name = cdata
Этот атрибут специфицирует имя аплета, которое позволяет аплетам найти друг друга в пределах страницы.
width = length
Этот атрибут специфицирует исходную ширину для области отображения аплета (без учета размера окна или области диалоговых обменов, которые вызывают аплет).
height = length
Этот атрибут специфицирует исходную высоту для области отображения аплета.
align = top|middle|bottom|left|right
Этот атрибут специфицирует положение объекта по отношению к окружающему тексту.
archive = cdata
Этот атрибут специфицирует имена одного или нескольких архивов, разделенные запятыми, содержащие классы и другие ресурсы, которые будут предварительно загружены. Классы загружаются с помощью вызова appletclassloader с данным codebase. Предзагрузка ресурсов может значительно улучшить работу аплета.
object = cdata
Этот атрибут присваивает имя ресурсу, который содержит последовательное представление аплета. Аплет приводится к стандартному виду. Используется метод start().
Этот элемент, поддерживаемый всеми java-броузерами, позволяет разработчикам встраивать Java-аплеты в HTML-документы. Содержимое аплетов используется агентом пользователя как альтернатива, если он не поддерживает данный элемент. При прочих условиях его содержимое должно игнорироваться. Ниже приведен пример Java-аплета.
<applet code=”bubbles.class” width=”500” height=”500”>
java-аплет, который рисует движущиеся пузыри.
</applet>
Эту запись можно переписать в другой форме.
<object codetype=”application/octet-stream”
classid=”java:bubbles.class”
java-аплет, который рисует движущиеся пузыри.
</object
Исходные данные можно передать аплету через элемент param
<applet code=”audioitem” width=”15” height=”15”>
<param name=”snd” value=”hello.au|welcome.au”>
java-аплет, который исполняет приветственную мелодию.
</applet>
Вариант, базирующийся на object, представлен ниже.
<object codetype=”application/octet-stream”
classid=”audioitem”
width=”15” height=”15”>
<param name=”snd” value=”hello.au|welcome.au”>
java-аплет, который исполняет приветственную мелодию.
</object>
19. Введение HTML-документа в другой HTML-документ
Иногда возникает необходимость не связи с другим HTML-документом, а полного его включения в текст. Для решения такой задачи рекомендуется использовать элемент object с атрибутом data. Ниже следующая строка включит содержимое file_to_include.html в позицию документа, где размещен элемент object.
<object data=”file_to_include.html”>
warning: file_to_include.html could not be included.
</object>
Содержание object отображается только в случае, когда атрибут data не может быть загружен. При использовании операций включения следует проявлять осторожность, так как файл может содержать элементы, которые вызовут непредсказуемые действия. Для введения определенного текста в документ можно также использовать элемент Iframe.
20. Введение карты изображения в html-документ
Использование карты изображения позволяет разработчику специфицировать активные зоны изображения и поставить им в соответствие определенные операции. Карта изображения создается путем установления связи между объектом и определенными областями изображения. Существует два типа карт изображения:
Сторона сервера. Когда пользователь активирует область карты изображения со стороны сервера с помощью мышки, координаты нажатия клавиши посылаются серверу, где помещен документ. Сервер интерпретирует эти координаты и выполняет определенные действия (определено атрибутом href элемента А).
Сторона клиента. Когда пользователь активирует область карты изображения со стороны клиента с помощью мышки, координаты нажатия клавиши интерпретируются агентом пользователя. Агент пользователя выбирает связь, которая была специфицирована для активированной области.
Предпочтительной считается карта изображения клиента. Предусматривается возможность использования карты изображения несколькими элементами.
20.1. Карты изображения клиента
Ниже описаны атрибуты элементов A и AREA, которые позволяют разработчику специфицировать ряд геометрических областей и ассоциировать их с определенными URL.
Описания атрибутов
shape = default|rect|circle|poly
Этот атрибут специфицирует форму области. Возможные значения:
| default | специфицирует всю область. | |
| rect | выделяет прямоугольную область. | |
| circle | выделяет круговую область. | |
| poly | выделяет область, ограниченную многогранником. |
Этот атрибут специфицирует положение и форму области на экране. Число и порядок значений зависит от определенной формы. Возможны комбинации:
| rect: | левый-х, верхний-у, правый-х, нижний-у. | |
| circle: | х центра, у центра, радиус. | |
| poly: | х1, у1, х2, у2,…хn, yn. |
Для элемента object описан также булев атрибут shapes, который определяет то, что объект является картой изображения. Ниже представлен пример с картой изображения клиента.
<object data=:navbar.gif” shapes>
<a href=”guide.html” shape=”rect” coords=”0,0,118,28”>access guide</a> |
<a href=”shotcut.html” shape=”rect” coords=”118,0,184,28”>go</a> |
<a href=”search.html” shape=”circ” coords=”184,200,60”>search</a> |
<a href=”top10.html” shape=”poly” coords=”276,0,373,28,50,50,276,0”>top ten</a>
</object>
Если элемент object содержит атрибут shapes, агент пользователя должен анализировать содержимое элемента с целью поиска якорей. Если две или более областей перекрываются, область, определенная первой, имеет приоритет.
20.2. Карты изображения клиента с map и area
Элементы map и area предоставляют альтернативный механизм для карт изображения клиента.
<!element map - - (area)*>
<!element area – o empty>
<!attrlist area
Определение атрибута
| nohref | Этот булев атрибут (если =true) указывает на то, что данная область не имеет никаких связей. |
Рассмотрим пример, представленный выше, переписанный в терминах MAP и AREA.
<object data=:navbar1.gif” usemap=”#map></object>
<map name=”map1”>
<area href=”top10.html”
</map>
Атрибут alt специфицирует альтернативный текст на случай, когда карта изображения не может быть отображена. map не совместима с версией HTML 2.0.
Карты изображения сервера
Карты изображения сервера могут представлять интерес в случае, когда карта изображения слишком сложна для стороны клиента. Такая карта может быть создана с помощью элемента img. Для того чтобы сделать это, нужно установить булев атрибут ismap в описании элемента IMG. Соответствующие области должны быть описаны с помощью атрибута usemap. Когда пользователь активирует область карты изображения, соответствующие координаты посылаются непосредственно серверу, где помещен документ. Координаты на экране выражаются в пикселях. Агент пользователя берет новый URL из URL, описанного атрибутом HREF, присоединив к нему символ “?”, за которым следуют координаты х и у, разделенные запятой. Например, в предыдущем примере, если пользователь кликнет в области x=10, y=27, то будет получен URL=/cgibin/navbar.map?10,27.
В следующем примере первая активная область определяет связь со стороны клиента. Вторая - определяет связь со стороны сервера, но не определяет ее форму и размер (это осуществляется значением по умолчанию атрибута shape). Так как области этих связей перекрываются, первая имеет более высокий приоритет. Таким образом, кликнув мышкой где-либо в прямоугольной области, мы пошлем соответствующие координаты серверу.
<object data=”game.gif” shapes>
</object>
21. Визуальное представление изображений, объектов и аплетов
Применение атрибутов элементов img и object для целей управления отображением не рекомендуется, предпочтение, как и раньше здесь отдается стилевым листам. Атрибуты height и width дают агенту пользователя информацию о размере изображения или объекта, что позволяет зарезервировать для него место, а тем временем продолжить отображение документа. Оба атрибута могут иметь значение типа length. Агент пользователя может изменить масштаб, если это необходимо. Атрибуты vspace и hspace специфицируют размер полей вокруг изображения или объекта. Значения по умолчанию этих атрибутов не определено, оно должно быть мало, но не равно нулю.
22. Как специфицировать альтернативный текст?
Описание атрибута
alt = cdata
Для агента пользователя, который не может отображать изображения, формы или аплеты, этот атрибут позволяет ввести альтернативный текст. Язык этого текста задается атрибутом lang. Атрибут alt является обязательным для элемента area и опционным для img, applet и input.
23. Стилевые листы
Стилевые листы являются главным инструментом при разработке дизайна HTML-страниц. Они дают разработчику возможность преобразовать текст в изображение, отображать таблицы, писать программы и делать многое другое. HTML 4.0 поддерживает следующие возможности:
Гибкое размещение стилевой информации. Помещение стилевых листов в отдельные файлы упрощает их повторное использование.
Независимость от стилевых особенностей используемого языка. Данная спецификация HTML не привязывает его к какому-то определенному языку.
Каскадирование стилевых листов. Эта особенность позволяет совместно использовать стилевую информацию из нескольких источников.
Зависимость от среды. HTML позволяет описать документ независимым от среды способом, что обеспечивает доступ широкому кругу людей, работающих в различных средах (Windows, X11, Mac, мультимедиа системы и пр.). Стилевые листы позволяют адаптироваться к среде наилучшим образом, используя все предоставляемые ей возможности.
Альтернативные стили. Разработчик может предложить пользователю несколько альтернативных стилей представления данных. Например, отображение с мелкими или крупными шрифтами, с или без графических объектов и т.д.
HTML-документ может содержать стилевые рекомендации внутри, но можно их импортировать и извне. Синтаксис стилевых правил определяется языком стилевых листов CSS (Cascading Style Sheets), который не является частью HTML. Так как агент пользователя должен осуществлять разбор стилевых инструкций, пользователь обязан декларировать, какой стилевой язык он использует. Можно использовать элемент META для установки стилевого языка по умолчанию. Так для установления в качестве стилевого языка по умолчанию CSS, в head документа нужно включить следующую декларацию.
<meta http-equiv=”content-style-type” content=”text/css”>
Стилевой язык может быть задан также в http-заголовках. Например:
content-style-type: text/css
Если использовано несколько деклараций стилевого языка, работает самая последняя декларация. Если нет явной декларации стилевого языка, по умолчанию устанавливается CSS. HTML-элементы и атрибуты определяют начало стилевого листа. Конец стилевого листа определяется открытым разграничителем конечной метки, за которым следует начальный символ имени SGML [a-za-z]. Агент пользователя должен иметь соответствующий хандлер стилевого листа.
Одним из строчных стилевых атрибутов является style = Cdata. Этот атрибут специфицирует стилевую информацию для текущего элемента. Ниже приведен пример задания цвета и размера шрифта в тексте параграфа.
<p type=”text/css” style=”font-size: 12pt; color: fuschia”>aren’t style sheet wonderful?
Декларация типа имя: значение является конструкцией языка CSS. Если стиль планируется использовать повторно в нескольких элементах, более корректным будет применение элемента style, а не атрибута style, который носит одноразовый характер.
23.1. Стилевая информация заголовка. Элемент style
<!element style - - cdata -- стилевая информация --
<!attlist style
| %i18n; | -- lang, dir, для использования с title -- | |
| type cdata #implied | -- тип содержимого internet для стилевого языка -- | |
| media cdata #implied | -- предназначено для использования в этих средах -- | |
| title cdata #implied | -- рекомендуемый title -- > |
type = cdata
Этот атрибут специфицирует язык стилевого листа (заменяет значение по умолчанию). Стилевой язык специфицируется также как и тип среды Интернет (internet media type) (т.е. “text/css”).
media cdata-list
Этот атрибут специфицирует среду для стилевой информации. Это может быть одна среда или перечень, где отдельные элементы списка разделены запятыми. Возможные типы сред:
screen: |
Вывод на экран дисплей (без многостраничной поддержки). Значение по умолчанию. | |
print: |
Постраничный вывод на непрозрачную бумагу. Предназначен также для вывода на экран в режиме preview. | |
projection: |
Вывод на проектор. | |
braille: |
Вывод кодов Брайля на тактильное устройство | |
speach: |
Вывод на речевой синтезатор. | |
all: |
Вывод на все устройства сразу. |
Следующая декларация CSS style устанавливает рамку вокруг каждого Н1 элемента в документе и центрирует ее на странице.
<head>
<style type=”text/css”>
</head>
Для спецификации того, что этот стиль информации должен применяться только для Н1-элементов определенного класса, модифицируем эту запись следующим образом.
<head>
<style type=”text/css”>
</head>
<body>
</body>
И наконец, для того чтобы ограничить зону действия стилевой информации одним случаем Н1, установим атрибут ID.
<head>
</head>
<body>
</body>
В следующем примере использован элемент span для определения шрифтового стиля первых нескольких слов.
<head>
</head>
<body>
</body>
В следующем примере используется div и атрибут class для выравнивания последовательности параграфов. Эта стилевая информация может быть использована повторно, например, для форматирования резюме научных статей путем установки атрибута class в соответствующем месте документа.
<head>
</head>
<body>
</div>
</body>
23.2. Типы среды
HTML позволяет разработчику конструировать документы, структура которых не зависит от специфических свойств среды. В результате пользователь может просматривать этот документ с использованием самых разных агентов пользователя: на персональной ЭВМ, рабочей станции, Х-терминале, специально приспособленном телефонном аппарате и т.д..
Атрибут media специфицирует среду вывода для формирования стилевых правил. Установив атрибут media, разработчик может позволить агенту пользователя избежать копирования через сеть стилевых листов, не используемых в данном документе. Ниже предлагается пример деклараций для элемента Н1. При отображении на экране текст будет голубым и выровненным по центру, при печати текст будет выровнен по центру. Предусмотрена возможность вывода и на речевой синтезатор.
<head>
<style type=”text/css” media=”screen, print”>
h1 { text-align: center }
</style>
<style type=”text/acss” media=”speach”>
h1 { cue-before: url(bell.aiff); cue-after: url(dong.wav)}
</style>
</head>
Предыдущий пример может быть переписан для случая применения внешних стилевых листов (вместо элемента style) в сочетании с атрибутом media. Агент пользователя на основе атрибута media принимает решение о копировании из сети тех или иных стилевых листов.
<head>
<link href=”docl-screen.css” rel=”stylesheet”
<link href=”docl-print.css” rel=”stylesheet”
<link href=”docl-speach.css” rel=”stylesheet”
</head>
23.3. Внешние стилевые листы
Стилевые листы могут быть определены отдельно от документа. Это позволяет использовать такие стилевые листы во многих документах. Кроме того, стиль может быть изменен без модификации самого документа. Любой стиль обычно представляет собой иерархию стилевых листов. Некоторые из них используются вне зависимости от выбора пользователя. Для выбора внешних стилевых листов используется элемент Link. При этом необходимо установить следующие атрибуты:
| href | для определения места размещения внешнего стилевого файла (href=url). |
| rel | определяет, является ли данный стилевой лист постоянным (rel=”stylesheet”), стилевым листом по умолчанию (rel=”stylesheet”) или листом по выбору (rel=”alternate stylesheet”). |
| title | устанавливает заголовок в случае, когда стилевой лист является листом по умолчанию (активируется и деактивируется пользователем). |
/p> Сначала специфицируются постоянные (persistent) внешние стилевые листы (например, из файла mystyle.css).
<link href=”mystyle/css” rel=”stylesheet”>
Установка атрибута title превращает постоянный стилевой лист в лист по умолчанию. Агенты пользователя должны предоставлять возможность применения именованных стилей на базе атрибута title.
<link href=”mystyle/css” title=”compact” rel=”stylesheet”>
Добавление ключевого слова “alternate” к атрибуту rel делает стилевой лист альтернативным.
<link href=”mystyle/css” title=”medium” rel=”alternate stylesheet”>
Все альтернативные стили, имеющие один и тот же заголовок (title), будут использоваться, когда пользователь (через агента пользователя) активирует этот стиль. Стилевые листы с разными заголовками в этом случае не будут применены. Однако, стилевые листы, которые не имеют атрибута title, применяются всегда (за исключением случая, когда пользователь отключает все стилевые листы).
Агент пользователя должен обеспечить средства выбора стилей для пользователей. Значение атрибута title предоставляет имя, которое может использоваться при выборе стиля. В предлагаемом примере определено два альтернативных стиля, названных “compact”. Если пользователь выберет стиль “compact”, будут применены оба внешних стилевых листа, а также стилевой лист “common.css” (применяется всегда, так как атрибут title не установлен). Если пользователь выберет стиль “big print”, агент пользователя применит файлы “bigprint.css” и “common.css”.
<link rel=”alternate stylesheet” title=”compact” href=”small-base.css”>
<link rel=”alternate stylesheet” title=”compact” href=”small-extras.css”>
<link rel=”alternate stylesheet” title=”big- print” href=”bigprint.css”>
<link rel=stylesheet href=”common.css”>
Ниже предлагается вариант с элементами link и style.
<link rel=stylesheet href=”corporate.css”>
<link rel=stylesheet href=”techreport.css”>
<style type=”text/css”>
</style>
23.4. Установка именованного стиля по умолчанию
Для установки в документе именованного стиля по умолчанию используется элемент meta. Например (установка стилевого листа “compact” в качестве стиля по умолчанию):
<meta http-equiv=”default-style” content=”compact”
Стилевой лист по умолчанию может быть установлен в HTML-заголовке.
default-style: “compact”
Если имеется две или более деклараций стилевого листа по умолчанию, то работает последняя декларация. Если явной декларации стиля по умолчанию нет, то берется первый элемент link, где есть title и где имеется атрибут rel=”stylesheet”.
При отображении документа с использованием стилевых листов выполняются определенные правила наследования свойств (тип шрифта, цвет и т.д.). Если то или иное свойство не может быть наследовано, используется значение по умолчанию.
Некоторые стилевые языки поддерживают синтаксис, который позволяет разработчику спрятать содержимое элементов style от агентов пользователя, которые их не поддерживают, с тем, чтобы они не пытались отобразить эти фрагменты, как текст. Например (случай с CSS):
<style type=”text/css”>
<!-- h1 { color: red }
p { color: blue} -->
</style
Иногда бывает удобно, конфигурируя WEB-сервер, установить стилевые листы, которые воздействуют на группу WWW-страниц. HTTP Link-заголовок имеет то же воздействие, что и элемент Link с теми же атрибутами и значениями. Заголовки с несколькими Link работают также как и несколько элементов Link, в соответствии с их порядком записи.
link: rel=stylesheet href=”corporate.css”
cоответствует
<link rel=”stylesheet” href=”corporate.css”>
Можно описать несколько альтернативных стилей, используя несколько Link-заголовков, а затем с помощью атрибута Rel определить стиль по умолчанию.
link: rel=”stylesheet” title=”compact” href=”compact.css”
link: rel=”alrernate stylesheet” title=”big print” href=”bigprint.css”
23.5. Форматирование
Для задания цвета фона может использоваться атрибут bgcolor = color (хотя это и не рекомендуется). Применение стилевых листов для решения этой задачи предпочтительнее.
Другой проблемой форматирования является выравнивание текста. Для этой цели служит атрибут Align = left|center|right|justify. Здесь справедливы те же замечания, что и в случае атрибута bgcolor. Ниже предлагается пример решения задачи выравнивания с использованием стилевого листа.
<head>
<style>
h1 { test-align: center }
</style>
</head>
<h1> how to carve wood </h1>
Следует иметь в виду, что приведенный текст отцентрирует все заголовки Н1. Можно ограничить зону действия данного стиля, установив атрибут ID.
<head>
<style type=”text/css”>
h1.wood {text-align: center}
</style>
</head>
<h1 id=”wood”> how to carve wood </h1>
Аналогично для выравнивания по правому и левому полям с использование атрибута align:
<p align=”justify”> ….далее следует текст….
То же с использованием стилевого листа:
<head>
<style type=”text/css”>
p.mypar {text-align: justify}
</style>
</head>
<p id=”mypar”> ….далее следует текст….
Для двойного выравнивания последовательности параграфов можно группировать их с помощью элемента div.
<div align=”justify”>
<p> … текст первого параграфа….
<p> … текст второго параграфа….
<p> … текст третьего параграфа….
</div>
Решение той же задачи с использованием каскадирования стилевых листов:
<head>
<style type=”text/css”>
div.mypars {text-align: justify}
</style>
</head>
<div id=”mypars”>
<p> … текст первого параграфа….
<p> … текст второго параграфа….
<p> … текст третьего параграфа….
</div>
Для выравнивания всего документа с использованием каскадирования стилевых листов можно записать:
<head>
<style type=”text/css”>
body {text-align: justify}
</style>
</head>
<body>
… текст документа, подлежащий выравниванию …
</body>
Элемент center работает также как и элемент div с атрибутом align=”center”. Использование center не рекомендуется.
23.6. Плавающие объекты
Изображения и объекты могут быть привязаны к тексту, а могут обтекаться текстом, прижимаясь к одной из сторон документа и деформируя его поля. Плавающие объекты начинаются с новой строки. Для управления положением плавающего объекта используется атрибут align. Например:
<img align=”left” src=http://foo.com/animage.gif>
Существует атрибут для элемента br, который управляет обтеканием объекта текстом. Это clear= none|left|right|all, который определяет то, где должна появиться следующая строка в процессе отображения.
| none | следующая строка будет отображена как обычно (значение по умолчанию). |
| left | следующая строка будет помещена ниже плавающего объекта на левом поле. |
| right | следующая строка будет помещена ниже плавающего объекта на правом поле. |
| all | следующая строка будет помещена ниже плавающего объекта на любом из доступных полей. |

Рассмотрим вариант, когда текст размещается справа от изображения, и посмотрим, что будет после прерывания строки с помощью BR.

Если атрибут clear=”none”, следующая строка начнется сразу под уже имеющимся текстом.

Если же clear = “left” или all, то мы получим:
Используя стилевые листы, мы можем потребовать, чтобы все разрывы строк обрабатывались аналогичным образом. Для реализации этого можно записать:
<style type=”text/css”>
br { clear: left }
</style>
Для того чтобы такая схема размещения текста сработала только раз, следует воспользоваться атрибутом ID.
<head>
…….
<style type=”text/css”>
br.mybr }clear: left}
</style>
</head>
<body>

……..
</body>
23.7. Элементы управления шрифтами: tt, i, b, big, small, strike, s и u
<!entity % font
“tt | i | b | u | s | strike | big | small “>
<!element (%font|%phrase) - - (%inline)*>
<!attlist (%font|%phrase) %attrs; -- %coreattrs, %i18n, %events -- >
Ниже приведены примеры управления шрифтами.
<b>bold</b>
<i>italic</i>, <b><i>bold italic</i></b>, <tt>teletype text</tt>
<big>big</big> <small> small </small> text.
Броузер отобразит при этом на экране:
bold, italic, bold italic, teletype text, big, small text.
Использование стилевых листов позволяет получить значительно большее многообразие шрифтов. Например, нижеприведенный текст даст распечатку голубым курсивом:
<head>
<style>
p.mypar {font-style: italic; color: blue}
</style>
</head>
<p id=”mypar”> … далее следует текст, печатаемый голубыми буквами курсивом.
23.8. Элементы модификаторов шрифтов: font и basefont
<!element font - - (%inline)* -- локальное изменение шрифта -->
<!attlist font
<!element basefont - o empty>
<!attlist basefont
С этими элементами могут использоваться атрибуты (все они не рекомендуются к использованию):
size = cdata
Атрибут определяет размер шрифта (1-7).
color = color
Атрибут определяет цвет шрифта.
face = cdata-list
Атрибут определяет список шрифтов, которые агент пользователя должен рассматривать в порядке приоритета.
Элемент font изменяет размер и цвет шрифта для текста, в нем содержащегося. Элемент basefont устанавливает базовый размер шрифта (с помощью атрибута size). Размер шрифта, заданного font является относительным по отношению к размеру, определенному basefont. Если basefont не задан, значением по умолчанию считается 4. Ниже приведены примеры задания шрифтов с помощью font (данная форма определения размера шрифта не рекомендуется).
<p> <font size=1> size=1</font>
<font size=2> size=2</font>
<font size=3> size=3</font>
<font size=4> size=4</font>
<font size=5> size=5</font>
<font size=6> size=6</font>
<font size=7> size=7</font>
Агент пользователя при этом отобразит следующее
size=1 size=2 size=3 size=4 size=5 size=6 size=7
23.9. Элемент hr
<!element hr - o empty>
Определение атрибутов
Этот булев атрибут требует, чтобы агент пользователя пользовался одноцветным способом отображения линии.
size = length
(Не рекомендуется) Этот атрибут определяет высоту линии.
width = length
(Не рекомендуется) Этот атрибут определяет ширину линии (по умолчанию 100%), то есть линия пресекает весь экран.
Пример использования элемента hr.
<hr width=”50%” align=”center”>
<hr size=”5” width=”50%” align=”center”>
<hr size=”5” width=”50%” align=”center”>
24. Рамки (frames)
Обычный документ имеет одну секцию заголовка и одну секцию тела документа. Документ с рамками имеет заголовок (head), frameset (набор рамок) и, опционно, тело документа. Секция frameset специфицирует раскладку объектов в основном окне агента пользователя. Секция body предлагает альтернативу для случая агентов пользователя, которые не поддерживают frameset.
24.1. Элемент frameset
<!element frameset - - ((frameset|frame) + & noframes?)>
<!attlist frameset
Определения атрибутов
rows = length-list
Этот атрибут специфицирует выкладку горизонтальных рамок. Значение представляет собой список длин, разделенных запятыми. Если атрибут не задан, значение по умолчанию равно 100%.
cols = length-list
Этот атрибут специфицирует выкладку вертикальных рамок. Значение представляет собой список длин, разделенных запятыми. Если атрибут не задан, значение по умолчанию равно 100%.
Все рамки предполагаются прямоугольными. Установка атрибута rows определяет число рамок по горизонтали, а атрибут cols задает число рамок по вертикали. Таким образом, задается сетка рамок. Если атрибут rows не задан, каждая колонка занимает всю длину страницы. Если атрибут cols не задан, каждый ряд занимает всю ширину страницы. Если не заданы оба атрибута, на странице присутствует одна рамка, занимающая всю страницу.
Размер может задаваться в пикселях (абсолютно), в процентах от размеров экрана или в относительных длинах в форме i*, где i – целое число. Когда заданы оба атрибута, агент пользователя сначала выделяет размеры, заданные абсолютно, затем оставшуюся часть делит в соответствии с определенными долями. Значение * эквивалентно 1*. Отображение страницы осуществляется слева направо и сверху вниз. Пример (экран делится на две равные части, верхнюю и нижнюю):
<frameset rows=”50%, 50%”>
… остальная часть определения …
</frameset>
В следующем примере создается три колонки: вторая имеет фиксированную ширину в 250 пикселей (что удобно для картинки известного размера). Первая получает 25% оставшегося пространства, а третья – 75%.
<frameset cols=”1*,250,3*”>
… остальная часть определения …
</frameset>
В следующем примере создается решетка 2х3
<frameset rows=”30%,70%” cols=”33%,34%,33%”>
… остальная часть определения …
</frameset>
В следующем примере предполагается, что высота окна равна 1000 пикселей. Для первой рамки выделяется 30% общей высоты (300 пикселей). Для второй рамки выделено точно 400 пикселей. Это оставляет 300 пикселей на две оставшиеся рамки. Высота четвертой рамки определена как “2*”, а третей - *, следовательно, третья получит 100, а четвертая – 200 пикселей.
<frameset rows=”30%,400,*,2*” >
… остальная часть определения …
</frameset>
Если при задании абсолютных размеров остается свободное место, или возникает перерасход пространства, агент пользователя пропорционально увеличит или уменьшит размеры рамок. frameset могут вкладываться друг в друга на любом уровне. В приведенном примере внешний frameset делит имеющееся пространство на три равные колонки. Внутренний frameset делит вторую область на два ряда не равной высоты.
<frameset rows=”33%,33%,34%” >
…содержимое первой рамки…
</frameset>
24.2. Элемент frame
<!element frame - o empty>
<!attlist frame
Определения атрибутов
name = cdata
Атрибут присваивает имя текущей рамке. К этому имени можно адресоваться.
src = url
Этот атрибут специфицирует положение исходного документа, содержимое которого заключено в рамку.
noresize
Этот булев атрибут говорит агенту пользователя, что размер окна рамки не может быть изменен.
scrolling = auto|yes|no
Этот атрибут специфицирует информацию о возможности прокрутки информации в данной рамке. Возможные значения:
| auto: | говорит агенту пользователя, что он может организовывать скроллинг по своему усмотрению (значение по умолчанию) | |
| yes: | говорит агенту пользователя, что он должен обеспечить скроллинг информации в окне. | |
| no: | говорит агенту пользователя, что скроллинг делать не нужно. |
/p> frameborder=1|0
Этот атрибут предоставляет агенту пользователя информацию о рамке вокруг текущего окошка. 1 означает, что агент пользователя должен прочертить границу вокруг текущей рамки (значение по умолчанию). 0 означает, что агент пользователя не должен прочерчивать границу вокруг текущей рамки.
marginwidth = length
Этот атрибут специфицирует правое и левое поля между текстом и границей рамки. Значение должно быть больше одного пикселя. Значение по умолчанию определяет агент пользователя.
marginheight = length
Этот атрибут специфицирует размер верхнего и нижнего поля между текстом и границей рамки. Значение должно быть больше одного пикселя. Значение по умолчанию определяет агент пользователя.
Атрибут SRC определяет источник текста, помещаемого в рамку. Содержимое рамки не может быть записано в том же документе, в котором описана сама рамка. Пример:
<html>
<frameset cols=”33%, 33%, 33%”>
</frameset>
</html>
В результате будет получена раскладка рамок, показанная ниже не рисунке.
Ниже приведенный пример содержит в себе ошибку, так как текст второй рамки включен в описание самой рамки.
<html>
<frameset cols=”50%,50%”>
</frameset>
<body>

… некоторый текст…
<h2><a name=”anchor_in_same_document”>important section</a></h2>
… некоторый текст…
</body>
</html>
Существует атрибут target = cdata, который специфицирует имя рамки, где должна быть размещена информация. Путем присвоения с помощью атрибута name имени рамке разработчик может ссылаться на нее, как на адрес связей. Атрибут target может быть установлен для элементов, создающих связи (А, link), карты изображения (area) и формы (form). Ниже предлагается пример, где target позволяет динамически изменять содержимое рамки:
<html>
<frameset rows=”50%,50%”>
</frameset>
</html>
Затем в init_dynamic.html мы организуем связь с рамкой под именем “dynamic”
<html>
<body >
… начало документа …
now you may advance to
… продолжение документа …
you’re doing great. now on to
</body>
</html>
Активирование любой связи приводит к открытию документа в рамке с именем “dynamic”, в то время как другие рамки (“fixed”) остаются со своим исходным содержимым.
24.3. Установка для связей адресов по умолчания
Когда многие связи в документе указывают на один и тот же адрес, имеется возможность специфицировать адрес только один раз, а ссылки обеспечить путем введения атрибута target в нужные элементы. Это делается путем установки атрибута target элемента base. Рассмотрим предыдущий пример с этой точки зрения.
<html>
<head>
<base target=”dynamic”>
</head>
<body>
… начало документа …
now you may advance to <a href=”slide2.html”>slide 2.</a>
… продолжение документа …
you’re doing great. now on to
<a href=”slide3.html”>slide 3.</a>
</head>
</html>
Существует несколько методов сделать рамку адресом связи.
Если элемент имеет атрибут target, указывающий на известную рамку, тогда при активации элемента, документ связанный с этим элементом, будет загружен в данную рамку.
Если элемент не имеет атрибута target и имеет элемент base, тогда именно base определяет рамку, куда будет произведена загрузка.
Если элемент и base не имеют атрибута target, документ, соответствующий элементу, будет загружен в рамку, содержащую этот элемент.
Если любой адрес (target) указывает на рамку f, агент пользователя создаст новое окно и рамку, припишет имя f этой рамке и загрузит документ, соответствующий элементу, в эту новую рамку.
Имя рамки должно начинаться с буквы (a-za-z). Агент пользователя должен игнорировать любые другие имена. Существует несколько имен, зарезервированных для специальных целей.
| _blank | агент пользователя должен загрузить документ в новую безымянную рамку. |
| _self | агент пользователя должен загрузить документ в ту же рамку, что и элемент, который ссылается на этот адрес (target). |
| _parent | агент пользователя должен загрузить документ в frameset, породивший текущую рамку. Это значение эквивалентно _self, если текущая рамка не имеет прародителя. |
| _top | агент пользователя должен загрузить документ в полное исходное окно. Значение эквивалентно _self, если текущее окно не имеет прародителя. |
24.4. Элемент noframes
<!element noframes - - (#pcdata, ((body,#pcdata)|
Элемент noframes специфицирует содержимое, которое должно быть отображено, только когда не отображаются рамки. Агенты пользователя могут отображать содержимое только в случае, когда они сконфигурированы с блокировкой поддержки рамок.
Предположим, что имеется frameset, определенный в “top.html”, который отображает документ “main.html”, и оглавление этого документа (“table_of_contents.html”). Тогда содержимое “top.html”:
<html>
<frameset cols=”50%,50%”>
</frameset>
</html>
Когда пользователь читает “top.html”, а агент пользователя не поддерживает работу с рамками, на экране ничего не появится, если в секции body (“top.html”) нет альтернативного текста. Если мы введем ”table_of_contents.html” и ”main.html” непосредственно в body, задача ассоциации документов будет решена. Но при этом мы можем заставить агента пользователя, который поддерживает рамки, скопировать один и тот же документ дважды. Более экономно включить оглавление в начало ”main.html”, в элемент noframes:
<html>
<body>
<noframes>
… оглавление …
</noframes>
… остальная часть документа …
</body>
</html>
Элемент noframes может использоваться в frameset-секции документа. Например:
<!doctype html public "-//w3c//dtd HTML 4.0 frameset//en"
"http://www.w3.org/tr/rec-html40">
<html>
<head>
<title>a frameset document with noframes</title>
</head>
<frameset cols="50%, 50%">
<frame src="main.html">
<frame src="table_of_contents.html">
<noframes>
<p>here is the <a href="main-noframes.html">
версия документа non-frame.</a>
</noframes>
</frameset>
</html>
24.5. Элемент iframe
| <!element iframe - - (%flow;)* | -- субокно в блоке текста --> |
| %coreattrs; | -- id, class, style, title -- | |
| longdesc %uri; #implied | -- указатель на более длинное описание (дополнение к title) -- | |
| name cdata #implied | -- имя файла для адресации -- | |
| src %uri; #implied | -- источник содержимого рамки -- | |
| frameborder (1|0) 1 | -- request frame borders? -- | |
| marginwidth %pixels; #implied | -- ширина поля в пикселях -- | |
| marginheight %pixels; #implied | -- высота поля в пикселях -- | |
| scrolling (yes|no|auto) auto | -- наличие поля прокрутки -- | |
| align %ialign; #implied | -- вертикальное и горизонтальное выравнивание -- | |
| height %length; #implied | -- высота рамки -- | |
| width %length; #implied | -- ширина рамки -- > |
longdesc = uri
Этот атрибут специфицирует связь с длинным описанием рамки. Это описание должно быть дополнением короткого описания, данного в атрибуте title.
name = cdata
Этот атрибут присваивает имя текущей рамке. Это имя может использоваться в последующих ссылках.
width = length
Ширина рамки.
height = length
Высота рамки.
Элемент Iframe позволяет разработчику ввести рамку в блок текста. Эта процедура схожа с введением одного HTML-документа в другой с помощью элемента object. Информация, которая должна быть введена, определяется атрибутом src этого элемента. Содержимое элемента Iframe отображается только агентами пользователя, которые не поддерживают рамки. Пример, когда рамка вводится внутрь текста, приведен ниже.
<iframe src="foo.html" width="400" height="500"
scrolling="auto" frameborder="1">
[ Ваш агент пользователя не поддерживает рамки или сконфигурирован без поддержки рамок]. Кликните для извлечения <a href="foo.html"> сопряженного документа. </a>]
</iframe>
Размеры этих рамок не могут быть изменены.
25. Формы
HTML-форма представляет собой часть документа, содержащая обычный текст, разметку (markup) и специальные элементы управления, называемые controls. controls служат для приема и обработки текста, вводимого пользователем. Форма – это аналог стандартного бланка, заполняемого пользователем. Заполненная форма может быть послана по почте другому пользователю, или передана программе для последующей обработки. Каждый control (графа бланка) должен иметь имя, а его значение определяется его типом. Ниже приведен пример формы, где используются метки и различного типа кнопки:
<form action="http://somesite.com/prog/adduser" method="post">
<p>
<label for="firstname">first name: </label>
<input type="text" id="firstname"><br>
<label for="lastname">last name: </label>
<input type="text" id="lastname"><br>
<label for="email">email: </label>
<input type="text" id="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
Каждый control имеет исходное и текущее значение, каждое из которых представляет собой символьную строку. Исходное значение может быть определено с помощью соответствующего атрибута.
Кнопки
Разработчики могут создавать три типа кнопок:
submit-кнопки. При активации эти кнопки преадресуют форму адресату. Форма может содержать более одной submit-кнопки.
Кнопки сброса: При активации эти кнопки возвращают все controls в исходное состояние.
Кнопки нажатия. Эти кнопки не имеют какого-либо фиксированного назначения. Каждой такой кнопке может быть поставлен в соответствие, например, скрипт клиента.
Разработчик создает кнопку с помощью элемента button или input. Следует иметь в виду, что элемент button предоставляет более широкие возможности, чем input.
Переключатели
Переключатели (chekbox; и радио-кнопки) представляют собой двухпозиционные приборы, которые могут находиться в состоянии on/off (вкл/выкл). Пользователь может переводить этот переключатель из одного состояния в другое. Переключатель находится в состоянии "on", когда установлен соответствующий атрибут управляющего элемента.
Несколько переключателей могут относиться к одному и тому же control, позволяя, например, выбрать одно из нескольких значений определенного параметра. Для формирования переключателя используется элемент input.
Радио-кнопки
Радио-кнопки схожи с переключателями. Но здесь при наличии нескольких кнопок, относящихся к одному имени control, перевод одной кнопки в состояние "on" переводит все другие кнопки с тем же именем в состояние "off". Для создания радио-кнопок используется элемент input.
Меню
Меню предоставляет пользователю выбор из нескольких возможностей. Для формирования меню используется элемент select, в сочетании с элементами optgroup и option.
Ввод текста
Разработчик может создать два типа controls, которые позволяют вводить текст. Элемент input создает однострочный control для ввода, а textarea предназначен для многострочного ввода. В обоих случаях введенный текст становится текущим значением control.
Выбор файла
Этот тип control позволяет пользователю выбрать файлы, так что их содержимое будет введено в форму. Для обеспечения выбора файла используется элемент input.
Скрытые элементы управления control
Разработчик может создать control, которые не отображаются на экране, но величины которых заносятся в форму. Для формирования скрытого control используется элемент input.
Объектные control
Разработчик может ввести в форму общие объекты, так что соответствующие величины будут заноситься в форму. Для работы с объектными control используется элемент object.
Элементы, используемые для создания controls, обычно вводятся в элемент FORM, но могут появляться и вне декларации FORM, когда они используются для построения интерфейса пользователя.
25.1. Элемент FORM
| <!element form - - (%block;|script)+ -(form) | -- интерактивная форма --> | |
| <!attlist form %attrs; | -- %coreattrs, %i18n, %events -- | |
| action %uri; #required | -- хандлер форм со стороны сервера -- | |
| method (get|post) get | -- http метод для ввода форм -- | |
| enctype %contenttype; "application/x-www-form-urlencoded" | ||
| onsubmit %script; #implied | -- форма введена -- | |
| onreset %script; #implied | -- форма возвращена в исходное состояние -- | |
| accept-charset %charsets; #implied | -- список поддерживаемых символьных наборов --> |
action = url
Этот атрибут специфицирует агента, который осуществляет обработку формы. Например, возможным значением атрибута может быть HTTP URI (для передачи формы программе) или mailto URI (для пересылки формы по электронной почте).
method = get|post
Этот атрибут специфицирует http-метод, который будет использоваться для представления данных. Возможные значения: "get" (по умолчанию) и "post". Метод post вводит пары имя/значение в тело формы.
enctype = content-type
Этот атрибут специфицирует тип содержимого (internet media type), используемого при передаче формы серверу (когда метод = "post"). Значение по умолчанию атрибута равно "application/x-www-form-urlencoded". Значение "multipart/form-data" должно использоваться в сочетании с type="file” элемента input.
accept-charset = charset list
Этот атрибут специфицирует список кодировок символов для входных данных, которые должны быть приняты сервером, обрабатывающим эти формы. Значения атрибута представляют собой список значений символьных комбинаций, разделенных пробелами или запятыми. Сервер должен интерпретировать этот список и воспринимать любой односимвольный код. Значение этого атрибута по умолчанию равно "unknown". Агент пользователя может интерпретировать это значение как символьную комбинацию, которая была использована для передачи документа, содержащего этот элемент form.
accept = content-type-list
Этот атрибут специфицирует список типов содержимого (в качестве разделителей используются занятые), которые сможет корректно воспринять и обработать сервер форм.
Элемент form работает как контейнер для controls. Он специфицирует:
Выкладку формы (заданную содержимым элемента).
Программу, которая будет обрабатывать заполненную форму (атрибут action). Принимающая программа должна быть способна разобрать пары имя/значение, для того чтобы использовать их.
Метод, посредством которого данные пользователя будут посланы серверу (атрибут method).
Кодировку символов, которая должна быть воспринята сервером, для того чтобы успешно произвести последующую обработку полученной формы (атрибут accept-charset). Агенты пользователя могут подсказать пользователю значения атрибута accept-charset и/или ограничить возможность ввода неузнаваемых символов.
Ниже приведен пример, который показывает форму, которая должна быть обработана программой "adduser". Форма посылается программе с помощью метода http "post”.
<form action="http://somesite.com/prog/adduser" method="post">
...form contents...
</form>
Следующий пример показывает, как послать форму по заданному электронному адресу:
<form action="mailto:kligor.t@gee.whiz.com" method="post">
...содержимое формы...
</form>
25.2. Элемент input
<!entity % inputtype
"(text | password | checkbox | radio | submit | reset |
file | hidden | image | button)" >
<!-- имя атрибута необходимо для всех кроме submit & reset -->
| <!element input - o empty | -- управление формой --> |
| <!attlist input %attrs; | -- %coreattrs, %i18n, %events -- |
| type %inputtype; text | -- what kind of widget is needed -- |
| name cdata #implied | -- представить как часть формы -- |
| value cdata #implied | -- необходимо для радио-кнопок и переключателей -- |
| checked (checked) #implied | -- для радио-кнопок и переключателей -- |
| disabled (disabled) #implied | -- не доступно в данном контексте -- |
| readonly (readonly) #implied | -- для текста и пароля -- |
| size cdata #implied | -- разный для каждого типа полей -- |
| maxlength number #implied | -- макс. число символов для текст. полей -- |
| src %uri; #implied | -- для полей с изображением -- |
| alt cdata #implied | -- краткое описание -- |
| usemap %uri; #implied | -- использование карты изображения клиента -- |
| tabindex number #implied | -- position in tabbing order -- |
| accesskey %character; #implied | -- клавиша доступа -- |
| onfocus %script; #implied | -- элемент выделен -- |
| onblur %script; #implied | -- элемент не выделен -- |
| onselect %script; #implied | -- некоторый текст был выбран -- |
| onchange %script; #implied | -- значение элемента изменилось -- |
| accept %contenttypes; #implied | -- list of mime types for file upload --> |
type = text|password|checkbox|radio|submit|reset|file|hidden|image|button
Этот атрибут специфицирует тип создаваемого control. Значение по умолчанию "text".
name = cdata
Этот атрибут присваивает имя control.
value = cdata
Этот атрибут специфицирует начальное значение control.
size = cdata
Этот атрибут сообщает агенту пользователя исходную ширину control. Ширина задается в пикселях, за исключением случая, когда тип атрибута "text" или "password". В этом варианте ширина измеряется числом символов.
maxlength = number
Когда тип атрибута "text" или "password", этот атрибут специфицирует максимальное число символов, которое предлагается ввести пользователю. Это число может превзойти указанный размер, тогда агент пользователя должен предложить механизм скроллинга.
checked.
Когда тип атрибута "radio" или "checkbox", этот булев атрибут указывает, что кнопка нажата. Агент пользователя должен игнорировать этот атрибут для всех других видов control.
src = url
Когда тип атрибута "image", этот атрибут специфицирует положение изображения, которое будет использовано для украшения кнопки.
Атрибут type элемента input определяет то, какой управляющий элемент создан.
text |
Этот тип создает текстовый бокс на одну строчку. Значение текстового control равно введенному тексту. |
password |
Подобен типу “text”, но отображение ввода делается так, что вводимые символы не видны (напр. каждому введенному символу ставится в соответствие *). Значение данного типа control равно введенному тексту. Служит для ввода паролей. |
checkbox |
Представляет собой двух позиционный переключатель (вкл/выкл=on/off). Когда переключатель в положении on, значение checkbox = “active”. Состояние переключателя передается только в случае, когда переключатель в состоянии on. |
<form action="http://somesite.com/prog/adduser" method="post">
<p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
radio |
также является двухпозиционным переключателем. Единственным отличием от checkbox является то, что при наличии нескольких радио-кнопок с идентичным именем в состоянии on может быть всегда только одна. | |
submit |
формирует кнопку submit. При активации этой кнопки пользователем, форма передается по адресу, указанному атрибутом action элемента form. Форма может содержать несколько таких кнопок. | |
image |
Создает графический образ кнопки submit. Значение атрибута src специфицирует URL изображения кнопки. Рекомендуется воспользоваться атрибутом alt, чтобы создать альтернативный текст для агентов пользователя, не поддерживающих графику. Если кнопка активизирована, форма передается серверу-адресату. Передаваемые данные содержат значения name.x=x и name.y=y, где “name” – значение атрибута name, х – число пикселей от левого края изображения, а у – число пикселей от верхней кромки изображения. Это позволяет варьировать реакцию сервера от координат места, где была нажата кнопка мышки. | |
reset |
Создает кнопку сброса. При нажатии этой кнопки пользователем всем controls формы присваиваются исходные значения, заданные атрибутом value. Пара имя/значение кнопки reset вместе с формой не пересылается. | |
button |
Создает кнопку, которая не имеет заранее определенной функции. Эта функция определяется скриптом клиента, который запускается при нажатии этой кнопки. Например, создадим кнопку, которая вызывает функцию verify: | |
| <input type=”button” value=”click me” onclick=”verify()”> | ||
hidden |
Создает элемент, не видимый при работе агента пользователя. Однако, имя и значение элемента передаются серверу вместе с формой. Эта форма controls используется для запоминания информации в паузах между обменами клиент/сервер. Следующий control типа hidden, тем не менее, должен передавать свое значение вместе с формой. | |
| <input type=”password” style=”display:none” | ||
| name=”invisible-password” | ||
| value=”mypassword”> | ||
file |
Позволяет пользователю присоединить содержимое файла к форме. |
/p> Следующий пример представляет собой анкету, предложенную выше, дополненную кнопками submit и reset. Кнопки содержат изображения, для чего использован элемент img.
<form action="http://somesite.com/prog/adduser" method="post">
<p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<button name="submit" value="submit" type="submit">
send<img src="/icons/wow.gif" alt="wow"></button>
<button name="reset" type="reset">
reset<img src="/icons/oops.gif" alt="oops"></button>
</p>
</form>
Внешне данная форма будет выглядеть для пользователя следующим образом:

25.3. Элемент isindex
<!element isindex - o empty>
<!attlist isindex
| %coreattrs; | -- id, class, style, title -- | |
| %i18n; | -- lang, dir -- | |
| prompt cdata @implied | -- сообщение-приглашение (prompt) --> |
Описание атрибута
prompt = cdata
Атрибут специфицирует строку приглашения для ввода. Служит для ввода одной строки пользователем. Например:
<isindex prompt=”enter your name: “>
Та же задача решается с использованием элемента input следующим образом (рекомендуемый вариант):
<form action=”…” method=”post”>
enter your name: <input type=”text”>
</form>
25.4. Элемент button
<!element button - - (%flow;)* -(a|%formctrl;|form|fieldset) -- клавиша -->
<!attlist button
| %attrs | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| value cdata #implied | -- при представлении посылать серверу -- | |
| type (button|submit|reset) submit | -- для использования в качестве кнопки -- | |
| disabled (disabled) #implied | -- в данном контексте недоступно -- | |
| tabindex number #implied | -- position in tabbing order -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- > |
/p> Описание атрибутов
name = cdata
Этот атрибут присваивает имя кнопке.
value = cdata
Этот атрибут присваивает значение кнопке.
type = button | submit | reset
Этот атрибут декларирует тип кнопки. Когда атрибут не задан, поведение кнопки не определено. Возможные значения:
| button: | Создает простую кнопку, которая может запускать скрипт. | |
| submit: | Создает кнопку, которая служит для отправки формы серверу (значение по умолчанию). | |
| reset: | Создает кнопку сброса для формы. |
<form action="http://somesite.com/prog/adduser" method="post"><p>
first name: <input type="text" name="firstname"><br>
last name: <input type="text" name="lastname"><br>
email: <input type="text" name="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<button name="submit" value="submit" type="submit">
send<img src="/icons/wow.gif" alt="wow"></button>
<button name="reset" type="reset">
reset<img src="/icons/oops.gif" alt="oops"></button>
</p>
</form>
Если используется button с элементом img, рекомендуется применение img-элемента с атрибутом alt, чтобы обеспечить совместимость с агентами пользователя, не поддерживающими графику. Недопустимо использование карты изображения с img в элементе button:
<button>
<img src=”foo.gif” usemap=”…”>
</button>
Элемент button с типом “reset” очень похож на элемент input с типом “reset”.
25.5. Элемент select
<!element select - - (optgroup|option)+ -- селектор опции -->
<!attlist select
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | -- имя поля -- | |
| size number #implied | -- rows visible -- | |
| multiple (multiple) #implied | -- по умолчанию один выбор -- | |
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| tabindex number #implied | -- position in tabbing order -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onchange %script; #implied | -- значение элемента изменено --> |
name = cdataЭтот атрибут присваивает имя control.
size = number
Если элемент select представлен в виде окна с полосой прокрутки, этот атрибут специфицирует число рядов в списке, которые должны быть видны одновременно. Визуальный агент пользователя не должен представлять элемент select в качестве окна; он может использовать и другой механизм, например, выпадающее меню.
multiple
Этот булев атрибут позволяет обеспечить множественный выбор. При отсутствии этого атрибута допускается только один выбор.
Элемент select создает список вариантов, из которых может выбирать пользователь. Каждый элемент select должен предложить как минимум один вариант. Каждый вариант специфицируется с помощью элемента option.
| <!element option - o (#pcdata) | -- доступный выбор --> | |
| <!attlist option | -- %coreattrs, %i18n, %events -- | |
| %attrs; | ||
| selected (selected) #implied | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| label %text; #implied | -- для использования иерархического меню -- | |
| value cdata #implied | -- содержимое элемента по умолчанию --> |
Этот булев атрибут определяет то, что данная опция является уже выбранной (pre-selected).
value = cdata
Этот атрибут специфицирует исходное значение control. Если атрибут не установлен, исходное значение определяется содержимым элемента option.
label = text
Этот атрибут позволяет разработчику специфицировать более короткую метку, чем содержимое элемента option. Если атрибут задан, агент пользователя должен использовать в качестве метки опции значение атрибута, а не содержимое элемента option.
Элемент select помогает создать меню, с помощью которого осуществляется выбор опции. Ниже приведен пример создания такого меню.
<form action="http://somesite.com/prog/component-select" method="post">
<p>
<select multiple size="4" name="component-select">
<option selected value="component_1_a">component_1</option>
<option selected value="component_1_b">component_2</option>
<option>component_3</option>
<option>component_4</option>
<option>component_5</option>
<option>component_6</option>
<option>component_7</option>
</select>
<input type="submit" value="send"><input type="reset">
</p>
</form>
Атрибут size определяет, что в окне должно быть видно 4 опции. Реальное число опций равно 7, по этой причине выбор остальных опций возможен с помощью механизма скролинга.
Элемент optgroup позволяет разработчику логически сгруппировать опции. Это особенно удобно, когда пользователь должен сделать выбор из длинного списка опций. В HTML 4.0 все элементы optgroup должны быть специфицированы в пределах элемента select (т.е., группы не могут вкладываться друг в друга). В ниже приведенном примере показано использование элемента optgroup:
<form action="http://somesite.com/prog/someprog" method="post">
<p>
<select name="comos">
<optgroup label="portmaster 3">
<option label="3.7.1" value="pm3_3.7.1">portmaster 3 with comos 3.7.1
<option label="3.7" value="pm3_3.7">portmaster 3 with comos 3.7
<option label="3.5" value="pm3_3.5">portmaster 3 with comos 3.5
</optgroup>
<option label="3.7" value="pm2_3.7">portmaster 2 with comos 3.7
<option label="3.5" value="pm2_3.5">portmaster 2 with comos 3.5
</optgroup>
<optgroup label="irx">
<option label="3.7r" value="irx_3.7r">irx with comos 3.7r
<option label="3.5r" value="irx_3.5r">irx with comos 3.5r
</optgroup>
</select>
</form>
25.6. Элемент optgroup
| <!element optgroup - - (option)+ | -- группа опции --> | |
| <!attlist optgroup | ||
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| disabled (disabled) #implied | -- недоступно в данном контексте -- |
label = text [cs]
Этот атрибут специфицирует метку опции для группы опций.
Когда форма передается на обработку, каждый из выборов группируется с именем “component-select”.
25.7. Элемент textarea
| <!element textarea - - (#pcdata) | -- поле многострочного текста --> |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| rows number #required | ||
| cols number #required | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| readonly (readonly) #implied | ||
| tabindex number #implied | -- position in tabbing order -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onselect %script; #implied | -- некоторый текст выбран -- | |
| onchange %script; #implied | -- значение элемента изменено -- > |
name = cdata [ci]
Этот атрибут присваивает имя control.
rows = number [cn]
Этот атрибут специфицирует номер видимой строки текста. Пользователь может ввести больше строк, чем это число, по этой причине агент пользователя должен предоставить средства для скролирования текста, чтобы обеспечить доступ к строкам за пределами видимости окна.
cols = number [cn]
Этот атрибут специфицирует видимую ширину строки (в символах). Пользователь может иметь возможность ввести более длинные строки, так что агент пользователя должен обеспечить средства для скролирования текста по горизонтали. Агент пользователя может разрывать строки, чтобы их сделать видимыми по всей длине без горизонтального скролинга.
Пример использования элемента textarea для создания текстовой области размером 20 строк по 80 колонок. В исходный момент зона содержит только две строки.
<form action="http://somesite.com/prog/text-read" method="post">
<p>
<textarea name="thetext" rows="20" cols="80">
first line of initial text.
second line of initial text.
</textarea>
<input type="submit" value="send"><input type="reset">
</p>
</form>
25.8. Элемент label
<!element label - - (%inline;)* -(label) -- form field label text -->
<!attlist label
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| for idref #implied | -- matches field id value -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен --> |
for = idref [cs]
Этот атрибут устанавливает соответствие между меткой и control. При наличии этого атрибута его значение должно совпадать с атрибутом id другого control того же документа. При отсутствии этого атрибута метка ставится в соответствие содержимому элемента.
Элемент label может использоваться для привязки информации к другим элементам control (за исключением других элементов label). Ниже приведены два примера использования элемента label.
<form action="..." method="post">
<table>
<tr>
<td><label for="fname">first name</label>
<td><input type="text" name="firstname" id="fname">
<tr>
<td><label for="lname">last name</label>
<td><input type="text" name="lastname" id="lname">
</table>
</form>
<form action="http://somesite.com/prog/adduser" method="post">
<p>
<label for="firstname">first name: </label>
<input type="text" id="firstname"><br>
<label for="lastname">last name: </label>
<input type="text" id="lastname"><br>
<label for="email">email: </label>
<input type="text" id="email"><br>
<input type="radio" name="sex" value="male"> male<br>
<input type="radio" name="sex" value="female"> female<br>
<input type="submit" value="send"> <input type="reset">
</p>
</form>
Для установления неявной связи между меткой и другим control контрольный элемент должен находиться внутри содержимого элемента label. В этом случае label может содержать только один контрольный элемент. В примере две метки неявно поставлены в соответствие двум вводимым текстам:
<form action="..." method="post">
<p>
<label>
first name
<input type="text" name="firstname">
</label>
<label>
<input type="text" name="lastname">
last name
</label>
</p>
</form>
25.9. Элементы fieldset и legend
<!-- #pcdata служит для решения проблемы смешанных данных, согласно спецификации здесь допустимы только whitespace! -->
<!element fieldset - - (#pcdata,legend,(%flow;)*) >
<!attlist fieldset
| %attrs; | -- %coreattrs, %i18n, %events -- > |
| <!element legend - - (%inline;)* | -- легенда поля --> |
<!attlist legend
| %attrs; | -- %coreattrs, %i18n, %events -- > |
| accesskey %character; #implied | -- клавиша доступа -- > |
align = top|bottom|left|right
Не рекомендуется к применению
. Этот атрибут специфицирует положение легенды по отношению к набору полей. Возможные значения:
| top: | Легенда размещается сверху (значение по умолчанию). |
| bottom: | Легенда размещается внизу. |
| left: | Легенда размещается слева. |
| right: | Легенда размещается справа. |
Элемент legend позволяет разработчику поставить в соответствие надпись, поясняющую назначение полей, и fieldset. Ниже представлен пример использования этих элементов.
<form action="..." method="post">
<p>
<fieldset>
<legend>personal information</legend>
last name: <input name="personal_lastname" type="text" tabindex="1">
first name: <input name="personal_firstname" type="text" tabindex="2">
address: <input name="personal_address" type="text" tabindex="3">
...more personal information...
</fieldset>
<fieldset>
<legend>medical history</legend>
<input name="history_illness"
type="checkbox"
value="smallpox" tabindex="20"> smallpox
<input name="history_illness"
type="checkbox"
value="mumps" tabindex="21"> mumps
<input name="history_illness"
type="checkbox"
value="dizziness" tabindex="22"> dizziness
<input name="history_illness"
type="checkbox"
value="sneezing" tabindex="23"> sneezing
...more medical history...
</fieldset>
<fieldset>
<legend>current medication</legend>
are you currently taking any medication?
<input name="medication_now"
type="radio"
value="yes" tabindex="35">yes
<input name="medication_now"
type="radio"
value="no" tabindex="35">no
if you are currently taking medication, please indicate
it in the space below:
<textarea name="current_medication"
rows="20" cols="50"
tabindex="40">
</textarea>
</fieldset>
</form>
Обратите внимание на то, что в этом примере можно улучшить представление формы путем выравнивания элементов в пределах каждого fieldset (с помощью стилевых листов), добавив цвета, подобрав шрифты и используя скрипты.
26. Выделение элементов
Активный элемент HTML-документа должен быть выделен. Существует несколько способов выделения элемента:
Пометить элемент с помощью мышки.
Выделить нужный элемент, перемещаясь от элемента к элементу с помощью стрелок или других клавиш.
Выбрать нужный элемент, нажав определенную комбинацию клавиш.
Описание атрибута
tabindex = integer
Этот атрибут специфицирует положение текущего элемента по порядку, значение может быть положительным или отрицательным.
Элементы, которые могут быть выделены, должны обрабатываться агентом пользователя согласно следующим правилам:
Тем элементам, которые поддерживают атрибут tabindex, присваиваются положительные значения и они просматриваются первыми. Процесс просмотра начинается с меньших значений tabindex и продолжается в направлении больших. Элементы, которые имеют равные значения tabindex должны обрабатываться в порядке их появления в документе.
Элементы, для которых атрибут tabindex не определен или не поддерживается, просматриваются в порядке их появления в документе.
Те элементы, которым приписано отрицательное значение tabindex, не участвуют в процессе просмотра.
Атрибут tabindex поддерживается элементами a, area, object, input, select, textarea и button. Ниже предлагается пример.
<!doctype html public "-//w3c//dtd html 4.0//en"
"http://www.w3.org/tr/rec-html40/strict.dtd">
<html>
<head>
<title>a document with form</title>
</head>
<body>
...some text...
<p>go to the
<a tabindex="10" href="http://www.w3.org/">w3c web site.</a>
...some more...
<button type="button" name="get-database"
tabindex="1" onclick="get-database">
get the current database.
</button>
...some more...
<form action="..." method="post">
<p>
<input tabindex="1" type="text" name="field1">
<input tabindex="2" type="text" name="field2">
<input tabindex="3" type="submit" name="submit">
</p>
</form>
</body>
</html>
Ключи доступа
accesskey = cdata
Этот атрибут присваивает ключ доступа элементу. Ключ доступа представляет собой одиночный символ в текущей кодировке агента пользователя.
Нажатие клавиши, соответствующей ключу доступа, приводит к выбору элемента.Действия, которые будут выполнены при выборе, зависят от элемента. Атрибут accesskey поддерживается элементами: label и legend. В приведенном примере клавиша “u” ставится в соответствие элементу управления input.
<form action="..." method="post">
<p>
<label for="fuser" accesskey="u">
user name
</label>
<input type="text" name="user" id="fuser">
</p>
</form>
В ниже приведенном примере ключ доступа поставлен в соответствие связи, описанной элементом А. Нажатие клавиши доступа (c) приводит к вызову другого элемента.
<p><a accesskey="c"
rel="contents"
href="http://someplace.com/specification/contents.html">
table of contents</a>
В системе MS Windows для активации ключа доступа одновременно с ним следует нажать клавишу alt.
Атрибут disabled
Когда этот булев атрибут установлен для control формы, он блокирует данный вид контроля для ввода пользователя. Атрибут disabled поддерживается элементами input, textarea, select, option, object, label и button.
Блокированный элемент не может быть выделен, он игнорируется при обходе элементов и значения блокированного элемента не передается вместе с формой. В ниже предлагаемом примере блокированный элемент input не может воспринять ввод пользователя и передать его с формой.
<input disabled name="fred" value="stone">
Изменить значение атрибута динамически можно только с помощью скрипта.
Атрибут readonly
Этот булев атрибут при установке запрещает изменение control. Элементы, предназначенные только для чтения, могут быть выбраны, но не могут быть изменены пользователем. Значения control в этом случае передается вместе с формой. Атрибут readonly поддерживается элементами input, text, password и textarea.
27. Скрипты
На стороне клиента скрипт представляет собой программу, которая может сопровождать документ HTML или быть непосредственно встроена в него. Программа исполняется на ЭВМ клиента при загрузке документа или при активации определенной связи. Скрипт предлагает разработчику заметно расширить возможности HTML-документа. В частности:
Скрипт может динамически изменять содержимое документа.
Скрипт может использоваться для обработки вводимой пользователем информации.
Скрипт может быть запущен каким-либо событием (выделение фрагмента, операции с мышкой, выгрузка документа и т.д.).
Скрипт может быть поставлен в соответствие одному из control формы и управляться им.
Существует два типа скриптов, которые могут быть подключены к документу:
Исполняемые только раз при загрузке документа агентом пользователя (это прежде всего скрипты элемента script).
Исполняемые каждый раз, когда происходит какое-то определенное событие. Такие скрипты могут быть подключены ко многим документам.
27.1. Элемент script
| <!element script - - %script; | -- текст скрипта --> |
| charset %charset; #implied | -- кодировка символов, подключенного ресурса -- |
| type %contenttype; #required | -- тип содержимого языка скрипта -- |
| src %uri; #implied | -- uri для внешнего скрипта -- |
| defer (defer) #implied | -- ua может отложить исполнение скрипта --> |
src = URI [ct]
Этот атрибут специфицирует местонахождения внешнего скрипта.
type = content-type
Этот атрибут специфицирует язык скрипта, включенного в элемент. Язык специфицируется в содержимом content-type (напр., "text/javascript"). Разработчик должен выдать значения этого атрибута, так как не существует никакого значения по умолчанию.
language = cdata
Не рекомендуется к применению. Этот атрибут специфицирует язык скрипта, включенного в элемент. Его содержимое представляет собой идентификатор языка. Но из-за отсутствия стандарта атрибут type предпочтительнее.
defer
Установка этого булева атрибута сообщает агенту пользователя о том, что скрипт не будет генерировать какого-либо текста документа, что позволяет агенту пользователя продолжить разборку и представление документа.
Элемент script размещает скрипт внутри документа. Этот элемент может встретиться в head или body HTML-документа любое число раз. Сам скрипт может находиться в содержательной части элемента script или во внешнем файле. Если атрибут src не установлен, агент пользователя должен интерпретировать содержимое элемента, как скрипт. Если же src содержит URL, то агент пользователя должен игнорировать содержимое элемента и получить скрипт через URL. Разработчик должен идентифицировать язык скрипта. Для того чтобы определить язык всех скриптов в документе, необходимо включить следующую meta-декларацию в head документа:
<meta http-equiv="content-script-type" content="type">
где “type” соответствует internet media type, именующему язык скрипта. В отсутствии META-декларации, значение по умолчанию может быть установлено с помощью HTTP-заголовка “content-script-type”
content-script-type: type
где “type” соответствует internet media type.
27.2. Локальная декларация языка скрипта
Можно описать язык скрипта в каждом элементе script независимо с помощью атрибута type. В отсутствии значения языка по умолчанию этот атрибут должен быть обязательно установлен. При наличии значения по умолчанию атрибут type переписывает это значение. Ниже приведен пример, где значение языка скриптов по умолчанию равно “text/tcl”. Один скрипт включен в заголовок, он размещен во внешнем файле и написан на языке “text/vbscript”. Включен скрипт и в тело script (написан на “text/javascript”).
<!doctype html public "-//w3c//dtd html 4.0//en"
"http://www.w3.org/tr/rec-html40/strict.dtd">z
<html>
<head>
<title>a document with script</title>
<meta http-equiv="content-script-type" content="text/tcl">
<script type="text/vbscript" src="http://someplace.com/progs/vbcalc">
</script>
</head>
<body>
<script type="text/javascript">
...some javascript...
</script>
</body>
</html>
27.3. Ссылки на html-документы из скрипта
В каждом языке имеется соглашение относительно взаимодействия с HTML-объектами. Содержимым элемента script является скрипт и по этой причине агент пользователя не должен рассматривать его как часть HTML-текста. Текст скрипта начинается сразу после начальной метки и завершается любой меткой, которая начинается с символов “</”. Ниже следующий пример не является корректным из-за наличия “</em>” символов внутри элемента script (эта комбинация указывает на окончание скрипта):
<scipt type=”text/javascript”>
</script>
Корректная версия записи выглядит как:
<scipt type=”text/javascript”>
</script>
В tcl можно это записать как:
<scipt type=”text/tcl”>
</script>
Определения атрибутов
onload = script [ct]
Событие onload происходит, когда пользователь заканчивает загрузку окна в рамках frameset. Этот атрибут может использоваться с элементами body и frameset.
onunload = script [ct]
Событие onunload происходит, когда агент пользователя удаляет документ из окна или рамки. Этот атрибут может использоваться с элементами BODY и frameset.
onclick = script [ct]
Событие onclick происходит, когда на устройстве (например, мышке), указывающем на клавишу, нажата кнопка. Этот атрибут может использоваться с большинством элементов.
ondblclick = script
Событие ondblclick происходит, когда на устройстве, указывающем на клавишу, кнопка нажата дважды. Этот атрибут может использоваться с большинством элементов.
onmousedown = script
Событие onmousedown происходит, когда на устройстве, указывающем на клавишу, кнопка находится в нажатом состоянии. Этот атрибут может использоваться с большинством элементов.
onmouseup = script
Событие onmouseup происходит, когда на устройстве, указывающем на клавишу, кнопка отпущена. Этот атрибут может использоваться с большинством элементов.
onmouseover = script
Событие onmouseover происходит, когда указатель устройства, наезжает на клавишу (элемент). Этот атрибут может использоваться с большинством элементов.
onmousemove = script
Событие onmousemove происходит, когда устройство указывающее на элемент, перемещено. Этот атрибут может использоваться с большинством элементов.
onmouseout = script
Событие onmouseout происходит, когда позиционер указателя сдвигается с поля элемента. Этот атрибут может использоваться с большинством элементов.
onfocus = script
Событие onfocus происходит, когда элемент оказывается выделен с помощью прибора-указателя или каким-либо другим способом (например, с помощью клавиш). Этот атрибут может использоваться с: label, input, select, textarea, и button.
onblur = script
Событие onblur происходит, когда элемент перестает быть выделенным с помощью прибора-указателя или каким-либо другим способом. navigation. Этот атрибут может использоваться с теми же элементами, что и onfocus.
onkeypress = script
Событие onkeypress происходит, когда клавиша нажата и отпущена на элементе. Этот атрибут может использоваться с большинством элементов.
onkeydown = script
Событие onkeydown происходит, когда клавиша нажата на элементе. Этот атрибут может использоваться с большинством элементов.
onkeyup = script
Событие onkeyup происходит, когда клавиша отпущена на элементе. Этот атрибут может использоваться с большинством элементов.
onsubmit = script
Событие onsubmit происходит, когда форма передана. Этот атрибут используется с элементом form.
onreset = script
Событие onreset происходит, когда форма сброшена. Этот атрибут используется с элементом form.
onselect = script
Событие onselect происходит, когда пользователь выбирает некоторый текст втекстовом поле. Этот атрибут может использоваться с элементами input и textarea.
onchange = script
Событие onchange происходит, когда control перестает быть выбранным и его значение модифицировано с момента выбора. Этот атрибут может использоваться с элементами input, select и textarea.
Имеется возможность установить соответствие между определенными действиями и несколькими событиями, когда пользователь взаимодействует с агентом пользователя. Управляющие элементы, такие как input, select, button, textarea и label реагируют на те или иные события. В следующем примере необходимо ввести имя пользователя в текстовое поле. Когда пользователь пытается покинуть это поле, событие onblur вызывает функцию javascript, которая проверяет корректность введенного имени.
<input name="num"
onchange="if (!checknum(this.value, 1, 10))
{this.focus();this.select();} else {thanks()}"
value="0">
Вот пример скрипта vbscript для обработки событий в текстовом поле:
<input name="edit1" size="50">
<script type="text/vbscript">
sub edit1_changed()
if edit1.value = "abc" then
button1.enabled = true
else
button1.enabled = false
end if
end sub
</script>
Ниже прведен пример с использованием tcl:
<input name="edit1" size="50">
<script type="text/tcl">
proc edit1_changed {} {
if {[edit value] == abc} {
button1 enable 1
} else {
button1 enable 0
}
}
edit1 onchange edit1_changed
</script>
Здесь приведен пример Javascript для демонстрации установки связи между скриптом и событием (в случае нажатия клавиши на мышке):
<button type="button" name="mybutton" value="10">
<script type="text/javascript">
function my_onclick() {
. . .
}
document.form.mybutton.onclick = my_onclick
</script>
</button>
Ниже представлен более интересный хандлер окна:
<script type="text/javascript">
function my_onload() {
. . .
}
var win = window.open("some/other/uri")
if (win) win.onload = my_onload
</script>
На tcl это выглядит как:
<script type="text/tcl">
proc my_onload {} {
. . .
}
set win [window open "some/other/uri"]
if {$win != ""} {
$win onload my_onload
}
</script>
Атрибуты скриптов для событий определяются как cdata. Значение атрибута должно быть заключено в одинарные или двойные кавычки. С учетом ограничений, налагаемых программой лексической разборки, случаи появления (“) и “&” в атрибуте хандлера событий должны быть записаны следующим образом:
'"' должно быть записано как """ или """
'&' должно быть записано как "&" или "&"
Поэтому ниже представленный пример должен быть записан как:
<input name="num" value="0"
onchange="if (compare(this.value, "help")) {gethelp()}">
sgml разрешает введение (‘) в строку атрибута следующим образом:
“this is ‘fine’ ” and “so is “this” ’
28. Динамическая модификация документов
Скрипты, которые исполняются в процессе загрузки документа, могут динамически модифицировать его содержимое. Эта возможность зависит от языка, используемого для написания скрипта. Динамическая модификация документов осуществляется следующим образом:
Сначала определяются все элементы script для того, чтобы загрузить документ.
Определяются все конструкции скрипта в пределах данного элемента script, которые генерируют SGML cdata. Полученный в результате текст загружается в документ в месте размещения элемента script.
Сгененированная cdata подвергается обратному преобразованию.
Следующий пример иллюстрирует то, как скрипты могут динамически модифицировать текст.
<title>test document</title>
<script type="text/javascript">
document.write("<p><b>hello world!<\/b>")
</script>
Приведенный выше текст дает тот же результат, что и html-текст:
<title>test document</title>
<p><b>hello world!</b>
28.1. Элемент noscript
<!element noscript - - (%block;)+
-- альтернативный текст для случая безскриптового отображения -->
<!attlist noscript
| %attrs; | -- %coreattrs, %i18n, %events -- > |
Агент пользователя сконфигурирован так, что он не поддерживает скрипты.
Агент пользователя не поддерживает язык скрипта, использованный в элементе script.
Агент пользователя, не поддерживающий скрипты для стороны клиента, должен осуществлять разборку и представление содержимого элемента. В следующем примере агент пользователя, который исполняет script, включит некоторую динамически созданную информацию, в текст документа. Если агент пользователя не поддерживает скрипты, пользователь может, тем не менее, получить эту информацию через сеть.
<script type="text/tcl">
...некоторый tcl-скрипт для введения данных...
</script>
<noscript>
<p>access the <a href="http://someplace.com/data">data.</a>
</noscript>
Агент пользователя, который не распознает элемент script, вероятно будет разбирать и отображать содержимое элемента, как текст. Некоторые интерпретаторы скриптов, включая те, которые ориентированы на Javascript, VBscript и TCL, позволяют помещать фрагменты текстов скриптов в SGML-комментарии. Тогда агент пользователя, не узнавший элемент script, игнорирует его текст, считая его комментарием, а продвинутый интерпретатор скриптов распознает скрипт, помещенный в комментарий, и исполнит его. Другим решением проблемы является помещение скрипта во внешний документ.
28.2. Комментирование скриптов в javascript
Интерпретатор javascript позволяет вводить строку “<!--“ в начало элемента script и игнорировать все символы, следующие за ней вплоть до конца строки. javascript интерпретирует “//” как начало комментария, который следует до конца текущей строки. Это необходимо, для того чтобы скрыть строку “-->” от интерпретатора javascript.
<script type="text/javascript">
<!-- to hide script contents from old browsers
function square(i) {
document.write("the call passed ", i ," to the function.","<br>")
return i * i
}
document.write("the function returned ",square(5),".")
// end hiding contents from old browsers -->
</script>
28.3. Комментирование скриптов в vbscript
В vbscript символ одиночной кавычки воспринимается, как начало комментария, который продолжается до конца строки. Это может быть использовано для того, чтобы спрятать “-->” от vbscript. Например:
<script type="text/vbscript">
<!--
sub foo()
...
end sub
‘ -->
</script>
28.4. Комментирование скриптов в tcl
В TCL для начала строки комментария используется символ “#” (действует до конца строки).
<script type="text/tcl">
<!-- чтобы скрыть содержимое скрипта от старых броузеров
proc square {i} {
document write "the call passed $i to the function.<br>"
return [expr $i * $i]
}
document write "the function returned [square 5]."
# end hiding contents from old browsers -->
</script>
Некоторые броузеры считают комментарий завершившимся на первом символе “>”.
29. Верификация документов
Многие разработчики при проверке своих документов полагаются на ограниченное число броузеров, предполагая, что если эти броузеры могут работать с их документами корректно, то они лишены ошибок. К сожалению, это очень неэффективный способ верификации документов, прежде всего из-за того, что многие броузеры приспособлены работать с не вполне корректными документами.
Для более тщательной проверки рекомендуется воспользоваться интерпретатором SGML, например, в случае проверки соответствия документа требованиям HTML 4.0 DTD это может быть NSGMLS. Если декларации типа в вашем документе включают URI, и ваш интерпретатор SGML поддерживает этот тип системных идентификаторов, то он получит DTD (Document Type Definition) непосредственно. В противном случае можно воспользоваться каталогом образцов SGML.
Предполагается, что DTD спасено в виде файла "strict.dtd", а объекты (entities) записаны в файлы "htmllat1.ent", "htmlsymbol.ent" и "htmlspecial.ent". В любом случае следует проверить то, что ваш интерпретатор SGML может работать с уникодами.
Следует иметь в виду, что такая проверка, хотя и полезна и настойчиво рекомендуется, не может гарантировать полного соответствия документа требованиям спецификации HTML 4.0. Это происходит потому, что интерпретатор SGML базируется на определенных SGML DTD, не выражают всех аспектов истинного документа HTML 4.0. Интерпретатор SGML гарантирует, что синтаксис, структура, список элементов и их атрибутов соответствуют рекомендациям стандарта. Но он не может, например, обнаружить ошибки при установке атрибута ширины элемента IMG. Хотя спецификация ограничивает значение атрибута "целым числом пикселей"," DTD определяет только то, что это cdata, что практически допускает любые значения. Только специализированная программа способна выловить все несоответствия с HTML 4.0.
Несмотря ни на что, этот тип верификации является рекомендуемым, так как позволяет обнаружить большинство ошибок.
29.1. Каталог образцов SGML
Этот каталог включает в себя отвергнутые директивы с тем, чтобы гарантировать, что обрабатывающее программное обеспечение, такое как NSGMLS, использует предпочтительно общедоступные идентификаторы по отношению к системным идентификаторам. Это означает, что пользователи не должны быть подключены к сети при обработке системных идентификаторов, базирующихся на URI.
override yes
public "-//w3c//dtd html 4.0//en" strict.dtd
public "-//w3c//dtd html 4.0 transitional//en" loose.dtd
public "-//w3c//dtd html 4.0 frameset//en" frameset.dtd
public "-//w3c//entities latin1//en//html" htmllat1.ent
public "-//w3c//entities special//en//html" htmlspecial.ent
public "-//w3c//entities symbols//en//html" htmlsymbol.ent
29.2. sgml декларация html 4.0
Замечание. Набор символов SGML-деклараций документа включает в себя первые 17 плоскостей [ISO10646] (17 раз по 65536). Это ограничение связано с тем, что это число в текущей версии стандарта SGML имеет только 8 цифр.
Замечание. Строго говоря, регистрационный номер ISO 177 относится к исходному состоянию ISO 10646 в 1993 году, в то время как в этой спецификации мы базируемся на последней версии ISO 10646.
29.3. SGML декларация
<!sgml "ISO 8879:1986"
-- SGML - предложениеHhypertext Markup Language версия 4.0. С поддержкой первых 17 плоскостей ISO10646 и увеличенными пределами для меток и литералов. --
charset
baseset "ISO registration number 177//charset
ISO/IEC 10646-1:1993 UCS-4 with
implementation level 3//esc 2/5 2/15 4/6"
| minimize | ||
| datatag | no | |
| omittag | yes | |
| rank | no | |
| shorttag | yes | |
| link | ||
| simple | no | |
| implicit | no | |
| explicit | no | |
| other | ||
| concur | no | |
| subdoc | no | |
| formal | yes | |
| appinfo | none |
<!-- Типовое применение:
<!doctype html public "-//w3c//dtd html 4.0//en"
FPI для переходного HTML 4.0 dtd соответствует:
"-//w3c//DTD HTML 4.0 transitional//en"
а его uri:
http://www.w3.org/tr/rec-html40/loose.dtd
Если вы пишете документ, который включает в себя рамки, используйте fpi:
"-//w3c//dtd html 4.0 frameset//en"
с uri:
http://www.w3.org/tr/rec-html40/frameset.dtd
Следующие uri поддерживаются в рамках html 4.0
"http://www.w3.org/tr/rec-html40/strict.dtd" (strict dtd)
"http://www.w3.org/tr/rec-html40/loose.dtd" (loose dtd)
"http://www.w3.org/tr/rec-html40/frameset.dtd" (frameset dtd)
"http://www.w3.org/tr/rec-html40/htmllat1.ent" (latin-1 entities)
"http://www.w3.org/tr/rec-html40/htmlsymbol.ent" (symbol entities)
"http://www.w3.org/tr/rec-html40/htmlspecial.ent" (special entities)
Эти uri указывают на последние версии каждого из файлов. Для ссылок используйте URI:
"http://www.w3.org/tr/1998/rec-html40-19980424/strict.dtd"
"http://www.w3.org/tr/1998/rec-html40-19980424/loose.dtd"
"http://www.w3.org/tr/1998/rec-html40-19980424/frameset.dtd"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmllat1.ent"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmlsymbol.ent"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmlspecial.ent"
-->
<!--================== Импортированные имена ===================== -- >
<!entity % contenttypes "cdata"
-- список кодов типов среды, разделенных запятыми, в соответствие с [rfc-2045] -->
<!entity % head.misc "script|style|meta|link|object" -- повторяющиеся элементы заголовков -->
<!entity % heading "h1|h2|h3|h4|h5|h6">
<!entity % list "ul | ol">
<!entity % preformatted "pre">
<!entity % color "cdata" -- цвет в представлении rgb: #rrggbb (hex формат) -->
<! -- Здесь представлены имена 16 широко известных цветов с их rgb значениями:
| black = | #000000 | green = | #008000 |
| silver = | #C0C0C0 | lime = | #00FF00 |
| gray = | #808080 | olive = | #808000 |
| white = | #FFFFFF | yellow = | #FFFF00 |
| maroon = | #800000 | navy = | #000080 |
| red = | #FF0000 | blue = | #0000FF |
| purple = | #800080 | teal = | #008080 |
| fuchsia = | #FF00FF | aqua = | #00FFFF |
<!--============== Символьные мнемонические объекты ==============-->
<!entity % htmllat1 public
"-//w3c//entities latin1//en//html"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmllat1.ent">
%htmllat1;
<!entity % htmlsymbol public
"-//w3c//entities symbols//en//html"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmlsymbol.ent">
%htmlsymbol;
<!entity % htmlspecial public
"-//w3c//entities special//en//html"
"http://www.w3.org/tr/1998/rec-html40-19980424/htmlspecial.ent">
%htmlspecial;
<!--===================== Общие атрибуты =======================-->
<!entity % coreattrs
"id id #implied
-- уникальный идентификатор, действительный для всего документа --
| class cdata #implied | -- список классов, разделенных пробелами -- | |
| style %stylesheet; #implied | -- ассоциированная стилевая информация -- | |
| title %text; #implied | -- рекомендуемые заголовки /приложения --" > |
| "lang %languagecode; #implied | -- код языка -- | |
| dir (ltr|rtl) #implied | -- направление для слабого/нейтрального текста --" > | |
| <!entity % events | ||
| "onclick %script; #implied | -- клавиша мышки была нажата -- | |
| ondblclick %script; #implied | -- клавиша мышки была нажата дважды -- | |
| onmousedown %script; #implied | -- клавиша мышки была нажата и удержана -- | |
| onmouseup %script; #implied | -- клавиша мышки была отпущена -- | |
| onmouseover %script; #implied | -- маркер был помещен на объект -- | |
| onmousemove %script; #implied | -- маркер перемещался в пределах объекта -- | |
| onmouseout %script; #implied | -- маркер удален с объекта -- | |
| onkeypress %script; #implied | -- клавиша была нажата и отпущена -- | |
| onkeydown %script; #implied | -- клавиша была зажата -- | |
| onkeyup %script; #implied | -- клавиша была отпущена --" > |
<!entity % html.reserved "ignore">
<!-- Следующие атрибуты зарезервированы для будущего использования -->
<![ %html.reserved; [
<!entity % reserved
| "datasrc %uri; #implied | -- a single or tabular data source -- | |
| datafld cdata #implied | -- свойство или имя колонки -- | |
| dataformatas (plaintext|html) plaintext | -- текст или html --" > |
<!entity % reserved "">
<!entity % attrs "%coreattrs; %i18n; %events;">
<!--================== Разметка текста (markup) ===================-->
<!entity % fontstyle "tt | i | b | big | small">
<!entity % phrase "em | strong | dfn | code |
samp | kbd | var | cite | abbr | acronym" >
<!entity % special
"a | img | object | br | script | map | q | sub | sup | span | bdo">
<!entity % formctrl "input | select | textarea | label | button">
<!-- %inline; охватывает строчные и "text-level" элементы -->
<!entity % inline "#pcdata | %fontstyle; | %phrase; | %special; | %formctrl;">
<!element (%fontstyle;|%phrase;) - - (%inline;)*>
<!attlist (%fontstyle;|%phrase;)
| %attrs; | -- %coreattrs, %i18n, %events -- > | |
| <!element (sub|sup) - - (%inline;)* | -- нижний или верхний индексы --> | |
| <!attlist (sub|sup) %attrs; | -- %coreattrs, %i18n, %events --> | |
| <!element span - - (%inline;)* | -- общий языковый/стилевой контейнер --> | |
| <!attlist span %attrs | -- %coreattrs, %i18n, %events -- | |
| %reserved | -- зарезервировано на будущее --> | |
| <!element bdo - - (%inline;)* | -- i18n bidi over-ride --> | |
| <!attlist bdo %coreattrs; | -- id, class, style, title -- | |
| lang %languagecode; #implied | -- код языка -- | |
| dir (ltr|rtl) #required | -- направление --> | |
| <!element br - o empty | -- принудительный разрыв строки --> | |
| <!attlist br %coreattrs; | -- id, class, style, title -- > | |
| <!element basefont - o empty | -- базовый размер шрифта --> | |
| <!attlist basefont | ||
| ID id #implied | -- идентификатор документа -- | |
| size cdata #required | -- базовый размер шрифта для элементов font -- | |
| color %color; #implied | -- цвет текста -- | |
| face cdata #implied | -- список имен шрифтов, разделенных запятыми -- > |
/p>
| <!element font - - (%inline;)* | -- локальная смена шрифта --> | |
| <!attlist font %coreattrs; | -- id, class, style, title -- | |
| %i18n; | -- lang, dir -- | |
| size cdata #implied | -- [+|-]nn e.g. size="+1", size="4" -- | |
| color %color; #implied | -- цвет текста -- | |
| face cdata #implied | -- список имен шрифтов, разделенных запятыми -- > |
<!-- HTML имеет две базовые модели содержимого:
%inline; элементы символьного уровня и текстовые строки
%block; блочные элементы, напр., параграфы и списки -->
<!entity % block
"p | %heading; | %list; | %preformatted; | dl | div | noscript |
blockquote | form | hr | table | fieldset | address">
<!entity % flow "%block; | %inline;">
<!--=================== Тело документа ========================-->
<!element body o o (%block;|script)+ +(ins|del) -- тело документа -->
| <!attlist body %attrs; | -- %coreattrs, %i18n, %events -- | |
| onload %script; #implied | -- документ был загружен -- | |
| onunload %script; #implied | -- документ был удален --> | |
| <!element address - - (%inline;)* | -- информация об авторе --> | |
| <!attlist address %attrs; | -- %coreattrs, %i18n, %events -- > | |
| <!element div - - (%flow;)* | -- общий языковый/стилевой контейнер --> | |
| <!attlist div %attrs; | -- %coreattrs, %i18n, %events -- | |
| %reserved; | -- зарезервировано на будущее --> |
<!entity % shape "(rect|circle|poly|default)">
<!-- Они могут помещаться в один и тот же документ или группироваться в отдельном документе, хотя это и не поддерживается широко -->
<!attlist map
<!--===================== Элемент link ======================-->
<!-- Значения отношений могут использоваться:
для специальных меню (toolbars), когда значения отношений используются с элементом link в заголовке документа, напр., start, contents, previous, next, index, end, help
для связи с отдельным стилевым листом (rel=stylesheet)
для организации связи со скриптом (rel=script)
с стилевыми листами для управления процессом представления документов из нескольких узлов при их печати
для создания связи с печатаемой версией документа, напр., postscript или pdf (rel=alternate media=print) -->
<!--===================== Изображения =====================-->
<!-- Длина, определенная в DTD, для cellpadding/cellspacing -->
<!-- Чтобы избежать проблем с агентами пользователя, ориентированными исключительно на работу с текстом, сделать изображение понятным и удобным для сетевого поиска для неграфических агентов пользователя, следует предусмотреть альтернативу описания с помощью alt, и избежать применения карт изображения на стороне сервера -->
| <!element img - o empty |
-- Встроенное изображение --> |
/p> <!attlist img
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| src %uri; #required | -- uri встроенного изображения -- | |
| alt %text; #required | -- краткое описание -- | |
| longdesc %uri; #implied | -- связь с длинным описанием (complements alt) -- | |
| height %length; #implied | -- присвоение нового значения высоты -- | |
| width %length; #implied | -- присвоение нового значения ширины-- | |
| usemap %uri; #implied | -- для использования с картой изображения клиента -- | |
| ismap (ismap) #implied | -- для использования с картой изображения сервера --> | |
| align %ialign; #implied | -- вертикальное или горизонтальное выравнивание-- | |
| border %length; #implied | -- ширина границы для связи -- | |
| hspace %pixels; #implied | -- горизонтальный пробельный массив-- | |
| vspace %pixels; #implied | -- вертикальный пробельный массив-- > |
<!--==================== object ===================-->
<!-- object используется для вставления объектов в качестве части html страниц. Элементы param должны предшествовать остальному содержимому. -->
<!attlist object
| <!element param - o empty | -- именованное значение свойства --> |
| id id #implied | -- идентификатор документа -- | |
| name cdata #required | -- имя свойства -- | |
| value cdata #implied | -- значение свойства -- | |
| valuetype (data|ref|object) data | -- Как интерпретировать значение -- | |
| type %contenttype; #implied | -- тип содержимого для значения, когда valuetype=ref --> |
<!-- Один из кодов или атрибутов объекта должен присутствовать. Помещайте элементы param до остального содержимого. -->
<!element applet - - (param | %flow;)* -- аплет java -->
| <!attlist applet %coreattrs; | -- id, class, style, title -- |
| codebase %uri; #implied | -- опционный базовый uri для аплета -- |
| archive cdata #implied | -- список архива с запятой в качестве разделителя-- |
| code cdata #implied | -- файл класса аплета -- |
| object cdata #implied | -- файл специального аплета -- |
| alt %text; #implied | -- краткое описание-- |
| name cdata #implied | -- позволяет аплетам найти друг друга -- |
| width %length; #required | -- начальная ширина -- |
| height %length; #required | -- начальная высота -- |
| align %ialign; #implied | -- вертикальное или горизонтальное выравнивание -- |
| hspace %pixels; #implied | -- горизонтальный пробельный массив-- |
| vspace %pixels; #implied | -- вертикальный пробельный массив-- > |
/p> <!--================ Горизонтальная линейка ==================-->
| <!element hr - o empty | -- горизонтальная линейка --> | |
| <!attlist hr %coreattrs; | -- id, class, style, title -- | |
| %events; > |
| <!element p - o (%inline;)* | -- параграф --> |
| <!attlist p %attrs; | -- %coreattrs, %i18n, %events -- > |
| %align; | -- выравнивание текста -- > |
<!--Существует 6 уровней заголовков от H1 (наиболее важный) до H6 (наименее важный). -->
| <!element (%heading;) - - (%inline;)* | -- Заголовок --> |
| <!attlist (%heading;) %attrs; | -- %coreattrs, %i18n, %events -- > |
| %align; | -- выравнивание текста -- > |
<!-- не включает разметку для изображений и изменений в размере шрифтов -->
<!entity % pre.exclusion "img|object|big|small|sub|sup">
<!element pre - - (%inline;)* -(%pre.exclusion;) -- преформатированный текст -->
<!attlist pre %attrs; -- %coreattrs, %i18n, %events -- >
<!--===================== inline quotes ====================-->
| <!element q - - (%inline;)* | -- Кавычки для текста в пределах строки --> | |
| <!attlist q %attrs; | -- %coreattrs, %i18n, %events -- | |
| cite %uri; #implied | -- uri для исходного документа или сообщения -- > |
<!element blockquote - - (%block;|script)+ -- Кавычки для многострочных блоков текста -->
<!attlist blockquote
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| cite %uri; #implied | -- uri для исходного документа или сообщения --> |
<!-- ins/del are handled by inclusion on body -->
<!--====================== Списки ========================-->
<!-- список определений - dt - для термов, dd - для их определений -->
<!-- Стиль нумерации упорядоченных списков (ol)
1 арабские числа 1, 2, 3, ...
a строчные буквы a, b, c, ...
a прописные буквы a, b, c, ...
i строчные римские i, ii, iii, ...
i прописные римские i, ii, iii, ...
Стиль применяется к номеру по порядку, который по умолчанию равен 1 для первого элемента упорядоченного списка. -->
<!entity % olstyle "cdata" -- ограничено перечнем: "(1|a|a|i|i)" -->
<!element ol - - (li)+ -- упорядоченный список -->
<!attlist ol
<!-- Неупорядоченные списки (ul) bullet styles -->
| <!element ul - - (li)+ | -- неупорядоченный список --> |
| <!attlist ul %attrs; | -- %coreattrs, %i18n, %events -- > |
| <!element li - o (%flow;)* | -- элемент списка --> |
| <!attlist li %attrs; | -- %coreattrs, %i18n, %events -- > |
| type %ulstyle; #implied | -- стиль bullet -- | |
| compact (compact) #implied | -- уменьшенный зазор между позициями-- > |
/p> <!--==================== Формы =======================-->
| ><!element form - - (%block;|script)+ -(form) |
-- интерактивная форма --> |
| <!attlist form %attrs; | -- %coreattrs, %i18n, %events -- | |
| action %uri; #required | -- хандлер форм для стороны сервера -- | |
| method (get|post) get | -- http метод для представления форм -- | |
| enctype %contenttype; "application/x-www-form-urlencoded" | ||
| onsubmit %script; #implied | -- форма была представлена -- | |
| onreset %script; #implied | -- форма возвращена в исходное состояние -- | |
| target %frametarget; #implied | -- отображать в этой рамке -- | |
| accept-charset %charsets; #implied | -- список поддерживаемых символьных наборов -- > |
<!element label - - (%inline;)* -(label) -- текст метки поля формы -->
| <!attlist label %attrs; | -- %coreattrs, %i18n, %events -- | |
| or idref #implied | -- проверяет корректность значения поля -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- > |
"(text | password | checkbox | radio | submit | reset | file | hidden | image | button)" >
<!-- имя атрибута необходимо всем кроме submit & reset -->
| <!element select - - (optgroup|option)+ | -- селектор опций --> | |
| <!attlist select %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | -- имя поля -- | |
| size number #implied | -- видимые строки -- | |
| multiple (multiple) #implied | -- по умолчанию один выбор -- | |
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| tabindex number #implied | -- номер позиции в меню -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onchange %script; #implied | -- значение элемента изменилось -- | |
| %reserved; | -- зарезервировано на будущее -- > |
| <!element optgroup - - (option)+ | -- группа опций --> | |
| <!attlist optgroup %attrs; | -- %coreattrs, %i18n, %events -- | |
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| label %text; #required | -- для использования в иерархических меню --> |
| <!element option - o (#pcdata) | -- селективный выбор --> | |
| <!attlist option %attrs; | -- %coreattrs, %i18n, %events -- | |
| selected (selected) #implied | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| label %text; #implied | -- для использования в иерархических меню -- | |
| value cdata #implied | -- значения по умолчанию содержимого элемента --> |
/p>
| <!element textarea - - (#pcdata) | -- многострочное текстовое поле --> |
| <!attlist textarea %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| rows number #required | ||
| cols number #required | ||
| disabled (disabled) #implied | -- недоступно в данном контексте -- | |
| readonly (readonly) #implied | ||
| tabindex number #implied | -- номер позиции в меню -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| onselect %script; #implied | -- некоторая часть текста выделена -- | |
| onchange %script; #implied | -- значение элемента изменилось -- | |
| %reserved; | -- зарезервировано на будущее --> |
| <!element fieldset - - (#pcdata,legend,(%flow;)*) | -- группа управлений формой --> | |
| <!attlist fieldset %attrs; | -- %coreattrs, %i18n, %events -- > | |
| <!element legend - - (%inline;)* | -- легенда поля --> | |
| <!entity % lalign "(top|bottom|left|right)"> | -- выравнивание --> | |
| <!attlist legend %attrs; | -- %coreattrs, %i18n, %events -- | |
| accesskey %character; #implied | -- клавиша доступа -- > |
-- кнопка нажатия -->
| <!attlist button %attrs; | -- %coreattrs, %i18n, %events -- | |
| name cdata #implied | ||
| value cdata #implied | -- посылается серверу при представлении -- | |
| type (button|submit|reset) submit | -- для использования в качестве кнопки в форме -- | |
| disabled (disabled) #implied | -- не доступно в данном контексте -- | |
| tabindex number #implied | -- номер позиции в меню -- | |
| accesskey %character; #implied | -- клавиша доступа -- | |
| onfocus %script; #implied | -- элемент выделен -- | |
| onblur %script; #implied | -- элемент не выделен -- | |
| %reserved; | -- зарезервировано на будущее -- > |
<!--===================== Таблицы ======================-->
<!-- Стандарт таблиц ietf HTML, см. [rfc-1942] -->
<!-- Атрибут border устанавливает толщину рамки вокруг таблицы. Единицы измерения по умолчанию пиксели. Атрибут frame специфицирует то, какую часть рамки вокруг таблицы следует отображать. Значение "border" включено для обеспечения обратной совместимости с <table border>, который выдает frame=border и border=implied. Для <table border=1> вы получите border=1 и frame=implied. В этом случае, представляется разумным считать, что frame=border для обратной совместимости с уже существующими броузерами. -->
<!entity % tframe "(void|above|below|hsides|lhs|rhs|vsides|box|border)">
<!-- Атрибут rules определяет, какие линии должны быть проведены между ячейками:
Если rules отсутствуют, то предполагается:
"none", если border отсутствует или =0, в противном случае "all" -->
<!entity % trules "(none | groups | rows | cols | all)">
<!-- горизонтальное размещение таблицы в документе -->
<!entity % talign "(left|center|right)">
<!-- Атрибуты горизонтального выравнивания для содержимого ячеек -->
<!entity % cellhalign "align (left|center|right|justify|char) #implied
| char %character; #implied | -- символ выравнивания, напр. символ=':' -- | |
| charoff %length; #implied | -- смещение символа выравнивания --" > |
<!entity % cellvalign "valign (top|middle|bottom|baseline) #implied" >
<!element table - -
(caption?, (col*|colgroup*), thead?, tfoot?, tbody+)>
| <!element caption - - (%inline;)* | -- Название таблицы --> |
| <!element thead - o (tr)+ | -- Заголовок таблицы --> |
| <!element tfoot - o (tr)+ | -- Подпись под таблицей --> |
| <!element tbody o o (tr)+ | -- Тело таблицы --> |
| <!element colgroup - o (col)* | -- Группа колонок таблицы --> |
| <!element col - o empty | -- Колонка таблицы --> |
| <!element tr - o (th|td)+ | -- Строка таблицы --> |
| <!element (th|td) - o (%flow;)* | -- Заголовок ячейки, данные ячейки таблицы --> |
/p>
| <!attlist table | -- Элемент таблицы -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| summary %text; #implied | -- цель/структура для речевого вывода -- | |
| width %length; #implied | -- ширина таблицы -- | |
| border %pixels; #implied | -- управляет шириной рамки вокруг таблицы -- | |
| frame %tframe; #implied | -- какую часть таблицы отображать-- | |
| rules %trules; #implied | -- линии между строками и колонками -- | |
| cellspacing %length; #implied | -- зазор между ячейками -- | |
| cellpadding %length; #implied | -- зазор внутри ячеек -- | |
| align %talign; #implied | -- положение таблицы по отношению к окну -- | |
| bgcolor %color; #implied | -- фоновый цвет ячеек таблицы -- | |
| %reserved; | -- зарезервировано на будущее -- | |
| datapagesize cdata #implied | -- зарезервировано на будущее -- > |
| <!attlist caption %attrs; | -- %coreattrs, %i18n, %events -- > |
| <!attlist colgroup %attrs; | -- %coreattrs, %i18n, %events -- | |
| span number 1 | -- число колонок в группе по умолчанию -- | |
| width %multilength; #implied | -- значение ширины по умолчанию для вложенных col -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > |
Атрибут width специфицирует ширину колонок, напр.
| width=64 | ширина в пикселях |
| width=0.5* | относительная ширина 0.5 |
| <!attlist col | -- группы колонок и свойства -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| span number 1 | -- атрибуты col воздействуют на n колонок -- | |
| width %multilength; #implied | -- спецификация ширины колонки -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > |
<!-- Используйте thead для дублирования заголовков при продолжении таблицы на нескольких страницах, или для статического заголовка для секций tbody со скролированием.
Используйте tfoot для дублирования подписи под таблицей при продолжении таблицы на нескольких страницах, или для статического заголовка для секций tbody со скролированием.
Используйте секции tbody, когда необходимы разделительные линии между группами строк в таблице. -->
| <!attlist (thead|tbody|tfoot) | -- секция таблицы -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках-- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > |
| <!attlist tr | -- строка таблицы -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > | |
| bgcolor %color; #implied | -- цвет фона для строки -- > |
<!entity % scope "(row|col|rowgroup|colgroup)">
<!-- th для заголовков, td для данных a, но для ячеек используется td -->
| <!attlist (th|td) | -- заголовок или данные ячейки -- | |
| %attrs; | -- %coreattrs, %i18n, %events -- | |
| abbr %text; #implied | -- сокращение для ячейки заголовка -- | |
| axis cdata #implied | -- имена групп связанных заголовков -- | |
| headers idrefs #implied | -- список id для ячеек заголовка | |
| scope %scope; #implied | -- область, перекрываемая ячеками заголовка -- | |
| rowspan number 1 | -- число строк в ячейке -- | |
| colspan number 1 | -- число колонок в ячейке -- | |
| %CEllhalign; | -- горизонтальное выравнивание в ячейках -- | |
| %CEllvalign; | -- вертикальное выравнивание в ячейках -- > | |
| nowrap (nowrap) #implied | -- подавление разрыва слов -- | |
| bgcolor %color; #implied | -- цвет фона ячейки -- | |
| width %pixels; #implied | -- ширина ячейки -- | |
| height %pixels; #implied | -- высота ячейки -- > |
/p> <!--=================== Рамки документа ====================-->
<!-- Модель содержимого для HTML- документа зависит от того, следует ли за head элемент frameset или body. Широко распространенное отсутствие начальной метки body делает непрактичным определение модели содержимого без использования помеченной секции. -->
<!-- Переключатель функций для набора рамок документов -->
<!entity % html.frameset "ignore">
<![ %html.frameset; [
<!element frameset - - ((frameset|frame)+ & noframes?) – разделение окна -->
| <!attlist frameset %coreattrs; | -- id, class, style, title -- |
| rows %multilengths; #implied | -- список длин, по умолчанию 100% (1 строка) -- |
| cols %multilengths; #implied | -- список длин, по умолчанию 100% (1 колонка) -- |
| onload %script; #implied | -- все рамки были загружены -- |
| onunload %script; #implied | -- все рамки удалены -- > |
<![ %html.frameset; [
<!-- резервные имена рамок начинаются с "_" в противном случае с буквы -->
<!element frame - o empty -- субокно -->
<!attlist frame
| %coreattrs; | -- id, class, style, title -- |
| longdesc %uri; #implied | -- указатель на длинное описание (complements title) -- |
| name cdata #implied | -- имя рамки для обращений -- |
| src %uri; #implied | -- источник содержимого рамки -- |
| frameborder (1|0) 1 | -- запрос границ рамки? -- |
| marginwidth %pixels; #implied | -- ширины полей в пикселях -- |
| marginheight %pixels; #implied | -- высота поля в пикселях -- |
| noresize (noresize) #implied | -- разрешить пользователям изменить размер рамок? -- |
| scrolling (yes|no|auto) auto | -- есть или нет полоса прокрутки -- > |
<!element iframe - - (%flow;)* -- inline subwindow -->
<!attlist iframe %coreattrs; -- id, class, style, title --
| longdesc %uri; #implied | -- указатель на длинное описание -- |
| name cdata #implied | -- имя рамки для обращений -- |
| src %uri; #implied | -- источник содержимого рамки -- |
| frameborder (1|0) 1 | -- запрос границ рамки? -- |
| marginwidth %pixels; #implied | -- ширины полей в пикселях -- |
| marginheight %pixels; #implied | -- высота поля в пикселях -- |
| scrolling (yes|no|auto) auto | -- есть или нет полоса прокрутки -- |
| align %ialign; #implied | -- вертикальное или горизонтальное выравнивание-- |
| height %length; #implied | -- высота рамки -- |
| width %length; #implied | -- ширина рамки -- > |
/p> <![ %html.frameset; [
<!entity % noframes.content "(body) -(noframes)">
]]>
<!entity % noframes.content "(%flow;)*">
<!element noframes - - %noframes.content;
< -- контейнер альтернативного сообщения для отображения без поддержки рамок -->
<!attlist noframes %attrs; -- %coreattrs, %i18n, %events -- >
<!--================== Заголовок документа ==================-->
<!-- %head.misc; определены ранее как "script|style|meta|link|object" -->
<!entity % head.content "title & base?">
<!element head o o (%head.content;) +(%head.misc;) -- Заголовок документа -->
| <!attlist head %i18n; | lang, dir | |
| profile %uri; #implied | -- именованный словарь мета инфо -- > |
<!element title - - (#pcdata) -(%head.misc;) -- заголовок документа -->
<!attlist title %i18n>
<!element isindex - o empty -- однострочное сообщение – подсказка -->
<!attlist isindex
| %coreattrs; | -- id, class, style, title -- |
| %i18n; | -- lang, dir -- |
| prompt %text; #implied | -- сообщение-подсказка --> |
<!attlist base href %uri; #required -- uri, выполняющий функцию базового идентификатора -- >
| target %frametarget; #implied | -- отображать в этой рамке -- > |
| <!element meta - o empty | -- общая метаинформация --> |
| <!attlist meta %i18n; | -- lang, dir, для использования с содержимым -- |
| http-equiv name #implied | -- имя заголовка http отклика -- |
| name name #implied | -- имя метаинформации -- |
| content cdata #required | -- ассоциированная информация -- |
| scheme cdata #implied | -- выбранная форма содержимого -- > |
| <!element style - - %stylesheet | -- стилевое инфо --> | |
| <!attlist style %i18n; | -- lang, dir, для использования в заголовке -- | |
| type %contenttype; #required | -- тип содержимого стилевого языка -- | |
| media %mediadesc; #implied | -- предназначено для работы с этими средами -- | |
| title %text; #implied | -- рекомендуемый title -- > |
/p> <!element script - - %script; -- декларации скрипта -->
<!attlist script charset %charset; #implied -- символьное кодирование подключенного ресурса --
| type %contenttype; #required | -- тип содержимого языка скрипта -- |
| language cdata #implied | -- предопределенное имя языка скрипта -- |
| src %uri; #implied | -- uri внешнего скрипта -- |
| defer (defer) #implied | -- ua может отложить исполнение скрипта -- |
| event cdata #implied | -- зарезервировано на будущее -- |
| for %uri; #implied | -- зарезервировано на будущее -- > |
<!attlist noscript %attrs; -- %coreattrs, %i18n, %events -- >
<!--================== Структура документа ===================-->
<!entity % version "version cdata #fixed '%html.version;`">
<!entity % html.content "head, body">
<!element html o o (%html.content;) -- корневой элемент документа -->
<!attlist html %i18n; -- lang, dir -- >
30. Определение типа документа frameset
<!-- Это HTML 4.0 frameset DTD, который должен использоваться для документов с рамками. Этот DTD идентичен переходному DTD HTML 4.0 за исключением модели содержимого "html" элемента: в документах с рамками, элемент "frameset" замещает элемент "body".
Дополнительная информация о HTML 4.0 доступна по адресу:
www.w3.org/tr/rec-html40. -->
<!entity % html.version "-//w3c//dtd HTML 4.0 frameset//en" -- Типовое использование:
<!doctype html public "-//w3c//dtd html 4.0 frameset//en"
"http://www.w3.org/tr/rec-html40/frameset.dtd">
<html>
<head>
...
</head>
<frameset>
...
</frameset>
</html>
-->
<!entity % html.frameset "include">
<!entity % html4.dtd public "-//w3c//dtd html 4.0 transitional//en">
%html4.dtd;
31. Эталонные символьные объекты в HTML 4.0
31.1. Введение
Эталонные символьные объекты представляют собой SGML конструкцию, которая соответствует набору символов документа. Эта версия HTML поддерживает несколько наборов эталонных последовательностей символов:
Символы ISO 8859-1 (Latin-1). В соответствии с секцией 14 RFC-1866, набор Latin-1 был расширен с тем, чтобы покрыть всю правую часть ISO-8859-1 (все позиции кодов с 1 в старшем бите), включая широко используемые , © и ®. Имена символьных объектов взяты из приложений SGML (определено в ISO8879).
Символы, математические символы и греческие буквы. Эти символы могут быть представлены глифами в шрифте adobe "symbol".
Символы разметки (markup) и символы интернационализации (напр., для двунаправленного текста).
Следующие разделы представляют собой полные списки эталонных символьных объектов. Хотя по соглашению ISO10646 комментарии пишутся большими буквами, мы для целей лучшей читаемости преобразовали их в строчные.
31.2. Эталонные символьные объекты для символов ISO 8859-1
Эталонные символьные объекты в этой секции формируют символы, чьи цифровые эквиваленты должны поддерживаться агентами пользователя HTML 2.0. Таким образом, эталонный символьный объект ÷ более удобная форма, чем ÷ для получения знака деления (/).
Чтобы поддержать эти именованные объекты агенты пользователя должны только распознать имя объекта и преобразовать его в символ из таблицы ISO88591.
Символ 65533 (FFFD в шестнадцатеричной нотации) является последним допустимым символом в UCS-2. 65534 (fffe в шестнадцатеричной нотации) не имеет какого-либо соответствия и зарезервирован для "неразрывного пробела нулевой ширины" для целей детектирования порядка байт. 65535 (FFFF в шестнадцатеричной нотации) вообще не имеет смысла.
32. Приложение А
Отличия html 3.2 и html 4.0
Изменения в элементах
Новые элементы
Новыми элементами в HTML 4.0 являются: abbr, acronym, bdo, button, col, colgroup, del, fieldset, frame, frameset, iframe, ins, label, legend, noframes, noscript, object, optgroup, param, s (не рекомендуемый), span, tbody, tfoot, thead и q.
Не рекомендуемые элементы
Следующие элементы являются не рекомендуемыми: applet, basefont, center, dir, font, isindex, menu, strike и u.
Устаревшие элементы
Следующие элементы являются устаревшими: listing, plaintext, и xmp. Вместо них разработчикам следует использовать элемент pre.
Изменения в атрибутах
Почти все атрибуты, которые специфицируют представление HTML-документа (напр., colors, alignment, fonts, graphics, и т.д.) объявлены не рекомендуемыми, предпочтение отдается стилевым листам.
Атрибуты id и class позволяют разработчику присвоить имя и класс информации элементам для стилевых листов, для скриптов, для деклараций объектов и т.д..
Изменения в доступе
В HTML 4.0 введено много изменений для обеспечения доступа, включая:
Атрибут title может быть теперь установлен почти для любого элемента.
Разработчик может выдавать длинные описания таблиц, изображений и рамок.
Изменения для мета данных
Разработчики могут теперь специфицировать профайлы, которые выдают объяснения по поводу мета данных, заданных элементами meta или link.
Изменения для текста
Новые возможности интернационализации позволяют разработчикам специфицировать язык документа и направление текста.
Элементы ins и del позволяют разработчикам помечать изменения, внесенные в документ.
Элементы ABBR и acronym позволяют разработчикам помечать сокращения и акронимы в своих документах.
Изменения для связей
Атрибут ID делает любой элемент якорем назначения связи.
Изменения для таблиц
Модель таблиц HTML 4.0 выросла из более ранней концепции HTML+ и первоначального проекта HTML 3.0. Предыдущая модель была расширена в ответ на следующие запросы от информационных провайдеров:
Разработчики могут специфицировать таблицы, которые отображаются агентом пользователя по мере получения данных.
Разработчики могут специфицировать таблицы, которые доступны пользователям с не визуальными агентами пользователя.
Разработчики могут специфицировать таблицы, с фиксированными заголовками и подписями. Агенты пользователя могут использовать преимущества этого решения при скролировании больших таблиц или при отображении таблиц в многостраничном формате.
Модель таблиц HTML 4. 0 удовлетворяет требованиям опционного выравнивания по колонкам, предоставляется больше гибкости при спецификации рамок и разделительных линий в таблицах. Ожидается, однако, что стилевые листы в самом ближайшем будущем возьмут на себя функции формирования и таблиц.
Кроме того главной целью является обеспечение обратной совместимости с широко распространенными приложениями таблиц Netscape. Другой целью было упрощение импорта таблиц совместимых с моделью SGML cals. Последний проект делает атрибут выравнивания совместимым с последней версией наиболее популярных броузеров.
Для формирования групп колонок с различной шириной и свойствами выравнивания введен новый элемент colgroup, который может работать с одним или более элементов col.
Стилевой атрибут включен как средство расширения свойств, связанных с краями внутренней области групп ячеек. Например, стиль линии: точечная, двойная, тонкая/толстая и т.д.; цвет заполнения внутренней области; поля ячейки и шрифты.
Атрибуты рамки и разделительных линий модифицированы для исключения конфликтов имен с sgml, а также для блокировки влияния совпадения имен атрибутов align и valign. Эти изменения стимулировались желанием исключить в будущем проблемы, если спецификация будет расширена и разрешит применение атрибутов рамок и разделительных линий другими элементами таблицы.
Изменения для изображений, объектов и карт изображений
Элемент object позволяет включать объекты.
Элементы iframe и object позволяют разработчикам создавать встраиваемые документы.
Атрибут alt необходим для элементов img и area.
Механизм создания карт изображения позволяет разработчикам создавать более доступные карты. Модель содержимого элемента map по этой причине была изменена.
Изменения для форм
Данная спецификация вводит несколько новых атрибутов и элементов, для работы с формами:
Атрибут ключа доступа позволяет разработчику специфицировать прямой доступ к управлению формой через клавиатуру.
Атрибут disabled позволяет разработчику сделать управление формой заблокированным.
Атрибут readonly позволяет разработчику запретить какие-либо изменения в управлении формой.
Элемент label устанавливает связь между меткой и конкретным видом управления формой.
Элемент fieldset группирует связанные по смыслу поля в соответствии элементом legend. Оба эти новые элемента позволяют лучше организовать процесс отображения и улучшить интерактивность. Броузеры, ориентированные на воспроизведение речи при описании формы могут учитывать, вводимые этими элементами метки (ярлыки).
Новый набор атрибутов в сочетании со скриптами позволяют разработчику форм верифицировать данные, вводимые пользователем.
Элементы button и input с типом "button" могут использоваться в комбинации со скриптами для существенного обогащения возможностей форм.
Элемент optgroup позволяет разработчику группировать опции в меню select, который весьма важен для обеспечения доступа к форме. Дополнительные изменения для интернационализации.
Изменения для стилевых листов
HTML 4.0 поддерживает больший набор описателей среды, так что разработчики могут писать стилевые листы, ориентированные на определенные внешние устройства.
Изменения для рамок
HTML 4.0 поддерживает документы со встроенными рамками.
Изменения для скриптов
Многие элементы имеют атрибуты событий, которые сопряжены со скриптами, исполняемыми при наступлении такого события (напр., при загрузке документа, при нажатии клавиши мышки и т.д.).
Изменения для интернационализации
HTML 4.0 интегрирует рекомендации RFC-2070 для интернационализации HTML.
Однако, эта спецификация и RFC-2070 отличаются в следующих пунктах:
Атрибут accept-charset был специфицирован скорее для элемента form, чем для textarea и input.
Спецификация HTML 4.0 дает дополнительные разъяснения для двунаправленных алгоритмов укладки текста.
Использование cdata для определения элементов script и style не сохраняет возможности перекодировки документа, как это описано в RFC-2070.
33. Приложение b
Рабочие характеристики, приложения и заметки для разработчиков.
Следующие замечания являются информативными, а не нормативными.
33.1. Замечания по поводу некорректных документов
Эта спецификация не определяет, как агент пользователя должен обрабатывать случаи ошибок, включая то, как агент пользователя должен себя вести, встретив элемент, атрибут, значение атрибута или объект, не специфицированный в данном документе.
Однако, для облегчения экспериментов и взаимосогласованности между различными приложениями разных версий HTML, рекомендуется следующее:
Если агент пользователя встретил незнакомый элемент, он должен попытаться отобразить (render) его содержимое.
Если агент пользователя встретил незнакомый атрибут, он должен его игнорировать всю спецификацию этого атрибута (напр., атрибут и его значение).
Если агент пользователя встретил незнакомое значение атрибута, он должен использовать значение атрибута по умолчанию.
Если он встретил не декларированный объект, объект должен восприниматься как символьная информация.
Рекомендуется также, чтобы агенты пользователя обеспечивали информирование пользователя о перечисленных выше случаях.
Так как агенты пользователя могут реагировать на ошибки по-разному разработчики и пользователи не должны предполагать какое-то определенное поведение системы при столкновении с ошибкой.
Спецификация HTML 2.0 (RFC-1866) предполагает, что многие агенты пользователя HTML 2.0 считают, что документы, не начинающиеся с декларации типа, являются документами HTML 2.0. Как показывает практика, это плохое предположение, данная спецификация не рекомендует такое поведение агентов пользователя.
Для целей совместимости разработчики не должны "расширять" HTML за пределы доступных механизмов SGML (напр., расширяя DTD, добавляя новые наборы объектов, и т.д.).
34. Специальные символы в значениях атрибута uri
34.1. Не-ASCII символы в значениях атрибута URL
Хотя URI не содержат не-ASCII значений, разработчики иногда специфицируют их в атрибутах, где должен лежать URI (напр., определенные с помощью %uri в DTD). Например, следующее значение Href нелегально:
<a href="http://foo.org/hakon">...</a>
Рекомендуется, чтобы агент пользователя воспринял следующее соглашение для обработки не-ASCII символов в следующих случаях:
Представлять каждый символ в UTF-8 (см. RFC-2044) как один или более байт.
Обходить эти байты с помощью механизма URI (напр., путем конверсии каждого байта в %HH, где HH представляет собой шестнадцатеричное представление значения байта).
Эта процедура выдает в результате синтаксически корректный uri (как это определено в RFC-1738, секция 2.2 или RFC-2141, секция 2), это не зависит от метода кодировки символов.
Замечание. Некоторые старые агенты пользователя обрабатывают URI в HTML тривиально, используя байты символов в том виде, в котором они записаны в документе. Некоторые старые HTML-документы полагаются на эту практику и прерывают свою работы при перекодировке (transcode). Агенты пользователя, которые хотят работать с этими старыми документами должны при получении URI, содержащего нестандартные символы, сначала использовать преобразование, базирующееся на UTF-8. Только если полученное в результате URI не удается распознать, они должны попробовать сформировать URI, базируясь на байтах символов в кодировке полученного документа.
Замечание. То же самое преобразование, базирующееся на UTF-8 должно быть применено к значениям атрибутов имен для элемента A.
34.2. Символ & в значениях атрибута URI
URI, который создан при выдаче формы, может быть использован в качестве связи типа якорь (напр., атрибут Href для элемента A). К сожалению использование символа "&" для разделения полей формы противоречит его применению в значениях атрибутов SGML для выделения символьных объектов. Например, для того чтобы использовать URI "http://host/?x=1&y=2" в качестве связующего URI, его следует записать в виде <a Href="http://host/?x=1&y=2"> или <a Href="http://host/?x=1&y=2">.
Рекомендуется, чтобы пользователи сервера http, и в частности, пользователи CGI поддерживали применение ";" вместо "&" с целью избавления разработчиков от обхода символов "&".
35. Замечания об использовании sgml
Разрывы строк
SGML специфицирует то, что разрыв строки сразу после начальной метки должен игнорироваться, также как и разрыв строки непосредственно перед конечной меткой. Это приложимо ко всем HTML-элементам без исключения. Следующие два HTML-примера должны отображаться идентично:
<p> Томас смотрит телевизор.</p>
<p>
Томас смотрит телевизор.
</p>
Аналогично идентичными должны быть и следующие два примера:
<a>my favorite website</a>
<a>
my favorite website
</a>
36. Спецификация не HTML-данных
Текст скрипта и стилевые данные могут появиться в содержимом элемента или в качестве значения атрибута.
Замечание. DTD определяет данные скриптов и стилей как Cdata для содержимого элементов и значения атрибутов. Правила SGML не позволяют использование символьных объектов в Cdata элементах, но допускают их в Cdata значений атрибутов. Разработчикам следует обращать особое внимание на случаи обмена данными скриптов и стилей методом вырезания и вставления между элементами и значениями атрибутов.
Эта асимметрия означает также, что при кросскодировании (transcoding) из богатого кодового набора символов в более бедный, кодировщик не может просто заменить неконвертируемые символы в скрипте или стилевых данных соответствующим цифровыми кодами. Он должен произвести разборку (анализ) HTML-документа и узнать все о каждом скрипте и стилевом языке для того, чтобы правильно обработать соответствующие данные.
Содержимое элемента
Когда скрипт или стилевые данные являются содержимым элемента (script и style), данные начинаются немедленно после начальной метки элемента и кончаются на первом etago ("</") разграничителе, за которым следует имя символа ([a-za-z]), это может быть и не конечной меткой элемента. Разработчики должны избегать использования строк "</" в теле элемента.
Нелегальный пример:
Следующий текст скрипта содержит недопустимую последовательность "</" (в качестве части "</em>") перед конечной меткой script:
<script type="text/javascript">
document.write ("<em>this won't work</em>")
</script>
В javascript, этот код может быть представлен корректно, путем сокрытия разграничителя Etago перед начальным символом имени SGML:
<script type="text/javascript">
document.write ("<em>this will work<\/em>")
</script>
В tcl, можно выполнить это следующим образом:
<script type="text/tcl">
document write "<em>this will work<\/em>"
</script>
В vbscript эта проблема может быть обойдена с помощью функции chr():
"<em>this will work<" & chr(47) & "em>"
Значения атрибутов
Когда скриптовые или стилевые данные представляют собой значение атрибута, разработчики должны избегать случаев использования одиночных или двойных кавычек в значениях атрибута в соответствии с рекомендациями языка скрипта или описания стиля. Разработчики должны также избегать включения "&", если "&" не означает начало символьного объекта.
* '"' should be written as """ or """
* '&' should be written as "&" or "&"
Таким образом, например, можно написать:
<input name="num" value="0"
onchange="if (compare(this.value, "help")) {gethelp()}">
37. Особенности sgml с ограниченной поддержкой
Системы SGML, соответствующие ISO-8879, должны поддерживать определенное число возможностей, которые не слишком широко поддерживаются агентами пользователя HTML. Разработчикам рекомендуется не использовать все эти возможности.
38. Булевы атрибуты
Разработчики должны учитывать, что многие агенты пользователя распознают не все булевы атрибуты. Например, разработчик может захотеть специфицировать:
<option selected>
вместо
<option selected="selected">
39. Помеченные секции
Помеченные секции играют роль, схожую с конструкцией #ifdef препроцессоров языка c.
<![include[
<!-- это будет включено -->
]]>
<![ignore[
<!-- это будет проигнорировано -->
]]>
SGML определяет также использование помеченных секций для содержимого Cdata, в пределах которого "<" не рассматривается как начало метки, напр.,
<![cdata[
<an> example of <sgml> markup that is
not <painful> to write with < and such.
]]>
Указание на то, что агент пользователя не распознал помеченную секцию, является появление символьной последовательности "]]>", которая будет отображена, когда агент пользователя ошибочно использует первый символ ">" в качестве конечной метки, начинающейся с "<![".
Инструкции обработки
Инструкции обработки представляют собой механизм выявления платформо зависимых идиом. Команды обработки начинаются с последовательности символов <? и завершаются >.
<?instruction >
Например:
<?>
<?style tt = font courier>
<?page break>
<?experiment> ... <?/experiment>
Разработчики должны учитывать то, что многие агенты пользователя отображают (render) инструкции обработки как часть текста документа.
Сжатая форма разметки документа (markup)
Некоторые конструкции SGML shorttag сокращают объем данных, вводимых с клавиатуры. Хотя эти конструкции технически не вводят неопределенности, они уменьшают ясность документов, особенно когда язык усовершенствуется и добавляются новые элементы. Документы, которые используют их, являются SGML документами, но могут не работать со многими существующими средствами HTML.
Конструкции shorttag, о которых идет речь, выглядят следующим образом:
* net tags:
<name/.../
* closed start tag:
<name1<name2>
* empty start tag:
<>
* empty end tag:
</>
40. Заметки по индексному поиску
40.1. Определение языка документа
В глобальном контексте WWW важно знать, какой язык использован при написании документа. Если вы подготовили перевод документа на другие языки, вам следует воспользоваться для ссылки на них элементом Link. Это позволяет индексной поисковой системе предложить пользователям результат на языке, который они предпочитают, вне зависимости от того, как составлен запрос. Например, следующие связи предлагают французскую и немецкую альтернативу поисковой системы.
<link rel="alternate"
type="text/html"
href="mydoc-fr.html" hreflang="fr"
lang="fr" title="la vie souterraine">
<link rel="alternate"
type="text/html"
href="mydoc-de.html" hreflang="de"
lang="de" title="das leben im untergrund">
Обеспечение ключевыми словами и описаниями
Некоторые системы индексации ищут META-элементы, которые определяют список ключевых слов или фраз, разделенных запятыми, или которые дают краткие описания. Поисковая система может представить эти ключевые слова в качестве результата поиска. Значение атрибута имени, которое ищется атрибутом поиска, не определено спецификацией. Рассмотрим такие примеры,
<meta name="keywords" content="vacation, greece, sunshine">
<meta name="description" content="idyllic european vacations">
Выделение начала коллекции
Собрание документов, где ищутся слова, часто преобразуется в собрание HTML-документов. Для результатов поиска полезно указать начало такого собрания. Вы можете помочь системе поиска. Использовав элемент Link с rel="start" и атрибутом title attribute, как в:
<link rel="begin"
type="text/html"
href="page1.html"
title="general theory of relativity">
Роботы с инструкцией индексирования
Люди могут удивиться, узнав, что их сайт был индексирован роботом, хотя роботу не было разрешено посещать некоторые критические секции. Многие web-роботы предлагают возможности администраторам сайтов и провайдерам информации ограничить возможности роботов. Это достигается с помощью двух механизмов: файла "robots.txt" и элемента meta в HTML-документах, как это показано ниже.
41. Поисковые роботы
Файл robots.txt
Когда робот посещает сайт, скажем http://www.foobar.com/, он сначала проверяет наличие http://www.foobar.com/robots.txt. Если он нашел этот документ, он анализирует его содержимое и выясняет, разрешен ли допуск к документу. Вы можете указать, что файл robots.txt доступен только для специальных роботов, и запретить доступ к определенным каталогам и файлам. Ниже приведен пример файла robots.txt, который препятствует всем роботам посещение всего сайта.
user-agent: * # applies to all robots
disallow: / # disallow indexing of all pages
Робот просто будет искать "/robots.txt" uri на вашем сайте, где сайт определен как HTTP-сервер, работающий на определенной ЭВМ с заданным номером порта. Ниже приведены примеры места положения robots.txt:
Сайт URI |
URI для robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
Некоторые советы: URI чувствительны к набору строчными или прописными буквами, а строка "/robots.txt" должна быть набрана строчными буквами. Пустые строки не допустимы.
Должен быть только одно поле "user-agent" на рекорд. Робот должен либерально интерпретировать это поле. Если значение равно "*", рекорд описывает политику доступа любого робота по умолчанию (робот не соответствует ни одному другому рекорду). Не допускается более одного такого рекорда в файле "/robots.txt".
Поле "disallow" специфицирует URI, который не должен посещаться. Это может быть полный проход, частичный проход, любой URI, который начинается с этой величины, не будет доступен. Например,
disallow: /help запрещает как /help.html так и /help/index.html, в то время как
disallow: /help/ запрещает посещение /help/index.html, но позволяет /help.html.
Пустое значение для "disallow", указывает, что все uri доступны. Хотя бы одно поле "disallow" должно присутствовать в файле robots.txt.
41.1. Роботы и элементы meta
Элемент meta позволяет HTML разработчикам сообщить приходящим роботам, можно ли индексировать документы. В ниже приведенном примере робот не должен ни индексировать документ, ни анализировать его связи.
<meta name="robots" content="noindex, nofollow">
Список терминов в содержимом включает в себя all, index, nofollow, noindex. Имена и содержимое значений атрибутов не зависит от регистра, использованного при наборе текста.
Замечание. В начале 1997 только несколько роботов следовало этим правилам, но ожидается, что ситуация изменится в ближайшее время.
42. Замечания о таблицах
Модель таблиц HTML взята из исследований существующих моделей таблиц SGML. Модель выбрана из соображений простоты и возможностей дальнейшего расширения функций, если это потребуется.
Важно, что модель таблиц HTML согласуется с большинством существующих средств их создания (напр., с текстовыми редакторами).
43. Динамическое реформатирование
Главным соображением при выработке модели таблиц HTML является то, что разработчик не должен заботиться о вариации размера таблиц пользователем или о его выборе шрифтов. Это делает рискованным задание ширины колонки в абсолютных единицах (пикселях). Вместо этого таблицы должны быть способны динамически приспосабливать размер таблицы к размерам имеющегося окна и к выбранным шрифтам. Разработчик может сформулировать пожелания относительно ширин колонок, но агент пользователя может и не следовать этим пожеланиям. Он должен обеспечить размер ячейки, достаточный для размещения самого крупного элемента.
44. Инкрементное отображение
Для больших таблиц или для медленных сетевых соединений пользователю важна возможность реализации инкрементного отображения таблицы. Агенты пользователя должны быть способны начать отображение таблицы до того, как будут получены все данные. Ширина окна по умолчанию для большинства агентов пользователя равна 80 символам, а графика для многих HTML страниц сконструирована с учетом этого значения. При специфицировании числа колонок, включая различные механизмы управления шириной колонок, разработчики могут подсказать агенту пользователя как организовать инкрементное отображение таблицы.
Для инкрементного отображения броузер должен знать число колонок и их ширину. Ширина таблицы по умолчанию определяется размером текущего окна (ширина="100%"). Это значение может быть изменено путем установки атрибута width в элементе table. По умолчанию, все колонки имеют равные ширины, но вы можете специфицировать ширины колонок с помощью одного или нескольких элементов col.
Последний пункт – число колонок. Некоторые люди предлагают ждать, пока первый ряд таблицы будет получен, но это может занять много времени, если ячейки содержат много материала. Имеет смысл, особенно для целей инкрементного отображения таблиц, задать разработчикам число колонок в таблице явно (в элементе table).
Разработчикам нужен способ, сообщить агенту пользователя, следует ли использовать инкрементное отображение или изменить размер таблицы с тем, чтобы можно было разместить содержимое ячеек. В режиме двухпроходного определения размеров число колонок определяется при первом проходе. При инкрементном режиме сначала должно быть объявлено число колонок (с помощью элементов col или colgroup).
45. Структура и презентация
HTML различает структурную разметку, такую как параграфы и цитаты из идиом отображения (rendering idioms) таких как поля, шрифты, цвета, и т.д. Как это различие влияет на таблицы? С чисто теоретической точки зрения выравнивание текста внутри ячеек таблицы и определение границы между ячейками, проблема отображения, а не структуры. На практике полезно использовать обе возможности. Модель таблиц HTML оставляет большую часть управления отображением стилевым листам.
Современные издательские системы предоставляют очень богатые возможности управления отображением таблиц. Эти спецификации предлагают разработчику возможность выбора класса стиля границ. Атрибут frame управляет наличием разграничительных линий вокруг таблицы, в то время как атрибут rules определяет выбор разделительных линий внутри таблицы. Стилевой атрибут может быть использован для спецификации информации, управляющей процессом отображения для индивидуальных элементов. Дополнительная информация может быть получена через элемент style в заголовке документа или из подключенного стилевого листа.
46. Группы строк и колонок
Таблицы рассматриваются как соединение опционной надписи и последовательность рядов, которые в свою очередь состоят из последовательности ячеек. Модель еще более дифференцирует заголовок и информационные ячейки и позволяет ячейкам занимать несколько рядов и колонок.
Эта спецификация (модель таблиц cals) позволяет группировать ряды в секции заголовка, тела и основания. Она упрощает представление информации и может использоваться для повторения верхней и нижней секций при разбиении таблиц на несколько страниц, или для обеспечения фиксированного заголовка над панелью со скролированием текста. Это позволяет отображать нижнюю секцию, не дожидаясь пока вся таблица будет обработана.
47. Доступность
Модель таблиц HTML включает атрибуты для пометки каждой ячейки с целью высококачественного преобразования текста в голос. Те же самые атрибуты могут использоваться для поддержки автоматического обмена с базами данных и электронными таблицами.
48. Рекомендуемые алгоритмы верстки
Если присутствуют элементы col или colgroup, они специфицируют число колонок и таблица может быть отображена с использованием фиксированной раскладки. В противном случае будет применен автоматический алгоритм раскладки, описанный ниже.
Если атрибут width не специфицирован, визуальные агенты пользователя должны предполагать значение по умолчанию, равное 100%.
Рекомендуется, чтобы агенты пользователя увеличивали ширину таблицы за пределы, специфицированные width в случаях, когда содержимое может не поместиться. Агенты пользователя, которые корректируют значение, заданное width должны делать это в пределах разумного. Агенты пользователя могут выбрать переносы строк, когда горизонтальный скролинг не желателен или не практичен.
Для целей раскладки агенты пользователя должны учитывать, что табличные надписи (специфицированные элементом caption) ведут себя подобно ячейкам таблицы. Каждая надпись является ячейкой, которая простирается через все колонки таблицы, если она размещена вверху или внизу таблицы, или через все ряды, если она находится справа или слева от таблицы.
49. Фиксированные алгоритмы верстки
Для этого алгоритма предполагается, что число колонок известно. Ширины колонок по умолчанию делаются равными. Разработчики могут поменять эти установки, задав относительные или абсолютные значения колонок с помощью элементов colgroup или col. Значение ширины по умолчанию равно расстоянию от левого до правого поля, но оно может быть скорректировано с помощью атрибута width в элементе table, или определено из абсолютных ширин колонок. Для того чтобы работать со смесью абсолютных и относительных ширин, сначала нужно выделить место для колонок с заданной абсолютной шириной. После этого, оставшееся пространство делится между колонками с учетом их относительных ширин.
Сам по себе синтаксис таблицы не гарантирует взаимосогласованности значений атрибутов. Например, число элементов col и colgroup может не совпадать с числом колонок, используемых в таблице. Дополнительные проблемы возникают, когда колонки слишком узки и может произойти переполнение ячейки. Ширина таблицы, как это специфицировано элементами table или col может вызвать переполнение ячейки таблицы. Рекомендуется, чтобы агенты пользователя умели выходить из этого положения, например, путем переноса слов.
В случае, когда переполнение ячейки вызывается словом, которое не может быть поделено, агент пользователя может рассмотреть возможность изменения ширин колонок и повторного отображения таблицы. В худшем случае, можно допустить обрубание слов, если вариации ширин колонок и скроллинг оказались невозможными. В любом случае, если содержимое ячейки разделено или обрублено, об этом должно быть сообщено пользователю соответствующим способом.
50. Алгоритм авто выкладки
Если число колонок не специфицировано элементами col и colgroup, тогда агент пользователя должен использовать алгоритм автоматической выкладки. Он использует два прохода по данным таблицы и линейно масштабирует размеры таблицы.
При первом проходе запрещается разрыв строк и агент пользователя отслеживает минимальные и максимальные ширины для всех ячеек. Максимальная ширина задается самой длинной строкой. Так как разрыв строк запрещен, параграфы рассматриваются, как длинные строки, если не введены переносы строк с помощью элементов BR. Минимальная ширина задается наиболее широким текстовым элементом (словом, изображением, и т.д.) с учетом абзацев маркеров и пр. Другими словами необходимо определить минимальную ширину ячейки, которая необходима в пределах окна для того, чтобы ячейка не переполнилась. Допуская перенос слов, мы минимизируем необходимость горизонтального скролинга или обрубания содержимого ячейки.
Этот процесс применим к любым вложенным таблицам. Минимальные и максимальные ширины ячеек для вложенных таблиц используются для определения минимальной и максимальной ширины этих таблиц, и, следовательно, таблиц их прародителей. Алгоритм является линейным и не зависит от глубины вложения.
Минимальная и максимальная ширины ячейки используются для определения минимальной и максимальной ширины колонки. Эти значения в свою очередь служат для нахождения минимальной и максимальной ширины таблицы. Следует учитывать, что ячейки могут содержать вложенные таблицы, но это не усложняет программу сколько-нибудь значительно. Следующим шагом является определение ширин колонок в соответствии с доступным пространством (напр., зазором между левым и правым полями).
Внешние ограничители таблицы и внутренние разделительные линии должны учитываться при определении ширин колонок. Имеется три варианта:
Минимальная ширина таблицы равна или шире наличного пространства. В этом случае следует приписать минимальную ширину и разрешить агенту пользователя горизонтальный скролинг.
Максимальная ширина таблицы укладывается в имеющееся пространство. В этом случае следует установить ширины колонок по максимуму.
Максимальная ширина таблицы больше наличного пространства, а минимальная - меньше.
Если ширина таблицы задана атрибутом width, агент пользователя пытается установить соответствующим образом ширины колонок.
Если с помощью элемента col указаны относительные длины колонок, алгоритм может быть модифицирован так, что ширина колонок может превысить минимально объявленное значение для того, чтобы удовлетворить требования относительных ограничений. Элементы col должны рассматриваться только как рекомендации и ширины колонок не должны делаться меньше их минимальной ширины. Аналогично, колонки не должны делаться настолько широкими, что таблица не поместится в отведенное ей окно. Если элемент col специфицирует относительную ширину нуль, ширина колонки должна быть выбрана равной минимальной ширине.
Если несколько ячеек в различных рядах одной и той же колонки используют выравнивание, тогда по умолчанию все такие ячейки должны быть выстроены в линию, вне зависимости от того, какой символ был использован для выравнивания.
Выбор имен атрибутов. Предпочтительно выбрать значения для атрибута frame, согласующееся с атрибутом rules и параметрами выравнивания. Например: none, top, bottom, topbot, left, right, leftright, all. К сожалению, sgml требует нумеровать значения атрибутов, чтобы обеспечить их уникальность для каждого элемента, вне зависимости от имени атрибута. Это сразу создает проблемы для "none", "left", "right" и "all". Значения для атрибута frame были выбраны для исключения конфликтов с атрибутами rules, align, и valign.
51. Замечания о формах
Инкрементное отображение
Инкрементное отображение документов, полученных по сети, создают некоторые проблемы, связанные с формами. Агенты пользователя должны позаботиться о том, чтобы форма не была передана серверу до тех пор, пока не получены все элементы формы.
Если формы связаны со скриптами стороны клиента, создаются предпосылки для будущих проблем. Например, хандлер скриптов для данного поля может относиться к полю, которого пока не существует.
52. Будущие проекты
Данная спецификация определяет набор элементов и атрибутов, достаточно мощных, чтобы выполнить основные требования по генерации форм. Однако остается пространство для дальнейшего совершенствования. Например, следующие проблемы могут найти решение в будущем:
Диапазон типов полей формы слишком ограничен по сравнению с современными пользовательскими интерфейсами. Например, не существует возможности использования табуляции при вводе данных.
Серверы не могут корректировать поля в уже записанных формах, и вынуждены вместо этого передавать весь HTML-документ.
Другим возможным расширением может стать атрибут usemap элемента input для использования в качестве карты изображения на стороне клиента, когда "type=image". Элемент area, соответствующий позиции, где была нажата кнопка мыши, должен будет выдать информацию, передаваемую серверу. Чтобы избежать необходимости модифицировать скрипты сервера, может оказаться разумным расширить возможности area в отношении передачи значений координат x и y для использования их элементом input.
53. Заметки о скриптах
Эта спецификация резервирует синтаксис для будущей поддержки скриптовых макро в атрибутах cdata HTML. Целью этого является допущение установки атрибутов, зависящих от свойств объектов, которые были записаны выше на странице. Синтаксис выглядит следующим образом:
attribute = "... &{ macro body }; ... "
Существующая практика скриптов
Тело макро состоит из одного или более записей на языке скриптов. Точка с запятой, следующая за правой фигурной скобкой, всегда необходима, иначе правая фигурная скобка будет рассматриваться как часть текста макро.
Обработка Cdata атрибутов производится следующим образом:
Анализатор текста sgml вычисляет любой символьный объект SGML (напр., ">").
Далее скриптовые макросы обрабатываются интерпретатором скриптов.
И, наконец, результирующая последовательность символов передается приложению для последующей обработки.
Обработка макро имеет место, когда документ загружается, но эта процедура не повторяется, когда документ изменяется в размере или перезакрашивается.
Не рекомендуемый пример:
Ниже приведены примеры с использованием Javascript. Первый делает фон документа рэндомизованным:
<body bgcolor='&{randomrbg};'>
Возможно, вы хотите приглушить фон для просмотра в вечернее время:
<body bgcolor='&{if(date.gethours > 18)...};'>
Следующий пример использует javascript при установке координат для карты изображения на стороне клиента:
<map name=foo>
<area shape="rect" coords="&{myrect(imageuri)};" href="&{myuri};" alt="">
</map>
Этот пример устанавливает размер изображения, базируясь на свойствах документа:
<img src="bar.gif" width='&{document.banner.width/2};' height='50%' alt="banner">
Вы можете установить URI для связи или изображения с помощью скрипта:
<SCRIPT type="text/javascript">
function manufacturer(widget) {
...
}
function location(manufacturer) {
...
}
function logo(manufacturer) {
...
}
</SCRIPT>
<A href='&{location(manufacturer("widget"))};'>widget</A>
<IMG src='&{logo(manufacturer("widget"))};' alt="logo">
Последний пример показывает, как SGML CDATA атрибуты могут помещаться в одинарные или двойные кавычки. Если вы помещаете строку атрибута в одиночные кавычки, вы можете использовать двойные кавычки в качестве части строки атрибута. Другой подход связан с использованием " для двухкавычечных меток:
<IMG src="&{logo(manufacturer("widget"))};" alt="logo">
53.1. Зарезервированный синтаксис для будущих скриптов
Так как не существует гарантии того, что имя адресата рамки уникально, представляется разумным описать существующую практику нахождения имени адресата, заданного в рамке:
Если имя адресата является зарезервированным именем, как это записано в нормативном тексте, следует использовать его так, как описано.
В противном случае, следует выполнить поиск согласно иерархии рамок в окне, где содержится эта связь. Следует использовать первую рамку, имя которой соответствует искомому.
Если такой рамки не найдено на этапе (2), используется этап 2 для каждого окна в послойном порядке, начиная с переднего плана. Поиск прекращается, когда найдена рамка с соответствующим именем.
Если такой рамки не найдено на этапе (3), следует создать новое окно и присвоить ему имя адресата.
54. Замечания о доступности
Замечание. Следующий алгоритм генерации альтернативного текста может быть заменен рекомендациями W3C Web Accessibility Initiative Group. Для получения дополнительной информации предлагается ссылка [WAIGUIDE].
Когда разработчик не устанавливает атрибут alt для элементов IMG или APPLET, агент пользователя должен предоставить альтернативный текст, который получается следующим способом:
Если title был специфицирован, его значение должно использоваться в качестве альтернативного текста. В противном случае, если HTTP-заголовки предоставляют информацию о title, эта информация и должна использоваться в качестве альтернативного текста. В противном случае, если включенные объекты содержат текстовые поля (напр., GIF изображения содержат некоторые текстовые поля), информация из текстовых полей извлекается и используется в качестве альтернативного текста. Так как агенты пользователя для извлечения текстовых данных могут быть вынуждены заполучить сначала весь объект, пользовательские агенты могут воспользоваться каким-либо более экономным подходом. В противном случае, в отсутствии другой информации агенты пользователя должны воспользоваться именем файла (за вычетом расширения) в качестве альтернативного текста.
Если разработчик не установил атрибут alt для элемента INPUT, агент пользователя должен получить альтернативный текст следующим образом:
Если был специфицирован атрибут title, его значение должно использоваться в качестве альтернативного текста. В противном случае, если специфицировано имя, его значение используется как альтернативный текст. В противном случае (кнопки submit и reset), значение атрибута type должно использоваться в качестве альтернативного текста.
55. Замечания о безопасности
Якоря, встроенные изображения и все другие элементы, которые содержат URI в качестве параметров, могут вызвать повторное обращение к URI в ответ на ввод пользователя. В этом случае, следует рассмотреть соображения безопасности RFC-1738. Широко распространенные методы посылки запросов форм – HTTP и SMTP – обеспечивают ограниченную конфиденциальность. Провайдеры информации, которые запрашивают необходимые данные с помощью форм – точнее с помощью элементов INPUT, type="password" – должны позаботиться о том, чтобы сами пользователи учитывали возможность утечки конфиденциальной информации.
55.1. Соображения безопасности для форм
Агент пользователя не должен посылать какой-либо файл, который пользователь не указал явно, как подлежащий пересылке. Таким образом, агенты пользователя HTML должны требовать подтверждения для любых имен файлов по умолчанию, которые могут быть указаны значениями атрибутов элемента INPUT.
Эта спецификация не содержит механизма шифрования данных. Раз файл загружен, агент должен обработать и записать его соответствующим образом.
56. Ссылки на литературу и сервера
| [CSS1] | "Cascading Style Sheets, level 1", H. W. Lie and B. Bos, 17 December 1996. Доступно по адресу: http://www.w3.org/TR/REC-CSS1-961217 |
| [DATETIME] | "Date and Time Formats", W3C Note, M. Wolf and C. Wicksteed, 15 September 1997. Доступно по адресу: http://www.w3.org/TR/NOTE-datetime |
| [IANA] | "Assigned Numbers", STD 2, RFC 1700, USC/ISI, J. Reynolds and J. Postel, October 1994. Доступно по адресу: http://ds.internic.net/rfc/rfc1700.txt |
| [ISO639] | "Codes for the representation of names of languages", ISO 639:1988. Дополнительная информация может быть получена по адресу: http://www.iso.ch/cate/d4766.html. См. также http://www.sil.org/sgml/iso639a.html |
| [ISO3166] | "Codes for the representation of names of countries", ISO 3166:1993. |
| [ISO8601] | "Data elements and interchange formats -- Information interchange -- Representation of dates and times", ISO 8601:1988 |
| [ISO8879] |
"Information Processing -- Text and Office Systems -- Standard Generalized Markup Language (SGML)", ISO 8879:1986. Информация о стандарте может быть получена по адресу http://www.iso.ch/cate/d16387.html . |
| [ISO10646] | "Information Technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane", ISO/IEC 10646-1:1993. Данная спецификация учитывает также первые пять поправок к документу ISO/IEC 10646-1:1993 |
| [ISO88591] | "Information Processing -- 8-bit single-byte coded graphic character sets -- Part 1: Latin alphabet No. 1", ISO 8859-1:1987 |
| [MIMETYPES] |
Список зарегистрированных типов содержимого (типы MIME). Список зарегистрированных типов можно найти по адресу ftp://ftp.isi.edu/in-notes/iana/assignments/media-types /. |
| [RFC1555] | "Hebrew Character Encoding for Internet Messages", H. Nussbacher and Y. Bourvine, December 1993. Доступно по адресу: http://ds.internic.net/rfc/rfc1555.txt . |
| [RFC1556] | "Handling of Bi-directional Texts in MIME", H. Nussbacher, December 1993. Доступно по адресу: http://ds.internic.net/rfc/rfc1556.txt |
| [RFC1738] | "Uniform Resource Locators", T. Berners-Lee, L. Masinter, and M. McCahill, December 1994. Доступно по адресу: http://ds.internic.net/rfc/rfc1738.txt. |
| [RFC1766] | "Tags for the Identification of Languages", H. Alvestrand, March 1995. Доступно по адресу: http://ds.internic.net/rfc/rfc1766.txt |
| [RFC1808] | "Relative Uniform Resource Locators", R. Fielding, June 1995. Доступно по адресу: http://ds.internic.net/rfc/rfc1808.txt . |
| [RFC2044] | "UTF-8, a transformation format of Unicode and ISO 10646", F. Yergeau, October 1996. Доступно по адресу: http://ds.internic.net/rfc/rfc2044.txt |
| [RFC2045] | "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", N. Freed and N. Borenstein, November 1996. Доступно по адресу: http://ds.internic.net/rfc/rfc2045.txt. Учтите, что это RFC замещает RFC1521, RFC1522 и RFC1590. |
| [RFC2046] | "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", N. Freed and N. Borenstein, November 1996. Доступно по адресу: http://ds.internic.net/rfc/rfc2046.txt. Учтите, что это RFC замещает RFC1521, RFC1522 и RFC1590. |
| [RFC2068] | "HTTP Version 1.1 ", R. Fielding, J. Gettys, J. Mogul, H. Frystyk Nielsen, and T. Berners-Lee, January 1997. Доступно по адресу: http://ds.internic.net/rfc/rfc2068.txt |
| [RFC2119] | "Key words for use in RFCs to Indicate Requirement Levels", S. Bradner, March 1997. Доступно по адресу: http://ds.internic.net/rfc/rfc2119.txt |
| [RFC2141] | "URN Syntax", R. Moats, May 1997. Доступно по адресу: http://ds.internic.net/rfc/rfc2141.txt |
| [SRGB] | "A Standard Default color Space for the Internet", version 1.10, M. Stokes, M. Anderson, S. Chandrasekar, and R. Motta, 5 November 1996. Доступно по адресу: http://www.w3.org/Graphics/Color/sRGB |
| [UNICODE] | "The Unicode Standard: Version 2.0", The Unicode Consortium, Addison-Wesley Developers Press, 1996. Спецификация учитывает также обнаруженные ошибки http://www.unicode.org/unicode/uni2errata/bidi.htm. Для получения дополнительной информации, рекомендуется посмотреть базовую страницу Unicode Consortium's по адресу http://www.unicode.org |
| [URI] | "Uniform Resource Identifiers (URI): Generic Syntax and Semantics", T. Berners-Lee, R. Fielding, L. Masinter, 18 November 1997. Доступно по адресу: http://www.ics.uci.edu/pub/ietf/uri/draft-fielding-uri-syntax-01.txt. Работа продолжается и ожидается, что тексты RFC-1738 и RFC-1808 будут пересмотрены. |
| [WEBSGML] | "Proposed TC for WebSGML Adaptations for SGML", C. F. Goldfarb, ed., 14 June 1997. Доступно по адресу: http://www.sgmlsource.com/8879rev/n1929.htm |
/p> Информационные ссылки
| [BRYAN88] | "SGML: An Author' s Guide to the Standard Generalized Markup Language", M. Bryan, Addison-Wesley Publishing Co., 1988 |
| [CALS] | Continuous Acquisition and Life-Cycle Support (CALS). CALS является стратегией Министерства обороны США для достижения эффективного создания, обмена и использования цифровых данных для оборудования и систем оружия. Дополнительная информация доступна на базовой странице CALS по адресу http://navysgml.dt.navy.mil/cals.html |
| [CHARSETS] | Registered charset values. Загрузка списка зарегистрированных наборов символов возможна по адресу ftp://ftp.isi.edu/in-notes/iana/assignments/character-sets |
| [CSS2] | "Cascading Style Sheets, level 2", B. Bos, H. W. Lie, C. Lilley, and I. Jacobs, November 1997. Доступно по адресу: http://www.w3.org/TR/WD-CSS2 |
| [DCORE] | The Dublin Core: дополнительная информация доступна по адресу http://purl.org/metadata/dublin_core |
| [ETHNO] | "Ethnologue, Languages of the World", 12th Edition, Barbara F. Grimes editor, Summer Institute of Linguistics, October 1992. |
| [GOLD90] | "The SGML Handbook", C. F. Goldfarb, Clarendon Press, 1991. |
| [HTML30] | "HyperText Markup Language Specification Version 3.0", Dave Raggett, September 1995. Доступно по адресу: http://www.w3.org/MarkUp/html3/CoverPage |
| [HTML32] | "HTML 3.2 Reference Specification", Dave Raggett, 14 January 1997. Доступно по адресу: http://www.w3.org/TR/REC-html32 |
| [HTML3STYLE] | "HTML and Style Sheets", B. Bos, D. Raggett, and H. Lie, 24 March 1997. Доступно по адресу: http://www.w3.org/TR/WD-style |
| [LEXHTML] | "A Lexical Analyzer for HTML and Basic SGML", D. Connolly, 15 June 1996. Доступно по адресу: http://www.w3.org/TR/WD-html-lex |
| [PICS] | Platform for Internet Content (PICS). Дополнительная информация доступна по адресу http://www.w3.org/PICS |
| [RDF] | The Resource Description Language: дополнительная информация доступна по адресу http://www.w3.org/Metadata/RDF |
| [RFC822] | "Standard for the Format of ARPA Internet Text Messages", Revised by David H. Crocker, August 1982. Доступно по адресу: http://ds.internic.net/rfc/rfc822.txt . |
| [RFC850] | "Standard for Interchange of USENET Messages", M. Horton, June 1983. Доступно по адресу: http://ds.internic.net/rfc/rfc850.txt |
| [RFC1468] | "Japanese Character Encoding for Internet Messages", J. Murai, M. Crispin, and E. van der Poel, June 1993. Доступно по адресу: http://ds.internic.net/rfc/rfc1468.txt |
| [RFC1630] | "Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web", T. Berners-Lee, June 1994. Доступно по адресу: http://ds.internic.net/rfc/rfc1630.txt |
| [RFC1866] | "HyperText Markup Language 2.0", T. Berners-Lee and D. Connolly, November 1995. Доступно по адресу: http://ds.internic.net/rfc/rfc1866.txt |
| [RFC1867] | "Form-based File Upload in HTML", E. Nebel and L. Masinter, November 1995. Доступно по адресу: http://ds.internic.net/rfc/rfc1867.txt. Ожидается, что RFC1867 будет поправлено, см.: ftp://ftp.ietf.org/internet-drafts/draft-masinter-form-data-01.txt, в настоящее время ведутся работы |
| [RFC1942] | "HTML Tables", Dave Raggett, May 1996. Доступно по адресу: http://ds.internic.net/rfc/rfc1942.txt |
| [RFC2048] | "Multipurpose Internet Mail Extensions (MIME) Part Four: Registration Procedures", N. Freed, J. Klensin, and J. Postel, November 1996. Доступно по адресу: http://ds.internic.net/rfc/rfc2048.txt. Учтите, что это RFC замещает RFC-1521, RFC-1522 и RFC-1590. |
| [RFC2070] | "Internationalization of the HyperText Markup Language", F. Yergeau, G. Nicol, G. Adams, and M. Dьrst, January 1997. Доступно по адресу: http://ds.internic.net/rfc/rfc2070.txt |
| [SGMLOPEN] | SGML Consortium. Базовая страница консорциума находится по адресу http://www.sgmlopen.org |
| [SP] | SP представляет собой общедоступный интерпретатор SGML. Доступно по адресу: ftp://ftp.jclark.com/pub/sp /. Дополнительная информация доступна по адресу: http://www.jclark.com |
| [SQ91] | "The SGML Primer", 3rd Edition, SoftQuad Inc., 1991 |
| [TAKADA] | "Multilingual Information Exchange through the World-Wide Web", Toshihiro Takada, Computer Networks and ISDN Systems, Vol. 27, No. 2, pp. 235-241, November 1994. |
| [WAIGUIDE] | Базовая информация по формированию HTML документов доступна на сайте Web Accessibility Initiative (WAI): http://www.w3.org/WAI/. |
| [VANH90] | "Practical SGML", E. van Herwijnen, Kluwer Academic Publishers Group, Norwell and Dordrecht, 1990 |
Язык описания маршрутной политики RPSL
4.4.11.8 Язык описания маршрутной политики RPSL
Семенов Ю.А. (ГНЦ ИТЭФ)
1. Введение
Язык описания маршрутной политики RPSL (Routing Policy Specification Language) позволяет оператору сети специфицировать маршрутную политику на различных уровнях иерархии Интернет, например, на уровне автономных систем (AS). Так что низкоуровневые конфигурации маршрутизаторов могут генерироваться на основании спецификаций RPSL. Язык RPSL является расширяемым и не препятствует внедрению новых протоколов маршрутизации.
Язык RPSL призван заменить язык спецификации маршрутной политики, используемый в настоящее время и описанный в документах RIPE-181 [6] или RFC-1786 [7]. RIPE-81 [8] был первым языком, использованным в Интернет для спецификации маршрутных политик. В процессе использования RIPE-181 стало понятно, что некоторые политики не могут быть специфицированы и необходим более совершенный язык.
Язык RPSL был сконструирован так, чтобы описание всей политики маршрутизации записывалось в одну распределенную базу данных, улучшая целостность маршрутизации в Интернет. RPSL не является языком конфигурации маршрутизатора. Язык RPSL сформирован так, чтобы конфигурация маршрутизатора осуществлялась на основе описания маршрутной политики автономной системы (класс aut-num) в сочетании с описанием маршрутизатора (класс inet-rtr), которое предоставляет идентификатор маршрутизатора, номер автономной системы, описания интерфейсов и партнеров маршрутизатора. Эти данные используются совместно с глобальной базой данных карты автономных систем (класс as-set), и информацией об автономных системах отправителях и о маршрутных префиксах (классы route и route-set).
Язык RPSL является объектно-ориентированным, то есть, объекты содержат блоки описания политики и административную информацию. Эти объекты регистрируются в IRR (Internet Routing Registry) авторизованными организациями. О IRR смотри [1, 17, 4].
Далее рассматриваются классы, которые используются для определения различных политик и административных объектов. Класс "mntner" определяет средства, предназначенные для добавления, уничтожения и модификации набора объектов. Классы "person" и "role" описывают технический и административный персонал, с которым можно установить контакт. Автономные системы (AS) специфицируются с помощью класса "aut-num". Маршруты специфицируются посредством класса "route". Наборы объектов могут быть определены с помощью классов "as-set", "route-set", "filter-set", "peering-set" и "rtr-set". Класс "dictionary" предоставляет возможность расширения возможностей языка. Класс "inet-rtr" используется для спецификации маршрутизаторов. Многие из этих классов были определены ранее, смотри [6, 13, 16, 12, 5].
2. Имена, зарезервированные слова и представления RPSL
Каждый класс имеет набор атрибутов, где записывается некоторая информация об объектах класса. Атрибуты могут быть обязательными и опционными. Обязательный атрибут должен быть определен для всех объектов класса. Опционный атрибут может отсутствовать. Атрибуты могут быть одно- и многозначными. Каждый объект однозначно идентифицируется набором атрибутов класса "key".
Значение любого атрибута имеет определенный тип. Язык RPSL не чувствителен к тому, в каком регистре записаны те или иные выражения. Далее перечислены наиболее часто используемые типы атрибутов.
Многие объекты в RPSL имеют имя. <object-name> составляется из букв, чисел, а также символов подчеркивания ("_") и дефисов ("-"), первым символов всегда должна быть буква, а последним символом - буква или цифра. Следующие слова зарезервированы в RPSL, и не могут использоваться в качестве имен:
any as-any rs-any peeras
and or not
atomic from to at action accept announce except refine
networks into inbound outbound
Имена, начинающиеся с определенных префиксов зарезервированы для определенных типов объектов. Имена, начинающиеся с "as-" зарезервированы для имен автономных систем. Имена, начинающиеся с "rs-" зарезервированы для набора имен маршрутов. Имена, начинающиеся с "rtrs-" зарезервированы для набора имен маршрутизаторов. Имена, начинающиеся с "fltr-" зарезервированы для набора имен фильтров. Имена, начинающиеся с "prng-" зарезервированы для набора имен партнеров.
<as-number>
<ipv4-address>
<address-prefix>
<address-prefix-range> |
Диапазоном адресных префиксов является адресный префикс, за которым следует опционный оператор диапазона. Операторами диапазона являются: |
^- |
оператор значений “больше, исключая”. Он служит для выделения адресных префиксов больше указанного, но исключая пограничное значение префикса. Например, 128.9.0.0/16^- содержит все префиксы больше 128.9.0.0/16, исключая значение 128.9.0.0/16. |
^+ |
оператор значений “больше, включая”. Он служит для выделения адресных префиксов больше указанного, включая пограничное значение префикса. Например, 5.0.0.0/8^+ содержит все префиксы больше 5.0.0.0/8, включая 5.0.0.0/8. |
^n |
где n целое, выделяет из адресного префикса все значения с длиной n. Например, 30.0.0.0/8^16 содержит все префиксы более 30.0.0.0/8, которые имеют длину 16, такие как 30.9.0.0/16. |
| ^n-m | где n и m целые числа, выделяет из адресного префикса все значения с длинами в интервале от n до m. Например, 30.0.0.0/8^24-32 содержит все значения из префикса 30.0.0.0/8, которые имеют длины в интервале 24-32, такие как 30.9.9.96/28. |
Применение двух операторов диапазона последовательно является ошибкой (напр. 30.0.0.0/8^24-28^+ - ошибка). Однако оператор диапазона может быть применен к набору адресных префиксов, содержащий диапазоны адресных префиксов (напр. {30.0.0.0/8^24-28}^27-30 не является ошибкой). В этом случае, внешний оператор ^n-m располагается над внутренним оператором ^k-l и становится оператором ^max(n,k)-m, если m больше или равно max(n,k), в противном случае префикс удаляется из набора. Заметим, что оператор ^n эквивалентен ^n-n. Префикс/l^+ эквивалентен префиксу prefix/l^l-32. Префикс/l^- эквивалентен префиксу prefix/l^(l+1)-32. Префикс {prefix/l^n-m}^+ эквивалентен префиксу {prefix/l^n-32}, а префикс {prefix/l^n-m}^- эквивалентен префиксу {prefix/l^(n+1)-32}. Например,
| {128.9.0.0/16^+}^- | == {128.9.0.0/16^-} |
| {128.9.0.0/16^-}^+ | == {128.9.0.0/16^-} |
| {128.9.0.0/16^17}^24 | == {128.9.0.0/16^24} |
| {128.9.0.0/16^20-24}^26-28 | == {128.9.0.0/16^26-28} |
| {128.9.0.0/16^20-24}^22-28 | == {128.9.0.0/16^22-28} |
| {128.9.0.0/16^20-24}^18-28 | == {128.9.0.0/16^20-28} |
| {128.9.0.0/16^20-24}^18-22 | == {128.9.0.0/16^20-22} |
| {128.9.0.0/16^20-24}^18-19 | == {} |
/p>
<date> |
Дата представляется в виде восьми десятичных цифр вида YYYYMMDD, где YYYY отображает год, MM представляет месяц (01 - 12) и DD характеризует день месяца (01 - 31). Все даты, если не определено что-то иное, задаются в стандарте UTC. Например, 07 июля 1938 представляется в виде 19380707. |
<email-address> |
описано в RFC-822 [10]. |
<dns-name> |
описано в RFC-1034 [17]. | /TR>
<nic-handle> |
представляет собой уникальный идентификатор, используемый при маршрутизации, присвоении адресов и т.д. для того, чтобы обеспечить однозначную ссылку на контактную информацию. Классы person и role связывают указатели NIC с действительными именами людей и контактной информацией. |
<free-form> |
представляет собой последовательность ASCII-символов. |
<X-name> |
является именем объекта типа X. То есть <mntner-name> является именем объекта mntner. |
<registry-name> |
является именем регистратора IRR. |
Описание атрибута может содержать комментарий. Комментарий может размещаться где угодно в определении объекта, он начинается с символа "#" и завершается первым же символом перехода на новую строку.
Целые числа могут задаваться:
в нотации языка программирования C (напр. 1, 12345),
в виде последовательности четырех одно-октетных целых чисел (в диапазоне 0-255), разделенных символом точка "." (например, 1.1.1.0, 255.255.0.0), в этом случае 4-октетное целое образуется объединением этих однооктетных целых чисел, начиная с наиболее значимых,
в виде двух 2-октетных целых чисел (в диапазоне 0 - 65535), разделенных символом двоеточие ":" (например, 3561:70, 3582:10), в этом случае 4-октетное целое число образуется путем объединения всех октетов в порядке их значимости.
3. Контактная информация
Классы mntner, person и role, а также атрибуты admin-c, tech-c, mnt-by, changed и всех классов характеризуют контактную информацию. Класс mntner специфицирует также аутентификационную информацию, необходимую для того, чтобы создать, ликвидировать или модифицировать другие объекты. Эти классы не специфицируют маршрутную политику и каждый реестр может иметь различные или дополнительные требования. В документе "Routing Policy System Security" [20] описана модель аутентификации и авторизации.
3.1. Класс mntner
Класс mntner специфицирует аутентификационную информацию, необходимую для того, чтобы создать, ликвидировать или модифицировать объекты RPSL. Провайдер прежде чем создавать RPSL-объект, должен создать объект mntner. Атрибуты класса mntner показаны на рис. .1. Класс mntner описан в [13].
Атрибут mntner является обязательным и выполняет функцию ключа класса. Его значение – имя RPSL. Атрибут auth специфицирует схему, которая будет использоваться для идентификации и аутентификации запросов актуализации. Атрибут имеет следующий синтаксис:
auth: <scheme-id> <auth-info>
Например, auth: NONE
| Атрибут | Значение | Тип |
| Mntner | <object-name> | обязательный, однозначный, ключ класса |
| Descry | <free-form> | обязательный, однозначный |
| Auth | Смотри описание в тексте | обязательный, многозначный |
| upd-to | <email-address> | обязательный, многозначный |
| mnt-nfy | <email-address> | опционный, многозначный |
| tech-c | <nic-handle> | обязательный, многозначный |
| admin-c | <nic-handle> | опционный, многозначный |
| remarks | <free-form> | опционный, многозначный |
| notify | <email-address> | опционный, многозначный |
| mnt-by | список <mntner-name> | обязательный, многозначный |
| changed | <email-address> <date> | обязательный, многозначный |
| source | <registry-name> | обязательный, однозначный |
/p> Рис. .1. Атрибуты класса mntner
auth: CRYPT-PW dhjsdfhruewf
auth: MAIL-FROM .*@ripe\.net
В настоящее время для <scheme-id> определены значения: NONE, MAIL-FROM, PGP-KEY и CRYPT-PW. <auth-info> представляет дополнительную информацию, необходимую для конкретной схемы: в случае MAIL-FROM, это регулярное выражение, соответствующее корректному электронному почтовому адресу. В случае CRYPT-PW, это пароль в крипто-формате UNIX. В случае PGP-KEY, это указатель на объект key-certif [22], содержащий открытый ключ PGP-пользователя. Если специфицировано несколько атрибутов auth, запрос эксплуатационный актуализации, удовлетворяющий любому из них, будет аутентифицирован.
Атрибут upd-to представляет собой электронный почтовый адрес. При неавторизованной попытке актуализации объекта, по этому адресу будет послано сообщение. Атрибут mnt-nfy также представляет собой почтовый адрес. При добавлении, изменении или удалении объекта по этому адресу посылается уведомляющее сообщение.
Атрибут descr является коротким текстовым описанием объекта, выполненным в произвольной форме. Атрибут tech-c представляет собой контактный дескриптор NIC. Он используется при возникновении технических проблем, например, при неверной конфигурации. Атрибут admin-c представляет собой административный контактный дескриптор NIC. Атрибут remarks представляет собой текстовый комментарий или разъяснение. Атрибут notify представляет собой электронный адрес, куда следует отправлять уведомление об изменении этого объекта. Атрибут mnt-by является списком имен объектов mntner. Атрибут changed определяет, кто последний раз изменял данный объект, и когда это изменение было произведено. Его синтаксис имеет следующий формат:
changed:
Например
changed: johndoe@terabit-labs.nn 19900401
<email-address> идентифицирует человека, который внес последние изменения. <YYYYMMDD> представляет собой дату изменения. Атрибут source специфицирует реестр, где объект зарегистрирован. На рис. .2 показан пример объекта mntner. В этом примере использован криптографический формат UNIX для паролей аутентификации.
| mntner: | RIPE-NCC-MNT |
| descr: | RIPE-NCC Maintainer |
| admin-c: | DK58 |
| tech-c: | OPS4-RIPE |
| upd-to: | ops@ripe.net |
| mnt-nfy: | ops-fyi@ripe.net |
| auth: | CRYPT-PW lz1A7/JnfkTtI |
| mnt-by: | RIPE-NCC-MNT |
| changed: | ripe-dbm@ripe.net 19970820 |
| source: | RIPE |
/p> Рис. 2. Пример объекта mntner.
Атрибуты descr, tech-c, admin-c, remarks, notify, mnt-by, changed и source являются атрибутами всех классов RPSL. Их синтаксис, семантика, а также статус mandatory (обязательный), optional (опционный), multi-valued (многозначный), или однозначный те же что и для всех классов RPSL. Единственным исключением является атрибут admin-c, который является обязательным для класса aut-num.
3.2. Класс person
Класс person используется для описания информации о людях. Хотя он не описывает маршрутную политику, его описание здесь приводится, так как многие объекты политики делают ссылки на конкретных людей. Класс person был впервые описан в [15].
Атрибуты класса person представлены на рис. .3 Атрибут person представляет собой полное имя человека. Атрибуты phone и fax-no имеют следующий синтаксис:
phone: +<country-code> <city> <subscriber> [ext. <extension>]
Например:
phone: +31 20 12334676
| Атрибут | Значение | Тип |
| Person | <free-form> | обязательный, однозначный |
| nic-hdl | <nic-handle> | обязательный, однозначный, ключ класса |
| address | <free-form> | обязательный, многозначный |
| phone | См. описание в тексте | обязательный, многозначный |
| fax-no | То же что и phone | опционный, многозначный |
| <email-address> | обязательный, многозначный |
phone: +44 123 987654 ext. 4711
На рис. .4 приведен пример объекта person.
| person: | Daniel Karrenberg |
| address: | RIPE Network Coordination Centre (NCC) |
| address: | Singel 258 |
| address: | NL-1016 AB Amsterdam |
| address: | Netherlands |
| phone: | +31 20 535 4444 |
| fax-no: | +31 20 535 4445 |
| e-mail: | Daniel.Karrenberg@ripe.net |
| nic-hdl: | DK58 |
| changed: | Daniel.Karrenberg@ripe.net 19970616 |
| source: | RIPE |
3.3. Класс role
Класс role подобен объекту person. Однако вместо описания человека он описывает роль, которую выполняет один или несколько человек. Примеры включают в себя консультационные пункты, центры сетевого мониторинга, системных администраторов и т.д. Объект role особенно полезен, так как человек, выполняющий роль, может быть заменен, а сама роль остается неизменной.
Атрибуты класса role показаны на рис. .5. Атрибуты лиц nic-hdl и классы role используют совместно одно и то же пространство имен. Атрибут trouble объекта role может содержать дополнительную контактную информацию, которая может быть использована при возникновении проблемы в любом объекте, который ссылается на данный объект role. На рис. .6 показан пример объекта role.
Рис. .5. Атрибуты класса role
| role: | RIPE NCC Operations |
| address: | Singel 258 |
| address: | 1016 AB Amsterdam |
| address: | The Netherlands |
| phone: | +31 20 535 4444 |
| fax-no: | +31 20 545 4445 |
| e-mail: | ops@ripe.net |
| admin-c: | CO19-RIPE |
| tech-c: | RW488-RIPE |
| tech-c: | JLSD1-RIPE |
| nic-hdl: | OPS4-RIPE |
| notify: | ops@ripe.net |
| changed: | roderik@ripe.net 19970926 |
| source: | RIPE |
4. Класс route
Каждый маршрут interAS (называемый также междоменным маршрутом), начинающийся в AS, специфицируется с помощью объекта route. Атрибуты класса route представлены на рис. .7. Атрибут route представляет собой адресный префикс маршрута, а атрибут origin является номером AS, где этот маршрут начинается. Пара атрибутов route и origin являются ключом класса.
На рис. .8 представлены примеры четырех объектов route. Заметим, что последние два объекта route имеют один и тот же адресный префикс 128.8.0.0/16. Однако они являются различными объектами route, так как они начинаются в разных AS (то есть они имеют разные ключи).
Атрибут |
Значение |
Тип |
| Route | <address-prefix> | обязательный, однозначный, ключ класса |
| Origin | <as-number> | обязательный, однозначный, ключ класса |
| member-of |
список <route-set-names> см. раздел 5 |
опционный, многозначный |
| Inject | см. раздел 8 | опционный, многозначный |
| Components | см. раздел 8 | опционный, однозначный |
| aggr-bndry | см. раздел 8 | опционный, однозначный |
| aggr-mtd | см. раздел 8 | опционный, однозначный |
| export-comps | см. раздел 8 | опционный, однозначный |
| holes | см. раздел 8 | опционный, многозначный |
/p> Рис. 7: Атрибуты класса route
| route: | 128.9.0.0/16 |
| origin: | AS226 |
| route: | 128.99.0.0/16 |
| origin: | AS226 |
| route: | 128.8.0.0/16 |
| origin: | AS1 |
| route: | 128.8.0.0/16 |
| origin: | AS2 |
5. Классы Set
При спецификации политики часто полезно определить наборы объектов. Для этих целей определены классы as-set, route-set, rtr-set, filter-set, and peering-set. Эти классы определяют именованный набор. Члены этих наборов могут быть специфицированы непосредственно путем перечисления их в определении набора, или косвенно, имея ссылки членов-объектов на имена наборов. Допускается применение обоих методов.
Имя набора является словом rpsl со следующими ограничениями. Все имена as-set начинаются с префикса "as-". Все имена route-set начинаются с префикса "rs-". Все наборы имен rtr-set начинаются с префикса "rtrs-". Все имена filter-set начинаются с префикса "fltr-". Все имена peering-set начинаются с префикса "prng-". Например, as-foo является корректным именем as-set.
Имена наборов могут быть иерархическими. Имя иерархического набора представляет собой последовательность имен наборов и номеров AS, разделенных символом двоеточие ":". По крайней мере, одна компонента такого имени должна быть действительным именем набора (то есть начинается с одного из префиксов). Все компоненты имени набора иерархического имени должны иметь один и тот же тип. Например, следующие имена корректны: AS1:AS-CUSTOMERS, AS1:RS-EXPORT:AS2, RS-EXCEPTIONS:RS-BOGUS.
Целью имени иерархического набора является выделение определенного пространства имен, так что администратор набора X1 управляет всем набором нижележащих имен, то есть X1:...:Xn-1. Таким образом, набор объектов с именем X1:...:Xn-1:Xn может быть создан администратором объекта с именем X1:...:Xn-1. То есть, только администратор AS1 может создать набор с именем AS1:AS-FOO. Только администратор AS1:AS-FOO может создать набор с именем AS1:AS-FOO:AS-BAR.
5.1. Класс as-set
Атрибуты класса as-set показан на рис. .9. Атрибут as- set определяет имя набора. Он является именем RPSL, которое начинается с "as-". Атрибут members перечисляет членов набора. Атрибут members является списком AS, или других имен as-set.
Атрибут |
Значение |
Тип |
| as-set | <object-name> | обязательный, однозначный, ключ класса |
| members | список <as-numbers> или | опционный, многозначный |
| Mbrs-by-ref | список <mntner-names> | опционный, многозначный |
На рис. .10 представлены два объекта as-set. Набор as-foo содержит две AS, в частности AS1 и AS2. Набор as-bar содержит членов набора as-foo и AS3, т.е. он содержит AS1, AS2, AS3. Набор as-empty не содержит членов.
| as-set: as-foo | as-set: as-bar | as-set: as-empty |
| members: AS1, AS2 | members: AS3, as-foo |
Атрибут mbrs-by-ref представляет собой список имен администраторов (maintainer) или ключевое слово ANY. Если используется этот атрибут, набор AS включает также автономные системы, чьи объекты aut-num зарегистрированы одним из этих администраторов и чей атрибут member-of относится к имени этого набора AS. Если значение атрибута mbrs-by-ref равно ANY, любой объект AS, относящийся к набору, является членом этого набора. Если атрибут mbrs-by-ref пропущен, только AS, перечисленные в атрибуте members, являются членами набора.
as-set: as-foo
members: AS1, AS2
mbrs-by-ref: MNTR-ME
Рис. .11. Объекты as-set.
На рис. .11 представлен пример объекта as-set, который использует атрибут mbrs-by-ref. Набор set as-foo
содержит AS1, AS2 и AS3. AS4 не является членом набора as-foo не смотря на то, что объект aut-num ссылается на as-foo. Это происходит потому, что MNTR-OTHER отсутствует в списке атрибута as-foo mbrs-by-ref.
5.2. Класс route-set
Атрибуты класса route-set показаны на рис. .12. Атрибут route-set определяет имя набора. Он является именем RPSL, которое начинается с "rs-". Атрибут members перечисляет членов набора. Атрибут members представляет собой список адресных префиксов или других имен route-set. Заметим, что, класс route-set является набором префиксов маршрутов, а не маршрутных объектов RPSL.
Атрибут |
Значение |
Тип |
| route-set | <object-name> | обязательный, однозначный, ключ класса |
| members | список <address-prefix-range> или <route-set-name> или <route-set-name><range-operator> | опционный, многозначный |
| Mbrs-by-ref | список <mntner-names> | опционный, многозначный |
/p> Рис. .12. Атрибуты класса route-set
На рис. . 13 приведены некоторые примеры объектов route-set. Набор rs-foo содержит два адресных префикса, в частности 128.9.0.0/16 и 128.9.0.0/24. Набор rs-bar содержит члены набора rs-foo и адресный префикс 128.7.0.0/16.
За адресным префиксом или именем route-set в атрибуте members может опционно следовать оператор диапазона. Например, следующий набор:
route-set: rs-foo
members: 128.9.0.0/16, 128.9.0.0/24
route-set: rs-bar
members: 128.7.0.0/16, rs-foo
Рис. .13. Объекты route-set
route-set: rs-bar
members: 5.0.0.0/8^+, 30.0.0.0/8^24-32, rs-foo^+
содержат все префиксы больше 5.0.0.0/8, включая 5.0.0.0/8, все префиксы больше 30.0.0.0/8, чья длина лежит в пределах 24 – 32, такие как 30.9.9.96/28, и все префиксы больше префиксов из маршрутного набора rs-foo.
Атрибут mbrs-by-ref представляет собой список имен администраторов и может содержать ключевое слово ANY. Если используется этот атрибут, маршрутный набор включает также префиксы, чьи маршрутные объекты зарегистрированы одним из администраторов, и чей атрибут member-of указывает на имя этого маршрутного набора. Если значение атрибута mbrs-by-ref равно ANY, любой объект, связанный с именем маршрутного набора, является его членом. Если атрибут mbrs-by-ref отсутствует, только адресные префиксы, перечисленные в атрибуте members, являются членами этого набора.
route-set: rs-foo
mbrs-by-ref: MNTR-ME, MNTR-YOU
route-set: rs-bar
members: 128.7.0.0/16
mbrs-by-ref: MNTR-YOU
route: 128.9.0.0/16
origin: AS1
member-of: rs-foo
mnt-by: MNTR-ME
route: 128.8.0.0/16
origin: AS2
member-of: rs-foo, rs-bar
mnt-by: MNTR-YOU
Рис. .14. Объекты route-set.
На рис. 14 представлен пример объектов route-set, которые используют атрибут mbrs-by-ref. Набор rs-foo содержит два адресных префикса, в частности 128.8.0.0/16 и 128.9.0.0/16, так как маршрутные объекты для 128.8.0.0/16 и 128.9.0.0/16 отнесены к набору имен rs-foo в их атрибуте member-of. Набор rs-bar содержит адресные префиксы 128.7.0.0/16 и 128.8.0.0/16. Маршрут 128.7.0.0/16 представлен явно в атрибуте members rs-bar, а маршрутный объект для 128.8.0.0/16 связан с именем набора rs-bar в атрибуте member-of. Заметим, что если адресный префикс представлен в атрибуте маршрутного набора members, он является членом этого маршрутного набора. Маршрутный объект, соответствующий этому адресному префиксу не должен содержать атрибут member-of, относящийся к имени этого набора. Атрибут маршрутного класса member-of является дополнительным механизмом для косвенной спецификации членов набора.
5.3. Объекты предопределенных наборов
В этом контексте, который предполагает набор маршрутов (например, атрибут members класса route-set), номер автономной системы ASx определяет набор маршрутов, который исходит из Asx, а as-set AS-X определяет набор маршрутов, которые исходят из автономной системы AS-X. Маршрут p считается начинающимся в ASx, если существует маршрутный объект для p с ASx в качестве значения атрибута origin. Например, на рис. .15, набор маршрутов rs-special содержит маршруты 128.9.0.0/16, AS1 и AS2, а также маршруты автономных систем набора AS-FOO.
route-set: rs-special
members: 128.9.0.0/16, AS1, AS2, AS-FOO
Рис. .15. Использование номеров AS и маршрутных наборов.
Набор rs-any содержит все маршруты, зарегистрированные в IRR. Набор as-any содержит все AS, зарегистрированные в IRR.
5.4. Класс Filters и filter-set
Атрибуты класса filter-set представлены на рис. 16. Объект filter-set определяет набор маршрутов, которые соответствуют этому фильтру. Атрибут filter-set определяет имя фильтра. Он является именем RPSL, которое начинается с "fltr-".
Рис. .16. Атрибуты класса filter
filter-set: fltr-foo
filter: { 5.0.0.0/8, 6.0.0.0/8 }
filter-set: fltr-bar
filter: (AS1 or fltr-foo) and
Рис. .17. Объекты filter-set.
Атрибут filter определяет фильтр политики для данного набора. Фильтр политики является логическим выражением, которое в случае приложения к набору маршрутов в качестве результата возвращает субнабор этих маршрутов. Считается, что фильтр политики соответствует возвращенному субнабору. Фильтр политики может соответствовать маршрутам, использующим любой атрибут BGP-прохода, такой как адресный префикс места назначения (или NLRI), AS-path, или атрибуты community.
Фильтры политики могут составляться путем использования операторов AND, OR и NOT. Ниже представленные фильтры политики могут использоваться для селекции субнабора маршрутов:
ANY |
Ключевое слово ANY соответствует всем маршрутам. |
Address-Prefix Set |
Это список адресных префиксов, заключенных в фигурные скобки '{' и '}'. Фильтр политики соответствует набору маршрутов, чей адресный префикс места назначения содержится в этом наборе. Например: |
/p> { 0.0.0.0/0 }
{ 128.9.0.0/16, 128.8.0.0/16, 128.7.128.0/17, 5.0.0.0/8 }
{ }
За адресным префиксом может опционно следовать оператор диапазона (то есть
{ 5.0.0.0/8^+, 128.9.0.0/16^-, 30.0.0.0/8^16, 30.0.0.0/8^24-32 }
содержит все префиксы больше 5.0.0.0/8, включая 5.0.0.0/8, все префиксы больше 128.9.0.0/16, исключая 128.9.0.0/16, все префиксы больше 30.0.0.0/8, которые имеют длину 16, такие как 30.9.0.0/16, и все префиксы больше 30.0.0.0/8, которые имеют длину в диапазоне 24 – 32, такие как 30.9.9.96/28.
Route Set Name |
Имя набора маршрутов соответствует набору маршрутов, которые являются членами набора. Имя набора маршрутов может быть именем объекта route-set, номером AS или именем объекта as-set (номера AS и имена as-set неявно определяют маршрутные наборы). Например: |
import: from AS2 accept AS2
import: from AS2 accept AS-FOO
import: from AS2 accept RS-FOO
Ключевое слово PeerAS может использоваться вместо номера AS партнера. PeerAS является особенно полезным, когда партнерство охарактеризовано с помощью AS-выражения. Например:
as-set: AS-FOO
members: AS2, AS3
aut-num: AS1
import: from AS-FOO accept PeerAS
то же самое, что и:
aut-num: AS1
import: from AS2 accept AS2
import: from AS3 accept AS3
За именем набора маршрутов может также следовать один из операторов '^-', '^+', например, { 5.0.0.0/8, 6.0.0.0/8 }^+ эквивалентно { 5.0.0.0/8^+, 6.0.0.0/8^+ } и AS1^- эквивалентно всем адресным префиксам, соответствующим маршрутам, исходящим из AS1.
Регулярные выражения для проходов AS
.
Регулярное выражение AS-path может использоваться в качестве фильтра политики путем заключения его в угловые скобки `'. Фильтр политики AS-path соответствует набору маршрутов, который проходит через последовательность AS, которая согласуется с регулярным выражением AS-path. Маршрутизатор может проверить это, используя атрибут AS_PATH в протоколе BGP [19], или атрибут RD_PATH в протоколе IDRP [18].
Регулярное выражение формируется следующим образом:
ASN |
где ASN является номером AS. ASN соответствует AS-path, который имеет длину равную 1 и содержит корректный номер AS (например, регулярное выражение AS-path AS1 соответствует AS-path "1"). Вместо номера AS-партнера может использоваться ключевое слово PeerAS. |
AS-set |
где AS-set является именем набора AS. AS-set соответствует AS-проходам, которые согласуются с одним из AS в AS-set. |
. |
соответствует AS-path, который согласуется с любым номером AS. |
[...] |
является набором номеров AS. Это выражение соответствует AS-path, согласующимся со списком номеров AS, записанных в скобках. Номера AS в наборе отделяются друг от друга пробелом или символом TAB (white space). Если между двумя номерами AS использован символ `-', в набор включаются все AS из этого диапазона. Если в список включено имя as-set, в набор войдут все номера AS as-set. |
[^...] |
является дополнением набора AS. Это выражение соответствует любому AS-path, который не соответствует набору номеров AS из приведенного набора. |
^ |
Соответствует пустой строке в начале AS-path. |
$ |
Соответствует пустой строке в конце AS-path. |
/p> Далее описываются операторы регулярных выражений. Эти операторы выполняются слева направо.
Унарные постфиксные операторы * + ? {m} {m,n} {m,}
Для регулярных выражений A, запись A* соответствует нулю или более использований A. A+ соответствует одному или более использованию A. A? соответствует нулю или одному использованию A. A{m} соответствует m использованиям A. A{m,n} соответствует от m до n использованиям A/, A{m,} соответствует m или более использованиям A. Например, [AS1 AS2]{2} соответствует AS1 AS1, AS1 AS2, AS2 AS1 и AS2 AS2.
Унарные постфиксные операторы ~* ~+ ~{m} ~{m,n} ~{m,}
Эти операторы имеют аналогичную функциональность, что и соответствующие операторы, перечисленные выше, но все включения регулярного выражения должны соответствовать одному образцу. Например, [AS1 AS2]~{2} соответствует AS1 AS1 и AS2 AS2, но не соответствует AS1 AS2 и AS2 AS1.
Двоичный оператор объединения
.
Это неявный оператор, он вставляется между двумя регулярными выражениями A и B, когда не специфицирован другой оператор. Полученное выражение A B соответствует AS-path, если A соответствует некоторому префиксу AS-path, а B соответствует остальной части AS-path.
Двоичный альтернативный оператор |
Для регулярных выражений A и B, A | B соответствует любому AS-path, который соответствует A или B.
Для изменения порядка действий, предусмотренного по умолчанию, можно использовать скобки. Для улучшения читаемости могут использоваться WS (пробел или символ TAB). Ниже приведены примеры фильтров AS-path:
<^AS1>
<^AS1 AS2 AS3$>
<^AS1 .* AS2$>.
Первый пример соответствует любому маршруту, чей AS-path содержит AS3, второй соответствует маршрутам, чьи AS-path начинаются с AS1, третий соответствует маршрутам, чьи AS-path заканчиваются AS2, четвертый соответствует маршрутам, чьи AS-path в точности равны "1 2 3", а пятый соответствует маршрутам, чьи AS-path начинаются в AS1 и заканчиваются в AS2 с любым числом промежуточных AS между ними.
Составные фильтры политики
.
Последующие операторы могут использоваться при формировании составных фильтров политики.
| NOT | Дан фильтр политики x, NOT x соответствует набору маршрутов, которые не соответствуют x. Таким образом он представляет отрицание фильтра политики x. |
| AND | Даны два фильтра политики x и y, x AND y соответствует пересечению множеств маршрутов, которые соответствуют как фильтру x так и фильтру y. |
| OR | Даны два фильтра политики x и y, x OR y соответствует объединению множеств маршрутов, которые соответствуют фильтру x или фильтру y. Заметим, что оператор OR может быть неявным, то есть `x y' эквивалентно `x OR y'. Например |
AS226 AS227 OR AS228
AS226 AND NOT {128.9.0.0/16}
AS226 AND {0.0.0.0/0^0-18}
Первый пример соответствует любому маршруту кроме 128.9.0.0/16 и 128.8.0.0/16. Второй пример соответствует маршрутам AS226, AS227 и AS228. Третий пример соответствует маршрутам AS226, исключая 128.9.0.0/16. Четвертый пример соответствует маршрутам AS226, чья длина не больше 18.
Атрибуты фильтров политики могут использоваться для сравнения значения других атрибутов. Атрибуты, чьи значения могут применяться в фильтрах политики, специфицированы в словаре RPSL. Пример использования атрибута BGP community приведен ниже:
aut-num: AS1
export: to AS2 announce AS1 AND NOT community(NO_EXPORT)
Фильтры, использующие атрибуты маршрутной политики, определенные в словаре, вычисляются до выполнения операторов AND, OR и NOT.
Имя набора фильтров. |
Имя набора фильтров отвечает набору маршрутов, которые соответствуют их атрибуту фильтра. Заметим, что атрибут фильтра набора может рекурсивно связан с другими именами наборов фильтров. Например на рис. .17, fltr-foo соответствует {5.0.0.0/8, 6.0.0.0/8} и fltr-bar соответствует маршрутам AS1 или { 5.0.0.0/8, 6.0.0.0/8 }, если их путь содержит AS2. |
5.5. Класс rtr-set
Атрибуты класса rtr-set представлены на рис. .18. Атрибут rtr-set определяет имя набора. Он является словом RPSL, которое начинается с "rtrs-". Атрибут members перечисляет членов набора. Атрибут members представляет собой список имен inet-rtr, ipv4_addresses или других имен rtr-set.
Атрибут |
Значение |
Тип |
| rtr-set | <object-name> | обязательный, однозначный, ключ класса |
| members | список <inet-rtr-names> или <rtr-set-names> или <ipv4_addresses> | опционный, многозначный |
| mbrsbyref | список <mntnernames> | опционный, многозначный |
/p> Рис. .18. Атрибуты класса rtr-set
На рис. .19 представлены два объекта rtr-set. Набор rtrs-foo содержит два маршрутизатора, в частности rtr1.isp.net и rtr2.isp.net. Набор rtrs-bar содержит членов набора rtrs-foo и rtr3.isp.net, то есть он содержит rtr1.isp.net, rtr2.isp.net, rtr3.isp.net.
| rtr-set: rtrs-foo | rtr-set: rtrs-bar |
| members: rtr1.isp.net, rtr2.isp.net | members: rtr3.isp.net, rtrs-foo |
Атрибут mbrs-by- ref содержит список имен администраторов (maintainer) или ключевое слово ANY. Если использован этот атрибут, набор маршрутизаторов включает также маршрутизаторы, чьи объекты inet-rtr зарегистрированы одним из этих администраторов и чей атрибут member-of согласуется с именем этого набора маршрутизаторов. Если значение атрибута mbrs-by-ref равно ANY, любой объект inet-rtr соотносящийся набору маршрутизаторов, является членом этого набора. Если атрибут mbrs-by-ref отсутствует, только маршрутизаторы перечисленные в атрибуте members, являются членами набора.
rtr-set: rtrs-foo
members: rtr1.isp.net, rtr2.isp.net
mbrs-by-ref: MNTR-ME
inet-rtr: rtr3.isp.net
local-as: as1
ifaddr: 1.1.1.1 masklen 30
member-of: rtrs-foo
mnt-by: MNTR-ME
Рис. .20. Объекты rtr-set.
На рис. 20 представлен пример объекта rtr-set, который использует атрибут mbrs-by-ref. Набор rtrs-foo содержит rtr1.isp.net, rtr2.isp.net и rtr3.isp.net.
5.6. Партнерство и класс peering-set
Атрибуты класса peering-set представлены на рис. .21. Объект peering-set определяет набор партнеров, который перечислен в его партнерских атрибутах (peering). Атрибут peering-set определяет имя набора. Он является именем RPSL, которое начинается с "prng-".
Рис. .21. Атрибуты класса filter
Атрибут peering определяет партнеров, которые могут быть использованы для импорта или экспорта маршрутных данных.

Рис. .22. Пример топологии, состоящий из трех AS: AS1, AS2 и AS3, двух точек обмена: EX1 и EX2 и шести маршрутизаторов (IP[R1]= 1.1.1.1, IP[R2]= 2.2.2.1, IP[R3]= 1.1.1.2, IP[R4]= 1.1.1.3, IP[R5]= 2.2.2.2, IP[R6]= 2.2.2.3).
При описании партнерства используется топология, показанная на рис. .22. В этой топологии имеется три автономные системы, AS1, AS2, and AS3; две точки обмена, EX1 и EX2, и шесть маршрутизаторов (R1-R6). Маршрутизаторы соединены с точками обмена. То есть, 1.1.1.1, 1.1.1.2 и 1.1.1.3 являются партнерами друг для друга, а 2.2.2.1, 2.2.2.2 и 2.2.2.3 – также партнеры друг для друга.
Синтаксис спецификации партнерства:
<as-expression> [<router-expression-1>] [at <router-expression-2>] | <peering-set-name>
где <as-expression> является выражением для номеров AS и наборов AS, использующих операторы AND, OR и EXCEPT, а выражения <router-expression-1> и <router-expression-2> являются функциями IP-адресов маршрутизаторов, имен inet-rtr, и имен rtr-set, использующих операторы AND, OR и EXCEPT. Двоичный оператор "EXCEPT" семантически эквивалентен комбинации "AND NOT". То есть "(AS1 OR AS2) EXCEPT AS2" эквивалентно "AS1".
Эта форма идентифицирует всех партнеров между любым локальным маршрутизатором в <router-expression-2> и любыми маршрутизаторами в <router-expression-1> в автономных системах из <as-expression>. Если <router-expression-2> не специфицировано, это по умолчанию предполагает, что все маршрутизаторы локальной AS связаны с AS из <as-expression>.
Если используется <peering-set-name>, партеры перечислены в соответствующем объекте peering-set. Заметим, что объекты peering-set могут быть рекурсивными.
Возможны также многие специальные формы этой общей спецификации партнеров. Ниже приведенные примеры иллюстрируют наиболее общие случаи с использованием атрибута import класса aut-num. В следующем примере 1.1.1.1 импортирует 128.9.0.0/16 из 1.1.1.2.
(1) aut-num: AS1
import: from AS2 1.1.1.2 at 1.1.1.1 accept { 128.9.0.0/16 }
В следующем примере 1.1.1.1 импортирует 128.9.0.0/16 из 1.1.1.2 и 1.1.1.3.
(2) aut-num: AS1
import: from AS2 at 1.1.1.1 accept { 128.9.0.0/16 }
В следующем примере 1.1.1.1 импортирует 128.9.0.0/16 из 1.1.1.2 и 1.1.1.3, а 9.9.9.1 импортирует 128.9.0.0/16 из 2.2.2.2.
(3) aut-num: AS1
import: from AS2 accept { 128.9.0.0/16 }
В следующем примере 9.9.9.1 импортирует 128.9.0.0/16 из 2.2.2.2 и 2.2.2.3.
(4) as-set: AS-FOO
members: AS2, AS3
aut-num: AS1
| import: from ASFOO |
В следующем примере 9.9.9.1 импортирует 128.9.0.0/16 из 2.2.2.2 и 2.2.2.3, а 1.1.1.1 импортирует 128.9.0.0/16 из 1.1.1.2 и 1.1.1.3.
(5) aut-num: AS1
| import: from AS-FOO | accept { 128.9.0.0/16 } |
(6) aut-num: AS1
import: from AS-FOO and not AS2 at not 1.1.1.1 accept { 128.9.0.0/16 }
Это связано с тем, что "AS-FOO and not AS2" эквивалентно AS3 и "not 1.1.1.1" эквивалентно 9.9.9.1.
В следующем примере 9.9.9.1 импортирует 128.9.0.0/16 из 2.2.2.2 и 2.2.2.3.
(7) peering-set: prng-bar peering: AS1 at 9.9.9.1
peering-set: prng-foo
peering: prng-bar
peering: AS2 at 9.9.9.1
aut-num: AS1
import: from prng-foo accept { 128.9.0.0/16 }
6. Класс aut-num
Маршрутная политика специфицируется с использованием класса aut-num. Атрибуты класса aut-num представлены на рис. .23. Значение атрибута aut-num равно номеру AS, описанной данным объектом. Атрибут as-name является символическим именем (в рамках синтаксиса имен RPSL) AS. Импорт, экспорт и маршрутная политика по умолчанию AS специфицируются, используя атрибуты import, export и default, соответственно.
Атрибут |
Значение |
Тип |
| aut-num | <as-number> | обязательный, однозначный, ключ класса |
| as-name | <object-name> | обязательный, однозначный |
| member-of | Список <as-set-names> | опционный, многозначный |
| import | См. раздел 6.1 | опционный, многозначный |
| export | См. раздел 6.2 | опционный, многозначный |
| default | См. раздел 6.5 | опционный, многозначный |
6.1. Атрибут import: Спецификация политики импорта
В RPSL политика импорта определяется двумя выражениями импортной политики. Каждое выражение импортной политики специфицируется с помощью атрибута import. Атрибут import имеет следующий синтаксис:
| import: | from <peering-1> [action <action-1>] . . . |
| from <peering-N> [action <action-N>] | |
| accept <filter> |
Например
aut-num: AS1
import: from AS2 action pref = 1; accept { 128.9.0.0/16 }
Этот пример утверждает, что маршрут 128.9.0.0/16 воспринят от AS2 с предпочтением 1. Далее рассматривается спецификация действий (action).
6.1.1. Спецификация действия (Action)
Действия политики в RPSL устанавливают или модифицируют атрибуты маршрутов, таких как предпочтение маршрута, добавляет атрибут BGP community или устанавливает атрибут MULTI-EXIT-DISCRIMINATOR. Действия политики могут также инструктировать маршрутизаторы по выполнению специальных операций, таких как гашение осцилляций маршрутов.
Атрибуты маршрутной политики, чьи значения могут быть модифицированы посредством действий политики, специфицированы в словаре RPSL. Каждое действие при записи в RPSL завершаются символом точка с запятой (';'). Имеется возможность формировать составные действия политики путем последовательного их перечисления. В этом случае действия выполняются в порядке слева направо. Например,
aut-num: AS1
import: from AS2 action pref = 10; med = 0; community.append(10250, 3561:10);
| accept { 128.9.0.0/16 } |
aut-num: AS1
| import: | from AS2 action pref = 1; |
| from AS3 action pref = 2; | |
| accept AS4 |
aut-num: AS1
| import: | from AS2 1.1.1.2 at 1.1.1.1 action pref = 1; | |
| from AS2 | action pref = 2; | |
| accept AS4 |
6.2. Атрибут export: Спецификация экспортной политики
Аналогично выражение экспортной политики специфицируется с помощью атрибута export. Атрибут export имеет следующий синтаксис:
| export: | to <peering-1> [action <action-1>] |
| . . . | |
| to <peering-N> [action <action-N>] | |
| announce <filter> |
Например
aut-num: AS1
export: to AS2 action med = 5; community .= { 70 }; announce AS4
В этом примере, маршруты AS4 объявляются автономной системе AS2 со значением атрибута med, равным 5 и атрибута community = 70.
Пример:
aut-num: AS1
export: to AS-FOO announce ANY
В этом примере, AS1 объявляет все свои маршруты автономным системам AS из набора AS-FOO.
6.3. Другие маршрутные протоколы, мультипротокольные маршрутные протоколы и обмен маршрутами между протоколами
Более сложный синтаксис атрибутов import и export выглядит следующим образом:
import: [protocol <protocol-1>] [into <protocol-2>]
export: [protocol <protocol-1>] [into <protocol-2>]
Этот синтаксис используется там, где при описании политики других протоколов маршрутизации могут использоваться спецификации опционных протоколов, или для введения маршрутов одного протокола в другой протокол, или для многопротокольной маршрутной политики. Корректные имена протоколов определены в словаре. <protocol-1> является именем протокола, чьими маршрутами производится обмен. <protocol-2> представляет собой имя протокола, который принимает данные об этих маршрутах. Как <protocol-1> так и <protocol-2> являются протоколами по умолчанию для IEGP (Internet Exterior Gateway Protocol), в настоящее время его функцию выполняет BGP. В последующем примере все маршруты interAS передаются протоколу RIP.
aut-num: AS1
import: from AS2 accept AS2
export: protocol BGP4 into RIP to AS1 announce ANY
В следующем примере, AS1 воспринимает маршруты AS2, включая любые адресные префиксы больше префиксов маршрутов AS2, но не передает эти дополнительные префиксы протоколу OSPF.
aut-num: AS1
import: from AS2 accept AS2^+
export: protocol BGP4 into OSPF to AS1 announce AS2
В следующем примере, AS1 передает свои статические маршруты (маршруты, которые являются членами набора AS1:RS-STATIC-ROUTES) маршрутному протоколу interAS и дважды добавляет AS1 к своему маршрутному набору AS.
aut-num: AS1
В следующем примере, AS1 воспринимает другой набор уникастных маршрутов для реверсивной мультикастной переадресации из AS2:
aut-num: AS1
import: from AS2 accept AS2
import: protocol IDMR
from AS2 accept AS2:RS-RPF-ROUTES
6.4. Разрешение неопределенности
Допускается, чтобы один и тот же обмен (peering) был описан в более чем одной спецификации партнерства в пределах выражения политики. Например:
aut-num: AS1
Это не ошибка, хотя такая запись определенно не желательна. Чтобы убрать неопределенность, используется действие (action), соответствующее первой спецификации партнерства. То есть маршруты воспринимаются с предпочтением, равным 2. Это правило называется правилом порядка спецификаций.
Рассмотрим пример:
aut-num: AS1
где обе спецификации партнерства перекрывают маршруты 1.1.1.1-1.1.1.2, хотя вторая спецификация более специфична. Здесь также используется правило порядка спецификаций, выполняется только действие (action) "pref = 2". В действительности, вторая пара пиринговых действий бесполезна, так как первая пара пиринговых действий покрывает действие второй. Если требуется политика, при которой эти маршруты воспринимались данным пирингом с предпочтением 1 и с предпочтением 2 для всех остальных пирингов, пользователь должен специфицировать следующее:
aut-num: AS1
aut-num: AS1
import: from AS2 action pref = 2; accept AS4
import: from AS2 action pref = 1; accept AS4
В этом случае, также используется правило порядка спецификаций. То есть маршруты AS4 от AS2 воспринимаются с предпочтением 2. Если фильтры перекрываются, но не тождественны:
aut-num: AS1
import: from AS2 action pref = 2; accept AS4
import: from AS2 action pref = 1; accept AS4 OR AS5
маршруты AS4 воспринимаются от AS2 с предпочтением 2 и, тем не менее, маршруты AS5 также воспринимаются, но с предпочтением 1.
Ниже приведено общее правило порядка спецификации для разработчиков программ RPSL. Рассмотрим два расширения политики:
aut-num: AS1
import: from peerings-1 action action-1 accept filter-1
import: from peerings-2 action action-2 accept filter-2
Вышеприведенные выражения политики эквивалентны следующим трем выражениям, где нет неопределенности:
aut-num: AS1
import: from peerings-1 action action-1 accept filter-1
import: from peerings-3 action action-2 accept filter-2 AND NOT filter-1
import: from peerings-4 action action-2 accept filter-2
где peerings-3 – это набор маршрутов, которые покрываются как peerings-1, так и peerings-2, а peerings-4 – набор маршрутов, которые покрываются peerings-2, но не покрываются peerings-1 ("filter-2 AND NOT filter-1" соответствует маршрутам, которые согласуются с filter-2, но не с filter-1).
Пример:
aut-num: AS1
Рассмотрим два пиринга с AS2, 1.1.1.1-1.1.1.2 и 9.9.9.1- 2.2.2.2. Оба выражения политики покрывают 1.1.1.1-1.1.1.2. Для этого пиринга, маршрут 128.9.0.0/16 воспринимается с предпочтением 2, а маршрут 75.0.0.0/8 воспринимается с предпочтением 1. Пиринг 9.9.9.1-2.2.2.2 покрывается только вторым выражением политики. Следовательно, как маршрут 128.9.0.0/16 так и маршрут 75.0.0.0/8 воспринимаются с предпочтением 1 пирингом 9.9.9.1-2.2.2.2. Заметим, что аналогичное правило разрешения неопределенности применимо к выражениям политики по умолчанию и экспортной политики (рассылка маршрутной информации).
6.5. Атрибут default. Спецификация политики по умолчанию
Политика маршрутизации по умолчанию специфицируется с помощью атрибута default. Атрибут default имеет следующий синтаксис:
default: to <peering> [action <action>] [networks <filter>]
Спецификации <action> и <filter> являются опционными. Семантика выглядит следующим образом: Спецификация <peering> указывает на AS (и маршрутизатор, если он имеется) по умолчанию; спецификация <action>, если присутствует, указывает на различные атрибуты конфигурации по умолчанию. Например, относительное предпочтение, если определено несколько маршрутов по умолчанию; а спецификация <filter>, если имеется, является фильтром политики. Маршрутизатор использует политику по умолчанию, если он получает от партнера маршруты, которые удовлетворяют требованиям фильтра <filter>.
В следующем примере, AS1 маршрутизируется по умолчанию через AS2.
aut-num: AS1
default: to AS2
В следующем примере, марштутизатор 1.1.1.1 в AS1 маршрутизуется по умолчанию через 1.1.1.2 в AS2.
aut-num: AS1
default: to AS2 1.1.1.2 at 1.1.1.1
В следующем примере, AS1 маршрутизуется по умолчанию через AS2 и AS3, но предпочитает AS2, а не AS3.
aut-num: AS1
default: to AS2 action pref = 1;
default: to AS3 action pref = 2;
В следующем примере, AS1 маршрутизуется по умолчанию через AS2 и использует 128.9.0.0/16 в качестве сети по умолчанию.
aut-num: AS1
default: to AS2 networks { 128.9.0.0/16 }
6.6. Спецификация структурированной политики
Политики импорта и экспорта (рассылки и приема маршрутной информации) могут быть структурированы. Применение структурированной политики рекомендуется для продвинутых пользователей RPSL. Синтаксис спецификации структурированной политики выглядит следующим образом:
| <import-factor> ::= | from <peering-1> [action <action-1>] | |
| . . . | ||
| from <peering-N> [action <action-N>] | ||
| accept <filter>; | ||
| <import-term> ::= | <import-factor> | | |
| LEFT-BRACE | ||
| <import-factor> | ||
| . . . | ||
| <import-factor> | ||
| RIGHT-BRACE | ||
| <import-expression> ::= | <import-term> | | |
| <import-term> EXCEPT <import-expression> | | | |
| <import-term> REFINE <import-expression> | ||
| import: | [protocol <protocol1>] [into <protocol2>] | |
| <import-expression> |
Семантика для оператора except имеет вид. Результатом операции исключения является еще один член <import-term>. Результирующий набор политики содержит описание политики правой стороны, но его фильтры модифицированы так, что остаются только маршруты, соответствующие левой стороне. Политика левой стороны, в конце концов, включается, а ее фильтры модифицируются так, чтобы исключить маршруты, соответствующие левой стороне. Заметим, что фильтры модифицированы во время этого процесса, но действия скопированы один к одному. При нескольких уровнях вложения операции (принять или уточнить) выполняются справа налево.
Рассмотрим следующий пример:
| import: | from AS1 action pref = 1; | accept as-foo; |
| except | { | |
| from AS2 action pref = 2; | accept AS226; | |
| except | { | |
| from AS3 action pref = 3; | accept {128.9.0.0/16}; |
}
где маршрут 128.9.0.0/16 порождается AS226, а AS226 является членом набора AS as-foo. В этом примере, маршрут 128.9.0.0/16 воспринят от AS3, любой другой маршрут (не 128.9.0.0/16) порожденный AS226 воспринимается от AS2, и любые другие маршруты AS из as-foo получены от AS1. Можно прийти к тому же заключению, используя алгебраические выкладки, определенные выше. Рассмотрим спецификацию внутреннего исключения:
from AS2 action pref = 2; accept AS226;
except { from AS3 action pref = 3; accept {128.9.0.0/16};}
Эквивалентно
{ from AS3 action pref = 3; accept AS226 AND {128.9.0.0/16};
from AS2 action pref = 2; accept AS226 AND NOT {128.9.0.0/16};}
Следовательно, исходное выражение эквивалентно:
| import: | from AS1 action pref = 1; accept as-foo; |
| except { from AS3 action pref = 3; accept AS226 AND {128.9.0.0/16}; | |
| from AS2 action pref = 2; accept AS226 AND NOT {128.9.0.0/16}; } |
Так как AS226 находится в as-foo и 128.9.0.0/16 заключен в AS226, выражение упрощается:
В случае оператора refine, результирующий набор формируется с помощью декартова произведения для двух сторон следующим образом. Для каждой политики l левой стороны и для каждой политики r правой стороны, пиринг результирующей политики является пересечением множеств пирингов r и l. Фильтр результирующей политики соответствует пересечению фильтров l и r. Действие результирующей политики есть действие l, за которым следует действие r. Если общие пиринги отсутствуют, или если множество пересечения фильтров является пустым, результирующая политика не формируется. Рассмотрим следующий пример:
| import: | { from AS-ANY action pref = 1; accept community(3560:10); |
| from AS-ANY action pref = 2; accept community(3560:20); | |
| } refine { from AS1 accept AS1; | |
| from AS2 accept AS2; | |
| from AS3 accept AS3; } |
| import: | { |
| from AS1 action pref = 1; accept community(3560:10) AND AS1; | |
| from AS1 action pref = 2; accept community(3560:20) AND AS1; | |
| from AS2 action pref = 1; accept community(3560:10) AND AS2; | |
| from AS2 action pref = 2; accept community(3560:20) AND AS2; | |
| from AS3 action pref = 1; accept community(3560:10) AND AS3; | |
| from AS3 action pref = 2; accept community(3560:20) AND AS3; } |
/p> Рассмотрим следующий пример:
| import: | { |
| from AS-ANY action med = 0; accept {0.0.0.0/0^0-18}; | |
| } refine { | |
| from AS1 at 1.1.1.1 action pref = 1; accept AS1; | |
| from AS1 action pref = 2; accept AS1; } |
| import: | { |
| from AS1 at 1.1.1.1 action med=0; pref=1; | |
| accept {0.0.0.0/0^0-18} AND AS1; | |
| from AS1 action med=0; pref=2; | |
| accept {0.0.0.0/0^0-18} AND AS1; } |
7. Класс dictionary
Класс dictionary обеспечивает расширяемость для RPSL. Объекты словаря определяют атрибуты маршрутной политики, типы и маршрутные протоколы. Атрибуты маршрутной политики, впредь называемые rp-атрибутами, могут соответствовать действительным протокольным атрибутам, таким как атрибуты пути BGP (напр., community, dpa и AS-path), или они могут соответствовать особенностям маршрутизатора (напр., гашение осцилляций маршрутов в BGP). Когда вводятся новые протоколы, новые протокольные атрибуты, или новые возможности миршрутизатора, объект словаря актуализуется, с тем чтобы ввести соответствующее описание rp-атрибута или протокола.
rp-атрибут относится к абстрактному классу, то есть представление данных не доступно. Вместо этого, доступ к ним определяется методом доступа. Например, rp-атрибут для BGP-атрибута AS-path называется aspath, и он имеет метод доступа, называемый prepend,
который вставляет дополнительные номера AS в атрибуты AS-path. Методы доступа могут воспринимать аргументы. Аргументы строго типофицируются. Например, метод prepend воспринимает номера AS в качестве аргументов.
Раз rp-аргумент определен в словаре, он может использоваться для описания фильтров и действий. Необходимы средства анализа политики, чтобы предоставить объект словаря и распознать вновь определенные rp-атрибуты, типы и протоколы. Средства анализа могут даже загружать программу для выполнения соответствующих операций, используя механизмы помимо RPSL.
Ниже рассматривается синтаксис и семантика класса dictionary. Это описание не существенно для понимания объектов dictionary (но оно существенно для их создания).
Атрибуты класса dictionary представлены на рис. .24. Атрибут dictionary является именем объекта словаря, подчиняющимся правилам присвоения имен в RPSL. Может существовать много объектов словаря, однако имеется только один стандартный объект "RPSL". Все средства используют этот словарь по умолчанию.
Атрибут |
Значение |
Тип |
| Dictionary | <object-name> | обязательный, однозначный, ключ класса |
| rp-attribute | См. описание в тексте | опционный, многозначный |
| typedef | См. описание в тексте | опционный, многозначный |
| protocol | См. описание в тексте | опционный, многозначный |
Атрибут rp-attribute имеет следующий синтаксис:
| rp-attribute: | |
| <method-1>(<type-1-1>, ..., <type-1-N1> [, "..."]) | |
| ... | |
| <method-M>(<type-M-1>, ..., <type-M-NM> [, "..."]) |
Рис. .25. Операторы
Атрибут rp- attribute может иметь много методов, определенных для него. Некоторые из методов могут даже иметь то же самое имя, в этом случае их аргументы должны относиться к другому типу. Если список аргументов завершается "...", метод может воспринять переменное число аргументов. В этом случае, действительные аргументы после N-го аргумента имеют тип <type-N>.
Аргумента строго типофицированы. <type> в RPSL является либо предопределенным, типом union, списочным, либо определенным в словаре. Предопределенные типы перечислены на рис. .26.
| integer[lower, upper] | ipv4_address |
| real[lower, upper] | address_prefix |
| enum[name, name, ...] | address_prefix_range |
| string | dns_name |
| Boolean | filter |
| rpsl_word | as_set_name |
| free_text | route_set_name |
| rtr_set_name | |
| as_number | filter_set_name |
| peering_set_name |
За целочисленными и действительными предопределенными типами могут следовать младшие или старшие секции, которые позволяют специфицировать набор допустимых значений аргумента. Спецификация диапазона является опционной. Для представления целых действительных значений и символьных строк используется нотация языка Си (ANSI). За типом enum следует список имен RPSL, которые являются значениями данного типа. Булев тип может принимать значение true или false. as_number, ipv4_address, address_prefix и dns_name типы имеют те же значения, что типы фильтра (раздел 2) и фильтры политики (раздел 6). Значения фильтра следует помещать в скобки.
Синтаксис типа union имеет следующий вид:
union <type-1>, ... , <type-N>
где <type-i> является типом RPSL. Тип union может иметь тип в интервале от <type-1> до <type-N>.
Синтаксис списочного типа приведен ниже:
list [<min_elems>:<max_elems>] of <type>
В этом случае элементы списка представляют <type>, а список содержит по крайней мере <min_elems> элементов, но не больше чем <max_elems>>. Размер спецификации является опционным. Если спецификация отсутствует, то никаких регламентаций на число элементов в списке не накладывается. Значение списочного типа представляется в виде последовательности элементов, разделенных символом запятой "," и заключенных в фигурные скобки "{" и "}". Атрибут typedef в словаре определяет именованный тип следующим образом:
typedef: <name> <type>
где <name> - имя типа <type>. Атрибут typedef является особенно полезным, когда тип не является предопределенным (напр., список объединений [union], список списков и т.д.). Атрибут класса словаря protocol определяет протокол и набор параметров пиринга для этого протокола, которые используются в классе inet-rtr (раздел 9). Его синтаксис представлен ниже:
| protocol: | <name> |
| MANDATORY | OPTIONAL <parameter-1>( | |
| <type-1-N1> [,"..."]) | |
| ... | |
| MANDATORY | OPTIONAL <parameter-M>( | <type-M-1>,..., |
| <type-M-NM> [,"..."]) |
7.1. Исходный словарь RPSL, пример действий политики и фильтры
dictionary: RPSL
rp-attribute: # меньшие значения соответствуют более высокому предпочтению pref
rp-attribute: # атрибут BGP multi_exit_discriminator
rp-attribute: # атрибут предпочтения места назначения BGP (dpa)
rp-attribute: # атрибут BGP aspath
typedef: # значение community в RPSL равно:
typedef: # список значений community { 40, no_export, 3561:70 }
rp-attribute: # атрибут BGP community
protocol: OSPF
protocol: RIP
protocol: IGRP
protocol: IS-IS
protocol: STATIC
protocol: RIPng
protocol: DVMRP
protocol: PIM-DM
protocol: PIM-SM
protocol: CBT
protocol: MOSPF
Рис. .27. Словарь RPSL
На рис. .27 показан исходный словарь RPSL. Он имеет семь rp-атрибутов: pref для присвоения локального предпочтения воспринимаемым маршрутам; med для присвоения значения атрибуту MULTI_EXIT_DISCRIMINATOR BGP; dpa для присвоения значения атрибуту DPA BGP; aspath для присвоения значения атрибуту AS_PATH BGP; community для присвоения или проверки значения атрибута community BGP; next-hop для назначения следующих маршрутизаторов в случае статических маршрутов; cost для назначения цены статических маршрутов. Словарь определяет два типа: community_elm и community_list. Тип community_elm является либо 4-байтовым целым числом без знака, либо одним из ключевых слов Интернет, no_export или no_advertise. Целое число может быть специфицировано с помощью двух 2-байтовых чисел, разделенных двоеточием ":", чтобы разделить пространство кода community так, чтобы провайдер мог использовать номер AS первых двух байт, и определить семантику выбора последних двух байт.
Исходный словарь (рис. .27) определяет только опции для BGP (Border Gateway Protocol): asno и flap_damp. Обязательная опция asno является номером AS партнера-маршрутизатора. Опция flap_damp инструктирует маршрутизатор гасить осцилляции маршрутов [21], при импортировании маршрутов от маршрутизатора-партнера. Она может быть специфицирована с или без параметров. Если параметры опущены, принимаются значения по умолчанию:
flap_damp(1000, 2000, 750, 900, 900, 20000)
То есть, назначается штраф 1000 для каждого переключения маршрута, маршрут закрывается, когда штраф достигает 2000. Штраф снижается вдвое после 15 минут стабильного режима вне зависимости оттого открыт путь или нет. Закрытый маршрут используется вновь, когда штраф падает ниже 750. Максимальный штраф маршрута может достигать 20,000 (т.e. максимальное время закрытия маршрута после стабилизации ситуации составляет около 75 минут).
Действия политики и фильтров, использующих rp-атрибуты
Синтаксис действия политики или фильтра, использующего rp-атрибут x выглядит следующим образом:
x.method(arguments)
x "op" argument
где method представляет собой метод, а "op" – метод оператора rp-атрибута x. Если метод оператора используется при спецификации составного фильтра политики, он определяется раньше, чем операторы составных фильтров политики (т.e. AND, OR, NOT или оператор). rp-атрибуту pref может быть присвоено положительное целое число следующим образом:
pref = 10;
rp-атрибуту med может быть присвоено положительное целое число или слово "igp_cost" следующим образом:
med = 0;
med = igp_cost;
rp-атрибуту dpa может быть присвоено положительное целое число следующим образом:
dpa = 100;
Значением атрибута community BGP является список, который состоит из 4-байтовых целых чисел, каждое их которых характеризует "community". Следующие примеры демонстрируют, как добавлять новые значения community к этому rp-атрибуту:
community .= { 100 };
community .= { NO_EXPORT };
community .= { 3561:10 };
В последнем случае, 4- байтовое целое число, сформированное так, что наиболее значимые два байта равны 3561, а менее значимые два байта равны 10. Следующие примеры показывают, как удалять элементы из rp-атрибута community:
community.delete(100, NO_EXPORT, 3561:10);
Фильтры, которые используют rp-атрибут community могут быть определены, как это показано в следующем примере:
community.contains(100, NO_EXPORT, 3561:10);
community(100, NO_EXPORT, 3561:10); # shortcut
rp-атрибуту community может быть присвоено значение, соответствующее списку community следующим образом:
community = {100, NO_EXPORT, 3561:10, 200};
community = {};
В этом первом случае, rp-атрибут community содержит значения (communities) 100, NO_EXPORT, 3561:10 и 200. В последнем случае, rp-атрибут community обнулен. rp-атрибут community может быть сравнен со списком communities следующим образом:
community == {100, NO_EXPORT, 3561:10, 200}; # точное соответствие
Чтобы повлиять на выбор маршрута, rp-атрибут BGP as_path может быть сделан длиннее путем предварительной прописи номеров AS следующим образом:
aspath.prepend(AS1);
aspath.prepend(AS1, AS1, AS1);
Следующие примеры некорректны:
| med = -50; | # -50 лежит вне диапазона |
| med = igp; | # igp не является одним из значений enum |
| med.assign(10); | # заданный метод не определен |
| community.append(AS3561:20); | # первый аргумент должен быть равен 3561. На рис. .28 показан более продвинутый пример, использующий rp-атрибут community. В этом примере, AS3561 базирует свое предпочтение при выборе маршрута на атрибуте community. Другие AS могут апосредовано влиять на выбор маршрутов AS3561 путем включения соответствующих значений communities в их оповещения о маршрутах. |
as-set: AS3561:AS-PEERS
members: AS2, AS3
aut-num: AS3561
Рис. .28. Пример политики с использованием rp-атрибута community.
8. Класс Advanced route
8.1. Спецификация агрегатных маршрутов
Атрибуты components, aggr-bndry, aggr-mtd, export-comps, inject и holes используются для спецификации агрегатных маршрутов [11]. Объект route специфицирует агрегатный маршрут, если специфицирован любой из этих атрибутов за исключением inject. Атрибут origin для агрегатного маршрута производит объединение маршрутов на базе AS. Здесь термин "aggregate" используется в отношении генерируемого маршрута, термин "component" относится к маршрутам, использованным для формирования атрибута объединения (aggregate) path, а термин "more specifics" относится к любому маршруту, который более специфичен для объединения, вне зависимости от того, используется ли он при формировании атрибутов path. Атрибут components определяет, какой из составляющих маршрутов используется для формирования объединения. Его синтаксис выглядит следующим образом:
components: [ATOMIC] [[<filter>] [protocol <protocol> <filter> ...]]
где <protocol> представляет собой имя протокола маршрутизации, такого как BGP4, OSPF или RIP (допустимые значения определяются словарем), а <filter> - выражение политики. Маршруты, соотносятся с одним из этих фильтров и получены с помощью соответствующего протокола, используются для формирования объединения (aggregate). Если <protocol> опущен, по умолчанию предполагается любой протокол. <filter> неявно содержит термин "AND" с более специфическими префиксами объединения, так что выбираются только маршруты компоненты. Если используется ключевое слово ATOMIC, объединение выполнено на уровне атомов [11]. Если атрибут components пропущен, используются все более специфичные префиксы без ключевого слова ATOMIC.
route: 128.8.0.0/15
origin: AS1
components: <^AS2>
route: 128.8.0.0/15
origin: AS1
Рис. .29. Два объекта агрегатных маршрутов.
На рис. 29 показаны два объекта route. В первом примере объединяются более специфические префиксы 128.8.0.0/15 с проходами, начинающимися с AS2. Во втором примере агрегатированы некоторые маршруты, полученные от BGP и некоторые маршруты, полученные из OSPF.
Атрибут aggr-bndry является AS-выражением для номеров и наборов (см. раздел 5.6). Результат определяет набор AS, который задает границу объединения (aggregation). Если атрибут aggr-bndry опущен, исходная AS является единственной границей объединения. За пределами границы объединения экспортируется только это объединение, а более специфичные префиксы передаваться не могут. Однако в пределах границы, более специфичные префиксы также могут пересылаться.
Атрибут aggr-mtd определяет то, как формируется объединение. Его синтаксис показан ниже:
| aggr-mtd: | inbound |
| | outbound [<as-expression>] |
| route: 128.8.0.0/15 | route: 128.8.0.0/15 |
| origin: AS1 | origin: AS2 |
| components: {128.8.0.0/15^-} | components: {128.8.0.0/15^-} |
| aggr-bndry: AS1 OR AS2 | aggr-bndry: AS1 OR AS2 |
| aggr-mtd: outbound AS-ANY | aggr-mtd: outbound AS-ANY |
/p> Рис. .30. Пример экспортного объединения большого числа AS.
На рис. 30 показан пример экспортного объединения. В этом примере, AS1 и AS2 представляют собой объединение и оповещают окружающий мир только о менее специфических префиксах 128.8.0.0/15, обмениваясь друг с другом более специфическими префиксами. Эта форма объединения полезна, когда некоторые компоненты находятся внутри AS1, а некоторые в AS2.
Когда агрегатируется набор маршрутов, предполагается экспортировать только агрегатные маршруты и блокировать экспорт более специфичных префиксов вне границы объединения, чтобы удовлетворить определенной политике и топологическим ограничениям (напр., компонента со многими интерфейсами (multi-homed)) часто необходимо экспортировать некоторые компоненты. Атрибут export-comps эквивалентен фильтру RPSL, который соответствует более специфичным префиксам. Если этот атрибут опущен, более специфические префиксы не экспортируются за пределы границы объединения. Заметим, что, фильтр export-comps содержит неявный оператор "AND" по отношению более специфичным префиксам объединения.
На рис. 31 показан пример экспортного объединения. В этом примере, более специфические префиксы 128.8.8.0/24 экспортируются из AS1 в дополнение к объединению. Это полезно, когда 128.8.8.0/24 является многопортовым узлом, связанным с другими AS.
| route: | 128.8.0.0/15 |
| origin: | AS1 |
| components: | {128.8.0.0/15^-} |
| aggr-mtd: | outbound AS-ANY |
| export-comps: | {128.8.8.0/24} |
Атрибут inject определяет, какие маршрутизаторы выполняют объединение, и когда они это делают. Синтаксис атрибута показан ниже:
| inject: | [at <router-expression>] ... |
| [action <action>] | |
| [upon <condition>] |
Все маршрутизаторы в <router-expression> и в агрегаторе (объединении) AS выполняют агрегацию. Если <router-expression> не специфицировано, все маршрутизаторы внутри агрегатора AS выполняют агрегацию. Спецификация <action> может установить атрибуты path объединения (aggregate), например, определить предпочтения для объединения.
Так как условие является булевым выражением, объединение создается, если и только если это условие истинно. <condition> - булево выражение, использующее логические операторы AND и OR (т.e. оператор NOT не разрешен):
HAVE-COMPONENTS { список префиксов }
EXCLUDE { список префиксов }
STATIC
Список префиксов в HAVE-COMPONENTS может состоять из более специфических префиксов объединения. Список может также включать диапазоны префиксов (т.e. использование операторов ^-, ^+, ^n, и ^n-m). В этом случае, по крайней мере, один префикс из каждого диапазона префиксов должен присутствовать в каждой маршрутной таблице, для того чтобы условие было выполнено. Список префиксов в EXCLUDE может быть произвольным. Условие выполняется, когда ни один из перечисленных префиксов не содержится в маршрутной таблице. Список может содержать диапазоны префиксов, а ни один префикс из этого диапазона не должен присутствовать в маршрутной таблице. Ключевое слово static всегда предполагается равным true.
| route: | 128.8.0.0/15 |
| origin: | AS1 |
| components: | {128.8.0.0/15^-} |
| aggr-mtd: | outbound AS-ANY |
| inject: | at 1.1.1.1 action dpa = 100; |
| inject: | at 1.1.1.2 action dpa = 110; |
| route: | 128.8.0.0/15 |
| origin: | AS1 |
| components: | {128.8.0.0/15^-} |
| aggr-mtd: | outbound AS-ANY |
| inject: | upon HAVE-COMPONENTS {128.8.0.0/16, 128.9.0.0/16} |
| holes: | 128.8.8.0/24 |
На рис. 32 показаны два примера. В первом случае, объединение вводится в два маршрутизатора, каждый из которых устанавливает атрибут прохода dpa по-разному. Во втором случае, объединение формируется только если в маршрутной таблице присутствуют как 128.8.0.0/16 так и 128.9.0.0/16, в отличие от первого случая, когда присутствия лишь одного из них достаточно для ввода (injection).
Атрибут holes перечисляет компоненты адресных префиксов, которые не достижимы через агрегатный маршрут (возможно, что часть адресного пространства не распределена). Атрибут holes полезен для диагностических целей. На рис. .32, второй пример имеет дырку, в частности 128.8.8.0/24. Это может быть связано с тем, что клиент менял провайдера и брал для этой цели эту часть адресного пространства.
8.1.1. Взаимодействие с политикой в классе aut-num
О сформированном объединении другие AS оповещаются только в случае, когда экспортная политика AS позволяет передавать объединения маршрутов. Когда объединение сформировано, более специфические префиксы запрещены для экспорта за исключением AS в aggr-bndry и компонент в export-comps.
Если объединение не сформировано, тогда более специфические префиксы объединения могут экспортироваться другим AS, но только если экспортная политика AS допускает это. Другими словами прежде чем маршрут (объединение) будет экспортировано, производится двойная фильтрация, один отбор основан на маршрутных объектах, а другой –на экспортной политике AS.
| route: | 128.8.0.0/16 |
| origin: | AS1 |
| route: | 128.9.0.0/16 |
| origin: | AS1 |
| route: | 128.8.0.0/15 |
| origin: | AS1 |
| aggr-bndry: | AS1 or AS2 or AS3 |
| aggr-mtd: | outbound AS3 or AS4 or AS5 |
| components: | {128.8.0.0/16, 128.9.0.0/16} |
| inject: | upon HAVE-COMPONENTS {128.9.0.0/16, 128.8.0.0/16} |
| aut-num: | AS1 |
| export: | to AS2 announce AS1 |
| export: | to AS3 announce AS1 and not {128.9.0.0/16} |
| export: | to AS4 announce AS1 |
| export: | to AS5 announce AS1 |
| export: | to AS6 announce AS1 |
На рис. 33 показан пример взаимодействия. При рассмотрении маршрутных объектов следует произвести обмен более специфическими префиксами 128.8.0.0/16 и 128.9.0.0/16 между AS1, AS2 и AS3 (граница объединения).
Экспортное объединение выполнено для AS4 и AS5, но не для AS3, так как AS3 находится на границе объединения. Объект aut-num допускает экспортирование обоих компонентов в AS2, и только компонент 128.8.0.0/16 в AS3. Объединение может быть сформировано, если присутствуют все компоненты. В данном случае только об этом объединении оповещены AS4 и AS5. Однако, если одна из компонент не доступна, объединение не может быть создано, и любая из доступных компонент или более специфический префикс будет экспортирован в AS4 и AS5. Вне зависимости от того, выполнено объединение или нет, только более специфические префиксы будут экспортированы в AS6.
При выполнении импортного объединения конфигурирующие генераторы могут опускать агрегационные заявления для маршрутизаторов, где импортная политика AS запрещает импортирование более специфических префиксов.
8.1.2. Разрешение неопределенности для перекрывающихся объединений
Когда специфицированы несколько маршрутных объединений и они перекрываются, т.e. один менее специфичен чем другой, тогда сначала определяются более а затем менее специфичные. Когда для партнера осуществляется экспортное объединение (outbound aggregation), объединение и компоненты, перечисленные в атрибуте export-comps, доступны для генерации следующих менее специфичных объединений. Компоненты, которые не специфицированы в атрибуте export-comps, являются недоступными. Маршрут экспортируем в AS, если это наименее специфическое объединение, экспортируемое в эту автономную систему или маршрут упомянут в атрибуте export-comps. Заметим, что это рекурсивное определение.
Рис. .34. Перекрывающиеся объединения.
На рис. 34, AS1 вместе с AS2 объединяют 128.8.0.0/16 и 128.9.0.0/16 в 128.8.0.0/15. Вместе с AS3, AS1 объединяет 128.10.0.0/16 и 128.11.0.0/16 в 128.10.0.0/15. Но все вместе они объединяют эти четыре маршрута в 128.8.0.0/14. Предполагая все четыре компоненты доступными, маршрутизатор в AS1 для внешней AS, скажем AS4, сначала сгенерирует 128.8.0.0/15 и 128.10.0.0/15. Это сделает 128.8.0.0/15, 128.10.0.0/15 и его исключение 128.11.0.0/16 доступным для генерации 128.8.0.0/14. Маршрутизатор из этих трех маршрутов будет затем генерировать 128.8.0.0/14. Следовательно, для AS4, 128.8.0.0/14 и его исключение, 128.10.0.0/15 и его исключение 128.11.0.0/16 станут экспортируемыми.
Для AS2, маршрутизатор в AS1 сгенерирует только 128.10.0.0/15. Следовательно, 128.10.0.0/15 и его исключение 128.11.0.0/ 16 станут экспортируемыми. Заметим, что 128.8.0.0/16 и 128.9.0.0/16 являются также экспортируемыми, так как они не участвуют в объединении, допускающем экспорт в AS2. Аналогично, для AS3, маршрутизатор в AS1 будет генерировать только 128.8.0.0/15. В этом случае 128.8.0.0/15, 128.10.0.0/16, 128.11.0.0/16 могут экспортироваться.
8.2. Спецификация статических маршрутов
Атрибут inject может служить для спецификации статических маршрутов, используя "upon static" в качестве условия:
| inject: | [at <routerexpression>] ... |
| [action <action>] | |
| upon static |
В следующем примере, маршрутизатор 1.1.1.1 вводит маршрут 128.7.0.0/16. Маршрутизаторы следующего шага (в этом примере, имеется два маршрутизатора “следующего шага”) для этого маршрута имеют адреса 1.1.1.2 и 1.1.1.3, а маршрут имеет цену 10 для 1.1.1.2 и 20 для 1.1.1.3.
route: 128.7.0.0/16
origin: AS1
inject: at 1.1.1.1 action next-hop = 1.1.1.2; cost = 10; upon static
inject: at 1.1.1.1 action next-hop = 1.1.1.3; cost = 20; upon static
9. Класс inet-rtr
Маршрутизаторы специфицируются с использованием класса inet-rtr. Атрибуты класса inet-rtr показаны на рис. 35. Атрибут inet-rtr представляет собой допустимое имя DNS описанного маршрутизатора. Каждый атрибут alias, если он присутствует, является каноническим именем DNS для маршрутизатора. Атрибут local-as специфицирует номер AS, которой управляет данный маршрутизатор.
Атрибут |
Значение |
Тип |
| inet-rtr | <dns-name> | обязательный, однозначный, ключ класса |
| alias | <dns-name> | опционный, многозначный |
| local-as | <as-number> | обязательный, однозначный |
| ifaddr | См. описание в тексте | обязательный, многозначный |
| peer | См. описание в тексте | опционный, многозначный |
| member-of | список <rtr-set-names> | опционный, многозначный |
/p> Рис. .35. Атрибуты класса inet-rtr
Значение атрибута ifaddr имеет следующий синтаксис:
<ipv4-address> masklen <integer>> [action <action>]
IP-адрес и длина маски являются обязательными для каждого интерфейса. Опционно можно специфицировать действие (action), которое позволяет установить другие параметры этого интерфейса.
На рис. .36 предложен пример объекта inet-rtr. Имя маршрутизатора "amsterdam.ripe.net". "amsterdam1.ripe.net" является каноническим именем для маршрутизатора. Маршрутизатор соединен с четырьмя сетями. Их IP-адреса и длины масок специфицированы в атрибутах ifaddr.
inet-rtr: Amsterdam.ripe.net
alias: amsterdam1.ripe.net
local-as: AS3333
ifaddr: 192.87.45.190 masklen 24
ifaddr: 192.87.4.28 masklen 24
ifaddr: 193.0.0.222 masklen 27
ifaddr: 193.0.0.158 masklen 27
peer: BGP4 192.87.45.195 asno(AS3334), flap_damp()
Рис. .36. Объекты inet-rtr
Каждый атрибут peer, если он имеется, специфицирует протокольный пиринг с другим маршрутизатором. Значение атрибута peer имеет следующий синтаксис:
| <protocol> <ipv4address> | <options> |
| | <protocol> <inet-rtr-name> | <options> |
| | <protocol> <rtr-set-name> | <options> |
| | <protocol> <peering-set-name> | <options> |
Вместо одиночного партнера с помощью форм <rtr-set-name> и <peering-set-name> может быть специфицирована группа партнеров. Если использована форма <peering-set- name>, то включаются только пиринги из соответствующего набора данного маршрутизатора. На рис. .37 показан пример объекта inet-rtr с пиринг-группами.
rtr-set: rtrs-ibgp-peers
members: 1.1.1.1, 2.2.2.2, 3.3.3.3
peering-set: prng-ebgp-peers
peering: AS3334 192.87.45.195
peering: AS3335 192.87.45.196
inet-rtr: Amsterdam.ripe.net
alias: amsterdam1.ripe.net
local-as: AS3333
ifaddr: 192.87.45.190 masklen 24
ifaddr: 192.87.4.28 masklen 24
ifaddr: 193.0.0.222 masklen 27
ifaddr: 193.0.0.158 masklen 27
peer: BGP4 rtrs-ibgp-peers asno(AS3333), flap_damp()
peer: BGP4 prng-ebgp-peers asno(PeerAS), flap_damp()
Рис. .37. Объект inet-rtr с пиринг-группами
10. Расширение RPSL
Практика работы с языками описания маршрутной политики (PRDB [2], RIPE-81 [8], and RIPE-181 [7]) показывает, что язык описания должен быть расширяемым. Новые маршрутные протоколы или новые особенности существующих протоколов могут быть легко описаны, с помощью класса dictionary RPSL. Могут быть добавлены новые классы или новые атрибуты существующих классов.
Класс dictionary является первичным механизмом расширения RPSL. Объекты словаря определяют атрибуты маршрутной политики, типы и протоколы маршрутизации.
Чтобы добавить соответствующее определение rp-атрибута, протокола, или новых особенностей маршрутизатора, вводится модификация словаря RPSL.
Когда изменяется словарь, должна быть обеспечена полная совместимость. Например, в случае демпфирования осцилляций аршрута спецификация параметров делается опционной, когда ISP на данном уровне не требует деталей. Предполагается, что любое средство, базирующееся на RPSL, выполняет по умолчанию определенные действия, встретив атрибуты маршрутной политики, которые не распознаны (напр., выдает предупреждение или просто игнорирует). Следовательно, старые средства демпфирования осцилляций маршрутов, обнаружив неизвестные им параметры спецификации, должны эти параметры игнорировать.
Любой класс может быть расширен путем добавления новых атрибутов. Для обеспечения полной совместимости новые атрибуты не должны противоречить семантике объектов, к которым они добавлены. Любое средство, которое использует IRR, должно быть устроено так, чтобы игнорировать атрибуты, которые оно не понимает.
Введение новых атрибутов рекомендуется, когда у существующего класса появляются новые черты. Например, класс RPSL route расширяет возможности препроцессора RIPE-181 путем введения нескольких новых атрибутов, которые разрешают агрегатирование и спецификации статических маршрутов.
Новые классы могут добавляться к RPSL для записи новых типов данных, характеризующих политику. Так как любое средство запрашивает IRR только о классах, которые ему известны, проблемы совместимости возникнуть просто не может.
Прежде чем добавлять новый класс, следует ответить на вопрос, относится ли информация, содержащаяся в объекте, к новому классу.
Ссылки
| [1] | Internet routing registry. procedures. http://www.ra.net/RADB.tools.docs/, http://www.ripe.net/db/doc.html. |
| [2] | Nsfnet policy routing database (prdb). Maintained by MERIT Network Inc., Ann Arbor, Michigan. Contents available from nic.merit.edu.:/nsfnet/announced.networks /nets.tag.now by anonymous ftp. |
| [3] | Alaettinouglu, C., Bates, T., Gerich, E., Karrenberg, D., Meyer, D., Terpstra, M. and C. Villamizer, "Routing Policy Specification Language (RPSL)", RFC 2280, January 1998. |
| [4] | C. Alaettinouglu, D. Meyer, and J. Schmitz. Application of routing policy specification language (rpsl) on the internet. Work in Progress. |
| [5] | T. Bates. Specifying an `internet router' in the routing registry. Technical Report RIPE-122, RIPE, RIPE NCC, Amsterdam, Netherlands, October 1994. |
| [6] | T. Bates, E. Gerich, L. Joncheray, J-M. Jouanigot, D. Karrenberg, M. Terpstra, and J. Yu. Representation of ip routing policies in a routing registry. Technical Report ripe-181, RIPE, RIPE NCC, Amsterdam, Netherlands, October 1994. |
| [7] | Bates, T., Gerich, E., Joncheray, L., Jouanigot, J-M., Karrenberg, D., Terpstra, M. and J. Yu, " Representation of IP Routing Policies in a Routing Registry", RFC-1786, March 1995. |
| [8] | T. Bates, J-M. Jouanigot, D. Karrenberg, P. Lothberg, and M. Terpstra. Representation of ip routing policies in the ripe database. Technical Report ripe-81, RIPE, RIPE NCC, Amsterdam, Netherlands, February 1993. |
| [9] | Chandra, R., Traina, P. and T. Li, "BGP Communities Attribute", RFC-1997, August 1996. |
| [10] | Crocker, D., "Standard for ARPA Internet Text Messages", STD 11, RFC-822, August 1982. |
| [11] | Fuller, V., Li, T., Yu, J. and K. Varadhan, "Classless Inter-Domain Routing (CIDR): an Address Assignment and Aggregation Strategy", RFC-1519, September 1993. |
| [12] | D. Karrenberg and T. Bates. Description of inter-as networks in the ripe routing registry. Technical Report RIPE-104, RIPE, RIPE NCC, Amsterdam, Netherlands, December 1993. |
| [13] | D. Karrenberg and M. Terpstra. Authorisation and notification of changes in the ripe database. Technical Report ripe-120, RIPE, RIPE NCC, Amsterdam, Netherlands, October 1994. |
| [14] | B. W. Kernighan and D. M. Ritchie. The C Programming Language. Prentice-Hall, 1978. |
| [15] | A. Lord and M. Terpstra. Ripe database template for networks and persons. Technical Report ripe-119, RIPE, RIPE NCC, Amsterdam, Netherlands, October 1994. |
| [16] | A. M. R. Magee. Ripe ncc database documentation. Technical Report RIPE-157, RIPE, RIPE NCC, Amsterdam, Netherlands, May 1997. |
| [17] | Mockapetris, P., "Domain names - concepts and facilities", STD 13, RFC-1034, November 1987. |
| [18] | Y. Rekhter. Inter-domain routing protocol (idrp). Journal of Internetworking Research and Experience, 4:61--80, 1993. |
| [19] | Rekhter Y. and T. Li, "A Border Gateway Protocol 4 (BGP-4)", RFC-1771, March 1995. |
| [20] | C. Villamizar, C. Alaettinouglu, D. Meyer, S. Murphy, and C. Orange. Routing policy system security", Work in Progress. |
| [21] | Villamizar, C., Chandra, R. and R. Govindan, "BGP Route Flap Damping", RFC-2439, November 1998. |
| [22] | J. Zsako, "PGP authentication for ripe database updates", Work in Progress. |
/p>
B. Грамматические правила
Ниже рассмотрены формальные грамматические правила RPSL. Основные типы данных определены в разделе 2. Правила записаны с использованием входного языка грамматического разбора GNU Bison.
//**** базовые атрибуты *********************************************
changed_attribute: ATTR_CHANGED TKN_EMAIL TKN_INT
//**** класс aut-num *************************************************
//// as_expression /////////////////////////////////////////////////////
opt_as_expression: | as_expression
as_expression: as_expression OP_OR as_expression_term | as_expression_term
as_expression_term: as_expression_term OP_AND as_expression_factor
| as_expression_term KEYW_EXCEPT as_expression_factor | as_expression_factor
as_expression_factor: '(' as_expression ')' | as_expression_operand
as_expression_operand: TKN_ASNO | TKN_ASNAME
//// router_expression /////////////////////////////////////////////////
opt_router_expression: | router_expression
opt_router_expression_with_at: | KEYW_AT router_expression
router_expression: router_expression OP_OR router_expression_term | router_expression_term
router_expression_term: router_expression_term OP_AND router_expression_factor
| router_expression_term KEYW_EXCEPT router_expression_factor | router_expression_factor
router_expression_factor: '(' router_expression ')' | router_expression_operand
router_expression_operand: TKN_IPV4 | TKN_DNS | TKN_RTRSNAME
//// пиринг ///////////////////////////////////////////////////////////
peering: as_expression opt_router_expression opt_router_expression_with_at
| TKN_PRNGNAME
//// действие ////////////////////////////////////////////////////////////
opt_action: | KEYW_ACTION action
action: single_action | action single_action
single_action: TKN_RP_ATTR '.' TKN_WORD '(' generic_list ')' ';'
| TKN_RP_ATTR TKN_OPERATOR list_item ';' | TKN_RP_ATTR '(' generic_list ')' ';'
| TKN_RP_ATTR '[' generic_list ']' ';' | ';'
//// фильтр ////////////////////////////////////////////////////////////
filter: filter OP_OR filter_term | filter filter_term %prec OP_OR | filter_term
filter_term : filter_term OP_AND filter_factor | filter_factor
filter_factor : OP_NOT filter_factor | '(' filter ')' | filter_operand
filter_operand: KEYW_ANY | '' | filter_rp_attribute | TKN_FLTRNAME
| filter_prefix
filter_prefix: filter_prefix_operand OP_MS | filter_prefix_operand
filter_prefix_operand: TKN_ASNO | KEYW_PEERAS | TKN_ASNAME | TKN_RSNAME
| '{' opt_filter_prefix_list '}'
opt_filter_prefix_list: | filter_prefix_list
filter_prefix_list: filter_prefix_list_prefix | filter_prefix_list ',' filter_prefix_list_prefix
filter_prefix_list_prefix: TKN_PRFXV4 | TKN_PRFXV4RNG
filter_aspath: filter_aspath '|' filter_aspath_term | filter_aspath_term
filter_aspath_term: filter_aspath_term filter_aspath_closure | filter_aspath_closure
filter_aspath_closure: filter_aspath_closure '*' | filter_aspath_closure '?' | filter_aspath_closure '+'
| filter_aspath_factor
filter_aspath_factor: '^' | '$' | '(' filter_aspath ')' | filter_aspath_no
filter_aspath_no: TKN_ASNO | KEYW_PEERAS | TKN_ASNAME | '.' | '[' filter_aspath_range ']'
| '[' '^' filter_aspath_range ']'
filter_aspath_range: | filter_aspath_range TKN_ASNO | filter_aspath_range KEYW_PEERAS
| filter_aspath_range '.' | filter_aspath_range TKN_ASNO '-' TKN_ASNO
| filter_aspath_range TKN_ASNAME
filter_rp_attribute: TKN_RP_ATTR '.' TKN_WORD '(' generic_list ')'
| TKN_RP_ATTR TKN_OPERATOR list_item | TKN_RP_ATTR '(' generic_list ')'
| TKN_RP_ATTR '[' generic_list ']'
//// пара пиринг-действий ///////////////////////////////////////////////
import_peering_action_list: KEYW_FROM peering opt_action
| import_peering_action_list KEYW_FROM peering opt_action
export_peering_action_list: KEYW_TO peering opt_action
| export_peering_action_list KEYW_TO peering opt_action
//// фактор import/export //////////////////////////////////////////////
import_factor: import_peering_action_list KEYW_ACCEPT filter
import_factor_list: import_factor ';' | import_factor_list import_factor ';'
export_factor: export_peering_action_list KEYW_ANNOUNCE filter
export_factor_list: export_factor ';' | export_factor_list export_factor ';'
//// термин import/export ////////////////////////////////////////////////
import_term: import_factor ';' | '{' import_factor_list '}'
export_term: export_factor ';' | '{' export_factor_list '}'
//// выражение import/export //////////////////////////////////////////
import_expression: import_term | import_term KEYW_REFINE import_expression
| import_term KEYW_EXCEPT import_expression
export_expression: export_term | export_term KEYW_REFINE export_expression
| export_term KEYW_EXCEPT export_expression
//// протокол ///////////////////////////////////////////////////////////
opt_protocol_from: | KEYW_PROTOCOL tkn_word
opt_protocol_into: | KEYW_INTO tkn_word
//**** атрибуты import/export ****************************************
import_attribute: ATTR_IMPORT
| ATTR_IMPORT opt_protocol_from opt_protocol_into import_factor
export_attribute: ATTR_EXPORT
| ATTR_EXPORT opt_protocol_from opt_protocol_into export_factor
opt_default_filter: | KEYW_NETWORKS filter
default_attribute: ATTR_DEFAULT KEYW_TO peering
filter_attribute: ATTR_FILTER filter
peering_attribute: ATTR_PEERING peering
//**** класс inet-rtr **************************************************
ifaddr_attribute: ATTR_IFADDR TKN_IPV4 KEYW_MASKLEN TKN_INT opt_action
//// атрибут peer ////////////////////////////////////////////////////
opt_peer_options: | peer_options
peer_options: peer_option | peer_options ',' peer_option
peer_option: tkn_word '(' generic_list ')'
peer_id: TKN_IPV4 | TKN_DNS | TKN_RTRSNAME | TKN_PRNGNAME
peer_attribute: ATTR_PEER tkn_word peer_id opt_peer_options
//**** класс route *****************************************************
aggr_bndry_attribute: ATTR_AGGR_BNDRY as_expression
aggr_mtd_attribute: ATTR_AGGR_MTD KEYW_INBOUND
| ATTR_AGGR_MTD KEYW_OUTBOUND opt_as_expression
//// атрибут inject //////////////////////////////////////////////////
opt_inject_expression: | KEYW_UPON inject_expression
inject_expression: inject_expression OP_OR inject_expression_term | inject_expression_term
inject_expression_term: inject_expression_term OP_AND inject_expression_factor
| inject_expression_factor
inject_expression_factor: '(' inject_expression ')' | inject_expression_operand
inject_expression_operand: KEYW_STATIC
| KEYW_HAVE_COMPONENTS '{' opt_filter_prefix_list '}'
| KEYW_EXCLUDE '{' opt_filter_prefix_list '}'
inject_attribute: ATTR_INJECT opt_router_expression_with_at opt_action opt_inject_expression
//// атрибут components //////////////////////////////////////////////
opt_atomic: | KEYW_ATOMIC
components_list: | filter | components_list KEYW_PROTOCOL tkn_word filter
components_attribute: ATTR_COMPONENTS opt_atomic components_list
//**** набор маршрутов *****************************************************
opt_rs_members_list: /* пустой список */
| rs_members_list
rs_members_list: rs_member | rs_members_list ',' rs_member
rs_member: TKN_ASNO | TKN_ASNO OP_MS | TKN_ASNAME | TKN_ASNAME OP_MS
| TKN_RSNAME | TKN_RSNAME OP_MS | TKN_PRFXV4 | TKN_PRFXV4RNG
rs_members_attribute: ATTR_RS_MEMBERS opt_rs_members_list
//**** словарь ******************************************************
rpattr_attribute: ATTR_RP_ATTR TKN_WORD methods
| ATTR_RP_ATTR TKN_RP_ATTR methods
methods: method | methods method
method: TKN_WORD '(' ')' | TKN_WORD '(' typedef_type_list ')'
| TKN_WORD '(' typedef_type_list ',' TKN_3DOTS ')'
| KEYW_OPERATOR TKN_OPERATOR '(' typedef_type_list ')'
| KEYW_OPERATOR TKN_OPERATOR '(' typedef_type_list ',' TKN_3DOTS ')'
//// атрибут typedef ////////////////////////////////////////////////
typedef_attribute: ATTR_TYPEDEF TKN_WORD typedef_type
typedef_type_list: typedef_type | typedef_type_list ',' typedef_type
typedef_type: KEYW_UNION typedef_type_list | KEYW_RANGE KEYW_OF typedef_type
| TKN_WORD | TKN_WORD '[' TKN_INT ',' TKN_INT ']'
| TKN_WORD '[' TKN_REAL ',' TKN_REAL ']' | TKN_WORD '[' enum_list ']'
| KEYW_LIST '[' TKN_INT ':' TKN_INT ']' KEYW_OF typedef_type
| KEYW_LIST KEYW_OF typedef_type
enum_list: tkn_word | enum_list ',' tkn_word
//// атрибут protocol ////////////////////////////////////////////////
protocol_attribute: ATTR_PROTOCOL tkn_word protocol_options
protocol_options: | protocol_options protocol_option
protocol_option: KEYW_MANDATORY method | KEYW_OPTIONAL method
//**** Описания лексем *********************************************
//// макросы flex, используемые при определении лексем /////////////////////////////
INT [[:digit:]]+
SINT [+-]?{INT}
REAL [+-]?{INT}?\.{INT}({WS}*E{WS}*[+-]?{INT})?
NAME [[:alpha:]]([[:alnum:]_-]*[[:alnum:]])?
ASNO AS{INT}
ASNAME AS-[[:alnum:]_-]*[[:alnum:]]
RSNAME RS-[[:alnum:]_-]*[[:alnum:]]
RTRSNAME RTRS-[[:alnum:]_-]*[[:alnum:]]
PRNGNAME PRNG-[[:alnum:]_-]*[[:alnum:]]
FLTRNAME FLTR-[[:alnum:]_-]*[[:alnum:]]
IPV4 [0-9]+(\.[0-9]+){3,3}
PRFXV4 {IPV4}\/[0-9]+
PRFXV4RNG {PRFXV4}("^+"|"^-"|"^"{INT}|"^"{INT}-{INT})
ENAMECHAR [^()<>,;:\\\"\.[\] \t\r]
ENAME ({ENAMECHAR}+(\.{ENAMECHAR}+)*\.?)|(\"[^\"@\\\r\n]+\")
DNAME [[:alnum:]_-]+
//// Определения лексем >////////////////////////////////////////////////
TKN_INT {SINT}
TKN_INT {INT}:{INT} if each {INT} is two octets
TKN_INT {INT}.{INT}.{INT}.{INT} if each {INT} is one octet
TKN_REAL {REAL}
TKN_STRING То же самое что и в языке СИ
TKN_IPV4 {IPV4}
TKN_PRFXV4 {PRFXV4}
TKN_PRFXV4RNG {PRFXV4RNG}
TKN_ASNO {ASNO}
TKN_ASNAME (({ASNO}|peeras|{ASNAME}):)*{ASNAME}\
(:({ASNO}|peeras|{ASNAME}))*
TKN_RSNAME (({ASNO}|peeras|{RSNAME}):)*{RSNAME}\
(:({ASNO}|peeras|{RSNAME}))*
TKN_RTRSNAME (({ASNO}|peeras|{RTRSNAME}):)*{RTRSNAME}\
(:({ASNO}|peeras|{RTRSNAME}))*
TKN_PRNGNAME (({ASNO}|peeras|{PRNGNAME}):)*{PRNGNAME}\
(:({ASNO}|peeras|{PRNGNAME}))*
TKN_FLTRNAME (({ASNO}|peeras|{FLTRNAME}):)*{FLTRNAME}\
(:({ASNO}|peeras|{FLTRNAME}))*
TKN_BOOLEAN true|false
TKN_RP_ATTR {NAME} if defined in dictionary
TKN_WORD {NAME}
TKN_DNS {DNAME}("."{DNAME})+
TKN_EMAIL {ENAME}@({DNAME}("."{DNAME})+|{IPV4})
Документ RFC-2280 [3] содержит раннюю версию языка RPSL.
Электронная почта
4.5.10 Электронная почта
Семенов Ю.А. (ГНЦ ИТЭФ)

Электронная почта - наиболее популярный и быстро развивающийся вид общения. Широко используются протоколы электронной почты UUCP (unix-to-unix copy protocol, RFC-976) и SMTP (simple mail transfer protocol; RFC-821, -822, -1351, -1352). Один из протоколов (RFC-822) определяет формат почтовых сообщений, второй (RFC-821) управляет их пересылкой. Имея механизмы промежуточного хранения почты (spooling) и механизмы повышения надежности доставки, протокол smtp базируется на TCP-протоколе в качестве транспортного и допускает использование различных транспортных сред. Он может доставлять сообщения даже в сети, не поддерживающие протоколы TCP/IP. Протокол SMTP обеспечивает как транспортировку сообщений одному получателю, так и размножение нескольких копий сообщения для передачи по разным адресам. Обычно в любом узле Интернет имеется почтовый сервер (MX), который принимает все сообщения и устанавливает их в очередь. Далее производится раскладка сообщений по почтовым ящикам ЭВМ пользователей. Если какая-то ЭВМ не включена, сервер попытается доставить почту позднее (например, через 30 мин). После заданного числа неудачных попыток или по истечении определенного времени (> 4-5 дней) сообщение может быть утрачено. При этом отправитель должен получить уведомление об этом. Над SMTP располагается почтовая служба конкретных вычислительных систем (например, POP3(RFC-1460), IMAP (RFC-2060), sendmail (UNIX), pine, elm (надстройка над sendmail), mush, mh и т.д.). Схема пересылки электронных почтовых сообщений (RFC-821) показана на рис. 4.5.10.1.
Существует множество реализаций электронной почты. Имеются версии практически для всех ЭВМ, операционных систем и сред.
Адреса электронной почты уникальны и однозначно определяют адресата, обладая иногда даже некоторой избыточностью. Символьные адреса электронной почты вполне соответствуют IP-нотации. Электронный почтовый адрес содержит две части, местную и доменную, например, vanja.ivanov@itep.ru (vanya.ivanov - местная). Доменная часть обычно совпадает с символьным IP-именем домена.
Если между отправителем и приемником имеется непосредственная связь, адрес имеет вид имя_пользователя@имя_ЭВМ. Когда приемник находится на ЭВМ, которая не поддерживает SMTP и передача происходит через промежуточный почтовый сервер, то адрес может иметь вид, например, ivanov%имя_удаленной_ЭВМ@имя_сервера (благодаря быстрому развитию Интернет в мире и даже в России такая схема используется сейчас крайне редко). Местная часть адреса определяется пользователем и часто совпадет с его именем или фамилией. Электронный адрес несравненно компактнее традиционных почтовых адресов, которые мы пишем на конвертах. Да и сами возможности электронной почты несравненно богаче почты традиционной. По этой причине можно утверждать, что традиционная почта постепенно будет в ближайшем будущем вытеснена ее электронным аналогом. Схема взаимодействия различных объектов электронной почты показана на рис. 4.5.10.1

Рис. 4.5.10.1. Схема пересылки электронных почтовых сообщений
Со временем можно ожидать, что электронные адреса станут универсальными, но это произойдет не скоро. Для этого нужно чтобы транспорт и другие службы научились работать с такими адресами. Электронные (IP) адреса удобнее для ЭВМ, чем традиционные, а принимая во внимание, что применение вычислительной техники повсеместно, вывод напрашивается сам собой. То что удобно для ЭВМ, удобно в конечном итоге для всех.
Любое почтовое сообщение можно разделить на три части: "конверт" (RFC-821), заголовки (RFC-822) и собственно текст. Конверт используется почтовым сервером и содержит две команды (тексты после двоеточия приведены в качестве примера):
MAIL From: <semenov@cl.itep.ru>
RCPT To: <king_penguin@antarctic.edu>
Существует девять полей заголовка, используемые почтовой программой пользователя: Received, From, To, Date, Subject, Message-Id, X-Phone, X-Mailer, Reply-To. Каждое из этих полей содержит имя, за которым после двоеточия следует его значение. Документ RFC-822 определяет формат и интерпретацию полей заголовка. Заголовки, начинающиеся с X- являются полями, определяемые пользователем.
При вызове почты ( командой mail или mailx) на экране будет распечатан служебный текст, который зависит от конкретной реализации mail, но практически непременным атрибутом любой версии будет являться полное число полученных вами почтовых сообщений (если таковые были). Это могут быть и сообщения, оставленные вами там после предшествующего чтения почты. Непрочитанные вами сообщения так или иначе помечаются (например, символом U на левом поле строки-описания сообщения или N для новых). Далее следует аннотация сообщения, по одной строке на сообщение. Аннотация обычно содержит номер сообщения (нумерация всегда начинается с 1), имя и адрес отправителя, дата и время отправки. После этого следуют (в некоторых реализациях) два числа, разделенных косой чертой ("/"). Они характеризуют размер сообщения в строках и полное число символов. В заключение следует, если еще есть место, предмет сообщения (Subject:). Ниже приведен пример текста такого аннотационного сообщения (SUN):
Mail version SMI 4.1-OWV3 Mon Sep 23 07:17:24 PDT 1991 Type ? for help.
"/usr/spool/mail/semenov": 4 messages 4 new
>N 1 mw@isds.Duke.EDU Wed Aug 23 14:15 92/4350
N 2 hochreit@informatik.tu-muenchen.de Wed Aug 23 23:54 71/2767 TR announcement: Long Sho
N 3 Voz@dice.ucl.ac.be Thu Aug 24 07:08 501/21416 ELENA Classification data
N 4 S.Renals@dcs.shef.ac.uk Thu Aug 24 07:08 58/2837 AbbotDemo: Continuous Spe
&
Не ленитесь заполнять поле Subject, иначе при большой почте ваш адресат может пропустить ваше сообщение. Среди наиболее значимых для пользователя полей заголовка можно выделить: адрес и имя отправителя (From:), дата отправки (Date:), адрес получателя (To:), адреса и время прохождения промежуточных узлов, списки лиц (Cc:), кому кроме вас послано это сообщение, предмет сообщения (Subject:), некоторая служебная информация и т.д. Число строк заголовка зависит от программы, реализующей функцию почты и от параметров, определенных пользователем, например, путем задания значений системных переменных.
Практически все пакеты электронной почты имеют возможность переадресовать сообщение другому адресату (Forward); отправить ответ (Replay) пославшему вам сообщение человеку (в этом случае в заголовке появится поле Replay-To); стереть сообщение не читая; в случае смены места работы или длительной командировки установить постоянную переадресацию (на ЭВМ SUN для этого нужно указать адрес нового почтового ящика в файле .forward); записать сообщение в файл (Save имя_файла) или отпечатать его на принтере.
Команда обращение к почтовому серверу обычно имеет вид:
mail местный_адрес@имя_домена, (все что записано после команды mail, является электронным адресом адресата). Например, если вы посылаете сообщение автору, то команда приобретает вид: mail semenov@itep.ru.
Использование промежуточного почтового сервера (mail gateway) несколько усложнит запись электронного адреса (это бывает нужно, например, когда кто-то вне Internet хочет послать сообщение клиенту Internet):
semenov%cl.itep.ru@имя_промежуточного_почтового_сервера
При этом предполагается, что промежуточный почтовый сервер возьмет местную часть адреса, заменит символ "%" на традиционный "@" и перешлет полученное сообщение по данному адресу. Встречаются нотации (хотя сегодня их уже смело можно назвать устаревшими), когда адрес имеет вид:
идентификатор_пользователя%имя_домена
или
идентификатор_пользователя:имя_домена.
При возникновении проблем рекомендуется обращаться к администратору вашей локальной сети.
Если вы любопытны и хотите посмотреть, какие служебные команды выдаются при отправке электронного сообщения, воспользуйтесь командой (в качестве адресата (xxxxxxxx) выберите своего друга, коллегу или знакомого, которому вам нужно что-то сообщить):
mail -v xxxxxxxx@cernvm.cern.ch (обращение к почтовой программе пользователя)
220 dxmint.cern. ch Sendmail ready at Thu, 6 Jul 1995 07:43:27 +200
>>> HELO itep.ru
250 dxmint.cern.ch Hello itep.ru, pleased to meet you
>>> MAIL From:<xxxxxxx@itep.ru>
250 <xxxxxxx@itep.ru>... Sender ok
>>> RCPT To:<xxxxxxxx@crnvma.cern.ch>
250 <xxxxxxxx@crnvma.cern.ch>... Recipient ok
>>> DATA
354 Enter mail, end with "." on line by itself
>>> . (команда завершения сообщения и его отправки адресату)
250 Ok
>>> QUIT
221 dxmint.cern.ch closing connection
xxxxxxxx@crnvma.cern.ch... Sent (сессия завершена)
Именно модификация команды mail -v обеспечивает вывод сообщений, отпечатанных ниже строки "Privet...". Для посылки почтового сообщения используется только пять команд: HELO, MAIL, RCPT, DATA и QUIT. Строчки, начинающиеся с >>>, являются командами, которые посланы SMTP-клиентом (xxxxxxx@ns.itep.ru). Строки же, которые начинаются с трехзначной цифры, представляют собой коды-отклики SMTP-сервера (в данном случае он имеет имя dxmint.cern.ch), тексты же, следующие после кода-отклика необязательны и могут отсутствовать. Процедура отправки сообщения начинается с того, что клиент выполняет операцию active open для TCP-порта 25. Далее клиент идентифицирует себя командой HELO, выдавая в качестве параметра адрес своего домена. Команда MAIL идентифицирует отправителя, команда RCPT - получателя. Число команд RCPT всегда равно числу получателей. Команда DATA служит для передачи сообщения, а QUIT – для завершения этой процедуры и ликвидации TCP-канала. Посмотрим как выглядит посланное выше сообщение после того, как я его переадресовал себе по адресу semenov@itep.ru:
From xxxxxxxx@crnvma.cern.ch Sat Jul 29 12:15:13 1995
Received: from cearn.cern.ch by ns.itep.ru with SMTP id AA25862
(5.67a8/IDA-1.5 for <SEMENOV@NS.ITEP.RU>); Sat, 29 Jul 1995 12:15:08 +0300
Received: from CERNVM.CERN.CH by CEARN.cern.ch (IBM VM SMTP V2R2)
with BSMTP id 3114; Sat, 29 Jul 95 10:07:15 SET
Received: from CERNVM.cern.ch (NJE origin@CERNVM) by CERNVM.CERN.CH (LMail
1.2a/1.8a) with BSMTP id 4132; Sat, 29 Jul 1995 10:11:12 +0200
Resent-Date: Sat, 29 Jul 95 10:10:30 SET
Resent-From: xxxxxxxx@crnvma.cern.ch
Resent-To: SEMENOV@NS.ITEP.RU
Received: from CERNVM (NJE origin SMTPIBM@CERNVM) by CERNVM.CERN.CH
Lmail V1.2a/1.8a) with BSMTP id 4125; Sat, 29 Jul 1995 10:08:44 +0200
Received: from dxmint.cern.ch by CERNVM.CERN.CH (IBM VM SMTP V2R2) with TCP;
Sat, 29 Jul 95 10:08:43 SET
Received: by ns.itep.ru id AA25665
(5.67a8/IDA-1.5 for xxxxxxxx@cernvm.cern.ch); Sat, 29 Jul 1995 12:12:26 +0300
Date: Sat, 29 Jul 1995 12:12:26 +0300
From: Yuri Semenov <semenov>
Message-Id: <199507290912.AA25665@ns.itep.ru>
To: xxxxxxxx@crnvma.cern.ch
Subject: Test it.
Status: R
--------------------------Original message---------------
Privet...
Текст, выделенный курсивом, представляет собой то, что пришло в CERN. "Накладные расходы" даже здесь значительны, ведь собственно текст состоит из одного слова, следующего после надписи "Original message". Переадресация же увеличивает издержки еще больше.
При описании DNS говорилось о существовании MX-записей, которые являются одной из разновидностей ресурсных рекордов. MX-записи могут использоваться для доставки почтовых сообщений адресатам, не имеющим прямого доступа к Интернет (RFC-974). Еще одним применением MX-записей является предоставление альтернативного получателя почтовых сообщений в случае, когда ЭВМ-получатель вышла из строя. Для выяснение конкретной конфигурации почтовых серверов можно воспользоваться командой host:
host -a -v -t mx cernvm.cern.ch
(команда выданная с терминала, ниже следует отклик на эту команду)
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=3
The following answer is not authoritative:
| cernvm.cern.ch | 30450 | IN | CNAME | crnvma.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 20 dxmint.cern.ch |
| crnvma.cern.ch | 86042 | IN | MX | 40 relay.EU.net |
/p> For authoritative answers, see:
| cern.ch | 198821 | IN | NS | dxmon.cern.ch |
| cern.ch | 198821 | IN | NS | ns.eu.net |
| cern.ch | 198821 | IN | NS | sunic.sunet.se |
| cern.ch | 198821 | IN | NS | scsnms.switch.ch |
| dxmint.cern.ch | 31455 | IN | A | 128.141.1.113 |
| relay.EU.net | 8411 | IN | A | 192.16.202.2 |
| dxmon.cern.ch | 371619 | IN | A | 192.65.185.10 |
| ns.eu.net | 38326 | IN | A | 192.16.202.11 |
| sunic.sunet.se | 331044 | IN | A | 192.36.148.18 |
| sunic.sunet.se | 331044 | IN | A | 192.36.125.2 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.10.30 |
| scsnms.switch.ch | 28536 | IN | A | 130.59.1.30 |
MX-записи с наименьшим предпочтением ( код предпочтения следует сразу за MX) указывают, что сначала следует попытаться переслать сообщение ЭВМ dxmint.cern.ch.
Следующий уровень предпочтения соответствует адресу relay.EU.net. Здесь же вы найдете CNAME-запись (канонические имена DNS). Кроме списка альтернативных почтовых серверов эта команда выдает информацию о списке серверов имен (DNS-серверов). В приведенном примере их четыре, они помечены символами NS и обслуживают домен cern.ch (см. первую колонку). В нижней части полученной таблицы вы можете найти IP-адреса приведенных MX- и NS-серверов (помечены символом A). Пояснения расшифровки содержимого других колонок можно найти выше, в описании DNS-системы (раздел 1.13 ).
При подготовке текста сообщения вы можете сначала воспользоваться традиционным редактором. Текст будет тогда размещен в файле и при отправке вы можете использовать, например, команду send имя_файла (в системе VMS) или командой GET ввести содержимое файла в текст сообщения (с помощью команды ~r имя_файла в UNIX). Чаще текст сообщения печатается в реальном масштабе времени, непосредственно перед отправкой. В этом случае сигналом конца ввода будет Ctrl-D или символ "." (точка) в начале очередной строки (или Ctrl-Z в VAX/VMS). Если по какой-либо причине вы передумали и не хотите отправлять уже набранное сообщение, процедуру можно прервать, нажав Ctrl-C.
При необходимости посылки одного и того же текста нескольким пользователям можно воспользоваться командой:
mail (или mailx) адрес_1 адрес_2 и т.д.
В этом случае сообщение будет послано по всем перечисленным адресам. Формат этой операции заметно варьируется для разных ЭВМ и программных пакетов. Вместо адресов могут использоваться псевдонимы, что несколько облегчает задачу. Для хранения псевдонимов (alias) служит специальный служебный файл. За описанием работы с псевдонимами вынужден отослать вас к описанию почтового пакета, с которым вы работаете.
На последней строке будет напечатан символ &, который указывает, что система ждет ввода команды (просмотр почты). Уход из mail производится по команде q (quit). В ответ на & вы можете ввести следующие команды (набор команд и их синтаксис может варьироваться от ЭВМ к ЭВМ и от реализации к реализации, см. табл. 4.5.10.1).
При работе в Unix в процессе печатания текста сообщения вы можете выдать почтовой программе определенные команды. Такие команды начинаются с символа "~" (тильда). Ниже приведен список таких команд, текст набранный курсивом, означает, что вместо него должны быть впечатаны имена, адреса и т.д. Многоточие показывает, что может быть введено более одного имени, адреса и пр.
Таблица 4.5.10.1. Внутренние команды почтовой программы UNIX
| Субкоманда MAIL | Описание |
| ~? | Отображает весь набор описаний ~-команд |
| ~b адрес... | Добавляет адрес в строку "Blind copy" (слепая копия "Bcc:"). |
| ~c адрес... | Добавляет адрес(а) в строку "Copy" или "Cc:". |
| ~d | Читает содержимое файла dead.letter |
| ~e | Вызывает редактор текста |
| ~f сообщения | Считывает сообщения |
| ~h | Редактирует все строки заголовка. |
| ~m сообщения | Считывает сообщения, сдвигает указатель вправо на одну табуляцию |
| ~p | Отображает (печатает) текущее сообщение |
| ~q | Уход из почты (Quit), эквивалентно двойному Ctrl-C |
| ~r файл | Считывает содержимое указанного файла в текст сообщения |
| ~s subject | Изменяет содержимое строки Subject |
| ~t адрес... | Добавляет адрес в строку "To:". |
| ~v | Вызывает альтернативный редактор (то же, что и ~e). |
| ~w файл | Записывает текущее сообщение в файл |
| ~! команда | Выполняет команду Shell и возвращается к сообщению |
| ~| команда | Пропускает текущее сообщение через фильтр |
/p> Если вы напечатаете ~f (без указания номера сообщения), в текст текущего сообщения будет внесено содержимое сообщения, которое вы читали последним. Стандартной формой использования ~f является, например, ~f 5, где 5 - номер сообщения. ~m делает тоже самое, но каждая строка сдвигается на один tab вправо.
В UNIX многие команды имеют разные функции, если они напечатаны строчными или прописными буквами, смотри, например, команды r и R в таблице 4.5.10.2. Не безразлично в UNIX и применение строчных и прописных символов в именах файлов, что бывает существенно, в частности, при работе с FTP-сервером.
Важной командой является SET, которая позволяет изменять системные переменные. Формат использования:
SET переменная=значение (Например, SET EDITOR=/bin/edMe=/bin/eda).
Уже сегодня можно переслать поздравительную цветную открытку вашим знакомым. Возможна по такой схеме пересылка и звуковых писем, лишь бы у вашего адресата была звуковая карта в ЭВМ. Ведутся работы и над протоколами видео-писем (NETBLT).
Тот факт, что электронная почта является наиболее популярным видом сервиса, делает ее объектом непрерывных доработок и усовершенствований. Так в документах RFC-1425, -1426, -1427 предлагается вариант расширения возможностей SMTP (ESMTP). Эта модификация сохраняет совместимость со старыми версиями. Клиент, желающий воспользоваться расширенными возможностями, посылает команду EHLO вместо HELO. Если сервер поддерживает ESMTP, он выдаст код-отклик 250. Этот вид отклика является многострочным, что позволяет серверу сообщить о видах сервиса, которые он поддерживает. Например:
250-8BITMIME (RFC-1426)
250-EXPN (RFC-821)
250-SIZE (RFC-1427)
250-HELP (RFC-821)
250-XADR
Таблица 4.5.10.2. Команды, выполняемые почтовой программой
| Команда | Описание | |
| Сокращение | Полное имя | |
| ? | - | Отображение списка исполняемых команд |
| ! | - | Выполнение одной команды Shell |
| + | - | Отобразить следующее сообщение |
| RETURN | - | Отобразить следующее сообщение |
| - | - | Отобразить предшествующее сообщение |
| число | - | Отобразить сообщение с номером "число". |
| d | delete | Стереть текущее сообщение |
| dp | - | Стереть текущее сообщение и отобразить следующее |
| e | edit | Вызвать редактор для работы с сообщениями |
| h | headers | Отобразить список заголовков сообщений |
| l | list | Выдать список имен всех доступных команд |
| m | Послать сообщение по указанному адресу или адресам | |
| n | - | Отобразить следующее сообщение и распечатать его |
| p | Отобразить (отпечатать) сообщения | |
| pre | preserve | Сохранить сообщения в системном почтовом ящике |
| q | quit | Завершить работу с почтой |
| r | replay | Ответить отправителю и всем прочим получателям |
| R | Replay | Ответить только отправителю |
| s | save | Сохранить сообщения в указанном файле или в mbox, если имя файла не указано |
| sh | shell | Временно уйти из почты и вернуться в shell |
| t | type | Тоже что и print |
| to | top | Отобразить несколько верхних строчек сообщения |
| u | undelete | Восстановить ранее стертые сообщения |
| v | - | Редактирование сообщения с помощью экранного редактора |
| w | write | Тоже что и s, но без записи заголовка |
| x | exit | Выйти из почты без спасения внесенных изменений |
| z | - | Отобразить следующий набор заголовков |
| z- | - | Отобразить предшествовавший набор заголовков сообщений |
/p> Ключевое слово 8BITMIME говорит о том, что клиент может добавить ключевое слово BODY к команде MAIL FROM и определить тип символов, используемых в сообщении (ASCII или 8-битные). Ключевое слово XADR указывает на то, что любые ключевые слова, начинающиеся с X, относятся к местным модификациям SMTP. Документ RFC-1522 определяет способ, как можно включить не ASCII-символы в заголовок почтового сообщения. Например:
=?набор_символов ?кодировка ?закодированный_текст ?=
набор_символов - спецификация набора символов: us-ascii или ISO-8859-X, где X - одиночная цифра, например ISO-8859-1. Поле кодировка содержит один символ, характеризующий метод кодировки. В настоящее время описаны два метода:
1. Q - набор печатных символов; символы, коды которых имеют неравный нулю 8-ой бит, отображается тремя символами: знаком равенства (=), за которым следует два шестнадцатеричных числа (например =AD). Так пробел будет иметь кодировку =20.
2. B - 64-символьный набор (Base64, латинские буквы, 10 цифр, а также символы + и /). Набор кодов Base64 приведен в таблице:
Таблица 4.5.10.3. Коды Base64
|
Код символа (6 бит) |
ASCII символ |
Код символа (6 бит) |
ASCII символ |
Код символа (6 бит) |
ASCII символ |
Код символа (6 бит) |
ASCII символ |
| 0 | A | 10 | Q | 20 | g | 30 | w |
| 1 | B | 11 | R | 21 | h | 31 | x |
| 2 | C | 12 | S | 22 | i | 32 | y |
| 3 | D | 13 | T | 23 | j | 33 | z |
| 4 | E | 14 | U | 24 | k | 34 | 0 |
| 5 | F | 15 | V | 25 | l | 35 | 1 |
| 6 | G | 16 | W | 26 | m | 36 | 2 |
| 7 | H | 17 | X | 27 | n | 37 | 3 |
| 8 | I | 18 | Y | 28 | o | 38 | 4 |
| 9 | J | 19 | Z | 29 | p | 39 | 5 |
| A | K | 1A | a | 2A | q | 3A | 6 |
| B | L | 1B | b | 2B | r | 3B | 7 |
| C | M | 1C | c | 2C | s | 3C | 8 |
| D | N | 1D | d | 2D | t | 3D | 9 |
| E | O | 1E | e | 2E | u | 3E | + |
| F | P | 1F | f | 2F | v | 3F | / |
| MIME-Version: | (версия MIME, сейчас 1.0) |
| Content-Type: | (тип содержимого, см. таблицу на рис. 4.5.10.4) |
| Content-Transfer-Encoding: | (кодирование содержимого) |
| Content-ID: | (идентификатор содержимого) |
| Content-Description: | (описание содержимого) |
/p> Поле заголовка Content-Transfer- Encoding используется пять видов кодировки (третий вид полей в приведенном выше списке):
7-бит (NVT ASCII, по умолчанию);
Набор печатных символов (полезен, когда только небольшая часть символов использует 8-ой бит);
64-символьный набор (Base64 см. выше в таблице 4.5.10.3);
8-битный набор символов, включающий псевдографику, с использованием построчного представления;
Двоичная кодировка (8-битное представление без построчного представления).
Только первые три типа согласуются с требованиями RFC-821. MIME позволяет снять с электронной почты привычные ограничения и предоставляет возможность пересылать любую информацию. Техника приложений (Attachment) позволяет пересылать через электронную почту любые файлы без какого-либо специального преобразования, выполняемого пользователем. При этом необходимо только, чтобы и приемник и передатчик поддерживали это расширение электронной почты. В MIME предусмотрены следующие типы и субтипы содержимого почтового сообщения:
Таблица 4.5.10.4. Типы и субтипы почтовых сообщений.
| Тип почтового сообщения |
Субтип почтового сообщения |
Описание |
| text | plain | Неформатированный текст |
| richtext | Текст с простым форматированием, таким как курсив, жирный, с подчеркиванием и т.д. | |
| enriched | Упрощение, прояснение и усовершенствование richtext | |
| multipart | mixed | Сообщение содержит несколько частей, которые обрабатываются последовательно |
| parallel | Сообщение содержит несколько частей, обрабатываемых параллельно | |
| digest | Краткое содержание почтового сообщения | |
| alternative | Сообщение содержит несколько частей с идентичным семантическим содержимым | |
| message | RFC822 | Содержимое является почтовым сообщением в стандарте RFC-822 |
| partial | Содержимое является фрагментом почтового сообщения | |
| external-body | Содержимое является указателем на действительный текст сообщения | |
| application | octet-stream | Произвольная двоичная информация |
| postscript | PostScript программа | |
| image | jpeg | Формат ISO 10918. |
| gif | Формат обмена CompuServe (Graphic Interchange Format). | |
| audio | basic | Формат ISO 11172 |
/p> Текст электронного сообщения не передает всех оттенков мыслей и эмоций отправителя, что может вызвать неверное восприятие. Для решения этой проблемы хотя бы частично используются символьные обозначения эмоций. Таблица таких обозначений приведена ниже. Чтобы легче воспринять и запомнить их, посмотрите на страницу, где напечатана таблица, справа.
| Символ | Значение |
| :-) | Улыбка |
| :-D | Смех |
| ;-) | Подмигивание |
| :-( | Неудовольствие |
| :-< | Огорчение |
| 8-) | Удивление |
| :-o | О, нет! |
| :-I | Безразличие |
| :-# | Вынужденная улыбка |
| :-] | Ухмылка |
| :-{) | Улыбка с усами |
| {:-) | Улыбка с париком |
| :-X | Мой рот на замке |
| =:-) | Панк-рокер |
| =:-( | Настоящий панк-рокер никогда не улыбается |
| %^) | Название для этой улыбки читателям предлагается придумать самостоятельно |
Электронная подпись
6.4.3 Электронная подпись
Семенов Ю.А. (ГНЦ ИТЭФ)

В конце любого письма мы привыкли ставить подпись с тем, чтобы уведомить получателя о том, кто является отправителем данного документа. Кроме того, подпись ответственного лица придает документу юридическую силу. По мере внедрения электронных средств доставки документов (факс и электронная почта) проблема их достоверности обрела крайнюю актуальность. Ведь копирование любой последовательности битов или пикселей не представляет никакой трудности. Современные телекоммуникационные каналы уязвимы для перехвата и искажения пересылаемых документов.
Рассмотрим сначала то, от каких действий злоумышленника должна защищать система идентификации.
Отказ от выполненных действий. Субъект утверждает, что он не посылал некоторый документ, хотя на самом деле он его послал.
Модификация документа. Получатель модифицирует полученный документ и утверждает, что именно такую версию документа он и получил.
Подделка. Субъект фабрикует сообщение и утверждает, что оно ему прислано.
Перехват. Злоумышленник С перехватывает сообщение, посланное А к В с целью модификации.
Маскировка. Посылка сообщения от чужого имени.
Повтор. Злоумышленник С посылает повторно сообщение от А к Б, перехваченное им ранее.
Решение практически всех этих проблем может быть реализовано с помощью электронной подписи, базирующейся на алгоритме RSA. Рассмотрим принципы, на которых базируется электронная подпись.
Пусть имеются секретные коды d, p и q, а также открытые e и n=pq. Пусть также А передает сообщение DATA адресату Б. Электронная подпись отправителя А базируется на его секретном ключе и открытом ключе получателя Б. Сначала отправитель с помощью хэш-функции (SHS - Secure Hash Standard; www.nist.gov/itl/div897/pubs/fip180-1.htp) генерирует дайджест своего сообщения длиной 160 бит (5 слов). Затем с помощью своего секретного ключа он формирует электронную подпись. При этом А не может отказаться от того, что именно он послал сообщение, так как только он знает свой секретный ключ. Электронную подпись нельзя использовать повторно и подписанный документ нельзя модифицировать, так как любые модификации неизбежно изменят его дайджест, а, следовательно, и электронную подпись. Получатель с помощью открытого ключа дешифрует код электронной подписи, а затем с использованием дайджеста проверяет ее корректность.
Национальный институт стандартов США принял стандарт DSS (Digital Signature Standard; www.itl.nist.gov/div897/pubs/fip198.htm), в основу которого легли алгоритмы Эль-Гамаля и RSA.
Рассмотрим алгоритмы вычисления дайджеста сообщения, электронной подписи и идентификации отправителя. Начнем с алгоритма SHA (Secure Hash Algorithm).
Сначала сообщение разбивается на блоки длиной 512 бит. Если длина сообщения не кратна 512, к последнему блоку приписывается справа 1, после чего он дополняется нулями до 512 бит. В конец последнего блока записывается код длины сообщения. В результате сообщение приобретает вид n 16-разрядных двоичных слов M1,M2,…,Mn. M1 содержит первый символ.
Алгоритм SHA использует 80 логических функций f0,f1,…,f79, которые производят операции над тремя 32-разрядными словами (B,C,D):
| Kt = 5A827999 | для 0 Ј t Ј 19 |
| Kt = 6ED9EBA1 | для 20 Ј t Ј 39 |
| Kt = 8F1BBCDC | для 40 Ј t Ј 59 |
| Kt = CA62C1D6 | для 60 Ј t Ј 79 |
H0 = 67452301
H1 = EFCDAB89
H2 = 98BADCFE
H3 = 10325476
H4 = C3D2E1F0
Делим массив M на группы из 16 слов W0, W1,…,W15 (W0 самое левое слово).
Для t = 16 - 79 wt = S1(Wt-3 XOR Wt-8 XOR Wt-14 XOR Wt-16)
Ak означает операцию циклического сдвига влево на k разрядов.
Пусть теперь A = H0, B = H1, C = H2, D = H3, E = H4.
for t = 0 to 79 do
TEMP = S5(A) + ft(B,C,D) + E + Wt + Kt. (TEMP – временная переменная).
E = D; D = C; C = S30(B); B = A; A = TEMP;
Пусть H0 = H0 + A; H1 = H1 + B; H2 = H2 + C; H3 = H3 + D; H4 = H4 + E.
В результате обработки массива М будет получено 5 слов H0, H1, H2, H3, H4 с общей длиной 160 бит, которые и образуют дайджест сообщения. Полученная кодовая последовательность с высокой степенью уникальности характеризует сообщение. Любое редактирование сообщения практически неизбежно приведет к изменению дайджеста. Поскольку алгоритм вычисления дайджеста общеизвестен, он не может рассматриваться как гарантия предотвращения модификации сообщения. Смысл вычисления дайджеста заключается в уменьшении объема данных, подлежащих шифрованию. Для того чтобы превратить дайджест в электронную подпись надо воспользоваться секретным ключом. Схема реализации алгоритма DSA (Digital Signature Standard) показана на рис. 6.4.3.1.

Рис. 6.4.3.1. Схема вычисления и верификации электронной подписи (DSA)
DSA использует следующие параметры (www.itl.nist.gov/div897/pubs/fip186.htm):
p
– простое число, которое при 512Ј L Ј 1024 удовлетворяет условию 2L-1 < p < 2L, L кратно 64.
q – простой делитель p-1, где 2159 < q < 2160.
g = h(p-1)/q mod p, где h любое целое, для которого 1 < h < p-1 и h(p-1)/q mod p > 1.
x равно случайному или псевдослучайному целому числу, для которого 0 < x < q.
y = gx mod p.
k равно случайному или псевдослучайному целому числу, для которого 0 < k < q.
Целые p, q и g могут быть общедоступными и использоваться группой пользователей. Секретным и открытым ключами являются х и у, соответственно. Параметры х и k используются только для формирования электронной цифровой подписи и должны храниться в секрете. Параметр k генерируется для каждой подписи.
Подпись сообщения M представляет собой два числа r и s, вычисленные согласно формулам:
r = (gk mod p) mod q
s = (k-1(SHA(M) + xr)) mod q
. (здесь k-1 величина обратная k).
SHA(M) – представляет собой дайджест сообщения M (160-битовая строка). После вычисления r и s следует проверить, не равно ли одно из них нулю.
Для верификации электронной подписи проверяющая сторона должна иметь параметры p, q и g, а также открытый ключ отправителя (подписанта) y.
Пусть M`, r` и s` представляют собой полученное сообщение и электронную подпись. Получатель начинает верификацию с проверки условия 0 < r` < q и 0 < s` < q. Если хотя бы одно из условий не выполнено, электронная подпись некорректна. Далее производится вычисление:
w = (s`)-1 mod q
u1 = ((SHA(M`)w) mod q
u2 = ((r`)w) mod q
v = (((g)u1 (y)u2) mod p) mod q.
Если v = r`, верификация подписи завершилась успешно и получатель может с высокой вероятностью быть уверен, что он получил сообщение от партнера, владеющего секретным ключом х, соответствующим открытому ключу у. Если же v не равно r`, то сообщение было модифицировано или подписано самозванцем. В ссылке 3 на предыдущей странице можно найти описание алгоритма нахождения (проверки) простых чисел и генерации псевдослучайных чисел.
Электронная торговля в Интернет
4.6 Электронная торговля в Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)
В “МК” за 11-12-2001 появилась заметка “Космонавты сходили по магазинам прямо на орбите”, где сообщалось о покупках сделанных космонавтами В. Дежуровым и М. Тюриным с борта международной космической станции. Покупки были осуществлены с помощью виртуальной платежной карты VISA. Понятно, что торговля в космосе не станет в ближайшее время бурно развивающимся бизнесом, это лишь говорит о впечатляющих возможностях новых технологий.
В перспективе для торговли через Интернет нет никаких ограничений. Но есть ряд областей, где именно этот вид торговли находится вне конкуренции. Это, прежде всего сфера сетевых развлечений, коммерческой информации, дистанционного обучения, платных консультаций, а также продажа небольших программ, например, антивирусных, программ защиты от SPAM и т.д. В этом случае Интернет позволяет понизить цену для покупателя и издержки для продавца.
С протокольной точки зрения здесь есть две задачи: обеспечение необходимого, масштабируемого уровня сервиса и гарантирование достаточно высокой безопасности для всех участников. При этом предполагается, что транспортные проблемы решает стэк протоколов Интернет.
Основы электронной коммерции были заложены с появлением кредитных карт. Но настоящий бум возник после широкого внедрения Интернет, когда появилась возможность доступа к этой сети с домашней ЭВМ. Сейчас вряд ли кто-либо из клиентов Интернет в России покупает ЭВМ или даже бытовую технику, не просмотрев соответствующую информацию в сети и не выбрав поставщика с наилучшим предложением. Электронная торговля возникла из рекламы через Интернет. Сначала фирма создавала свой WEB-сервер, где были представлены товары или услуги с указанием их расценок. Позднее через форму HTML стало возможным сделать заказ. Так появились первые Интернет-магазины. Оплата на первом этапе производилась исключительно через кредитные карточки. Но скоро выяснилось, что существуют области, где кредитные карты не оптимальны (речь идет о покупках с ценами, сопоставимыми с одним центом, а себестоимость операции с кредитной картой относительно высока), да и безопасность первых систем оплаты оставляла желать лучшего. Так появились самые разнообразные схемы платежей.
За рубежом через Интернет покупаются не только билеты на самолет или в театр, но даже автомобили. Просмотрев предложения в сети, изучив на дисплее интерьер салона и технические параметры, выбрав и оплатив покупку, клиент находит следующим утром ключи от авто в своем почтовом ящике, а саму машину на парковке у дома. Для россиянина это звучит как сказка. Разные торговые системы базируются на удаленном доступе типа telnet (SSH) или на технологии WEB-серверов (SSL).
Многим знакома компания, торгующая книгами amazon.com. Появились аналогичные предложения по книгам, CD, видеокассетам и другим мелочам и в России. Прогресс этой ветви бизнеса сдерживается отсутствием развитой системы электронных платежей, да и российская банковская система совершенно не отвечает своему основному назначению. По сложившейся традиции российский банкир считает деньги вкладчика своими, и в соответствии с этой концепцией строит свою финансовую политику. Скажу прямо, я не доверю российскому банкиру и рубля, солидный швейцарский, немецкий или американский банк другое дело. А ведь банковское дело не может существовать без доверия.
Основные проблемы торговли через Интернет
Проблема доверия не так проста и за рубежом, но уже по иной причине. Программное обеспечение, обслуживающее электронную торговлю и банковские операции, может иметь случайные или преднамеренные ошибки. Достаточно вспомнить банковскую программу, которая при начислении процентов по вкладам всегда округляла результат до цента в меньшую сторону, а разницу (доли цента) переводила на счет автора программы, что при большом числе операций составило многие тысячи долларов. С этой точки зрения желательно, чтобы тексты программ были общедоступны. Но такие программы достаточно сложны, создание их требует больших инвестиций, и по этой причине их тексты обычно составляют коммерческую тайну. А человек должен доверить свои с таким трудом заработанные деньги этой программе. Согласитесь, что это психологически не так просто. По этой причине верификация и сертификация таких программ выступает на лидирующие позиции.
Эти и многие другие обстоятельства, безусловно, тормозят развитие электронной торговли, но остановить прогресс в этой области даже они не в силах. Электронная коммерция базируется на определенном уровне доверия, риска и надежности, так как получение товара или услуги разнесено по времени с получением денег или платежного документа. Для того чтобы сделка состоялась, партнеры должны быть уверены, что вероятность риска находится на приемлемо низком уровне, а возможная потеря по недобросовестной сделке должна перекрываться прибылью от остальных сделок. На этом принципе существует Интернет-торговля дешевыми товарами – ковриками для мыши или небольшими программами (цена товара или услуги не более 10-30 долларов США). Впрочем, и это относится не к РФ, где царствует предоплата, так как продавец не без основания считает, что вероятность недобросовестности клиента достаточно велика. Все это создает большие неудобства для честных покупателей и ограничивает объемы продаж. Все действующие системы Интернет-магазинов в РФ базируются на доставке и наличной оплате или на различных схемах предоплаты. Не трудно видеть, что эта жуликоватость наносит в конечном итоге ущерб развитию экономики, от которого страдают все граждане. Мне представляется даже, что постепенное внедрение электронной торговли позволит постепенно поменять жизненную философию широкого слоя вовлеченного в этот процесс населения, я уже не говорю о характере самого бизнеса.
Так как современный бизнес повсеместно базируется на использовании вычислительной техники (ЭВМ, электронные кассовые аппараты, банкоматы и пр.), внедрение электронной коммерции является естественным процессом.
Любая современная торговая фирма имеет уже работающую систему склад-магазин, учитывающую наличие запасов, объемы продаж по конкретным позициям, что повышает эффективность и позволяет проконтролировать действенность рекламы. А это еще одно приложение Интернет. Вместо широковещательного навязывания всем детских подгузников можно перейти к адресной рекламе. Я страдаю от спама (нелегальная рассылка различных коммерческих, а часто и откровенно мошеннических предложений), но готов получать время от времени информацию о результатах испытаний различных компонентов вычислительной техники и сетевого оборудования (позитивным примером такого рода рекламы можно считать сервер
www.tolly.com). Рекламный бизнес через Интернет в США только в 1995 году принес 55 миллионов долларов, сейчас эти объемы превзойдены более чем на порядок.
Интернет с его TCP/IP транспортом не может считаться безопасным. По этой причине разработки последних лет были ориентированы на решение этой проблемы. Разработаны протоколы STT (Secure Transaction Technology), SSL, TLS, L2TP, SHTTP, SEPP (Secure Electronic Payment Protocol) и, наконец, SET (Secure Electronic Transactions), предусмотрены специальные меры и в новом протоколе IPv6. Большинство WEB-серверов используют OS UNIX, где администратор системы (root) имеет привилегии, открывающие ему доступ ко всем каталогам и файлам. Это создает еще один источник угроз.
С начала 90-х годов началось развитие электронных платежных средств на основе кредитных карт со встроенными микропроцессорами (Integrated Circuit Card Specifications for Payment Systems). Такие карты обеспечивают более высокий уровень безопасности, так как могут предложить надежную аутентификацию самой карты и ее владельца. Процессор может использовать записанные в нем индивидуальные ключи шифрования, известные только банку эмитенту карты и/или ее пользователю. Карта имеет 8 внешних контактов (см. раздел 4.5). Стандарт на такие карты описан в документе ISO 7816 (Identification cards – Integrated circuit(s) cards with contacts). Этот стандарт базируется на нескольких более общих стандартах, имеющих отношения к идентификационным картам, – ISO 7810, ISO 7811, ISO 7812 и ISO 7813. Смарт-карта содержит ИС (20х20мм), где на одном кристалле интегрирован 8-битовый процессор, выполняющий все логические и вычислительные операции (10МГц); ROM – память, ориентированная только на чтение, запись в которую производит изготовитель ИС и где хранится операционная система и прикладные программы (16K); EEPROM – ROM с возможностью электрической перезаписи, которая предназначена для записи и хранения балансовых данных и индивидуальной информации владельца карты (8K); RAM> – оперативная память (512 байт); система ввода-вывода (приведенные цифры относятся к карте Mondex). Себестоимость смарт-карты составляет около 5$. Можно быть уверенным, что приведенные цифры к моменту публикации устареют. Карта является объектом, с которой злоумышленник может экспериментировать неограниченно долго с привлечением любой техники.
Изготовление карты и запись в нее информации производится различными участниками. Разработано ряд дополнительных мер для поднятия уровня безопасности. Код программ в ROM является невидимым, тестовые контакты после контроля содержимого карты дезактивируются. Содержимое программ, занесенных в ROM, закрыто и известно только разработчикам. Запись в EEPROM осуществляется с помощью нескольких команд в строго определенном порядке. Как команды, так и их порядок известны только разработчику и производителю карты. Более того, содержимое EEPROM контролируется с помощью специального хэш-кода. Содержимое EEPROM защищено от воздействия UV-излучения и любых других видов электромагнитного излучения. Ключи шифрования заносятся на карту в процессе персонализации и не могут быть считаны потом. Никакие тексты каких-либо программ никогда не публикуются. Считается, что спецификация для смарт-карт в части безопасности будет в будущем пересмотрена.
Объединение лидеров в этой области – Europay, MasterCard и VISA разработало спецификацию EMV (по первым буквам фирм участниц; декабрь 1993 года, в 1995-96 опубликованы улучшенные версии). Серьезным ограничением в этой области является отсутствие единого международного стандарта.
За последние годы разработано много различных систем выполнения платежей: ASH, Achex, BankNet, BidPay, BillPoint, BIPS, CAFE, Cartio, CashBox, CyberCash, DebitNet, DigiCash, DigiGold, eCash, E-gold, EMV, Gmoney, HashCash, iBill, IPAY, iPIN, Kagi, MagnaCash, Mondex, PayCash, PayPal, PayWord, PCPay, PocketPass, MicroMint, Millicent, NetCard, NetCash, NetCheque, NetPay, NetChex, Qpass, QuickCommerce, SOX, SET, TeleCheck, Transfer, WebCharge, WebMoney, WiSP, WorldPay, Ziplock и т.д. (смотри, http://ganges.cs.tcd.ie/mepeirce/Project/oninternet.html), которые обеспечивают расчеты в широком диапазоне требований по надежности и безопасности. Каждому уровню цен, товаров или услуг должен соответствовать определенный вид электронных платежей. Первой безопасной сетевой системой платежей была First Virtual (1995 г). Приведенный перечень систем платежей является достаточно случайным и неполным. Из этого списка ряд систем работают в РФ (например, WebMoney Transfer и PayCash). Разработано и используется уже десятки таких систем, которые прокладывают дорогу чисто электронным деньгам. Область использования наличных бумажных и металлических денег постепенно сужается и со временем этот традиционный вид платежей уйдет в историю (см., например, статью “Будущее денег”
http://www.businessweek.com/1995/24/b3428001.htm). Для РФ новые платежные системы, работающие без кредитных карт, особенно привлекательны, так как число граждан России, имеющих такие карты, незначительно. Внедрение электронных денег, решая многие проблемы, ставит ряд новых.
Кто будет выпускать и регулировать выпуск электронных денег (в случае бумажных денег – это функция центрального национального банка)? Коммерческий банк может предоставить кредитов на сумму, превосходящую наличные депозиты. В случае электронных денег это создает еще большую свободу при операциях такого рода. Уже имеются прецеденты эмиссии электронных денег структурами, не имеющими никакого отношения к банковской системе.
Как будут решаться проблемы налогов? Ведь в этом случае трудно отследить движение денег из-за его глобального характера.
Кто должен определить стандарты на электронные деньги и операции с ними?
Кто и как будет обеспечивать безопасность операций и защиту интересов покупателей-клиентов?
Список таких вопросов можно существенно расширить. Электронные деньги существенно меняют и функции банков, более того некоторые операции банков могут выполняться другими структурами, например, сетевыми сервис-провайдерами или компаниями-разработчиками программного обеспечения. Так, например, MicroSoft через десятки миллионов пользователей Windows может легко захватить заметный сегмент в сфере предоставления кредитов в виде электронных денег. Интернет здесь может использоваться как при покупке через сеть, так и при оплате традиционной (очной) покупки. Схемы взаимодействия участников сделки могут быть весьма замысловатыми, ведь покупатель может быть в одной стране, продавец - в другой, банк покупателя - в третьей, а банк продавца - в четвертой. Учитывая, что в сделке, кроме того, могут участвовать компания, осуществляющая доставку покупки, и фирма, выполняющая обслуживание товара, например мобильного телефона, ситуация еще более осложняется. Понятно, что необходимо определенное юридическое обеспечение подобного рода операций, но уже это выходит за рамки данной книги.
Электронная коммерция поменяет современную жизнь также, как Интернет изменил среду общения и доступ к информации.
В торговле основную прибыль всегда давала информация (знание конъюнктуры рынка, знание производителей и пр.). Современный этап с его взрывным развитием технологий делает этот фактор решающим.
Несколько лет назад я наблюдал, как в книжном магазине в Гамбурге продавали одну книгу. Вещь достаточно ординарная, если бы не одно обстоятельство, - эта книга печаталась и переплеталась в присутствии покупателя. Название я ее забыл, но помню, что автором был американец. Уже здесь видны определенные проблемы. Как проконтролировать тираж, чтобы авторские права не пострадали, как и где начислять налоги на эту деятельность?
До недавнего времени программы продавались в коробках, произведенных фирмой разработчиком (практически как книги). Новейшей тенденцией является торговля программами (пока дешевыми) через Интернет. Для этого имеются все средства и предпосылки. Но эта схема порождает немало юридических и коммерческих проблем. Здесь и упомянутая проблема налогов (пока в США торговля через Интернет не облагается налогами), и нарушения авторских прав. Ведь нужно определить, кто должен платить налоги, дилер, продавший программу, или фирма разработчик, а это не безразлично, если они расположены в разных странах. Да и взаимоотношения между дилером и разработчиком нужно как-то урегулировать, так как нужен надежный контроль за проданным количеством копий программы. Где здесь место таможни (пока продавались коробки с программами, были сопроводительные бумаги, на которых можно было после оплаты сбора поставить штамп “Таможня дала добро”)? Сходные проблемы ждут разработчиков и продавцов компьютерных игр, музыкальных CD и DVD-дисков, а в перспективе очень многих других товаров.
Развитию электронной торговли способствуют широко распространенные системы склад-магазин (смотри рис. 2.1 и 2.2). Здесь склад и магазин могут иметь общего хозяина, а могу принадлежать и различным фирмам. Прямого отношения к электронной торговле эти структуры не имеют, но при их создании решались некоторые проблемы и создавались программы, которые могут найти применение в электронной коммерции.

Рис. 2.1. Простейшая схема системы склад-магазин

Рис. 2.2. Продвинутая схема системы склад-магазин
В реальной жизни сервер может размещаться на оптовом складе, который обслуживает сеть магазинов, база данных может быть распределенной и т.д., суть от этого не меняется. В любой из этих схем должна быть решена проблема безопасности и надежности передачи информации, а это роднит эти схемы со схемами электронной торговли. В общем случае взаимоотношения между складом и магазином могут быть исключительно коммерческими, что делает эти объекты субъектами, осуществляющими торговые операции. Взаимоотношения с современным банком в любом случае относится к сфере электронной коммерции. Наличие таких структур заметно стимулирует внедрение электронной торговли, так как эта технология предполагает взаимодействие различных систем распределенных баз данных.
В общем случае в электронной коммерции могут быть задействованы 5 субъектов – продавец, покупатель, банкир, агент доставки и агент обслуживания. Взаимодействие этих субъектов и документооборот между ними регламентируется протоколом IOTP.
Теперь попытаемся проанализировать, в чем заключаются преимущества и недостатки электронной торговли для покупателя и продавца.
Схема P2P работает при распродаже старых компонентов ЭВМ, книг, кустарных изделий и пр. их владельцами, при обмене и покупке-продаже различных предметов коллекционерами, а также при оказании услуг по ремонту настройке сложного бытового оборудования или, например, в сфере индивидуального обучения.
Более перспективной представляется схема B2C>, именно к этому классу относятся практически все Интернет-магазины. В РФ пару лет назад возник бум создания таких структур. Даже ТВ было привлечено к рекламе некоторых из них. Пожалуй, это было несколько преждевременно. Сохранились лишь несколько книжных магазинов, торговля бытовой техникой, произведениями искусства, лекарствами и т.д.. Пытаются выжить некоторые Интернет-аукционы, которые по своей функции являются, чем-то средним между B2C и P2P. Следует обратить внимание, что почти все они не используют сетевых платежных систем. Во многих случаях отсутствие коммерческого успеха связано с тем, что такие магазины не дают сверхприбылей, но требуют получения лицензий и других начальных инвестиций. Сюда относится и отсутствие достаточного платежеспособного спроса у той части населения, которая знакома с технологиями Интернет и имеет к нему доступ, неразвитая кредитная и банковская системы.
В РФ более успешной оказалась область В2В, охватывающая оптовую торговлю медикаментами, металлами, нефтепродуктами, стройматериалами и т.д.. Но даже здесь этот бизнес сильно отличается от аналогичной деятельности, скажем, в США.
Как уже отмечалось выше, торговля сопряжена не только с оплатой товара и его получением, но с немалым объемом документов (заказы, счета, чеки, накладные, расписки, платежные поручения и т.д.). В настоящее время специально для торговли через Интернет разработан открытый протокол торговли через Интернет IOTP (Internet Open Trading Protocol).
Элементы теории графов
10.21 Элементы теории графов
Семенов Ю.А. (ГНЦ ИТЭФ)

Рис. 10.21.1 Примеры неориентированного и ориентированного графов (А и Б)
Введем более строгие определения. Граф представляет собой структуру П = <V,E>, в которой V представляет собой конечный набор узлов, а EН VЕV представляет собой конечный набор ребер. Для ориентированного графа E Н Vґ V – конечный набор ориентированных ребер. Ребром может быть прямая или кривая линия. Ребра не могут иметь общих точек кроме вершин (узлов) графа. Замкнутая кривая в E может иметь только одну точку из множества V, а каждая незамкнутая кривая в E имеет ровно две точки множества V. Если V и E конечные множества, то и граф им соответствующий называется конечным. Граф называется вырожденным, если он не имеет ребер. Параллельными ребрами графа называются такие, которые имеют общие узлы начала и конца.
Графы отображаются на плоскости набором точек и соединяющих их линий или векторов. При этом грани могут отображаться и кривыми линиями, а их длина не играет никакой роли.
Граф G называется плоским, если его можно отобразить в плоскости без пересечения его граней.
Очертанием графа (face) считается любая топологически связанная область, ограниченная ребрами графа.
Неориентированный граф G = <V,E> называется связанным, если для любых двух узлов x,y О V существует последовательность ребер из набора E, соединяющий x и y.
Граф G связан тогда и только тогда, когда множество его вершин нельзя разбить на два непустых подмножества V1 и V2 так, чтобы обе граничные точки каждого ребра находились в одном и том же подмножестве.
Граф G называется k-связным (k і 1), если не существует набора из k-1 или меньшего числа узлов V`Н V, такого, что удаление всех узлов V` и сопряженных с ними ребер, сделают граф G несвязанным.
Теорема Менгера
: граф G является k-связанным тогда и только тогда, когда любые два различные узла x и y графа G соединены по крайне мере k путями, не содержащими общих узлов.
k-связанные графы представляют особый интерес для сетевых приложений. Определенную проблему составляет автоматическое отображение графа на экране или бумаге. Кроме того, для многих приложений (например, CAD) все узлы графа должны совпадать с узлами технологической сетки. Возникают и другие ограничения, например необходимость размещения всех узлов на прямой линии. В этом случае ребра графа могут представлять собой кривые линии, дуги или ломаные линии, состоящие из отрезков прямых. Смотри, например, рисунок 10.21.2.

Рис. 10.21.2
Граф слева безусловно легче воспринять, чем граф справа, хотя они эквивалентны. Существует ряд алгоритмов, позволяющих определить, является ли граф плоским. Так граф на рис. 10.21.3 на первый взгляд не является плоским (ведь его ребра пересекаются в нескольких местах). Но он может быть перерисован (см. рис. 10.21.3а), после чего его плоскостность уже не подвергается сомнению.

Рис. 10.21.3. Граф и его матрица смежности

Рис. 10.21.3а. Преобразование графа с рис 3
Матрица смежности, характеризующая этот граф, эквивалентна приведенной на рис. 10.21.3, а сами графы изоморфны. Для представления графа может использоваться Булева функция S(x,y), для которой S(i,j)=1 тогда и только тогда, когда (i,j)О E. S(i,j) обозначает ребро графа, соединяющее узлы i и j. Одной из возможностей реализации s является использование матрицы смежности А графа g. А – двухмерная матрица.
Для описания графа с помощью матрицы смежности A(i,j), где (i,j) О E, необходимо пронумеровать узлы графа. Элементы матрицы могут принимать значения 0 или 1. Так как представленный на рисунке граф не имеет ребер исходящих и завершающихся в одном и том же узле (нет петель), диагональные элементы матрицы равны нулю. Единицы присутствуют в позициях, которые соответствуют парам узлов, соединенных ребрами, например, 1-3, 1-4 или 5-2 и 5-3. Число ребер, исходящих из вершины (петля учитывается дважды), называется степенью вершины d(v). В конечном графе число вершин с нечетной степенью всегда четно.
Другой способ представления графа обеспечивает функция, которая выдает списки узлов, с которыми данный узел связан непосредственно. Для графа, отображенного на рис. 10.21.4, такое описание можно представить в виде структуры (таблица 10.21.1). В колонке s представлены номера узлов, далее в строке таблицы следует список соседних узлов. По этой причине число колонок в каждой из строк различно.

Рис. 10.21.4
Таблица 10.21.1.
S |
Список “соседних” узлов | |||
| 1 | 2 | 5 | 6 | |
| 2 | 1 | 3 | ||
| 3 | 2 | 4 | 5 | |
| 4 | 3 | |||
| 5 | 1 | 3 | 6 | 7 |
| 6 | 1 | 5 | 7 | |
| 7 | 5 | 6 |
Граф называется полным, если любые две вершины являются смежными.
Если для всех вершин d(v) = k, то граф называется однородным графом степени k или k-однородным. Граф на рис. 10.21.5 является полным и 3-однородным.

Рис. 10.21.5.
Конечная последовательность ребер графа e1, e2,…,en называется маршрутом длины n. Маршрут называется замкнутым, если вершины начала и конца маршрута совпадают. Если ребра, образующие маршрут различны, то такой маршрут называется цепью.
Граф называется деревом, если он связан и не имеет циклов. Граф является деревом тогда и только тогда, когда каждая пара различных вершин соединяется одной и только одной цепью. Каждое дерево с n вершинами имеет ровно n-1 ребро. Удаление любого ребра в дереве делает его несвязным. По этой причине дерево можно считать минимальным связным графом. Если все вершины графа G принадлежат дереву Т, то считается, что дерево покрывает граф G.
Граф, не имеющий циклов и состоящий из k компонент, называется лесом из k деревьев. Лес из k деревьев, содержащий n вершин имеет в точности n-k ребер.
Пусть G=(v,e) связный граф и FМ E подмножество его ребер. При этом F называется разделяющим подмножеством тогда и только тогда, когда подграф G’=(V, E-F) несвязан. E-F обозначает множество ребер, которое принадлежит Е, но не принадлежит F.
Если узлы графа могут быть соединены несколькими путями, сеть, описываемая таким графом, обладает повышенной надежностью. Рассмотрим задачу выбора оптимального дерева маршрутов, лишенного циклов, в такой сети (см. рис. 10.21.6). Алгоритм используется в схеме “расширяющееся дерево” для локальных сетей со сложной топологией. Алгоритм преобразует многосвязный граф в плоский без замкнутых структур.

Рис. 10.21.6.
В качестве начального выбираем узел 1. Матрица оценки формируется поэтапно (А-E). На этапе А выбирается узел 5, так как к нему ведет ребро с метрикой 1. Здесь становятся доступными ребра, ведущие к узлам 2, 4, 6 и 7. Ребро 1-5 из рассмотрения устраняется. На следующем этапе выбирается узел 7, к нему от узла 5 ведет ребро с метрикой 1. Здесь в рассмотрение включаются ребра 7-4 и 7-8. Следующим выбранным узлом становится 4 и включается в перечень ребро 4-2. Далее рассматривается узел 6 и ребра 6-8 и 6-3.

В результате граф приобретает вид, показанный на рисунке 10.21.7.

Рис. 10.21.7.
Рассмотренный алгоритм сходен с алгоритмом Дикстры, используемым для поиска наилучшего пути во внутреннем протоколе маршрутизации ospf.
Выбранный метод аналитического представления графа достаточно прост, но требует для графа с N узлами N2 ячеек памяти (бит). Впрочем, для неориентированного графа матрица является симметричной и для ее хранения в памяти ЭВМ достаточно N(N-1)/2 ячеек. Это справедливо и для ориентированных графов без петель.
Петлей
называется ребро графа, которое начинается и завершается в одном и том же узле (рис. 10.21.8).
Рис. 10.21.8.
Справедливо следующее утверждение. Узлы i,j соединены путем длиной k тогда и только тогда, когда Ak(i,j)=1.
Надо сказать, что графы являются весьма удобным средством описания и оптимизации алгоритмов вычисления. В качестве примера рассмотрим вычисление квадратного полинома ax2+bx+c по схеме Горнера (рис. 10.21.9).

Рис. 10.21.9. Граф вычисления квадратного полинома по схеме Горнера.
Эталонная сетевая модель ISO
4.3.1 Эталонная сетевая модель ISO
Семенов Ю.А. (ГНЦ ИТЭФ)
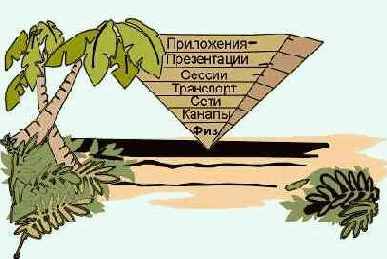
Международная организация по стандартизации (ISO) определила 7-уровневую эталонную сетевую модель для открытых систем (OSI), (Интернет использует 4-х уровневое подмножество). Ниже на рис. 4.3.1.1 показана схема этих уровней, справа записаны коды документов международного Телекоммуникационного союза (ITU), регламентирующих протоколы соответствующих уровней.

Рис. 4.3.1.1. Семиуровневая эталонная модель ISO
Разбиение совокупности (стека) сетевых протоколов по уровням связана с попыткой унификации аппаратного и программного обеспечения. Предполагается, что каждому из уровней соответствует определенная ункциональная программа с жестко заданными входным и выходным интерфейсами. Форматы данных на заданном уровне модели для отправителя и получателя должны быть идентичны. Физический уровень локальных сетей определен документами, например, Ethernet II, IEEE 802.3 и т.д. Модели ISO наиболее полно соответствуют сети X.25.
Физический уровень X.25 определяет стандарт на связь между ЭВМ и сетевыми коммутаторами (X.21), а также на процедуры обмена пакетами между ЭВМ. X.21 характеризует некоторые аспекты построения общественных сетей передачи данных. Следует учитывать, что стандарт X.25 появился раньше рекомендаций ITU-T и опыт его применения был учтен при составлении новейших рекомендаций. На физическом уровне могут использоваться также протоколы X.21bis, RS232 или V.35.
Канальный уровень определяет то, как информация передается от ЭВМ к пакетному коммутатору (HDLC - high data link communication, бит-ориентированная процедура управления), на этом уровне исправляются ошибки, возникающие на физическом уровне.
Сетевой уровень определяет взаимодействие различных частей субсети, форматы пакетов, процедуры повторной передачи пакетов, стандартизует схему адресации и маршрутизации.
Транспортный уровень определяет надежность передачи данных по схеме точка-точка, избавляет уровень сессий от забот по обеспечению надежной и эффективной передачи данных.
Уровень сессий описывает то, как протокольное программное обеспечение должно организовать обеспечение выполнения любых прикладных программ. Организует двухстороннее взаимодействие сетевых объектов и необходимую синхронизацию процедур.
Презентационный уровень обеспечивает прикладной уровень стандартными услугами (сжатие информации, поддержка ASN.1 (abstract syntax notation 1) управляющих протоколов и т.д.).
Прикладной уровень - это все, что может понадобиться пользователям сетей, например X.400.
Международным стандартом в процедуре HDLC определены два вида кадров:
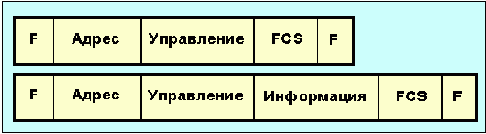
Рис. 4.3.1.2 Два вида кадров процедур HDLC
Флаг f = 01111110 задает границы кадра, SCS - контрольная сумма. Поля информация может иметь переменную длину, кратную восьми бит. Для HDLC определены три класса кадров: информационные (I), управляющие (S -supervisory) и ненумерованные (U - unnumbered). (Эти форматы соответствуют канальному уровню протокола x.25). Формат поля управление I-кадра показан на рис. 4.3.1.3.

Рис. 4.3.1.3. Формат поля управления I-кадра (нумерация по модулю 128)
\
N(S) и N(S) представляют собой поля номера кадров. N(R) - номер текущего кадра, а N(R) - номер следующего кадра, который отправитель текущего кадра ожидает получить. При несоответствии ожидаемого номера и полученного возникает ошибка. Если используется нумерация кадров по модулю 8, то максимальное число кадров, не получивших подтверждение не может превышать 7, а размер полей N(S) и N(R) равен трем бит. Это справедливо и для s-кадров. i, s и u-кадры могут иметь обычный (один байт) и расширенный (2 байта) форматы. Младший бит (1) расположен слева. Поле P/F - флаг опрос/окончание опроса. Информационный (I) кадр содержит поле информация (см. рис. 4.3.1.2). Формат S- кадра показан на рис. 4.3.1.4.

Рис. 4.3.1.4. Формат поля управления s-кадра (расширенный вариант)
Для однобайтовой версии s-кадра за полем s следует непосредственно поле P/F. Поле S определяет тип управляющего кадра (см. таблицу 4.3.1.1):
Таблица 4.3.1.1. Коды поля S
Код s-поля
Назначение

Рис. 4.3.1.5. Формат поля управления U-кадра
U-кадр используется для формирования канала, изменения режима работы и управления системой передачи данных. Существует версия, когда поле “0” размещается не в 8-ой позиции, а в 5-ой. В нижней части рисунка показана расширенная версия формата. Младшие разряды располагаются слева. Поле m может принимать значения, приведенные в таблице 3.5.1.2.
Установление соединения начинается с передачи в канал команды SABM (или SABME). Если удаленной станцией эта команда принята правильно и имеется возможность установления соединения, то присылается отклик UA. При этом переменные состояния на удаленной станции V(S) и V(R) (аналоги полей N(S) и N(R) в пакетах) устанавливаются в нулевое состояние.
Таблица 4.3.1.2. Коды поля M (U-кадр).
Код поля М |
Мнемоника |
Назначение |
| 00000 | UI | Ненумерованная информация |
| 00001 | SNRM | Установка нормального отклика (set normal regime mode) |
| 00010 | DISC/RD | Отсоединение (disconnect / request disconnect) |
| 00100 | up | Ненумерованный запрос передачи (unnumbered poll) |
| 00110 | ua | Ненумерованный отклик (unnumbered acknowledgment) |
| 00111 | test | Тестирование системы передачи данных |
| 10000 | SIM/RIM | Установка режима асинхронного отклика (set initialization mode / request initialization mode) |
| 10001 | FRMR | Отклонение кадра (frame reject) |
| 11000 | SARM/DM | Установка режима асинхронного отклика (set asynchronous acknowledgment regime mode / disconnect mode) |
| 11001 | RSET | Сброс (возврат в исходное состояние) |
| 11010 | SARME | SARM с расширенной нумерацией |
| 11011 | SNRME | snrm с расширенной нумерацией |
| 11100 | SAMB | Установка асинхронного сбалансированного режима |
| 11101 | XID | Идентификация коммутатора (exchange identifier) |
| 11110 | SABME | SABM с расширенной нумерацией |
/p> После благополучного получения пакета ua локальной станцией соединение считается установленным и может начинаться обмен данными. Информацию несут кадры типа I, а также FRMR и UI-кадры типа U. В кадре ответа FRMR должно присутствовать информационное поле, содержащее обоснование присылки такого ответа. Структура этого поля для обычного и расширенного (внизу) форматов показана на рис. 4.3.1.6.
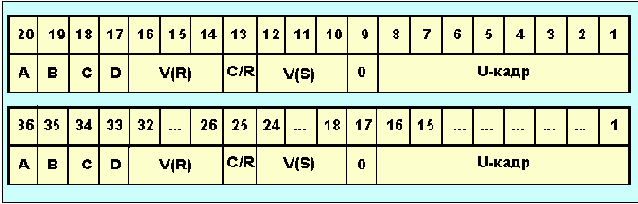
Рис. 4.3.1.6. Структура информационного поля для FRMR-кадров
Биты A, B, C и D определяют причину, по который кадр не был доставлен. Если бит равен 1, то это указывает на соответствующую причины недоставки. Бит A указывает на неверное значение N(R). Бит B =1 говорит о слишком большой длине информационного поля. Бит C - указывает на то, что поле управления неопределенно из-за наличия в кадре недопустимой для данной команды или отклика информационного поля, а D=1 означает, что поле управления принятого кадра не определено или же неприемлемо. V(R) и V(S) текущие значения переменных приема и передачи, соответственно. C/R (Command/Response) =1 означает, что ошибочное сообщение является откликом (=0 - командой). Большинство U-кадров интерпретируются как команды или отклики в зависимости от контекста и того, кто их послал. В некоторых случаях для разделения откликов и команд используется поле адреса. Одним из наиболее известных протоколов сетевого уровня, использующих HDLC, является X.25.
Кабельные каналы связи
3.1 Кабельные каналы связи
Семенов Ю.А. (ГНЦ ИТЭФ)

Кабельные каналы для целей телекоммуникаций исторически использовались первыми. Да и сегодня по суммарной длине они превосходят даже спутниковые каналы. Основную долю этих каналов, насчитывающих многие сотни тысяч километров, составляют телефонные медные кабели. Эти кабели содержат десятки или даже сотни скрученных пар проводов. Полоса пропускания таких кабелей обычно составляет 3-3,5 кГц при длине 2-10 км. Эта полоса диктовалась ранее нуждами аналогового голосового обмена в рамках коммутируемой телефонной сети. c учетом возрастающих требованиям к широкополосности каналов скрученные пары проводов пытались заменить коаксиальными кабелями, которые имеют полосу от 100 до 500 МГц (до 1 Гбит/с), и даже полыми волноводами. Именно коаксиальные кабели стали в начале транспортной средой локальных сетей ЭВМ (10base-5 и 10base-2; см. рис. 3.1.1).

Рис. 3.1.1. 1 – центральный проводник; 2 – изолятор; 3 – проводник-экран; внешний изолятор
Коаксиальная система проводников из-за своей симметричности вызывает минимальное внешнее электромагнитное излучение. Сигнал распространяется по центральной медной жиле, контур тока замыкается через внешний экранный провод. При заземлении экрана в нескольких точках по нему начинают протекать выравнивающие токи (ведь разные “земли” обычно имеют неравные потенциалы). Такие токи могут стать причиной внешних наводок (иной раз достаточных для выхода из строя интерфейсного оборудования), именно это обстоятельство является причиной требования заземления кабеля локальной сети только в одной точке. Наибольшее распространение получили кабели с волновым сопротивлением 50 ом. Это связано с тем, что эти кабели из-за относительно толстой центральной жилы характеризуются минимальным ослаблением сигнала (волновое сопротивление пропорционально логарифму отношения диаметров внешнего и внутреннего проводников). Но по мере развития технологии скрученные пары смогли вытеснить из этой области коаксиальные кабели. Это произошло, когда полоса пропускания скрученных пар достигла 200-350 МГц при длине 100м (неэкранированные и экранированные скрученные пары категории 5 и 6), а цены на единицу длины сравнялись. Скрученные пары проводников позволяют использовать биполярные приемники, что делает систему менее уязвимой (по сравнению с коаксиальными кабелями) к внешним наводкам. Но основополагающей причиной вытеснения коаксиальных кабелей явилась относительная дешевизна скрученных пар. Скрученные пары бывают одинарными, объединенными в многопарный кабель или оформленными в виде плоского ленточного кабеля. Применение проводов сети переменного тока для локальных сетей и передачи данных допустимо для весьма ограниченных расстояний. В таблице 3.1.1 приведены характеристики каналов, базирующихся на обычном и широкополосном коаксиальном кабелях.
Таблица 3.1.1
При диагностировании сетей не всегда под руками может оказаться настоящий сетевой тестер типа WaveTek, и часто приходится довольствоваться обычным авометром. В этом случае может оказаться полезной таблица 3.1.2, где приведены удельные сопротивления используемых сетевых кабелей. Произведя измерение сопротивления сегмента, вы можете оценить его длину.

Рис. 3.1.2. Зависимость ослабления сигнала в кабеле от его частоты
Таблица 3.1.2 Сопротивление кабеля по постоянному току
Эти данные взяты из Handbook of LAN Cable Testing. Wavetek Corporation, California
.
| Скрученная пара | Ом/100 м |
| 24 AWG | 18,8 |
| 22 AWG | 11,8 |
Таблица 3.1.3. Новые европейские стандарты для скрученных пар (CENELEC)
| Стандарт | Назначение |
Экран |
Полоса пропускания |
| EN 50288-2-1 | Для магистральной прокладки | + | < 100 МГц (кат. 5) |
| EN 50288-2-2 | Для подключения приборов и коммутации | + | < 100 МГц (кат. 5) |
| EN 50288-3-1 | Для магистральной прокладки | - | < 100 МГц (кат. 5) |
| EN 50288-3-2 | Для подключения приборов и коммутации | - | < 100 МГц (кат. 5) |
| EN 50288-4-1 | Для магистральной прокладки | + | < 600 МГц (кат. 7) |
| EN 50288-4-2 | Для подключения приборов и коммутации | + | < 600 МГц (кат. 7) |
| EN 50288-5-1 | Для магистральной прокладки | + | < 250 МГц (кат. 6) |
| EN 50288-5-2 | Для подключения приборов и коммутации | + | < 250 МГц (кат. 6) |
| EN 50288-6-1 | Для магистральной прокладки | - | < 250 МГц (кат. 6) |
| EN 50288-6-2 | Для подключения приборов и коммутации | - | < 250 МГц (кат. 6) |
/p> Таблица 3.1.3A. Обзор категорий кабелей со скрученными парами проводов (ISO/IEC 11801 = EN 50173)
| Категория | Полоса пропускания |
Применения |
| 3 | до 16 МГц | Ethernet, Token Ring, телефон |
| 4 | до 20 МГц | Ethernet, Token Ring, телефон |
| 5 | до 100 МГц | Ethernet, ATM, FE,Token Ring, телефон |
| 6 | до 200/250 МГц | GigaEthernet,Ethernet, FE, ATM, Token Ring |
| 7 | до 600 МГц | GigaEthernet,Ethernet, FE, ATM, Token Ring |
| Класс | Применение |
A | Голос и сетевые приложения до 100 кГц |
B | Информационные приложения до 1 МГц |
С | Информационные приложения до 16 МГц |
В | Информационные приложения до 100 МГц |
E | Информационные приложения до 200/250 МГц |
F | Информационные приложения до 600 МГц |
LWL | Информационные приложения от 10 МГц |
| Стандарт | Экран |
Полоса пропускания |
| EN 60603-7-2 | - | < 100 МГц (кат. 5) |
| EN 60603-7-3 | + | < 100 МГц (кат. 5) |
| EN 60603-7-4 | - | < 250 МГц (кат. 6) |
| EN 60603-7-5 | + | < 250 МГц (кат. 6) |
| EN 60603-7-7 | + | < 600 МГц (кат. 7) |
[МГц]
Данные, приведенные в таблице 3.1.2, могут использоваться для оперативной предварительной оценки качества кабельного сегмента (соответствует стандарту EIA/TIA 568, 1991 год). Частотные характеристики неэкранированных пар категории 6 представлены в табл. 3.1.5`.
Таблица 3.1.5. Параметры неэкранированных пар категории 6
| Частота, МГц | Затухание, дБ/100м | NEXT, дБ | ACR, дБ/100м |
| 1 | 2,3 | 62 | 60 |
| 10 | 6,9 | 47 | 41 |
| 100 | 23,0 | 38 | 23 |
| 300 | 46,8 | 31 | 4 |
ACR - Attenuation-to-Crosstalk Ratio.
NEXT - Near End CrossTalk.
Кабели, изготовленные из скрученных пар категории 5 (волновое сопротивление 100,15 Ом), с полосой 100 Мгц обеспечивают пропускную способность при передаче сигналов ATM 155 Мбит/с. При 4 скрученных парах это позволяет осуществлять передачу до 622 Мбит/с. Кабели категории 6 сертифицируются до частот 300 Мгц, а экранированные и до 600 Мгц (волновое сопротивление 100 Ом). В таблице 3.1.6 приведены данные по затуханию и перекрестным наводкам. Приведены характеристики такого кабеля с 4-мя скрученными экранированными парами (S-FTP).
Таблица 3.1.6
NEXT - Near End Cross Talk - перекрестные наводки ближнего конца кабеля.
ACR - Attenuation-to Crosstalk Ratio.
Такой кабель пригоден для передачи информации со скоростью более 1 Гбит/с. ACR - Attenuation-to-Crosstalk Ratio (отношение ослабления к относительной величине перекресных наводок).
Ниже на рис. 3.1.3 показана зависимость наводок на ближнем конце кабеля, содержащего скрученные пары, (NEXT – Near End CrossTalk) от частоты передаваемого сигнала.

Рис. 3.1.3. Зависимость наводок NEXT от частоты передаваемого сигнала.
На рис. 3.1.4 представлена зависимость ослабления сигнала в неэкранированной скрученной паре (именно такие кабели наиболее часто используются для локальных сетей) от частоты передаваемого сигнала. Следует иметь в виду, что при частотах в области сотен мегагерц и выше существенный вклад начинает давать поглощение в диэлектрике. Таким образом, даже если проводники изготовить из чистого золота, существенного продвижения по полосе пропускания достичь не удастся.

Рис. 3.1.4. Зависимость ослабления сигнала от частоты для неэкранированной скрученной пары
Для неэкранированной скрученной пары 5-ой категории зависимость отношения сигнал-шум от длины с учетом ослабления и наводок NEXT показана на рис. 3.1.5.

Рис. 3.1.5 Зависимость отношения сигнал/шум от частоты с учетом ослабления и наводок на ближнем конце кабеля
Характеристики неэкранированных скрученных пар американского стандарта 24 AWG (приведены характеристики кабелей, используемых при построении локальных сетей) для кабелей различной категории собраны в таблице 3.1.7.
Таблица 3.1.7.
| Категория кабеля | Сопротивление по постоянному току (L=300м) |
Ослабление [дБ] |
NEXT [дБ] |
| III | 28,4 |
17 @ 4 МГц 30 @ 10 МГц 40 @ 16 МГц |
32 @ 4 МГц 26 @ 10 МГц 23 @ 16 МГц |
| IV | 28,4 |
13 @ 4 МГц 22 @ 10 МГц 27 @ 16 МГц 31 @ 20 МГц |
47 @ 4 МГц 41 @ 10 МГц 38 @ 16 МГц 36 @ 20 МГц |
| V | 28,4 |
13 @ 4 МГц 20 @ 10 МГц 25 @ 16 МГц 28 @ 20 МГц 67 @ 100 МГц |
53 @ 4 МГц 47 @ 10 МГц 44 @ 16 МГц 42 @ 20 МГц 32 @ 100 МГц |
Канальный протокол Fibre Channel
4.1.12 Канальный протокол Fibre Channel
Семенов Ю.А. (ГНЦ ИТЭФ)
www.prz.tu-berlin.de/docs/html/EANTC/INFOSYS/fibrechannel/detail
, http://www.fibrechannel.com/technology/physical.htm и http://www.ancor.com. http://www.iol.unh.edu/training/fc/fc_tutorial.html. Последний уже сейчас превосходит по быстродействию существующие сети в 10-100 раз. Он легко стыкуется с протоколами локальных и региональных сетей. Fibre Channel имеет уникальную систему физического интерфейса и форматы кадров, которые позволяют этому стандарту обеспечить простую стыковку с канальными протоколами IPI (Intelligent Peripheral Interface), SCSI, HIPPI, ATM, IP и 802.2. Это позволяет, например, организовать скоростной канал между ЭВМ и дисковой накопительной системой RAID. Быстродействие сетей Fibre Channel составляет nґ 100Мбайт/с при длинах канала 10 км и более. Предусмотрена работа и на меньших скоростях (например, 12,5 Мбайт/c). Предельная скорость передачи составляет 4,25 Гбод. В качестве транспортной среды может использоваться одномодовое или мультимодовое оптическое волокно. Допускается применение медного коаксиального кабеля и скрученных пар (при скоростях до 200 Мбайт/с). Fibre Channel имеет шесть независимых классов услуг (каждый класс представляет определенную стратегию обмена информацией), которые облегчают решать широкий диапазон прикладных задач:Fibre Channel превосходит другие сети и по некоторым экономическим параметрам (см. табл. 4.1.12.1).
Таблица 4.1.12.1 (www.ancor.com/ctspr97.htm )
Сеть |
Стоимость за Мбит/сек |
| fddi | 109,1$ США |
| Fast Ethernet | 12,8 $ |
| ATM | 23,8$ |
| Fibre Channel | 9,5$ |
Формат пакетов в сетях Fibre Channel показан на рис. 4.1.12.1. Здесь используются 24-битовые адреса, что позволяет адресовать до 16 миллионов объектов. Сеть может строить соединения по схеме точка-точка, допускается и кольцевая архитектура с возможностью арбитража (FC-al) и другие схемы (например, “ткань соединений” (fabric), допускающее большое число независимых обменов одновременно). Схема кольцевого соединения показана на рис. 4.1.12.2. К кольцу может быть подключено до 128 узлов. Протокол Fibre Channel предусматривает 5 уровней, которые определяют физическую среду, скорости передачи, схему кодирования, форматы пакетов, управление потоком и различные виды услуг. На физическом уровне (FC-ph 1993 год) предусмотрены три подуровня. FC использует оптические волокна диаметром 62,5, 50мкм и одномодовые. Для обеспечения безопасности предусмотрен опционный контроль подключенности оптического разъема (OFC). Для этого передатчик время от времени посылает короткие световые импульсы приемнику. Если приемник получает такой импульс, процесс обмена продолжается.
FC-0 определяет физические характеристики интерфейса и среды, включая кабели, разъемы, драйверы (ECL, LED, лазеры), передатчики и приемники. Вместе с FC-1 этот уровень образует физический слой.
FC-1 определяет метод кодирования/декодирования (8B/10B) и протокол передачи, где объединяется пересылка данных и синхронизирующей информации.
FC-2 определяет правила сигнального протокола, классы услуг, топологию, методику сегментации, задает формат кадра и описывает передачу информационных кадров.
FС-3 определяет работу нескольких портов на одном узле и обеспечивает общие виды сервиса.
FC-4 обеспечивает реализацию набора прикладных команд и протоколов вышележащего уровня (например, для SCSI, IPI, IEEE 802, SBCCS, HIPPI, IP, ATM и т.д.)
FC-0 и FC-1 образуют физический уровень, соответствующей стандартной модели ISO.

Рис. 4.1.12.1. Формат пакета Fibre Channel
Стандарт FC допускает соединение типа точка-точка, арбитражное кольцо и структура (верх, середина и низ рисунка 4.1.12.2). Кольцевая архитектура обеспечивает самое дешевое подключение. Система арбитража допускает обмен только между двумя узлами одновременно. Следует учесть, что кольцевая структура не предполагает применения маркерной схемы доступа. Когда подключенное к сети устройство готово передать данные, он передает сигнал-примитив ARBX, где X - физический адрес устройства в кольце арбитража (al_pa). Если устройство получит свой собственный сигнал-примитив ARBX, оно получает контроль над кольцом и может начать передачу. Инициатор обмена посылает сигнал-примитив open (OPN) и устанавливает связь с адресатом. Время удержания контроля над кольцом не лимитируется. Если контроль над кольцом одновременно пытаются захватить два устройства, сравниваются значения X сигналов ARB. Устройство с меньшим al_pa получает преимущество, прибор с большим al_pa блокируется.
Прежде чем использовать кольцо его нужно инициализировать (процедура LIP), так чтобы каждый порт получил свой физический адрес (al_pa - один октет, что и определяет макcимальное число портов в кольце арбитража). Процедура инициализации начинается сразу после включения питания посылкой сигнала-примитива LIP через порт l_port. Затем осуществляется выбор устройства, которое будет управлять процессом выбора al_pa.

Рис. 4.1.12.2. Типы топологии FC
Перед передачей октеты преобразуются в 10- битовые кодовые последовательности, называемые символами передачи (кодировка IBM 8B/10B). Логической единице соответствует больший уровень световой энергии. В Fibre Channel предусмотрено два режима обмена буфер-буфер и точка-точка (end-to-end). Передача данных осуществляется только когда принимающая сторона готова к этому. Прежде чем что-либо посылать стороны должны выполнить операцию login. В ходе выполнения login определяется верхний предел объема пересылаемых данных (credit). Значение параметра credit задает число кадров, которые могут быть приняты. После передачи очередного кадра значение credit уменьшается на единицу. Когда значение этой переменной достигает нуля, дальнейшая передача блокируется до тех пор, пока получатель не обработает один или более кадров и будет готов продолжить прием. Здесь имеет место довольно тесная аналогия с окнами в протоколе TCP. Режим обмена буфер-буфер предполагает установление связи между портами N_Port и F_Port или между двумя N_Port. При установлении соединения каждая из сторон сообщает партнеру, сколько кадров она готова принять (значение переменной BB_Credit). Режим точка-точка (end-to-end) реализуется между портами типа N_Port. Предельное число кадров, которые сторона может принять, задается переменной EE_Credit. Эта переменная устанавливается равной нулю при инициализации, увеличивается на единицу при передаче кадра и уменьшается при получении кадра ACK Link Control. Кадр ACK может указывать на то, что порт получил и обработал один кадр, N кадров или всю последовательность кадров. Смотри также "Definitions of Managed Objects for the Fabric Element in Fibre Channel Standard". K. Teow. May 2000, RFC-2837.
Каналы передачи данных
3 Каналы передачи данных
Семенов Ю.А. (ГНЦ ИТЭФ)

За последние двадцать лет пропускная способность каналов выросла с 56 кбит/c до 1 Гбит/с. Разработаны технологии, способные работать в случае оптических кабелей со скоростью 50 Тбит/с. Вероятность ошибки при этом сократилась с 10-5 на бит до пренебрежимо низкого уровня. Современный же лимит в несколько Гбит/с связан главным образом с тем, что люди не научились делать быстродействующие преобразователи электрических сигналов в оптические.
Кодировщики голоса (Vocoder)
2.4.2 Кодировщики голоса (Vocoder)
Семенов Ю.А. (ГНЦ ИТЭФ)
Эта технология находит применение в военных системах связи, в диспетчерских службах, а также в системах пейджерной связи. Разработчики преобразователей голоса учли особенности работы горла, голосовых связок и всего речевого аппарата. Звонкие и глухие звуки воспроизводятся здесь различными способами (с помощью импульсного генератора и генератора шума, соответственно). Блок-схема преобразователя звука типа вокодер показана на рис. 2.4.2.1. Исходный спектр человеческого голоса здесь делится на ряд субдиапазонов (на рис. 2.4.2.1 их число равно16) по 200 Гц каждый. Эти субдиапазоны выделяются узкополосными фильтрами, за которыми следуют выпрямители и фильтры низких частот (20 Гц). Выходные сигналы этих фильтров мультиплексируются и преобразуются в цифровую форму. Частота стробирования этих сигналов составляет примерно 50 Гц. Разрядность АЦП в этом случае может составлять 3 бита. На принимающей стороне осуществляется цифро-аналоговое преобразование (ЦАП) и мультиплексирование. Сбалансированные амплитудные модуляторы, управляемые ЦАП и переключателем, выдают сигналы на узкополосные фильтры. Все эти сигналы смешиваются в сумматоре, а результат воспроизводится.
Не трудно видеть, что в случае схемы, показанной на рис. 2.4.2.1, необходимое быстродействие передающей линии составляет 3 бита * 50 Гц * 16 каналов = 2,4 Кбит/с. Дальнейший выигрыш может быть получен за счет цифрового сжатия. Число каналов (фильтров) и ширина пропускаемой полосы частот может варьироваться, соответственно будет меняться и качество воспроизведения звука. Минимально возможная полоса пропускания передающей линии, при которой значение передаваемого текста еще воспринимается правильно, лежит ниже 1 Кбит/с.
Предшествующая фраза, включая пробелы и знаки препинания, содержит около 150 символов. Для ее произношения требуется около 10 сек (15 символов в сек). Но даже вокодеру потребуется для этого предложения передать не менее 10000 бит. Откуда такое отличие? Во-первых, человеческая речь индивидуальна и эта фраза, произнесенная разными людьми, будет звучать по-разному, кроме того, существует эмоциональная окраска, которой практически лишена буквенная запись. Во-вторых, даже самая совершенная современная система сжатия звуковой информации не идеальна и остается широкое поле для дальнейшего совершенствования. Пути могут быть разными в зависимости от поставленной задачи. Если требуется передать только информацию, следует преобразовать звук в символьную (буквенную) форму, передать эти данные в цифровом виде, а на принимающей стороне осуществить обратное преобразование. Само буквенное представление может быть также подвергнуто некоторому сжатию, но это неизбежно увеличит задержку воспроизведения. В сущности, данная схема является развитием идей, заложенных в вокодере.
В случае необходимости передачи индивидуальных особенностей голоса, сначала должен проводиться анализ этих персональных отличий. Особенности голоса в закодированном виде передаются принимающей стороне, где эти данные используются в дальнейшем при воспроизведении закодированного текста. Эти схемы потребуют довольно мощных сигнальных процессоров и, вероятно, найдут применение лишь в следующем веке.

Рис. 2.4.2.1. Блок-схема кодирования/декодирования человеческого голоса (Vocoder)
Коды протоколов в Ethernet II
10.2 Коды протоколов в Ethernet II
Семенов Ю.А. (ГНЦ ИТЭФ)
Десятичный код
Hex
Описание
Коммутируемая мультимегабитная информационная служба SMDS
4.1.13 Коммутируемая мультимегабитная информационная служба SMDS
Семенов Ю.А. (ГНЦ ИТЭФ)
Коммутируемая мультимегабитная информационная служба SMDS (Switched Multimegabit Data Service; RFC-1209, -1694) создана для объединения большого числа локальных сетей. Система была разработана в 80-е годы и реализована в начале 90-х годов. Система SMDS функционирует как высокоскоростная опорная сеть, транспортирующая пакеты от одной локальной сети к другой. SMDS рассчитана на большие краткосрочные всплески трафика. При N локальных сетях, соединенных выделенными каналами, полносвязная схема их соединения требует N(N-1)/2 каналов (см. рис. .1А). Для системы SMDS требуется только N каналов до ближайшего SMDS-маршрутизатора (рис. .1В).

Рис. .1. Разные варианты объединения локальных сетей
Быстродействие системы SMDS составляет 45 Мбит/с. Система SMDS использует передачу данных без установления соединения. Формат пакета SMDS показан на рис. .2.

Рис. .2. Формат SMDS-пакета
Адреса места назначения и отправителя состоят из 4-битного кода, за которым следует телефонный номер, содержащий до 15 десятичных чисел. Каждая цифра кодируется посредством четырех бит. Телефонный номер содержит код страны, код зоны и номер клиента-подписчика, что делает сеть SMDS международной. Длина поля данные является переменной. Когда пакет попадает в сеть SMDS, первый маршрутизатор проверяет, соответствует ли адрес отправителя номеру входной линии. При несоответствии пакет отбрасывается.
Существенной особенностью SMDS является возможность мультикастинга. Пользователь может составить список номеров и присвоить ему специфический адрес. Отправка пакета по этому адресу вызовет его переадресацию всем клиентам, чьи адреса присутствуют в списке. Это воспроизведение на сетевом уровне возможности почтового списка рассылки.
Другой особенностью адресации в SMDS является возможность использования списков доступа (screening) для входящих и исходящих пакетов. Кроме того, такая функция позволяет эффективно строить корпоративные сети типа Интранет. Поле данных может содержать в себе кадр Ethernet или пакет Token Ring, что также повышает эффективность и надежность работы сети, упрощая задачу интерфейсного оборудования.
Работа в условиях всплесков загрузки осуществляется следующим образом. Маршрутизатор в каждом из интерфейсов содержит счетчик, который инкрементируется с постоянной частотой (например, раз в 10 мксек). Когда на вход маршрутизатора приходит пакет, осуществляется сравнение длины пакета в байтах с содержимым этого счетчика. Если содержимое счетчика больше, пакет немедленно пересылается, а содержимое счетчика уменьшается на длину пакета. Если длина пакета больше содержимого счетчика, такой пакет отбрасывается. В результате при данной частоте приращения счетчика в среднем допускается передача 100000 байт/сек. Но импульсная загрузка может существенно превышать это значение.
Конфигурирование сетевых систем
5.5 Конфигурирование сетевых систем
Семенов Ю.А. (ГНЦ ИТЭФ)
Таблица 5.5.1. Конфигурационные файлы
Название файла
Назначение
Файл /usr/lib/aliases используется для создания почтовых ящиков, которым не соответствуют какие-либо аккоунты. Здесь прописываются псевдонимы, которым система пересылает поступающие почтовые сообщения. Строка переадресации в этом файле имеет форму:
alias: имя_пользователя или
alias: имя_пользователя_1, имя_пользователя_2, ..., имя_пользователя_N.
В первом случае вся почта приходящая alias переадресуется пользователя с указанным именем. Во втором - всем пользователям, имена которых представлены в списке. Если список не умещается в одной строке, перед вводом "возврата каретки" следует напечатать символ "/". В качестве аккоунтов могут использоваться как локальные так и стандартные почтовые адреса. Для особо длинных списков можно ввести специальную строку в файл /usr/lib/aliases:
authors:":include:/usr/local/lib/authors.list", где authors - псевдоним, а authors.list - файл, содержащий список адресатов, кому следует переслать сообщение.
Наиболее мощной и по этой причине наиболее опасной возможностью файла псевдонимов является переадресация входной почты программе, указанной в псевдониме. Когда первым символом имени аккоунта в псевдониме является вертикальная черта (|), то управление будет передано программе, чье имя следует за этим символом, а входные почтовые сообщения будут передаваться этой программе, например строка:
listserv: "|/usr/local/bin/listserv -l"
обеспечит пересылку почты программе listserv, как если бы исполнялась команда cat mailfile|listserv -l. Эта техника используется для интерпретации содержимого поля subject или тела сообщения в качестве команд управления подписными листами.
Файл named.boot, который служит для инициализации сервера имен, имеет следующую структуру. Строки, начинающиеся с точки с запятой являются комментариями. Строка sortlist определяет порядок, в котором выдаются адреса сервером, если их число в отклике превышает 1. Запись directory, описывает положение информационных файлов (имя проход/каталога). Строка cashe, служит для инициализации кэша сервера имен с использованием файла named.ca. Этот также как и другие файлы должны находиться в каталоге, указанном в записи directory. Записи primary указывают, в каких файлах размещена информация таблиц соответствия имен и IP-адресов. Последняя запись primary содержит информацию для локальной ЭВМ. В записях secondary специфицируется данные, которые должны считываться с первичного сервера и из локальных файлов.
В файле named.local содержится локальный интерфейс обратной связи сервера имен. Файл включает в себя только одну запись SOA (Start of Authority) и две ресурсных записи. Запись SOA определяет начало зоны. Символ @ в начале первого поля записи задает имя зоны. Четвертое поле этой записи содержит имя первичного сервера имен данного субдомена, а следующее поле хранит имя администратора, ответственного за данный субдомен (его почтовый адрес). Запись SOA включает в себя список из 5 чисел, заключенный в скобки.
Версия или серийный номер. Первое число в списке увеличивается каждый раз при актуализации файла. Вторичные серверы имен проверяют и сравнивают номер версии файла первичного сервера с имеющимся у них кодом, для того чтобы определить, следует ли копировать базу данных DNS.
Время обновления (refresh time). Определяет время в секундах, задающее период запросов вторичного DNS к первичному.
Время повторной попытки. Задает время в секундах, когда вторичный сервер имен может повторить запрос в случае неудачи предыдущего.
Время истечения пригодности (expiration time). Верхний предел временного интервала в секундах по истечении которого база данных вторичного DNS считается устаревшей без проведения актуализации.
Минимум. Значение по умолчанию для таймера TTL для экспортируемых ресурсных записей.
Файл /etc/hosts.equiv позволяет составить список ЭВМ, объединенных в группу. Пользователь, находящийся в одной из ЭВМ этой группы, может установить связь с другой, не вводя своего пароля. Понятно, что применение этого метода входа, предоставляя некоторые удобства, создает и определенные угрозы с точки зрения сетевой безопасности.
Файл .rhosts, который размещается в корневом каталоге пользователя, позволяет ему описать список ЭВМ, куда он имеет доступ. При этом появляется возможность войти из данной ЭВМ в любую из названных машин без ввода пароля. Замечания об использовании файла hosts.equiv в полном объеме справедливы и в данном случае.
Если к ЭВМ подключены модемы, необходимо применение так называемого dialup-пароля. Удаленный пользователь помимо своего ID и пароля должен ввести еще и dialup-пароль, который является общим для всех работающих на данной ЭВМ. Если все три параметра аутентификации корректны, доступ будет разрешен. При ошибке в любом из трех компонентов ЭВМ попросит повторить их ввод, не указывая, где совершена ошибка. Файл /etc/dpasswd является исполняемым и может реализовать ряд опций.
a [список] характеризует список терминалов, который добавляется к /etc/dialups. Пользователь при входе с такого терминала должен будет ввести пароль dialup. Элементы в списке заключаются в кавычки и разделяются пробелами или запятыми.
d [список] определяет список терминалов, которые должны быть удалены из /etc/dialups и пользователю будет не нужно в будущем вводить пароль dialup при входе с этих терминалов.
r [список] меняет login shell на /bin/sh для каждого из пользователей, перечисленных в списке.
s [shell] модифицирует запись в файле /etc/d_passwd или добавляет новую запись.
u [список] создает новое ядро (shell) для имен, указанных в списке. Добавляются записи в etc/d_passwd для нового ядра, а пароль работает для всех пользователей из списка, если не оговорено обратного.
x [shell] удаляет shell и пароль из файла /etc/d_passwd
Коррекция ошибок
2.8 Коррекция ошибок
Семенов Ю.А. (ГНЦ ИТЭФ)

Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещенные процесса: обнаружение ошибки и определение места (идентификация сообщения и позиции в сообщении). После решения этих двух задач, исправление тривиально – надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7) используемый при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7+4=11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 не трудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7).
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XOR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11 = | 1011 | ||
| 10 = | 1010 | ||
| 09 = | 1001 | ||
| 05 = | 0101 | ||
| 03 = | 0011 | ||
| s = | 1110 |
/p> Таким образом, приемник получит код:
| Позиция бита: | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Значение бита: | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 08 = | 1000 |
| 05 = | 0101 |
| 04 = | 0100 |
| 03 = | 0011 |
| 02 = | 0010 |
| s = | 0000 |
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 08 = | 1000 |
| 07 = | 0111 |
| 05 = | 0101 |
| 04 = | 0100 |
| 03 = | 0011 |
| 02 = | 0010 |
| s = | 0111 |
В общем случае код имеет N=M+C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М=4, а N=7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4
С2 = М1 + М3 + М4
С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1
С12 = С2 + М4 + М3 + М1
С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом.
| С11 | С12 | С13 | Значение |
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет | 0 | 0 | 1 | Бит С3 не верен |
| 0 | 1 | 0 | Бит С2 не верен |
| 0 | 1 | 1 | Бит М3 не верен> |
| 1 | 0 | 0 | Бит С1 не верен> |
| 1 | 0 | 1 | Бит М2 не верен |
| 1 | 1 | 0 | Бит М1 не верен |
| 1 | 1 | 1 | Бит М4 не верен |
/p> Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N – число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
Можно доказать, что для исправления ошибок с кратностью не более qmm (как правило, оно выбирается равным D = 2qm +1). В теории кодирования существуют следующие оценки максимального числа N n-разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 |
n 2n /(1+n) |
| d=2q+1 |
 |
k= n – log(n+1),
откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Циклические коды
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-Hocquenghem). Это коды с широким выбором длины и возможностей исправления ошибок. Циклические коды характеризуются полиномом g(x) степени n-k, g(x) = 1 + g1x + g2x2 + … + xn-k. g(x) называется порождающим многочленом циклического кода. Если многочлен g(x) n-k и является делителем многочлена xn + 1, то код C(g(x)) является линейным циклическим (n,k)-кодом. Число циклических n-разрядных кодов равно числу делителей многочлена xn + 1.
При кодировании слова все кодовые слова кратны g(x). g(x) определяется на основе сомножителей полинома xn +1 как:
xn +1 = g(x)h(x)
Например, если n=7 (x7+1), его сомножители (1 + x + x3)(1 + x + x2 + x4), а g(x) = 1+x + x3.
Чтобы представить сообщение h(x) в виде циклического кода, в котором можно указать постоянные места проверочных и информационных символов, нужно разделить многочлен xn-kh(x) на g(x) и прибавить остаток от деления к многочлену xn-kh(x). См. Л.Ф. Куликовский и В.В. Мотов, “Теоретические основы информационных процессов”. Москва “Высшая школа” 1987. Привлекательность циклических кодов заключается в простоте аппаратной реализации с использованием сдвиговых регистров.
Пусть общее число бит в блоке равно N, из них полезную информацию несут в себе K бит, тогда в случае ошибки, имеется возможность исправить m бит. Таблица 2.8.1 содержит зависимость m от N и K для кодов ВСН.
Таблица 2.8.1
| Общее число бит N | Число полезных бит М | Число исправляемых бит m |
| 31 | 26 | 1 |
| 21 | 2 | |
| 16 | 3 | |
| 63 | 57 | 1 |
| 51 | 2 | |
| 45 | 3 | |
| 127 | 120 | 1 |
| 113 | 2 | |
| 106 | 3 |
Таблица 2.8.2
| Число полезных бит М | Число избыточных бит (n-m) | ||
| 6 | 7 | 8 | |
| 32 | 48% | 74% | 89% |
| 40 | 36% | 68% | 84% |
| 48 | 23% | 62% | 81% |
Применение кодов свертки позволяют уменьшить вероятность ошибок при обмене, даже если число ошибок при передаче блока данных больше 1.
Линейные блочные коды
Блочный код определяется, как набор возможных кодов, который получается из последовательности бит, составляющих сообщение. Например, если мы имеем К бит, то имеется 2К возможных сообщений и такое же число кодов, которые могут быть получены из этих сообщений. Набор этих кодов представляет собой блочный код. Линейные коды получаются в результате перемножения сообщения М на порождающую матрицу G[IA]. Каждой порождающей матрице ставится в соответствие матрица проверки четности (n-k)*n. Эта матрица позволяет исправлять ошибки в полученных сообщениях путем вычисления синдрома. Матрица проверки четности находится из матрицы идентичности i и транспонированной матрицы А. G[IA] ==> H[ATI].
| I | A | AT [ZEBR_TAG_/table> Если   Синдром полученного сообщения равен S = [полученное сообщение]. [матрица проверки четности]. Если синдром содержит нули, ошибок нет, в противном случае сообщение доставлено с ошибкой. Если сообщение М соответствует М=2k, а k =3 высота матрицы, то можно записать восемь кодов: |
/p>
| Сообщения | Кодовые вектора | Вычисленные как |
| M1 = 000 | V1 = 000000 | M1.G |
| M2 = 001 | V2 = 001101 | M2.G |
| M3 = 010 | V3 = 010011 | M3. G |
| M4 = 100 | V4 = 100110 | M4. G |
| M5 = 011 | V5 = 011110 | M5.G |
| M6 = 101 | V6 = 101011 | M6 .G |
| M7 = 110 | V7 = 110101 | M7 .G |
| M8 = 111 | V8 = 111000 | M8 .G |
Таблица 2.8.3. Стандартный массив для кодов (6,3)
| 000000 | 001101 | 010011 | 100110 | 011110 | 101011 | 110101 | 111000 |
| 000001 | 001100 | 010010 | 100111 | 011111 | 101010 | 110100 | 111001 |
| 000010 | 001111 | 010001 | 100100 | 011100 | 101001 | 110111 | 111010 |
| 000100 | 001001 | 010111 | 100010 | 011010 | 101111 | 110001 | 111100 |
| 001000 | 000101 | 011011 | 101110 | 010110 | 100011 | 111101 | 110000 |
| 010000 | 011101 | 000011 | 110110 | 001110 | 111011 | 100101 | 101000 |
| 100000 | 101101 | 110011 | 000110 | 111110 | 001011 | 010101 | 011000 |
| 001001 | 000100 | 011010 | 101111 | 010111 | 100010 | 111100 | 011001 |
Синдром равен произведению левой колонки (CL "coset leader") стандартного массива на транспонированную матрицу контроля четности HT.
| Синдром = CL . HT | Левая колонка стандартного массива |
| 000 | 000000 |
| 001 | 000001 |
| 010 | 000010 |
| 100 | 000100 |
| 110 | 001000 |
| 101 | 010000 |
| 011 | 100000 |
| 111 | 001001 |

этот результат указывает на место ошибки, истинное значение кода получается в результате операции XOR:

Смотри также
www.cs.ucl.ac.uk/staff/S.Bhatti/D51-notes/node33.html (Saleem Bhatti).

)window.location='http://www.somecompany.com/people/ian/vocation/family.png'){kind=link}