Краткий справочник по командам UNIX
10.18 Краткий справочник по командам UNIX
Семенов Ю.А. (ГНЦ ИТЭФ)
Первая версия UNIX была создана в 1971 году, в 1979 году была подготовлена 7-я редакция (Bourne Shell и компилятор С, разработанная Керниганом и Ритчи; тогда же фирма Microsoft купила права и разработала свою версию для РС - XENIX). Первая версия BSD (Беркли) была подготовлена в 1978 году. В 1981 году закончена версия, поддерживающая стек протоколов TCP/IP (4.2BSD). В 1990 году в UNIX была встроена система NFS. Несколько лет назад в университете Хельсинки (Линусом Торвальдсом) была разработана версия UNIX, известная под названием LINUX.UNIX имеет двухуровневую структуру: ядро, где сконцентрированы базовые услуги и оболочка, куда входят редакторы, интерпретаторы, например СС, а также lp, routed, inetd, init
и т.д.
Код UNIX написан на Си (на 30% больше по объему и на 20% ниже по производительности, чем версия на ассемблере). Система открытая, рассчитанная на многозадачность и большое число пользователей.
Интерфейс системных вызовов предоставляет набор услуг ядра и определяет формат запросов. Ядро состоит из трех частей:
Файловая система
Система управления процессами и памятью
Система ввода/вывода.
Файловая система
обеспечивает интерфейс доступа к данным на дисковых накопителях и в периферийных устройствах ввода/вывода. Одни и те же функции open(), read(0, write() могут использоваться при чтении/записи на диске и при выводе данных на принтер или терминал. Файловая система управляет правами доступа и привилегиями. Она обеспечивает перенаправление запросов, адресованных периферийным устройствам.
Система управления процессами
ЭВМ, причем их число обычно превышает число ЦПУ. Специальной задачей ядра является планирование выполнением процессов (scheduler). Сюда входит управление ресурсами системы (временем ЦПУ, дисковым пространством, распределением памяти и т.д.). Данная система занимается созданием и удалением процессов, синхронизацией их работы и взаимодействием процессов (например, обменом данными).
Система ввода/вывода
обслуживает запросы файловой системы и системы управления процессами для доступа к периферийным устройствам (дискам, лентам, печати, терминалам). Эта система организует взаимодействие с драйверами этих устройств.
Файловая система UNIX представляет собой древовидную структуру. Каждый файл имеет имя, которое определяет его место на дереве файловой системы. Корнем этой системы является корневой каталог с именем /.
В этом каталоге обычно содержатся каталоги:
/bin
Каталог наиболее популярных системных команд и утилит.
/dev
Каталог файлов для периферийных устройств, например дисковых накопителей (/dev/cdrom, /dev/mem, /dev/null или /dev/ttyp10).
/etc
Здесь находятся конфигурационные файлы и утилиты администрирования, среди них скрипты инициализации системы.
/lib
Каталог библиотечных файлов языка Си и других языков.
/lost+found
Каталог “потерянных” файлов. Ошибки при неправильном выключении ЭВМ могут привести к появлению безымянных файлов (содержимое корректно, но нет ссылок на этот файл ни в одном из каталогов).
/mnt
Каталог для установления временных связей (монтирования) физических файловых систем с корневой системой. Обычно каталог пуст.
/home
Служит для размещения каталогов пользователей (в прежних версиях для этого служил каталог /usr.
/var
Предназначен для размещения сервисных подкаталогов, например, электронной почты (/usr/spool), утилит UNIX (/usr/bin), программ, исполняемых на данной ЭВМ (/usr/local), файлов заголовков (/usr/include), системы справочника (/usr/man).
/tmp
Служит для записи временных файлов. Полные имена остальных файлов содержат путь – список каталогов, размещенных между / и данным файлом. По этой причине полное имя любого файла начинается с символа / (не содержит в отличие от Windows имени диска (например, CD), другого внешнего устройства или удаленной ЭВМ).
UNIX, тем не менее, не предполагает наличия лишь одной файловой системы. Число таких файловых систем в этой ОС не лимитировано, они могут располагаться на одном дисковом накопителе, на разных устройствах или даже на разных ЭВМ.
Каждый файл имеет сопряженные с ним метаданные, записанные в индексных дескрипторах – inode. Имя файла является указателем на его метаданные (метаданные не содержат указателя на имя файла). Существует 6 типов файлов:
Обычный файл (regular)
Каталог (directory)
Файл внешнего устройства
Канал с именем (FIFO)
Связь (link)
socket
Обычный файл
является наиболее распространенным типом. Для операционной системы такой файл представляется простой последовательностью байтов. Интерпретация содержимого такого файла находится в зоне ответственности прикладной программы, которая с ним работает.
Каталог
– это файл, содержащий имена находящихся в нем файлов и указатели на информацию, позволяющую ОС производить операции над этими файлами. Запись в каталог имеет право только ядро. Каталог представляет собой таблицу, каждая запись в которой соответствует некоторому файлу.
Файл внешнего устройства
обеспечивает доступ к этому прибору. UNIX различает символьные и блочные файлы. Символьные файлы служат для не буферизованного обмена, а блочные предполагают обмен порциями данных фиксированной длины.
Каналы с именем
(FIFO) – это файлы, служащие для связи между процессами.
Файловая система допускает наличие нескольких имен у одного файла. Связь имени файла с его метаданными называется жесткой связью. С помощью команды ln можно создать еще одно имя для файла. Особым типом файла является символическая связь, позволяющей косвенно обращаться к файлу. Символическая связь является особым типом файла.
Socket
служит для взаимодействия между процессами. Интерфейс socket используется, например, для доступа к сети TCP/IP.
Любой файл имеет двух владельцев – собственно создателя и группу (chown, chgrp и chmod). Файл создается не пользователем, а процессом, им запущенным. Атрибуты этого процесс присваиваются и файлу (r, w и x). Имеется также несколько дополнительных атрибутов, среди них sticky bit, который требует сохранения образа \исполняемого файла в памяти после завершения его работы. Атрибуты SUID и GUID позволяют изменить права пользователя в направлении расширения (до уровня создателя файла) на время исполнения данной программы (это используется, например, в случае работы с файлом /etc/passwd). В случае каталогов sticky bit позволяет стереть только файлы, которыми владеет пользователь.
Различается несколько типов процессов.
Системные процессы являются частью ядра и резидентно размещены в оперативной памяти. Они запускаются при инициализации ядра системы. Системными процессами являются, например, kmadaemon (диспетчер памяти ядра), shed (диспетчер свопинга), bdfflush (диспетчер кэша), init (прародитель всех остальных процессов).
Демоны – не интерактивные процессы, запускаемые путем загрузки в память соответствующих программ и выполняемые в фоновом режиме. Демоны не ассоциируются ни с одним из пользователей (они служат, например, для организации терминального ввода, печатающего устройства, сетевого доступа).
Прикладные процессы – это остальные процессы принадлежащие, как правило, пользователям.
Процессы создаются процедурой fork и характеризуются набором атрибутов:
PID |
(Process ID) представляет собой уникальное имя процесса (идентификатор нового процесса характеризуется большим кодом, чем идентификатор предыдущего). После уничтожения процесса ликвидируется и его PID и этот идентификатор может быть присвоен новому процессу. |
PPID |
(Parent Process ID) – идентификатор процесса, породившего данный процесс. |
Приоритет процесса |
(Nice Number) учитывается планировщиком при определении очередности запуска процессов. |
TTY |
псевдотерминал, ассоциированный с процессом. Демоны не имеют псевдотерминала. |
RID (Real ID) |
пользователя, запустившего данный процесс. Эффективный идентификатор (EUID) служит для определения прав доступа процесса к системным ресурсам. |
Так, когда пользователь вводит команду ls, текущий процесс shell осуществляет вызов fork, порождая новый процесс – копию shell. Порожденный процесс осуществит вызов exec, указав в качестве параметра имя исполняемого файла (ls). Ls замещает shell, а по завершении работы процесс уничтожается.
Сигналы
Сигналы служат для того, чтобы передавать от одного процесса к другому или от ядра к какому-то процессу, уведомление о происхождении некоторого события. Примером такого события может быть нажатие клавиши мышки или нажатие клавиш <Ctrl><C> (SIGINIT)или <Ctrl><Alt><Del>.
Для отправления сигнала служит команда kill pid, где sig_no – номер или символическое название сигнала, pid - идентификатор процесса, которому адресован сигнал. Для остановки процесса, выполняемого в фоновом режиме можно послать сигнал SIGTERM. Например, kill $!, где $! – переменная, где хранится идентификатор процесса (PID), запущенного последним.
Таблица 1.
Сигналы
| Имя сигнала | Функция по умолчанию | Описание |
| SIGABRT | Завершение + ядро | Результат системного вызова abort |
| SIGALRM | Завершение | Результат срабатывания таймера, установленного системными вызовом alarm или setitimer |
| SIGBUS | Завершение + ядро | Результат аппаратной ошибки. Сигнал посылается при обращении к виртуальному адресу, для которого отсутствует соответствующая физическая страница памяти. |
| SIGCHLD | Игнорирование | Сообщает родительскому процессу о завершении исполнения дочернего |
| SIGEGV | Завершение + ядро | Формируется при попытке обращения к неверному адресу или области памяти, для которой у процесса нет привилегий. |
| SIGFPE | Завершение + ядро | Сигнал возникает в случае деления на нуль или при переполнении в операциях с плавающей запятой. |
| SIGHUP | Завершение | Посылается хозяину сессии, связанной с консолью, когда ядро обнаружит, что терминал отключился. Сигнал передается всем процессам текущей группы при завершении сессии хозяина. Этот сигнал иногда используется для взаимодействия процессов, например, для уведомления демонов о необходимости обновления конфигурационных данных. |
| SIGILL | Завершение + ядро | Посылается ядром при попытке процесса выполнить недопустимую команду. |
| SIGINT | Завершение | Посылается ядром всем процессам при нажатии комбинации клавиш <Del> или <Crtl><C>. |
| SIGKILL | Завершение | Сигнал прерывает выполнение процесса. Перехват или игнорирование этого сигнала невозможно. |
| SIGPIPE | Завершение | Результат попытки записи в канал или сокет, когда получатель данных закрыл соответствующий дескриптор. |
| SIGPOLL | Завершение | Результат реализации определенного события для устройства, которое опрашивается. |
| SIGPWR | Игнорирование | Результат угрозы потери питания (при переключении на UPS). |
| SIGQUIT | Завершение + ядро | Посылается ядром всем процессам текущей группы при нажатии клавиш <Crtl><\>. |
| SIGSTOP | Стоп | Посылается всем процессам текущей группы при нажатии пользователем комбинации клавиш <Crtl><Z>. Процесс останавливается. |
| SIGSYS | Завершение + ядро | Посылается ядром при попытке некорректного системного вызова |
| SIGTERM | Завершение | Предупреждение о скорой ликвидации процесса (ликвидировать временные файлы, прервать текущие обмены) Команда kill посылает именно этот сигнал. |
| SIGTTIN | Стоп | Формируется ядром при попытке фонового процесса выполнить чтение с консоли. |
| SIGTTOU | Стоп | Формируется ядром при попытке фонового процесса выполнить запись в консоль |
| SIGUSR1 | Завершение | Предназначен для прикладных задач, как средство взаимодействия процессов. |
| SIGUSR2 | Завершение | Предназначен для прикладных задач, как средство взаимодействия процессов. |
/p> Сигнал может игнорироваться, могут быть предприняты действия, предусмотренные по умолчанию, или процесс может взять на себя функцию обработки сигнала. Если процесс не остановился, существует способ заставить его выполнить это требование, послав команду:
kill –9 pid
Иногда и это может не помочь, например, в случае процессов зомби (процесса нет а запись о нем имеется), операции в NFS или с ленточным ЗУ.
Атрибуты пользователя в файле /etc/passwd (одна строка – одна запись):
имя:passwd-encod:UID:GID:комментарии:home-dir:shell
имя
уникальное регистрационное имя пользователя (вводится при login)
passwd-encod
закодированный пароль пользователя. Часто пароль хранится в отдельном файле, а здесь вместо него проставляется символ х. Если в этом поле стоит символ *, то данный пользователь в систему войти не может (используется для псевдопользователей)
UID
Идентификатор пользователя, который наследуется порожденными им процессами. ROOT имеет UID=0.
GID
Идентификатор первичной группы пользователя, который соответствует идентификатору в файле /etc/group, где содержится список имен пользователей-членов группы.
Комментарии
Обычно здесь записывается истинное имя пользователя, здесь может быть записана дополнительная информация, например, телефон или e-mail пользователя, считываемые программой finger.
home-dir
Базовый каталог пользователя, где он оказывается после входа в систему.
Shell
Название программы, используемой системой в качестве командного интерпретатора (например, /bin/sh). Разные интерпретаторы используют разные скрипты инициализации (.profole, .login и т.д.).
В первой строке скрипта помещается строка #! /bin/sh, указывающая на тип и размещения интерпретатора. Поскольку скрипт исполняется интерпретатором, работает он медленно. Значение PID сохраняется в переменной $$, что можно использовать при формировании имен временных файлов, гарантируя их уникальность. Переменные $1, $2 и т.д. несут в себе значения параметров, переданных скрипту. Число таких параметров записывается в переменной $#. Результат работы скрипта заносится в переменную $?. Ненулевое значение $? свидетельствует об ошибке. В переменной $! Хранится PID последнего процесса, запущенного в фоновом режиме. Переменная $* хранит в себе все переменные, переданные скрипту в виде единой строки вида: “$1 $2 $3 …”. Другое представление переданных параметров предлагает переменная $@= “$1” “$2” “$3” …
Таблица 2.
Перенаправление потоков ввода/вывода
| Обозначение | Выполняемая операция |
>файл |
Стандартный вывод перенаправляется в файл |
>>файл |
Данные из стандартного вывода добавляются в файл |
<файл |
Стандартный ввод перенаправляется в файл |
p1|p2 |
Вывод программы p1 направляется на вход программы p2 |
n>файл |
Перенаправление вывода из файла с идентификатором n в файл |
n>>файл |
Тоже, что и в предыдущей строке, но данные добавляются к содержимому файла |
n>&m |
Объединение потоков с идентификаторами n и m |
<<str |
“Ввод здесь” – используется стандартный ввод до подстроки str. При этом осуществляется подстановка метасимволов интерпретатора |
<<\str |
То же, что и в предшествующей строке, но без подстановки. |
ps – ef | grep proс
осуществляет вывод данных о конкретном процессе proс. Несколько более корректна команда:
ps – ef | grep proс grep –v grep
так как в потоке, формируемом командой ps, присутствуют две строки, содержащие proс - строка процесса proс и строка процесса grep с параметром proс.
Для запуска выполнения команды в фоновом режиме достаточно завершить ее символов &.
Виртуальная память процесса состоит из сегментов памяти. Размер, содержимое и размещение сегментов определяется самой программой (например, применением библиотек). Исполняемые файлы могут иметь формат COFF (Common Object File Format) и ELF (Executable and Linking Format).
Функция main() является первой, определенной пользователем. Именное ей будет передано управление после формирования соответствующего окружения запускаемой программы. Функция main определяется следующим образом.
main(int argc, char *argv[], char *envp[]);
Аргумент argc определяет число параметров, переданных программе. Указатели на эти параметры передаются с помощью массива argv[], так через argv[0] передается имя программы, argv[1] – несет в себе первый параметр и т.д. до argv[argc-1]. Массив envp[] несет в себе список указателей на переменные окружения, передаваемые программе. Переменные представляют собой строки имя=значение_переменной.
В среде UNIX существует два базовых интерфейса для файлового ввода/вывода.
Интерфейс системных вызовов, непосредственно взаимодействующих с ядром ОС.
Стандартная библиотека ввода-вывода.
С файлом ассоциируется дескриптор, который в свою очередь связан с файловым указателем смещения, начиная с которого будет произведена последующая операция чтения/записи. Каждая операция чтения или записи увеличивает этот указатель на число переданных байтов. При открытии файла указатель принимает значение нуль.
Процессы
Процесс характеризуется набором атрибутов и идентификаторов. Важнейшим из них является идентификатор процесса PID и идентификатор родительского процесса PPID. PID является именем процесса в ОС. Существует еще 4 идентификатора, которые определяют доступ к системным ресурсам.
Идентификатор пользователя – UID.
Эффективный идентификатор пользователя – ЕUID
Идентификатор группы GID
Эффективный идентификатор группы ЕGID.
Процессы с идентификаторами SUID и SGID ни при каких обстоятельствах не должны порождать других процессов
.
Процесс при реализации использует разные системные ресурсы – память, процессор, возможности файловой системы и ввод/вывод. ОС создает иллюзию одновременного исполнения нескольких процессов (предполагается, что имеется только один процессор), распределяя ресурсы между ними и препятствуя злоупотреблениям.
Выполнение процесса может происходить в двух режимах – в режиме ядра (kernel mode) и в режиме пользователя (user mode). В режиме пользователя процесс исполняет команды прикладной программы, доступные на непривилегированном уровне. Для получения каких-либо услуг ядра процесс делает системный вызов. При этом могут исполняться инструкции ядра, но от имени процесса, реализующего системный вызов. Выполнение процесса переходит в режим ядра, что защищает адресное пространство ядра. Следует иметь в виду, что некоторые инструкции, например, изменение содержимого регистров управления памятью, возможно только в режиме ядра.
По этой причине образ процесса состоит из двух частей: данных режима ядра и режима пользователя. Каждый процесс представляется в системе двумя основными структурами данных – proc и user, описанными в файлах <sys/proc.h> и <say/user.h>, соответственно. Структура proc является записью системной таблицы процессов, которая всегда находится в оперативной памяти. Запись этой таблицы для активного в данный момент процесса адресуется системной переменной curproc. Каждый раз при переключении контекста, когда ресурсы процессора передаются другому процессу, соответственно изменяется содержимое переменной curproc, которая теперь будет указывать на proc активного процесса.
Структура user, называемая также u-area или u block, содержит данные о процессе, которые нужны ядру при выполнении процесса. В отличие от структуры proc, адресуемой с помощью указателя curproc, данные user размещаются в определенном месте виртуальной памяти ядра и адресуются через переменную u. u area также содержит стек фиксированного размера – системный стек или стек ядра (kernel stack). При выполнении процесса в режиме ядра операционная система использует стек, а не стек процесса.
Современные процессоры поддерживают разбивку адресного пространства на области переменного размера – сегменты, и области фиксированного объема – страницы.
Процессоры Intel позволяют разделить память на несколько логических сегментов. Виртуальный адрес при этом состоит из двух частей – селектора сегмента и смещения в пределах сегмента. Поле селектора INDEX указывает на дескриптор сегмента, где записано его положение, размер и права доступа RPL (Descriptor Privilege Level).
При запуске программы командный интерпретатор порождает процесс, который наследует все 4 идентификатора и имеет те же права, что и shell.Так как в сеансе пользователя прародителем всех процессов является login shell, то их идентификаторы будут идентичны. При запуске программы сначала порождается новый процесс, а затем загружается программа.
Процесс порождается с помощью системного вызова fork:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
Порожденный процесс (дочерний) является точной копией родительского процесса. Дочерний процесс наследует следующие атрибуты:
идентификатор пользователя и группы
все указатели и дескрипторы файлов
диспозицию сигналов и их обработчики
текущий и корневой каталог
переменные окружения
маску файлов
ограничения, налагаемые на процесс
управляющий терминал
Конфигурация виртуальной памяти также сохраняется (те же сегменты программ, данных, стека и пр.). После завершения вызова fork оба процесса будут выполнять одну и ту же инструкцию. Отличаются эти процессы PID, PPID (идентификатор родительского процесса), дочерний процесс не имеет сигналов, ждущих доставки, отличаются и код, возвращаемый системным вызовом fork (родителю возвращается PID дочернего процесса, а дочернему - 0). Если код =0, то возврат осуществляется только в родительский процесс.
Для загрузки исполняемого файла используется вызов exec (аргумент – запускаемая программа). При этом существующий процесс замещается новым, соответствующим исполняемому файлу.
идентификаторы PID и PPID
все указатели и дескрипторы файлов, для которых не установлен флаг FD_CLOEXEC
идентификаторы пользователя и группы
текущий и корневой каталог
переменные окружения
маску файлов
ограничения, налагаемые на процесс
управляющий терминал
Процессы могут уведомлять друг друга о произошедших событиях с помощью сигналов, каждый из которых имеет символьное имя и номер. Сигнал может инициировать попытка деления на 0 или обращение по недопустимому адресу.
ОС UNIX создает иллюзию одновременного исполнения процессов, стараясь эффективно распределять между ними имеющиеся ресурсы. Выполнение процесса возможно в режиме ядра (kernel mode) и в режиме задачи (user mode). В последнем случае процесс реализует инструкции прикладной программы, допустимые на непривилегированном уровне защиты процессора. При этом системные структуры данных недоступны. Для получения таких данных процесс делает системный вызов (на время происходит переход процесса в режим ядра).
Каждый процесс представляется в системе двумя основными структурами данных – proc и user, описанными в файлах <sys/proc.h> и <sys/user.h>. Структура proc представляет собой системную таблицу процессов, которая находится в оперативной памяти резидентно. Текущий процесс адресуется системной переменной curproc. Структура user размещается в виртуальной памяти. Область user содержит также системный стек и стек ядра.
Распределение оперативной памяти всегда бывает динамическим. Процессы выполняются в своем виртуальном адресном пространстве. Виртуальные адреса преобразуются в физические на аппаратном уровне при активном участии ОС. Объем виртуальной памяти может значительно превышать объем физической. Процессоры обычно поддерживают разделение адресного пространства области переменного размера – сегменты и фиксированного размера - страницы. Для каждой страницы может быть задано собственная схема преобразования виртуальных адресов в физические. Intel поддерживает работу с сегментами (сегментные регистры), где задается селектор сегмента (дескриптор) и смещение в пределах сегмента.
Распределение ресурсов процессора осуществляется планировщиком, который выделяет кванты времени каждому из активных процессов. Здесь приложения делятся на три класса:
Интерактивные
Фоновые
Реального времени
Каждый процесс в UNIX имеет свой контекст (контекст сохраняется при прерывании процесса). Контекст определяется следующими составляющими:
Адресное пространство процесса в режиме user
Управляющая информация (proc и user).
Окружение процесса (в виде пар переменная=значение).
Аппаратный контекст (регистры процессора)
Работа планировщика UNIX основана на использовании приоритетов процессов. Если процесс имеет наивысший приоритет и готов к работе, планировщик прервет работу текущего процесса, если у него более низкий приоритет, даже при условии, что он не выбрал до конца свой квант времени. Работа программы ядра обычно не прерывается. Это касается и процессов user, если они в данный момент осуществляют системный вызов.
Каждый процесс имеет два атрибута приоритета – текущий и относительный (nice). Первый служит для реализации планирования, второй присваивается при порождении процесса и воздействует на значение текущего приоритета. Текущий приоритет может характеризоваться кодами 0 (низший) – 127 (высший). Для режима user используются коды приоритета 0-65, а для ядра – 66-94 (системный диапазон).
Процессы с кодами 96-127 имеют фиксированный приоритет, который не может изменить ОС (обычно служат для процессов реального времени).
Процессу, ожидающему освобождения какого-то ресурса, система присваивает значение кода приоритета сна, выбираемое из диапазона системных приоритетов (в версии BSD большему коду соответствует меньший приоритет). Процессы типа “ожидание ввода с клавиатуры” имеют высокий приоритет сна и им сразу предоставляется ресурс процессора. Фоновые же процессы, забирающие много времени ЦПУ, получают относительно низкий приоритет.
Каждую секунду ядро пересчитывает текущие значения кодов приоритета для процессов, ожидающих запуска (коды<65), повышая вероятность получения ими требуемого ресурса. Так 4.3BSD использует для расчета приоритета процесса следующую формулу:
p_cpu = p_cpu*(2*load)/(2*load+1),
где load – среднее число процессов в очереди за последнюю секунду. В результате после долгого ожидания даже низкоприоритетный процесс имеет определенный шанс получить требуемый ресурс.
Ядро генерирует и посылает процессу сигнал в ответ на определенные события, вызванные самим процессом, другим процессом, прерыванием (например, терминальным) или внешним событием. Это могут быть Alarm, нарушение по выделенным квотам, особые ситуации, например деление на нуль и т.д. Некоторые сигналы можно заблокировать, отложить их обработку, или проигнорировать, для других (например, SIGKILL и SIGSTOP) это невозможно.
Взаимное влияние процессов в UNIX минимизировано (многозадачность!), но система была бы неэффективной, если бы она не позволяла процессам обмениваться данными и сигналами (IPC – Inter Process Communications). Для реализации этой задачи в UNIX предусмотрены:
каналы
сигналы
FIFO (First-In-First-Out - именованные каналы)
очереди сообщений
семафоры
совместно используемые области памяти
сокеты>
Для создания канала используется системный вызов pipe int pipe(int *filedes); который возвращает два дескриптора файла filedes[0] – для записи в канал и filedes[1] для чтения из канала. Когда один процесс записывает данные в filedes[0], другой получает их из filedes[1]. Здесь уместен вопрос, как этот другой процесс узнает дескриптор filedes[1]?
Нужно вспомнить, что дочерний процесс наследует все дескрипторы файлов родительского процесса. Таким образом, к дескрипторам имеет доступ процесс, сформировавший канал, и все его дочерние процессы, что позволяет работать каналам только между родственными процессами. Для независимых процессов такой метод обмена недоступен. Канальный обмен может быть запущен и с консоли. Например:
cat file.txt | wc
Здесь символ | олицетворяет создание канала между выводом из файла file.txt и программой wc, подсчитывающей число символов в словах. Процессы эти не являются независимыми, так как оба порождены процессом shell.
Метод FIFO ( в BSD не реализован) сходен с канальным обменом, так как также организует лишь однонаправленный обмен. Такие каналы имеют имена, что позволяет их применять при обмене между независимыми процессами. FIFO – это отдельный тип файла в файловой системе UNIX. Для формирования FIFO используется системный вызов mknod.
int mknod(char *pathname, int mode, int dev);
где pathname – имя файла (FIFO),
mode – флаги владения и прав доступа,
dev – при создании FIFO игнорируется.
Допускается создание FIFO и из командной строки: mknod name p.
FIFO также как и обычные канала работают с соблюдением следующих правил.
Если из канала берется меньше байтов, чем там содержится, остальные остаются там для последующего чтения.
При попытке прочесть больше байт, чем имеется в канале, читающий процесс должен соответствующим образом обработать возникшую ситуацию.
Если в канале ничего нет и ни один процесс не открыл его на запись, при чтении будет получено нуль байтов. Если один или более процессов открыло канал на запись, вызов read будет заблокирован до появления данных.
В случае записи в канал несколькими процессами, эти данные не перемешиваются.
При попытке записать большее число байтов, чем это позволено каналом или FIFO, вызов write блокируется до освобождения нужного места. Если процесс предпринимает попытку записи в канал, не открытый ни одним из процессов для чтения, процессу посылается сигнал SIGPIPE, а вызов write присылает 0 с кодом ошибки errno=EPIPE.
Сообщения
Очереди сообщения являются составной частью UNIX System V. Процесс, заносящий сообщение в очередь, может не ожидать чтения этого сообщения каким-либо другим процессом. Сообщения имеют следующие атрибуты:
Тип сообщения
Длина данных в байтах
Данные (если длина ненулевая)
Очередь сообщений имеет вид списка в адресном пространстве ядра. Для каждой очереди ядро формирует заголовок(msqid_ds), где размещаются данные о правах доступа к очереди (msg_perm), о текущем состоянии очереди (msg_cbytes – число байтов msg_qnum – число сообщений в очереди), а также указатели на первое и последнее сообщение. Создание новой очереди сообщений осуществляется посредством системного вызова msgget:
#include <sys/types.h>
#include <sys/ipc.h>
#include e <sys/ipc.h>
int msgget( key_t key, int msgflag );
Эта функция выдает дескриптор элемента очереди, или –1 - в случае ошибки. Процесс может с помощью оператора msgsnd поместить сообщение в очередь, получить сообщение из очереди посредством msgrcv и манипулировать сообщениями с помощью msgctl.
Семафоры
Для управления доступом нескольких процессов к разделяемым ресурсам используются семафоры. Семафоры являются одной из форм IPC (Inter-Process Communication). Для обеспечения работы нужно обеспечить выполнение следующих условий:
Семафор должен быть доступен разным процессам и, по этой причине, находиться в адресной среде ядра.
Операция проверки и изменения семафора должна быть реализована в режиме ядра.
Помимо значения семафора в структуре sem записывается идентификатор процесса, вызвавшего последнюю операцию над семафором, число процессов, ожидающих увеличения значения семафора.
Разделяемая память
Активное использование каналов, FIFO и очередей сообщений может привести к снижению производительности машины. Это сопряжено с тем, что передаваемые данные сначала из буфера передающего процесса в буфер ядра, и только затем в буфер принимающего процесса. Техника разделяемой памяти позволяет избавиться от этих потерь, предоставив доступ двум или более процессам доступ общей зоне памяти.
Пока один процесс читает данные из разделяемой памяти, другой не должен туда писать и наоборот. Такого рода согласование работы осуществляется посредством семафоров.
Файловая система
В настоящее время UNIX использует виртуальную файловую систему, которая допускает работу с несколькими физическими файловыми системами самых разных типов. Система S5FS занимает раздел диска и состоит из трех компонентов.
Суперблока, где хранится общая информация о файловой системе, о ее архитектуре, числе блоков, и индексных дескрипторов (inode).
Массива индексных дескрипторов (ilist), где записаны метаданные всех файлов системы. Индексный дескриптор содержит статусные данные о файле и информацию о расположении этих данных на диске. Ядро обращается к inode по индексу массива ilist. Один inode является корневым, через него происходит доступ к структуре каталогов и файлов после монтирования файловой системы.
Блоки данных файлов и каталогов. Размер блока кратен 512 байтам.
Индексный дескриптор (inode) несет в себе информацию о файле, необходимую для обработки метаданных файла. Каждый файл ассоциируется с одним inode. При открытии файла ядро записывает копию inode в таблицу in-core inode.
Слабой точкой файловой системы F5FS является суперблок. Он записан на диске в одном экземпляре и по этой причине уязвим. Низкая производительность этой файловой системы связана с тем, что метаданные файлов размещены в начале диска, а данные на относительном расстоянии от них. Это вызывает постоянные перемещения считывающих головок, снижая быстродействие системы.
Имена файлов хранятся в специальных файлах, называемых каталогами. По этой причине любой реальный файл данных может иметь любое число имен. Каталог файловой системы представляет собой таблицу, каждый элемент которой имеет длину 16 байтов: 2 байта номер индексного дескриптора, 14 – его имя. Число inode не может превышать 65535. Имя файла в этой системе (S5FS) не должно превышать 14 символов.
имеет имя “..”.
При удалении имени файла из каталога номер соответствующего inode устанавливается равным 0. Ядро не удаляет свободные элементы, по этой причине размер каталога при удалении файлов не уменьшается.
Новая файловая система FFS (Berkeley Fast File System) использует те же структуры длинные имена файлов (до 255 символов). Записи каталога имеют следующую структуру:
d_namlen - Длина имени файла
d_name[] - Имя файла
Имя файла имеет переменную длину, дополняемую нулями до 4-байтовой границы. Метаданные активных файлов, на которые ссылаются один или более процессов, представлены в памяти в виде in-core inode. В виртуальной файловой системе в качестве in-core inode выступает vnode. Структура vnode одинакова для всех файлов и не зависит от типа файловой системы. vnode содержит данные, необходимые для работы виртуальной файловой системы, а также характеристики файла, такие как его тип.
Получение описания инструкций (Help): man <имя объекта>
Уход из UNIX Ctrl-d или logout.
passwd |
Смена пароля пользователя |
| Вызов редактора | ed - строчный редактор; sed - потоковый редактор |
pwd |
Выдача полного имени текущего каталога |
clear |
Очистка экрана терминала. |
ls [-флаги...] имя... Распечатка каталога
Флаги:
| -a | печатает все имена файлов в каталоге; |
| -c | сортирует список файлов по времени последней модификации; |
| -d | печатает информацию только о каталогах (эквивалентно -l); |
| -f | для каждого подкаталога выводит его содержимое, этот флаг выключает все другие флаги; |
| -g | вместо идентификатора владельца печатается идентификатор группы; |
| -l | печатает полную информацию о файлах; |
| -r | сортирует список в обратном порядке; |
| -s | выводит размер файлов в блоках; |
| -t | сортировка по времени; |
| -u | сортирует список файлов по времени последнего доступа. |
| lc | Вывод содержимого каталога по столбцам (аналогична ls, но присутствует не во всех системах); |
| Образование нового каталога | mkdir |
| Переход из каталога в каталог | cd |
| Возвращение в предыдущий каталог | cd .. |
| Переход в параллельный каталог b | cd ../b |
| Возврат в базовый каталог | cd ../../ |
| Удаление каталога | rmdir <имя_каталога> |
 test <параметр> <файл> |
| -b | является блочным специальным файлом; |
| -c | символьным специальным файлом; |
| -d | каталогом; |
| -f | обычным файлом (не каталогом); |
| -g | установлен бит идентификатора группы; |
| -k | второй промежуточный бит округления; |
| -r | доступен для чтения; |
| -s | имеет ненулевой размер; |
| -t[fds] | открытый файл с дескриптором fsd связан с терминалом (по умолчанию fsd=1); |
| -u | установлен бит идентификатора пользователя; |
| -w | доступен для записи; |
| -x | для исполнения. |
/p>
cat [файл1 файл2 ...] |
Слияние файлов ( если указано одно имя команда выводит содержимое на терминал, эквивалентно команде page) |
cp файл1 файл2 или cp файл1 файл2 .... файлN каталог.
uucp |
делает то же, что и cp, но между двумя UNIX машинами в сети. |
имя ЭВМ отделяется от имени файла с помощью "!". Перед именем файл2 необходимо указать также имя каталога или поставить "~", если оно неизвестно.
| Например: | /usr/ivanov/news или ~ivanov/news. |
| -m | посылает сообщение отправителю о доставке файла1; |
| -n | посылает аналогичное сообщение получателю. |
mv файл1 файл2 или mv каталог1 каталог2
Печать файлов
Печать содержимого одного или нескольких файлов c автоматическим разбиением на страницы и с заголовком на каждой странице;
pr [флаги]...[файл]...
Флаги:
| -h | задает заголовок; |
| -ln | задает длину страницы в n строк (по умолчанию - 60); |
| -m | Печатать все файлы одновременно в своих колонках; |
| -n | в n колонок; |
| +n | начиная со страницы n; |
| -t | не печатать 5 строк заголовка и 5 последних строк страницы; |
| -wn | задает ширину стр. в n символов (по умолчанию - 72); |
more [файл] |
Отображает файл поэкранно. |
lpr [флаги]...[файл]...
Флаги:
| -c | cкопировать файл перед печатью; |
| -m | отправить почтовое сообщение по завершении печати; |
| -n | не сообщать по почте о завершении печати (по умолчанию); |
| -r | удалить файл после печати. |
lp [флаги] [файл_1, файл_2,....файл_N]
Флаги:
| -d | задает имя принтера; |
| -o | служит для задания субпараметров печати; |
| -n[число] | задает число копий печати; |
| -m | выводит на терминал сообщение по завершении печати; |
| -q[приоритет] | определяет уровень приоритета для запросов печати (максимальный - 0, минимальный -39); |
| -s | блокирует сообщение "request идентификатор"; |
| -R | удаляет напечатанные файлы; |
| -L | использует подключенный к вашему терминалу локальный принтер; |
| lprint | эквивалент команды pr -L; |
| lpstat | выдает сообщение о статусе принтера; |
| cancel | отменяет запрос вывода на печать. |
/p>
Сравнение файлов
Сравнение файлов и выдача отчета о различиях;
cmp [-l][-s] файл1 файл2
Флаги:
| -l | выдача полного списка различий; |
| -s | выдача кода результата; (если равны - 0; неравны - 1; хотя бы один недоступен - 2); |
rm [флаги] файл
Флаги:
| -f | если для файла запрещена запись/чтение; |
| -i | удаление в интерактивном режиме; ( * означает - все файлы каталога); |
| -r | * удаление всех файлов и подкаталогов; |
find каталог ... аргументы ...
Просматриваются рекурсивно все подкаталоги для каждого указанного каталога и ищутся файлы отвечающие условиям, заданным в аргументах. Числовые аргументы со знаком "+" означают "больше чем", а числовой аргумент со знаком "-" "меньше чем". Аргументы - это условия поиска; любому аргументу предшествует знак "-", все аргументы считаются соединенными знаком "И". -o соединитель ИЛИ, перед каждым символом "ИЛИ" должен ставиться знак "\";
Допускаются аргументы:
| -name имя файла | имя файла совпадает с заданным; |
| -type c | тип файла совпадает с с; |
| -links n | файл имеет n связей; |
| -user имя | файл принадлежит пользователю с данным именем; |
| -group имя | файл принадлежит группе с именем; |
| -size n | длина файла равна n блокам; |
| -inum n | индекс файла равен n; |
| -mtime n | последняя модификация файла была n дней назад; |
| -exec команда | выполняется команда UNIX; |
| -ok команда | то же, что и -exec, но печатается на терминале; |
| печатается имя текущего файла; | |
| -newer файл | текущий файл был модифицирован позже заданного |
clri файл-система индекс...
Удаляет индексный дескриптор для файла, отсутствующего в каталогах.
Библиотекарь
ar флаги [имя] библиотека [файл...]
Флаги:
| a | указывает (совместно с r или m) на то, что файлы следует помещать после заданного файла; |
| b | то же, что и a, но файлы размещаются перед заданным файлом; |
| c | создание библиотечного файла; |
| d | удалить файлы из библиотеки; |
| l | поместить временные файлы библиотекаря в текущем каталоге; |
| m | переместить файлы в конец библиотеки или вслед за указанным файлом; |
| p | напечатать содержимое заданных файлов; |
| q | добавить файлы в конец библиотеки; |
| r | заменить файлы в библиотеке на новые. Если файлов нет, они просто добавляются; |
| t | перечислить файлы, входящие в библиотеку; |
| u | совместно с r указывает, что будет заменяться только те файлы библиотеки, которые были модифицированы раньше заданных файлов. |
| v | печать дополнительной информации (вид действия, имя файла) применяется совместно с d, m, r, x; |
| x | скопировать файлы в текущий каталог; |
/p> Построение таблицы с содержанием библиотеки
ranlib [библиотека]
Служит для подготовки работы редактора связей.
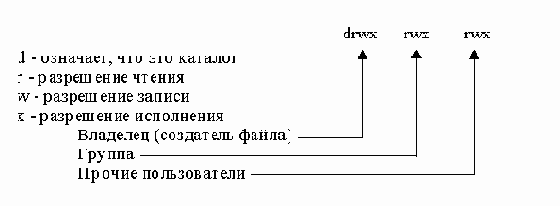
| Установка кода защиты файла | chmod код |
4000 разрешение смены идентификатора пользователя;
2000 разрешение смены идентификатора группы;
1000 сохранение образа файла после отсоединения всех процессов;
0400 разрешение чтения владельцу файла;
0200 разрешение записи владельцу файла;
0100 разрешение записи, чтения и выполнения владельцу;
0070 разрешение записи, чтения и выполнения группе;
0007 разрешение чтения, записи, исполнения всем.
Символьная форма позволяет установить биты кода защиты индивидуально и имеет вид:
[ugoa][+-=][rwxstugo],
где
| u | владелец, |
| g | группа, |
| o | прочие, |
| a | все категории пользователей (по умолчанию), |
| + | разрешить доступ, |
| - | запретить доступ, |
| r | чтение, |
| w | запись, |
| x | исполнение, |
| s | смена идентификатора пользователя или группы, |
| t | сохранение образа файла в области выгрузки, |
| ugo | оставить текущее значение бита доступа. |
dcheck [индексы][файловая система]
Сравнивает счетчик числа связей в индексном дескрипторе с числом записей в каталогах, ссылающихся на данный дескриптор. Индексы генерируются командой icheck. Проверка распределения памяти в файловой системе
icheck [-s][-b блок...][файловая система]
Исследуется файловая система, проверяется правильность списков свободных и используемых блоков, выводит общее число файлов, каталогов, число используемых блоков, число свободных блоков и т.д.
Флаги:
-b выдача диагностических сообщений для заданных
блоков.
-s создание списка свободных блоков;
Генерация имен файлов по заданным индексам
nchek [-i индексы] [-a][-s][файловая система]
Генерирует полные имена файлов для заданного списка индексов файловой системы, осуществляет поиск имен поврежденных файлов.
Флаги:
| -a | печатает тот же список, что и для флага -i и дополнительно все файлы, имена которых начинаются с "." и "..". |
| -i | печатает полный список файлов для индексов, перечисленных после данного флага. |
| -s | печатаются только специальные файлы и файлы с установленным режимом смены идентификатора пользователя. |
/p> Создание файловой системы
/etc/mkfs [файловая система][размер]
Создает новую файловую систему на диске или части диска согласно числу блоков, заданному аргументом размер. Такая система может быть присоединена к основной файловой системе с помощью команды mount.
Создание специальных файлов
/etc/mknod имя [c][b] тип устройство
Создание специальных файлов, располагающихся в каталоге /dev, где описываются характеристики драйверов устройств и файловых систем. Аргументы тип и устройство относятся к драйверу и к специальному входу в драйвер.
Монтирование файловой системы
/etc/mount файловая-система [-r] имя файла
Демонтирование файловой системы
/etc/umount файловая-система
Временная смена идентификатора пользователя
su [идентификатор]
Изменяет идентификатор пользователя, и выполняет операции, которые возможно было бы нельзя выполнить с другим идентификатором из-за отсутствия права доступа. Для возврата к исходной среде следует нажать ctrl-d.
Модификация суперблока - sync
Освобождаются буферы и модифицируется файловая система на диске. Sync автоматически выполняется через заданный промежуток времени, задаваемый администратором.
Библиотекарь магнитной ленты (или дискеты)
tar [флаги][имя]
Сохраняет и восстанавливает файлы и каталоги с использованием магнитной ленты (или дискет).
Флаги:
| c | создает новую ленту для записи на нее файлов; |
| r | заданные файлы записываются в конец ленты; |
| t | печатает список файлов и каталогов, имеющихся на ленте, из числа заданных в команде; |
| x | чтение с ленты заданных файлов или каталогов, если имеется несколько версий, читается последняя; |
| u | заданные файлы добавляются на ленту, если их там нет или если это новые версии. Следующие флаги используются для модификации вышеприведенных функций. |
| b | коэффициент блокирования при чтении и записи, по умолчанию = 1, максимальное значение = 20; |
| f | следующий за f аргумент рассматривается как имя устройства вместо принятого по умолчанию /dev/mt?. |
| l | обеспечивает выдачу сообщения, если при записи не удается получить доступ ко всем файлам; |
| m | сообщает программе tar, что не следует изменять время модификации при записи файлов на ленту; |
| v | печать имен всех файлов и каталогов, при выполнении данной операции; |
| w | печатает наименование заданного действия и имя файла, после чего ожидается ответ пользователя. При "y" действие выполняется. |
| 0,...,7 | определяет номер устройства, на котором установлена лента, по умолчанию 1. |
/p> Смена владельца файла chown
chown имя файл
Смена группы chgrp
chgrp группа файл
Изменение направления ввода/вывода
| < > | задает направление ввода/вывода; |
| << >> | задает направление, но добавляет к уже имеющемуся; |
| | | служит для передачи данных от одной команды к другой. |
tr [-cds][строка_1][строка_1]
Считывает данные из стандартного ввода. Символы, не совпадающие с символом в аргументе "строка_1", передается на стандартный вывод без изменения. Символы же, совпадающие с символом в аргументе "строка_1", заменяются на соответствующие символы из аргумента "строка_2".
Асинхронное выполнение команд
| & | поставленное в конце командной строки позволяет продолжить работу, не дожидаясь окончания выполнения команды. |
Появление приглашения после ввода команды wait указывает на завершение всех запущенных ранее процессов.
at время [дата_и_время][приращение] список_команд
Команда планирования выполнения заданий.
Позволяет выполнить команду в указанный день и час, которые могут модифицироваться необязательным приращением.
at -r идентификатор_задания
Отменяет запрос.
batch
планирует задания на то время, когда это будет позволять система.
Системные команды
mail имя файла или mail [-r] [-q] [-p] [-f файл]
Обращение к почтовому серверу.
Флаги:
| -f | файл используется в качестве почтового ящика; |
| -p | печать почты; |
| -q | QUIT (прерывание процедуры); |
| -r | упорядочение - раньше посланное сообщение читается раньше; без флага - обратный порядок. |
| d | удаление данного почтового сообщения; |
| m [имя] | переслать сообщение указанному пользователю; |
| p | напечатать сообщение еще раз и вернуться к предшествующему сообщению; |
| _ | вернуться к предыдущему сообщению; |
| s [файл] | записать сообщение в файл; |
| ctrl/d | вернуть сообщение в почтовый ящик и завершить выполнение команды mail (= q). |
| x | выход без изменения почтового ящика; |
| ! | временный выход в SHELL; |
| ? | напечатать список команд mail. |
Сообщение всем работающим пользователям
wall
администратор что-то сообщает всем.
Конец сообщения по ctrl/d.
Посылка сообщения другому пользователю
write имя [терминал]
Разрешение или отмена сообщений
mesg [y] [n] (флаги - "y" и "n")
присылаемых другими пользователями.
Команды обработки файлов
comm [-[123]] файл1 файл2 |
поиск одинаковых и разных строк в файлах, флаги "123" обозначают номера колонок. Результат печатается в трех колонках: |
2 - строки встречаются только в файле2;
3 - строки встречаются в обоих файлах.
Преобразование файла
dd [аргументы] |
позволяет задавать входной и выходной файлы, указывать виды преобразований. Обычно используется для магнитных лент. |
| if=имя | имя входного файла; |
| of=имя | имя выходного файла; |
| ibs=n | размер входного блока в байтах (512 по умолчанию); |
| obs=n | размер выходного блока (512 по умолчанию); |
| bs=n | размер входного и выходного блоков; |
| cbs=n | размер буфера преобразования в байтах; |
| skip=n | перед копированием пропустить n входных записей; |
| files=n | скопировать n файлов с входной ленты; |
| seek=n | установить выходной файл на запись с номером n перед началом копирования; |
| count=n | скопировать n входных записей. |
grep [флаг] ... выражение [файл]
Служит для поиска соответствующих выражений (строк) в одном или нескольких файлах.
Флаги:
| -b | перед каждой обнаруженной строкой печатается номер блока, где она содержится; |
| -c | печатается только число строк, содержащих шаблон; |
| -e | используется перед шаблоном, который начинается с символа "-"; |
| -h | не печатаются имена файлов перед строками; |
| -l | печатаются имена файлов, содержащие искомые строки; |
| -n | перед каждой обнаруженной строкой печатается ее порядковый номер в файле; |
| -s | вырабатывается только статус результата выполнения команды; |
| -v | печатаются все строки, не содержащие шаблона; |
| -y | строчные буквы в шаблоне считаются совпадающими как со строчными, так и прописными в файле. |
egrep |
модифицированная версия grep. |
fgrep |
упрощенная версия команды grep. Ищет только фиксированные строки, но работает быстрее чем grep. |
/p> Восьмеричный дамп файла
od[-флаги] файл[[+] смещение [.][b]].
Флаги:
| -b | каждый байт файла интерпретируется как восьмеричное число; | |
| -c | байты интерпретируются как символы ASCII, неграфические символы выдаются в виде: | |
| нулевой байт | \0 | |
| возврат на шаг | \b | |
| перевод формата | \f | |
| перевод строки | \n | |
| возврат каретки | \r | |
| горизонтальный TAB | \t | |
| остальные | ddd |
| -d | каждое слово интерпретируется как десятичное число; |
| -o | слова интерпретируются как восьмеричные числа; |
| -x | слова интерпретируются как шестнадцатеричные числа. |
dump [флаги[аргумент...] файловая система]
Используется администратором для обеспечения сохранности всех данных в файловой системе.
Флаги:
| d | задание плотности записи на ленту. |
| f | задает устройство для защиты; |
| s | задание размера ленты; |
| u | запись времени защиты; |
| 0-9 | уровень защиты; |
restor флаги [аргументы]
Чтение магнитных лент, записанных командой dump.
Разбиение файла на части
split [-n][файл[имя]]
разбивает файл на части по n строк (по умолчанию n=1000).
Если задано имя выходного файла, то генерируется последовательность файлов с данным именем и буквами aa, ab, ac,... в конце. Если имя выходного файла не задано, используется имя "x".
Подсчет числа слов
wc[-lwc] [файл]
Определяет число строк, слов и символов в одном или более файлов. Строки в файле разделяются символом "\n", слова - пробелами, горизонтальной табуляцией или переводом строки.
Флаги:
| l | подсчет числа строк в файле; |
| w | подсчет числа слов в файле; |
| c | подсчет числа символов в файле; |
uniq [-флаги[+n][-n]][вход][выход]
Находит одинаковые соседние строки файла. По умолчанию все одинаковые строки кроме одной удаляются.
Флаги:
| c | одинаковые строки удаляются, но в начале строки ставится их исходное число; |
| d | выводятся только одинаковые строки; |
| -n | первые n полей при сравнении пропускаются; |
| +n | перед сравнением пропускаются первые n символов; |
| u | выводятся только разные строки. |
/p> Обнаружение различий в файлах
diff[-флаги]файл1 файл2
Определяются изменения, которые должны быть произведены в файлах, чтобы сделать их идентичными.
Позволяет экономить место при хранении ряда версий файла.
Флаги:
| -b | игнорируются все пробелы и символы табуляции в конце строки, любые комбинации таких символов считаются эквивалентными; |
| -e | выдает последовательность команд редактора ed, с помощью которых первый файл может быть сделан эквивалентным второму. |
| -f | вырабатывает список изменений; |
| -h | быстро обнаруживает различия, но не всегда корректно. |
sort[-флаги...][+поз1[-поз2]]...[-o имя][-T каталог][имя]...
соединяет и сортирует файлы, помещает результат в заданный файл. Если ключ сортировки не задан, при сравнении используется вся строка.
Флаги:
| b | при сравнении полей игнорируются пробелы и табуляции в начале строки; |
| c | проверяется, отсортирован ли входной файл в соответствии с заданными правилами; |
| d | "словарная сортировка": в сравнении участвуют только буквы, цифры и пробелы; |
| f | прописные буквы воспринимаются как строчные; |
| i | при нечисловых сравнениях игнорируются символы, не входящие в диапазон ASCII 040-0176; |
| m | слияние файлов, которые предполагаются отсортированными; |
| n | сортировка по арифметическому значению; |
| o | имя, идущее после воспринимается как имя выходного файла; |
| r | задается обратный порядок сортировки; |
| tx | буква t указывает на то, что вместо принятого по умолчанию пробела в качестве разделителя используется горизонтальная табуляция; |
| T | задает имя каталога, где размещаются временные файлы; |
| u | если одному ключу соответствует несколько строк, выводится только одна из них. |
Вывод аргументов
echo[-n][аргумент]
Выводит в стандартный файл заданные ей аргументы, разделяя их пробелами и завершая вывод переводом строки. Служит для сообщения о выполнении последовательности команд. Флаг -n предоставляет возможность отменить перевод строки после вывода аргументов.
Уничтожение процесса
kill [-флаг] процесс...
единственный флаг, допустимый в команде kill, - номер сигнала, например флаг -9 безусловно ликвидирует процесс.
Задержка выполнения команды
sleep время
Задерживает выполнение команды на время, заданное в секундах.
Понижение приоритета команды
nice [-число]команда[аргументы]
Позволяет выполнить другую команду, с более низким приоритетом. Аргумент-число определяет степень понижения приоритета. Чем больше число, тем меньше приоритет.
Дублирование стандартного вывода
tee [флаг]...[флаг]...
команда читает информацию из стандартного ввода и выводит ее одновременно на терминал и в заданные файлы.
Флаги:
| -i | игнорировать прерывания; |
| -a | вывод будет добавлен к файлу, вместо принятого по умолчанию создания нового файла. |
date [ггммддччмм][.сс]]
| гг | год |
| мм | месяц |
| дд | день |
| чч | час |
| мм | минуты |
| сс | секунды |
who [файл] [am I]
выдает список всех пользователей, работающих в данный момент, и имена их терминалов. [файл] - имя файла, где хранится информация о текущих пользователях. По умолчанию /etc/utmp. [am I] - дает возможность сообщить под каким именем вы вошли в систему.
Получение имени терминала
tty
печатает имя терминала, за которым вы работаете.
Состояние процессов
ps [флаг...][файл]
предоставляет информацию об активных процессах в системе.
Флаги:
| a | выдается информация обо всех процессах, управляемых терминалами. |
| x | выдается информация обо всех процессах, не управляемых терминалами (системных). |
| l | выдается полная информация с указанием состояния каждого процесса. |
| PID | идентификатор процесса; |
| TTY | номер терминала; |
| CMD | команда, выполняемая процессом. |
| UID | идентификатор пользователя; |
| PPID | идентификатор процесса, породившего данный процесс; |
| CPU | системная составляющая приоритета процесса; |
| PRI | приоритет процесса, чем больше, тем ниже; |
| NICE | пользовательская составляющая приоритета процесса; |
| ADDR | для резидентного процесса адрес в памяти, в противном случае на диске; |
| SZ | размер образа процесса в блоках; |
| WCHAN | событие, которого ожидает процесс с состоянием S или W; пустое поле означает, что процесс работает. |
/p>
pstat |
сообщает о статусе системы. |
du[-s][-a][имя...]
Флаги:
| -s | выводит только общее количество блоков для всех файлов. |
| -a | печатает информацию для каждого файла. |
df [файловая система]
выводит количество блоков, доступных в заданной файловой системе.
Определение типа файла
file имя...
Определяется тип файла: .OBJ, .C, ASCII и т.д.
Печать календаря
cal [месяц]год
Установка функций терминала
stty [аргументы...]
позволяет узнать состояние любого терминала и настроить его на требуемый режим работы.
Аргументы:
| even | включить контроль по четности; |
| -even | выключить контроль по четности; |
| odd | включить контроль на нечетность; |
| raw | включить прозрачный режим ввода; |
| nl | концом строки считать символ "перевода строки"; |
| -nl | концом строки считать символ "возврат каретки"; |
| echo | отображать на экране каждый вводимый символ; |
| -echo | не отображать вводимые символы; |
| lcase | преобразовывать прописные символы в строчные; |
| tabs | заменить символы табуляции на пробелы при выводе; |
| erase | установит следующий за erase символ в качестве символа стирания; |
| kill | установит следующий за kill символ в качестве символа отмены; |
tabs [аргументы]
Устанавливает параметры табуляции для любого терминала.
Аргументы:
| -n | используется, когда левое поле текста не выравнивается; |
| терминал | описывает тип рабочего терминала. |
uncompress |
разархивирует файлы, имеющие расширение .Z; |
uncompress имя_файла |
работает для файлов без расширения .Z. |
uuencode файл указатель |
используется для передачи двоичных (иногда и русских) файлов по электронной почте. Преобразует двоичный файл в ASCII-формат. Параметр указатель используется при декодировании и служит для указания маршрута и имени файла для команды uudecode. Результат кодировки можно положить в другой файл или непосредственно переслать по электронной почте. |
uudecode файл |
используется для передачи двоичных (иногда и русских) файлов по электронной почте. Преобразует двоичный файл в ASCII-формат. Параметр указатель используется при декодировании и служит для указания маршрута и имени файла для команды uudecode. Результат кодировки можно положить в другой файл или непосредственно переслать по электронной почте. |
nslookup |
выводит IP-информацию о домене; |
crypt |
кодирует файл по заданному пользователем ключу |
uuname |
выводит список узлов, известных данному узлу; |
uux |
выполняет команды на удаленной машине UNIX. |
Квантовая криптография
6.9 Квантовая криптография
Семенов Ю.А. (ГНЦ ИТЭФ)
Базовой задачей криптографии является шифрование данных и аутентификация отправителя. Это легко выполнить, если как отправитель, так и получатель имеют псевдослучайные последовательности бит, называемые ключами. Перед началом обмена каждый из участников должен получить ключ, причем эту процедуру следует выполнить с наивысшим уровнем конфиденциальности, так чтобы никакая третья сторона не могла получить доступ даже к части этой информации. Задача безопасной пересылки ключей может быть решена с помощью квантовой рассылки ключей QKD (Quantum Key Distribution). Надежность метода зиждется на нерушимости законов квантовой механики. Злоумышленник не может отвести часть сигнала с передающей линии, так как нельзя поделить электромагнитный квант на части. Любая попытка злоумышленника вмешаться в процесс передачи вызовет непомерно высокий уровень ошибок. Степень надежности в данной методике выше, чем в случае применения алгоритмов с парными ключами (например, RSA). Здесь ключ может генерироваться во время передачи по совершенно открытому оптическому каналу. Скорость передачи данных при этой технике не высока, но для передачи ключа она и не нужна. По существу квантовая криптография может заменить алгоритм Диффи-Хелмана, который в настоящее время часто используется для пересылки секретных ключей шифрования по каналам связи.Первый протокол квантовой криптографии (BB84) был предложен и опубликован в 1984 году Беннетом и Брассардом. Позднее идея была развита Экертом в 1991 году. В основе метода квантовой криптографии лежит наблюдение квантовых состояний фотонов. Отправитель задает эти состояния, а получатель их регистрирует. Здесь используется квантовый принцип неопределенности, когда две квантовые величины не могут быть измерены одновременно с требуемой точностью. Так поляризация фотонов может быть ортогональной диагональной или циркулярной. Измерение одного вида поляризации рэндомизует другую составляющую. Таким образом, если отправитель и получатель не договорились между собой, какой вид поляризации брать за основу, получатель может разрушить посланный отправителем сигнал, не получив никакой полезной информации.
Отправитель кодирует отправляемые данные, задавая определенные квантовые состояния, получатель регистрирует эти состояния. Затем получатель и отправитель совместно обсуждают результаты наблюдений. В конечном итоге со сколь угодно высокой достоверностью можно быть уверенным, что переданная и принятая кодовые последовательности тождественны. Обсуждение результатов касается ошибок, внесенных шумами или злоумышленником, и ни в малейшей мере не раскрывает содержимого переданного сообщения. Может обсуждаться четность сообщения, но не отдельные биты. При передаче данных контролируется поляризация фотонов. Поляризация может быть ортогональной (горизонтальной или вертикальной), циркулярной (левой или правой) и диагональной (45 или 1350).
В качестве источника света может использоваться светоизлучающий диод или лазер. Свет фильтруется, поляризуется и формируется в виде коротких импульсов малой интенсивности. Поляризация каждого импульса модулируется отправителем произвольным образом в соответствии с одним из четырех перечисленных состояний (горизонтальная, вертикальная, лево- или право-циркулярная).
Получатель измеряет поляризацию фотонов, используя произвольную последовательность базовых состояний (ортогональная или циркулярная). Получатель открыто сообщает отправителю, какую последовательность базовых состояний он использовал. Отправитель открыто уведомляет получателя о том, какие базовые состояния использованы корректно. Все измерения, выполненные при неверных базовых состояниях, отбрасываются. Измерения интерпретируются согласно двоичной схеме: лево-циркулярная поляризация или горизонтальная - 0, право-циркулярная или вертикальная - 1. Реализация протокола осложняется присутствием шума, который может вызвать ошибки. Вносимые ошибки могут быть обнаружены и устранены с помощью подсчета четности, при этом один бит из каждого блока отбрасывается. Беннет в 1991 году предложил следующий протокол.
Отправитель и получатель договариваются о произвольной перестановке битов в строках, чтобы сделать положения ошибок случайными.
Строки делятся на блоки размера k (k выбирается так, чтобы вероятность ошибки в блоке была мала).
Для каждого блока отправитель и получатель вычисляют и открыто оповещают друг друга о полученных результатах. Последний бит каждого блока удаляется.
Для каждого блока, где четность оказалась разной, получатель и отправитель производят итерационный поиск и исправление неверных битов.
Чтобы исключить кратные ошибки, которые могут быть не замечены, операции пунктов 1-4 повторяются для большего значения k.
Для того чтобы определить, остались или нет необнаруженные ошибки, получатель и отправитель повторяют псевдослучайные проверки:
Получатель и отправитель открыто объявляют о случайном перемешивании позиций половины бит в их строках.
Получатель и отправитель открыто сравнивают четности. Если строки отличаются, четности должны не совпадать с вероятностью 1/2.
Если имеет место отличие, получатель и отправитель, использует двоичный поиск и удаление неверных битов.
Если отличий нет, после m итераций получатель и отправитель получают идентичные строки с вероятностью ошибки 2-m.
Схема реализация однонаправленного канала с квантовым шифрованием показана на рис. .1. Передающая сторона находится слева, а принимающая - справа. Ячейки Покеля служат для импульсной вариации поляризации потока квантов передатчиком и для анализа импульсов поляризации приемником. Передатчик может формировать одно из четырех состояний поляризации (0, 45, 90 и 135 градусов). Собственно передаваемые данные поступают в виде управляющих сигналов на эти ячейки. В качестве канала передачи данных может использоваться оптическое волокно. В качестве первичного источника света можно использовать и лазер.

Рис. .1. Практическая схема реализации идеи квантовой криптографии
На принимающей стороне после ячейки Покеля ставится кальцитовая призма, которая расщепляет пучок на два фотодетектора (ФЭУ), измеряющие две ортогональные составляющие поляризации. При формировании передаваемых импульсов квантов приходится решать проблему их интенсивности. Если квантов в импульсе 1000, есть вероятность того, что 100 квантов по пути будет отведено злоумышленником на свой приемник. Анализируя позднее открытые переговоры между передающей и принимающей стороной, он может получить нужную ему информацию. В идеале число квантов в импульсе должно быть около одного. Здесь любая попытка отвода части квантов злоумышленником приведет к существенному росту числа ошибок у принимающей стороны. В этом случае принятые данные должны быть отброшены и попытка передачи повторена. Но, делая канал более устойчивым к перехвату, мы в этом случае сталкиваемся с проблемой "темнового" шума (выдача сигнала в отсутствии фотонов на входе) приемника (ведь мы вынуждены повышать его чувствительность). Для того чтобы обеспечить надежную транспортировку данных логическому нулю и единице могут соответствовать определенные последовательности состояний, допускающие коррекцию одинарных и даже кратных ошибок.
Дальнейшего улучшения надежности криптосистемы можно достичь, используя эффект EPR (Binstein-Podolsky-Rosen). Эффект EPR возникает, когда сферически симметричный атом излучает два фотона в противоположных направлениях в сторону двух наблюдателей. Фотоны излучаются с неопределенной поляризацией, но в силу симметрии их поляризации всегда противоположны. Важной особенностью этого эффекта является то, что поляризация фотонов становится известной только после измерения. На основе EPR Экерт предложил крипто-схему, которая гарантирует безопасность пересылки и хранения ключа. Отправитель генерирует некоторое количество EPR фотонных пар. Один фотон из каждой пары он оставляет для себя, второй посылает своему партнеру. При этом, если эффективность регистрации близка к единице, при получении отправителем значения поляризации 1, его партнер зарегистрирует значение 0 и наоборот. Ясно, что таким образом партнеры всякий раз, когда требуется, могут получить идентичные псевдослучайные кодовые последовательности. Практически реализация данной схемы проблематична из-за низкой эффективности регистрации и измерения поляризации одиночного фотона.
Неэффективность регистрации является платой за секретность. Следует учитывать, что при работе в однофотонном режиме возникают чисто квантовые эффекты. При горизонтальной поляризации (H) и использовании вертикального поляризатора (V) результат очевиден - фотон не будет зарегистрирован. При 450 поляризации фотона и вертикальном поляризаторе (V) вероятность регистрации 50%. Именно это обстоятельство и используется в квантовой криптографии. Результаты анализа при передаче двоичных разрядов представлены в таблице .1. Здесь предполагается, что для передатчика логическому нулю соответствует поляризация V, а единице - +450, для принимающей стороны логическому нулю соответствует поляризация -450, а единице - Н.
0 0 1 1 Результат приема - - + - Понятно, что в первой и четвертой колонке поляризации передачи и приеме ортогональны и результат детектирования будет отсутствовать. В колонках 2 и 3 коды двоичных разрядов совпадают и поляризации не ортогональны. По этой причине с вероятностью 50% может быть позитивный результат в любом из этих случаев (и даже в обоих). В таблице предполагается, что успешное детектирование фотона происходит для случая колонки 3. Именно этот бит становится первым битом общего секретного ключа передатчика и приемника.
Однофотонные состояния поляризации более удобны для передачи данных на большие расстояния по оптическим кабелям. Такого рода схема показана на рис. .2 (алгоритм В92; R. J. Hughes, G. G. Luther, G. L. Morgan, C. G. Peterson and C. Simmons, "Quantum cryptography over optical fibers", Uni. of California, Physics Division, LANL, Los Alamos, NM 87545, USA).

Рис. .2. Реализация алгоритма B92
В алгоритме В92 приемник и передатчик создают систему, базирующуюся на интерферометрах Маха-Цендера. Отправитель определяет углы фазового сдвига, соответствующие логическому нулю и единице (FA=p/2), а приемник задает свои фазовые сдвиги для логического нуля (FB=3p/2) и единицы (FB=p). В данном контексте изменение фазы 2p соответствует изменению длины пути на одну длину волны используемого излучения.
Хотя фотоны ведут себя при детектировании как частицы, они распространяются как волны. Вероятность того, что фотон, посланный отправителем, будет детектирован получателем равна
| PD = cos2{(FA - FB)/2} | [1] |
Для регистрации одиночных фотонов, помимо ФЭУ, могут использоваться твердотельные лавинные фотодиоды (германиевые и InGaAs). Для понижения уровня шума их следует охлаждать. Эффективность регистрации одиночных фотонов лежит в диапазоне 10-40%. При этом следует учитывать также довольно высокое поглощение света оптическим волокном (~0,3-3ДБ/км). Схема интерферометра с двумя волокнами достаточно нестабильна из-за разных свойств транспортных волокон и может успешно работать только при малых расстояниях. Лучших характеристик можно достичь, мультиплексируя оба пути фотонов в одно волокно [7] (см. рис. .3).

Рис. .3. Интерферометр с одним транспортным волокном
В этом варианте отправитель и получатель имеют идентичные неравноплечие интерферометры Маха-Цендера (красным цветом отмечены зеркала). Разность фаз длинного и короткого путей DT много больше времени когерентности светового источника. По этой причине интерференции в пределах малых интерферометров не происходит (Б). Но на выходе интерферометра получателя она возможна (В). Вероятность того, что фотонные амплитуды сложатся (центральный пик выходного сигнала интерферометра В) равна
| P = (1/8)[1 + cos(FA - FB)] | [2] |
Библиография
Charles H. Bennett, Francois Bessette, Gilles Brassard, Louis Salvail, and John Smolin, "Experimental Quantum Cryptography", J. of Cryptography 5, 1992, An excellent description of a protocol for quantum key distribution, along with a description of the first working system.
Charles H. Bennett, Gilles Brassard, and Artur Ekert, Quantum Cryptography, Scientific American, July, 1992 (www.scitec.auckland.ac.nz/king/Preprints/book/quantcos/aq/ qcrypt.htm).
www.cyberbeach.net/~jdwyer/quantum_crypto/quantum2.htm
www.cs.dartmoth.edu/jford/crypto.html
A.K. Ekert, " Quantum Cryptography Based on Bell's Theorem", Phys. Rev. lett. 67, 661 (1991).
Toby Howard, Quantum Cryptography, 1997, www.cs.man.ac.uk/aig/staff/toby /writing/PCW/qcrypt.htm
C.H. Bennet, " Quantum Cryptography Using Any Two Non-Orthogonal States", Phys. Rev. lett. 68, 3121 (1992).
J. D. Franson and H.Ilves, "Quantum Cryptography Using Optical Fibers", Appl. Optics 33, 2949 (1994)
R. J. Hughes et al., "Quantum Cryptography Over 14 km of Installed Optical Fiber", Los Alamos report LA-UR-95-2836, invited paper to appear in Proceeding of "Seventh Rochester Conference on Coherence and Quantum Optics", Rochester, NY, June 1995.
С. H. Bennet et al., "Generalized Privacy Amplification", IEEE Trans. Inf. Theory 41, 1915 (1995)
Литература
9 Литература
Семенов Ю.А. (ГНЦ ИТЭФ)

Guide to Network Resource Tools
. EARN Association, Sept. 15, 1993, V2.0. (ISBN 2- 910286-03-7). 3. Douglas E. Comer, Internetworking with TCP/IP, Prentice Hall, Englewood Cliffs, N.J. 07632, 1988 4. Uyless Black, TCP/IP and Related Protocols, McGraw-Hill, Inc, New York. 1992 5. Feinler, E., et al, DDN Protocol Handbook, DDN Network Information Center, SRI International, Ravenswood Avenue, Menlow Park, California, USA, 1985 6. Spider Systems, Ltd., "Packets and Protocols", Stanwell Street, Edinburgh, UK. EH6 5NG, 1990. 7. Tony Bates, et al, "Representation of IP Routing Polices in a Routing Registry" (RIPE-181.txt, October 1994) 8. A. N. Bobyshev, S. I. Burov, M. Ernst, A. I. Kravtsov, A. O. Saphonov, Yu. A. Semenov "ITEPNET to Internet communication", ITEP III92. 9. Robert J. T. Morris "Neural Network Control of Communications Systems" IEEE Transactions on Neural Networks, Vol. 5, No. 4, July 1944. 10. Paul J. Fortier, Handbook of LAN Technology. 2-nd Edition, McGraw-Hill, 1992 11. W.Richard Stevens "TCP/IP Illustrated", Addison-Wesley Publishing Company, 1994. 12. Matthew Flint Arnett, Mike Coulombe, et al. Inside TCP/IP, Second Edition, New Riders Publishing, 1995 13. Лаура Ф. Чаппелл и Дэн Е. Хейкс. Анализатор локальных сетей NetWare (Руководство Novell), Москва, Изд. “ЛОРИ”, 1995. 14. А. В. Фролов и Г. В. Фролов, Локальные сети персональных компьютеров. Использование протоколов IPX, SPX, NETBIOS, Москва, “Диалог-МИФИ”, 1993 15. К. Джамса, К. Коуп, Программирование для INTERNET в среде Windows, Санкт-Петербург, “ПИТЕР”, 1996. 16.
ISDN How to get a high-speed connection to the Internet
, Charles Summers, Bryant Dunetz, “John Wiley @ Sons, Inc.”
17.
ISDN Explained, Worldwide Network and Applications Technology
, 2 edition, John M. Griffiths, John Wiley & sons.
18.
ISDN. Цифровая сеть с интеграцией служб. Понятия, методы, системы. П. Боккер, Москва, Радио и связь, 1991.
19.
С. Вильховченко, Модем 96. Выбор, настройка и использование. Москва, ABF, 1995.
20.
Справочник “Протоколы информационно-вычислительных сетей”. Под ред. И. А. Мизина и А. П. Кулешова, Радио и связь, Москва 1990.
21.
Douglas E. Comer, Internetworking with TCP/IP, Prentice Hall, Englewood Cliffs, N.J. 07632, 1988
22.
Craig Hunt, TCP/IP Network Administration, O’Reilly Associates, Inc., Sebastopol, USA, 1992
23.
А. В. Фролов и Г.В. Фролов, Модемы и факс-модемы. Программирование для MS-DOS и Windows. Москва, “Диалог-МИФИ”, 1995.
24.
Семенов Ю. А. “Протоколы и ресурсы INTERNET” “Радио и связь”, Москва, 1996
25.
Семенов Ю. А. “Сети Интернет. Архитектура и протоколы”, СИРИНЪ, 1998.
26.
А. Н. Назаров, М.В. Симонов, “ATM-технология высокоскоростных сетей” ЭКО-ТРЕНДЗ, Москва 1998.
27.
Н. Н. Слепов, “Синхронные цифровые сети SDH” ЭКО-ТРЕНДЗ, Москва 1998.
28.
"Интернет. Всемирная компьютерная сеть. Практическое пособие и путеводитель". Москва 1995, изд. "Синтез".
29.
"World Wide Web. Всемирная Информационная паутина в сети Интернет". Практическое руководство. МГУ, 1995.
30.
Эд Крол “Все об INTERNET” BNV, Киев 1995.
31.
Пол Гилстер "Навигатор INTERNET. Путеводитель для человека с компьютером и модемом", Москва 1995.
32.
С. Клименко, В. Уразметов "Internet. Среда обитания информационного общества". РФФИ, Информационные системы в науке.
33.
Лаем Куин, Ричард Рассел, Fast Ethernet, bhv, Киев, 1998.
34.
Тимоти Паркер, Освой самостоятельно TCP/IP. Бином, Москва 1997.
35.
Дональд Дж. Стерлинг, Волоконная оптика. Техническое руководство. Изд. “ЛОРИ”, Москва, 1998
36.
Дж. Гауэр, Оптические системы связи. Москва, “Радио и связь”, 1989.
37.
Стивен Спейнаур и Валери Куэрсиа. Справочник WEB-мастера, BHV, Киев, 1997.
38.
Lincoln D. Stein, Web Security: a step-by-step reference guide, Addison-Wesley, 1997
39.
К.Шеннон, Работы по теории информации и кибернетике, Москва,"Изд. иностранной литературы", 1963
40.
В.Е.Котов, Сети Петри,"Наука", Москва, Глав. ред. физ-мат. лит., 1984
41.
Лайза Хендерсон, Том Дженкинс, Frame Relay межсетевые взаимодействия, Москва, "Горячая линия - Телеком", 2000
Локально адаптивный алгоритм сжатия
2.6.2 Локально адаптивный алгоритм сжатия
Семенов Ю.А. (ГНЦ ИТЭФ)
Этот алгоритм используется для кодирования (L,I), где L строка длиной N, а I – индекс. Это кодирование содержит в себе несколько этапов.
1. Сначала кодируется каждый символ L с использованием локально адаптивного алгоритма для каждого из символов индивидуально. Определяется вектор целых чисел R[0],…,R[N-1], который представляет собой коды для символов L[0],…,L[N-1]. Инициализируется список символов Y, который содержит в себе каждый символ из алфавита Х только один раз. Для каждого i = 0,…,N-1 устанавливается R[i] равным числу символов, предшествующих символу L[i] из списка Y. Взяв Y = [‘a’,’b’,’c’,’r’] в качестве исходного и L = ‘caraab’, вычисляем вектор R: (2 1 3 1 0 3).
2. Применяем алгоритм Хафмана или другой аналогичный алгоритм сжатия к элементам R, рассматривая каждый элемент в качестве объекта для сжатия. В результате получается код OUT и индекс I.
Рассмотрим процедуру декодирования полученного сжатого текста (OUT,I).
Здесь на основе (OUT,I) необходимо вычислить (L,I). Предполагается, что список Y известен.
Сначала вычисляется вектор R, содержащий N чисел: (2 1 3 1 0 3).
Далее вычисляется строка L, содержащая N символов, что дает значения R[0],…,R[N-1]. Если необходимо, инициализируется список Y, содержащий символы алфавита X (как и при процедуре кодирования). Для каждого i = 0,…,N-1 последовательно устанавливается значение L[i], равное символу в положении R[i] из списка Y (нумеруется, начиная с 0), затем символ сдвигается к началу Y. Результирующая строка L представляет собой последнюю колонку матрицы M. Результатом работы алгоритма будет (L,I). Взяв Y = [‘a’,’b’,’c’,’r’] вычисляем строку L = ‘caraab’.
Наиболее важным фактором, определяющим скорость сжатия, является время, необходимое для сортировки вращений во входном блоке. Наиболее быстрый способ решения проблемы заключается в сортировке связанных строк по суффиксам.
Для того чтобы сжать строку S, сначала сформируем строку S’, которая является объединением S c EOF, новым символом, который не встречается в S. После этого используется стандартный алгоритм к строке S’. Так как EOF отличается от прочих символов в S, суффиксы S’ сортируются в том же порядке, как и вращения S’. Это может быть сделано путем построения дерева суффиксов, которое может быть затем обойдено в лексикографическом порядке для сортировки суффиксов. Для этой цели может быть использован алгоритм формирования дерева суффиксов Мак-Крейгта. Его быстродействие составляет 40% от наиболее быстрой методики в случае работы с текстами. Алгоритм работы с деревом суффиксов требует более четырех слов на каждый исходный символ. Манбер и Майерс предложили простой алгоритм сортировки суффиксов строки. Этот алгоритм требует только двух слов на каждый входной символ. Алгоритм работает сначала с первыми i символами суффикса а за тем, используя положения суффиксов в сортируемом массиве, производит сортировку для первых 2i символов. К сожалению этот алгоритм работает заметно медленнее.
В работе [1] предложен несколько лучший алгоритм сортировки суффиксов. В этом алгоритме сортируются суффиксы строки S, которая содержит N символов S[0,…,N-1].
Пусть k число символов, соответствующих машинному слову. Образуем строку S’ из S путем добавления k символов EOF в строку S. Предполагается, что EOF не встречается в строке S.
Инициализируем массив W из N слов W[0,…,N-1] так, что W[i] содержат символы S’[i,…,i+k-1] упорядоченные таким образом, что целочисленное сравнение слов согласуется с лексикографическим сравнением для k-символьных строк. Упаковка символов в слова имеет два преимущества: это позволяет для двух префиксов сравнить сразу k байт и отбросить многие случаи, описанные ниже.
Инициализируется массив V из N целых чисел. Если элемент V содержит j, он представляет собой суффикс S’, чей первый символ равен S’[j]. Когда выполнение алгоритма завершено, суффикс V[i] будет i-ым суффиксом в лексикографическом порядке.
Инициализируем целочисленный массив V так, что для каждого i = 0,…,N-1 : V[i]=i.
Сортируем элементы V, используя первые два символа каждого суффикса в качестве ключа сортировки. Далее для каждого символа ch из алфавита выполняем шаги 6 и 7. Когда эти итерации завершены, V представляет собой отсортированные суффиксы S и работа алгоритма завершается.
Для каждого символа ch’ в алфавите выполняем сортировку элементов V, начинающихся с ch, за которым следует ch’. В процессе выполнения сортировки сравниваем элементы V путем сопоставления суффиксов, которые они представляют при индексировании массива W. На каждом шаге рекурсии следует отслеживать число символов, которые оказались равными в группе, чтобы не сравнивать их снова. Все суффиксы, начинающиеся с ch, отсортированы в рамках V.
Для каждого элемента V[i], соответствующего суффиксу, начинающемуся с ch (то есть, для которого S[V[i]] = ch), установить W[V[i]] значение с ch в старших битах и i в младших битах. Новое значение W[V[i]] сортируется в те же позиции, что и старые значения.
Данный алгоритм может быть улучшен различными способами. Одним из самоочевидных методов является выбор символа ch на этапе 5, начиная с наименьшего общего символа в S и предшествующий наиболее общему.
Ссылки
M.Burrows and D.J.Wheeler. A block-sorting Lossless Data Compression Algorithm. Digital Systems Research Center. SRC report 124. May 10, 1994.
J.L.Bently, D.D.Sleator, R.E.Tarjan, and V.K.Wei. A locally adaptive data compression algorithm. Communications of the ACM, Vol. 29, No. 4, April 1986, pp. 320-330
E.M.McCreight. A space economical suffix tree construction algorithm. Journal of the ACM, Val. 32, No. 2, April 1976, pp. 262-272.
U.Manber and E.W.Mayers, Suffix arrays: Anew method for on-line string searches. SIAM Journal on Computing, Vol. 22, No. 5, October 1993, pp. 935-948.
Смотри также раздел 2.6.3 "Сжатие данных с использованием преобразования Барроуза-Вилера",
Локальные сети ArcNet
4.1.5 Локальные сети ArcNet
Семенов Ю.А. (ГНЦ ИТЭФ)

ARCNET - (attached resource computing network - смотри также http://www.smc.com/network/arcnet) представляет собой стандарт на локальные сети, разработанный корпорацией datapoint в 1977 году. Эта сеть базируется на идее маркерной шины и может позволить реализовать топологию шины, кольца или звезды при скорости обмена 2,5Мбит/с. Сеть строится вокруг активных и пассивных повторителей (HUB). Активные повторители (обычно 8-канальные) могут соединяться друг с другом, с пассивными повторителями/разветвителями и оконечными ЭВМ (рабочими станциями). Длина таких соединений, выполняемых 93-омным коаксиальным кабелем (RG-62, разъемы BNC), может достигать 600м. Допускается применение скрученных пар (RS485) или оптического волокна. Пассивный 4-входовый повторитель позволяет подключать до трех рабочих станций кабелем длиной до 35 м, один из входов всегда занят соединением с активным повторителем. Пассивные повторители не могут соединяться друг с другом. Активные повторители могут образовывать иерархическую структуру. Максимальное число рабочих станций в сети равно 255. Предельная суммарная длина кабелей многосегментной сети составляет около 7 км. Схема соединений в сети arcnet показана на рис. 4.1.5.1 (пунктиром обозначены возможные связи с другими активными повторителями или маршрутизаторами).
В настоящее время разработан стандарт arcnet plus, рассчитанный на скорость обмена до 20 Мбит/с, совместимый с прежней версией. Новый стандарт позволяет строить сети с числом станций в 8 раз больше, чем старый. Если в сети присутствуют узлы, рассчитанные на разную скорость обмена, выбор полосы пропускания осуществляется при установлении связи. Соединение с другими сетями (например, Ethernet, Token Ring или Интернет) возможно через специальные шлюзы, мосты или маршрутизаторы.
Каждому узлу в сети присваивается уникальный адрес в диапазоне от 1 до 255. Стандарт arcnet поддерживает работу с пакетами двух длин:
Пакет маркер (itt-приглашение). Рабочая станция, получившая такой пакет, может что-нибудь послать.
Запрос свободного буфера (FBE - free buffer enquire). Служит для выяснения возможности приема данных получателем.
Подтверждение получения (ACK), посылается в ответ на FBE при корректном приеме.
Отрицательное подтверждение (NAK), посылается в случае приема с ошибкой.
Пакет, содержащий информацию, адрес получателя, отправителя и контрольную сумму.
Сеть Arcnet допускает фрагментацию (ANSI 878.2) сообщений и инкапсуляцию (ansi 878.3) пакетов, отвечающих требованиям других протоколов.

Рис. 4.1.5.1. Топологическая схема сети Arcnet
Все кадры начинаются с аппаратного заголовка и завершаются пользовательскими данными, в начале которых всегда присутствует программный заголовок. Между аппаратным и программным заголовками вводится заполнитель, обеспечивающий постоянство длин пакетов. Этот заполнитель удаляется интерфейсом так, что программа его не видит.
Короткие кадры могут содержать от 0 до 249 байт полезной информации. Длинные кадры могут нести от 253 до 504 байт. Для того, чтобы иметь возможность работать с кадрами, содержащими 250, 251 или 252 байт информации, введен специальный формат (exception). Форматы этих кадров ARCNET представлены на рис. 4.1.5.2.
Эти пакеты представлены так, как их видит программное прикладное обеспечение, по этой причине это представление иногда называется “буферным”. Пакеты в сети выглядят несколько иначе: идентификатор места назначения дублируется, заполнитель между полем смещения и идентификатором протокола вообще не пересылается.
arcnet позволяет делить длинные внешние пакеты или сообщения на ряд фрагментов, максимальное число которых может достигать 120.
Поле флаг фрагментации указывает на наличие фрагментации пакета. Не фрагментированные пакеты имеют этот флаг равный нулю. Для первого пакета фрагментированного сообщения этот флаг равен ((t-2)*2)+1, где t - полное число фрагментов.

Рис. 4.1.5.2 Форматы кадров ARCNET
Пакеты, несущие в себе последующие части сообщения, имеют в этом поле код равный ((N-1)*2), где N - номер фрагмента. Так пятый фрагмент сообщения будет содержать в поле флага фрагментации код 8. Принимающая станция может идентифицировать последний фрагмент сообщения, так как он будет иметь флаг фрагментации больше, чем у первого фрагмента. Значения флага фрагментации более 0xEE запрещены.
Значение флага фрагментации 0xFF используется для пометки кадров специального формата (exception). Все фрагменты одного и того же сообщения имеют идентичные поля номера по порядку.
IP и ARP-дейтограммы инкапсулируются в соответствующие ARCNET пакеты. Если длина дейтограмм превосходит 504 октета, они делятся на фрагменты и пересылаются по частям. Взаимосвязь IP- и 8-битных ARCNET адресов осуществляется с помощью протокола ARP (см. RFC-826. Plammer D., “An Ethernet Address Resolution Protocol”, MIT, Nov. 1982).
Можно устроить так, чтобы младшие 8 бит IP-адреса совпадали с ARCNET адресом. В этом случае ARP-протокол не потребуется. Но этот путь не рекомендуется, так как он менее гибок. Все широковещательные и мультикастинг IP-адреса должны соответствовать ARCNET-адресу 0.
Корпорация Datapoint использует следующие идентификаторы протоколов: 212 (десятичное) для IP, 213 - для ARP и 214 - для протокола RARP.
Сети ARCNET отличаются дешевизной, простотой установки и эксплуатации. За последнее время в связи с резким удешевлением Ethernet-интерфейсов это преимущество несколько нивелировалось. Взаимодействие ARCNET и Интернет описано в документе STD-46.
Локальные сети (обзор)
4.1 Локальные сети (обзор)
Семенов Ю.А. (ГНЦ ИТЭФ)

В этом разделе речь идет о физической среде локальных сетей.
Маршрутная политика
4.4.11.7 Маршрутная политика
Семенов Ю.А. (ГНЦ ИТЭФ)
Содержанием политики маршрутизации являются правила обмена маршрутной информацией между автономными системами (RIPE-181.txt). Не следует путать "маршрутную политику" и просто "политику", между ними такое же различие, как между "милостивым государем" и "государем". Способы их описания разнятся столь же значительно. При описании обычной политики одной из главных задач является сокрытие истинных намерений, а одним из средств - многословие. При описании же маршрутной политики важна лаконичность и четкость. В Интернет для решения этой задачи выработан стандарт, краткое изложение которого на конкретных примерах будет приведено ниже. Объектами маршрутной политики являются автономные системы (AUT-NUM) и маршруты (route). Существует два акта маршрутной политики:
оповещение
(announce) и
восприятие (accept).
Эти акты определяют взаимодействие с ближайшими соседями. Совокупность информации, выданной всеми маршрутизаторами региональной сети, описывает ее граф. Следует иметь в виду, что в пределах автономной системы (AS) может работать только один внутренний протокол маршрутизации (IGP), а обмен маршрутной информацией между автономными системами происходит в соответствии с внешним протоколом маршрутизации (EGP). Эта идея продемонстрирована на рис. 4.4.11.4.1. ЭВМ (или узлы) A1,B1,C1,D1 и маршрутизатор G-1 составляют одну автономную систему, а A2,B2,C2,D2,E2 и маршрутизатор G-2 - вторую.
Рис. 4.4.11.4.1. Схема связи автономных систем
Пусть имеются две автономные системы ASX и ASY, обменивающиеся маршрутной информацией. ASX знает, как можно достичь сети Net1, которая может и не принадлежать ASX. Аналогично ASY знает, как послать пакет для сети Net2.
net1 .... ASX ASY ...... Net2
Для того чтобы пакеты попали из Net1 в Net2 через ASX и ASY, автономная система ASX должна анонсировать сеть Net1 автономной системе ASY, используя один из внешних протоколов маршрутизации (EGP или BGP), а ASY должна воспринять эту информацию и использовать. Предметом маршрутной политики в этом случае является решение ASX послать маршрутную информацию ASY, а также решение ASY эту информацию принять и использовать. Не существует никаких правил, которые бы вынуждали ASX и ASY к принятию таких решений. Таким образом, протокол маршрутизации определяет формат маршрутной информации, способ ее пересылки и хранения, но решения о ее посылке той или иной AS, а также решение об использовании маршрутной информации, поступающей извне остаются в руках администратора AS.
Так как все существующие протоколы маршрутизации используют при работе с пакетами только адрес места назначения, разделить поток пакетов кроме как по этому параметру не возможно. Если пакеты с одним и тем же адресом места назначения попали в общий маршрутизатор, AS или канал связи, они обречены далее двигаться вместе.
Особый случай составляет топология, при которой две as имеют много возможных маршрутов связи с различными политиками маршрутизации.

Рис. 4.4.11.4.2
Под каналом в данном случае подразумевается любая среда коммуникации - Ethernet, FDDI и т.д.. Может так случиться, что AS2 предпочитает использовать канал 2 только для обмена с AS4. А канал 1 используется для связи с AS3 и в качестве резервного маршрута (back-up) к AS4 в случае выхода из строя канала 2. Для описания маршрутной политики используются атрибуты interas-in и interas-out. Эти атрибуты позволяют описать локальные решения AS, основанные на ее предпочтениях, так как это делается в протоколах BGP-4 или IGRP. Пример такого описания представлен ниже:
aut-num: AS2 - (номер автономной системы, формат:
AS)
as-in: from AS3 10 accept AS3 AS4
(описание воспринимаемой маршрутной информации от других AS-партнеров. Формат описания:
from accept ;
здесь - относится к AS-соседям; - положительное целое число, характеризующее относительную ценность маршрутов, чем меньше cost, тем предпочтительнее маршрут; ключевые слова from (от) и accept (воспринимает) могут отсутствовать.)
Маршрутная политика () может иметь следующие форматы.
Список из одного или нескольких кодов AS, AS-макро или список маршрутов. Список маршрутов записывается в префиксной форме, в качестве разделителей используются запятые и фигурные скобки.
Список ключевых слов. В настоящее время определено ключевое слово ANY, которое говорит о том, что речь может идти о любых соседних AS.
Логическое выражение, включающее в себя объекты типа 1 или 2, объединенные операторами AND, OR, NOT, которые в данном случае, строго говоря, не являются Булевыми. Так например, AS1 OR AS2 означает все маршруты AS1 или AS2. Или AS1 AND HepNet означает маршрут AS1, принадлежащий объединению HepNet. NOT AS3 означает любой маршрут кроме маршрутов AS3.
Приоритеты операторов распределены в следующем порядке: для оператора () слева направо; для NOT - справа на лево; для AND и OR - слева направо.
В отсутствии логических операторов элементы списка (AS, AS-макро, объединения и списки маршрутов) предполагаются объединенными оператором OR.
as-out: to AS3 announce AS1 AS2
(описание сформированной маршрутной информации, рассылаемой другим AS-партнерам). Формат описания:
to announce ;
ключевые слова to {указатель адресата} и announce
{указатель списка доступных AS} могут и отсутствовать.)
относится к AS-соседям.
interas-in: from AS3 193.0.1.1/32 193.0.1.2/32 (pref= 5) accept AS3
interas-in: from AS3 193.0.1.1/32 193.0.1.2/32 (pref=15) accept AS4
interas-in: from AS3 193.0.1.5/32 193.0.1.6/32 (pref=10) accept AS4
...
interas-in: описывает локальные предпочтения для соединений с другими AS. Это описание имеет формат:
from
accept
Ключевые слова from (от) и accept (воспринимает) могут отсутствовать. - автономная система, описанная в as-in. - (идентификатор местного маршрутизатора) содержит IP-адрес пограничного маршрутизатора, политика которого описывается. содержит IP-адрес соседнего маршрутизатора, от которого воспринимается маршрутная информация, описанная в . IP-адреса имеют префиксный формат (описание префиксного формата см. выше в конце раздела 1.4.11.4 [бесклассовая интердоменная маршрутизация - CIDR]).
Предпочтение описывается, как = ; ключевое слово должно обязательно присутствовать. В настоящее время стандарт поддерживает только один вид - "pref". может принимать один из следующих видов:
- положительное число, служащее выражением относительной ценности исследуемых маршрутов. Чем меньше - тем предпочтительнее маршрут. имеет смысл при сравнении атрибутов interas-in и совершенно не применима для сравнения с атрибутами as-in.
Любой маршрут, описанный в interas-in и неупомянутый в AS-IN, предполагается отвергнутым. Система диагностики выдаст при этом сигнал ошибки. Атрибуты interas-out сходны с interas-in, также как as-out и as-in.
Если мы рассмотрим соответствующие атрибуты interas-out для AS3, то увидим следующее:
aut-num: AS3
as-in: from AS2 10 accept AS1 A2
as-out: to AS2 announce AS3 AS4
interas-out: to AS2 193.0.1.2/32 193.0.1.1/32 (metric-out=5) announce AS3
interas-out: to AS2 193.0.1.2/32 193.0.1.1/32 (metric-out=15) announce AS4
interas-out: to AS2 193.0.1.6/32 193.0.1.5/32 (metric-out=10) announce AS4
...
Оператор interas-out: имеет формат:
to aut-num> []
announce
Ключевые слова IN и announce могут и отсутствовать. Остальные фрагменты оператора идентичны описанным выше.
является необязательным параметром и описывается как:
(=), следует заметить, что в данном случае наличие скобок "()" и ключевого слова (тип метрики) обязательно. В настоящее время поддерживается только один тип метрики "metric-out". Параметр может иметь следующий вид:
- метрика для оценки выходных маршрутов, чем ниже ее значение, тем предпочтительнее маршрут. Именно эта оценка маршрута передается соседним маршрутизаторам. IGP - этот тип метрики указывает на то, что она отражает оценку внутренних маршрутов AS. Следует избегать использования и IGP для одних и тех же точек назначения.
Атрибут as-exclude отмечает список транзитных AS, маршруты через которые должны быть исключены из рассмотрения. Формат использования:
exclude to , ключевые слова exclude и to не являются обязательными. - описывает транзитные AS. В качестве можно использовать одно из:
, AS макро, ANY (любой) или community.
Атрибут default указывает на маршрут по умолчанию. Формат атрибута:
,
где указывает на AS-партнера, путь к которому и предлагается в качестве маршрута по умолчанию. Атрибут - положительное целое число, характеризующее уровень приоритета предлагаемого маршрута. AS-macro является удобным средством группировать автономные системы. AS-макро могут использоваться в для атрибутов as-in и as-out. В качестве примера можно привести:
aut-num: AS786
as-in: from AS1755 100 accept AS-EBONE AND NOT AS1104
as-out: to AS1755 announce AS786
.......
Здесь присутствует as-macro с именем AS-EBONE, описание которого может выглядеть как:
as-macro: AS-EBONE (имя AS-макро)
descr: ASes routed by EBONE (AS, маршрутизируемые в EBONE)
as-list: AS2121 AS1104 AS2600 AS2122 (список AS)
as-list: AS1103 AS1755 AS2043
guardian: guardian@ebone.net (администратор EBONE)
......
В результате описание маршрутной политики будет выглядеть как:
aut-num: AS786
as-in: from AS1755 100 accept (AS2121 OR AS1104 OR AS2600 OR AS2122
as-in: from AS1755 100 accept AS1103 OR AS1755 OR AS2043)AND NOT AS1104
......
Community - это группа маршрутов, которые не могут быть представлены одной AS или группой AS. Это может быть полезно при описании доступа к супер-ЭВМ, это может быть группа маршрутов, используемых для специальных целей, возможно объединение в группу для получения сетевой статистики. Такие группы не обмениваются маршрутной информацией. Группа Community может использоваться в качестве объекта маршрутной политики автономных систем. Примерами объектов типа community могут служить HEPNET (объединение сетей для физики высоких энергий), NSFNET (Национальная Научная сеть США), опорная московская оптоволоконная сеть.
Существует еще несколько атрибутов, которые помогают получить вспомогательную информацию. Более детальное описание форматов и алгоритмов решения проблем реализации различных политик маршрутизации читатель может найти в ссылке в начале раздела.
Метод Шеннона-Фано
2.6.4 Метод Шеннона-Фано
Семенов Ю.А. (ГНЦ ИТЭФ)
Данный метод выделяется своей простотой. Берутся исходные сообщения m(i) и их вероятности появления P(m(i)). Этот список делится на две группы с примерно равной интегральной вероятностью. Каждому сообщению из группы 1 присваивается 0 в качестве первой цифры кода. Сообщениям из второй группы ставятся в соответствие коды, начинающиеся с 1. Каждая из этих групп делится на две аналогичным образом и добавляется еще одна цифра кода. Процесс продолжается до тех пор, пока не будут получены группы, содержащие лишь одно сообщение. Каждому сообщению в результате будет присвоен код x c длиной –lg(P(x)). Это справедливо, если возможно деление на подгруппы с совершенно равной суммарной вероятностью. Если же это невозможно, некоторые коды будут иметь длину –lg(P(x))+1. Алгоритм Шеннона-Фано не гарантирует оптимального кодирования. Смотри
http://www.ics.uci.edu/~dan/pubs/DC-Sec3.html.
Методы преобразования и передачи изображения
2.5 Методы преобразования и передачи изображения
Семенов Ю.А. (ГНЦ ИТЭФ)
Передача изображения представляет собой наиболее тяжелую проблему, так как человеческий глаз с информационной точки зрения несравненно совершеннее уха.
В 1902 году Артур Корн (Германия) запатентовал систему фотоэлектрического сканирования изображения, а в 1910 году заработала первая международная факсимильная связь Берлин-Париж-Лондон. До 60-х годов этого века рынок факсимильной аппаратуры был ограничен.
В 1968 году CCITT разработала рекомендации по факсимильному оборудованию, которое было способно передавать страницу за 6 минут при разрешении 3.85 линий на мм. Позднее в 1976 году аналоговая факсимильная техника была улучшена. Это позволило сократить время передачи страницы до 3 минут. В 1980 году разработан стандарт для цифровых факс-машин (группа 3), здесь уже предусматривается сжатие информации, что позволяет сократить время передачи страницы до 1 мин при скорости передачи 4800 бит/с. Следует иметь в виду, что сжатие информации в сочетании с ошибками пересылки может приводить к неузнаваемости изображения локальному или полному. По этой причине число линий сканирования, которые используются при обработке изображения, с целью сжатия может варьироваться (1-4) и определяется в результате диалога между отправителем и получателем, а передача каждой скан-линии завершается довольно длинным кодом, предназначенным для надежного распознавания завершения строки сканирования, а также коррекции ошибок. Факсимильное оборудование группы 3 может и не обеспечивать сжатия передаваемых (принимаемых) данных. В 1984 году разработаны требования к факс-аппаратам группы 4. Система базируется на двухмерной системе кодирования изображения (MMR - Modified Modified Reed).
Факсимильное оборудование поделено на 4 группы. Первая группа практически совпадает с традиционным фототелеграфным оборудованием (6 минут на страницу при разрешении 3.85 линий на миллиметр). Динамической вариации кодовой таблицы не предусмотрено. При этом для кодирования очередной линии сканирования используются результаты, полученные для предшествующей линии. Следует учитывать, что зона сканирования факс-машины больше размера изображения и всегда имеются пустые строки и поля, что предоставляет дополнительные возможности для сжатия передаваемой информации. Существует три режима кодирования: вертикальный, горизонтальный и проходной. Последний режим реализуется, когда позиция в эталонной строке a2 находится слева от b1 (см. рис. 2.5.1; вериткальному и горизонтальному режиму соответствует нижняя часть рисунка). При “вертикальном” режиме кодирования (a2 справа от b1 и |b1a1|) позиция b1 кодируется относительно позиции a1. Относительное положение b1a1 может принимать одно из семи значений V(0), VR(1), VR(2), VR(3), VL(1), vL(2) и VL(3) (см. табл. 2.5.1). Индексы r и l указывают на то, что b1 находится справа или слева по отношению к a1, а число в скобках обозначает расстояние b1a1. Если используется “горизонтальный” режим кодирования (a2 справа от b1 и |b1a1|>3), длины b0b1 и b1b2 отображаются с помощью кодовой комбинации H+M(b0b1)+M(b1b2). H представляет собой код 001, взятый из двумерной кодовой таблицы. M(b0b1) и M(b1b2) являются кодовыми

Рис. 2.5.1. Режимы кодирования: проходной; вертикальный; горизонтальный
Факс-оборудование группы 4 может поддерживать так называемый расширенный режим, когда часть рабочего поля кодируется без использования алгоритмов уплотнения информации (как правило, это участки, где попытка сжать либо ничего не дает, либо даже приводит к увеличению объема передаваемых данных). Оборудование этой группа использует на канальном уровне процедуры HDLC LAPB. Рекомендуемой полосой пропускания канала, к которому подключается такое оборудование, является 64 Кбит/с.
Таблица 2.5.1. Кодирование элементов изображения
Режим кодирования
Элементы, подлежащие кодированию
Обозначение
Код
Проход a1a2 p 0001 Горизонтальный b0b1,b1b2 h 001+m(b0b1)+m(b1b2) Вертикальный b1 под a1 b1a1=0
b1 справа от a1 b1a1=1
b1a1=2
b1a1=3
b1 слева от a1 b1a1=1
b1a1=2
b1a1=3 v(0)
vr(1)
vr(2)
vr(3)
vl(1)
vl(2)
vl(3). 1
011
000011
0000011
010
000010
0000010
0000001ххх Перед началом передачи терминалы должны обменяться своими идентификаторами (TID - terminal identification). В последнее время появились факс-аппараты, которые печатают изображение на обычную бумагу с разрешением 300-400 точек на дюйм. Такая схема удобна, но имеет некоторые недостатки. Такие аппараты дороги, печать может начаться не ранее, чем будет передана вся страница; передающий аппарат может иметь более низкое разрешение, нужно уметь адаптироваться к любому разрешению, что приводит к тому, что скорость печати изображения при низком разрешении остается столь же низкой, как и при высокой.
В 1970 году в Бритиш Телеком были разработаны основные принципы еще одного вида передачи графической информации - телетекста, первые опыты по его внедрению относятся к 1979 году. Стандарт на мозаичное представление символов был принят CEPT в 1983 году. Каждому символу ставится в соответствие код длиной в 7-8 бит. На экране такой символ отображается с помощью специального знакового генератора, использующего таблицу.
Полному экрану видео текста, содержащему 24 строки по 40 символов, соответствует 960 байт, для передачи которых по коммутируемой телефонной сети требуется 6,4 секунды. D-канал ISDN может пропустить эту информацию за 1 сек, а B-канал быстрее за 0,1 сек. Телетекст позволяет более эффективно использовать каналы связи и не налагает чрезмерных требований на устройства отображения.
Известно, что для корректной передачи цвета требуется 16 миллионов оттенков (8 бит на каждую из трех цветовых компонент). Таким образом, для описания картинки на экране, содержащей 575 линий по 720 пикселей, требуется 1,240 Мбайта. Для передачи такой информации по B-каналу ISDN, если не используется сжатие, потребуется около 2,5 минут. Эта цифра помогает понять актуальность проблемы сжатия графической информации. При передаче чисто текстовой информации электронная почта имеет по этой причине абсолютное преимущество перед факсом. В перспективе можно ожидать внедрения сжатия информации при передаче почтовых сообщений с последующей дешифровкой данных принимающей стороной. Первым шагом на этом пути является внедрение системы MIME. Такое усовершенствование электронной почты сделает ее еще более грозным конкурентом факс-машин. Ведь передача графических образов уже не является монополией факсимильных систем, а возможность шифрования почтовых сообщений (например, в PGP) делает электронную почту более противостоящей перехвату. Таким образом, чтобы выдержать конкуренцию со стороны электронной почты разработчикам факс-систем нужно упорно работать.
Стандарты для представления и передачи изображения разрабатывает Joint Photographic Expert Group (JPEG). Для сжатия графической информации в настоящее время используется дискретное косинусное двухмерное преобразование (DCT - Discrete Cosine Transform), которое дает субъективно наилучший результат и описывается уравнением:

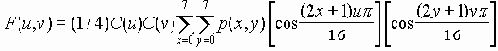 [2.5.1]
[2.5.1]где v - горизонтальная координата графического блока, u - вертикальная, x - вертикальная координата внутри блока, а y - горизонтальная координата внутри блока, C(u), C(v) = 1/

для u,v = 0 и С(u), С(v) = 1 в противном случае. Два члена в квадратных скобках являются ядрами преобразования, показанными ниже на рис. 2.5.2, а p(x,y) представляет собой пиксельные данные блока реального рисунка. Начало координат в обоих случаях в верхнем левом углу. Процесс кодирования сводится к разбиению изображения на блоки 8*8 пикселей и выполнению процедуры двухмерного DCT для каждого из этих блоков. Полученные коэффициенты преобразования дискретизируются. 64 числа, характеризующие уровень сигнала, превращаются в 64 коэффициента преобразования (амплитуды пространственных частот), которые хорошо поддаются процедуре сжатия. Дискретизатор округляет коэффициенты, эта процедура вносит некоторые ошибки, но обратное преобразование на принимающей стороне за счет усреднения частично устраняет вносимые искажения. На практике дискретизатор реализует несколько более сложный алгоритм.
Интуитивно метод DCT базируется на выявлении того, насколько вышестоящий блок отличается от нижестоящего. Для реального представления (сжатия) коэффициентов преобразования здесь также используются коды Хафмана.

Рис. 2.5.2. Графическое представление двухмерного преобразования по формуле [2.5.1]
DCT обеспечивает сжатие на уровне 0.5-1.0 бит/пиксель при хорошем качестве изображения. Сжатие требует времени, а максимально приемлемым временем задержки при пересылке изображения является 5 секунд. На рис. 2.5.3 приведена качественная оценка четкости и соответствия оригиналу изображения в зависимости от величины сжатия (DCT). Если использовать скорость обмена 64 кбит/с, то степени сжатия 0,01 бита на пиксель будет соответствовать время передачи изображения 0,04 секунды, а сжатию 10 - время передачи 40сек.

Рис. 2.5.3. Качество DCT-изображения для различных значений сжатия информации (картинка имеет разрешение 512*512 пикселей; заполненные квадратики соответствуют цветному изображению, а незаполненные - черно-белому)
Отображение графического образа может выполняться последовательно (примерно так, как мы читаем текст: слева-направо и сверху-вниз) или с использованием прогрессивного кодирования (сначала передается вся картинка с низким разрешением, затем последовательно четкость изображения доводится до максимальной). Последний метод весьма удобен для систем WWW, где просмотрев изображение низкого разрешения, можно отменить передачу данных улучшающих четкость и тем самым сэкономить время. Хорошо распознаваемое изображение получается при сжатии порядка 0,1 бита на пиксель.
Проблема сжатия и передачи движущегося изображения еще сложнее. Алгоритм кодирования такого изображения описан в рекомендациях CCITT H.261 и предполагает, что скорость передачи при этом лежит в интервале 40кбит/с - 2Мбит/с. Следует иметь в виду, что видео телефония и видеоконференции требуют синхронной передачи звука и изображения (стандарт H.221, например 46,4 Кбит/с для видео и 16 Кбит/с для звука). Нормальный формат телевидения имеет 625 и 525 строк развертки и частоту кадров 25-30 в секунду. Цветное телевидение использует сигналы R (red), G (green) и B (blue), причем яркость луча (y) определяется соотношением: Y = 0.30R + 0.59G + 0.11B (при отображении белого цвета). Информация о цветах определяется формулами: СB = B - Y и CR = R - Y. Зная величины y, CB и СR, можно восстановить значения R, G и B. При сжатии цветного изображения учитывается тот факт, что человеческий глаз извлекает большую часть информации из контуров предметов, а не из цветных деталей. Например в рекомендации CCIR 601 предлагается использовать полосу 13.5 Мгц для кодирования Y и только по 6.75 Мгц для СB и CR. Такая схема требует 216 Мбит/с, что в 3375 раза превышает возможности стандартного 64кбит/с B-канала ISDN. Приемлемыми решениями могут быть:
снижение числа строк до 288 (формат 625 строк) для отображения яркости;
использование максимально возможного сжатия графических данных;
повышение пропускной способности канала. Для разрешение по горизонтали вполне достаточно 3 Мгц. Рекомендация 601 требует 720 пикселей для яркости и 360 для каждой из составляющих цветов. В настоящее время используется стандарт CIF (Common Intermediate Format). Для некоторых приложений рекомендовано вдвое более низкое разрешение по каждой из осей (quarter CIF). PCM-кодирование CIF с 8 битами на пиксель требует 352х288х(1+1/4+1/4)х29.97х8 = 36.5 Мбит/с.
Проблема сжатия информации была, есть и всегда будет актуальной. При известных современных методах, чем больше эффективность сжатия - больше задержка (наилучший результат можно получить, используя сжатие всего фильма, чем кадра или тем более строки). В каждом конкретном случае выбирается то или иное компромиссное решение. При работе в реальном масштабе времени, где в процессе обмена участвует человек, задержки более секунды вызывают раздражение, и приходится ограничиваться сравнительно скромными коэффициентами сжатия.
При пересылке движущегося изображения производится сравнение текущего кадра с предшествующим. Если кадры идентичны, никакого информационного обмена не происходит. Если кадры отличаются лишь смещением какого-то объекта, выявляются границы этого объекта, направление и величина вектора его перемещения. Так как использование индивидуальных векторов перемещения для каждого пикселя слишком расточительно, используется общий вектор для блока пикселей 16*16 по яркости и для соответствующего блока 8*8 по цвету. Точность задания вектора перемещения обычно лежит в пределах 1/2 пикселя (стандарт MPEG-2). Только эта информация и передается по каналу связи. Выявление движущихся объектов осуществляется путем вычитания изображения двух последовательных кадров. Если бы передавалась всегда только разница кадров, происходило бы накопление ошибок. Кроме того, как кодер, так и декодер содержат прямой и обратный DCT-преобразователь. Если комбинация прямого и обратного DCT-преобразования не приводит к получению исходного объекта, то такого рода эффекты могут заметно усилиться. Для исключения этого время от времени производится передача непосредственно видеосигнала. Практически преобразователь изображения представляет чудо современной технологии, которое даст работу еще не одному поколению математиков и инженеров.
Нисколько не проще система передачи и мультиплексирования потока видео данных, который содержит помимо обычной информации описания формы движущихся объектов, векторы перемещения, коэффициенты дискретизации и многое другое. Схема передачи графической информации имеет 4-х уровневую, иерархическую структуру. Передача каждого кадра изображения начинается с 20-битного кода PSC (Picture Start Code, эта сигнатура позволяет выделить начало кадра изображения в общем потоке), далее следует 5-битовый код TR (Temporal Reference, временная метка, которая позволяет поместить соответствующую часть изображения в правильную точку экрана). Изображение пересылается частями, имеется 4 уровня: кадр, группа блоков GoB (Group of Blocks), макроблоки (MB) и просто блоки.
Ядро всей структуры составляет процедура передачи кадра (внутренний слой, существуют еще слои GoB, MB и блока, см. рис. 2.5.4, 2.5.5, 2.5.6)
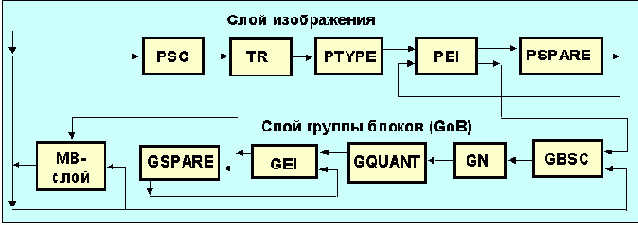
Рис. 2.5.4. Схема передачи кадра изображения
Поле Ptype содержит 6 бит, которые характеризуют формат изображения (используется ли формат CIF или QCIF). Однобитное поле PEI указывает на то, следует ли далее 8-битное поле PSpare (предназначено на будущее). Если PEI=0, начинается цикл передачи GoB. Группа блоков составляет одну двенадцатую картинки CIF или одну треть QCIF. GoB описывает Y (яркость), 176 пикселей для каждой из 48 строк и соответствующие 88*24 элементов для CB и CR.
GBSC - (Group of Blocks Start Code) представляет собой 16-разрядное слово, за которым следует 4 бита номера GoB (GN - GoB number). GN указывает, какой части изображения соответствует данный GoB. Поле gquant имеет 5 бит и указывает на номер преобразователя (одного из 31 дискретизаторов), который используется данным GoB. Смысл GEI идентичен PEI. GEI и GSpare позволяют сформировать структуру данных, идентичную той, что используется на уровне кадра.
Формат пересылки mb сложнее (см. [17]). Каждый GoB делится на 33 макроблока (MB), каждый из которых соответствует 16 строкам по 16 пикселей Y (четыре блока 8*8) и CB и CR. Каждый макроблок начинается с его адреса MBA (MacroBlock Address), имеющего переменную длину и определяющего положение макроблока в GoB.

Рис. 2.5.5. Блок-схема кодирования и передачи изображения
Макроблоки не передаются, если данная часть изображения не изменилась. За MBA следует код переменной длины Mtype, характеризующий формат макроблока (применен ли метод подвижного вектора MVD и т.д.) и последующую информацию. CBP (Coded Block Pattern) представляет собой кодовое слово переменной длины, которое несет в себе информацию о том, какой из шести блоков преобразования (8*8) содержит коэффициенты (слой блоков). CBP нужно не для всех типов макроблоков. Каждый блок завершается флагом EOB (End of Block).

Рис. 2.5.6. Размещение блоков в макроблоках
Сама природа алгоритма кодирования и передачи графических данных такова, что число бит передаваемых в единицу времени зависит от характера изображения. Чем динамичнее изменяется картинка, тем больше поток данных. Для выравнивания потока данных широко используется буферизация. Буферизация в свою очередь порождает дополнительные задержки, которые в случае видео-конференций или видео-телефонии не должны превышать нескольких сотен миллисекунд.
Так как при передаче изображения широко используются коды переменной длины, она крайне уязвима для любых искажений. В случае ошибки будет испорчена вся информация вплоть до следующего стартового кода GoB. Из-за рекурсивности алгоритма формирования картинки, искажения будут оставаться на экране довольно долго. Использование векторов перемещения может привести к дрейфу искажений по экрану и расширению их области. Для того чтобы уменьшить последствия искажений, в передаваемый информационный поток включаются коды коррекции ошибок BCH (511,493; Forward Error Correction Code), которые позволяют исправить любые две ошибки или кластер, содержащий до 6 ошибок в блоке из 511 бит (см. рис. 2.5.7). Алгоритм работает в широком диапазоне скоростей передачи информации. Для реализации коррекции ошибок в поток двоичных данных включается 8 пакетов, каждый из которых включает в себя 1 кадровый бит, 1 бит индикатор заполнения, 492 бита кодированных данных и 18 бит четности. Поле Fi (индикатор заполнения) может равняться нулю, тогда последующие 492 бита не являются графической информацией и могут игнорироваться. Алгоритм предназначен для работы в динамическом диапазоне частот 40:1.
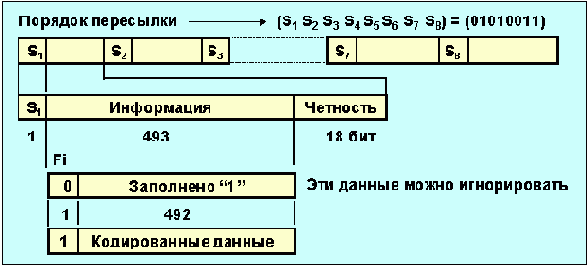
Рис. 2.5.7 Схема передачи данных с коррекцией ошибок
Во время переговоров или в ходе видеоконференции может возникнуть необходимость отобразить текст, выделить на экране какой-то объект, послать факс и т.д. Для решения таких задач можно использовать D-канал, но это не оптимально, так как он имеет свои специфические функции. Поэтому более привлекательным представляется создание специального протокола, работающего в рамках B-канала (H.221). Для этих целей используется младший бит каждого из октетов, что позволяет создать канал с пропускной способностью 8 Кбит/с. этот сервисный канал использует кадры по 80 бит. Первые 8 бит служат для целей синхронизации (FAS - Frame Alignment Signal) и выполняют следующие функции:
выделение начала кадра (исключение имитации этого в информационном потоке);
выделение начала блока кадров (опционно до 16 кадров);
выполнение функций счетчика в многокадровых блоках (по модулю 16), может использоваться в многоточечных соединениях;
нумерация соединений;
CRC-контроль (опционно);
”A-бит” для определения кадр/мультикадр/синхронизация при пересылке в противоположном направлении (A=0 - передача, см. также структуру кадров isdn );
При работе с каналами на 384, 1536 и 1920 Кбит/с сервисный канал использует тайм-слот 1. Следующие 8 бит имеют название BAS (Bit Allocation Signal) и выполняют следующие функции:
код, характеризующий возможности канала (узко/широко полосная передача звука, различные видео параметры, тип шифрования и т.д.);
коды команд, определяющие значения передаваемых кадров;
ESC-последовательности.
Очевидно, что BAS-коды (H.242) должны быть надежно защищены от ошибок. Для этой цели они пересылаются с использованием кодов, допускающих коррекцию ошибок. При работе оба приемника непрерывно ищут разделительный код кадров. Когда он обнаружен, бит А для выходного канала делается равным нулю. Только после получения А=0 терминал может быть уверен в том, что удаленный терминал правильно воспринял код BAS. Работа с кодами BAS описана в документе H.242. При установлении режима обмена терминалы обмениваются командами BAS. Команда действительна для последующих двух кадров, следовательно, при частоте кадров 100 Гц, изменения режима могут производиться каждые 20 мс.
Многоточечный вызов может рассматриваться как несколько связей между терминалами и бриджом MCU (Multipoint Control Unit) по схеме точка-точка. Простой MTU передает на каждый из терминалов смешанный аудио-сигнал от остальных терминалов. Каждый терминал осуществляет широковещательную передачу для остальных терминалов, участвующих в обмене. При видео обмене на терминал выводится только одна картинка. Дополнительную информацию по данной тематике можно найти в рекомендациях H.231, H242 и H.243.
Для передачи нормального телевизионного изображения необходимо 364 Кбит/с (4х64 Кбит/c). Интеграция телевидения с сетями передачи данных, появление видеотелефона и широкое внедрение видеоконференций становится велением времени. Требования к каждому из этих видов услуг варьируется значительно в зависимости от приложения. Например, ставшие обычными телевизионные мосты требуют высокого качества передачи изображения и звука. А в некоторых дорогостоящих отраслях науки, где международное сотрудничество стало неизбежным, важным является передача статических изображений (чертежи, схемы, описания алгоритмов, и т.д.) с высоким (иногда более высоким, чем в телевидении) разрешением. Здесь важно передать звук с приемлемым качеством (но заметно хуже, чем на ТВ) и обеспечить синхронное перемещение маркера мыши по экрану в ходе обсуждения переданного документа. Экономия только на авиа билетах (не говоря о командировочных и времени экспертов) способна перекрыть издержки по оплате канала для видеоконференции. В этом режиме приемлемым может считаться один кадр в 1-4 секунды.
Рисунок известного французского художника Клода Серрэ из книги “Черный юмор и люди в белом” (см. начало раздела) может служить иллюстрацией того, к чему может привести использование протокола tcp при передаче изображения в реальном масштабе времени. Предположим, что в процессе передачи изображения носа пакеты были повреждены, тогда спустя некоторое время, определяемое размером окна (TCP), будет проведена повторная их передача. Тем временем переданные ранее пакеты будут использованы для построения изображения, а часть картинки, содержавшаяся в пакетах, посланных вместо поврежденных, будет отображена совсем не там, где это следует. Реально из-за повреждения пакетов возможны в этой версии и более тяжелые искажения изображения. Именно это является причиной использования UDP для передачи видео и аудио информации при видео и аудио конференциях (еще лучшего результата можно достичь, использую протокол RTP). Протокол UDP не требует подтверждения и повторной передачи при ошибке доставки. Поврежденные пакеты вызовут искажения изображения (или звука) лишь локально.
Ситуация меняется в случае посылки изображения или звукового послания по электронной почте. Здесь в случае повторной передачи пакетов в конечном итоге будет сформирован файл, уже не содержащий ошибок. Такое решение приемлемо всякий раз, когда большая задержка появления изображения или звука не играет никакой роли.
Стандарт MPEG
Стандарт MPEG-2 является усовершенствованием MPEG-1 и базируется на схеме шифрования с потерями и передачи без потерь. Кодирование в MPEG-2 идентично используемому в MPEG-1 (I- P- и B-кадры; В-кадры не используются). I-кадр (Intracoded) представляет собой изображение, закодированное согласно стандарту JPEG при полном разрешении по яркости и половинном разрешении по цвету. Такие кадры должны появляться периодически. Эти кадры обеспечивают совместимость с MPEG-1, и исключают влияние накопления ошибок в процессе передачи. P-кадры (Predictive) содержат отличие блоков в последнем кадре изображения (базируются на идее макроблоков). B-кадры (Bidirectional) характеризуют отличие двух последовательных изображений. Здесь применено двойное косинусное преобразование с числом коэффициентов 10*10 (против 8*8 в MPEG-1). MPEG-2 предназначен для широковещательного телевидения (включая прямое спутниковое - DBS) и для записи на CD-ROM и поддерживает четыре разных стандартов разрешения: 352*240 (низкое), 720*480 (базовое), 1440*1152 (высокое-1440) и 1920*1080 (высокое). Низкое разрешение служит для обеспечения совместимости с MPEG-1. Базовое разрешение ориентировано на работу со стандартом NTSC. Последние два стандарта относятся к телевидению высокого разрешения (HDTV). Помимо этого MPEG-2 поддерживает 5 профайлов для различных прикладных областей. Основной профайл ориентирован на общие приложения с базовым разрешением. Простой профайл сходен с основным профайлом, но не работает с B-кадрами, чтобы облегчить процедуры кодирования/декодирования. Остальные профайлы служат для обеспечения масштабируемости и работы с HDTV, они отличаются цветовым разрешением и форматами информационных потоков. Скорость передачи данных для каждой комбинации разрешения и профайла различна и лежит в диапазоне от 3 до 100 Мбит/c. Для обычного ТВ характерна скорость 3-4 Мбит/c. В таблице 2.5.2 представлены размеры кадров в битах для MPEG-1 и MPEG-2.
Таблица 2.5.2. Размеры кадров MPEG-1 и MPEG-2
| Тип кадра | ||||
| i | p | b | Средний | |
| mpeg-1 (1,15 Мбит/с) | 150,000 | 50,000 | 20,000 | 38,000 |
| mpeg-2 (4 Мбит/c) | 400,000 | 200,000 | 80,000 | 130,000 |

Рис. 2.5.8. Мультиплексирование аудио и видео данных в MPEG-1 и MPEG-2 (внизу)
Преобразование аналогового сигнала в цифровую последовательность осуществляется в MPEG-2 с помощью кодеков, создавая первичный поток в 140 Мбит/с, который затем преобразуется для передачи через стандартные каналы 1,5 и 15 Мбит/с (например, для прямого широковещательного, спутникового телевидения). В соответствии со стандартом сжатия данных H.320 можно обеспечить передачу видео + аудио по каналу 56 кбит/с с низким разрешением и частотой 1 кадр/сек. Смотри раздел "Видеоконференции по каналам ISDN и Интернет".
Интерактивное телевидение
В последнее время благодаря широкому внедрению цифрового телевидения и новых стандартов передачи изображения (MPEG-2) открылись возможности для "телевидения по требованию" (интерактивного телевидения) - системы, где клиент может самостоятельно и индивидуально формировать ТВ-программу. Первые опыты такого рода относятся к 1995 году. Такие системы базируются на существующих сетях кабельного телевидения. Но развитие оптоволоконных технологий позволяют ожидать полной интеграции кабельного цифрового телевидения и информационных сетей Интернет. Следует, впрочем, заметить, что оптоволокно в каждом жилище является пока непозволительной роскошью. Общая схема такой системы показана на рис. 2.5.9.

Рис. 2.5.9. Схема реализации интерактивного телевидения
Базовый мультимедийный сервер может обслуживать отдельный район города. В пределах квартала размещается промежуточный центр, где размещается локальный буферный сервер, где записываются фрагменты программ, заказанные локальными клиентами. Только новостийные и некоторые спортивные программы передаются в реальном масштабе времени, все фильмы берутся из локальной фильмотеки или предварительно записываются в накопитель из центрального мультимедиа-сервера. Транспортной средой здесь может стать ATM, SDH или Fibre Channel. Оптическое волокно доходит до квартального сервера или даже до дома клиента. Индивидуальная раздача сигнала на терминалы (телевизоры) может осуществляться через существующие телевизионные кабели. В этом случае по имеющимся каналам может передаваться не только программа телевидения и осуществляться телефонные переговоры, но выполняться полное информационное обслуживание. Сюда может включаться, помимо заказа ТВ-программ, подписка на газеты, заказ билетов на транспорт или в театр, получение прогноза погоды и данных о состоянии дорог, доступ к базам данных, включая библиотеки и фонотеки и многое другое. Особый интерес представляет возможность практически полного вытеснения традиционных газет. Клиент сможет получать только интересующие его статьи из любых газет (и только их и оплачивать). Если какая-то статья его заинтересует и он захочет почитать ее позднее в машине или на даче, он сможет ее распечатать на принтере, подключенном к его телевизору-терминалу. Цены на цветные принтеры в настоящее время спустились ниже 100 долларов, таким образом нужная копия уже сейчас дешевле стоимости газеты. Экономия на бумаге и средствах доставки очевидны, да и необходимость в типографиях отпадет, ведь даже книги можно будет получить непосредственно дома (хотя привлекательность данной услуги и не вполне очевидна - хорошо сброшированная и переплетенная книга будет привлекательным объектом еще долго (прогноз относительно будущих книг сотри в разделе "Заключение"). Массовое внедрение таких технологий будет стимулировать падение цен на соответствующие процессоры и принтеры. Интерактивная схема подключения телевизора-терминала сделает возможным многие новые виды развлечений, а также выполнение многих покупок, не выходя из дома. Традиционной почте подписала отсроченный приговор почта электронная, но появление интерактивных широкополосных средств завершит многовековую историю почты (да и телеграфа). Ей будет оставлена доставка товаров, билетов и документов. Побочным продуктом прогресса в данной области станет общедоступный видеотелефон.
В жилье клиента будет входить оптоволоконный кабель, завершающийся интерфейсной коробкой с разъемами для подключения телефона, телевизора и ЭВМ. Даже современные ограниченные скорости передачи позволяют решить стоящие проблемы. Во-первых люди не смотрят телевизор круглые сутки, это позволяет ночью или в рабочее время, когда клиент на службе, произвести передачу нужных фрагментов ТВ-программы на локальный сервер. Во-вторых популярность фильмов и программ не однородна, что также снижает требование на широкополосность. Известно, что наиболее популярный фильм запрашивается примерно в К раз чаще, чем фильм, занимающий к-ое место в списке популярности (эмпирический закон Ципфа (Zipf), выведенный из статистики контор по прокату видеокассет). Это означает, что из предлагаемого списка будут выбраны не все фильмы, а наиболее популярные фрагменты программ можно передавать по схеме MBONE, минимизируя загрузку каналов (смотри также описание протокола PIM). Способствовать решению данной проблемы будет и появление CD с емкостью 4 Гбайта. Но проблем здесь остается немало, так трудно себе представить, что все клиенты захотят смотреть один и тот же фильм в одно время. Решение подобной задачи потребует очень большого объема буферной памяти и ощутимо поднимет требования к широкополосности канала. "Синхронизовать" клиентов можно будет дифференциацией оплаты для разных временных интервалов, и группированием клиентов, заказавших близкие времена начала демонстрации фильмов, путем предварительного оповещения. Но несмотря на все эти ухищрения, локальные серверы должны будут иметь сложную иерархическую систему буферной памяти, базирующейся на разных принципах работы (CD, магнитная лента, дисковая память и даже RAM).
Практическая реализация фантастической схемы, предложенной в предыдущем абзаце, уже осуществляется в США и Канаде. Здесь есть немало проблем, например, нужен дешевый широкополосный кабельный модем (смотри раздел "Модемы", там же приведена схема подключения телевизора-терминала через кабельный модем). Предстоит написать огромное число различных сервисных программ, но все базовые технологии уже существуют.
Методы преобразования и передачи звуковых сигналов
2.4 Методы преобразования и передачи звуковых сигналов
Семенов Ю.А. (ГНЦ ИТЭФ)

На физическом уровне в ISDN используется кодово-импульсная модуляция с частотой стробирования 8кГц (что превосходит ограничение Найквиста = 2*3.3кГц, где 3.3кГц - полоса пропускания канала для традиционной телефонной сети). Эмпирически установлено, что для удовлетворительного воспроизведения речи, достаточно 4096 уровней квантования сигнала (12 разрядов АЦП). Такое разрешение диктуется большим динамическим диапазоном сигналов. По этой причине возникает возможность преобразования 12-битных кодов в 8-битные, что формирует информационный поток в 64 Кбит/c. Для этого используется логарифмическое преобразование. Природа позаботилась о человеке, снабдив его логарифмической чувствительностью слуха, в противном случае у нас в мозгу перегорали бы предохранители при близком выстреле или грозовом разряде. Логарифмическое преобразование наталкивается на определенные трудности при низких значениях входного сигнала, ведь логарифм для значений меньше 1 имеет отрицательную величину. Функция же преобразования должна пройти через нуль. В США две логарифмические кривые смещаются в направлении оси ординат (вертикальная ось), в результате получается функция вида:
| y ~ log(1 +mx) | (так называемая m-зависимость [m-law]) | ||
| В Европе используется функция преобразования вида: | |||
| y ~ ax | в области значений x вблизи нуля и | ||
| y ~ 1 + log(Ax) | при “больших” значениях x (A-зависимость [a-law], см. рис. 2.4.1) |
Для дальнейшего упрощения процесса преобразования реальные кривые апроксимируются последовательностью отрезков прямых, наклоны которых каждый раз меняется вдвое. На практике функция табулируется (рекомендация G.711) и отличия m- и A-функций пренебрежимо малы. Но следует учитывать, что при реализации практической связи между Европой и Америкой, например телефонной, необходим m/A-конвертор.
Для кодирования используется симметричный код, у которого первый бит характеризует полярность сигнала.
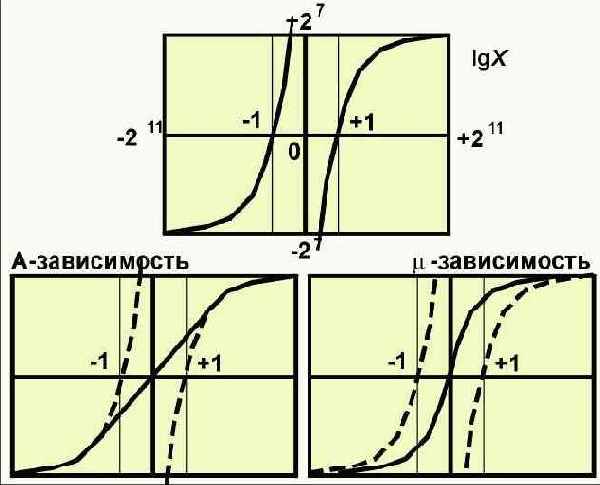
Рис. 2.4.1. Иллюстрация функций преобразования сигналов
Дальнейшим усовершенствованием схемы pcm является адаптивный дифференциальный метод кодово-импульсной модуляции (Рис. 2.4.2). Здесь преобразуется в код не уровень сигнала в момент времени ti, а разница уровней в моменты ti и ti-1. Так как обычно сигнал меняется плавно, что типично для человеческой речи, можно заметно сократить необходимое число разрядов АЦП. Принципиальное отличие между PCM и ADPCM (1984 год) заключается в использовании адаптивного АЦП и дифференциального кодирования, соответственно. Адаптивный АЦП отличается от стандартного PCM-преобразователя тем, что в любой момент времени уровни квантования расположены однородно (а не логарифмически), причем шаг квантования меняется в зависимости от уровня сигнала. Применение адаптивного метода базируется на том, что в человеческой речи последовательные уровни сигнала не являются независимыми. Поэтому, преобразуя и передавая лишь разницу между предсказанием и реальным значением, можно заметно снизить загрузку линии, а также требования к широкополосности канала. Следует иметь в виду, что метод не лишен серьезных недостатков: уровень шумов, связанный с квантованием сигнала, выше; при резких изменениях уровня сигнала, превышающих диапазон АЦП, возможны серьезные искажения.
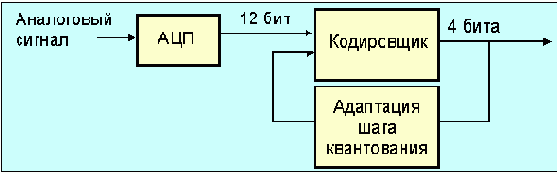
Рис. 2.4.2. Адаптивный преобразователь голоса в код
Расширение диапазона преобразования достигается умножением шага квантования на величину несколько больше (или меньше) единицы.
При дифференциальном преобразовании на вход кодировщика подается не сам сигнал, а разница между текущим значением сигнала и предыдущим (рис. 2.4.3).

Рис. 2.4.3. ADPCM-преобразователь голоса в код для 32кбит/с
Блок прогнозирования является адаптивным фильтром, который использует предшествующий код для оценки последующего стробирования. На вход кодировщика поступает сигнал, пропорциональный разнице между входным сигналом и предсказанием. Чем точнее предсказание, тем меньше бит нужно, чтобы с нужной точностью закодировать эту разницу. Характер человеческой речи позволяет заметно снизить требования к каналу при использовании адаптивного дифференциального преобразователя.
Для компактных музыкальных дисков (cd) характерна полоса 50Гц - 20 кГц, обычная же речь соответствует полосе 50 Гц - 7 кГц. Только звуки типа Ф или С имеют заметные составляющие в высокочастотной части звукового спектра. Для высококачественной передачи речи используется субдиапазонный ADPCM-преобразователь (Adaptive Differential Pulse Code Modulation). В нем звук сначала стробируется с частотой 16 кГц, производится преобразование в цифровой код с разрешением не менее 14 бит, а затем подается на квадратурный зеркальный фильтр (qmf), который разделяет сигнал на два субдиапазона (50Гц-4кГц и 4кГц-7кГц). Диапазоны этих фильтров перекрываются в области 4кГц. Нижнему диапазону ставится в соответствие 6 бит (48кбит/с), а верхнему 2 бита (16 Кбит/с). Выходы этих фильтров мультиплексируются, формируя 64 кбит/с -поток.
На CD используется 16-битное кодирование с частотой стробирования 44,1 кГц, что создает информационный поток 705 Кбит/c. Для стерео сигнала этот поток может удвоиться. Практически это не так - сигналы в стереоканалах сильно коррелированны, и можно кодировать и передавать лишь их разницу, на практике высокочастотные сигналы каналов суммируются, для различия каналов передается код их относительной интенсивности. Исследования показывают, что для акустического восприятия тонкие спектральные детали важны лишь в окрестности 2 кГц. Для передачи звуковой информации с учетом этих факторов был разработан стандарт MUSICAM (Masking pattern Universal Sub-band Integrated Coding and Multiplexing), который согласуется с ISO MPEG (Moving Picture Expert Group; стандарт ISO 11172). musicam развивает идеологию деления звукового диапазона на субдиапазоны, здесь 20кГц делится на 32 равных интервалов. Логарифмическая чувствительность человеческого уха и эффект маскирования позволяет уменьшить число разрядов кодирования. Эффект маскирования связан с тем, что в присутствии больших звуковых амплитуд человеческое ухо нечувствительно к малым амплитудам близких частот. Причем чем ближе частота к частоте маскирующего сигнала, тем сильнее этот эффект (см. рис. 2.4.4). Сплошной линией на рисунке показана нормальная зависимость порога чувствительности уха, а пунктиром - зависимость порога чувствительности в присутствии 500-герцного тона с амплитудой в 110 дБ.

Рис. 2.4.4. Изменение порога чувствительности человеческого уха под влиянием эффекта маскирования.
При разбиении на субдиапазоны можно оценить эффект маскирования и передавать только ту часть информации, которая этому эффекту не подвержена. При этом уровень ошибок квантования следует держать лишь ниже порога маскирования, что также снижает информационный поток. Для стробирования высококачественных звуковых сигналов используются частоты 32, 44,1 или 48 кГц. Стандартом предусмотрено три уровня кодирования звука, отличающиеся по сложности и качеству. На первом уровне производится разбивка на 32 диапазона, определение диапазонных коэффициентов и формирование кадров, несущих по 384 результатов стробирования. Уровень 2 формирует кадры с 1152 результатами стробирования и дополнительными данными. Уровень 3 допускает динамическое разбиение на субдиапазоны и уплотнение данных с использованием кодов Хафмана. Любой декодер способен работать на своем и более низком уровне.
Для улучшения качества передачи низких частот в дополнение к суб-диапазонным фильтрам, используется быстрое Фурье-преобразование (FFT). Результирующая частота бит при передаче звуковых данных оказывается не постоянной. Практическое измерение показывает, что частота редко превышает 110кбит/с, применение 128кбит/с делает качество воспроизведения неотличимым от CD. Ограничение скорости на уровне 64 Кбит/с вносит лишь незначительные искажения.
Ниже в таблицах представлены данные по скоростям передачи аудиоданных по традиционным цифровым и отповолоконным каналам (см. также раздел 3.5.6).
Таблица 2.4.1
Скорости передачи данных по цифровым каналам
Линия |
Быстродействие Мбит/с |
Число аудио каналов |
| DS-0 | 0,064 | 1 |
| T-1 | 1,544 | 24 |
| T-1C | 3,152 | 48 |
| T-2 | 6,312 | 96 |
| T-3 | 44,736 | 672 |
Линия OC-x |
Быстродействие Мбит/с |
Число аудио каналов |
STM-x |
| 1 | 51,84 | 672 | - |
| 3 | 155,52 | 2016 | 1 |
| 9 | 466,56 | 6048 | 3 |
| 12 | 622.08 | 8064 | 4 |
| 24 | 1244,16 | 16128 | 8 |
| 48 | 2488,32 | 32256 | 16 |
| 96 | 4976,64 | 64512 | 32 |
| 192 | 9953,28 | 129024 | 64 |
Методы сжатия информации
2.6 Методы сжатия информации
Семенов Ю.А. (ГНЦ ИТЭФ)

Полагаю, что все читатели знакомы с архиваторами файлов, вероятно, многие из вас неоднократно ими пользовались. Целью архивации файлов является экономия места на жестком или гибком магнитном диске. Кому не приходилось время от времени задумываться над тем, войдет ли данный файл на дискету? Существует большое число программ-архиваторов, имеются и специальные системные программные средства типа Stacker или Doublespace и т.д., решающие эту проблему.
Первые теоретические разработки в области сжатия информации относятся к концу 40-х годов. В конце семидесятых появились работы Шеннона, Фано и Хафмана. К этому времени относится и создание алгоритма FGK (Faller, Gallager, Knuth), где используется идея "сродства", а получатель и отправитель динамически меняют дерево кодов (смотри, например, http://www.ics.uci.edu/~dan/plus/DC-Sec4.html).
Пропускная способность каналов связи более дорогостоящий ресурс, чем дисковое пространство, по этой причине сжатие данных до или во время их передачи еще более актуально. Здесь целью сжатия информации является экономия пропускной способности и в конечном итоге ее увеличение. Все известные алгоритмы сжатия сводятся к шифрованию входной информации, а принимающая сторона выполняет дешифровку принятых данных.
Существуют методы, которые предполагают некоторые потери исходных данных, другие алгоритмы позволяют преобразовать информацию без потерь. Сжатие с потерями используется при передаче звуковой или графической информации, при этом учитывается несовершенство органов слуха и зрения, которые не замечают некоторого ухудшения качества, связанного с этими потерями. Более детально эти методы рассмотрены в разделе "Преобразование, кодировка и передача информации".
Сжатие информации без потерь осуществляется статистическим кодированием или на основе предварительно созданного словаря. Статистические алгоритмы (напр., схема кодирования Хафмана) присваивают каждому входному символу определенный код. При этом наиболее часто используемому символу присваивается наиболее короткий код, а наиболее редкому - более длинный. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти.
Альтернативой статистическому алгоритму является схема сжатия, основанная на динамически изменяемом словаре (напр., алгоритмы Лембеля-Зива). Данный метод предполагает замену потока символов кодами, записанными в памяти в виде словаря (таблица перекодировки). Соотношение между символами и кодами меняется вместе с изменением данных. Таблицы кодирования периодически меняются, что делает метод более гибким. Размер небольших словарей лежит в пределах 2-32 килобайт, но более высоких коэффициентов сжатия можно достичь при заметно больших словарях до 400 килобайт.
Реализация алгоритма возможна в двух режимах: непрерывном и пакетном. Первый использует для создания и поддержки словаря непрерывный поток символов. При этом возможен многопротокольный режим (например, TCP/IP и DECnet). Словари сжатия и декомпрессии должны изменяться синхронно, а канал должен быть достаточно надежен (напр., X.25 или PPP), что гарантирует отсутствие искажения словаря при повреждении или потере пакета. При искажении одного из словарей оба ликвидируются и должны быть созданы вновь.
Пакетный режим сжатия также использует поток символов для создания и поддержания словаря, но поток здесь ограничен одним пакетом и по этой причине синхронизация словарей ограничена границами кадра. Для пакетного режима достаточно иметь словарь объемом, порядка 4 Кбайт. Непрерывный режим обеспечивает лучшие коэффициенты сжатия, но задержка получения информации (сумма времен сжатия и декомпрессии) при этом больше, чем в пакетном режиме.
При передаче пакетов иногда применяется сжатие заголовков, например, алгоритм Ван Якобсона (RFC-1144). Этот алгоритм используется при скоростях передачи менее 64 Kбит/с. При этом достижимо повышение пропускной способности на 50% для скорости передачи 4800 бит/с. Сжатие заголовков зависит от типа протокола. При передаче больших пакетов на сверх высоких скоростях по региональным сетям используются специальные канальные алгоритмы, независящие от рабочих протоколов. Канальные методы сжатия информации не могут использоваться для сетей, базирующихся на пакетной технологии, SMDS (Switched Multi-megabit Data Service), ATM, X.25 и Frame Relay. Канальные методы сжатия дают хорошие результаты при соединении по схеме точка-точка, а при использовании маршрутизаторов возникают проблемы - ведь нужно выполнять процедуры сжатия/декомпрессии в каждом маршрутизаторе, что заметно увеличивает суммарное время доставки информации. Возникает и проблема совместимости маршрутизаторов, которая может быть устранена процедурой идентификации при у становлении виртуального канала.
Иногда для сжатия информации используют аппаратные средства. Такие устройства должны располагаться как со стороны передатчика, так и со стороны приемника. Как правило, они дают хорошие коэффициенты сжатия и приемлемые задержки, но они применимы лишь при соединениях точка-точка. Такие устройства могут быть внешними или встроенными, появились и специальные интегральные схемы, решающие задачи сжатия/декомпрессии. На практике задача может решаться как аппаратно, так и программно, возможны и комбинированные решения.
Если при работе с пакетами заголовки оставлять неизмененными, а сжимать только информационные поля, ограничение на использование стандартных маршрутизаторов может быть снято. Пакеты будут доставляться конечному адресату, и только там будет выполняться процедура декомпрессии. Такая схема сжатия данных приемлема для сетей X.25, SMDS, Frame Relay и ATM. Маршрутизаторы корпорации CISCO поддерживают практически все режимы сжатия/декомпрессии информации, перечисленные выше.
Сжатие информации является актуальной задачей, как при ее хранении, так и при пересылке. Сначала рассмотрим вариант алгоритма Зива-Лемпеля.
Многоцелевое расширение почты Интернет (MIME)
4.4.14.4 Многоцелевое расширение почты Интернет (MIME)
Семенов Ю.А. (ГНЦ ИТЭФ)

Формат тела Интернет сообщений
Стандарт STD 11, RFC 822 определяет протокол представления сообщений, структуру их заголовков. При этом предполагается, что текст сообщения построен исключительно из кодов US-ASCII. Набор документов MIME (Multipurpose Internet Mail Extensions; RFC-2045-49) задает формат сообщений, который предоставляет следующие возможности.
Передача текстовых сообщений с символьным набором, отличным от US-ASCII.
Передача сообщений нетекстового формата (например, звукового письма).
Использование комбинированных сообщений, содержащих разнородные части.
Размещение в заголовке информации в символьном наборе, отличном от US-ASCII.
Документ RFC-2045 характеризует различные заголовки, которые служат для описания структуры MIME-сообщений. RFC 2046 определяет общую структуру MIME и исходный набор типов среды. RFC 2047 описывает расширения документа RFC 822, позволяя применение в полях заголовков символьных наборов, отличных US-ASCII. RFC 2048 специфицирует различные ограничения, вводимые IANA, для процедур, сопряженных с MIME. RFC 2049 характеризует критерии соответствия требованиям MIME, содержит примеры допустимых форматов и библиографию.
1. Введение
Документ RFC 822, который прослужил без малого 20 лет, регламентировал работу лишь с текстовыми сообщениями (передача аудио- видео- или графических сообщений в нем не рассматривалась). Но даже в случае чисто текстовых документов возникали проблемы при работе с языковыми наборами, требующими символов, которые отсутствуют в US-ASCII.
Одним из существенных ограничений традиционной электронной почты, базирующейся на RFC 821-822, является установка предельного размера строки (1000 7-битовых US-ASCII символов). Это вынуждало пользователей конвертировать текст различными методами в последовательность US-ASCII-кодов (например, процедура uuencode или преобразование в коды Base-64).
Существенные проблемы возникали при почтовом обмене между узлами, поддерживающими протоколы RFC 822 и X.400. Протокол X.400 [X400] определяет механизм включения нетекстовых материалов в почтовые сообщения. Существующие протоколы согласования работы X.400 и RFC 822 предполагают, что X.400 осуществляет преобразование нетекстовых вставок в формат IA5Text, или такие сообщения просто выбрасываются. Отправитель сообщения часто не знает о возможностях получателя, что может привести к тому, что последний, получив сообщения, попросту не сможет его прочесть. Таким образом, нужен механизм согласования возможностей отправителя и получателя на начальной стадии их взаимодействия до начала передачи тела сообщения.
В протоколе MIME регламентируется следующее:
Поле заголовка MIME-Version, которое характеризует версию протокола и позволяет почтовым агентам согласовать свои возможности и исключить конфликты с устаревшим программным обеспечением.
Поле заголовка Content-Type, которое используется для спецификации типа среды и субтипа данных в теле сообщения, а также для описания канонической формы этих данных.
Поле заголовка Content-Transfer-Encoding, которое может использоваться для задания типа преобразования.
Два дополнительные поля заголовка, предусмотренные для уточнения описания данных в теле сообщения (Content-ID и Content-Description).
Важно заметить, что основополагающими принципами при создании MIME была совместимость с существующими стандартами и надежность работы. Для тех, кто попытается реализовать протокол MIME, определенный интерес могут представлять документы RFC 1344, RFC 1345 и RFC 1524.
Далее все цифровые величины и октеты приводятся в десятичном представлении. Все значения типа среды, субтипы и имена параметров безразличны к регистру их написания. Значения параметров, напротив, зависимы от того строчными или прописными буквами они записаны.
Терм CRLF в данном описании относится к последовательности октетов, соответствующих ASCII-символам CR (десятичный код 13) и LF (десятичный код 10), которые обозначают разрыв строки.
Терм "символьный набор" используется в MIME для того, чтобы обозначить метод преобразования последовательности октетов в последовательность символов. Заметим, что безусловное и однозначное преобразование в обратном направлении не требуется, то есть не все символы могут быть представлены через данный символьный набор (более чем одна последовательность октетов может соответствовать одной и той же последовательности символов).
Это определение имеет целью позволить различные виды символьного кодирования, начиная с простой ASCII-таблицы кончая сложными методами, использующими технику ISO 2022.
Термин "символьный набор" был первоначально введен для описания прямых схем преобразования, таких как ASCII и ISO-8859-1, для которых характерна однозначная связь символов и кодовых октетов. Многооктетные кодированные символьные наборы и методики переключения несколько осложнили ситуацию.
Термин "сообщение", обозначает сообщение типа RFC 822, передаваемое по сети, или сообщение, инкапсулированное в тело типа "message/rfc822" или "message/partial".
Термин "объект" (entity) относится к полям заголовка MIME и содержимому сообщения или его части в случае, если оно составное. Спецификация таких объектов определяется исключительно MIME. Так как содержимое объекта часто называется "тело", имеет смысл говорить о теле объекта. Любой вид поля может быть представлен в заголовке объекта, но только поля, имена которых начинаются с "content-" имеют значение, связанное с протоколом MIME.
Выражение "7-битовые данные" относится к данным, которые образуют относительно короткие строки с длиной менее 998 октетов, завершающиеся последовательностью CRLF [RFC-821]. Октеты с кодом больше чем 127 или равные нулю не допустимы. Октеты CR (десятичный код 13) и LF (десятичный код 10) могут встречаться только в виде последовательности, отмечающей конец строки.
Выражение "8-битовые данные " относится к данным, которые образуют относительно короткие строки с длиной менее 998 октетов, завершающиеся последовательностью CRLF [RFC-821]. Но здесь допустимы октеты с десятичными значениями кодов, превышающими 127 (нулевые коды не допускаются).
"Строки" в данном контексте представляют собой последовательности октетов, завершающиеся CRLF. Это согласуется с документами RFC 821 и RFC 822.
2. Поля заголовка MIME
MIME определяет ряд новых полей заголовков по сравнению с RFC 822. Они описывают содержимое MIME-объекта. Эти поля заголовков используются в двух контекстах:
В качестве части стандартного заголовка RFC 822.
В MIME-заголовке в рамках составной конструкции сообщения.
Ниже представлено формальное описание этих полей заголовка.
entity-headers := [ content CRLF ] [ encoding CRLF ] [ id CRLF ] [ description CRLF ]
*( MIME-extension-field CRLF )
MIME-message-headers := entity-headers fields version CRLF
; Порядок полей заголовка, представленный в данном BNF-определении, не имеет никакого значения.
MIME-part-headers := entity-headers [ fields ]
; Любое поле, не начинающееся с "content-" не может иметь какого-либо значения и может игнорироваться.
; Порядок полей заголовка, представленный в данном BNF-определении, не имеет никакого значения.
3. Поле заголовка MIME-Version
Так как документ RFC 822 был опубликован в 1982, там имелся только один формат для сообщений, передаваемых по каналам Интернет, и по этой причине не было необходимости декларировать тип такого стандарта. MIME является независимым дополнением документа RFC 822. Хотя протокол MIME строился так, чтобы обеспечить совместимость с RFC 822, бывают обстоятельства, когда почтовому агенту желательно выяснить, составлено ли сообщение с учетом нового стандарта. Поле заголовка "MIME-Version" служит как раз для того, чтобы можно было определить, какому стандарту соответствует тело сообщения. Сообщения, соответствующие MIME обязаны содержать такое поле заголовка со следующим текстом:
MIME-Version: 1.0
Присутствие этого поля заголовка означает, что сообщение подготовлено согласно требованиям MIME. Так как существует возможность того, что в будущем формат документов может быть изменен, формальное BNF-представление поля MIME-Version следует записать следующим образом:
version := "MIME-Version" ":" 1*DIGIT "." 1*DIGIT
Таким образом, будущие спецификаторы формата, которые могут заменить версию "1.0", ограничены двумя цифровыми полями, разделенными точкой. Если сообщение получено со значением поля MIME-version, отличным от "1.0", оно может не соответствовать данному описанию.
Заметим, что поле заголовка MIME-Version должно располагаться в самом начале сообщения. При составном сообщении не требуется, чтобы каждая из частей начиналась с поля версии. Это необходимо лишь в случае, когда заголовки встроенных сообщений типа "message/rfc822" или "message/partial" объявляют о совместимости со стандартом MIME.
Для некоторых приложений согласование версий должно проводиться независимо. Некоторые форматы (такие как application/postscript) имеют внутреннюю систему нумерации версий для каждого типа среды. Там где имеет место такое соглашение, MIME не предпринимает попыток подменить эту систему. Там где такого соглашения нет, тип среды MIME может использовать параметр "version" в поле типа содержимого. При проверке значений MIME-Version любые строки комментария RFC 822 должны игнорироваться. В частности, следующие четыре записи поля MIME-Version эквивалентны.
MIME-Version: 1.0
MIME-Version: 1.0 (produced by MetaSend Vx.x)
MIME-Version: (produced by MetaSend Vx.x) 1.0
MIME-Version: 1.(produced by MetaSend Vx.x)0
В отсутствии поля MIME-Version, принимающий почтовый агент (следующий стандарту MIME или нет) может опционно интерпретировать сообщения согласно локальным соглашениям.
Нельзя быть уверенным, что почтовое сообщение, не согласованное с MIME, является непременно обычным текстом в кодировке ASCII, так как оно может содержать код согласно локальному соглашению (например, результат работы процедуры UUTNCODE или какого-то архиватора).
4. Поле заголовка Content-Type
Задачей поля Content-Type является описание информации, содержащейся в теле сообщения. Этого описания должно быть достаточно, чтобы принимающий агент пользователя был способен воспринять и отобразить полученные данные. Значение этого поля называется типом среды.
Поле заголовка Content-Type было первым, определенным в документе RFC-1049. В RFC-1049 использовался более простой и менее мощный синтаксис, который, в прочем, вполне согласуется с регламентациями MIME.
Поле заголовка Content-Type специфицирует природу данных в теле объекта, сообщая тип среды и идентификаторы субтипа, а также предоставляя вспомогательную информацию, которая может требоваться для определенного типа среды. После типа среды и имен субтипов может следовать набор параметров, который описывается в нотации атрибут = значение. Порядок параметров не имеет значения. Тип среды верхнего уровня используется для декларирования общего типа данных, в то время как субтип определяет специфический формат информации. Таким образом, типа среды "image/xyz" достаточно, чтобы сообщить агенту пользователя, что данные представляют собой изображение, даже если агент пользователя не имеет представления о формате изображения "xyz". Такая информация может использоваться, например, для того чтобы решить, следует ли показывать пользователю исходные данные нераспознанного субтипа. Такая операция разумна для нераспознанного субтипа текста, но бессмысленна для изображения или звука. По этой причине, зарегистрированные субтипы текста, изображения, аудио и видео не должны содержать вложенной информации другого типа. Такой составной формат должен быть представлен с использованием "multipart" или "application" типов.
Параметры являются модификаторами субтипа среды и по этой причине не могут существенно влиять на природу содержимого. Набор значимых параметров зависит от типа и субтипа среды. Большинство параметров связано с одним специфическим субтипом. Однако тип среды верхнего уровня может определить параметры, которые применимы к любому субтипу данного типа. Параметры могут быть необходимы для определенных типов и субтипов, могут они быть и опционными. Реализации MIME должны игнорировать любые параметры, если их имена не распознаны.
Например, параметр "charset" применим к любому субтипу "текста", в то время как параметр "boundary" необходим для любого субтипа типа среды "multipart". Не существует параметров, применимых для всех типов среды.
Исходный набор из семи типов среды верхнего уровня определен в документе RFC 2046. Пять из них являются дискретными типами. Остальные два являются составными типами, чье содержимое требует дополнительной обработки процессорами MIME.
Этот набор типов среды верхнего уровня является замкнутым. Предполагается, что необходимые расширения набора могут осуществляться за счет введения субтипов к существующим базовым типам. В будущем, расширение базового набора допустимо лишь при смене стандарта. Если необходим какой-то новый базовый тип среды, его имя должно начинаться с "X-", что указывает на то, что он не является стандартным.
4.1. Синтаксис поля заголовка Content-Type
В нотации BNF, значение поля заголовка Content-Type определяется следующим образом:
extension-token := ietf-token / x-token ietf-token := x-token := subtype := extension-token / iana-token iana-token := parameter := attribute "=" value attribute := token ; Распознавание атрибутов не зависит от регистра, в котором они напечатаны. value := token / quoted-string token := 1* tspecials := "(" / ")" / "" / "@" / "," / ";" / ":" / "\" / "/" / "[" / "]" / "?" / "=" ; Должно представлять собой строку в кавычках Заметим, что определение "tspecials" совпадает с определением "specials" в RFC 822 с добавлением трех символов "/", "?" и "=" и удалением "." (точка).
Заметим также, что спецификация субтипа является MANDATORY - она не может быть удалена из поля заголовка Content-Type. Не существует субтипов по умолчанию. Тип, субтип и имена параметров не зависят от регистра, в которых они напечатаны. Например, TEXT, Text и TeXt являются эквивалентными типами среды верхнего уровня. Значения же параметров в норме чувствительны к регистру, в котором они напечатаны, но иногда интерпретируются без учета регистра в зависимости от приложения. (Например, границы типа multipart являются чувствительными к регистру, а параметр "access-type" для сообщения message/External-body не чувствителен.)
Обратите внимание, что значение строки в кавычках не включает в себя сами кавычки. В полях заголовка в соответствии с RFC 822 допускаются комментарии. Таким образом, две приведенные ниже формы являются эквивалентными.
Content-type: text/plain; charset=us-ascii (Plain text)
Content-type: text/plain; charset="us-ascii".
Предполагается, что имена субтипов при их применении не вызовут конфликтов. Так недопустимо, чтобы в различных приложениях "Content-Type: application/foobar" означало различные вещи. Существует два приемлемых механизма определения новых субтипов среды.
Частные значения (начинающиеся с "X-") могут быть определены для двух взаимодействующих агентов без официальной регистрации или стандартизации.
Новые стандартные значения должны регистрироваться IANA, как это описано в RFC 2048.
4.2. Значения по умолчанию Content-Type
Сообщения по умолчанию без MIME-заголовка Content-Type согласно протоколу должны содержать простой текст с символьным набором ASCII, который может быть специфицирован явно.
Content-type: text/plain; charset=us-ascii
Это значение подразумевается, если не специфицировано поле заголовка Content-Type. Рекомендуется, чтобы это значение по умолчанию использовалось в случае, когда встретилась нераспознанное значение поля заголовка Content-Type. В присутствии поля заголовка MIME-Version и отсутствии поля Content-Type, принимающий агент пользователя может также предположить, что отправитель предлагает простой текст в ASCII-кодировке. Простой ASCII-текст может предполагаться в отсутствии MIME-Version или в присутствии синтаксически некорректного поля заголовка Content-Type, хотя это может и не совпадать с намерениями отправителя.
5. Поле заголовка Content-Transfer-Encoding
Многие типы среды, которые могут передаваться посредством электронной почты, представляются в своем естественном формате, таком как 8-битовые символы или двоичные данные. Такие данные не могут быть переданы посредством некоторых транспортных протоколов. Например, RFC 821 (SMTP) ограничивает почтовые сообщения 7-битовым символьным набором ASCII со строками короче 1000 символов, включая строчные разделители CRLF.
Таким образом, необходимо определить стандартный механизм кодировки таких данных в 7-битный формат с короткими строками. В MIME для этой цели используется поле заголовка "Content-Transfer-Encoding". Это поле не было определено каким-либо прежним стандартом.
5.1. Синтаксис Content-Transfer-Encoding
Значения полей Content-Transfer-Encoding представляют собой лексему, характеризующую тип кодирования, как это описано ниже.
| encoding | := | "Content-Transfer-Encoding" ":" mechanism |
| mechanism | := | "7bit" / "8bit" / "binary" / "quoted-printable" / "base64" / ietf-token / x-token |
/p> Эти значения не чувствительны к регистру, в котором напечатаны. - Base64, BASE64 и bAsE64 эквивалентны. Тип кодировки 7BIT требует, чтобы тело уже имело 7-битовое представление, пригодное для передачи. Это значение по умолчанию, означает, что в отсутствии поля Transfer-Encoding предполагается "Content-Transfer-Encoding: 7BIT".
5.2. Семантика Content-Transfer-Encodings
Лексема Content-Transfer-Encoding предоставляет два вида информации. Она специфицирует, какому виду кодового преобразования подвергнуто тело сообщения и, следовательно, какая процедура декодирования должна использоваться при восстановлении исходного вида сообщения.
Преобразовательная часть любого Content-Transfer-Encodings специфицирует явно или неявно алгоритм декодирования, который либо восстановит исходный вид последовательности или обнаружит ошибку. Преобразования Content-Transfer-Encodings для нормальной работы никогда не требует какой-либо дополнительной внешней информации. Преобразование заданной последовательности октетов в другую эквивалентную кодовую последовательность совершенно легально.
В настоящее время определены три преобразования: тождественное (никакого преобразования), преобразование в последовательность печатных символов и в последовательность кодов "base64".
Значения Content-Transfer-Encoding "7bit", "8bit" и "binary" означают, что никакого преобразования не произведено. Они указывают на тип тела сообщения, и позволяют предполагать, какое кодирование может потребоваться при передаче данных.
Кодирование в последовательность печатных символов или в кодовую последовательность base64 предполагает преобразование из произвольного исходного формата в представление "7bit", что позволяет передачу через любые транспортные среды.
Всегда должна использоваться корректная метка Content-Transfer-Encoding. Пометка данных, преобразованных программой UUENCODE и содержащих 8-битовые символы, как "7bit" не допустима, такие данные должны помечаться только как "binary".
При прочих равных условиях предпочтительным представлением является последовательность печатных символов или кодов base64.
Передача почтовых сообщений закодированных программой uuencode описана в документе RFC 1652. Но следует иметь в виду, что ни при каких обстоятельствах Content-Transfer-Encoding "binary" нельзя считать приемлемым для e-mail. Однако когда используется MIME, двоичное тело сообщение может быть помечено как таковое.
5.3. Новое значение Content-Transfer-Encodings
Программисты могут, если необходимо, определить частные значения Content-Transfer-Encoding. При этом должны использоваться x-лексемы, которые представляют собой имена с префиксом "X-", что указывает на нестандартный статус, например, "Content-Transfer- Encoding: x-my-new-encoding". Дополнительные стандартизованные значения Content-Transfer-Encoding должны быть специфицированы в официальных документах RFC.
В отличие от типов среды и субтипов, формирование новых значений Content- Transfer-Encoding категорически не рекомендуется, так как может привести к полному выходу из строя системы.
4. Реализация и применение
Если поле заголовка Content-Transfer-Encoding появляется как часть заголовка сообщения, оно относится ко всему телу сообщения. Если поле заголовка Content-Transfer-Encoding появляется в качестве части заголовка объекта, то зоной его действия будет тело этого объекта. Если объект имеет тип "multipart", то Content-Transfer-Encoding не может иметь значение "7bit", "8bit" или "binary". Следует заметить, что большинство типов среды определены в терминах октетов, а не бит, поэтому описываемые механизмы относятся к кодировке произвольных потоков октетов, а не бит. Если необходимо закодировать битовую последовательность, она должна быть преобразована в последовательность октетов с сетевой последовательностью бит ("big-endian"), в которой более ранние биты становятся старшими битами октетов. Битовые потоки, длина которых не кратна 8, должны быть дополнены нулями.
Механизмы кодировки, определенные здесь, осуществляют преобразование любых данных в ASCII. Таким образом, предположим, например, что объект имеет следующие поля заголовка:
Content-Type: text/plain; charset=ISO-8859-1
Content-transfer-encoding: base64
Это должно интерпретироваться так, что тело имеет кодировку base64, а исходные данные имели представление в ISO-8859-1.
Определенные значения Content-Transfer-Encoding могут использоваться только с определенными типами среды. В частности, категорически запрещено использовать любую кодировку отличную от "7bit", "8bit" или "binary" с любым составным типом среды, т.e. включающим и другие поля Content-Type. В настоящее время допустимы составные типы среды "multipart" и "message". Все кодировки, допустимые для тел типа multipart или message должны использоваться на самом внутреннем уровне.
Следует также заметить, что по определению, если составной объект имеет значение transfer-encoding равное "7bit", но один из составляющих объектов имеет менее регламентирующее значение, например, "8bit", тогда либо внешняя метка "7bit" является ошибкой, или внутренняя метка "8bit" устанавливает слишком высокое требование к транспортной системе (следовало проставить 7bit).
Хотя запрет использования content-transfer-encodings для составного тела может показаться чрезмерно регламентирующим, следует избегать вложенных кодирований, в которых данные подвергаются последовательно обработке несколькими алгоритмами. Вложенные кодирования заметно повышают сложность агентов пользователя. Помимо очевидных проблем эффективности при множественном кодировании они могут затемнить базовую структуру сообщения. В частности они могут подразумевать, что необходимо несколько операций декодирования, чтобы определить, какие типы тел содержит сообщение. Запрет вложенных кодировок может осложнить работу некоторых почтовых шлюзов, но это представляется меньшей бедой, чем осложнение жизни агентов пользователя при вложенном кодировании.
Любой объект с нераспознанным значением Content-Transfer- Encoding должен рассматриваться, как если бы он имел код Content-type "application/octet-stream", вне зависимости оттого, что утверждается полем заголовка Content-Type.
Может показаться, что Content-Transfer-Encoding может быть выяснено из характеристик среды, для которой нужно осуществить кодирование или, по крайней мере, что определенное Content-Transfer-Encodings может быть предназначено для использования с определенными типами среды. Есть несколько причин, почему это не так. Во-первых, существующие различные типы транспорта, используемые для почты, некоторые кодирования могут годиться для определенных комбинаций типов среды и транспорта, но быть непригодными для других. Например, при 8-битовой передаче, при определенном символьном наборе для текста не потребуется никакого кодирования, в то время как такое кодирование очевидно необходимо для 7-битового SMTP.
Во-вторых, определенные типы среды могут требовать различного транспортного кодирования при разных обстоятельствах. Например, многие PostScript-тела могут целиком состоять из коротких строк 7-битовых кодов, и, следовательно, совсем не требуют кодирования. Другие тела PostScript (в особенности те, что используют механизм двоичного кодирования уровня 2 PostScript) могут быть представлены с использованием двоичного транспортного кодирования. Наконец, так как поле Content-Type ориентировано на то, чтобы предоставлять открытые механизмы спецификации, строгие ассоциации типов среды и кодирования эффективно соединяют спецификацию прикладного протокола с определенным транспортом нижнего уровня. Это нежелательно, так как разработчики типа среды не должны заботиться обо всех видах транспорта и их особенностях.
5.5. Транслирующее кодирование
Кодирование с использованием закавыченных строк печатных символов и кодов base64 устроено так, чтобы позволить взаимные преобразования. Единственная проблема, которая здесь возникает, это обработка принудительных разрывов строк для закавыченных последовательностей печатных символов. При преобразовании закавыченных строк в коды base64 принудительные разрывы строк отображаются последовательностями CRLF. Аналогично, последовательность CRLF в канонической форме данных, полученной после декодирования из base64, должна преобразоваться в принудительный разрыв строки в случае представления текста в виде закавыченной строки печатных символов. Каноническая модель кодирования представлена в документе RFC 2049.
5.6. Транспортное кодирование содержимого Quoted-Printable
Кодирование Quoted- Printable имеет целью представление данных, состоящих по большей части из октетов, которые соответствуют печатным символам ASCII-набора. Оно преобразует данные таким образом, что результирующие октеты не будут видоизменены при транспортировке почты. Если преобразуемые данные представляют собой ASCII-текст, то после кодирования они сохранят читабельность. Тело, которое целиком состоит из ASCII-кодов, может быть также представлено в виде закавыченной строки печатных символов. При этом сохраняется целостность текста в процессе прохождении через шлюз, который осуществляет трансляцию символов и/или обработку разрывов строк. При этом кодировании октеты должны определяться согласно изложенным ниже правилам:
8-битовое представление. Любой октет, за исключением CR или LF, которые являются частью последовательности разрыва строки CRLF, канонического (стандартного) формата данных может быть представлен с помощью символом "=", за которым следуют две шестнадцатеричные цифры, характеризующие значение октета. Для этих целей используются цифры шестнадцатеричного алфавита "0123456789ABCDEF". Должны использоваться прописные буквы; использование строчных букв недопустимо. Так, например, десятичное значение 12 (ASCII FF) может быть представлено как "=0C", а десятичное значение 61 (ASCII символ знака равенства) представляется с помощью "=3D". Это правило должно выполняться всегда за исключением случаев, когда правила допускают альтернативное кодирование.
(2)
Литеральное представление. Октеты с десятичными кодами в интервале 33 - 60 включительно, и 62 - 126, включительно, могут представляться ASCII-символами, которые соответствуют этим октетам (с ! до < и с > до ~ соответственно).
(3)
Пробелы. Октеты со значениями кодов 9 и 32 могут отображаться с помощью ASCII-символов TAB (HT) и пробел, соответственно, но не должны использоваться в конце строки. За любым символом TAB (HT) или пробел в кодируемой строке должен следовать печатный символ. В частности, символ "=" в конце каждой кодируемой строки, обозначающий "мягкий" разрыв строки (смотри правило #5), может следовать за одним или более символами TAB (HT) или SP. Отсюда следует, что октет, равный 9 или 32 появляющийся в конце кодируемой строки должен быть представлен в форме, указанной правилом #1. Это правило необходимо, так как некоторые MTA (Message Transport Agents, программы, которые передают сообщения от одного пользователя другому) дополняют строки пробелами, а другие удаляют пробелы (HT или SP) в конце строки. Следовательно, при декодировании тела, представленного в форме закавыченных печатных последовательностей, любые HT или SP должны быть удалены.
(4)
Разрывы строк. Разрыв строки в теле текста, представленный последовательностью CRLF в канонической форме, для закавыченной печатной строки отмечается CRLF. Последовательности типа "=0D", "=0A", "=0A=0D" и "=0D=0A" появляются в нетекстовых данных, представленных в виде закавыченных строк печатных символов.
Заметим, что многие реализации могут выбрать для кодирования непосредственно локальное представление различных типов содержимого, а не преобразование в каноническую форму, кодирование и только затем преобразование в локальное представление. В частности, такая техника может быть применена к простому тексту в системах, которые используют для межстрочных разрывов последовательности, отличные от CRLF. Такая оптимизация конкретной программной реализации вполне допустима, но только когда комбинированный шаг канонизация-кодирование эквивалентен выполнению всех трех шагов отдельно.
(5)
Мягкие разрывы строки. Кодирование с помощью закавыченных строк печатных символов требует, чтобы строки содержали не более 76 символов. Если нужно закодировать более длинные строки вводятся “мягкие” разрывы строк. Символ равенства в конце строки как раз и обозначает такой разрыв.
Так пусть имеется следующий текст, который надо преобразовать:
Now's the time for all folk to come to the aid of their country
.
Это может быть представлено следующим образом с помощью закавыченных строк печатных символов:
Now's the time =
Это предоставляет механизм, с помощью которого длинные строки преобразуются таким образом, как они должны быть запомнены агентом пользователя. Ограничение в 76 символов не учитывает завершающие строку CRLF, но включают все прочие символы, включая знаки равенства. Так как символ дефис ("-") может отображаться в закавыченных строках самим собой, нужно следить за тем, чтобы при инкапсуляции закодированного так фрагмента, в одном или более составных объектов пограничные разделители не появились в закодированном теле. Хорошей стратегией является выбор в качестве границы последовательности символов "=_", которая не может встретиться в закавыченной строке печатных символов.
Преобразование в закавыченные строки печатных символов представляет собой компромисс между читабельностью и надежностью при транспортировке. Тела, закодированные с помощью закавыченных строк печатных символов, пропускаются без проблем большинством почтовых шлюзов. Проблемы могут возникать только со шлюзами, осуществляющими трансляцию в коды EBCDIC. Кодирование с помощью base64 обеспечивает более высокий уровень надежности. Методом получения разумно высокой надежности транспортировки через шлюзы EBCDIC является представление символов !"#$@[\]^`{|}~ согласно правилу #1.
Так как закавыченные последовательности печатных символов предполагаются ориентированными на строчное представление, разрывы между строками могут видоизменяться в процессе транспортировки. Если изменение кодов разрыва строк может вызвать искажения или сбои, следует использовать кодирование с помощью base64.
Несколько видов субстрок не могут генерироваться согласно правилам кодирования для представления с помощью закавыченных последовательностей печатаемых символов. Ниже перечисляются эти нелегальные субстроки и предлагаются способы их кодирования.
Символ "=", за которым следует две шестнадцатеричные цифры, одна или обе из которых являются строчными символами (abcdef). Надежные реализации могут распознавать их как прописные буквы.
(2)
Символ "=", за которым следует символ, не являющийся ни шестнадцатеричной цифрой (включая abcdef), ни CR из комбинации CRLF. Это не может стать частью ASCII-текста, включенного в сообщение, без преобразования в закавыченную последовательность печатных кодов. Разумным решением для надежной реализации может быть включение символа "=" и следующих за ним кодов в декодированную последовательность, без какого-либо преобразования и, если возможно, дать и сигнал агенту пользователя, что декодирование в этом месте оказалось невозможным.
(3)
Символ "=" не может быть последним или завершающим символом в кодируемом объекте. Решением проблемы можно считать способ, предложенный в пункте (2).
(4)
Управляющие символы, отличные от TAB, CR и LF (в качестве части CRLF) не должны присутствовать. То же справедливо для октетов с десятичными значениями больше чем 126. Если такие коды обнаруживаются в приходящих закавыченных последовательностях печатных символов, корректная реализация может исключить из декодированных данных и предупредить пользователя о том, что обнаружен нелегальный символ.
(5)
Закодированные строки не должны быть длиннее 76 символов, не считая завершающие CRLF. Если во входном потоке обнаружены более длинные строки, надежная реализация может их декодировать, но должна предупредить пользователя об ошибке.
Если двоичные данные закодированы в виде закавыченных последовательностей печатных символов, следует позаботиться о том, чтобы символы CR и LF были представлены в виде "=0D" и "=0A", соответственно. В частности, последовательность CRLF в двоичных данных должна кодироваться как "=0D=0A". В противном случае, если CRLF была бы представлена как “жесткий” разрыв строки, она может декодироваться некорректно на платформах с различными способами обработки разрывов строки. С формальной точки зрения, закавыченные последовательности печатных символов подчиняются следующей грамматике.
| quoted-printable | := | qp-line *(CRLF qp-line) | |
| qp-line | := | *(qp-segment transport-padding CRLF) qp-part transport-padding | |
| qp-part | := | qp-section | ; Максимальна длина 76 символов |
| qp-segment | := | qp-section *(SPACE / TAB) "=" | ; Максимальна длина 76 символов |
| qp-section | := | [*(ptext / SPACE / TAB) ptext] | |
| ptext | := | hex-octet / safe-char | |
| safe-char | := | ; Символы, не включенные в список "mail-safe" RFC 2049, не рекомендуются к применению. | |
| hex-octet | := | "=" 2(DIGIT / "A" / "B" / "C" / "D" / "E" / "F") | ; Октет должен использоваться для символов с кодами > 127, =, SP или TAB в конце строк, и рекомендуются для любого символа не указанного в списке "mail-safe" документа RFC 2049. |
| transport-padding | := | *LWSP-char | ; Составители не должны генерировать заполнители ненулевой длины, но получатели должны быть способны обрабатывать заполнители, добавленные при транспортировке. |
/p> Добавление LWSP между элементами, показанное в данном BNF-представлении, не допустимо, так как данное BNF не специфицирует структурированных полей заголовка.
5.7. Транспортное кодирование Base64 (Content-Transfer-Encoding)
Транспортное кодирование на основе Base64 создано для представления произвольной последовательности октетов в форме, которая не обязательно должна быть приемлемой для прочтения человеком. Алгоритмы кодирования и декодирования просты. Это кодирование сходно с тем что используется в почтовом приложении PEM (Privacy Enhanced Mail), как это определено в RFC-1421.
Здесь используется 65-символьный субнабор ASCII, для каждого печатного символа выделено по 6 бит. Дополнительный 65-ый символ "=", используется для обозначения специальных функций обработки.
Этот субнабор имеет важное свойство, которое заключается в том, что он представляется идентично во всех версиях ISO 646, включая US-ASCII, и все символы субнабора имеют аналоги во всех версиях EBCDIC. Другие популярные кодировки, такие как применение утилиты uuencode, Macintosh binhex 4.0 [RFC-1741] и base85, специфицированная как часть уровня 2 PostScript, имеют отличающиеся свойства и, следовательно, не выполняют условий переносимости, которым должна удовлетворять двоичное транспортное кодирование электронной почты.
При кодировании входные 24-битовые группы преобразуют в 4 символа. Входная группа формируется из трех 8-битовых кодов и обрабатывается слева направо. Эти 24 бита рассматриваются в дальнейшем как 4 6-битовые группы, каждая из которых транслируется в одно число из алфавита base64. Когда кодируется битовый поток с использованием base64, предполагается, что старший бит передается первым. То есть, первый бит потока станет старшим битом первого 8-битового байта, а 8-ой бит станет его последним битом.
Каждая 6-битовая группа используется как индекс массива из 64 печатных символов. Символ, на который указывает индекс, берется из массива и помещается в выходной поток. Эти символы представлены в таблице .1., из их перечня исключены коды, имеющие особое значение для протокола SMTP (например, ".", CR, LF), а также разграничитель секций составного сообщения "-" (RFC-2046).
Таблица .1. Коды Base64
символа
(6 бит)
ASCII
символ
Код
символа
(6 бит)
ASCII
символ
Код
символа
(6 бит)
ASCII
символ
Код
символа
(6 бит)
ASCII
символ
0
A
10
Q
20
g
30
w
1
B
11
R
21
h
31
x
2
C
12
S
22
i
32
y
3
D
13
T
23
j
33
z
4
E
14
U
24
k
34
0
5
F
15
V
25
l
35
1
6
G
16
W
26
m
36
2
7
H
17
X
27
n
37
3
8
I
18
Y
28
o
38
4
9
J
19
Z
29
p
39
5
A
K
1A
a
2A
q
3A
6
B
L
1B
b
2B
r
3B
7
C
M
1C
c
2C
s
3C
8
D
N
1D
d
2D
t
3D
9
E
O
1E
e
2E
u
3E
+
F
P
1F
f
2F
v
3F
/
Закодированный выходной поток должен иметь формат последовательности из одной или более строк длиной не более 76 символов каждая. Все разрывы строк или другие символы, не содержащиеся в таблице .1. должны игнорироваться декодирующим программным обеспечением. В данных, представленных в кодах base64, символы отличные от тех, что представлены в таблице .1., разрывы строк и другие пробелы обычно указывает на ошибку передачи, которая вызовет предупреждение или даже выбрасывание сообщения.
Если число бит в группе меньше 24, используется специальная обработка. Неполная битовая группа дополняется нулями справа до 24. Заполнение в конце информационной группы осуществляется с использованием символа "=". Так как последовательность кодов base64 представляет собой поток октетов, возможны следующие случаи:
последний блок кодируемых данных кратен 24 битам; здесь, завершающий выходной блок будет содержать в себе 4 символа и никакого заполнителя,
завершающий блок кодируемых данных содержит ровно 8 бит; здесь, оконечный выходной блок будет содержать два символа, за которыми будут следовать два символа заполнителя, или
последний блок кодируемой информации содержит ровно 16 бит; здесь, оконечный блок на выходе будет иметь три символа плюс один символ заполнителя "=".
Так как "=" используется для дополнения, его наличие указывает на то, что достигнут конец массива данных. Такая уверенность не возможна, когда число переданных октетов кратно трем и нет ни одного символа "=". Любые символы, не входящие в алфавит base64-должны игнорироваться.
Следует позаботиться о том, чтобы использовались корректные октеты в качестве разделителей строк при работе с base64. В частности, разрывы строк должны быть преобразованы в последовательности CRLF до выполнения кодирования base64.
6. Поле заголовка Content-ID
При создании агента пользователя высокого уровня, может быть желательно, допустить одному телу ссылаться на другое. Тела могут быть помечены с помощью поля заголовка "Content-ID", которое синтаксически идентично полю "Message-ID":
id := "Content-ID" ":" msg-id
Подобно значениям Message-ID, значения Content-ID должны генерироваться уникальными.
Значение Content-ID может использоваться для идентификации MIME-объектов в нескольких контекстах, в частности для кэширования данных с доступом через механизм message/external-body. Хотя заголовок Content-ID является обычно опционным, его использование является обязательным в приложениях, которые генерируют данные опционного типа среды MIME "message/external-body". По этой причине каждый объект message/external-body должен иметь поле Content-ID, для того чтобы разрешить кэширование таких данных.
7. Поле заголовка Content-Description
Часто оказывается желательным установить соответствие между описательной информацией и данным телом. Например, может быть полезным пометить тело типа "image" как "изображение старта космического корабля". Такой текст может быть помещен в поле заголовка Content-Description. Это поле всегда является опционным.
description := "Content-Description" ":" *text
Предполагается, что описание дается с использованием символьного набора US-ASCII, хотя механизм, специфицированный в RFC 2047, может быть использован и для значений Content-Description, не соответствующих стандарту US-ASCII.
8. Дополнительные поля заголовка MIME
Будущие документы могут содержать дополнительные поля заголовков MIME для различных целей. Любое новое поле заголовка, которое описывает содержимое сообщения должно начинаться со строки "Content-", для того чтобы такие поля можно было с гарантией отличить от обычных полей заголовков сообщения, следующих стандарту RFC-822.
MIME-extension-field :=
Используя поля заголовка MIME-Version, Content-Type и Content-Transfer-Encoding, можно подключить стандартным образом произвольные типы данных и добиться совместимости с требованиями документа RFC-822. Никакие ограничения введенные документами RFC-821 или RFC-822 не нарушаются, были приняты меры, чтобы исключить проблемы, связанные с дополнительными ограничениями из-за свойств некоторых механизмов пересылки почты по Интернет (см. RFC-2049).
Приложение A -- обзор грамматики
Это приложение содержит грамматические описания всех конструкций, содержащихся в протоколе MIME.
| attribute | := | token | Распознавание атрибутов не зависит от регистра, в котором написаны их имена. |
| composite-type | := | "message" / "multipart" / extension-token | |
| Content | := | "Content-Type" ":" type "/" subtype *(";" parameter) | Распознавание типов среды и субтипов не зависит от регистра, в котором написаны их имена. |
| description | := | "Content-Description" ":" *text | |
| discrete-type | := | "text" / "image" / "audio" / "video" / "application" / extension-token | |
| encoding | := | "Content-Transfer-Encoding" ":" mechanism | |
| entity-headers | := | [ content CRLF ] [ encoding CRLF ] [ id CRLF ] [ description CRLF ] *( MIME-extension-field CRLF ) | |
| extension-token | := | ietf-token / x-token | |
| hex-octet | := | "=" 2(DIGIT / "A" / "B" / "C" / "D" / "E" / "F") | Октет должен использоваться для символов > 127, =, пробелов или TAB в конце строк, и рекомендуется для любого символа вне списка "mail-safe" RFC 2049. |
| iana-token | := | ||
| ietf-token | := | ||
| Id | := | "Content-ID" ":" msg-id | |
| mechanism | := | "7bit" / "8bit" / "binary" / "quoted-printable" / "base64" / ietf-token / x-token | |
| MIME-extension-field | := | ||
| MIME-message-headers | := | entity-headers fields version CRLF | Порядок полей заголовка, заданный в BNF-определении не играет никакой роли. |
| MIME-part-headers | := | Заголовки объекта [поля] | Любое поле, начинающееся с "content-", не имеет строго заданного значения и может игнорироваться. |
| parameter | := | атрибут "=" значение | |
| Ptext | := | hex-octet / safe-char | |
| qp-line | := | *(qp-segment transport-padding CRLF) транспортный заполнитель qp-части | |
| qp-part | := | qp-секция | Максимальная длина 76 символов |
| qp-section | := | [*(ptext / SPACE / TAB) ptext] | |
| qp-segment | := | qp-секция *(SPACE / TAB) "=" | Максимальная длина 76 символов |
| Quoted-printable | := | qp-line *(CRLF qp-line) | |
| safe-char | := | Символы вне списка "mail-safe" в RFC 2049 не рекомендуются. | |
| subtype | := | Лексема расширения / лексема iana | |
| Token | := | 1* | |
| transport-padding | := | *LWSP-char | Программа-отправитель не должна формировать транспортное заполнение ненулевой длины, но получатели должны быть способны обрабатывать такие транспортные заполнители. |
| tspecials | := | "(" / ")" / "" / "@" / "," / ";" / ":" / "\" / "/" / "[" / "]" / "?" / "=" | При использовании в значениях параметров они должны иметь формат закавыченных строк. |
| Type | := | discretetype / compositetype | |
| Value | := | лексема / закавыченная строка | |
| version | := | "MIME-Version" ":" 1*DIGIT "." 1*DIGIT | |
| x-token | := |
/p>
II. Типы среды
1. Введение
Поле Content- Type используется для спецификации природы информации в теле MIME-объекта путем присвоения идентификаторов типа и субтипа среды и предоставления дополнительной информации, которая может быть необходима для данной разновидности среды. За именами типа и субтипа среды в поле следует набор параметров, заданных в нотации атрибут/значение. Порядок следования параметров не существенен.
Тип среды верхнего уровня используется для декларации общего типа данных, в то время как субтип определяет специфический формат данного типа информации. Таким образом, тип среды "image/xyz" говорит агенту пользователя, что данные характеризуют изображение и имеют формат "xyz". Такая информация может использоваться, для того чтобы решить, отображать ли пользователю исходные данные нераспознанного субтипа. Такие действия могут быть разумными для нераспознанного фрагмента субтипа "text", но не для субтипов "image" или "audio". По этой причине, зарегистрированные субтипы "text", "image", "audio" и "video" не должны содержать встроенных фрагментов другого типа. Такие составные форматы должны использовать типы "multipart" или "application".
Параметры являются модификаторами субтипа среды, и как таковые не оказывают никакого влияния на содержимое. Набор параметров зависит от типа и субтипа среды. Большинство параметров связано с одним специфическим субтипом. Однако определенный тип среды высшего уровня может определить параметры, которые приложимы к любому субтипу данного типа. Параметры могут быть обязательными или опционными. MIME игнорирует любые параметры, имена которых нераспознаны.
Поле заголовка Content-Type и механизм типа среды спроектированы так, чтобы сохранить масштабируемость, обеспечивая постепенный рост со временем числа пар тип/субтип и сопряженных с ними параметров. Транспортное кодирование MIME, а также типы доступа "message/external-body" со временем могут обрести новые значения. Для того чтобы гарантировать то, что такие значения разработаны и специфицированы корректно, в MIME предусмотрен процесс регистрации, который использует IANA (Internet Assigned Numbers Authority) в качестве главного органа контролирующего данный процесс (см. RFC 2048). В данном разделе описаны семь стандартизованных типов среды верхнего уровня.
2. Определение типов среды верхнего уровня
Определение типа среды верхнего уровня состоит из:
Имя и описание типа, включая критерии, согласно которым можно решить, относится ли данная среда к указанному типу.
(2)
Имена и определения параметров, если таковые имеются, которые определены для всех субтипов данного типа, включая то, является ли данный параметр обязательным или опционным.
(3)
Как агент пользователя и/или шлюз должен обрабатывать не узнанный субтип данного типа.
(4)
Общие соображения о шлюзовании объектов данного типа, если таковые имеются.
(5)
Любые ограничения на транспортное кодирование объектов данного типа.
3. Обзор базовых типов среды верхнего уровня
Имеется пять дискретных типов среды высокого уровня.
text
– текстовая информация. Субтип "plain" в частности указывает, что текст не содержит команд форматирования или каких-либо директив. Такой текст нужно отображать, так как он есть. Не нужно никакого специального программного обеспечения для восприятия такого текста, помимо поддержки указанного символьного набора. Другие субтипы должны использоваться для обогащенного текста (enriched) в форме, где прикладное программное обеспечение может улучшить представление текста. Но такая программа не нужна для общей обработки содержимого. Возможные субтипы "text" включают в себя любые форматы, которые могут быть прочитаны без обращения к программе, которая понимает этот формат. В частности, форматы, которые используют встроенное двоичное форматирование, не считаются непосредственно читаемыми. Очень простой и портативный субтип, "richtext", был определен в документе RFC 1341, и позднее пересмотрен в RFC 1896 под именем "enriched".
(2)
image
- графические данные. "Image" требует устройства отображения (такого как графический дисплей, графический принтер, или факс) для того чтобы просмотреть информацию. Первичный субтип определен для широко используемого формата изображения JPEG. Субтипы определены для двух широко используемых форматов изображения jpeg и gif.
(3)
audio
- звуковые данные. "Audio" требует выходного устройства ( такого как громкоговоритель или телефон) для воспроизведения содержимого.
(4)
video
– видео данные. "Video" требует выходного устройства, способного воспроизвести движущееся изображение. В данном документе определен первичный субтип "mpeg".
(5)
application
– некоторые другие типы данных, обычно не интерпретированные двоичные данные или информация, которая должна быть обработана приложением. Субтип "octet-stream" следует использовать в случае не интерпретируемых двоичных данных, в этом случае простейшей рекомендацией может служить передача этой информации в файл пользователя. Субтип "PostScript" определен для транспортировки PostScript текстов.
Существует два составных типа среды высшего уровня.
multipart
– данные, состоящие из нескольких объектов с различными типами данных. Определены четыре первичных субтипов, включая базовый субтип "mixed", специфицирующий смешанный набор частей, "alternative" - для представления одних и тех же данных в различных форматах, "parallel" - для частей, которые должны представляться одновременно и "digest" - для составных объектов, в которых каждая часть имеет тип по умолчанию "message/rfc822".
(2)
message
- инкапсулированное сообщение. Тело типа среды "message" составляет часть или весь объект сообщения некоторого типа. Такие объекты могут содержать в свою очередь другие объекты. Субтип "rfc822" используется, когда инкапсулированное содержимое само является сообщением RFC 822. Субтип "partial" определен для частичных сообщений вида RFC 822, чтобы разрешить по-фрагментную передачу слишком длинных тел сообщения. Другой субтип "external-body" определен для спецификации протяженных тел с помощью ссылок на внешние источники информации.
4. Дискретные значения типа среды
Пять из семи базовых значений типа среды относятся к дискретным телам. Содержимое этих типов должно обрабатываться с использование механизмов за пределами MIME, они непрозрачны для MIME-процессоров.
4.1. Тип среды Text
Тип среды "text" предназначен для посылки материала, который имеет принципиально текстуальную форму. Параметр "charset" можно использовать для указания символьного набора тела субтипов "text", включая субтип "text/plain", который является общим субтипом для чистого текста. Чистый текст не содержит форматирующих команд, спецификаций атрибутов шрифтов, инструкций обработки, директив интерпретации или разметки. Чистый текст представляет собой последовательность символов, которая может содержать разрывы строк или страниц.
Помимо чистого текста существует много форматов, называемых "богатый" текст ("rich text"). Интересной характеристикой многих таких представлений является то, что они читабельны даже без программы, которая его интерпретирует. Полезно затем отличать их на верхнем уровне от таких нечитабельных данных как изображения, звук или текст, представленный в нечитаемом виде. В отсутствии подходящей интерпретирующей программы разумно показать субтипы "text" пользователю, в то время как это неразумно для большей части нетекстовых данных. Такие форматированные текстовые данные должны представляться с помощью субтипов "text".
4.1.1. Представление разрывов строк
Каноническая форма любого субтипа MIME "text" должна всегда оформлять разрыв строки с помощью последовательности CRLF. Аналогично, любое появление CRLF в тексте MIME должно означать разрыв строки. Использование CR и LF по отдельности вне обозначения разрыва строки запрещено. Это правило работает вне зависимости от используемого символьного набора.
Правильная интерпретация разрывов строк при отображении текста зависит от типа среды. Следует учитывать, что одно и то же оформление разрывов строк при отображении "text/plain" может восприниматься корректно, в то время как для других субтипов "text", например, "text/enriched" [RFC-1896] аналогичные разрывы строк будут восприниматься как неверные. Нет необходимости в добавлении каких-либо разрывов строк при отображении "text/plain", в то время как отображение "text/enriched" требует введения соответствующего оформления разрывов строк.
Некоторые протоколы определяют максимальную длину строки. Например, SMTP [RFC-821] допускает максимум 998 октетов перед последовательностью CRLF. Для того чтобы реализовать транспортировку посредством такого протокола, данные, содержащие слишком длинные сегменты без CRLF, должны быть закодированы с применением соответствующего content-transfer-encoding.
4.1.2. Параметр Charset
Критическим параметром, который может быть специфицирован в поле Content-Type для данных "text/plain", является символьный набор. Он специфицируется параметром "charset", например, как:
Content-type: text/plain; charset=iso-8859-1
В отличие от других значений параметров, значения параметра символьный набор не чувствительны к регистру, в котором написано его имя. Значением по умолчанию параметра символьный набор равно US-ASCII.
Для других субтипов "text", семантика параметра "charset" должна быть определена аналогично параметрам, заданным для "text/plain", т.e., тело состоит полностью из символов данного набора. В частности, авторы будущих определений субтипов "text" должны обратить особое внимание мультиоктетным символьным наборам. Параметр charset для субтипов "text" дает имя символьному набору, как это определено в RFC 2045.
Заметим, что специфицированный символьный набор включает в себя 8-битовые коды и эти символы используются в теле, поле заголовка Content-Transfer-Encoding и для передачи данных с помощью транспортных протоколов (например, SMTP) необходима соответствующая кодировка, такая как [RFC-821].
Значение символьного набора по умолчанию, равное US-ASCII, являлось причиной многих неурядиц в прошлом. Для того чтобы исключить какие-либо неопределенности в будущем, настоятельно рекомендуется новым агентам пользователя задавать символьный набор в явном виде в качестве параметра типа среды в поле заголовка Content-Type. "US-ASCII" не указывает на произвольный 7-битовый символьный набор, а говорит о том, что все октеты в теле должны интерпретироваться как символы US-ASCII. Национальные и ориентированные на приложения версии ISO 646 [ISO-646] обычно не идентичны US-ASCII, и их непосредственное применение в электронной почте может вызвать проблемы. Имя символьного набора "US-ASCII" относится к кодам, заданным в документе ANSI X3.4-1986 [US- ASCII].
Полный набор символов US-ASCII представлен в ANSI X3.4-1986. Заметим, что управляющие символы, включая DEL (0-31, 127) не имеют определенного значения, исключение составляет комбинация CRLF (US-ASCII значения 13 и 10) обозначающая разрыв строки. Два символа имеют широко используемые функции, это: FF (12) – продолжить последующий текст с начала новой страницы, и TAB или HT (9) часто (хотя и не всегда) означает "переместить курсор в следующую колонку. Колонки нумеруются, начиная с нуля и их позиции кратны 8. Помимо этих случаев любые управляющие символы или DEL в теле объекта могут появиться при следующих условиях.
по причине того, что субтип текста, отличающийся от "plain", приписывает им некоторые дополнительные значения, или
(2)
в рамках контекста частного соглашения между отправителем и получателем.
Определены следующие значения charset:
US-ASCII – как это определено в ANSI X3.4-1986 [US-ASCII].
(2)
ISO-8859-X -- где "X" следует замещать как это требуется для частей ISO-8859 [ISO-8859]. Допустимыми подменами "X" являются цифры от 1 до 10.
Символы с кодами в диапазоне 128-159 не имеют стандартизованных значений в рамках ISO-8859-X. Символы с кодами меньше 128 в ISO-8859-X имеют те же значения, что и в US-ASCII.
Значения символьных наборов "ISO-8859-6" и "ISO-8859-8" специфицируют применение визуального метода [RFC-1556].
Все эти символьные наборы используются как чисто 7-битовые или 8-битовые без модификаций связанных или .
Никакие символьные наборы, отличные от определенных выше, не могут использоваться в электронной почте без публикации и формальной регистрации в IANA. Допустимы частные соглашения, в этом случае имя символьного набора должно начинаться с "X-".
Потребителям не рекомендуется определять новые символьные наборы, если это не диктуется крайней необходимостью. Параметр "charset" был первоначально определен для текстовых данных. Однако возможно его использование и для не текстовой информации, обычно это делается для синтаксической совместимости.
Если широко используемый символьный набор А является подмножеством другого символьного набора Б, а тело содержит только символы из набора А, он должен быть помечен как А.
4.1.3. Субтип Subtype
Простейшим и наиболее важным субтипом "text" является "plain". Он указывает, что текст не содержит форматирующих команд или директив. Чистый текст может отображаться непосредственно без какой-либо обработки. По умолчанию для электронной почты предполагается тип среды "text/plain; charset=us-ascii".
4.1.4. Не распознанные субтипы
Не распознанные субтипы "text" должны обрабатываться как чистый текст ("plain"), поскольку реализация MIME знает, как работать с данным символьным набором. Не распознанные субтипы, которые также специфицируют нераспознаваемый символьный набор, должны обрабатываться как "application/octet- stream".
4.2. Тип среды Image
Тип среды "image" указывает, что тело содержит изображение. Субтип называет имя специфического формата изображения. Эти имена не чувствительны к регистру. Исходным субтипом является "jpeg", который использует кодировку JFIF для формата JPEG [JPEG]. Не распознанные субтипы "image" должны обрабатываться как "application/octet-stream".
4.3. Тип среды Audio
Исходный субтип "basic" специфицирован, для того чтобы удовлетворить требованиям, которые соответствуют самому нижнему в иерархии аудио-форматов. Предполагается, что форматы для более высококачественного воспроизведения и/или низко полосной передачи будут определены позднее.
Содержимое субтипа "audio/basic" представляет собой моноканальное звуковое кодирование, использующее 8-битоый ISDN-стандарт с m-функцией преобразования [PCM] с частотой стробирования 8000 Hz. Не распознанные субтипы "audio" должны обрабатываться как "application/octet-stream".
4.4. Тип среды Type
Тип среды "video" указывает, что тело содержит движущееся изображение, возможно цветное и в сопровождении звука. Термин 'video' используется в самом общем значении, и не подразумевает какого-то конкретного формата. Субтип "mpeg" относится к видео закодированного согласно стандарту MPEG [MPEG]. Не распознанные субтипы "video" должны обрабатываться как "application/octet-stream".
4.5. Тип среды Application
Тип среды "application" следует использовать для дискретных данных, которые не могут быть отнесены ни к какой другой категории, в частности для данных, которые должны быть обработаны какой-то прикладной программой. Это информация, которая должна обрабатываться приложением до того как она станет доступной для просмотра пользователем. К предполагаемым применениям типа среды "application" относится файловый обмен, электронные таблицы, диспетчерские системы, базирующиеся на электронной почте.
Такие приложения могут быть определены как субтипы типа среды "application". В данном документе определены два субтипа:
octet-stream и PostScript.
4.5.1. Субтип Octet-Stream (поток октетов)
Субтип "octet-stream" используется для индикации того, что тело содержит произвольные двоичные данные. В настоящее время определены следующие параметры:
| (1) | TYPE – общий тип или категория двоичных данных. Это параметр предназначен для оператора-получателя, а не для программы обработки. |
| (2) | PADDING – число бит заполнителя, добавленного к потоку бит, представляющему действительное содержимое, для того чтобы получить байт-ориентированный поток. Используется, когда число бит в теле не кратно 8 |
4.5.2. Субтип PostScript
Тип среды "application/postscript" указывает на программу PostScript. В настоящее время допускается два варианта языка PostScript. Исходный вариант уровня 1 описан в [POSTSCRIPT], а более новый вариант уровня 2 рассмотрен в [POSTSCRIPT2].
Описания языка PostScript предоставляет возможности внутренней пометки специфических возможностей данного приложения. Эта пометка, называемая DSC (document structuring conventions) PostScript, предоставляет существенно больше информации, чем уровень языка. Использование DSC рекомендуется даже тогда, когда это непосредственно не требуется, так как обеспечивает более широкую совместимость. Документы, которые недостаточно структурированы, не могут быть проверены с целью выяснения того, могут ли они работать в данной среде.
Работа универсальных интерпретаторов PostScript представляет серьезную угрозу безопасности, разработчикам не рекомендуется просто посылать тела PostScript имеющимся ("off-the-shelf") интерпретаторам. В то время как посылка PostScript-файла на принтер обычно безопасна, программисты должны рассмотреть все возможные последствия, прежде чем ввести интерактивное отображение тел типа PostScript на их читающих средствах MIME.
Ниже перечислены возможные проблемы, связанные с транспортировкой объектов PostScript.
В список опасных операций языка PostScript входят "deletefile", "renamefile", "filenameforall" и "file". "File" является единственной опасной процедурой, которая применяется для входных/выходных потоков не стандартных данных. Конкретные реализации могут определить не стандартные файловые операторы, которые могут также представлять угрозу безопасности. "Filenameforall", - оператор поиска файлов, может показаться на первый взгляд безобидным.
Заметим, что этот оператор может раскрыть информацию о том, к каким файлам имеет доступ пользователь, а эти данные могут облегчить задачу хакеру. Отправители сообщений должны избегать использования потенциально опасных файловых операторов, так как такие операторы, скорее всего, недоступны в PostScript приложениях, где приняты меры по обеспечению безопасности. Программное обеспечение, которое используется для приема и отображения, должно блокировать потенциально опасные файловые операторы или принять меры по ограничению их возможностей.
(2)
Язык PostScript предоставляет возможность для выхода из цикла интерпретатора или сервера. Операторы, сопряженные с выходом интерпретатора из цикла могут интерферировать с процедурами последующей обработки документов. Операторы PostScript, которые выводят интерпретатор из цикла, включают в себя серверы выхода и начала задания. Программе отправки сообщения не следует генерировать PostScript, который зависит от функционирования выхода интерпретатора из цикла, так как такая процедура может отсутствовать в реализациях с повышенной безопасностью. Программа приема сообщений должна полностью блокировать работу операторов "startjob" и "exitserver", также какие-либо изменения в среде PostScript на постоянной основе. Если эти операции не могут быть полностью исключены, для их выполнения должен быть организован контролируемый доступ с необходимостью ввода пароля.
(3)
PostScript предоставляет операторы для установки системных параметров и специфических параметров внешних устройств. Эти установки параметров могут влиять неблагоприятным образом на работу интерпретатора. Процедуры PostScript, которые устанавливают системные параметры, могут включать в себя операторы "setsystemparams" и "setdevparams". Программа отправки не должна генерировать PostScript-сообщений, которые зависят от установки системных параметров. Программа приема и отображения сообщений должна блокировать изменение системных параметров. Если блокировка по каким-либо причинам невозможна, процедура установки параметров должна требовать специфического пароля.
(4)
Некоторые реализации PostScript предоставляют нестандартные возможности для прямой загрузки и исполнения машинных кодов. Такие возможности чреваты злоупотреблениями. Программа отправки сообщений не должна использовать такие возможности. Программа приема и отображения сообщений не должна позволять применение таких операторов, если они имеются.
(5)
PostScript является расширяемым языком, и многое, если не большинство, его реализаций предоставляют большое число расширений. Программа отправки сообщений не должна использовать нестандартные расширения. Программа приема и отображения сообщений должна быть уверена, что эти нестандартные расширения не представляют угрозы.
(6)
Имеется возможность написания такой PostScript-программы, которая потребует огромных системных ресурсов. Можно также написать PostScript-фрагмент, который реализует бесконечный цикл. Оба варианта представляют угрозу для ничего не подозревающего получателя. Программа отправки сообщений должна избегать создания и распространения таких кодов. Программа приема и отображения сообщений должна предоставлять подходящий механизм для блокировки исполнения и удаления таких программ по истечении некоторого заданного времени.
(7)
Существует возможность включения двоичной информации в PostScript-текст. Это не рекомендуется в электронной почте, так как это не поддерживается всеми PostScript-интерпретаторами, потому что сильно усложняет использование транспортного кодирования MIME.
(8)
Наконец, в некоторых интерпретаторах PostScript вполне возможны ошибки, которые могут использоваться для получения не авторизованного доступа к системе получателя.
4.5.3. Другие субтипы приложений
Ожидается, что в будущем будут определены многие другие субтипы "application". Реализации MIME должны уметь обрабатывать нераспознанные субтипы как "application/octet-stream".
5. Значения типа среды Composite (составной)
Оставшиеся два из семи исходных значений Content-Type относятся к составным объектам. Составные объекты обрабатываются с использованием механизмов MIME -- процессор MIME обрабатывает тело объекта непосредственно.
5.1. Тип среды Multipart
В случае составных объектов, когда один или более различных наборов данных объединяется в одном теле, в заголовке объекта должно присутствовать поле типа среды "multipart". Тело должно тогда содержать одну или более частей, каждая из которых начинается с разделительной строки. За разделительной строкой следует заголовок, пустая строка и тело объекта. Таким образом, часть тела по своему синтаксису аналогична сообщению в RFC-822, но имеет другое назначение.
Часть тела является объектом и, следовательно, не должна интерпретироваться как сообщение RFC-822. Начнем с того, что части тела должны иметь заголовки. Допустимы части тела, которые начинаются с пустой строки. В таком случае отсутствие заголовка Content-Type обычно указывает, что соответствующее тело имеет тип содержимого "text/plain; charset=US-ASCII".
Единственные поля заголовка, которые определяют назначение частей тела, имеют имена, начинающиеся с "Content-". Все другие поля в заголовке части тела могут игнорироваться. Для экспериментальных или частных назначений могут создаваться поля, с именами, начинающимися с "X-". Информация, содержащаяся в этих полях может теряться в некоторых шлюзах.
Различие между сообщением RFC-822 и частью тела не велико, но существенно. Шлюз между Интернет и почтовым сервером X.400, например, должен быть способен различать части тела, содержащие изображение и инкапсулированное сообщение, тело которого представляет собой JPEG-образ. Для того чтобы представить последнее, часть тела должна иметь "Content-Type: message/rfc822", и ее тело после пустой строки должно представлять собой инкапсулированное сообщение со своим собственным полем заголовка "Content-Type: image/jpeg". Применение подобного синтаксиса способствует преобразованию сообщений в части тела и обратно.
Как было заявлено ранее, каждая часть тела начинается со строки-разграничителя. Разграничитель не должен появляться внутри любой инкапсулированной части, или в качестве префикса любой строки. Это подразумевает, что генерирующий агент способен специфицировать уникальное значение пограничного параметра, которое не содержит в качестве префикса значения разграничительного параметра вкладываемой части.
Все существующие и будущие субтипы типа "multipart" должны использовать идентичный синтаксис. Субтипы могут отличаться по своей семантике и могут вводить дополнительные ограничения на синтаксис, но должны согласовываться с базовым синтаксисом типа "multipart". Это требование гарантирует, что все агенты пользователя будут, по крайней мере, способны распознать и разделить части составного объекта, даже если они относятся к нераспознанным субтипам.
Как задано в определении поля Content-Transfer-Encoding [RFC-2045], никакие кодировки кроме "7bit", "8bit" или "binary" не разрешены для объектов типа "multipart". Граничные разделители и поля заголовков "multipart" всегда представляются как 7-битовые коды US-ASCII, а данные внутри частей тела могут быть закодированы по-разному и иметь свои поля Content-Transfer-Encoding для каждой из частей.
5.1.1. Общий синтаксис
Поле Content-Type для составных объектов требует одного параметра - "boundary". Строка-разделитель определяется как строка, содержащая два символа дефис ("-", десятичный код 45), за которыми следует значение пограничного параметра из поля заголовка Content-Type, опционный строчный пробел и заключительные CRLF.
Символы дефис служат для некоторой совместимости с ранним методом (RFC-934) инкапсуляции сообщений, и для облегчения поиска границ для некоторых приложений. Однако следует заметить, что составные сообщения не вполне совместимы с инкапсуляцией, описанной в RFC-934. В частности, они не подчиняются RFC-934 регламентации использования кавычек для вложенных строк, которые начинаются с дефиса. Этот механизм был выбран помимо RFC-934, потому что при данной схеме происходит удлинение строк для каждого уровня закавычивания. Возрастание длины строк, а также то, что некоторые реализации SMTP осуществляют разрыв строк, делают механизм RFC-934 неприменимым для составных сообщений при большой глубине вложений.
Грамматика для параметров поля Content-type такова, что в строке Content- type часто необходимо помещать пограничный параметр в кавычки. Это необходимо не всегда, но никогда не повредит. Программисты должны тщательно изучить грамматику, для того чтобы избежать генерации некорректных полей Content-type. Таким образом, типичное поле заголовка "multipart" Content-Type может выглядеть как:
Content-Type: multipart/mixed; boundary=gc0p4Jq0M2Yt08j34c0p
Content-Type: multipart/mixed; boundary="gc0pJq0M:08jU534c0p"
Это значение Content-Type указывает, что содержимое состоит из одной или более частей со структурой, которая синтаксически идентична сообщению RFC-822, за исключением того, что область заголовка может быть совершенно пустой, а каждая из частей начинается со строки
--gc0pJq0M:08jU534c0p
Пограничный разделитель должен размещаться в начале строки, т.e., следовать за CRLF, а начальный CRLF рассматривается объединенным со строкой пограничного разделителя, а не частью предшествующей секции. За границей может следовать нуль или более символов строчного пробела (HT, SP). Далее следует еще один CRLF и поля заголовка следующей части, или два CRLF, что означает отсутствие полей заголовка следующей части. Если поле Content-Type отсутствует, предполагается объект типа "message/rfc822" в сообщении "multipart/digest", в противном случае "text/plain".
Граничные разделители не должны появляться внутри инкапсулированного материала и не должны быть длиннее 70 символов, не считая двух начальных символов дефис.
Строка пограничного разделителя, следующая за последней частью тела, является уникальной и указывает, что далее не следует более никаких частей тела. Такая разделительная строка идентична предшествующим с добавлением двух символов дефис после значения граничного параметра.
--gc0pJq0M:08jU534c0p--
Сравнение пограничной строки должно сопоставлять значение пограничного параметра с началом каждой строки-кандидата. Полного совпадения всей строки-кандидата не требуется, достаточно наличия разграничителя, следующего за CRLF.
Имеется место для дополнительной информации перед пограничным разделителем и после оконечного разграничителя. Эти области следует в норме оставлять пустыми, а программные реализации должны игнорировать размещенную там информацию. Некоторые реализации используют эти "ниши" для пересылки сообщений принимающим программам.
Пограничный параметр в выше приведенном примере может быть результатом работы алгоритма, специально созданного для генерации кодов, которые с крайне малой вероятностью могут встретиться в инкапсулируемых данных. Другой алгоритм может выдать более "читаемый" код пограничного разделителя, что может потребовать предварительного просмотра инкапсулируемых данных. Простейшей строкой пограничного разделителя может служить "---", а закрывающим разделителем - "-----".
Ниже представлен простой пример составного сообщения, имеющего две части, каждая из которых содержит чистый текст, введенный явно и неявно:
From: Nathaniel Borenstein
To: Ned Freed
Date: Sun, 21 Mar 1993 23:56:48 -0800 (PST)
Subject: Sample message
MIME-Version: 1.0
Content-type: multipart/mixed; boundary="simple boundary"
Это преамбула. Она будет проигнорирована, но, тем не менее, это удобное место, чтобы отправитель мог поместить сообщение для принимающей стороны, которая не поддерживает MIME.
| простая граница | Это неявно введенный чистый US-ASCII-текст. Он не завершается на данной строке |
| простая граница | Content-type: text/plain; charset=us-ascii. Это явно введенный чистый US-ASCII-текст. Он завершается на данной строке |
| простая граница | Это эпилог. Он также игнорируется |
Практика показала, что тип "multipart" с единственной составной частью полезен для посылки сообщений с нетекстовым типом среды. Он имеет возможность формирования преамбулы, как места, где можно поместить инструкции по декодированию. Кроме того, многие шлюзы SMTP перемещают или удаляют заголовки MIME, и хороший MIME-декодер таким путем может получить необходимую информацию даже в отсутствие заголовка Content-Type и корректно декодировать сообщение.
Единственным обязательным глобальным параметром для типа среды "multipart" является граничный параметр, который состоит из 1 - 70 кодов из символьного набора, который надежен по отношению преобразований, осуществляемых почтовыми шлюзами. Значение параметра не должно завершаться пробелом. Формально это записывается в BNF-представлении следующим образом.
boundary := 0*69 bcharsnospace
bchars := bcharsnospace / " "
bcharsnospace := DIGIT / ALPHA / "'" / "(" / ")" / "+" / "_" / "," / "-" / "." / "/" / ":" / "=" / "?"
Вообще тело объекта "multipart" может быть специфицировано как:
dash-boundary := "--" boundary
; boundary берется из значения граничного параметра поля Content-Type.
multipart-body := [preamble CRLF]
| dash-boundary transport-padding CRLF | |
| body-part *encapsulation | |
| close-delimiter transport-padding | |
| [CRLF epilogue] |
| transport-padding := *LWSP-char |
Отправители не должны генерировать транспортные ; заполнители ненулевой длины, но получатели ; должны уметь обрабатывать заполнители, введенные ; при транспортировке. |
delimiter := CRLF dash-boundary
close-delimiter := delimiter "--"
epilogue := discard-text
; не должен появляться где-либо в теле секции. Заметим, что семантика части тела
; отличается от семантики сообщения, как это описано в тексте.
OCTET :=
Введение пробелов (HT, SP) и комментариев RFC 822 между элементами, показанными выше, не допустимо, так как эти BNF не специфицируют структурированное поле заголовка.
В определенных транспортных зонах регламентации RFC 822, такие как ограничение применения каких-либо символов, помимо печатных кодов US-ASCII могут не действовать. Ослабление этих ограничений может рассматриваться как локальное расширение определения тел, например, чтобы включить октеты вне набора US-ASCII, постольку, поскольку эти расширения поддерживаются системой передачи и соответствующим образом документированы в поле заголовка Content-Transfer-Encoding. Однако заголовки ни в коем случае не могут содержать чего-либо помимо кодов US-ASCII.
5.1.2. Обработка вложенных и составных сообщений
Субтип "message/rfc822" не имеет других условий завершения кроме окончания массива данных. Аналогично, некорректно укороченный составной объект не будет иметь завершающего разделителя, что может вызвать нарушение работы почтовой системы.
Существенно, чтобы такие объекты обрабатывались корректно, когда они сами вложены в другие составные структуры. Реализации MIME должны уметь распознавать граничные маркеры на любом уровне вложения.
5.1.3. Субтип Mixed
Субтип "mixed" типа "multipart" предназначен для использования в условиях, когда части тела независимы и должны объединяться в определенном порядке. Любые субтипы "multipart", которые не распознаны программой, должны восприниматься как субтип "mixed".
5.1.4. Субтип Alternative
Тип "multipart/alternative" синтаксически идентичен "multipart/mixed", но имеет иную семантику. В частности, каждая часть тела является альтернативой одной и той же информации.
Системы должны распознавать, что содержимое различных частей взаимозаменяемы. Системы должны выбрать наилучший тип на основе локального окружения и в некоторых случаях с использованием диалога с пользователем. Как и для "multipart/mixed", порядок частей тела является существенным. В этом случае, альтернативы появляются в порядке возрастания правдоподобия оригинальному содержимому. Вообще наилучшим выбором является последняя часть типа, поддерживаемая локальной средой приемной системы..
"Multipart/alternative" может использоваться, например, для посылки сообщения в любом формате таким образом, чтобы его было легко отобразить:
From: Nathaniel Borenstein
To: Ned Freed
Date: Mon, 22 Mar 1993 09:41:09 -0800 (PST)
Subject: Formatted text mail
MIME-Version: 1.0
Content-Type: multipart/alternative; boundary=boundary42
--boundary42
Content-Type: text/plain; charset=us-ascii
... здесь следует версия сообщения в виде чистого текста ...
--boundary42
Content-Type: text/enriched
... здесь следует версия сообщения RFC 1896 в виде обогащенного текста (text/enriched) ...
--boundary42
Content-Type: application/x-whatever
... здесь следует наиболее причудливая версия сообщения ...
--boundary42--
В этом примере пользователи, чья почтовая система может работать с форматом "application/x-whatever", увидят только причудливую версию сообщения, в то время как другие пользователи увидят версию с обогащенным или чистым текстом, в зависимости от возможностей их системы.
Вообще, агенты пользователя, которые формируют объекты "multipart/alternative" должны размещать части тела в порядке их предпочтения, то есть, предпочтительный формат следует последним. Посылающий агент пользователя должен поместить простейший формат текста первым, а обогащенный - последним. Принимающие агенты должны воспринять самый последний формат, который они способны отобразить. В случае, когда одной из альтернатив является тип "multipart", который содержит нераспознанные составные части, агент пользователя может отобразить эту альтернативу, более раннюю или даже обе версии сообщения.
Возможен вариант, когда агент пользователя способен распознать и отобразить разные форматы, он может предложить окончательный выбор самому пользователю. Это имеет смысл, например, если сообщение включает графическую и текстовую версии сообщения. Агент пользователя не должен автоматически отображать все версии, какие он воспринял, он должен отобразить последнюю, или предоставить выбор оператору.
Каждая часть объекта "multipart/alternative" представляет одну и ту же информацию, версии не необязательно тождественны. Например, информация теряется, когда осуществляется трансляция ODA в PostScript или в чистый текст. Рекомендуется, чтобы каждая часть имела свое значение Content-ID в тех случаях, когда содержимое частей неэквивалентно. Например, там, где несколько частей типа "message/external-body" специфицируют способы доступа к идентичной информации, следует использовать одни и те же значения поля Content-ID. Возможен вариант, когда одно значение Content-ID может относиться к объекту "multipart/alternative", в то время как одно или более других значений Content-ID будут относиться к частям внутри объекта.
5.1.5. Субтип Digest
Этот документ определяет субтип "digest" типа содержимого "multipart". Этот тип синтаксически идентичен "multipart/mixed", но их семантика различна. В частности, в дайджесте, значение по умолчанию Content-Type для части тела меняется с "text/plain" на "message/rfc822". Это сделано, для того чтобы допустить более читаемый формат дайджеста, совместимый с RFC-934.
Хотя можно специфицировать значение Content-Type для части тела в дайджесте, который отличается от "message/rfc822", такая часть как "text/plain", содержащая описание материала в дайджесте, делает это нежелательным. Тип содержимого "multipart/digest" предназначен для использования при посылке группы сообщений. Если необходима часть "text/plain", она должна быть включена как отдельная компонента сообщения "multipart/mixed". Дайджест в этом формате может выглядеть как.
From: Moderator-Address
To: Recipient-List
Date: Mon, 22 Mar 1994 13:34:51 +0000
Subject: Internet Digest, volume 42
MIME-Version: 1.0
Content-Type: multipart/mixed;
boundary="---- главный разделитель ----"
------ главный разделитель ----
...Вводный текст или содержимое таблицы...
------ главный разделитель ----
Content-Type: multipart/digest;
boundary="---- следующее сообщение ----"
------ следующее сообщение ----
From: someone-else
Date: Fri, 26 Mar 1993 11:13:32 +0200
Subject: my opinion
... здесь размещается тело...
------ следующее сообщение ----
From: someone-else-again
Date: Fri, 26 Mar 1993 10:07:13 -0500
Subject: my different opinion
... здесь размещается следующее тело ...
------ следующее сообщение ------
------ главный разделитель ------
5.1.6. Субтип Parallel
Этот документ определяет субтип "parallel" типа содержимого "multipart". Этот тип синтаксически идентичен "multipart/mixed", но их семантика различна. В частности, в параллельном объекте, порядок частей тела не играет роли.
Представление этого типа заключается в одновременном отображении всех частей с использованием имеющихся оборудования и программ. Однако программа отправитель должна учесть то, что многие приемники почты не способны выполнять операции параллельно и отобразят все части сообщения последовательно.
5.1.7. Прочие субтипы Multipart
В будущем ожидается появление новых субтипов "multipart". Реализации MIME должны уметь работать с нераспознанными субтипами "multipart" как с "multipart/mixed".
5.2. Тип среды Message
Часто желательно при посылке почты вложить туда какое-то другое сообщение. Для решения этой задачи определен специальный тип среды "message”. В частности, для вложения в сообщения RFC-822 служит субтип "rfc822"
Субтип "message" часто накладывает ограничения на допустимые типы кодирования. Эти ограничения описаны для каждого специфического субтипа. Почтовые шлюзы, системы транспортировки и другие почтовые агенты иногда изменяют заголовки верхнего уровня в сообщениях RFC 822. В частности, они часто добавляют, удаляют и меняют порядок полей заголовков. Эти операции запрещены для заголовков, вложенных в тело сообщения типа "message."
5.2.1. Субтип RFC822
Тип среды "message/rfc822" указывает, что тело содержит инкапсулированное сообщение. Однако в отличие от сообщений верхнего уровня RFC-822, ограничение, связанное с обязательным присутствием в теле "message/rfc822" заголовков "From", "Date", и, по крайней мере, одного адреса места назначения, здесь удалено. Необходимо лишь присутствие одного из заголовков "From", "Subject" или "Date". Следует заметить, что, несмотря на использование чисел "822", объект "message/rfc822" не должен абсолютно следовать регламентациям RFC-822. Более того, сообщение "message/rfc822" может быть статьей новостей или сообщением MIME.
В теле объекта "message/rfc822" не разрешены никакие кодировки помимо "7bit", "8bit" или "binary". Поля заголовка сообщения содержат только US-ASCII в любом регистре, а информация в теле может быть закодирована. Не-US-ASCII-текст в заголовках инкапсулированного сообщения может быть специфицирован с использованием механизма, описанного в документе RFC-2047.
5.2.2. Субтип Partial
Субтип "partial" определен, для того чтобы разрешить разделять на части слишком большие объекты, которые затем доставляются в виде отдельных почтовых сообщений и автоматически восстанавливаются как единое целое принимающим агентом пользователя. Этот механизм может использоваться, когда промежуточный транспортный агент ограничивает максимальный размер почтового сообщения. Тип среды "message/partial", таким образом, указывает, что тело содержит фрагмент некоторого большого объекта.
Так как данные типа "message" могут не быть закодированны в виде base64 или закавыченной строки печатных символов, может возникнуть проблема, если объекты "message/partial" созданы в среде, которая поддерживает двоичный или 8-битовый обмен. Проблема возникает из-за того, что двоичные данные надо будет разбить на несколько сообщений "message/partial", каждое из которых требует двоичного транспорта. Если такие сообщения встретят по пути шлюз с 7-битовой передачей, не будет никакой возможности перекодировать эти фрагменты для 7-битовой среды. Можно конечно дождаться прихода всех составных частей, собрать исходный объект, закодировать его с помощью, например, base64, после чего начать все с начала. Но даже такой сложный сценарий может оказаться неосуществимым из-за того, что фрагменты могут транспортироваться разными путями. По этой причине, было специфицировано, что объекты типа "message/partial" должны всегда иметь транспортное кодирование “7bit” (по умолчанию). В частности, даже для сред, которые поддерживают двоичный или 8-битовый обмен, использование транспортного кодирования "8bit" или "binary" для MIME-объектов типа "message/partial" запрещено. Это в свою очередь предполагает, что внутреннее сообщение не должно использовать кодирование "8bit" или "binary". Так как некоторые агенты пересылки сообщений могут выбрать автоматическую фрагментацию длинных сообщений, а также из-за того, что эти агенты могут использовать разные пороги фрагментации, может так получиться, что фрагменты после сборки в свою очередь окажутся частями сообщения. Это вполне допустимо.
В поле Content-Type типа "message/partial" необходимо специфицировать три параметра. "id" - уникальный идентификатор, который должен использоваться для привязки фрагментов друг к другу. "number" - целое число, которое является номером фрагмента. "total" - целое число, характеризующее полное число фрагментов. Число фрагментов является опционным и обязательно присутствует только в последнем фрагменте. Заметим также, что эти параметры могут быть заданы в любом порядке. Таким образом, второй сегмент 3-фрагментного сообщения может иметь поля заголовка одного из следующих видов.
ontent-Type: Message/Partial; number=2; total=3;
ontent-Type: Message/Partial;
number=2
Но в третьем сегменте должно быть специфицировано полное число фрагментов.
Content-Type: Message/Partial; number=3; total=3;
Заметьте, что нумерация фрагментов начинается с 1, а не 0.
Когда фрагменты объекта, разорванные таким способом, складываются вместе, результатом всегда будет исходный MIME-объект, который может иметь свое собственное поле заголовка Content-Type, и, следовательно, иметь любой другой тип данных.
5.2.2.1. Фрагментация и сборка сообщений
Семантика восстановленных фрагментов сообщений должна соответствовать "внутреннему" сообщению, а не сообщению, в которое оно вложено. Это делает возможным, например, посылку большого аудио-сообщения в виде нескольких сообщений-фрагментов таким образом, что получатель воспримет его как простое аудио-сообщение, а не инкапсулированное сообщение, содержащее аудио-сообщение. Такая инкапсуляция рассматривается как прозрачная. Когда формируются фрагменты и осуществляется сборка составных частей сообщения "message/partial", заголовки инкапсулированного сообщения должны объединяться с заголовками вложенных объектов. При реализации этой процедуры должны выполняться следующие правила:
Фрагментирующие агенты должны разделять сообщения только по границам строк. Это ограничение вводится из-за того, что при несоблюдении данного правила возникнет транспортная проблема сохранения семантики сообщения, не заканчивающегося последовательностью CRLF. Многие виды транспорта не способны решить такую задачу.
(2)
Все поля заголовка исходного вложенного сообщения, за исключением тех, чьи имена начинаются с "Content-", и специфических полей заголовка "Subject", "Message-ID", "Encrypted" и "MIME-Version", должны копироваться в новое сообщение.
(3)
Поля заголовка вложенного сообщения, начинающиеся с "Content-", плюс поля "Subject", "Message-ID", "Encrypted" и "MIME-Version" fields, должны быть добавлены в порядке к полям нового сообщения. Любые поля заголовка, которые не начинаются с "Content-" (за исключением полей "Subject", "Message-ID", "Encrypted" и "MIME-Version") будут проигнорированы и отброшены.
(4)
Все поля заголовка второго и любых последующих вложенных сообщений отбрасываются принимающей программой в процессе сборки.
5.2.2.2. Пример фрагментации и сборки
Если аудио-сообщение разделено на два фрагмента, первая часть может выглядеть как:
X-Weird-Header-1: Foo
From: Bill@host.com
Subject: Audio mail (part 1 of 2)
Message-ID:
MIME-Version: 1.0
Content-type: message/partial; id="ABC@host.com";
number=1; total=2
X-Weird-Header-1: Bar
X-Weird-Header-2: Hello
Message-ID:
Subject: Audio mail
Content-transfer-encoding: base64
... здесь помещается первая половина закодированных аудио-данных ...
а вторая часть может выглядеть следующим образом:
From: Bill@host.com
>To: joe@otherhost.com
Date: Fri, 26 Mar 1993 12:59:38 -0500 (EST)
Subject: Audio mail (part 2 of 2)
MIME-Version: 1.0
Message-ID:
Content-type: message/partial;
id="ABC@host.com"; number=2; total=2
... здесь помещается вторая половина закодированных аудио-данных ...
Затем, когда фрагментируемое сообщение оказывается собрано, результат, отображаемый для пользователя, должен выглядеть как:
X-Weird-Header-1: Foo
From: Bill@host.com
To: joe@otherhost.com
Date: Fri, 26 Mar 1993 12:59:38 -0500 (EST)
Subject: Audio mail
Message-ID:
MIME-Version: 1.0
Content-type: audio/basic
Content-transfer-encoding: base64
... здесь помещается первая половина закодированных аудио-данных ...
... здесь помещается вторая половина закодированных аудио-данных ...
Включение в заголовки второго и последующих секций фрагментированного сообщения поля "References" (ссылка), которое указывает на Message-Id (идентификатор сообщения) предшествующей секции, может быть полезно для системы чтения почты, которая умеет отслеживать ссылки. Однако генерация полей "References" является опционной.
Наконец, следует заметить, что поле "Encrypted" заголовка является устаревшим из-за внедрения конфиденциальной почты PEM (Privacy Enhanced Messaging; RFC-1421, RFC-1422, RFC-1423, RFC-1424), но правила описанные выше, несмотря ни на что, описывают правильный путь его обработки, если оно встретится в контексте прямого и обратного преобразования фрагментов "message/partial".
5.2.3. Субтип External-Body
Субтип external-body указывает, что в сообщении содержатся не данные, а ссылка на место, где эти данные находятся. В этом случае параметры описывают механизм доступа к внешним данным.
Когда объект MIME имеет тип "message/external-body", он состоит из заголовка, двух последовательностей CRLF, и заголовка для инкапсулированного сообщения. Если появится еще одна пара последовательностей CRLF, это завершит заголовок инкапсулированного сообщения. Однако так как тело инкапсулированного сообщения само является внешним, оно не появится вслед за заголовком. Например, рассмотрим следующее сообщение:
Content-type: message/external-body;
name="/u/nsb/Me.jpeg"
Content-type: image/jpeg
Content-ID:
Content-Transfer-Encoding: binary
Это в действительности не тело!
Область в конце, которую можно назвать телом-фантомом, игнорируется для большинства сообщений с внешним телом. Однако оно может использоваться для хранения вспомогательной информации для некоторых таких сообщений, как это действительно бывает, когда тип доступа - "mail-server". Единственный тип доступа, описанный в этом документе и использующий тело-фантом, это "mail-server", но могут быть описаны другие типы в будущем.
Инкапсулированные заголовки во всех объектах "message/external-body" должны включать в себя поле заголовка Content-ID, для того чтобы предоставить уникальный идентификатор, который служит для ссылки на данные. Этот идентификатор может быть использован в процессе кэширования и для распознавания входных данных, когда типом доступа является "mail-server".
Заметим, что, как это специфицировано здесь, лексемы, которые описывают данные внешнего тела, такие как имена файлов и команды почтового сервера, должны быть записаны с использованием символьного набора US-ASCII.
Как с "message/partial", объекты MIME типа "message/external-body" MUST имеют транспортное кодирование 7-бит (по умолчанию). В частности, даже в среде, которая поддерживает 8-битовую транспортировку, использование транспортного кодирования "8bit" или "binary" категорически запрещено для объектов типа "message/external-body".
5.2.3.1. Общие параметры External-Body
С "message/external- body" могут использоваться следующие параметры:
ACCESS-TYPE (тип доступа). Слово, характеризующее поддерживаемый механизм доступа, с помощью которого можно получить файл или данные. Это слово не чувствительно к регистру, в котором напечатано. Параметр может принимать следующие значения "FTP", "ANON-FTP", "TFTP", "LOCAL-FILE" и "MAIL-SERVER". Будущие значения, за исключением экспериментальных, начинающихся с "X-", должны регистрироваться IANA, как это описано в RFC-2048. Данный параметр является обязательным и должен присутствовать в каждом "message/external-body".
(2)
EXPIRATION (конец срока действия). Дата (имеет синтаксис "date-time" как в RFC-822, документ RFC-1123 разрешил 4 цифры для обозначения года), после которой существование внешних данных не гарантируется. Этот параметр может использоваться с любым типом доступа и является опционным.
(3)
SIZE (размер). Число октетов данных. Этот параметр предназначен, для того чтобы помочь получателю решить, достаточно ли ресурсов памяти для приема этих внешних данных. Заметим, что параметр описывает размер данных в канонической форме, то есть, до использования какого-либо транспортного кодирования или после декодирования. Этот параметр может использоваться с любым типом доступа и является опционным.
(4)
PERMISSION (разрешение). Не чувствительное к регистру поле, которое указывает, предполагается ли возможность для клиента переписать данные. По умолчанию или, если разрешение соответствует "read", считается, что это запрещено и что, если данные однажды извлечены, они не потребуются никогда. Если PERMISSION соответствует "read-write", такое предположение не верно. "Read" и "Read-write" являются единственными определенными значениями параметра разрешения. Этот параметр используется с любым типом доступа и является опционным.
5.2.3.2. Типы доступа 'ftp' и 'tftp'
Тип доступа FTP или TFTP указывают, что тело сообщения доступно в виде файла с помощью протоколов FTP [RFC-959] или TFTP [RFC- 783], соответственно. Для этих типов доступа необходимы следующие параметры:
NAME (имя). Имя файла, который содержит тело данных.
(2)
SITE (узел). ЭВМ, с которой может быть получен файл с помощью данного протокола. Это должно быть официально зарегистрированное имя, а не псевдоним.
(3)
Прежде чем какие-либо данные будут извлечены с помощью FTP, пользователь должен выполнить процедуру аутентификации (ввести имя и пароль) на машине, указанной в параметре SITE. По соображениям безопасности имя и пароль не специфицируются параметрами типа доступа, они должны быть получены непосредственно от пользователя.
Кроме того, следующие параметры являются опционными:
DIRECTORY (каталог). Каталог, из которого должен быть взят файл с именем, заданным параметром NAME.
(2)
MODE (режим). Строка символов, не зависящая от регистра ввода и указывающая на режим, который должен использоваться при извлечении информации. Допустимыми значениями параметра для типа доступа "TFTP" являются "NETASCII", "OCTET" и "MAIL", как это определено для протокола TFTP [RFC- 783]. Допустимыми значениями параметра для типа доступа "FTP" являются "ASCII", "EBCDIC", "IMAGE" и "LOCALn", где "n" - целое число, обычно 8. Они соответствуют типам представления "A" "E" "I" и "L n", как это задано протоколом FTP [RFC-959]. Заметим, что "BINARY" и "TENEX" не являются корректными значениями для MODE и что вместо этого следует использовать "OCTET", "IMAGE" или "LOCAL8". Если параметр MODE не задан, значением по умолчанию является "NETASCII" для TFTP и "ASCII" во всех прочих случаях.
5.2.3.3. Тип доступа 'anon-ftp'
Тип доступа "anon-ftp" идентичен варианту "ftp", за исключением того, что пользователю не нужно предоставлять имя и пароль. Вместо этого протокол ftp воспользуется именем "anonymous" и паролем, равным почтовому адресу пользователя.
5.2.3.4. Тип доступа 'local-file'
Тип доступа "local-file" указывает, что тело данных доступно в виде файла на локальной ЭВМ. Для этого типа доступа определены два дополнительные параметра:
| (1) | NAME (имя). Имя файла, который содержит тело данных. Этот параметр является обязательным для типа доступа "local-file". |
| (2) | SITE (узел). Спецификатор домена для данной ЭВМ или набора машин, которые имеют доступ к данному информационному файлу. Этот опционный параметр используется для описания локального указателя на данные, т.е., узел или группа узлов, откуда данный файл доступен. В качестве символов подмены в имени домена могут использоваться звездочки, как, например, в "*.bellcore.com", чтобы указать на группу ЭВМ, откуда данные доступны непосредственно. |
/p>
5.2.3.5. Тип доступа 'mail-server' Access-Type
Тип доступа "mail-server" указывает, что тело данных доступно на почтовом сервере. Для этого типа доступа определены два дополнительные параметра:
SERVER (сервер). Спецификация адреса почтового сервера, с которого может быть получены данные. Этот параметр является обязательным для типа доступа "mail-server".
(2)
SUBJECT (тема сообщения). Тема сообщения (subject), которая используется в почтовом сообщении с целью получения данных. Этот параметр является опционным.
Так как почтовые сервера воспринимают разнообразные синтаксисы, некоторые из которых являются многострочными, полная команда, которая должна быть послана почтовому серверу, не включается в качестве параметра с поле заголовка content-type. Вместо этого, она заносится как тело-фантом, когда тип среды соответствует "message/external-body", а тип доступа - mail-server.
Заметим, что MIME не определяет синтаксис почтового сервера. Скорее, оно позволяет включение произвольных команд почтового сервера в тело-фантом. Программные реализации должны включать тело-фантом в тело сообщения, которое посылается по адресу почтового сервера для получения нужных данных.
В отличие от других типов доступа, доступ к почтовому серверу является асинхронным и происходит в произвольный момент времени. По этой причине важно, чтобы существовал механизм, с помощью которого полученные данные могли быть сопоставлены с исходным объектом "message/external-body". Почтовые серверы MIME должны использовать то же поле Content-ID в сообщении-отклике, которое было использовано в исходных объектах "message/external-body", для того чтобы облегчить такое сопоставление.
5.2.3.6. Соображения безопасности External-Body
Объекты "Message/external-body" подводят к следующим важным соображениям безопасности:
Доступ к данным через указатель "message/external-body" эффективно приводит к тому, что получатель сообщения выполняет операцию, которую специфицировал отправитель. Следовательно, отправитель сообщения может заставить получателя выполнить нечто, что тот бы в противном случае не сделал. Например, отправитель может специфицировать процедуру, которая попытается извлечь данные, для получения которых тот не имеет авторизации, принуждая получателя помимо его воли нарушить некоторые правила безопасности. По этой причине агенты пользователя, способные работать с внешними указателями, должны сначала описать процедуру, которую ни хотят предложить выполнить получателю, попросить разрешения и только после этого запускать этот процесс.
(2)
Иногда MIME используется в среде, которая предоставляет некоторые гарантии целостности и аутентичности сообщений. В этой ситуации такие гарантии можно отнести только к собственно содержимому сообщения. Что касается механизма MIME "message/external-body", здесь такие гарантии, вообще говоря, могут быть и не реализованы. В частности, имеется возможность разрушить определенные механизмы доступа, даже если сама система доставки сообщений вполне безопасна.
5.2.3.7. Примеры и дальнейшие расширения
Когда используется механизм внешнего тела в сочетании с типом среды "multipart/alternative", это расширяет функциональность "multipart/alternative", так как включает случай, когда один и тот же объект может быть получен через разные механизмы доступа. Когда это сделано, отправитель сообщения должен упорядочить части по предпочтительности формата, а затем по механизму доступа.
Для распределенных файловых систем очень трудно знать заранее группу машин, где файл может быть доступен непосредственно. Следовательно, имеет смысл предоставить как имя файла на случай его прямой доступности, так имена одного или нескольких узлов, где может быть доступен этот файл. Программные реализации могут пытаться извлечь удаленные файлы, используя FTP или другой протокол. Если внешнее тело доступно за счет нескольких механизмов, отправитель может включить несколько объектов типа "message/external-body" в секции тела объекта "multipart/alternative".
Однако механизм внешнего тела не ограничивается извлечением файлов, как это показывается типом доступа mail-server. Помимо этого, можно предположить, например, использование видео-сервера для внешнего доступа к видео клипам.
Поля заголовка вложенного сообщения, которые появляются в теле "message/external-body" должны использоваться для декларации типа среды внешнего тела, если оно представляет собой нечто отличное от чистого текста US-ASCII, так как внешнее тело не имеет секции заголовка, чтобы декларировать тип. Аналогично здесь должно быть также декларировано любое транспортное кодирование, отличное от "7bit". Таким образом, полное сообщение "message/external-body", относящееся к объекту в формате PostScript, может выглядеть как:
From: От кого-то
To: Кому-то
Date: Когда-то
Subject: Нечто
MIME-Version: 1.0
Message-ID:
Content-Type: multipart/alternative; boundary=42
Content-ID:
--42
Content-Type: message/external-body; name="BodyFormats.ps";
access-type=ANON-FTP; directory="pub";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID:
--42
Content-Type: message/external-body; access-type=local-file;
site="thumper.bellcore.com";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID:
--42
Content-Type: message/external-body;
server="listserv@bogus.bitnet";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)"
Content-type: application/postscript
Content-ID:
get RFC-MIME.DOC
--42--
Заметим, что в вышеприведенных примерах в качестве транспортного кодирования для Postscript данных предполагается "7bit".
Подобно типу "message/partial", тип среды "message/external-body" предполагается прозрачным, т.е. передается тип данных внешнего тела, а не сообщение с телом данного типа. Таким образом, заголовки внешней и внутренней частей должны быть объединены с использованием правил, изложенных выше для "message/partial". В частности, это означает, что поля Content-type и Subject переписываются, а поле From сохраняется в неизменном виде.
Заметьте, что, так как внешние тела не передаются вместе с указателем, они не должны удовлетворять транспортным ограничениям, которые налагаются на сам указатель. В частности, почтовая транспортная среда Интернет может реализовать 7-битовый обмен и накладывать ограничение на длину строк, но они не распространяются на указатели на двоичное внешнее тело. Таким образом, транспортное кодирование не обязательно, но допустимо.
Заметим, что тело сообщения типа "message/external-body" регламентируется базовым синтаксисом сообщения RFC 822. В частности, все, что размещено перед первой парой CRLF является заголовком, в то время как все, что следует после заголовка, представляет собой данные, которые игнорируются для большинства типов доступа.
6. Экспериментальные значения типа среды
Значение типа среды, начинающееся с символов "X-" представляет собой частное значение, предназначенное для применения системами, которые согласились между собой работать в таком режиме. Любой формат, не являющийся стандартным, должен иметь имя, начинающееся с префикса "X-", а утвержденные стандартные имена никогда не начинаются с "X-".
Вообще, использование "X-" для типов верхнего уровня категорически не рекомендуется. Разработчики должны придумывать субтипы существующих типов. Во многих случаях субтип "application" будет более уместен, чем новый тип верхнего уровня.
Приложение A -- обзор грамматики
Данное приложение содержит все синтаксические конструкции, описанные в разделе MIME. Сама по себе данная грамматика не может считаться полной. Она базируется на нескольких правилах, определенных в документе RFC 822. Если какой-то термин не определен, его значение предполагается заданным в RFC 822. Сами правила RFC 822 здесь не представлены.
boundary := 0*69 bcharsnospace
bchars := bcharsnospace / " "
bcharsnospace := DIGIT / ALPHA / "'" / "(" / ")" / "+" / "_" / "," / "-" / "." / "/" / ":" / "=" / "?"
body-part :=
close-delimiter := delimiter "--"
dash-boundary := "--" boundary
delimiter := CRLF dash-boundary
discard-text := *(*text CRLF); Может игнорироваться или отбрасываться.
encapsulation := delimiter transport-padding CRLF body-part
epilogue := discard-text
multipart-body := [preamble CRLF]
body-part *encapsulation
close-delimiter transport-padding
[CRLF epilogue]
preamble := discard-text
transport-padding := *LWSP-char
; Отправители не должны генерировать транспортных заполнителей не нулевой
; длины, но получатели должны уметь обрабатывать заполнители, добавленные в
; сообщение при транспортировке.
III. Расширения для заголовков сообщений с не-ASCII текстом
В этом разделе описывается техника кодирования не-ASCII-текста в различных частях заголовка сообщения RFC-822 [2].
Подобно тому, как это рассказано в первом разделе описания MIME, методика сконструирована так, чтобы допустить использование не-ASCII символов в заголовках сообщения так, чтобы даже специфические) удаляют некоторые поля заголовков, сохраняя другие, (b) меняет содержимое адресов в полях To или Cc, (c) меняют вертикальный порядок размещения полей заголовка. Кроме того, некоторые почтовые программы не всегда способны корректно интерпретировать заголовки сообщений, в которых встречаются некоторые редко используемые рекомендации документа RFC 822, например, символы обратной косой черты для выделения специальных символов типа "
Расширения, описанные здесь, не базируются на редко используемых возможностях RFC-822. Вместо этого, определенные последовательности "обычных" печатных ASCII символов (известных как "encoded-words" – кодировочные слова) зарезервированы для использования в качестве кодированных данных. Синтаксис кодированных слов таков, что они вряд ли могут появиться в нормальном тексте заголовков сообщений. Более того, символы, используемые в кодировочных словах, не могут иметь специального назначения в контексте, где появляются эти слова.
Вообще, "encoded-word>" представляет собой последовательность печатных ASCII-символов, которая начинается с "=?", завершается "?=" и имеет два "?" между ними. Оно специфицирует символьный набор и метод кодирования, а также включает в себя оригинальный текст в виде графических ASCII-символов, созданный согласно правилам данного метода кодирования.
Отправители почты, которые используют данную спецификацию, предоставят средства для помещения не-ASCII текста в поля заголовка, но транслируют эти поля (или соответствующие части полей) в кодировочные слова, прежде чем помещать их в заголовок сообщения.
Система чтения почты, которая реализует данную спецификацию, распознает кодировочные слова, когда они встречаются в определенной части заголовка сообщения. Вместо того чтобы отображать кодировочное слово, программа осуществляет декодирование исходного текста с использованием соответствующего символьного набора.
Данный документ в заметной мере базируется на нотации и терминах RFC-822 и RFC-2045. В частности, синтаксис для ABNF, используемый здесь, определен в RFC-822. Среди терминов, определенных в RFC-822 и использованных в данном документе: 'addr-spec' (спецификация адреса), 'атом', 'CHAR', 'комментарий', 'CTL', 'ctext', 'linear-white-space' (HT| SP|CRLF), 'фраза', 'quoted-pair', 'закавыченная строка', 'пробел' и 'слово'. Успешная реализация расширения этого протокола требует тщательного внимания к определениям этих терминов в RFC-822.
Когда в данном документе встречается термин "ASCII", он относится к "7-битовому стандарту, ANSI X3.4-1986. Имя этого символьного набора в MIME "US-ASCII".
2. Синтаксис кодированных слов (encoded-words)
'Кодировочное слово' определено согласно следующей ABNF-грамматике. Используется нотация RFC-822, за исключением того, что символы “white space” (HT и SP) не должны появляться между компонентами кодировочного слова.
encoded-word = "=?" charset "?" encoding "?" encoded-text "?="
; см. секцию 3
encoding = token
; см. секцию 4
token = 1*
especials = "(" / ")" / "" / "@" / "," / ";" / ":" / " / "/" / "[" / "]" / "?" / "." / "="
encoded-text = 1*
Слова 'encoding' и 'charset' не зависят от регистра, в котором напечатаны. Таким образом символьный набор с именем "ISO-8859-1" эквивалентен "ISO-8859-1", а кодирование с именем "Q" может записываться как "Q" или "q".
'Кодировочное слово' (encoded-word) не может быть длиннее 75 символов, включая 'charset', 'encoding', 'encoded-text' и разделители. Если желательно закодировать текст больший, чем 75 символов, можно использовать несколько кодировочных слов, разделенных CRLF SP.
Хотя ограничений на длину многострочного поля заголовка, каждая строка поля заголовка, которая содержит одно или более кодировочных слов, ограничена 76 символами.
Ограничения длины введены, для того чтобы облегчить сетевое взаимодействие различных почтовых шлюзов и упростить работу программ разборки кодировочных слов.
'Кодировочные слова' сконструированы так, чтобы быть узнаваемыми как “атомы” программой грамматического разбора RFC-822. Как следствие, незакодированные символы SP и HT в пределах кодировочных слов запрещены. Например, символьная последовательность
=?iso-8859-1?q?this is some text?=
будет воспринята программой разборки RFC-822 как четыре атома, а не как один атом, или как ''кодировочное слово” (в случае программы разборки, воспринимающей кодировочные слова). Правильный способ закодировать строку "this is some text" – это кодировать и сами пробелы, например:
=?iso-8859-1?q?this=20is=20some=20text?=
3. Символьный набор
Секция 'charset' кодировочного слова специфицирует символьный набор, соответствующий незакодированному тексту. 'charset' может представлять любой символьный набор, разрешенный параметром "charset" MIME части тела "text/plain", или любой символьный набор с именем, зарегистрированным IANA для использования с типом содержимого text/plain MIME.
Некоторые символьные наборы используют технику переключения кодов для перехода между режимом "ASCII" и другими режимами. Если текст в кодировочном слове содержит последовательность, которая заставляет интерпретатор символьного набора переключиться из режима ASCII, он должен содержать дополнительные управляющие коды, которые переключат систему в ASCII-режим в конце кодировочного слова.
Когда имеется возможность использования более одного символьного набора для представления текста в кодировочном слове и в отсутствии частного соглашения между отправителем и получателем сообщения, рекомендуется, чтобы предпочтительно использовались члены символьного семейства ISO-8859-*.
4. Кодирование
Первоначально легальными значениями кодирования являются "Q" и "B". Эти кодировки описаны ниже. Кодирование "Q" рекомендуется для использования, когда большинство символов, которые нужно преобразовать, представлены в наборе ASCII; в противном случае, следует использовать "B"-кодирование. Несмортя ни на что программа, читающая почту, которая воспринимает кодировочные слова, должна быть способна обрабатывать любые кодировки для любых символьных наборов, которые она поддерживает.
В кодированном тексте может использоваться только субнабор печатных ASCII-символов. Символы SP и HT не допустимы, чтобы начало и конец кодировочного слова были выделены однозначно. Символ "?" используется в “кодировочном слове” для разделения различных частей этого слова друг от друга. По этой причине "?" не может появляться в секциях “кодировочного слова”. Другие символы могут также оказаться нелегальными в определенном контексте. Например, 'encoded-word' во 'фразе', предшествующей адресу в поле заголовка From не может содержать какие-либо специальные символы ("specials"), определенные в RFC-822. Наконец, некоторые другие символы также недопустимы в определенных контекстах, это связано с необходимостью обеспечить надежность пересылки сообщений через почтовые шлюзы.
"B"-кодирование автоматически отвечает этим требованиям. "Q"-кодирование допускает использование широкого перечня печатных символов в некритических позициях заголовка сообщения (например, в Subject), с ограниченным списком символов, допустимых в других полях.
4.1. "B"-кодирование
"B"-кодирование идентично "BASE64", описанному RFC-2045.
4.2. "Q"-кодирование
"Q"- кодирование подобно закавыченным строкам печатных символов ("Quoted-Printable"), описанным в RFC-2045. Оно создано, для того чтобы позволить читать текст, содержащему по большей части ASCII-символы, а алфавитно-цифровом терминале без декодирования.
| (1) | Любой 8-битовый код может быть представлен с помощью символа "=", за которым следуют два шестнадцатеричных числа. Например, если бы используемый символьный набор был ISO-8859-1, символ "=" кодировался как "=3D", а пробел (SP) как "=20". (Для шестнадцатеричных чисел следует использовать верхний регистр "A" - "F".) |
| (2) | 8-битовое шестнадцатеричное число 20 (напр., ISO-8859-1 SPACE) может быть представлено как "_" (знак подчеркивания, ASCII 95.). (Этот символ может не пройти через некоторые почтовые шлюзы, но его использование существенно улучшает читаемость "Q"-кодированных данных в почтовых системах, которые поддерживают этот вид кодирования). Заметим, что "_" всегда представляется шестнадцатеричным кодом 20, даже если символ пробел (SPACE) занимает другую кодовую позицию в используемом символьном наборе. |
| (3) | 8-битовые значения, которые соответствуют печатным ASCII-символам, отличным от "=", "?" и "_", могут быть представлены самими собой. Об ограничениях см. раздел 5. В частности, SP и HT не должны представляться самими собой в пределах кодировочных слов. |
5. Использование кодировочных слов в заголовках сообщений
'encoded-word' может появиться в заголовке сообщения или в заголовке тела секции в соответствии со следующими правилами:
| (1) | 'encoded-word' может заменить текстовую лексему (как это определено в RFC-822) в любом из полей заголовка Subject или Comments, в любом поле расширения заголовка, или любом поле секции тела MIME, для которого поле тела определено как '*text'. 'encoded-word' может также появиться в любом поле сообщения или секции тела, определенном пользователем ("X-"). Обычный ASCII-текст и 'кодировочные слова' могут появляться совместно в пределах одного и того же поля заголовка. Однако 'кодировочное слово', появляющееся в поле заголовка, определенное как '*text', должно быть отделено от любого смежного 'encoded-word' или 'текста' с помощью LWS (HT|SP|CRLF). |
| (2) | 'encoded-word' может появляться внутри 'комментария', ограниченного "(" и ")", т.е., там, где допустим 'ctext'. Более точно, ABNF-определение (RFC-822) для 'comment' следует скорректировать как: |
/p> comment = "(" *(ctext | quoted-pair | comment | encoded-word) ")"
"Q"-кодированное 'encoded-word', которое появляется в комментарии не должно содержать символов "(", ")" или ". 'Кодировочное слово', появляющееся в комментарии должно отделяться от смежного 'encoded-word' или 'ctext' с помощью LWS.
Важно заметить, что комментарии распознаются только внутри структурированных полей тела. В полях, чьи тела определены как '*text', "(" и ")" обрабатываются как обычные символы, а не как разделители комментариев, и применимо правило (1) этой секции. (См. RFC-822, секции 3.1.2 и 3.1.3)
| (3) |
В качестве замены для объекта 'word' во 'фразе', например, перед адресом в заголовке From, To или Cc. ABNF-определение для 'phrase' RFC-822 приобретает вид: phrase = 1*( encoded-word / word) |
+ 'encoded-word' не должно появляться в любой части 'addr-spec'.
+ 'encoded-word' не должно появляться в пределах 'quoted-string'.
+ 'encoded-word' не должно использоваться в поле заголовка Received.
+ 'encoded-word' не должно использоваться в параметре MIME поля Content-Type или Content-Disposition, или в любом структурированном поле тела, за исключением 'comment' или 'phrase'.
'Кодированный текст' не должен продолжаться от одного 'encoded-word' к другому. Это предполагает, что секция кодированного текста 'B-encoded-word' будет иметь длину кратную 4 символам; для 'Q-encoded-word', за любым символом "=", который появляется в секции кодированного текста, следуют две шестнадцатеричные цифры.
Каждое 'encoded-word' должно кодировать полное число октетов. 'Кодированный текст' в каждом 'encoded-word' должен быть хорошо оформлен согласно специфицированному кодированию. 'Кодированный текст' не может продолжаться в следующем 'encoded-word'. (Например, "=?charset?Q?=?= =?charset?Q?AB?=" было бы нелегальным, так как два шестнадцатеричные числа "AB" должны следовать за "=" в одном и том же 'encoded-word'.)
Каждое 'encoded-word' представлять собой целое число символов. Многооктетные символы не могут расщепляться между смежными 'кодировочными словами'.
Согласно этой схеме кодируются только печатные символы и WS (HT и SP). Однако так как эти схемы кодирования позволяют работать с произвольными октетами, программы чтения почты, которые используют такое декодирование, должны быть избавлены от любых нежелательных побочных эффектов при отображении данных на терминале получателя.
Использование этих методов для кодирования нетекстовых данных (напр., изображения или голоса) в данном документе не определено. Применение 'кодировочных слов' для представления строк ASCII-символов допустимо, но не рекомендуется.
6. Поддержка 'кодировочных слов' в программах чтения почты
6.1. Распознавание 'кодировочных слов' в заголовках сообщений
Программа чтения почты должна осуществлять разбор сообщения и заголовков секций согласно правилам RFC-822, для того чтобы правильно распознать 'кодировочные слова'.
'кодировочные слова' должны распознаваться как:
| (1) | Поле заголовка любого сообщения или части тела, определенное как '*text', или любое поле заголовка, определенное пользователем, должно разбираться следующим образом: Начало обозначается LWS (HR|SP|CRLF), любая последовательность вплоть до 75 печатных символов (не содержащая LWS) должна рассматриваться как кандидат в 'кодировочные слова' и проверяться на соблюдение правил синтаксиса, описанных в секции 2 данного раздела. Любую другую последовательность печатных символов следует рассматривать как обычный ASCII-текст. |
| (2) | Любое поле заголовка, не определенное как '*text' должно разбираться согласно синтаксическим правилам для данного поля заголовка. Однако любое 'слово', которое появляется в пределах 'фразы' должно обрабатываться как 'кодировочное слово', если оно отвечает синтаксическим правилам секции 2. В противном случае оно должно обрабатываться как обычное 'слово'. |
| (3) | Внутри 'комментария', любая последовательность с длиной до 75 символов (не содержащая LWS), которая отвечает синтаксическим правилам секции 2, должна обрабатываться как 'кодировочное слово'. В противном случае оно должно обрабатываться как обычный текст комментария. |
| (4) | Поле заголовка MIME-Version может отсутствовать в 'кодировочных словах', которые обрабатываются согласно данной спецификации. Причиной этого является то, что программа чтения почты не предполагает разбирать весь заголовок сообщения, прежде чем отображать строки, которые могут содержать 'кодировочные слова'. |
/p>
6.2. Отображение кодированных слов
Любые распознанные ' кодированные слова' декодируются и, если возможно, полученный в результате текст отображается с использованием стандартного символьного набора.
Декодирование и отображение закодированных слов происходит, после того как структурные поля тела будут разобраны на лексемы. Следовательно, возможно спрятать 'специальные' символы в 'кодировочных словах', которые при отображении будут неотличимы от 'специальных' символов окружающего текста. По этой и другим причинам вообще невозможно транслировать заголовок сообщения, содержащий 'кодировочные слова', к виду, который может анализироваться программой чтения почты (RFC-822).
При отображении конкретного поля заголовка, который содержит несколько 'кодировочных слов', любой LWS, который разделяет пару смежных 'кодировочных слов', игнорируется.
В случае определения в будущем другого кодирования, которое почтовая программа не поддерживает, она может отобразить 'кодировочное слово', как обычный текст или выдать сообщение, что текст не может быть декодирован.
Если почтовая программа не поддерживает использованный символьный набор, она может отобразить 'кодировочное слово', как обычный текст (т.е., так как оно записано в заголовке), может попробовать отобразить его с использованием имеющегося символьного набора, или выдать сообщение, что текст не может быть отображен.
Если используемый символьный набор реализует технику кодового переключения, отображение кодированного текста начинается в режиме "ASCII". Кроме того, почтовая программа должна проверить, что выходное устройство снова в режиме "ASCII", после того как отображено 'кодировочное слово'.
6.3. Обработка почтовой программой некорректно сформированных 'кодировочных слов'
Возможно, что 'кодировочное слово', которое легально согласно синтаксическим правилам секции 2, не корректно сформировано с точки зрения регламентаций использованного правила кодирования. Например:
| (1) | 'Кодировочное слово', которое содержит символы нелегальные для конкретного кодирования (Например, "-" в "B"-кодировании, или SP и HT в "B"- или "Q"-кодировании), является некорректно сформированным. |
| (2) | Любое 'кодировочное слово', которое кодирует нецелое число символов или октетов является некорректно сформированным. |
/p> Программа чтения почты не должна пытаться отобразить текст, ассоциированный с 'кодировочным словом', которое сформировано некорректно. Однако программа чтения почты не должна препятствовать отображению или обработке сообщения из-за того, что 'кодировочное слово' некорректно сформировано.
7. Согласование
Программа, формирующая почтовое сообщение и соответствующая данной спецификации, должна гарантировать, что любая строка печатных ASCII-символов, не содержащая HT и SP в пределах '*text' или '*ctext', начинается с "=?" и завершается "?=" является корректным 'кодировочным словом'. ("Начинается" означает: в начале тела сразу после LWS, или сразу после "(" для 'кодировочного слова' в пределах '*ctext'; "завершается" означает: в конце тела, непосредственно перед LWS, или непосредственно перед ")" для 'кодировочного слова' в '*ctext'.) Кроме того, любое 'слово' в 'фразе', которое начинается с "=?" и завершается "?=" должно быть корректным 'кодировочным словом'.
Программа, читающая почтовые сообщения, совместимые с данной спецификацией должна быть способна отделить 'кодировочное слово' от 'text', 'ctext', или 'слов', которые согласуются с правилами секции 6, где бы они не встретились в заголовке сообщения. Она должна поддерживать "B"- и "Q"-кодирование для любых символьных наборов, которые она поддерживает. Программа должна быть способна отобразить не кодированный текст, если символьный набор соответствует "US-ASCII". Для символьных наборов ISO-8859-*, программа должна быть способна, по крайней мере, отобразить символы, которые совпадают с ASCII.
8. Примеры
Ниже приведены примеры заголовок сообщений, содержащих 'кодировочные слова':
From: =?US-ASCII?Q?Keith_Moore?=
To: =?ISO-8859-1?Q?Keld_J=F8rn_Simonsen?=
CC: =?ISO-8859-1?Q?Andr=E9?= Pirard
Subject: =?ISO-8859-1?B?SWYgeW91IGNhbiByZWFkIHRoaXMgeW8=?=
=?ISO-8859-2?B?dSB1bmRlcnN0YW5kIHRoZSBleGFtcGxlLg==?=
В выше приведенном примере в 'кодировочном слове' поля, последний символ "=" в конце кодированного текста необходим, так как каждое 'кодировочное слово' должно быть самодостаточным (символ "=" завершает группу из 4 символов base64 представляющих 2 октета). Дополнительный октет может быть закодирован в первом 'кодировочном слове' (так чтобы 'кодировочное слово' содержало число октетов кратное трем). Второе 'кодировочное слово' использует символьный набор, не совпадающий с тем, что применен в первом слове.
From: =?ISO-8859-1?Q?Olle_J=E4rnefors?=
To: ietf-822@dimacs.rutgers.edu, ojarnef@admin.kth.se
>Subject: Time for ISO 10646?
To: Dave Crocker
Cc: ietf-822@dimacs.rutgers.edu, paf@comsol.se
From: =?ISO-8859-1?Q?Patrik_F=E4ltstr=F6m?=
Subject: Re: RFC-HDR care and feeding
From: Nathaniel Borenstein
(=?iso-8859-8?b?7eXs+SDv4SDp7Oj08A==?=)
To: Greg Vaudreuil , Ned Freed
, Keith Moore
Subject: Test of new header generator
MIME-Version: 1.0
Content-type: text/plain; charset=ISO-8859-1
Правила несколько отличаются для полей, определенных как '*text' так как "(" и ")" не распознаются в качестве разделителей комментария. [Секция 5, параграф (1)].
В каждом из следующих примеров, если бы одна и та же последовательность встретилась в поле '*text', форма "Отображается как" не рассматривалась бы как кодировочные слова, а была бы идентична форме "Кодированное представление". Это происходит, потому что каждое из 'кодировочных слов' в ниже приведенных примерах соседствуют с символами "(" или ")".
Отображается как
(=?ISO-8859-1?Q?a?=)
(a)
(=?ISO-8859-1?Q?a?= b)
(a b)
В пределах 'комментария', HT или SP должны появляться между 'кодировочным словом' и окружающим текстом. [Секция 5, параграф (2)]. Однако HT или SP не нужны между начальным символом "(", который открывает 'комментарий', и 'кодировочным словом'.
| (=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) | (ab) |
| (=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) | (ab) |
|
(=?ISO-8859-1?Q?a?= =?ISO-8859-1?Q?b?=) |
(ab) |
| (=?ISO-8859-1?Q?a_b?=) | (a b) |
| (=?ISO-8859-1?Q?a?= =?ISO-8859-2?Q?_b?=) | (a b) |
/p> Для того чтобы пробел был отображен между двумя строками кодированного текста, SP может быть закодирован как составная часть одного из 'кодировочных слов'.
9. Ссылки
| [RFC-822] | Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC-822, UDEL, August 1982. |
| [RFC-2049] | Borenstein, N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples", RFC 2049, November 1996. |
| [RFC-2045] | Borenstein, N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC-2045, November 1996. |
| [RFC-2046] | Borenstein N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC 2046, November 1996. |
| [RFC-2048] | Freed, N., Klensin, J., and J. Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: Registration Procedures", RFC 2048, November 1996. |
IV. Процедуры регистрации
1. Введение
Современные протоколы Интернет с самого начала создавались таким образом, чтобы их было легко расширить или модернизировать. В частности, MIME [RFC-2045] является открытой системой, допускающей введение новых типов объектов, символьных наборов и методов доступа без изменения базового протокола. Однако необходим процесс регистрации, чтобы гарантировать, что набор таких значений соответствует стандарту и может использоваться в общедоступных сетях.
Здесь рассматриваются процедуры регистрации, которые осуществляются через IANA (Internet Assigned Numbers Authority), центральной инстанции для решения этих проблем.
Процесс регистрации для типов среды был первоначально определен в контексте асинхронной почтовой среды Интернет. В этой почтовой среде существует необходимость ограничить число возможных типов среды, чтобы увеличить вероятность успешного взаимодействия с удаленной почтовой системой, когда ее возможности заранее не известны.
2. Регистрация типа среды
Регистрация нового типа среды начинается с формирования регистрационного предложения. Регистрация может произойти в рамках различных регистрационных схем (деревьев), которые предполагают различные требования. Вообще, новое регистрационное предложение оценивается и рассматривается в зависимости от используемой схемы (дерева). Тип среды затем регистрируется, если предложение оказывается приемлемым.
2.1. Деревья регистрации и имена субтипов
Для того чтобы увеличить эффективность и гибкость процесса регистрации различные структуры субтипов имен могут быть зарегистрированы так, чтобы удовлетворить различным естественным требованиям, например, субтип, который будет рекомендованa для широкого использования сообществом Интернет или субтип, который используется для переноса файлов, ассоциированных с некоторой частной программой. Последующие субсекции данного документа определяют регистрационные "деревья", отличающиеся использованием стандартной формы имен (например, имен вида "tree.subtree...type"). Заметим, что некоторые типы среды определены до появления данного документа и их имена не согласуются с данной схемой. Смотри приложение A, где рассматривается эта проблема.
2.1.1. IETF-дерево
Дерево IETF служит для типов, представляющих общий интерес для сообщества Интернет. Регистрация в IETF требует одобрения IESG и публикации данного типа среды в каком-то документе RFC.
Типы среды в IETF-дереве обычно обозначаются именами, которые не оформлены стандартным образом, т.е., не содержат символов точка (".", полный останов).
"Хозяином" регистрации типа среды в рамках дерева IETF предполагается сама группа IETF. Модификации или изменения спецификации требуют той же процедуры, что и регистрация.
2.1.2. Дерево производителя (Vendor Tree)
Дерево производителя используется для типов среды, соответствующих определенным коммерческим продуктам.
Результат регистрации может быть ассоциирован с деревом производителя тем, кто нуждается в замене файлов, сопряженных с определенным программным продуктом. Однако регистрация формально принадлежит производителю или организации, разработавшей программу или формат.
Регистрация в рамках дерева производителя выделяется с помощью префикса имени "vnd.". Далее может следовать имя известного производителя (например, "vnd.lapot"), адрес производителя или место расположения программы, заключительная секция имени может содержать наименование типа среды (например, vnd.bigcompany.funnypictures).
2.1.3. Частное дерево
Регистрация типов среды, созданных с экспериментальными целями, могут быть зарегистрированы в рамках частного дерева. Регистрация такого вида имеет префикс имени "prs.". Хозяином "частной" регистрации и соответствующих спецификаций является человек или объект, осуществивший регистрацию. Публикация частных типов среды не требуется.
2.1.4. Специальное `x.'-дерево
Для удобства и симметрии со схемой регистрации имена типов среды, начинающиеся с "x." могут использоваться для тех же целей, что и имена, начинающиеся с "x-". Эти типы не являются зарегистрированными и могут использоваться партнерами при взаимном согласии.
Однако при упрощенной процедуре регистрации, описанной выше для частных типов и типов среды производителей трудно себе представить ситуацию, когда бы возникла необходимость использования незарегистрированных типов среды.
2.1.5. Дополнительные регистрационные деревья
От случая к случаю как этого требует сообщество, IANA может по согласованию с IESG, создать новое регистрационное дерево верхнего уровня. Предполагается, что такие деревья могут быть созданы для внешней регистрации и управления, например научными сообществами для их внутреннего использования. Вообще, качество рассмотрения спецификаций для этих деревьев регистрации должно быть столь же тщательным, как и в случае IETF. О создании этих новых деревьев уведомляет публикация RFC, одобренная IESG.
2.2. Требования регистрации
Предложения регистрации среды должны соответствовать требованиям изложенным ниже в последующих разделах. Заметим, что требования могут иной раз зависеть от дерева регистрации.
2.2.1. Требования функциональности
Типы среды должны функционировать как настоящий формат среды. Регистрация вещей, которые относятся в большей мере к транспортному кодированию, выбору символьного набора не допускается. Например, хотя существуют приложения, которые осуществляют транспортное декодирование base64 [RFC-2045], base64 не может быть зарегистрировано в качестве типа среды. Это требование не зависит от используемого регистрационного дерева.
2.2.2. Требования к именам
Всем зарегистрированным типам среды должны быть присвоены имена типов и субтипов MIME. Комбинация этих имен служит в дальнейшем для идентификации типа среды и формата субтипа.
При выборе имени типа верхнего уровня должна учитываться природа типа среды. Например, среда, используемая для представления статической картинки должна быть субтипом типа изображение, в то время как среда, способная представлять звуковую информацию должна принадлежать аудио типу. Для получения дополнительной информации смотри RFC-2046.
Новые субтипы типов верхнего уровня должны соответствовать регламентациям этого уровня. Например, все субтипы типа составных данных должны использовать один и тот же синтаксис инкапсуляции.
В некоторых случаях новый субтип среды может не вполне согласовываться с определенным на текущий момент типом содержимого верхнего уровня. Если такое произошло, следует определить новый тип верхнего уровня, который бы согласовывался с данным субтипом. Такое определение должно быть выполнено согласно стандартной процедуре и опубликовано в RFC. Это требование не зависит от используемого регистрационного дерева.
2.2.3. Требования к параметрам
Типы среды могут использовать один или более параметров MIME, некоторые параметры могут оказаться автоматически доступными для типа среды в случае, когда они применимы ко всему семейству субтипов. В любом случае имена, величины и назначение любого параметра должны быть полностью специфицированы при регистрации типа среды в рамках дерева IETF. Они должны быть специфицированы как можно полнее, когда тип среды регистрируется в рамках частного дерева или дерева производителя.
Новые параметры не могут определяться с целью расширения функциональности для типов, зарегистрированных в рамках дерева IETF. Но новые параметры могут быть добавлены для передачи дополнительной информации, которая не изменяет существующую функциональность.
2.2.4. Требования к канонизации и формату
Все зарегистрированные типы среды должны использовать один канонический формат данных вне зависимости от дерева регистрации. Спецификация формата каждого типа среды необходима для всех типов зарегистрированных для дерева IETF, эта информация должна присутствовать и в предложении для регистрации типа среды. Спецификации формата и особенностей обработки могут быть, а могут и не быть общедоступны для типов среды, зарегистрированных для дерева производителя. В предложения регистрации такого вида включаются только спецификации программы и ее версии пригодной для работы с данным типом среды. Включение спецификаций формата или ссылки на них в предложение регистрации желательно, но не обязательно.
Спецификации формата необходимы для регистрации в рамках частного дерева, они могут быть опубликованы в RFC или помещены в депозитарий IANA. Спецификации, помещаемые в депозитарий должны отвечать тем же требованиям, что и регистрируемые.
Некоторые типы среды включают в себя патентованные технологии. Регистрация типа среды, включающего в себя патентованные технологии, также разрешена. Однако устанавливаются ограничения (RFC-1602) на применение патентованных технологий в рамках стандартных протоколов.
2.2.5. Рекомендации по взаимозаменяемости
Типы среды должны быть способны работать с максимально возможным числом систем и приложений. Однако некоторые типы среды неизбежно будут иметь проблемы при работе на некоторых платформах. Могут возникнуть трудности из-за различных версий, порядка байт, специфики работы шлюза и т.д.
Способность работы с любыми типами среды не требуется, но желательно, чтобы были четко описаны границы применимости. Публикация типа среды не предполагает исчерпывающего обзора возможностей работы с различными платформами и приложениями.
2.2.6. Требования к безопасности
Рассмотрение аспектов безопасности необходимо для всех типов, регистрируемых в рамках IETF-дерева. Аналогичный анализ для типов среды регистрируемых в рамках частного дерева или дерева производителя рекомендуется, но не является обязательным. Однако вне зависимости от того что анализ безопасности мог проводиться или нет, все описания соображений по безопасности должны быть выполнены крайне аккуратно вне зависимости от дерева регистрации. В частности, заявление, что "никакие соображения безопасности не сопряжены с этим типом" не следует путать с "безопасность сопряженная с данным типом не анализировалась и не оценивалась".
Не существует требования, чтобы регистрируемые типы среды были безопасны и не несли в себе каких либо рисков. Несмотря на это, все известные риски должны быть идентифицированы при регистрации типа вне зависимости от используемого дерева.
Секция безопасности подлежит дальнейшему развитию. Некоторые аспекты, которые следует учитывать при анализе безопасности типа среды, перечислены ниже.
| (1) | Комплексные типы среды могут включать в себя директивы, которые определяют действия над файлами или другими ресурсами получателя. Во многих случаях для отправителя перечисляются действия, которые могут вызвать разрушительные последствия. Смотри регистрацию типа среды application/postscript в RFC-2046 в качестве примера таких директив. |
| (2) | Сложные типы среды могут включать директивы, определяющие действия, которые сами по себе безвредны для получателя, но могут вызвать раскрытие конфиденциальных данных или упростить последующие атаки или нарушить конфиденциальность для получателя каким-либо способом. Регистрация типа среды application/postscript иллюстрирует, как следует обрабатывать такие директивы. |
| (3) | Тип среды могут быть ориентированы на применения, которые требуют определенного уровня безопасности, но не предоставляют самих механизмов безопасности. Например, тип среды может быть предназначен для запоминания конфиденциальной медицинской информации, которая в свою очередь требует внешней системы обеспечения секретности. |
/p> В асинхронных почтовых системах, где информация о возможностях удаленного почтового агента часто не доступна для отправителя, максимум взаимодействия может быть достигнут путем ограничения числа типов среды, используемых для общих форматов, которые предполагается широко внедрять. Именно эта концепция, принятая в прошлом, явилась причиной ограничения числа возможных типов среды и привела к формированию процесса регистрации типов среды.
Однако необходимость в "общих" типах среды не требует ограничения регистрации новых типов. Если для определенного приложения рекомендуется ограниченный набор типов среды, это должно быть определено отдельным заявлением применимости для приложения или среды реализации.
2.2.7. Требования к публикации
Предложения для типов среды регистрируемых в рамках IETF-дерева должны публиковаться в виде RFC. RFC-публикации типа среды производителя или частного типа среды желательны, но не обязательны. Во всех случаях IANA сохраняет копии всех предложений по типам среды и публикует их как часть самого регистрационного дерева типов среды.
Дерево IETF существует для типов среды, которые действительно требуют серьезного анализа и стандартного процесса одобрения, в то время как деревья производителей и частные деревья такой процедуры не требуют. Ожидается, что заявления о применимости для конкретных приложений будут публиковаться время от времени для типов среды, которые доказали свою эффективность в определенных контекстах.
Как было обсуждено выше, регистрация типа среды верхнего уровня предполагает стандартную процедуру принятия и, следовательно, обязательную RFC-публикацию.
2.2.8. Дополнительная информация
Различные виды опционной информации могут быть включены в спецификацию типа среды, если таковые имеются:
| (1) | Магические числа (длина, значения октетов). Магические числа представляют собой байтовые последовательности, которые всегда имеются и по этой причине могут использоваться для идентификации объектов, принадлежащих данному типу среды. |
| (2) | Расширения имени файлов, используемые на одной или более платформах для индикации того, что файл содержит данный тип среды. |
| (3) | Код типа файла Macintosh (4 октета) используется для маркировки файлов, содержащих данный тип среды. |
/p> Такая информация часто оказывается весьма полезной и, если имеется, то должна предоставляться.
2.3. Процедура регистрации
Следующая процедура была применена IANA для обзора и одобрения новых типов среды. Для регистрации в рамках дерева IETF, нужно следовать обычной процедуре, осуществляя на первом этапе рассылку интернет-проекта. Для регистрации в рамках частного дерева или дерева производителя осуществляется без широкого обсуждения. Проект непосредственно направляется IANA (по адресу iana@iana.org).
2.3.1. Представление типа среды на суд сообщества
Все начинается с посылки предложения регистрации типа среды лист-серверу ietf-types@iana.org. Отклики ожидаются в течение двух недель. Этот подписной лист был учрежден для целей обсуждения предлагаемых типов среды и доступа. Предложенные типы среды, если они формально не зарегистрированы, не могут быть использованы; префикс "x-", специфицированный в RFC-2045, может применяться до тех пор, пока процесс регистрации не завершится.
Типы среды, регистрируемые в рамках дерева IETF должны представляться на одобрение IESG.
Получив подтверждение, что тип среды отвечает всем требованиям, автор может послать запрос регистрации IANA, которая зарегистрирует тип среды и сделает его доступным для всего сообщества.
2.4. Комментарии по поводу регистрации типа среды
Комментарии по поводу регистрации типа среды могут быть направлены членам сообщества IANA. Эти комментарии будут переданы "хозяину" типа среды. Комментаторы могут потребовать, чтобы их замечания были присовокуплены к материалам регистрации данного типа среды и, если IANA одобрит это, такая процедура будет произведена.
2.5. Расположение списка зарегистрированных типов среды
Материалы регистрации типа среды доступны через анонимный FTP сервер ftp://ftp.isi.edu/in-notes/iana/assignments/media-types/, а все зарегистрированные типы среды будут перечислены в периодически обновляемом документе "Assigned Numbers" RFC [в настоящее время STD-2, RFC-1700]. Описания типа среды и другие материалы могут быть также опубликованы в виде информационных RFC путем посылки документа по адресу "rfc-editor@isi.edu" [RFC-1543].
2.6. Процедура регистрации типа среды в IANA
IANA регистрирует типы среды, принадлежащие дереву IETF. Частные типы и типы среды производителя регистрируются IANA автоматически и без формального обсуждения, если выполнены следующие условия:
| (1) | Типы среды должен функционировать как истинный формат среды. В частности, символьный набор или транспортное кодирование не могут быть зарегистрированы в качестве типа среды. |
| (2) | Все типы среды должны иметь корректно сформированные имена типа и субтипов. Все имена типов должны быть определены стандартным образом. Все имена субтипов должны быть уникальными, должны соответствовать грамматике MIME и содержать корректный префикс дерева. |
| (3) | Типы, регистрируемые в рамках частного дерева, должны быть снабжены спецификацией формата, или указателем на такую спецификацию. |
| (4) | Любые соображения по безопасности должны отражать объективную ситуацию и быть корректными. IANA не проводит экспертизу, но откровенно некомпетентные материалы отбрасываются. |
2.7. Управление изменением
Раз тип среды опубликован IANA, автор может потребовать изменения его описания. Запрос изменения оформляется также как и сама регистрация:
Рассылка пересмотренной заявки регистрации через подписной лист ietftypes.
(2)
Ожидание в течение двух недель комментариев.
(3)
Публикация после формального обсуждения IANA, если это необходимо.
Изменения следует делать лишь при обнаружении серьезных упущений или ошибок в опубликованной спецификации.
Владелец типа содержимого может передать ответственность за него другому лицу или организации, проинформировав об этом IANA и список рассылки ietf-типов. Это может быть сделано без обсуждения.
IESG может переадресовать ответственность за определенный тип среды. Наиболее общим случаем является разрешение изменений в описании типа среды в ситуации, когда автор исходного документа умер, эмигрировал или стал недоступен и не может внести изменения крайне важные для сообщества пользователей.
Регистрации типа среды не могут быть аннулированы. Типы среды, которые не используются более, объявляются устаревшими (OBSOLETE) путем изменения их поля "intended use" (область применения). Такие типы среды будет помечены соответствующим образом и в списках, публикуемых IANA.
2.8. Регистрационный шаблон
To: ietf-types@iana.org
Subject: Registration of MIME media type XXX/YYY(Регистрация типа среды MIME)
| MIME media type name: | (Имя типа среды MIME) |
| MIME subtype name: | (Имя субтипа среды MIME) |
| Required parameters: | (Необходимые параметры) |
| Optional parameters: | (Опционные параметры) |
| Encoding considerations: | (Соображения по кодированию) |
| Security considerations: | (Соображения безопасности) |
| Interoperability considerations: | (Соображения совместимости) |
| Published specification: | (Опубликованная спецификация) |
| Applications which use this media type: | (Приложения, использующие данный тип среды) |
| Additional information: | (Дополнительная информация) |
| Magic number(s): | (Магические числа) |
| File extension(s): | (Расширение имени файла) |
| Macintosh File Type Code(s): | (Код типа файла Macintosh) |
|
Person & email address to contact for further information: |
(Контактный адрес) |
|
Intended usage: (Одно из COMMON, LIMITED USE или OBSOLETE) |
(Возможное применение) |
| Author/Change controller: |
(Автор/ответственный) Сюда может быть добавлена любая другая информация на усмотрение автора. |
3. Типы доступа к внешнему телу
RFC-2046 определяет тип среды message/external-body, в рамках которой объект MIME может действовать, как указатель на реальное информационное тело сообщения. Каждый указатель message/external-body специфицирует тип доступа, который определяет механизм получения реального тела сообщения. RFC-2046 определяет исходный набор типов доступа, но допустимо описание нового механизма доступа в процессе регистрации нового типа среды.
3.1. Требования к регистрации
Спецификации нового типа доступа должны отвечать ряду требований, описанных ниже.
Каждый тип доступа должен иметь уникальное имя. Это имя появляется в параметре типа доступа в поле заголовка типа содержимого message/external-body, и должно соответствовать синтаксису параметров MIME.
Все протоколы транспортные средства и процедуры, используемые данным типом доступа, должны быть описаны в самой спецификации типа доступа или в какой-то другой общедоступной спецификации, достаточно подробно, чтобы этим мог воспользоваться квалифицированный программист. Использование секретных и/или частных методов доступа категорически запрещено. Ограничения, введенные документом RFC-1602 на стандартизацию патентованных алгоритмов, также должны быть учтены.
Все типы доступа должны быть описаны в RFC. RFC может быть информационным, а не обязательно описанием стандарта.
Любые соображения безопасности, которые возникают в связи с реализацией типа доступа, должны быть подробно описаны. Совсем не нужно, чтобы метод доступа был безопасным или лишенным рисков, но известные риски должны быть идентифицированы.
3.2. Процедура регистрации
Регистрация нового типа доступа начинается с создания проекта RFC. Далее осуществляется рассылка проекта через список подписки ietf-types@iana.org. Для получения откликов выделяется две недели. Этот подписной лист создан для целей обсуждения предлагаемых типов среды и доступа. Предлагаемые типы доступа не должны применяться до момента формальной регистрации.
Когда двухнедельный период истечет, ответственное лицо, назначенное региональным директором IETF, переадресует запрос iana@isi.edu, или отклоняет его из-за существенных возражений, высказанных в процессе обсуждения.
Решения принятые ответственным лицом IETF рассылаются всем через подписной лист IETF-types всем заинтересованным лицам в пределах двух недель. Это решение может быть обжаловано в IESG.
Утвержденная спецификация типа доступа должна быть опубликована в качестве документа RFC. Информационные RFC публикуются путем посылки их по адресу "rfc-editor@isi.edu".
3.3. Расположение списка зарегистрированных типов доступа
Зарегистрированные спецификации типа доступа доступны через анонимное FTP на сервере ftp://ftp.isi.edu/in-notes/iana/assignments/access-types/. Все зарегистрированные типы доступа включаются в перечень типов доступа, периодически публикуемый в документе "Assigned Numbers" RFC-1700.
4. Транспортное кодирование
Транспортное кодирование представляет собой преобразование, применяемое к типам среды MIME после конвертации в каноническую форму. Транспортное кодирование используется в нескольких целях.
| (1) | Многие виды транспорта, особенно пересылка сообщений, могут обрабатывать только данные, состоящие из относительно коротких строк текста. Существуют также строгие ограничения на то, какие символы могут использоваться в этих строках текста. Некоторые виды транспортировки допускают использование только субнабора US-ASCII, а другие не могут работать с некоторыми символьными последовательностями. Транспортное кодирование используется, для того чтобы преобразовать двоичные данные в текстовую форму. Примеры такого сорта транспортного кодирования включают применение base64 и закавыченных строк печатных символов, определенных в RFC-2045. |
| (2) | Изображение, аудио, видео и даже объекты приложений имеют иногда овольно большой размер. Алгоритмы сжатия часто весьма эффективны для сокращения объектов большого размера. Транспортное кодирование может использоваться также, для того чтобы с помощью универсальных алгоритмов сжатия без потерь сократить размер MIME-объектов. |
| (3) | Транспортное кодирование может быть определено, как средства представления существующих форматов кодирования в контексте MIME. |
/p> Стандартизация большого числа видов транспортного кодирования представляется серьезным барьером для обеспечения совместной работы различных узлов. Несмотря ни на что, определена процедура для обеспечения средств определения дополнительных транспортных кодировок.
4.1. Требования к транспортному кодированию
Спецификации транспортного кодирования должны отвечать определенному числу требований, описанных ниже.
Каждый тип транспортного кодирования должен иметь уникальное имя. Это имя записывается в поле заголовка Content-Transfer-Encoding и должно согласовываться с его синтаксисом.
Все алгоритмы, используемые при транспортном кодировании (напр. преобразование к печатному виду или сжатие) должны быть описаны в спецификациях транспортного кодирования. Использование секретных алгоритмов транспортного кодирования категорически запрещено. Ограничения, накладываемые документом RFC-1602 на стандартизацию патентованных алгоритмов должно непременно учитываться.
Все виды транспортного кодирования должны быть применимы для произвольной последовательности октетов, имеющей любую длину. Зависимость от конкретного входного формата не допускается.
Не существует требования, чтобы транспортное кодирование приводило к определенному выходному формату. Однако выходной формат каждого транспортного кодирования должен быть исчерпывающе документирован. В частности, каждая спецификация должна ясно объявить, являются ли выходные данные 7-битовыми, 8-битовыми или просто двоичными.
Все виды транспортного кодирования должны быть полностью инвертируемыми на любой платформе. Всегда должна иметься возможность преобразовать данные к исходному виду с помощью соответствующей декодирующей процедуры. Заметим, что эти требования исключают все виды сжатия с частичной потерей информации и все виды шифрования в качестве разновидностей транспортного кодирования.
Все виды транспортного кодирования должны предоставлять некоторый вид новых функциональных возможностей.
4.2. Процедура определения транспортного кодирования
Определение нового вида транспортного кодирования начинается с создания проекта стандартного документа RFC. RFC должен определить транспортное кодирование точно и исчерпывающе и предоставить необходимое обоснование введения этого вида кодирования. Эта спецификация должна быть представлена на рассмотрение IESG. IESG может
| (1) | отклонить спецификацию, как неприемлемую для стандартизации, |
| (2) | одобрить создание рабочей группы IETF для разработки спецификации, согласно действующей процедуре IETF, или |
| (3) | принять спецификацию, так как она есть, и поместить ее в перечень стандартов. |
4.3. Процедуры IANA для регистрации транспортного кодирования
Не существует необходимости для специальной процедуры регистрации транспортного кодирования IANA. Все стандартные транспортные виды кодирования должны быть оформлены в виде RFC, таким образом, ответственность по информированию IANA об одобрении нового вида транспортного кодирования лежит на IESG.
4.4. Размещение списка зарегистрированных видов транспортного кодирования
Регистрационные материалы по всем стандартизованным видам транспортного кодирования доступны через анонимное FTP на сервере
ftp://ftp.isi.edu/in-notes/iana/assignments/transfer-encodings/. Все зарегистрированные типы транспортного кодирования обязательно заносятся в списки документа "Assigned Numbers" [RFC-1700].
V. Критерии совместимости и примеры
Далее рассмотрено, какие части MIME должны поддерживаться MIME-совместимой программной реализацией.
1. Совместимость с MIME
Механизмы, описанные в данном разделе являются открытыми для дальнейшего расширения. Не предполагается, что все реализации будут поддерживать все существующие типы среды. Для того чтобы обеспечить наибольшую область применимости полезно определить концепцию "MIME-совместимости", которая позволит обмениваться сообщениями, содержащими данные в формате, отличном от US-ASCII.
Почтовый агент пользователя, совместимый с MIME должен:
| (1) | Всегда генерировать поле заголовка "MIME-Version: 1.0" в любом формируемом сообщении. |
| (2) |
Распознавать поле заголовка Content-Transfer-Encoding и декодировать все получаемые данные, кодированные в формате закавыченных последовательностей печатных символов или в base64. Должна идентифицироваться также форма преобразования (7-бит, 8-бит или двоичная). Любые не 7-битовые данные, посланные без кодирования, должны быть соответствующим образом помечены в поле content-transfer-encoding как 8-битовые или двоичные в зависимости от реального формата. Если транспортная система не поддерживает 8-битовый или двоичный формат (как, например, SMTP [RFC-821]), отправитель должен выполнить кодирование и пометить данные, как закодированные в формате base64 или закавыченных последовательностей печатных символов. |
| (3) | Должен обрабатывать любые нераспознанные транспортные кодирования как тип содержимого "application/octet-stream", вне зависимости от того, распознан или нет действительный тип содержимого. |
| (4) | Распознавать и интерпретировать поле заголовка Content-Type, и избегать отображения исходных данных со значением поля Content-Type, отличным от text. Реализации должны быть способны посылать, по крайней мере, сообщения text/plain, с символьным набором, специфицированным с помощью параметра charset, если это не US-ASCII. |
| (5) | Игнорировать любые параметры типа содержимого с не распознанными именами. |
| (6) | Работать с ниже приведенными значениями типов среды. |
/p> Текст:
| - | Распознавать и отображать "текст" почтового сообщения с символьным набором "US-ASCII." |
| - | Распознавать другие символьные наборы, по крайней мере, на таком уровне, чтобы информировать пользователя о том, какой символьный набор использован. |
| - | Распознавать символьные наборы "ISO-8859-*" на таком уровне, чтобы быть способным отобразить те символы, которые являются общими для ISO-8859-* и US-ASCII, то есть все символы с кодами в диапазоне 1-127. |
| - | Для нераспознанных субтипов в рамках известного символьного набора показать или предложить показать версию исходных данных после преобразования содержимого из канонической формы в локальную. |
| - | Обрабатывать материал с неизвестным символьным набором так, как если бы это был "application/octet-stream". |
| - | На минимальном уровне предоставить возможность обрабатывать любой не узнанный субтип, как если бы он был "application/octet-stream". |
| - | Предложить возможность удаления кодирования base64 или закавыченных последовательностей печатных символов, определенных в данном документе, если они были применены, и положить результат в файл пользователя. |
| - | Распознается составной субтип. Отображает всю информацию на уровне сообщения и на уровне заголовка тела, а затем отображает или предлагает отобразить каждую из составляющих частей индивидуально. |
| - | Распознается cубтип "alternative", и исключается отображение лишних частей сообщения multipart/alternative. |
| - | Распознается субтип "multipart/digest", используя формат "message/RFC-822" а не "text/plain" в качестве типа среды по умолчанию для частей тела внутри объектов "multipart/digest". |
| - | Любые не узнанные субтипы обрабатываются, как если бы они были типа "mixed". |
| - | Распознаются и отображаются, по крайней мере, инкапсулированные данные сообщения RFC-822 (message/RFC-822) таким образом, чтобы сохранить любую рекурсивную структуру, то есть, отображая или предлагая отобразить инкапсулированные данные с учетом типа среды. |
| - | Любые не распознанные субтипы обрабатывается как если бы они имели тип "application/octet-stream". |
/p>
| (7) | При встрече нераспознанного поля Content-Type, программная реализация должна воспринимать ее как если бы она имела тип "application/octet-stream" без каких либо параметров субаргументов. Как обрабатывать эти данные зависит исключительно от конкретной реализации, но желательны опции, предлагающие пользователю после декодирования транспортного формата записать данные в файл или предложить пользователю ввести имя файла, который преобразует содержимое в приемлемый формат. |
| (8) |
Нужны адаптирующиеся агенты пользователя, если они предоставляют нестандартную поддержку для сообщений, не следующих протоколу MIME, и использующих символьный набор отличный от US-ASCII. Адаптирующиеся агенты пользователя не должны посылать сообщения, которые не следуют протоколу MIME и в то же время содержат текст отличный от US-ASCII. В частности, использование текста не US-ASCII в почтовом сообщении без поля MIME-Version категорически не рекомендуется, так как это уменьшает коммуникационные возможности. Адаптирующиеся агенты пользователя должны содержать корректные метки MIME при посылке чего-либо отличного от чистого текста с символьным набором US-ASCII. Кроме того, агенты пользователя, не поддерживающие MIME, должны модифицироваться, если это возможно, чтобы включить соответствующую информацию заголовка MIME в отправляемое сообщение, даже если ничего более из протокола MIME не поддерживается. Эта модификация произведет малое, если вообще какое-либо влияние на получателей, не поддерживающих MIME, но поможет MIME корректно отобразить текст сообщения. |
| (9) | Адаптирующиеся агенты пользователя должны гарантировать, что любая строка печатных US-ASCII-символов (без WS) в пределах "*text" или "*ctext", которая начинается с "=?" и завершается "?=", является корректным кодировочным словом. Слово "начинается" здесь означает - в начале поля тела или сразу после LWS, а "завершается" означает - в конце поля-тела или сразу перед LWS. Кроме того любое "слово" в пределах "фразы", которое начинается с "=?" и завершается "?=", должно быть корректным кодировочным словом. |
| (10) | Адаптирующиеся агенты пользователя должны быть способны отделит кодировочные слова от "text", "ctext" или "word", в соответствии с правилами секции 4, где бы они не встретились в заголовках сообщения. Они должны поддерживать как "B"- так и "Q"-кодирование для любого поддерживаемого символьного набора. Программа должна быть способна отобразить не кодированный текст, если символьным набором является "US-ASCII". Для символьных наборов ISO-8859-*, программа, читающая почтовые сообщения должна быть способна, по крайней мере, отобразить символы, которые входят также и в набор US-ASCII. Агент пользователя, который отвечает данным условиям, считается адаптированным к MIME. |
/p> Есть и другое соображение, почему всегда безопасно посылать данные в формате, согласованным с MIME, ведь такая форма не вступит в конфликт с промежуточными почтовыми серверами, работающими в соответствие со стандартами RFC-821 и RFC-822. Агенты пользователя, которые адаптированы к MIME имеют дополнительную гарантию, что пользователю не будет представлена информация, не воспринимаемая как текст.
2. Базовые моменты при посылке почтовых сообщений
Почта в Интернет не совершенная однородная система. Почта может оказаться поврежденной на нескольких этапах ее транспортировки к месту назначения. Почтовое сообщение может проходить через участки среды, использующие различные сетевые технологии. Многие сетевые и почтовые технологии не поддерживают полную функциональность, возможную в рамках протокола SMTP. Почтовое сообщение, проходя через эти среды, может быть модифицировано, для того чтобы решить проблему его передачи адресату.
В сети Интернет имеется большое число почтовых агентов, которые в процессе реализации протокола SMTP, модифицируют сообщения на пролете. Следующие соображения могут оказаться полезными любому, кто разрабатывает формат данных (тип среды), который бы сохранялся неповрежденным в любых сетевых средах и для любых почтовых агентов. Заметим, что данные, закодированные в base64, удовлетворяют этим требованиям, а некоторые хорошо известные механизмы, в частности утилита UNIX uuencode, не удовлетворяет. Заметим также, что данные, закодированные с использованием закавыченных последовательностей печатных символов, успешно преодолевают большинство почтовых шлюзов, но могут быть повреждены в системах, которые используют символьный набор EBCDIC.
При некоторых обстоятельствах кодирование, использованное для данных, может изменить работу почтового шлюза или агента пользователя. В частности, может потребоваться преобразование из base64 в закавыченную печатную форму и обратно. Это может вызвать искажения для последовательностей CRLF, определяющих границы строк в тексте.
2)
Многие системы могут выбрать для хранения и представления текста другое локальное соглашение для обозначения начала новой строки. Это локальное соглашение может не согласовываться с RFC-822, где для этого используется CRLF. Известны системы, где для этой цели применяют один символ CR, один LF, CRLF, или нечто совсем другое. В результате получается, что изолированные CR и LF символы не вполне надежны; они могут быть потеряны или преобразованы некоторыми системами в другие разделители, следовательно, на них нельзя положиться.
3)
Передача нулей (US-ASCII значение 0) проблематична в Интернет-почте. Это по большей части результат введения нулей, используемых в качестве завершающего символа во многих стандартных программных библиотеках реального времени в языке Си. Практика использования нулей в качестве завершающего символа настолько распространена, что нельзя рассчитывать на то, что эти нули будут сохранены в сообщении.
4)
TAB (HT) символы могут быть неверно интерпретированы или автоматически преобразованы в переменное число пробелов. Это неизбежно в некоторых условиях, в особенности тех, которые базируются на символьном наборе US-ASCII. Такое преобразование не рекомендуется, но может случиться и форматы почты не должны полагаться на сохранение символов TAB (HT).
5)
Строки длиннее 76 символов могут быть разорваны или укорочены некоторыми почтовыми агентами. Разрыв строк или укорочение при транспортировке почты не рекомендуется, но избежать этого иногда невозможно. Приложения, которые требуют длинных строк, должны каким то образом делать различие между "мягким" и "жестким" разрывом строки. Простым способом решить эту проблему является применение кодирования с помощью закавыченных строк печатных символов.
6)
Завершающие символы строки (SP и HT) могут быть отброшены некоторыми транспортными агентами, в то время как другие могут дополнить строки этими символами так, что все строки почтового файла обретают равную длину. На присутствие завершающих символов SP или HT рассчитывать не приходится.
7)
Многие почтовые домены используют вариации символьного набора US-ASCII, или работают с символьными наборами типа EBCDIC, который содержит большинство но не все символы из US-ASCII. Корректная трансляция символов в не инвариантный набор не может быть зависимой от конвертирующих шлюзов по дороге. Например, возникает проблема при пересылке информации, обработанной программой uuencodE, через сеть BITNET. Аналогичные проблемы могут возникнуть без прохода через шлюз, так как многие ЭВМ в Интернет используют символьный набор отличный от US-ASCII. Определение печатной строки в X.400 добавляет новые ограничения в некоторых специфических случаях. В частности, символами, которые могут быть пропущены через любые шлюзы, считаются 73 символа. В их число входят прописные и строчные буквы A-Z и a-z, 10 цифр - 0-9 и следующие одиннадцать специальных символов.
"'" (US-ASCII десятичное значение 39)
"(" (US-ASCII десятичное значение 40)
")" (US-ASCII десятичное значение 41)
"+" (US-ASCII десятичное значение 43)
"," (US-ASCII десятичное значение 44)
"-" (US-ASCII десятичное значение 45)
"." (US-ASCII десятичное значение 46)
"/" (US-ASCII десятичное значение 47)
":" (US-ASCII десятичное значение 58)
"=" (US-ASCII десятичное значение 61)
"?" (US-ASCII десятичное значение 63)
Максимально переносимое почтовое сообщение имеет короткие строки, содержащие только эти 73 с имвола. Кодирование base64 отвечает этому правилу.
(8)
Некоторые почтовые транспортные агенты искажают данные, которые содержат определенные символьные строки. В частности, одиночный символ точка (".") на строке может быть поврежден в некоторых SMTP реализациях, а строки, которые начинаются с пяти символов "From " (пятым символом является пробел), также могут быть повреждены. Хорошие агенты-отправители могут предотвратить эти искажения путем кодирования данных (например, в закавыченных строках печатных символов в начале строки вместо "From " используется "=46rom " и "=2E" вместо одиночной ".").
Заметим, что приведенный выше список не является рекомендацией для почтовых транспортных агентов. В документе RFC-821 не запрещается заменять символы или разрывать длинные строки. Более того, данный список отражает негативную практику для существующих сетей и программные реализации должны быть устойчивы против таких эффектов, с которыми им придется столкнуться.
3. Каноническая модель кодирования
Процесс формирования объекта MIME можно смоделировать в виде цепочки последовательных шагов. Заметим, что эти шаги сходны с используемыми в PEM [RFC-1421] и реализуются для каждого "внутреннего" уровня тела сообщения.
| (1) | Создание локальной формы. |
| (2) | Преобразование в каноническую форму. |
Например, в случае чистого текста, данные должны преобразовываться с использованием поддерживаемого символьного набора, а строки должны завершаться CRLF, как этого требует RFC-822. Заметьте, что ограничения на длины строк, налагаемые RFC-822, игнорируются, если на следующем шаге выполняется кодирование с использованием base64 или закавыченных строк печатных символов.
| (3) | Применение транспортного кодирования. |
/p> Применяется подходящее для данного тела транспортное кодирование. Заметим, что не существует жесткой связи между типом среды и транспортным кодированием. В частности, может оказаться вполне приемлемым выбор base64 или закавыченных строк печатных символов.
| (4) | Вставление в объект. |
Преобразование из формата объекта в локальную форму представления производится в обратном порядке. Заметим, что реверсирование этих шагов может вызвать различный результат, так как не существует гарантии, что исходная и оконечная формы окажутся идентичными. Очень важно учесть, что эти шаги являются лишь моделью, а не руководством к тому, как на самом деле следует строить систему. В частности, модель не срабатывает в двух достаточно общих случаях.
| (1) | Во многих вариантах преобразование к канонической форме предваряется некоторой трансляцией в самой кодирующей программе, которая непосредственно работает с локальным форматом. Например, локальное соглашение о разрывах строк для текста тел может реализоваться с помощью самого кодировщика, который владеет информацией о характере локального формата. |
| (2) | Выходные данные кодировщика могут проходить через один или более дополнительных ступеней прежде чем будут переданы в виде сообщения. Выход кодировщика как таковой может не согласовываться с форматами, специфицированными в RFC-822. В частности, если это окажется удобно преобразователю, разрыв линии может обозначаться каким то иным способом, а не CRLF, как этого требует стандарт RFC-822. |
Content-type: text/foo; charset=bar
Content-Transfer-Encoding: base64
должно быть сначала представлено в форме text/foo, затем, если необходимо, представлено в символьном наборе и, наконец, трансформировано с использованием алгоритма base64 в формат, безопасный для пересылки через любые шлюзы.
Некоторые проблемы вызывают почтовые системы, которые для обозначения перехода на новую строку используют нечто отличное от CRLF, принятого в стандарте RFC-822. Важно отметить, что эти форматы не являются каноническими RFC-822/MIME. Заметим также, что форматы, где вместо последовательности CRLF заносится, например, LF не способны представлять сообщения MIME, содержащие двоичные данные с октетами LF, которые не являются частью последовательности CRLF.
Приложение A. Сложный пример составного сообщения
Данное сообщение содержит пять частей, которые должны быть отображены последовательно: - два вводных объекта чистого текста, встроенное составное сообщение, объект типа text/enriched и завершающее инкапсулированное текстовое сообщение с символьным набором не ASCII типа. Встроенное составное сообщение в свою очередь содержит два объекта, которые должны отображаться в параллель, изображение и звуковой фрагмент.
MIME-Version: 1.0
From: Nathaniel Borenstein
To: Ned Freed
Date: Fri, 07 Oct 1994 16:15:05 -0700 (PDT)
Subject: A multipart example(составной пример)
Content-Type: multipart/mixed;boundary=unique-boundary-1
Это область преамбулы составного сообщения. Программы чтения почты, приспособленные для чтения составных сообщений, должны игнорировать эту преамбулу.
--unique-boundary-1
... Здесь размещается некоторый текст ...
[Заметим, что пробел между границей и началом текста в этой части означает, что не было никаких заголовков и данный текст представлен в символьном наборе US-ASCII.]
--unique-boundary-1
Content-type: text/plain; charset=US-ASCII
Это может быть частью предыдущей секции, но иллюстрирует различие непосредственного и неявного ввода текста частей тела.
--unique-boundary-1
Content-Type: multipart/parallel; boundary=unique-boundary-2
--unique-boundary-2
Content-Type: audio/basic
Content-Transfer-Encoding: base64
... здесь размещаются одноканальные аудио данные, полученные при частоте стробирования 8 кГц, представленные с использованием m-преобразования, и закодированные с привлечением base64 ...
--unique-boundary-2
Content-Type: image/jpeg
Content-Transfer-Encoding: base64
... здесь размещается изображение, закодированное с привлечением base64 ...
--unique-boundary-2--
--unique-boundary-1
Content-type: text/enriched
This is enriched.
как определено в RFC-1896
Isn't it
cool?
-unique-boundary-1
Content-Type: message/RFC-822
From: (mailbox in US-ASCII)
To: (address in US-ASCII)
Subject: (subject in US-ASCII)
Content-Type: Text/plain; charset=ISO-8859-1
Content-Transfer-Encoding: Quoted-printable
Additional text in ISO-8859-1 goes here ...
--unique-boundary-1--
Ссылки
| [ATK] | Borenstein, Nathaniel S., Multimedia Applications Development with the Andrew Toolkit, PrenticeHall, 1990. |
| [ISO-2022] | International Standard -- Information Processing -- Character Code Structure and Extension Techniques, ISO/IEC 2022:1994, 4th ed. |
| [ISO-8859] |
International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets - Part 1: Latin Alphabet No. 1, ISO 8859-1:1987, 1st ed. - Part 2: Latin Alphabet No. 2, ISO 8859-2:1987, 1st ed. - Part 3: Latin Alphabet No. 3, ISO 8859-3:1988, 1st ed. - Part 4: Latin Alphabet No. 4, ISO 8859-4:1988, 1st ed. - Part 5: Latin/Cyrillic Alphabet, ISO 8859-5:1988, 1st ed. - Part 6: Latin/Arabic Alphabet, ISO 8859-6:1987, 1st ed. - Part 7: Latin/Greek Alphabet, ISO 8859-7:1987, 1st ed. - Part 8: Latin/Hebrew Alphabet, ISO 8859-8:1988, 1st ed. - Part 9: Latin Alphabet No. 5, ISO/IEC 8859-9:1989, 1st ed. International Standard -- Information Technology -- 8-bit Single-Byte Coded Graphic Character Sets >- Part 10: Latin Alphabet No. 6, ISO/IEC 8859-10:1992, 1st ed. |
| [ISO-646] | International Standard -- Information Technology – ISO 7-bit Coded Character Set for Information Interchange, ISO 646:1991, 3rd ed.. |
| [JPEG] | JPEG Draft Standard ISO 10918-1 CD. |
| [MPEG] | Video Coding Draft Standard ISO 11172 CD, ISO IEC/JTC1/SC2/WG11 (Motion Picture Experts Group), May, 1991. |
| [PCM] | CCITT, Fascicle III.4 - Recommendation G.711, "Pulse Code Modulation (PCM) of Voice Frequencies", Geneva, 1972. |
| [POSTSCRIPT] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, 1985. |
| [POSTSCRIPT2] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, Second Ed., 1990. |
| [RFC-783] | Sollins, K.R., "TFTP Protocol (revision 2)", RFC-783, MIT, June 1981. |
| [RFC-821] | Postel, J.B., "Simple Mail Transfer Protocol", STD-10, RFC-821, USC/Information Sciences Institute, August 1982. |
| [RFC-822] | Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC-822, UDEL, August 1982. |
| [RFC-934] | Rose, M. and E. Stefferud, "Proposed Standard for Message Encapsulation", RFC-934, Delaware and NMA, January 1985. |
| [RFC-959] | Postel, J. and J. Reynolds, "File Transfer Protocol", STD 9, RFC-959, USC/Information Sciences Institute, October 1985. |
| [RFC-1049] | Sirbu, M., "Content-Type Header Field for Internet Messages", RFC-1049, CMU, March 1988. |
| [RFC-1154] | Robinson, D., and R. Ullmann, "Encoding Header Field for Internet Messages", RFC-1154, Prime Computer, Inc., April 1990. |
| [RFC-1341] | Borenstein, N., and N. Freed, "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1341, Bellcore, Innosoft, June 1992. |
| [RFC-1342] | Moore, K., "Representation of Non-Ascii Text in Internet Message Headers", RFC-1342, University of Tennessee, June 1992. |
| [RFC-1344] | Borenstein, N., "Implications of MIME for Internet Mail Gateways", RFC-1344, Bellcore, June 1992. |
| [RFC-1345] | Simonsen, K., "Character Mnemonics & Character Sets", RFC-1345, Rationel Almen Planlaegning, June 1992. |
| [RFC-1421] | Linn, J., "Privacy Enhancement for Internet Electronic Mail: Part I -- Message Encryption and Authentication Procedures", RFC-1421, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1422] | Kent, S., "Privacy Enhancement for Internet Electronic Mail: Part II -- Certificate-Based Key Management", RFC-1422, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1423] | Balenson, D., "Privacy Enhancement for Internet Electronic Mail: Part III -- Algorithms, Modes, and Identifiers", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1424] | Kaliski, B., "Privacy Enhancement for Internet Electronic Mail: Part IV -- Key Certification and Related Services", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1521] | Borenstein, N., and Freed, N., "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1521, Bellcore, Innosoft, September, 1993. |
| [RFC-1522] | Moore, K., "Representation of Non-ASCII Text in Internet Message Headers", RFC-1522, University of Tennessee, September 1993. |
| [RFC-1524] | Borenstein, N., "A User Agent Configuration Mechanism for Multimedia Mail Format Information", RFC-1524, Bellcore, September 1993. |
| [RFC-1543] | Postel, J., "Instructions to RFC Authors", RFC-1543, USC/Information Sciences Institute, October 1993. |
| [RFC-1556] | Nussbacher, H., "Handling of Bi-directional Texts in MIME", RFC-1556, Israeli Inter-University Computer Center, December 1993. |
| [RFC-1590] | Postel, J., "Media Type Registration Procedure", RFC-1590, USC/Information Sciences Institute, March 1994. |
| [RFC-1602] | Internet Architecture Board, Internet Engineering Steering Group, Huitema, C., Gross, P., "The Internet Standards Process -- Revision 2", March 1994. |
| [RFC-1652] | Klensin, J., (WG Chair), Freed, N., (Editor), Rose, M., Stefferud, E., and Crocker, D., "SMTP Service Extension for 8bit-MIME transport", RFC-1652, United Nations University, Innosoft, Dover Beach Consulting, Inc., Network Management Associates, Inc., The Branch Office, March 1994. |
| [RFC-1700] | Reynolds, J. and J. Postel, "Assigned Numbers", STD-2, RFC-1700, USC/Information Sciences Institute, October 1994. |
| [RFC-1741] | Faltstrom, P., Crocker, D., and Fair, E., "MIME Content Type for BinHex Encoded Files", December 1994. |
| [RFC-1896] | Resnick, P., and A. Walker, "The text/enriched MIME Content-type", RFC-1896, February, 1996. |
| [RFC-2045] | Freed, N., and and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC-2045, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2046] | Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC-2046, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2047] | Moore, K., "Multipurpose Internet Mail Extensions (MIME) Part Three: Representation of Non-ASCII Text in Internet Message Headers", RFC-2047, University of Tennessee, November 1996. |
| [RFC-2048] | Freed, N., Klensin, J., and J. Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: MIME Registration Procedures", RFC-2048, Innosoft, MCI, ISI, November 1996. |
| [RFC-2049] | Freed, N. and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples", RFC-2049 (this document), Innosoft, First Virtual Holdings, November 1996. |
| [US-ASCII] | Coded Character Set -- 7-Bit American Standard Code for Information Interchange, ANSI X3.4-1986. |
| [X400] | Schicker, Pietro, "Message Handling Systems, X.400", Message Handling Systems and Distributed Applications, E. Stefferud, O-j. Jacobsen, and P. Schicker, eds., North-Holland, 1989, pp. 3-41. |
Мобильные телекоммуникации
4.1.8.1 Мобильные телекоммуникации
Семенов Ю.А. (ГНЦ ИТЭФ)

В 80-х – 90-х годах весьма активное развитие получила мобильная телефония. В последнее время услуги мобильной связи стали применяться и для передачи цифровых данных. Мобильные телекоммуникации использует диапазоны в интервале 50 МГц – 1 ГГц. Мобильные системы работают при малых выходных мощностях передатчика, что ограничивает размер зоны приема. Вне этой зоны другие передатчики могут функционировать независимо. Такие зоны называются сотами (ячейками). По аналогии с пчелиными сотами их часто изображают шестигранными, хотя реально они могут иметь самую причудливую форму в зависимости от профиля местности. Ячейки должны перекрываться, так как показано на рис. 4.1.8.1.1

Рис. 4.1.8.1.1. Схема расположения ячеек при сотовой связи
Светлыми кружками отмечены реальные границы ячеек, их перекрытие должно обеспечить перекрытие всей зоны телекоммуникаций. В центре ячейки находится базовая станция ретранслятор. Такая станция содержит в себе ЭВМ и приемо-передатчик, соединенный с антенной. Такие системы могут обслуживать пейджерную или мобильную телефонную сеть. Пейджерные каналы однонаправлены а телефонные двунапрвлены (см. рис. 4.1.8.1.2). Пейджинговые системы требуют небольшой полосы пропускания. А одно сообщение редко содержит более 30 байт. Большинство современных пейджигновых систем работает в частотном диапазоне 930-932 МГц (старые занимали 150-174 МГц).
Рис. 4.1.8.1.2. Каналы пейджерной (слева) и мобильной телефонной сети (справа).
В небольших системах все базовые станции соединены с MTSO(mobile telephone switching office). В больших сетях может потребоваться несколько MTSO, которые в свою очередь управляются mtso следующего уровня и т.д.. Узловая MTSO соединена со станцией коммутируемой телефонной сети. В любой момент времени каждый мобильный телефон логически находится в одной определенной ячейке и управляется одной базовой станцией. Когда телефон покидает ячейку, базовая станция обнаруживает падение уровня сигнала и запрашивает окружающие станции об уровне сигнала для данного аппарата. Управление аппаратом передается станции с наибольшим входным сигналом. Телефон информируется о смене управляющей станции, при этом предлагается переключиться на новый частотный канал (в смежных ячейках должны использоваться разные частотные каналы). Процесс переключения занимает около 300 мсек (handoff), что должно быть практически незаметно для пользователя. Присвоением частот управляет MTSO. Сигнал передатчика падает по мере удаления от центра ячейки, где он должен быть расположен. Там же должен находиться и приемник. В пределах ячейки предусмотрено несколько каналов для приема/передачи, разнесенные по частоте. Эти каналы управляются центральным коммутатором ячейки (MSC – mobile-service switching centre).
В рамках американского стандарта первого поколения AMPS (advanced mobile phone service; 1982) формируется 40 МГц канал в интервале 800-900 МГц. Система использует 832 полнодуплексных каналов. Данный частотный диапазон делится пополам, 20 МГц выделяется для передачи и столько же для приема. Данные диапазоны делятся в свою очередь на 666 двусторонних каналов, каждый по 30 кГц. Эти каналы расщепляются на 21 субканал, сгруппированные по 3. Обычно, как показано на рис. 4.1.8.1.1, гексагональные ячейки группируются по 7 (центральная и 6 ее соседей). Имея 666 каналов, можно выделить три набора по 31 каналу для каждой ячейки. Такая схема удобна в случае возникновения необходимости увеличения числа каналов, для этого достаточно уменьшить размер ячейки – число ячеек увеличится и, как следствие, увеличится число каналов на единицу площади. В хорошо спланированной сети плотность ячеек пропорциональна плотности пользователей. AMPS для разделения каналов использует метод мультиплексирования по частоте.
Каждый мобильный телефон в amps имеет 32-битовый серийный номер и телефонный номер, характеризуемый 10 цифрами. Телефонный номер представляется как код зоны (3 десятичные цифры) и номер подписчика (7 десятичных цифр). Когда телефон включается, он сканирует список из 21 управляющих каналов и находит тот, у которого наиболее мощный сигнал. Управляющая информация передается в цифровой форме, хотя сам голосовой сигнал является аналоговым. При нормальной работе мобильный телефон перерегистрируется в MTSO (mobile telephone switching office) каждые 15 мин.
При осуществлении вызова пользователь набирает номер телефона и нажимает кнопку send. Аппарат посылает набранный номер и свой идентификационный код. Базовая станция принимает вызов и передает его MTSO. Если звонящий является клиентом mtso или ее партнером, ишется свободный канал и мобильный телефон переключается на него, ожидая когда адресат снимет трубку.
В режиме приема аппарат постоянно прослушивает канал пейджинга, чтобы обнаружить обращенный к нему вызов. Осуществляется обмен командными сообщениями с MTSO, после чего раздается звонок вызова.
Аналоговые сотовые телефоны не обеспечивают конфиденциальности. С помощью широкополосного сканера можно зафиксировать вызов и осуществить прослушивание. Другим недостатком является возможность кражи эфирного времени. Вседиапазонный приемник, подключенный к ЭВМ, может записать 32-битовый серийный номер и 34-битовый телефонный номер всех телефонов, работающих поблизости. Собрав такие данные вор может по очереди пользоваться любым из перехваченных номеров.
AMPS базируется на аналоговой модуляции, существует еще полдюжины аналогичных не стыкуемых друг с другом систем. В последнее время аналоговая модуляция повсеместно вытесняется цифровой. В Европе принят единый стандарт для систем мобильной связи GSM (groupe special mobile, второе поколение мобильных средств связи). gsm использует диапазоны 900 и 1800 МГц. Это довольно сложный стандарт, его описание занимает около 5000 страниц. Идеологически система имеет много общего с ISDN (например, переадресацию вызовов). GSM имеет 200 полнодуплексных каналов на ячейку, с полосой частот 200 кГц, что позволяет ей обеспечить пропускную способность 270,833 бит/с на канал. Каждый из 124 частотных каналов делится в GSM между восемью пользователями (мультиплексирование по времени). Теоретически в каждой ячейке может существовать 992 канала, на практике многие из них недоступны из-за интерференции с соседними ячейками.
Система мультиплексирования по времени имеет специфическую структуру. Отдельные временные домены объединяются в мультифреймы. Упрощенная схема структуры показана на рис. 4.1.8.1.3.

Рис. 4.1.8.1.3. Структура кадров в GSM
Каждый временной домен (TDM) содержит 148-битовый кадр данных, начинающийся и завершающийся последовательностью из трех нулей. Кадр имеет два 57-битовых поля данных, каждое из которых имеет специальный бит, который указывает на то, что лежит в кадре - голос или данные. Между информационными полями размещается поле синхронизации (Sync). Хотя информационный кадр имеет длительность 547 мксек, передатчику позволено передавать его лишь раз в 4615 мксек, так остальное время зарезервировано для передачи другими станциями. Если исключить накладные накладные расходы каждому соединению выделена полоса (без учета сжатия данных) 9600 кбит/с.
Восемь информационных кадров образуют TDM-кадр, а 26 TDM-кадров объединяются в 128- микросекундный мультифрейм. Как видно из рисунка 4.1.8.1.2 позиция 12 в мультифрейме занята для целей управления, а 25-я зарезервирована для будущих применений. Существует также стандарт на 51-позиционный мультифрейм, содержащий больше управляющих вставок. Управляющий канал используется для регистрации, актуализации положения и формирования соединения. Каждая стационарная станция поддерживает базу данных, где хранится информация обо всех обслуживаемых в данный момент клиентах. Общий управляющий канал делится на три субканала. Первый служит для обслуживания вызовов (paging channel), второй (random access channel) реализует произвольный доступ в рамках системы ALOHA (устанавливаются параметры вызова). Третий субканал служит для предоставления доступа (access grant channel).
Алгоритмы обслуживания мобильной связи достаточно нетривиальны. Из рисунка 4.1.8.1.1 видно, что области перекрываются (иначе бы существовали "мертвые" зоны без связи). Существуют даже субобласти, накрываемые тремя MSC. По это причине процедура должна четко определить, с каким из MSC клиент должен быть связан, и при каких условиях его следует переключить на соседний MSC, не прерывая связи. Система должна также компенсировать падение сигнала, иногда достаточно резкое, чтобы обеспечить комфортную связь и безошибочную передачу информации. По этой причине частота ошибок (BER) в таких сетях составляет 10-3 (против 10-6 для обычных стационарных цифровых каналов связи). Следует иметь в виду, что в условиях города сигнал падает пропорционально не квадрату, а четвертой степени расстояния. На распространение радиоволн в городе влияют ориентация улиц (до 20 дБ), туннели (до 30 дБ) и листва деревьев в сельской местности (до 18 дБ).
GSM - система базирующаяся в основном на коммутации каналов. Применение модема на переносной ЭВМ позволяет подключиться к сети Интернет. Но здесь не все беспроблемно. Базовые станции временами теряют связь друг с другом (переключение с канала на канал), что может приводить к 300 миллисекундным потери данных. Как уже говорилось выше, здесь высока вероятность ошибок. Так, нажав клавишу "a", можно получить на экране букву "я". Да и расценка за минуту работы в Интернет здесь весьма высока. В связи с этим был разработан стандарт на цифровую систему коммутации пакетов CDPD (Cellular Digital Packet Data). Система работает поверх AMPS. Система обеспечивает информационную пропускную способность на уровне 9,6 кбит/с. CDPD довольно точно следует модели OSI. В CDPD определены три типа интерфейсов. Е-интерфейс (внешний по отношению CDPD-провайдеру) соединяют CDPD-область с определенной сетью. I-интерфейс (внутренний по отношению CDPD-провайдеру) соединяет CDPD-области друг с другом. A-интерфейс (эфирный) используется для связи базовой станции с мобильной ЭВМ. В функции этого интерфейса входит сжатие и шифрование данных, а также исправление ошибок. 274-битные блоки сжатой и зашифрованной информации вкладываются в 378-битовые блоки, предназначенные для коррекции ошибок согласно алгоритму Рида-Соломона. К каждому такому блоку добавляется семь 6-битовых флагов. Результирующие блоки имеют 420 бит и передаются в виде семи 60-битовых микроблоков. Эти микроблоки передаются к базовой станции со скоростью 19,2 кбит/с. Канал с аналогичным быстродействием создается для пересылки информации в противоположном направлении. При обмене применяется мультиплексирование с делением по времени. При этом временные домены имеют длительность 3,125 мсек (60 бит).
Когда мобильная ЭВМ хочет что- то передать, прослушивается канал базовой станции и проверяется флаг, сообщающий, свободен ли входной канал базовой станции. Если канал занят, ЭВМ вместо ожидания до очередного временного домена, пропуская псевдослучайное число временных доменов, после чего повторяет попытку. Если повторная попытка неудачна, время ожидания увеличивается примерно вдвое. Когда, наконец, ЭВМ обнаруживает, что канал свободен, она начинает пересылку своих микроблоков. Предусмотрена процедура, препятствующая попытке всех ЭВМ, готовых к передаче, захватить канал, как только он оказался свободным. Этот алгоритм называется DSMA (Digital Sense Multiple Access). Но, несмотря на применение DSMA, столкновение все же возможно, так как две или более ЭВМ могут воспользоваться одним и тем же временным доменом для начала передачи. Для выявления столкновений предусмотрен специальный флаг, который позволяет судить, корректно ли доставлен предыдущий микроблок. К сожалению это происходит не мгновенно а лишь спустя несколько микроблоков. При обнаружении ошибки передача прерывается. Следует иметь в виду, что информационный обмен имеет более низкий приоритет по отношению передачи голосовых данных. Предусмотрена возможность создания выделенных CDPD-каналов.
GSM использует довольно сложную комбинацию методик ALOHA, TDM и FDM. CDPD для передачи одиночных кадров не вполне согласуется с алгоритмом CSMA. Впрочем существует еще один метод формирования радио каналов - CDMA (Code Division Multiple Access).
Метод CDMA принципиально отличается от описанных выше, которые использовали для дультиплексирования доступа FDM, TDM или ALOHA. CDMA позволяет каждой станции осуществлять передачу во всем частотном диапазоне постоянно. Множественные передачи реализуются с привлечением теории кодирования. Здесь предполагается, что сигналы, совпадающие по времени складываются линейно. В CDMA каждый бит-тайм делится на m коротких интервалов, называемых чипами. Обычно используется 64 или 128 чипов на бит. Каждой станции присваивается уникальный m-битный код (chip sequence). Чтобы передать 1 бит станция посылает свой чип-код. Для простоты далее будем предполагать, что m=8. Для того чтобы послать нулевой бит, посылается дополнение чип-кода по модулю один. Никакие другие кодовые последовательности не разрешены. Например, пусть станции 1 поставлен в соответствие чип-код 01010101, тогда при посылке логической 1 она отправляет код 01010101, а при отправке логического нуля - 10101010. Если имеется канал с полосой 1 МГц и 100 станций с FDM, то каждая из них получит по 10 КГц (10 кбит/c при 1 бите на Гц). При CDMA каждая станция использует весь частотный диапазон, так что будет получена скорость передачи 1 мегачип в секунду. При менее 100 чипов на бит CDMA обеспечивает большую пропускную способность, чем FDM. Для упрощения введем двуполярную нотацию, где нулю соответствует -1, а единице +1. Тогда чип-код станции 1 получит вид -1 +1 -1 +1 -1 +1 -1 +1. Каждая из станций получает уникальный чип-код. Чип-коды можно представить в виде m-компонентных векторов. Чип-коды выбираются так, что все они попарно ортогональны (не любой уникальный чип-код пригоден, так, если станция 1 имеет чип-код 01010101, то станция 2 не может иметь чип-код 10101001, но чип-код 10100101 вполне допустим). Математически это можно выразить следующим образом:
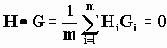
где Hi и Gi компоненты векторов чип-кодов H и G. Это равенство указывает, что число разных компонентов равно числу равных. Если G и H ортогональны, то и

Когда сигналы от разных станций совпадают во времени и складываются, принимающая сторона легко может вычислить наличие соответствующей компоненты. Если компоненты суммарного сигнала Si, то компоненты Gi вычисляются с помощью произведения Si*H. Действительно, если:
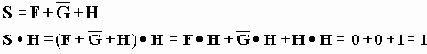
Здесь первые два слагаемых равны нулю в силу ортогональности выбранных чип-кодов. Последнее же слагаемое равно 1 согласно [1]. Во всех этих рассуждениях предполагалось, что все станции работают синхронно и начинают передачу чип-кодов одновременно.
Для пояснения метода рассмотрим конкретный пример в выше предложенной нотации. присвоим станциям F, G, H, I ортогональные чип-коды:
F=01010101 > -1 +1 -1 +1 -1 +1 -1 +1
G=10100101 > +1 -1 +1 -1 -1 +1 -1 +1
H=10011001 > +1 -1 -1 +1 +1 -1 -1 +1
I=11111111 > +1 +1 +1 +1 +1 +1 +1 +1
Теперь рассмотрим четыре варианта наложений:
Только F > S1=[-1 +1 -1 +1 -1 +1 -1 +1]
F+I > S2=[0 +2 0 +2 0 +2 0 +2]
F+G+H > S3=[+1 -1 -1 +1 -1 +1 -3 +3]
Для выявления наличия компоненты G выполним операции "умножения" согласно описанным выше правилам.
S1*G =[-1 -1 -1 -1 +1 +1 +1 +1]/8=0 (G отсутствует)
S2*G =[0 -2 0 -2 - +2 0 +2]/8=0 (G отсутствует)
S3*G =[+1 +1 -1 -1 +1 +1 +3 +3]/8=1 (G имеется - передана логическая 1)
S4*G =[-1 -1 -3 -3 -1 -1 +1 +1]/8=-1 (G имеется - передан логический 0)
Хотя теоретически здесь все прекрасно, наложение слишком большого числа чип-кодов может создать проблемы и, в конечном итоге, привести к ошибкам.
Идеальная мобильная система связи представляется в виде телефонной трубки, которой человек пользуется дома, в автомобиле, в отпуске или командировке. При этом телефонный номер не меняется, где бы вы не находились. Такая система разрабатывается в настоящее время и называется PCS (Personal Communication Services) в США. В остальном мире эта система имеет имя PCN (Personal Communications Network). PCS использует технику сотовой телефонной сети. Но здесь размер ячейки лежит в пределах 50-100 м (против 20 км для AMPS). Это позволяет работать с малой выходной мощностью порядка 0,25 Вт и понизить вес аппарата. При этом для покрытия той же области требуется в 40000 раз больше ячеек и, следовательно, такая система будет значительно дороже даже с учетом более низкой цены одной ячейки. Некоторые телефонные компании осознали, что старомодные телеграфные столбы являются идеальным местом для размещения базовых станций новой системы (провода уже имеются!). Для системы PCS зарегервирован диапазон частот 1,7-2,3 ГГц.
Модель машины конечных состояний
10.23 Модель машины конечных состояний
Семенов Ю.А. (ГНЦ ИТЭФ)
Базовой концепцией построения многих современных протоколов является машина конечных состояний (FSM - Finite State Machine). При этом подходе каждый протокол характеризуется машиной, которая в любой момент времени находится в каком-то конкретном состоянии. Каждому состоянию соответствует определнный набор значений системных переменных. Такой подход требует определенного уровня абстрагирования. Например, для того чтобы ЭВМ перешла из состояния ожидания в состояние, когда получено некоторое сообщение, реализуется достаточно много промежуточных операций (проверка качества сигнала, контроль целостности сообщения, проверка отсутствия переполнения буфера и многие другие). Все эти промежуточные операции и состояния считаются переходными и в данной модели не рассматриваются. Таким образом, состояние протокольной машины полностью определяется набором значений определенных системных переменных. Так состояние протокольной машины канала определяется состояниями клиента и сервера. Если состояние как отправителя так и получателя характеризуются двумя битами, то состояние системы будет характеризоваться 16 состояниями. Из любого состояния может быть нуль или более возможных переходов в другое состояние. Переход из одного состояние в другое происходит при наступлении определенного события (например, полчение сообщения, прерывание, таймаут и т.д.).Машина состояний протокола может быть охарактеризована с помощью ориентированного графа, в котором число узлов равно числу конечных состояний системы, а число ребер всей совокупности возможных переходов из одного состояния в другое. Одно из состояний выбирается в качестве исходного. Из этого состояния система может попасть в некоторые (все) другие состояния с помощью последовательности переходов. Данный подход позволяет часто выявить слабые места протокола (например, возможности "повисаний").
Машина конечных состояний протокола характеризуется следующими наборами переменных
S Набор состояний процессов и канала M Набор кадров, которые могут быть переданы по каналу I Набор исходных состояний процессов T Набор переходов между состояниями В начальный момент все процессы находятся в исходных состояниях. Дальнейшие переходы из состояния в состояние определяются событиями, происходящими в системе. Каждое событие может вызвать переход в новое состояние какого-то процесса или канала. Если в результате анализа графа машины конечных состояний выясняется, что в случае прихода кадра некоторого типа, не определено, в какое состояние должна перейти машина, это свидетельствует о наличии ошибки в протоколе. Если обнаруживается одно или несколько состояний, из которых нет перехода куда-либо во вне (тупик), такое положение также свидетельствует об ошибке. В качестве примера машины конечных состояний можно рассмотреть граф протокола TCP.
Модемы
4.3.7 Модемы
Семенов Ю.А. (ГНЦ ИТЭФ)
Само название этого прибора происходит от имеющихся в нем модулятора и демодулятора. Современный модем можно отнести к числу устройств с наибольшим числом современных технологий на кубический сантиметр. Разнообразие модемов огромно. Они различаются по конструкции, по используемым протоколам, по характеру интерфейсов и т.д. Основное назначение модема оптимальное преобразование цифрового сигнала в аналоговый для передачи его по каналу связи и, соответственно, обратное преобразование на принимающей стороне. Под “оптимальным преобразованием” понимается такое, которое обеспечивает надежность связи, улучшает отношение сигнал шум и как следствие пропускную способность канала. Это преобразование необходимо для обеспечения улучшения отношения сигнал-шум. В качестве канала передачи данных может быть использована городская телефонная сеть, выделенная линия или радио-канал. Схема взаимодействия модемов показана на рис. 4.3.7.1.
Рис. 4.3.7.1. Схема соединения двух модемов (М1 и М2) через канал
В качестве последовательного интерфейса может выступать RS-232, V.35, G.703 и т.д.. Все модемы содержат в себе управляющий микропроцессор, постоянную память (ROM), куда записано фирменное программное обеспечение и интерпретатор команд, энергонезависимую память (NVRAM - non-volatile RAM), которая хранит конфигурационные профайлы модема, телефонные номера и т.д., буфер ввода/вывода (128-256 байт), сигнальный процессор (DSP), включающий в себя модулятор и демодулятор, интерфейс для связи с ЭВМ (RS-232) и оперативную память.
Первоначально модемы использовались для связи через традиционные коммутируемые телефонные линии. Так как такие линии содержат только два провода, а информационный обмен должен происходить в обоих направлениях одновременно, возникает проблема отделения передаваемого сигнала от приходящего из вне (подавление эхо; см. раздел 2.1). Для выделенных четырехпроводных линий эта проблема значительно упрощается, здесь прием и передача осуществляется по разным скрученным парам и эхо возникает лишь из-за перекрестных наводок (NEXT). Модемы подключаются к последовательным интерфейсам ЭВМ (COM-порт, RS-232), иногда для подключения модема используется специальная плата расширения, которая имеет дополнительные буферы и помогает достичь большего сжатия информации, существуют модемы, подключаемые и к параллельному порту ЭВМ. Модемы (микромодемы) могут работать не только через общедоступную телефонную сеть, они могут найти применение при соединении терминалов или ЭВМ в пределах организации, если расстояние между ними исчисляются сотнями метров (а иногда и километрами). В этом случае они помогают повысить надежность связи и исключить влияние разностей потенциалов между земляными шинами соединяемого оборудования. Микромодемы не требуют подключения к сети переменного тока, так как получают питание через разъем последовательного интерфейса (RS-232).
Все протоколы модемов утверждаются международным телекоммуникационным союзом (ITU), ранее за это был ответственен Консультативный комитет CCITT. Асинхронные модемы поддерживают определенный набор команд, который был впервые применен фирмой hayes в модеме smartmodem 1200. Модемы, придерживающиеся этого стандарта, называются Hayes-совместимыми. Совместимость предполагает идентичность функций первых 28 управляющих регистров модема (всего модем может иметь более сотни регистров). Почти все внутренние команды начинаются с символов AT (attention) и имеют по три символа. По этой причине их иногда называют AT-командами. Hayes-совместимость гарантирует, что данный модем будет работать со стандартными терминальными программами. Реально набор команд для модемов разных производителей варьируется в широких пределах. Для синхронных модемов набор команд регламентируется стандартом V.25bis. Ниже (таблица 4.3.7.1) приводится перечень стандартных модемных протоколов и стандартов.
Таблица 4.3.7.1. Основные протоколы модемов
tcm Семейство 2-проводных модемов, работающих на частотах до 9600бит/с V.32bis TCM
Модем, работающий на выделенную линию для частот 7200, 12000 и 14400бит/с V.33 TCM Модем на частоту 14.4кбит/с для выделенных линий V.34 Модем на частоту 28.8кбит/с, использован новый протокол установления связи V.34bis Модем на частоту 32 кбит/с V.35 Модем, работающий на выделенную линию с частотами до 9600бит/с V.42bis Стандарт для сжатия данных в модемах (4:1) Начиная с модемов V.32bis, стала использоваться динамическая регулировка скорости в ходе телекоммуникационной сессии в зависимости от состояния линии связи. Качество линии отслеживается по отношению сигнал/шум или по проценту блоков, переданных с ошибкой за определенный период времени.
Важным свойством модемов является возможность коррекции ошибок и сжатия информации. Ошибки корректируются путем повторной пересылки ошибочных блоков (ARQ - automatic repeat request). Ошибки контролируются с использованием CRC (cyclic redundancy check). Этим целям отвечает стандарт V.42, принятый еще в 1988 году, он включает в себя протокол LAPM (link access procedure for modems) и один из протоколов mnp (microcom networking protocol). В V.42 применен алгоритм сжатия информации Lempel-Ziv. При установлении связи между модемами определяется, какой из протоколов коррекции и сжатия они оба поддерживают. Если это V.42, то они сначала пытаются работать с использованием протокола LAPM. При неудаче (один из модемов не поддерживает V.42) используется протокол MNP. Перечисленные ниже алгоритмы коррекции ошибок и сжатия информации работают только для асинхронных модемов. Для синхронных модемов известен алгоритм сжатия SDS (synchronous data compression) фирмы motorola (коэффициент упаковки ~3.5, что для модемов V.34 может довести скорость обмена до 100кбит/с).
Ниже приведена таблица основных протоколов детектирования ошибок и сжатия информации, все протоколы mnp совместимы снизу вверх. При установлении связи между модемами используется наивысший протокол, поддерживаемый с обеих сторон канала.
Таблица 4.3.7.2. Протоколы mnp
MNP-1 |
Асинхронная полудуплексная передача данных с побайтовой организацией. Эффективность 70% (2400Кбит/с -> 1680Кбит/c). |
MNP-2 |
Асинхронная дуплексная передача данных с побайтовой организацией. Эффективность 84% (2400кбит/с -> 2000кбит/c) |
MNP-3 |
Синхронная дуплексная передача данных с побитовой организацией. Эффективность 108%. |
MNP-4 |
Адаптивная сборка передаваемых блоков (вариация размера блока) и оптимизация фазы. Эффективность 120% |
MNP-5 |
Помимо новшеств MNP-4 применено сжатие данных. Эффективность 200%. Используется только совместно с MNP-2-4 |
MNP-6 |
Снабжен адаптивностью скорости передачи, рассчитан на работу до 9.6кбит/с. Имеется возможность автоматического переключения из дуплексного режима в полудуплексный и обратно с учетом ситуации |
MNP-7 |
Усовершенствованный алгоритм сжатия данных. Эффективность до 300%. |
MNP-8,9 |
Еще более мощные алгоритмы сжатия |
MNP-10 |
Протокол, ориентированный на работу в сетях с высоким уровнем шумов (сотовые сети, сельские и междугородние линии), надежность достигается благодаря многократным попыткам установить связь, вариации размера пакета и подстройки скорости передачи |
Рис. 4.3.7.2 Схема подключения модема
Модем подключается к ЭВМ (см. рис. 4.3.7.2) через последовательный интерфейс RS-232c (существуют версии модемов, способных работать и с параллельным интерфейсом, который обладает почти в 3 раза большим быстродействием). Ниже в таблице представлена разводка для 9- и 25- контактных разъемов (таблица 4.3.7.3), используемых для последовательных интерфейсов (синхронные модемы используют только 25-контактный разъем).
Таблица 4.3.7.3. Разводка стандартных разъемов модема
| Сигнал | Номер контакта (db-9) | Номер контакта (db-25) | Назначение |
| DCD | 1 | 8 | Несущая обнаружена (data carrier detected) |
| RXD | 2 | 2 | Передача данных от DCE к DTE(received data) |
| TXD | 3 | 3 | Передача данных от DTE к DCE(transmit data) |
| DTR | 4 | 20 | Данные для передачи готовы (data transfer ready ) |
| GND | 5 | 7 | Земляной контакт |
| DSR | 6 | 6 | Готовность dce к работе (data set ready) |
| RTS | 7 | 4 | Готовность DTE к передаче (request to send) |
| CTS | 8 | 5 | Готовность DCE к передаче (clear to send) |
| RI | 9 | 22 | Индикатор звонка (ring indicator) |
/p> В персональных ЭВМ может быть 2 или 4 последовательных портов (интерфейсов), которые имеют логические имена COM1-COM4, им соответствуют следующие прерывания и адреса:
| COM1,3 | IRQ4 | 0x3f8 |
| COM2,4 | IRQ3 | 0x2f8 |
Модем может находиться в режиме данных (режим по умолчанию) и в командном режиме. Последний используется для реконфигурации модема и подготовки его к работе. Реконфигурация и управление возможны из локальной ЭВМ через последовательный порт, с передней панели модема, или при установленной связи через удаленный модем, если такой режим поддерживается. Переключение в командный режим производится с помощью ESC-последовательности (по умолчанию это три символа “+” с предшествующей и последующей секундной паузой).
При использовании большого числа модемов они для удобства обслуживания объединяются в группы (пулы). Модемный пул представляет в себя стандартный каркас, где размещается какое-то количество бескорпусных модемов. На передней панели находится, как правило, только индикация, выходы в телефонную сеть и разъемы последовательного интерфейса подключаются через заднюю панель. Такой пул содержит в себе обычно управляющий процессор. Так как в настоящее время не существует стандартов на организацию модемных пулов, они ориентированы на использование модемов только определенной фирмы. К пулу может подключаться дисплей, который отображает текущее состояние всех модемов. Процессор может контролировать состояние модемов, устанавливать их режим работы, а в некоторых случаях и выполнять функцию маршрутизатора, управляя встроенным многоканальным, последовательным интерфейсом. В последнем случае такой пул подключается непосредственно к локальной сети (например, Ethernet), а не к ЭВМ. Пул позволяет предотвращать “повисание” и отключение телефонных линий, что заметно повышает надежность системы. Некоторые модемы (например, фирмы Penril) имеют независимые узкополосные (~300 бит/с), дополнительные каналы для дистанционного управления. Такие каналы обладают повышенной устойчивостью, что позволяет сохранять целостность системы даже при временных отключеньях электропитания.
Таблица 4.3.7.4. Протоколы передачи файлов
xmodem |
Протокол (1977г, В. Кристенсен для ОС CP/M). Алгоритм: принимающая ЭВМ посылает символ NAK (ASCII 021) передающая ЭВМ посылает блок информации принимающая ЭВМ проверяет контрольную сумму и, если все в порядке, посылает код ASCII 06 (ACK), в противном случае NAK далее следует повтор передачи при ошибке или посылка следующего блока данных при успехе. Формат блока данных: номер пакета, 128 байт данных и 2 байта контрольной суммы. В Xmodem на принимающей стороне приходится вручную указывать имя файла |
Kermit |
Наиболее распространенный протокол, использующий блоки переменной длины с максимальным размером 94 байта (программы написаны на Си или ФОРТРАН). Является пакетным протоколом, позволяя пересылать за один раз несколько файлов, для повышения эффективности пересылки использует предварительную архивацию и коррекцию ошибок (Колумбийский университет, 1981г.). |
Modem7 |
Усовершенствованная версия xmodem для работы по коммутируемым телефонным каналам (передается имя файла). |
Xmodem/1024 |
Разновидность Xmodem с размером блока данных 1024 байта. |
Xmodem/CRC |
Разновидность xmodem, использующая 16 битовую crc. |
Telink |
Передается кроме имени файла, дата, время, можно передать несколько файлов за одну сессию. |
Ymodem |
Протокол использует CRC-16, передает имена файлов, размер, дату создания и время, в зависимости от условий передачи размер блока варьируется от 128 до 1024 байт (Чак Форсберг, 1984-85). |
Sealink |
Модификация протокола ymodem. |
Zmodem |
Протокол использует CRC-32 (или CRC-16), динамическое изменение размера блока (32-1024 байта), автоматический выбор протокола обмена, сжатие файлов при пересылке, возобновление передачи с прерванного места в случае разрыва связи. На сегодня это самый совершенный протокол. |
Чтобы обеспечить безопасность и исключить несанкционированный доступ к сети, можно воспользоваться методом “обратного телефонного вызова”, некоторые модемы реализуют его аппаратно. Метод предполагает, что после установления связи и проверки авторизации связь прерывается, а входной модем сети производит набор номера клиента, который хранится в памяти, и устанавливает связь повторно. Такая схема исключает передачу входного пароля друзьям или знакомым, так как это становится бессмысленным - модем будет пытаться установить связь по номеру вашего домашнего телефона.
Модемы обычно имеют дисплей, который позволяет контролировать работу этого прибора. Модемы разных производителей имеют различные типы дисплеев, ниже приведен список наиболее часто встречающихся индикаторов.
MR |
Модем включен и готов к работе (modem ready); |
TR |
“Терминал готов” (terminal ready) - включается, когда модем обнаруживает сигнал tdr (data terminal ready), передаваемый вашим программным обеспечением; |
HS |
Индикатор включается, когда модем работает на максимальной для него скорости (high speed). |
CD |
Обнаружен несущий сигнал (carrier detected), гаснет лишь тогда, когда "партнер положит трубку"; |
AA |
Модем включен в режим авто-ответа (auto answer); |
OH |
Модем занял линию - “трубка снята” (off-hook); |
RD |
Индикатор мигает (receive data), когда ЭВМ принимает данные из своего модема. |
SD |
Индикатор (send data) мигает при передаче данных из ЭВМ в модем. |
RL |
Индикатор (reliable link) указывает на то, что модем договорился с партнером о типе протокола MNP. |
RD |
Принимаются данные (receive data). Индикатор мигает при передаче данных в ЭВМ. |
TS |
Модем находится в режиме самотестирования. |
PWR |
Включено питание модема. |
| V.17 | 9.6 или 14.4 Кбит/с |
V.21 |
200 бит/с (используется только на этапе установления связи) |
V.27ter |
2.4 или 4.8 Кбит/с |
V.29 |
7.2 или 9.6 Кбит/с |
V.527ter |
2400 или 4800 бит/с |
/p> Для обеспечения работы факс- модема пригодны программы: Bitfax, Winfax, Quicklink или любая другая, поставляемая вместе с приобретенным вами модемом. Следует иметь в виду, что для пересылки через факс-модем традиционного документа, подготовленного на типографском бланке, написанного от руки и т.д., вам потребуется сканнер. В перспективе факс-технология будет вытеснена электронной почтой, которая эффективнее и, при необходимости, может обеспечить большую безопасность.
В настоящее время технология модемов продолжает развиваться, появились и активно внедряются кабельные модемы, много усилий тратится на развитие ADSL (см. http://www.adsl.com/general_tutorial.html (asymmetric digital subscriber line), SDSL (single line digital subscriber line), hdsl (high data rate digital subscriber line), VDSL (very high data rate digital subscriber line) и некоторых других технологий, связанных с передачей мультимедиа данных. (См. XDSL. atg’s communications & networking technology guide series. pairgain, copperoptics company; http://www.techguide.com/). Эти технологии предназначены для обеспечения широкополосного канала между провайдером и конечным пользователем (проблема последней мили). [Должен заметить, что миля мера иностранная и российским 1,853 км, если речь идет о телефонных кабелях, не соответствует. Провода у нас другого качества и наша миля как бы длиннее, если судить по искажениям сигнала и шумам]. Здесь используются три метода модуляции (2B1Q, CAP и DMT). ADSL позволяет приспособить обычные телефонные линии для мультимедийных приложений и для высокоскоростной передачи данных (до 6 Мбит/с). Два ADSL-модема, соединенные скрученной парой проводов образуют три информационных канала: скоростной однонаправленный (нисходящий) канал (1,5-6,1 Мбит/с), среднескоростной дуплексный канал (16-640 Кбит/с) и POTS-канал (plain old telephone service). POTS сохраняет работоспособность даже при отказе ADSL. Каждый из этих каналов может мультиплексироваться, образуя каналы меньшего быстродействия. ADSL-модемы могут работать и с ATM-сетями, но следует учитывать их принципиальную асимметричность – передача в одном направлении и в другом имеет разную скорость. Для передачи данных в сети Интернет это не удобно. Но для транспортировки телевизионного сигнала такая схема представляется вполне эффективной.
Для провода длиной 5, 5 км при диаметре сечения 0,5 мм (стандартные условия для isdn) пропускная способность составляет 1,5 - 2,0 Мбит/с (верхний край полосы пропускания около 1 МГц). При организации дуплексного канала весь частотный диапазон делится пополам и одна из частей используется для передачи данных в одном направлении, другая - в противоположном. Каждый из частотных диапазонов в свою очередь делится на части и для каждой из них используется техника эхо-подавления. Для POTS-канала выделяется 4 кГц в низкочастотной части диапазона.
HDSL представляет собой способ передачи потоков T1 или E1 по скрученным парам проводов с использованием улучшенной техники модуляции (для передачи 1,544-2,048 Мбит/с достаточно полосы 80-240 кГц). SDSL представляет собой версию HDSL с одной скрученной парой. Ниже в таблице 4.3.7.5 приведены сравнительные данные для различных систем передачи информации.
Таблица 4.3.7.5. Свойства различных систем (модемов) передачи информации.
Название |
Расшифровка |
Длина канала при 24 awg (0,5мм) |
Быстродействие |
Применение |
|
V.22 V.32 V.34 |
Модемы голосового диапазона | 12 км |
1200 бит/c 28800 бит/c |
Передача данных |
| DSL | digital subscriber line | 5,4 км | 160 Кбит/с | Услуги ISDN, передача данных и голоса |
| HDSL | high data rate digital subscriber line | 3,6 км |
1,544 Мбит/с 2,048 Мбит/с |
t1/e1 каналы, локальные и региональные сети. |
| SDSL | single line digital subscriber line | - |
1,544 Мбит/с 2,048 Мбит/с |
t1/e1 каналы, локальные и региональные сети |
| ADSL | asymmetric digital subscriber line | 3,6/5,4 км |
1,5-9 Мбит/с или 16-640 Кбит/c | Доступ к Интернет, видео, интерактивное мультимедиа. |
| VDSL | very high data rate digital subscriber line | - |
13-52 Мбит/с или 1,5-2,3 Мбит/с |
То же, что и ADSL плюс HDTV |
Рис. 4.3.7.3. Ограничения пропускной способности для разных типов канала
DSL представляет собой канал ISDN-BRI (Basic Rate Interface; 2*64 + 16 Кбит/c), совместимый с POTS, ISDN и DDS. На рис. 4.3.7. 3 показаны области применимости различных канальных технологий.
Для 5 Мбит/с при симметричной нагрузке можно работать до расстояний 1500 м (VDSL).
Для 10 Мбит/с при симметричной нагрузке можно работать до расстояний 1200 м.
Для 15 Мбит/с при симметричной нагрузке можно работать до расстояний 1000 м.
Метод модуляции 2B1Q характеризуется четырьмя уровнями амплитудной модуляции (4-PAM; +3, +1, -1 и -3). CAP-модуляция (Carrierless Amplitude and Phase) характеризуется четырьмя уровнями амплитуды и четырьмя фиксированными значениями фазы, что дает в плоскости амплитуда-фаза 16 независимых состояний. DTM-модуляция (Discrete Multi-tone) предполагает использование нескольких смежных, узких частотных диапазонов. На рис. 4.3.7.2 показана схема подключения оборудования ADSL для различных оконечных терминалов.

Рис. 4.3.7.4. Схема подключения оборудования ADSL (IF – ADSL/Ethernet интерфейс)
В качестве внешней сети на рис. 4.3.7.4 может использоваться практически любая достаточно быстродействующая среда, например ATM. Выбор того или иного внешнего канала зависит от стоящей задачи. Так файл размером 30 Кбайт (среднего размера электронное сообщение) будет передан через модем V.34 за 8,3 сек, по каналу ISDN – за 1,9 сек, по каналу HDSL – за 0,16 сек, а по каналу VDSL – быстрее 0,04 сек. В большинстве случаев вполне приемлемым можно считать уже первые два варианта. Деловой электронный документ имеет размер порядка 250 Кбайт. Здесь для пересылки его указанными способами потребуется уже, соответственно: 69,4; 15,6; 1,3 и 0,3 секунды. Более чем минутное время доставки (в реальности это обычно больше) в некоторых случаях не будет признано удовлетворительным. Время пересылки рентгенограммы (~5 Мбайт) будет пропорционально больше (23 мин, 5,2 мин, 26 сек и 6,5 сек). Считается, что приемлемым временем отклика на команду следует считать 3 секунды, а до 80% трафика локальной сети составляет внешний поток данных. Если же стоит задача организации видеоконференции (384 Кбит/с), то решение проблемы возможно уже только с использованием каналов xDSL. Учитывая стремительный рост потребной пропускной способности каналов, не трудно предсказать перспективность внедрения технологии xDSL.
Пример использования модема ADSL для подключения телевизора и модема к широкополосному каналу представлен на рис. 4.3.7.5. Управляющий канал на 16 кбит/с может использоваться для целей интерактивного телевидения (смотри раздел "Методы преобразования и передачи изображения").

Рис. 4.3.7.5. Схема подключения телевизора и телефона через модем ADSL
Мультикастинг и MBONE
4.4.9.1 Мультикастинг и MBONE
Семенов Ю.А. (ГНЦ ИТЭФ)
MBONE - это виртуальная сеть, базирующаяся на мультикастинг-протоколах, которые были одобрены IETF летом 1992 года. В основу легли разработки, выполненные в компании Ксерокс. Данный режим работы поддерживается не всеми маршрутизаторами. Сеть представляет собой систему Ethernet-сетей, объединенных друг с другом соединениями точка-точка, которые называются "туннелями". Конечными точками таких туннелей обычно являются машины класса рабочих станций, снабженные соответствующим программным обеспечением. Впервые мультикастинг-туннель был реализован в Стэнфордском университете в 1988 году.
IP-мультикастинг-пакеты инкапсулируются при передаче через туннели так, что они выглядят как обычные IP-уникаст-пакеты.
Мультикастинг-маршрутизатор при посылке пакета через туннель подготавливает IP-пакет с заголовком, который содержит адрес маршрутизатора-партнера на другом конце туннеля, при этом поле IP-протокола содержит код 4 (IP). Маршрутизатор-приемник извлекает вложенный мультикастинг-пакет и направляет далее, если это требуется.
MBONE требует пропускной способности магистральных каналов не ниже 500Kбит/с.
Каждый туннель имеет определенный порог для переменной времени жизни пакета (time-to-live - TTL). Согласно договоренности (IETF) широкополосная видео-информация передается с малыми начальными значениями TTL. Малые значения TTL не позволяет видео-пакетам загружать слишком большие участки сети. Мультикастинг-дейтограмма с TTL=0 может быть доступна только процессу, существующему в ЭВМ, породившей эту дейтограмму. По умолчанию мультикастинг-дейтограммы имеют TTL=1, такая дейтограмма не может покинуть пределов субсети, и только дейтограммы с TTL>1 могут переадресовываться маршрутизаторами. Следует помнить, что маршрутизатор не откликнется ICMP-сообщением "время истекло", когда TTL достигнет нуля, так как вообще дейтограммы с мультикастинг-адресами не вызывают ICMP-откликов. Увеличивая TTL, прикладной процесс может расширять "зону взаимодействия". Сначала дейтограмма может посылаться с TTL=1, если отклика не получено, c TTL=2 и так далее. Эта схема позволяет найти ближайший сервер (с точки зрения числа шагов до него). Для приложений, которые ограничивают свою активность в пределах одного шага, предусмотрен специальный интервал адресов 224.0.0.0 - 224.0.0.255. Мультикастинг-маршрутизатор не должен переадресовывать дейтограммы с такими адресами вне зависимости от значения TTL. Адрес 224.0.0.1 является адресом группы "все ЭВМ" и относится ко всем ЭВМ и маршрутизаторам, способным работать в режиме мультикастинга. Каждая ЭВМ автоматически включается в эту группу при инициализации интерфейса. О членстве в этой группе ЭВМ не сообщает.
Конфигурация системы в режиме мультикастинга производится автоматически. Для того чтобы изменить конфигурацию системы, или добавить еще один туннель используются специальные конфигурационные команды, которые записываются в /etc/mrouted.conf. Существует два типа таких команд:
phyint <local-addr> [disable] [metric <m>] [threshold <t>]
tunnel <local-addr> <remote-addr> [metric <m>] [threshold <t>]
Первая команда может отменить мультикастинг-маршрутизацию для конкретного физического интерфейса, идентифицируемого по его IP-адресу (<local-addr>), или заменить значение метрики или порога. Эта команда должна выдаваться до команды tunnel. Последняя команда может служить для установления туннеля между местным IP-адресом (<local-addr>) и удаленным IP-адресом (<remote-addr>). Значения метрики и порога по умолчанию равны 1.
Специфика мультикастинг-туннелей требует принципиально новых решений задачи маршрутизации, первой попыткой разрешить эту проблему был протокол DVMRP. Следует иметь в виду, что DVMRP может решить лишь часть задачи, хотя бы потому, что это внутренний протокол. Главной особенностью мультикастинг-маршрутизации является то, что нужно проложить маршруты от источника к совокупности адресатов, от которых пришли запросы участия в процессе. Режим мультикастинга поддерживается не всеми маршрутизаторами Интернет. Возможны конфликты при решении задачи маршрутизации, когда транзитный маршрутизатор не имеет "своих" участников группы (а должен выделить заметный ресурс каналов для удовлетворения внешних запросов).
Набор AT-команд модемов
10.9 Набор AT-команд модемов
Семенов Ю.А. (ГНЦ ИТЭФ)
AT-команды посылаются ЭВМ или терминалом модему через последовательный интерфейс RS-232 (модем должен быть при этом в командном режиме). Все эти команды начинаются с префикса AT, за исключением A/, A> и +++. Код A/ вызывает выполнение модемом предыдущей команды, A> заставляет модем выполнять предыдущую команду до 9 раз или пока не будет нажата какая-либо клавиша терминала или управляющей панели модема, или пока не будет установлена связь с удаленным модемом. Команда +++ (ESC-последовательность) переводит модем в командный режим или возвращает его в режим передачи данных.Таблица 10.9.1. Стандартные AT-команды
Обозначение команды
Описание функции команды
A Включает режим отклика (снимается трубка, выполняется подключение к линии) + B0 Выбирает режим CCITT V.22 (1200бит/с, по умолчанию) B1 Выбирает для коммуникации стандарт Bell 212A (1200 бит/с) D Вход в базовый режим, набор номера и попытка соединения с удаленным модемом.
Числа и модификаторы, применимые с командой D:
0-9,#,* - цифры набора номера. Ниже следуют модификаторы набора.
P - Импульсный набор.
T - Тоновый набор.
R - Начинает вызов в режиме отклика. Вводится как последняя цифра.
S - Набирается номер, записанный в памяти.
W - Ожидание длинного гудка перед набором (длительность ожидания определяется S7, по умолчанию 30сек).
, - Пауза на время, заданное S8 (по умолчанию 2сек).
; - Возврат в командный режим после набора номера.
@ - Ожидание 5 сек. молчания прежде чем продолжить, в противном случае возврат (NO ANSWER).
DL
Набор номера, использованного последним.
DSn
Набор номера, записанного в EEPROM в позиции n(0-9).
E0
Запрет символьного отклика в командном режиме.
+ E1
Разрешает символьный отклик в командном режиме.
Fn
Переключение между дуплексным и полудуплексным режимами (n=0 - полудуплексный; n=1 - дуплексный).
H0
Вешание трубки и отключение от линии
H1
Снятие трубки и подключение к линии
I0
Отображение информации о модеме (идентификационный код)
I1
Отображение результата проверки контрольной суммы ROM (EPRROM).
I2
Проверяется состояние внутренней памяти ROM и возвращается сообщение OK или CHECKSUM ERROR.
I3
Выдается версия модема
I4
Модем передает ЭВМ строку, заданную производителем модема.
I5
Выдается код страны производителя.
I6
Выдается код модели модема
L0-7
Управление громкостью динамика (по умолчанию L4).
M0
Громкоговоритель всегда выключен.
+ M1
Громкоговоритель включен пока не обнаружена несущая.
M2
Громкоговоритель всегда включен.
M3
Громкоговоритель включен после набора последней цифры и выключается после детектирования несущей.
N0-7
Управление громкостью звонка. N0 запретит звонок при приходе сигнала вызова.
O
Возвращение в состояние on line.
P
Импульсный набор
+ Q0
Модем возвращает код результата (по умолчанию)
Q1
Модем не возвращает код результата
Q2
Модем возвращает код результата, но отключается после ответа на звонок.
Sr=n
Записывает в S-регистр r код n, n должно быть десятичным числом в интервале 0-255.
Sr ?
Отображает код, записанный в регистре r.
+ T
Тоновый набор (по умолчанию)
V0
Отображает код результата в сжатой цифровой форме.
+ V1
Отображает код результата в символьной форме (по умолчанию)
Xn
Опции отображения работы и кодов результата (по умолчанию X5). Определяет набор сообщений, управляет определением сигнала “занято” и проверкой наличия гудка.
Yn
Определяет способ отключения модема от линии. Команда Y1 заставляет модем повесить трубку, если от удаленного модема получен сигнал BREAK. Команда Y0 запрещает прерывать связь при получении длительного сигнала BREAK
Wn
Записывает текущую конфигурацию модема в профайл n.
Zn
Устанавливает конфигурацию модема из профайла n (n=0-3). Z4 устанавливает заводской набор параметров модема.
Символ “+” указывает на то, что данный режим является режимом по умолчанию.
Команда X0 заставляет модем посылать сообщения в короткой форме. Номер набирается после паузы вне зависимости от наличия гудка. Состояние “занято” не распознается. После команды X1 модем посылает сообщения в полной форме. Команда X2 отличается от X1 и X0 тем, что набор номера выполняется лишь при наличии гудка. Команда X3 требует полной формы сообщений, номер набирается после паузы вне зависимости от наличия гудка, сигнал занято идентифицируется. Команда X4 сходна с X3, но требует для набора наличия гудка. При получении команд X2 или X4 модем разрывает связь и кладет трубку, если удаленный модем переведет линию в состояние BREAK на 1,6 секунды.
Существует несколько команд вывода справочной информации (работают не на всех модемах):
| $ | справочная информация по базовому набору команд; |
| &$ | справочная информация по расширенному набору команд (названия команд начинаются с символа &); |
| *$ | справочная информация по улучшенному набору команд. |
Команда |
Описание |
| &B0 | DTE/DCE скорость следует за быстродействием линии. |
| + &B1 | DTE/DCE скорость зафиксирована на уровне заданном DTE (300-76800 бит/с, режим по умолчанию) |
| &C0 | Предполагает, что несущая всегда присутствует (делает CD=ON) |
| + &C1 | CD отслеживает наличие несущей (по умолчанию.) |
| &D0 | Игнорируется DTR сигнал, предполагает DTR=ON. |
| &D1 | Переключение DTR OFF->ON вызывает набор номера по умолчанию. |
| &D2 | DTR OFF вызывает отключение от линии и переход модема в командный режим. |
| &D3 | Аналогична &D2, но вызывает также загрузку профайла 0. |
| &F | Загружает в RAM заводской набор параметров модема. |
| &K0 | Никакого контроля ошибок. |
| &K1 | MNP4 (включая MNP3) |
| &K2 | MNP4 + MNP5 |
| &K3 | V.42 (эквивалентно &K1) |
| + &K4 | V.42 + V.42bis (эквивалентно &K2) |
| + &L0 | Выход в обычную городскую телефонную сеть (по умолчанию) |
| &L1 | 2-проводная выделенная линия. |
| &L2 | 4-проводная выделенная линия |
/p> Пример записи AT-команды: ATDnnnnnnnnn, где последовательность символов n включает номер телефона и модификаторы набора (к модификаторам можно отнести P и T, указывающие на импульсный и тоновый тип набора соответственно. Допускается и более удобная для восприятия запись: ATD 8, (095) 123-94-42.
Таблица 10.9.3. Сообщения модема (коды результата Xn)
Код |
Название |
Описание |
| 0 | OK | Команда выполнена без ошибок |
| 1 | Connect | Установлена связь на скорости 300 бит/с (после реализации команд X1, X2, X3, X4) или на скорости 600, 1200, 2400 бит/с (после команды X0) |
| 2 | Ring | Обнаружен сигнал звонка. Этот код модем передает ЭВМ каждый раз, когда поступает сигнал вызова. |
| 3 | No Carrier | Потеряна или не получена несущая от удаленного модема. |
| 4 | Error | Обнаружена ошибка в командной строке, переполнен командный буфер или обнаружена ошибка контрольной суммы. |
| 5 | Connect 1200 | Установлена связь на скорости 1200 бит/с (см. команды X1, X2, X3, X4). |
| 6 | No Dial Tone | Нет сигнала (гудка) при снятии трубки (см. команды X2, X4) |
| 7 | Busy | Обнаружен сигнал <занято> после набора номера. |
| 8 | No Answer | Отклик может быть получен при использовании в командной строке символа @, если не выполнено условие - 5-сек тишины. |
| 9 | Ringing | Пришел вызов (звонок) |
| 10 | Connect 2400 | Установлена связь на скорости 2400бит/с (см. команды X1, X2, X3, X4). |
| 11 | Connect 4800 | Установлена связь на скорости 4800бит/с |
| 12 | Connect 9600 | Установлена связь на скорости 9600бит/с |
| 14 | Connect 19200 | Установлена связь на скорости 19200бит/с |
| 15 | Connect 7200 | Установлена связь на скорости 7200бит/с |
| 16 | Connect 12000 | Установлена связь на скорости 12000бит/с |
| 17 | Connect 14400 | Установлена связь на скорости 14400бит/с |
| 18 | Connect 16800 | Установлена связь на скорости 16800бит/с |
| 19 | Connect 38400 | Установлена связь на скорости 38400бит/с |
| 20 | Connect 57600 | Установлена связь на скорости 57600бит/с |
| 21 | Connect 76800 | Установлена связь на скорости 76800бит/с |
Национальные коды доменов в Интернет
10.12 Национальные коды доменов в Интернет
Семенов Ю.А. (ГНЦ ИТЭФ)

Обычно завершающий код Internet-адреса определяет государственную принадлежность узла, сервера или ЭВМ (информация взята на сервере RIPE Network Coordination Center (X.500 в ISO 3166)). Информация упорядочена согласно англоязычным названиям стран.
Страна
Английское название
Двухбуквенный код
Трехбуквенный код
Числовой код
Афганистан
AFGHANISTAN
AF
AFG
004
Албания
ALBANIA
AL
ALB
008
Алжир
ALGERIA
DZ
DZA
012
Американское Самоа
AMERICAN SAMOA
AS
ASM
016
Андорра
ANDORRA
AD
AND
020
Ангола
ANGOLA
AO
AGO
024
ANGUILLA
AI
AIA
660
Антарктика
ANTARCTICA
AQ
ATA
010
Антигуа и Барбуда
ANTIGUA AND BARBUDA
AG
ATG
028
Аргентина
ARGENTINA
AR
ARG
032
Армения
ARMENIA
AM
ARM
051
Аруба
ARUBA
AW
ABW
533
Австралия
AUSTRALIA
AU
AUS
036
Австрия
AUSTRIA
AT
AUT
040
Азербайджан
AZERBAIJAN
AZ
AZE
031
Багамские острова
BAHAMAS
BS
BHS
044
Бахрейн
BAHRAIN
BH
BHR
048
Бангладеш
BANGLADESH
BD
BGD
050
Барбадос
BARBADOS
BB
BRB
052
Беларусь
BELARUS
BY
BLR
112
Бельгия
BELGIUM
BE
BEL
056
Белиз
BELIZE
BZ
BLZ
084
Бенин
BENIN
BJ
BEN
204
Бермудские острова
BERMUDA
BM
BMU
060
Бутан
BHUTAN
BT
BTN
064
Боливия
BOLIVIA
BO
BOL
068
Босния и Герцеговина
BOSNIA AND HERZEGOWINA
BA
BIH
070
Ботсвана
BOTSWANA
BW
BWA
072
BOUVET ISLAND
BV
BVT
074
Бразилия
BRAZIL
BR
BRA
076
Британская территория в Индийском океане
BRITISH INDIAN OCEAN TERRITORY
IO
IOT
086
Бруней
BRUNEI DARUSSALAM
BN
BRN
096
Болгария
BULGARIA
BG
BGR
100
Буркина Фасо
BURKINA FASO
BF
BFA
854
Бурунди
BURUNDI
BI
BDI
108
Камбоджа
CAMBODIA
KH
KHM
116
Камерун
CAMEROON
CM
CMR
120
Канада
CANADA
CA
CAN
124
CAPE VERDE
CV
CPV
132
Каймановы острова
CAYMAN ISLANDS
KY
CYM
136
Центрально Африканская Республика
CENTRAL AFRICAN REPUBLIC
CF
CAF
140
Чад
CHAD
TD
TCD
148
Чили
CHILE
CL
CHL
152
Китай
CHINA
CN
CHN
156
Остров Рождества
CHRISTMAS ISLAND
CX
CXR
162
Кокосовые острова
COCOS (KEELING) ISLANDS
CC
CCK
166
Колумбия
COLOMBIA
CO
COL
170
Каморы
COMOROS
KM
COM
174
Конго
CONGO
CG
COG
178
Острова Кука
COOK ISLANDS
CK
COK
184
Коста-Рика
COSTA RICA
CR
CRI
188
Кот де Вуар
COTE D'IVOIRE
CI
CIV
384
Хорватия
CROATIA
HR
HRV
191
Куба
CUBA
CU
CUB
192
Кипр
CYPRUS
CY
CYP
196
Чешская республика
CZECH REPUBLIC
CZ
CZE
203
Дания
DENMARK
DK
DNK
208
Джибути
DJIBOUTI
DJ
DJI
262
Доминика
DOMINICA
DM
DMA
212
Доминиканская республика
DOMINICAN REPUBLIC
DO
DOM
214
Восточный Тимор
EAST TIMOR
TP
TMP
626
Эквадор
ECUADOR
EC
ECU
218
Египет
EGYPT
EG
EGY
818
Сальвадор
EL SALVADOR
SV
SLV
222
Экваториальная Гвинея
EQUATORIAL GUINEA
GQ
GNQ
226
Эритрея
ERITREA
ER
ERI
232
Эстония
ESTONIA
EE
EST
233
Эфиопия
ETHIOPIA
ET
ETH
231
Фолклендские острова
FALKLAND ISLANDS
FK
FLK
238
Острова Фаро
FAROE ISLANDS
FO
FRO
234
Фиджи
FIJI
FJ
FJI
242
Финляндия
FINLAND
FI
FIN
246
Франция
FRANCE
FR
FRA
250
Франция, метрополия
FRANCE, METROPOLITAN
FX
FXX
249
Французская Гвинея
FRENCH GUIANA
GF
GUF
254
Французская Полинезия
FRENCH POLYNESIA
PF
PYF
258
Французские Южные территории
FRENCH SOUTHERN TERRITORIES
TF
ATF
260
Габон
GABON
GA
GAB
266
Гамбия
GAMBIA
GM
GMB
270
Грузия
GEORGIA
GE
GEO
268
Германия
GERMANY
DE
DEU
276
Гана
GHANA
GH
GHA
288
Гибралтар
GIBRALTAR
GI
GIB
292
Греция
GREECE
GR
GRC
300
Гренландия
GREENLAND
GL
GRL
304
Гренада
GRENADA
GD
GRD
308
Гваделупа
GUADELOUPE
GP
GLP
312
Гуам
GUAM
GU
GUM
316
Гватемала
GUATEMALA
GT
GTM
320
Гвинея
GUINEA
GN
GIN
324
Гвинея-Биссау
GUINEA-BISSAU
GW
GNB
624
Гайана
GUYANA
GY
GUY
328
Гаити
HAITI
HT
HTI
332
HEARD AND MC DONALD ISLANDS
HM
HMD
334
Гондурас
HONDURAS
HN
HND
340
Гонконг
HONG KONG
HK
HKG
344
Венгрия
HUNGARY
HU
HUN
348
Исландия
ICELAND
IS
ISL
352
Индия
INDIA
IN
IND
356
Индонезия
INDONESIA
ID
IDN
360
Иран
IRAN
IR
IRN
364
Ирак
IRAQ
IQ
IRQ
368
Ирландия
IRELAND
IE
IRL
372
Израиль
ISRAEL
IL
ISR
376
Италия
ITALY
IT
ITA
380
Ямайка
JAMAICA
JM
JAM
388
Япония
JAPAN
JP
JPN
392
Иордания
JORDAN
JO
JOR
400
Казахстан
KAZAKHSTAN
KZ
KAZ
398
Кения
KENYA
KE
KEN
404
Кирибати
KIRIBATI
KI
KIR
296
КНДР
KOREA, DEMOCRATIC PEOPLE'S REPUBLIC OF
KP
PRK
408
Корея
KOREA
KR
KOR
410
Кувейт
KUWAIT
KW
KWT
414
Киргизстан
KYRGYZSTAN
KG
KGZ
417
Лаос
LAO PEOPLE'S DEMOCRATIC REPUBLIC
LA
LAO
418
Латвия
LATVIA
LV
LVA
428
Леван
LEBANON
LB
LBN
422
Лесото
LESOTHO
LS
LSO
426
Либерия
LIBERIA
LR
LBR
430
Ливия
LIBYAN ARAB JAMAHIRIYA
LY
LBY
434
Лихтенштейн
LIECHTENSTEIN
LI
LIE
438
Литва
LITHUANIA
LT
LTU
440
Люксембург
LUXEMBOURG
LU
LUX
442
Макао
MACAU
MO
MAC
446
Македония
MACEDONIA,
MK
MKD
807
Мадагаскар
MADAGASCAR
MG
MDG
450
Малави
MALAWI
MW
MWI
454
Малайзия
MALAYSIA
MY
MYS
458
Мальдивские острова
MALDIVES
MV
MDV
462
Мали
MALI
ML
MLI
466
Мальта
MALTA
MT
MLT
470
Маршалловы острова
MARSHALL ISLANDS
MH
MHL
584
Мартиника
MARTINIQUE
MQ
MTQ
474
Мавритания
MAURITANIA
MR
MRT
478
Маврикий
MAURITIUS
MU
MUS
480
MAYOTTE
YT
MYT
175
Мексика
MEXICO
MX
MEX
484
Микронезия
MICRONESIA
FM
FSM
583
Молдова
MOLDOVA
MD
MDA
498
Монако
MONACO
MC
MCO
492
Монголия
MONGOLIA
MN
MNG
496
MONTSERRAT
MS
MSR
500
Марокко
MOROCCO
MA
MAR
504
Мозамбик
MOZAMBIQUE
MZ
MOZ
508
MYANMAR
MM
MMR
104
Намибия
NAMIBIA
NA
NAM
516
Остров Науру
NAURU
NR
NRU
520
Непал
NEPAL
NP
NPL
524
Нидерланды
NETHERLANDS
NL
NLD
528
Нидерландские Антиллы
NETHERLANDS ANTILLES
AN
ANT
530
Новая Каледония
NEW CALEDONIA
NC
NCL
540
Новая Зеландия
NEW ZEALAND
NZ
NZL
554
Никарагуа
NICARAGUA
NI
NIC
558
Нигер
NIGER
NE
NER
562
Нигерия
NIGERIA
NG
NGA
566
NIUE
NU
NIU
570
Остров Норфолк
NORFOLK ISLAND
NF
NFK
574
Северные Марианские острова
NORTHERN MARIANA ISLANDS
MP
MNP
580
Норвегия
NORWAY
NO
NOR
578
Оман
OMAN
OM
OMN
512
Пакистан
PAKISTAN
PK
PAK
586
Остров Палау
PALAU
PW
PLW
585
Панама
PANAMA
PA
PAN
591
Папуа Новая Гвинея
PAPUA NEW GUINEA
PG
PNG
598
Парагвай
PARAGUAY
PY
PRY
600
Перу
PERU
PE
PER
604
Филиппины
PHILIPPINES
PH
PHL
608
Остров Питкэрн
PITCAIRN
PN
PCN
612
Польша
POLAND
PL
POL
616
Португалия
PORTUGAL
PT
PRT
620
Пуэрто-Рико
PUERTO RICO
PR
PRI
630
Катар
QATAR
QA
QAT
634
Реюньон
REUNION
RE
REU
638
Румыния
ROMANIA
RO
ROM
642
Россия
RUSSIAN FEDERATION
RU
RUS
643
Руанда
RWANDA
RW
RWA
646
Сант Китс и Невис
SAINT KITTS AND NEVIS
KN
KNA
659
Сент-Люсия
SAINT LUCIA
LC
LCA
662
Сент-Винсент и Гренадины
SAINT VINCENT AND THE GRENADINES
VC
VCT
670
Самоа
SAMOA
WS
WSM
882
Сан-Марино
SAN MARINO
SM
SMR
674
Сан Томе и Принсипи
SAO TOME AND PRINCIPE
ST
STP
678
Саудовская Аравия
SAUDI ARABIA
SA
SAU
682
Сенегал
SENEGAL
SN
SEN
686
Сейшельские острова
SEYCHELLES
SC
SYC
690
Сиерра-Леоне
SIERRA LEONE
SL
SLE
694
Сингапур
SINGAPORE
SG
SGP
702
Словакия
SLOVAKIA
SK
SVK
703
Словения
SLOVENIA
SI
SVN
705
Соломоновы острова
SOLOMON ISLANDS
SB
SLB
090
Сомали
SOMALIA
SO
SOM
706
Южная Африка
SOUTH AFRICA
ZA
ZAF
710
Южная Георгия и Южные Сэндвичевы острова
SOUTH GEORGIA AND THE SOUTH SANDWICH ISLANDS
GS
SGS
239
Испания
SPAIN
ES
ESP
724
Шри-Ланка
SRI LANKA
LK
LKA
144
Св. Елена
ST. HELENA
SH
SHN
654
Сен-Пьер и Микелон
ST. PIERRE AND MIQUELON
PM
SPM
666
Судан
SUDAN
SD
SDN
736
Суринам
SURINAME
SR
SUR
740
Острова Свалбард и Ян-Майена
SVALBARD AND JAN MAYEN ISLANDS
SJ
SJM
744
Свазиленд
SWAZILAND
SZ
SWZ
748
Швеция
SWEDEN
SE
SWE
752
Швейцария
SWITZERLAND
CH
CHE
756
Сирия
SYRIAN ARAB REPUBLIC
SY
SYR
760
Тайвань
TAIWAN, PROVINCE OF CHINA
TW
TWN
158
Таджикистан
TAJIKISTAN
TJ
TJK
762
Танзания
TANZANIA
TZ
TZA
834
Таиланд
THAILAND
TH
THA
764
Того
TOGO
TG
TGO
768
Острова Токелау
TOKELAU
TK
TKL
772
Тонга
TONGA
TO
TON
776
Тринидад и Тобаго
TRINIDAD AND TOBAGO
TT
TTO
780
Тунис
TUNISIA
TN
TUN
788
Турция
TURKEY
TR
TUR
792
Туркменистан
TURKMENISTAN
TM
TKM
795
TURKS AND CAICOS ISLANDS
TC
TCA
796
Тувалу
TUVALU
TV
TUV
798
Уганда
UGANDA
UG
UGA
800
Украина
UKRAINE
UA
UKR
804
Объединенные арабские Эмираты
UNITED ARAB EMIRATES
AE
ARE
784
Великобритания
UNITED KINGDOM
GB
GBR
826
Соединенные Штаты
UNITED STATES
US
USA
840
UNITED STATES MINOR OUTLYING ISLANDS
UM
UMI
581
Уругвай
URUGUAY
UY
URY
858
Узбекистан
UZBEKISTAN
UZ
UZB
860
Вануату
VANUATU
VU
VUT
548
Ватикан
VATICAN CITY STATE (HOLY SEE)
VA
VAT
336
Венесуэла
VENEZUELA
VE
VEN
862
Вьетнам
VIET NAM
VN
VNM
704
Виргинские острова (ВБ)
VIRGIN ISLANDS (BRITISH)
VG
VGB
092
Виргинские острова (США)
VIRGIN ISLANDS (U.S.)
VI
VIR
850
Острова Эллис и Футуна
WALLIS AND FUTUNA ISLANDS
WF
WLF
876
Западная Сахара
WESTERN SAHARA
EH
ESH
732
Йемен
YEMEN
YE
YEM
887
Югославия
YUGOSLAVIA
YU
YUG
891
Заир
ZAIRE
ZR
ZAR
180
Замбия
ZAMBIA
ZM
ZMB
894
Зимбабве
ZIMBABWE
ZW
ZWE
716
Наиболее употребимые сокращения, используемые в телекоммуникациях (с разбивкой по буквам)
10.10 Наиболее употребимые сокращения, используемые в телекоммуникациях (с разбивкой по буквам)

Обширный файл английских сокращений по данной тематике можно найти по адресу ftp.temple.edu /pub/info/help-net/babel95c.txt. Возможен доступ к этому файлу и через listserv@vm.temple.edu или с помощью gopher.temple.edu, существуют и другие источники аналогичной информации, например, http://acm.org/~jochen _hayek/jochan_hayer_18.html#sec291 или www.srl.rmit.edu.au /pg/general/diction.htm. Там же можно найти много и других справочных данных.
Наложенные сети
4.2 Наложенные сети
Семенов Ю.А. (ГНЦ ИТЭФ)
В отличие от локальных наложенные сети не требуют использования специальных аппаратных средств для подключения. Так, если ЭВМ подключена к Ethernet (к ArcNet или Token Ring), нужны только соответствующие программные средства, чтобы она стала узлом сети Novell. Почтовая сеть (протоколы SMTP или UUCP) и сеть новостей (Usenet, протокол NNTP) относятся к наложенным сетям. Интернет (семейство протоколов TCP/IP) является также примером наложенной сети. Проблематика Интернет выделена в самостоятельный раздел лишь в силу объема и разнообразия материалов. Одна и та же ЭВМ может быть узлом нескольких разных наложенных сетей. Смешанные сети могут создавать проблемы для администраторов сетей, но для пользователей они дают лишь дополнительные возможности. В таких сетях неизбежно возникает проблема присвоения имен и установки соответствия между виртуальными и физическими адресами (в Интернет эта проблема решается с помощью протокола ARP).
