АДАПТЕР ПАРАЛЛЕЛЬНОГО ИНТЕРФЕЙСА
Передача данных в параллельном формате в общем случае является более высокоскоростной, чем передача в последовательном формате, поскольку все биты символа информации передаются параллельно по времени, т.е. одновременно. Однако это обстоятельство требует наличия достаточно большого числа физических цепей промежуточного интерфейса. Ввиду этого обмен по параллельным промежуточным интерфейсам обычно используется при работе микроЭВМ с близко расположенными высокоскоростными ПУ. Уже отмечалось, что одними из наиболее распространенных промежуточных интерфейсов являются интерфейс CENTRONICS и его модификации. Отмечалось также, что серийно выпускаются программируемые БИС адаптеров, поддерживающих интерфейс CENTRONICS и другие типы параллельных интерфейсов. Примером такого адаптера является БИС КР580ВВ55.
БИС КР580ВВ55 представляет собой программируемый адаптер параллельного интерфейса, позволяющий организовать обмен в параллельном коде практически с любым периферийным оборудованием. Структурная схема БИС адаптера приведена на рис. 8.10. Из структурной схемы БИС следует, что для подключения к линиям связи адаптер имеет три восьмибитовых порта A, B, C. Порты A и B не разделены, а порт C по существу представляет собой два четырехбитовых порта.
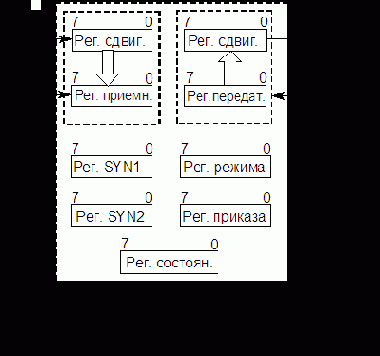
Программная модель адаптера приведена на рис. 8.11. Регистр состояния на рисунке изображен пунктиром, поскольку физически он отсутствует и его функции выполняет порт С.
Прием и передача данных через порты осуществляются разными регистрами. Т.е. каждый порт содержит регистр-защелку, в которой фиксируются данные для передачи в линию связи, и регистр, отображающий состояние линии связи при приеме. Подключение того или другого регистра к линии связи определяется режимами работы данного порта и осуществляется соответствующими управляющими сигналами. (Подробнее этот вопрос будет рассмотрен ниже.) Отметим, что выводы портов и разряды регистров портов связаны через переключающие схемы, что особенно важно помнить при изучении функционирования порта C в различных режимах.
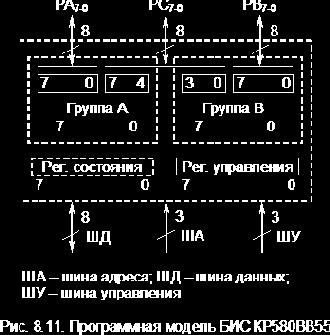
Для подключения к системной магистрали микроЭВМ используются 14 линий:
D7-0 – двунаправленная шина данных с трехстабильным буфером.
A1, A0 – линии адреса, которые выбирают внутренний регистр адаптера, подключаемый к ШД (00 – порт A, 01 – порт B, 10 – порт C и 11 – регистр управления).



RESET (сброс) – H-активный сигнал сброса для приведения адаптера в начальное состояние. При действии сигнала сброса в регистр управления записывается слово (приказ), переводящее все три порта в режим 0 и состояние ввода.
Следует иметь в виду, что есть запретные комбинации сигналов. Так, недопустимым является считывание информации из регистра управления, т.е. комбинация


Программирование и обмен данными с адаптером осуществляется обычно командами IN и OUT, при выполнении которых на линиях A7-0 (A15-8) выставляется код адреса. Обмен информацией с адаптером в этом случае можно вести только через аккумулятор. Входы A1, А0 адаптера обычно подключаются к младшим линиям ША, а подключение входа CS зависит от принятого способа выбора адаптера, если адаптеров несколько. В частности, если адаптеров меньше или равно шести, вход

(A7-2). В этом случае кодами адресов будут комбинации 011111xx, 101111xx,..., 111110xx. Если адаптеров больше шести, то требуется дешифратор с L-активными выходами.
Адаптер может функционировать в трех основных режимах.
Режим 0 – простой ВВ. В режиме 0 обеспечивается возможность синхронного и асинхронного программно-управляемого обмена данными через два независимых восьмиразрядных порта A и B и два четырехразрядных порта C.
Режим 1 – стробируемый ВВ. В режиме 1 обеспечивается возможность обмена данными с ПУ через два независимых восьмиразрядных порта A и B по сигналам квитирования. При этом линии порта C используют для приема и выдачи сигналов управления обменом.
Режим 2 – двунаправленный канал. В режиме 2 обеспечивается возможность обмена данными через восьмиразрядный двунаправленный порт A по сигналам квитирования. Для приема и передачи сигналов управления обменом используют пять линий порта C.
Более подробно эти режимы будут рассмотрены ниже.
Режим работы каждого из портов A, B и C определяется содержимым регистра управления, в который загружается управляющее слово (или приказ). Формат управляющего слова определения режима приведен на рис. 8.12. Из рисунка следует, что управляющее слово определения режима идентифицируется состоянием
D7 = 1. Кроме того, режим работы половины порта C (PC7-4) определяется режимом работы порта A (группа A), а режим работы другой половины (PC3-0) определяется режимом работы порта B (группа B).

При подаче сигнала RESET регистр управления устанавливается в состояние, при котором все каналы настраиваются на работу в режиме 0 для ввода информации. Режим работы портов можно изменить как в начале, так и в процессе выполнения программы, что позволяет обслужить различные ПУ одной БИС в определенном порядке. При изменении режима работы любого порта все входные и выходные регистры портов и триггеры состояния сбрасываются.
В дополнение к основному режиму работы обеспечивается возможность программно-независимой установки 1 или 0 в любой из разрядов порта C. Управляющее слово установки и сброса разрядов порта С идентифицируется состоянием D7 = 0 и имеет формат, приведенный на рис. 8.13. Приказы данного формата используются, как правило, в режимах 1 и 2. Если микросхема запрограммирована для работы в режимах 1 или 2, то через выводы C0 и C3 порта C выдаются сигналы, которые могут использоваться как сигналы запросов прерывания для МП. Запретить или разрешить формирование этих сигналов в адаптере можно установкой или сбросом соответствующего разряда в регистре порта C.
Это позволяет программисту запрещать или разрешать обслуживание любого ПУ без анализа запросов в контроллере прерываний.
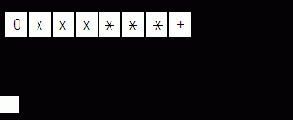
Теперь рассмотрим более подробно основные особенности
функционирования адаптера в различных режимах. При этом следует помнить, что выводы портов и разряды регистров портов связаны через переключающие схемы (это уже отмечалось). Кроме того, адаптер содержит схемы "И", позволяющие выполнять простейшие логические операции над содержимым определенных разрядов регистра порта C и сигналами на соответствующих выводах порта. Результаты этих операций появляются в виде соответствующих сигналов (H или L) на выводах C0 или C3. Порты A и B служат только для обмена данными и не содержат никаких логических элементов, при этом операции установки и сброса отдельных бит портов A и B можно реализовать только через аккумулятор с помощью операндов-масок, т.е. в три этапа.
Режим 0
Применяется в программно-управляемом ВВ с медленно действующими ПУ (например, посимвольный принтер или программатор). В этом случае не требуется сигналов управления обменом информации с ПУ, а необходимы только известительные сигналы, сообщающие о готовности ПУ к вводу и выводу информации. При работе в режиме 0 обеспечивается простой ввод и вывод информации через любой из трех портов. Как уже отмечалось, в этом режиме микросхема представляет собой совокупность двух восьми- и двух четырехразрядных каналов ВВ. В режиме 0 возможны 16 различных комбинаций схем ВВ портов A, B и C, которые определяются содержанием разрядов управляющего слова.
Выводимые данные фиксируются в регистрах-защелках, входящих в состав всех портов, а вводимые данные не запоминаются, т.е. при операции считывания входного порта в аккумулятор передается текущее
состояние цепей линии связи. Это справедливо только для режима 0.
В качестве примера рассмотрим использование адаптера в режиме 0 для организации интерфейса с посимвольным принтером и программатором, имеющим канал записи и канал считывания. Пусть два устройства вывода (принтер и канал записи программатора) разделяют общую шину данных порта А.
Считаем, что состояние готовности всех устройств представляет H-активный сигнал READY, а собственно передача данных сопровождается L-активными сигналами

Из рисунка видно, что группа A (A7-0, C6-4) работает на вывод, а группа B (B7-0, C2-0) – на ввод. Данную конфигурацию определяет приказ вида 10000011 (или 83H).
Для организации ВВ необходима подпрограмма инициализации адаптера и три аналогичных подпрограммы ВВ для каждого ПУ. Каждая из них выполняет следующие действия: ввод слова состояния (порт С), проверку готовности, ввод или вывод данных и формирование сопровождающего строба. Если ПУ не готово к обмену, МП входит в цикл ожидания. В данном случае фактически реализован режим 1 программным способом, однако в общем случае для обмена в режиме 0 не требуется никаких сопровождающих сигналов. Например, при выводе информации на индикаторы.

Режим 1
Это режим стробированного ВВ, предназначенный для однонаправленного обмена данными, инициируемого прерываниями. Собственно передача данных осуществляется через порты A и B, а шесть линий порта C используются для управления обменом. Каждая из этих линий в режиме 1 имеет строгое функциональное назначение, которое не может быть изменено пользователем. В то же время две оставшиеся линии порта C по усмотрению программиста могут работать либо на прием, либо на передачу.
Таким образом, в режиме 1 пользователю предоставляются следующие возможности:
Запрограммировать один или два параллельных порта с линиями квитирования и прерывания, каждый из которых может работать на ввод или вывод.
При использовании только одного порта остальные 13 линий адаптера запрограммировать в режим 0.
При определении двух портов в режим 1 оставшиеся две линии использовать для ввода или вывода.
В качестве иллюстрации рассмотрим форматы управляющих слов и функциональные схемы каналов A при вводе данных в режиме 1 и В при выводе
данных в режиме 1.
Канал A (режим 1, ввод данных). Формат управляющего слова приведен на
рис. 8.15, причем знак X обозначает, что значение бита в слове безразлично.

В соответствии с таким управляющим словом функциональная схема канала A имеет вид, приведенный на рис. 8.16.

Канал B (режим 1, вывод данных). Формат управляющего слова приведен на рис. 8.17.

В соответствии с таким управляющим словом функциональная схема канала B имеет вид, приведенный на рис. 8.18.

Функциональные схемы, приведенные на рис. 8.16 и 8.18, требуют некоторых пояснений, а именно:
РгC2, РгC4 – триггеры 2-го и 4-го разрядов регистра порта C;
C5-0 – выходы порта C.

IBF (входной буфер загружен) – выходной сигнал, высокий уровень которого свидетельствует о том, что входные данные записаны во входной регистр-защелку соответствующего канала. Устанавливается спадом
том










никак не воздействуют на разряды РгС2 и РгС4 регистра порта С.
IRQ (запрос прерывания) – выходной сигнал, который можно использовать как запрос прерывания МП.
Остановимся на сигналах

Для состояния ввода (порт А) сигнал








При необходимости использования обоих каналов (А и В) в рассмотренных состояниях управляющие слова, приведенные на рис. 8.15 и рис. 8.17, объединяются в одно общее управляющее слово. Аналогичным образом каналы А и В в режиме 1 могут быть запрограммированы и на другие комбинации операций ВВ. Форматы управляющих слов и функциональные схемы каналов для этих комбинаций операций ВВ в настоящем разделе не рассматриваются. Отметим только, что передача сигналов управления обменом осуществляется всегда по шести линиям порта С, но свободными могут оставаться не линии С7, С6, как было в рассмотренном случае, а линии С5, С4.
Режим 2
Это режим двунаправленного обмена, обеспечивающий ввод и вывод данных через один порт. В этом режиме может работать только группа A. Порт A используется для передачи собственно 8-битных данных, а для обеспечения протокола обмена используются пять линий порта C. Функции сигналов управления, используемых для передачи информации в режиме 2, и временные соотношения между ними такие же, как и в режиме 1.
Формат управляющего слова в режиме 2 изображен на рис. 8.19. В соответствии с таким управляющим словом функциональная схема канала A имеет вид, приведенный на рис. 8.20. Следует отметить, что биты D2-D0 управляющего слова задают режим работы группы В. Если для группы А определен режим 2, то для группы В может быть определен режим 1 или режим 0.

Вводимые и выводимые данные фиксируются в регистрах-защелках порта А. Общая дисциплина квитирования, как уже отмечалось, аналогична режиму 1. Однако имеются отдельные сигналы (триггеры) разрешения запросов прерывания для состояния вывода и ввода порта А:

INTE WRA
– сигнал разрешения запросов прерывания IRQA
по каналу А для состояния вывода. Управляется установкой и сбросом бита регистра порта С РгС6.
INTE RDA
– сигнал разрешения запросов прерывания IRQA
по каналу А для состояния ввода. Управляется установкой и сбросом бита регистра порта С РгС4.
Назначение линий С2-0 порта С зависит от запрограммированного режима группы В (биты D2-D0
управляющего слова).
Если адаптер запрограммирован для работы в режиме 1 или 2, то состояние каждого сигнала управления об установлении связи с ПУ, принимаемого и выдаваемого через выводы порта C, фиксируется в регистре порта C. Это позволяет программисту проверять состояние каждого ПУ простым чтением содержимого регистра порта C и соответствующим образом изменять программу. Форматы слова состояния в настоящем разделе не рассматриваются.
АДАПТЕР ПОСЛЕДОВАТЕЛЬНОГО ИНТЕРФЕЙСА
Передача данных в последовательном формате имеет ряд преимуществ, основным из которых является минимальное качество физических линий (проводников) промежуточного интерфейса. В простейшем случае (например, нуль-модемное соединение) требуются только две физические линии. Это обстоятельство обусловило очень широкое распространение таких интерфейсов в вычислительной
технике.
Обмен по последовательным промежуточным интерфейсам обычно используется при работе микроЭВМ с удаленными или медленно действующими ПУ, с модемом, в распределенных системах сбора и обработки информации. Уже отмечалось, что одним из наиболее распространенных последовательных промежуточных интерфейсов являются интерфейс RS-232C и его модификации. (Речь идет об относительно низкоскоростных интерфейсах). Отмечалось также, что серийно выпускаются программируемые БИС адаптеров, поддерживающих интерфейс RS-232C. Не рассматривая протоколы обмена для конкретных интерфейсов, отметим только некоторые особенности передачи данных в последовательном формате.
Единицей обмена в последовательном формате является символ, представленный в одной из систем кодирования и содержащий 5-8 информационных бит. Биты представлены в линии связи импульсами тока. На практике применяют два режима последовательного обмена: асинхронный (или стартстопный) и синхронный.
Асинхронный режим
Каждый символ передается автономно, и передача может быть начата в любой момент времени. Стандартный формат посылки приведен на рис. 8.4.
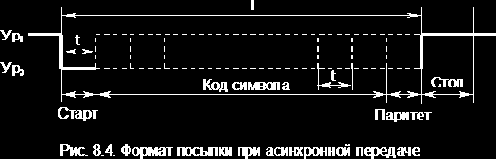
Передача начинается со стартового бита, являющегося логическим нулем, т.е. с прекращением тока в линии связи (длина бита обозначается t). Затем, в зависимости от разрядности кода, передаются 5-8 бит собственно символа. Передача символа завершается необязательным битом четного или нечетного паритета и 1, 1.5 или 2 стоповыми битами. Таким образом, максимальная длина посылки Т может быть равна 11 битам. Скорость передачи измеряется либо числом символов в секунду (1/Т), либо числом битовых посылок в секунду (1/t).
Синхронный режим
Передача начинается с одного или двух символов синхронизации SYN1 и SYN2, после которых последовательно без всяких разделителей передаются
5-8–битовые коды символов с необязательными битами четного или нечетного паритета. Формат сигналов в линии связи имеет вид, приведенный на рис. 8.5.

В обоих режимах необходимо контролировать передачу по битам паритета (если он предусмотрен в формате), выдерживать временные соотношения, а в асинхронном режиме дополнительно контролировать установленный формат символа.
Из сказанного следует, что асинхронному режиму свойственна избыточность. Так, минимальный код в 5 бит могут сопровождать 4 служебных бита, т.е. непроизводительное использование линии связи доходит до 44%, поэтому асинхронный режим используется в системах с небольшой скоростью передачи или с нерегулярным обменом.
Некоторые типы ППУ жестко настроены только на синхронный или асинхронный обмен. Но наибольшей гибкостью отличаются ППУ, которые называются УСАПП – универсальный синхронно-асинхронный приемопередатчик. Типичным примером такого УСАПП является БИС адаптера последовательного промежуточного интерфейса КР580ВВ51, структурная схема которой приведена на рис. 8.6.

Этот адаптер производит автоматическое преобразование кода из параллельного в последовательный и наоборот, а для МП выглядит устройством параллельного ввода и вывода. Он может работать в полудуплексном и дуплексном режимах. Наличие в БИС двойных буферов приводит к тому, что для реакции МП на запрос прерывания от адаптера в распоряжении МП имеется временной интервал Т передачи одного символа. Данный адаптер также генерирует и принимает сигналы управления модемом. С точки зрения программиста адаптер (т.е. его программная модель) имеет вид, приведенный на рис. 8.7.
В общем случае схема подключения адаптера к системной магистрали выглядит так, как показано на рис. 8.8, хотя возможны и другие варианты.
Адаптер имеет двунаправленный буфер ШД, который служит для передачи собственно данных, управляющих слов и информации состояния.
Его выходные каскады имеют три состояния и позволяют отключать адаптер от ШД. Как правило, обмен инициируется командами IN, OUT.
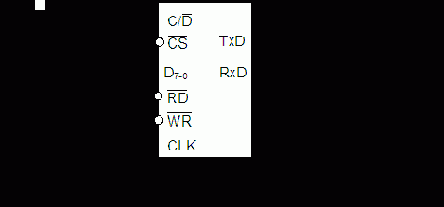
Схема управления воспринимает сигналы с ШУ и генерирует внутренние управляющие сигналы. В ее составе имеются регистр режима и регистр команды, которые хранят управляющие слова функционального определения адаптера.
Ниже рассматриваются только основные моменты функционирования данного адаптера. В частности, не рассматривается взаимодействие адаптера и модема (и соответствующие этому взаимодействию сигналы управления – сигналы блока управления модемом).
В адаптер подаются шесть входных управляющих сигналов:
RESET (сброс) – H-активный сигнал сброса с минимальной длительностью 6 периодов синхронизации. После воздействия этого сигнала адаптер переходит в "холостой" режим и остается в нем до загрузки управляющих слов.
CLK (синхронизация) – подключается ко второй фазе тактового генератора МП (F2). Частота сигнала CLK минимум в 30 раз выше частоты приема или передачи (имеются в виду частоты передачи или приема отдельных бит, а не их блоков).


ром и ШД.
Узел передатчика со схемой управления выполняет все функции, связанные с передачей последовательных данных, в частности:
- воспринимает параллельные коды символов от МП;
- автоматически вводит необходимые служебные биты и символы синхронизации;
- выдает последовательный поток данных на выход TxD.
К этому узлу относятся следующие внешние сигналы:
TxD (выход передатчика) – подключается к линии связи или модему.


TxE (пустой передатчик) – H-активный выходной сигнал, обозначающий отсутствие в адаптере символа для передачи (появляется, когда последний бит кода "выталкивается" из регистра сдвига, а в регистре передатчика также ничего нет). Его можно использовать для идентификации в полудуплексном режиме связи окончания передачи и коммутации линии на прием. В синхронном режиме H-уровень TxE указывает, что символ вовремя не загрузили в адаптер и в качестве "заполнения" автоматически передаются сигналы синхронизации.
Сигнал TxE сбрасывается при загрузке символа в адаптер, т.е. в регистр передатчика. Если регистр сдвига пуст и присутствует сигнал

TxRDY (готовность передатчика) – H-активный выходной сигнал, определяющий готовность передатчика к загрузке нового символа с ШД (т.е. он индицирует, что регистр передатчика пуст и готов к загрузке). В это время предыдущий символ может еще находиться в регистре сдвига и постепенно "выдвигаться" в линию связи. Как только он будет полностью "выдвинут", новый символ будет перемещен в регистр сдвига (при наличии сигнала

Сигнал TxRDY может быть использован как запрос прерывания процессора.
При загрузке в регистр передатчика нового символа сигнал TxRDY сбрасывается. Состояние этого выхода (TxRDY), так же как и TxE, может быть опрошено программным способом, посредством считывания слова состояния.
Узел приемника со схемой управления выполняет все функции, связанные с приемом последовательных данных, в частности:
- воспринимает последовательные данные с входа RxD;
- контролирует и исключает служебные биты и символы синхронизации;
- преобразует последовательные данные в параллельный формат и передает "собранный" символ в процессор.
К этому узлу относятся следующие внешние сигналы:



RxRDY (готовность приемника) – H-активный выходной сигнал, свидетельствующий о готовности приемника к выдаче принятого символа в параллельном коде на ШД (т.е. символ информации полностью "вошел" в регистр сдвига и был перемещен в регистр приемника). Сигнал RxRDY может быть использован как запрос прерывания процессора. После считывания символа из адаптера (из регистра приемника) сигнал RxRDY сбрасывается. Состояние выхода RxRDY может быть опрошено программным способом, посредством считывания слова состояния.
SYNDET (обнаружение синхронизации) – H-активный сигнал синхронного режима, который можно запрограммировать как входной и как выходной. Если он запрограммирован как выходной, то при обнаружении символа SYN, на выходе SYNDET формируется высокий уровень в момент, соответствующий середине последнего бита (если есть SYN1 и SYN2, это относится к SYN2).
При считывании слова состояния сигнал сбрасывается. Если он запрограммирован как входной, то подача на него высокого уровня фиксирует момент начала приема символа, т.е. инициализируется ввод слова в приемник в последовательном коде, начиная со следующего за SYNDET сигнала
Сигналы, связанные с узлом управления модемом, в настоящем разделе не рассматриваются, поскольку требуют достаточно подробного изучения протокола обмена в стандарте RS-232C. Остановимся только на основных моментах процесса программирования (инициализации) адаптера.
Управляющие слова, определяющие функциональную конфигурацию адаптера, должны загружаться сразу после операции сброса. Управляющие слова имеют два формата – слово режима и слово приказа (или команда). Оба слова имеют длину
8 бит.
Слово режима задает общие рабочие характеристики адаптера и загружается первым, так как осуществляет коммутацию схем прибора. В закодированном виде слово режима несет информацию о числе стоп-бит (1, 1.5, 2 бита), виде паритета (четный, нечетный), длине слова данных (5, 6, 7, 8 бит) и скорости передачи (эти же биты определяют режим – синхронный или асинхронный). После слова режима загружаются один или два символа синхронизации, если был определен синхронный режим (SYN1 и SYN2). Если адаптер запрограммирован на синхронный режим с одним символом синхронизации, то SYN2 пропускается. Если определен асинхронный обмен, то пропускаются оба символа SYN. Последним в адаптер загружается слово приказа, определяющее конкретные действия, в соответствии со словом режима.
Загрузка всех управляющих слов производится обычно командой OUT (хотя можно обращаться и как к ячейке памяти) при следующих значениях управляющих сигналов:




в слове приказа).
Слово приказа, как уже отмечалось, задает конкретные операции адаптера. Назначение отдельных разрядов слова приказа в данном разделе не рассматривается.
Отметим только, что его разряды задают разрешение передачи или приема, сброс признаков ошибок, сигналы управления модемом, а также несут и некоторую другую информацию.

При организации последовательного интерфейса возникает необходимость в анализе состояния адаптера со стороны процессора. Состояние адаптера можно считать в любой момент времени посредством команды IN либо обратившись к регистру состояния как к ячейке памяти. При этом сигнал
D3 (PE) – ошибка паритета – устанавливается при обнаружении в принятом слове данных нарушения паритета;
D4 (OE) – ошибка переполнения – устанавливается в любом режиме, если процессор вовремя не считал символ из регистра приемника (это слово данных теряется).
D5 (FE) – ошибка кадра – устанавливается в асинхронном режиме, если в конце любого слова данных не обнаружен стоповый бит.
D7 (DSR) – готовность модема.
Все флажки ошибок сбрасываются, если бит D4
команды установлен в 1. Следует особо подчеркнуть, что возникновение любого ошибочного условия не останавливает работу адаптера. Он только фиксирует ошибки, а реагировать на них должен сам процессор.
АЛГОРИТМЫ УПРАВЛЕНИЯ МНОГОУРОВНЕВОЙ ПАМЯТЬЮ
Будем рассматривать двухуровневую память со страничной организацией, состоящую из оперативной (верхний уровень) и внешней (нижний уровень) памятей. Если при выполнении программы обнаруживается, что страница с нужными данными (операндами, куском программы) отсутствует в памяти верхнего уровня, она передается туда из памяти нижнего уровня. Если при этом в памяти верхнего уровня нет для нее свободного места, то она замещает одну из страниц, находящихся в ОП. При этом если в замещаемую страницу во время ее пребывания в ОП производилась запись, то она должна быть передана в память нижнего уровня (заменит там свою устаревшую копию).
Эти операции передачи информации между уровнями памяти вызывают простои процессора и, следовательно, потери производительности вычислительной системы, поэтому следует стремиться уменьшить число таких операций в процессе выполнения программы. Очевидно, что число этих операций обмена информацией зависит от того, какая информация отсылается из памяти верхнего уровня, так как к этой информации возможно обращение в процессе дальнейшего выполнения программы.
Приведем формализованную модель процесса обмена информацией между верхним и нижним уровнями памяти. Пусть программа вместе с исходными данными состоит из k страниц, которым присвоены номера 1, 2, ..., k, тогда программу можно рассматривать как множество страниц:
Q = {1,2, …, k}.
Все страницы программы постоянно хранятся в памяти нижнего уровня, а, кроме того, r из них могут находиться в памяти верхнего уровня (оперативной памяти), при этом
1 < r < k.
Выполнение программы порождает последовательность обращений к страницам памяти. Рассматриваем эту последовательность как реализацию некоторого случайного процесса:
q0, q1, q2, …, qt,
где qt – случайная дискретная величина, принимающая в момент времени t значение одного из номеров страниц программы (qt Î Q).
Если St – совокупность страниц в памяти верхнего уровня в момент t, причем в любой момент в этой памяти присутствует r страниц программы, то изменение состояния памяти верхнего уровня после обращения qt
описывается следующими соотношениями:


В первом случае обращение производится к странице, которая находится в памяти верхнего уровня, и поэтому состояние этой памяти не меняется.
Во втором случае происходит обращение к странице, отсутствующей в памяти верхнего уровня. Эта ситуация называется страничным сбоем, так как программа не может дальше выполняться, пока нужная страница qt
не будет переписана из памяти нижнего уровня в память верхнего уровня, что сопряжено с потерями времени. Поскольку в памяти верхнего уровня нет свободного места, из нее приходится удалять некоторую страницу vt с тем, чтобы на ее место можно было поместить страницу qt. Если во время пребывания страницы vt в памяти верхнего уровня в нее производилась запись, эта страница при замещении должна переписываться в память нижнего уровня. Такая процедура называется процессом замещения страниц, а правило, по которому при возникновении страничного сбоя выбирается страница vt Î St для удаления из памяти верхнего уровня, – алгоритмом замещения.
Для данной программы, порождающей некоторый поток обращений к памяти, существует, по крайней мере, одна такая последовательность замещений страниц, которая дает минимальное для этой программы число страничных сбоев – минимально возможную последовательность замещений. При конструировании алгоритма замещений стремятся приблизить реализуемую этим алгоритмом последовательность замещений к минимальной.
Оптимизация процесса замещений страниц упрощается, если известно, в каком порядке в будущем будут происходить обращения к памяти или, по крайней мере, вероятности обращений в будущем к отдельным страницам программы. Ясно, например, что в первую очередь из памяти верхнего уровня следует удалить страницу, к которой обращений больше не будет (вероятность обращений в будущем равна 0).
Трудность состоит в том, что, как правило, при выполнении программы отсутствуют информация о потоке обращений или сколько-нибудь достоверные сведения о вероятности обращений к отдельным страницам в будущие моменты времени.
Алгоритмы замещения можно разделить на две группы:
физически нереализуемые, использующие информацию (реально отсутствующую) о потоке обращений в будущие моменты времени;
физически реализуемые или эвристические, использующие только информацию об обращениях к памяти в прошедшие моменты времени, т.е. только историю процесса.
Хотя алгоритмы первой группы на практике применить нельзя, они играют важную роль в теории алгоритмов замещения, позволяя производить оценки (в том числе экспериментальные), в какой степени характеристики эвристических алгоритмов приближаются к предельно возможным оптимальным.
Физически нереализуемые алгоритмы
Алгоритм Михновского-Шора. При каждом замещении страницы из памяти верхнего уровня отсылается в память нижнего уровня страница, очередное обращение к которой произойдет позже, чем к любой другой странице в памяти верхнего уровня.
Справедливо следующее предложение. Число замещений страниц в памяти верхнего уровня (число страничных сбоев) при выполнении замещений по алгоритму Михновского-Шора является минимальным для заданных потока обращений и исходного распределения памяти, что имеет теоретическое доказательство.
Таким образом, алгоритм Михновского-Шора реализует минимально возможную для данной программы последовательность замещений, поэтому этот алгоритм называют МИН-алгоритмом.
Если условиться, что известна вероятность обращений к отдельным страницам программы, то оптимальным в смысле минимума среднего числа страничных сбоев является ОПТ-алгоритм: при каждом замещении страницы из памяти верхнего уровня отсылается страница, вероятность обращения к которой не больше, чем к любой другой странице в этой памяти.
Физически реализуемые (эвристические) алгоритмы замещения
Был предложен ряд алгоритмов этого класса.
Алгоритм случайного замещения (СЗ-алгоритм). При возникновении страничного сбоя из памяти верхнего уровня с равной вероятностью отсылается любая из находящихся там страниц.
НДИ-алгоритм. Из памяти верхнего уровня отсылается страница, наиболее давно использовавшаяся.
Алгоритм "первый пришел – первый ушел" (ПППУ-алгоритм). Отсылается страница, дольше других находившаяся в памяти верхнего уровня.
Алгоритм "последний пришел – первый ушел". Отсылается страница, позже других поступившая в память верхнего уровня.
Следующие два алгоритма обладают определенными свойствами адаптации к потоку обращений к памяти.
Алгоритм "карабкающаяся страница" (КС-алгоритм). Страницы в памяти верхнего уровня образуют последовательность:

При очередном обращении qt к памяти эта последовательность изменяется по правилу:


При обращении к странице jm, присутствующей в памяти верхнего уровня, последняя меняется местами с соседней слева страницей, другими словами, "карабкается" к началу последовательности, подальше от ее конца, куда происходит замещение при страничном сбое. Этот процесс иллюстрирует схема на рис. 9.18.

Алгоритм "рабочий комплект" (РК-алгоритм). Страницы в памяти верхнего уровня, использовавшиеся в течение заданного интервала времени, образуют "рабочий комплект". Страницы из этой памяти, не вошедшие в "рабочий комплект", формируют две очереди кандидатов на замещение:
- очередь страниц, в которые не вносились изменения, пока они присутствовали в памяти верхнего уровня;
- очередь страниц, в которые вносились изменения.
Замещение при страничном сбое производится по правилу: первый пришел из рабочего комплекта – первый ушел из памяти верхнего уровня. При этом сначала подлежат замещению страницы из первой очереди. Описанный алгоритм использовался еще в компьютерах IBM-360/370.
Предположим, что последовательность обращений q1, q2, …, qt соответствует последовательности независимых случайных дискретных величин, таких что



Примем за состояние процесса замещения набор (а в некоторых случаях упорядоченную последовательность) страниц, находящихся в памяти верхнего уровня. Тогда для ряда алгоритмов замещения (СЗ, НДИ, ПППУ и некоторых других) процесс изменения состояния верхнего уровня описывается однородной конечной эргодической цепью Маркова, что указывает на существование стационарных вероятностей пребывания процесса в определенных состояниях и, как следствие этого, стационарных вероятностей страничных сбоев.
В качестве критерия эффективности Wr,k алгоритма замещения А примем стационарную вероятность страничных сбоев:

Можно для ряда алгоритмов замещения найти зависимость Wr,k
от p1, p2, …, pk и сравнить алгоритмы между собой, а также с физически нереализуемым ОПТ-алгоритмом. Определить Wr,k
для ряда алгоритмов можно, используя метод, основанный на однородных эргодических цепях Маркова.
Описанные выше эвристические алгоритмы замещения страниц и их различные комбинации лежат в основе алгоритмов замещения, используемых в современных ЭВМ. При этом конкретные технические реализации алгоритмов замещения страниц весьма сложные и сильно зависят от конкретной конфигурации аппаратных средств, типа операционной системы и даже ее модификации. Следует отметить только, что в большинстве случаев алгоритмы замещения страниц в современных ЭВМ содержат механизмы упреждающей выборки страниц. Идея использования упреждающей загрузки страниц из ВП в ОП, как и в случае обновления блоков в кэш-памяти
(см. п. 9.3.3), основана на предположении о том, что при очередном страничном сбое обращение с большой вероятностью произойдет к следующей по порядку странице, уже находящейся в ОП. Кроме того, как уже отмечалось в п. 9.4.1, перемещение модифицированных страниц из ОП в ВП осуществляется в большинстве случаев через кэшированную часть ОП (дисковый кэш), поскольку велика вероятность обращения к недавно удаленной странице. Такой механизм позволяет ускорить процесс подкачки страниц при повторном обращении.
Более подробно вопросы организации виртуальной памяти в настоящем разделе не рассматриваются, поскольку относятся к области системного программного обеспечения компьютера (ядра операционной системы).
БУФЕРИЗАЦИЯ ПАМЯТИ
Суть этого метода состоит в том, что между процессором и ОП включаются дополнительные блоки буферных памятей относительно небольшой емкости, но имеющие быстродействие существенно выше, чем ОП. При обращении к таким памятям у процессора не возникает проблем с запаздыванием сигналов и уменьшением из-за этого скорости обмена. Как уже отмечалось, повышение быстродействия БИСов памяти сопровождается резким повышением их стоимости, поэтому доля буферной памяти в общем объеме небольшая, порядка 16-256 Кбайт на 4-8 Мбайт основной памяти. Сверхоперативная память, упоминавшаяся ранее в п. 4.1, также является буферной, однако ее емкость очень незначительна (десятки слов) и в данном случае не учитывается.
В общем случае буферная память состоит из двух модулей: буферной памяти команд и буферной памяти операндов. Структура памяти в этом случае имеет вид, показанный на рис. 9.6. Такая схема буферизации ОП использовалась еще в мэйнфреймах 60-х гг.
Представленные буферные памяти в современных ЭВМ скрыты от программиста в том смысле, что он не может их адресовать и может даже не знать об их существовании, поэтому они получили название кэш-памятей (cache – тайник). Некоторые ЭВМ содержат объединенную кэш-память операндов и команд. Наличие кэш в общем случае не исключает присутствия в процессоре небольшой сверхоперативной памяти.
Таким образом, кэш-память представляет собой быстродействующее ЗУ, размещенное в одном кристалле с процессором или же внешнее по отношению к кристаллу, но размещенное на той же плате. При обращении процессора к ОП для считывания в кэш пересылается блок информации, содержащий нужное слово. При этом происходит опережающая выборка, так как высока вероятность того, что ближайшие обращения будут происходить к словам блока, уже находящегося в кэш. Это приводит к значительному уменьшению среднего времени, затрачиваемого на выборку данных и команд.

Для обращения к кэш, размещенному вне кристалла процессора, но на одной с ним плате, может потребоваться несколько тактов, тогда как при обращении к кэш, размещенному внутри кристалла процессора, может оказаться достаточно одного такта.
Однако даже размещение кэш на одной плате с процессором позволяет избежать большого числа циклов ожидания, которые неизбежны при работе с ОП, расположенной на отдельной плате и взаимодействующей с процессором через системную шину. Кроме того, выборка содержимого кэш-памяти может производиться произвольным образом, и, следовательно, в адресном пространстве кэш можно разместить командные циклы с входящими в них командами переходов (передачи управления).
Все это позволяет не только ускорить операции обмена процессор - память, но также снизить загрузку системной магистрали. Последнее стало особенно актуально с возникновением многопроцессорных систем, в которых процессорные элементы располагаются на общей магистрали и имеют общий модуль ОП. Уже отмечалось, что обмен между устройствами ЭВМ по общей магистрали возможен только в неперекрывающиеся моменты времени (т.е. в каждый момент времени с ОП может общаться только один процессор). Поэтому кэш-память оказалась очень удобным инструментом для сокращения числа обращений каждого процессора к ОП, а следовательно, и загрузки системной магистрали ЭВМ.
Таким образом, снижение загрузки системной магистрали
является еще одной причиной (помимо ускорения операций обмена процессор – ОП) включения в структуру современных ЭВМ модулей кэш. Кроме того, как будет показано в гл. 11, наличие кэш-памяти достаточного объема позволяет не прерывать
работу процессора даже при захвате магистрали каким-либо устройством, т.е. при осуществлении обмена в режиме ПДП.
Производительность кэш-памяти определяется временем доступа к ней и вероятностью удачных обращений, которая зависит от объема кэш и количества слов в блоке (строке), переносимых в кэш при каждом обращении к ОП. С увеличением длины блока возрастает вероятность того, что следующее обращение будет удачным, т.е. необходимая информация окажется в кэш-памяти. Однако эта зависимость нелинейная и имеет свой оптимум в координатах "производительность - стоимость", который обусловлен тем, что увеличение размера блока свыше некоторого оптимального приводит лишь к незначительному увеличению вероятности удачных обращений к кэш.
Полная производительность памяти ЭВМ ( при наличии кэш) является функцией времени доступа к кэш, вероятности удачных обращений к кэш и времени обращения к ОП, которое происходит при неудачном обращении к кэш. Численная оценка полной производительности памяти оказывается в этом случае очень сложной задачей, особенно при учете увеличения быстродействия ОП за счет расслоения, и решается только статистическими методами.
При проектировании аппаратного и алгоритмического обеспечения кэш-памяти приходится учитывать большое число различных факторов и, часто взаимоисключающих, требований, поэтому конкретное исполнение кэш-памяти в различных ЭВМ отличается большим разнообразием. В частности, одной из проблем является взаимодействие кэш и ОП при изменении в процессе выполнения программы находящейся в кэш информации. В настоящее время эта задача решается, в основном, двумя путями, каждый из которых определяет тип кэш:
Запоминание новой информации происходит одновременно в кэш и ОП (write through – сквозная запись). При этом в ОП всегда есть последняя копия хранящейся в кэш информации. Это удобно, но длинный цикл ОП снижает производительность процессора.
Запоминание новой информации происходит только в кэш. Копирование ее в ОП происходит только при передаче в другие устройства ЭВМ или при вытеснении из кэш в результате вызова новой информации из ОП (write back – обратная запись).
Задача выбора алгоритма перемещения блоков информации из кэш-памяти в ОП при вызове из ОП новых блоков также не имеет однозначного решения. В большинстве случаев из кэш-памяти удаляется блок информации, который используется наиболее редко либо не использовался дольше других. Возможны и другие алгоритмы замещения. В частности, в кэш с прямым отображением, в котором за каждой ячейкой кэш закреплена определенная группа ячеек ОП, замена информации в ячейках кэш происходит по мере обращения процессора к соответствующей группе ячеек ОП (более подробно этот вопрос рассматривается ниже).
Следует отметить, что наличие кэш-памяти усложняет работу вычислительной системы и требует дополнительного программно- аппаратного обеспечения.
В частности, требуется специальный контроллер кэш-памяти, который перехватывает обращения процессора к ОП и обрабатывает их непосредственно сам, без передачи запросов шине.
В качестве примера рассмотрим организацию кэш-памяти в вычислительных системах, построенных на базе 32-разрядного процессора I80386. В архитектуре микропроцессора I80386 за ячейку памяти на аппаратном уровне принята последовательность из восьми смежных бит, т.е. 1 байт. Несмотря на то, что МП I80386 является 32 - разрядным, наибольшая эффективность достигается в нем при обработке 16-разрядных данных, поэтому в качестве машинного слова
в данном МП выбраны два объединенных байта.
В вычислительных системах, построенных на базе I80386, управление кэш-памятью осуществляется высокопроизводительным контроллером кэш-памяти I82385. Для инициализации контроллера I82385 не требуется специального программного обеспечения, а сам контроллер программно невидим (прозрачен), поэтому он может быть легко применен в системах с уже существующим программным обеспечением, а разработка нового программного продукта не потребует специфических условий, связанных с этим контроллером. Контроллер обеспечивает прозрачность на шине с помощью наблюдения за шиной ("подслушивание" шины). Наблюдение за шиной реализуется контроллером через интерфейс, аналогичный интерфейсу шины процессора I80386. Благодаря своей прозрачности контроллер кэш-памяти I82385 может быть включен в состав микропроцессорных систем на базе I80386 для работы в конвейерном и неконвейерном режиме и адресации пространства ОП до 4 Гбайт. Обновление ОП выполняется на каждом цикле записи методом "сквозной записи". При этом производительность повышается вследствие выдачи запросов на операции записи через некоторый буфер, позволяющий процессору продолжать работу с кэш-памятью, пока идет обращение к ОП. Если содержимое ячеек ОП, копии которых находятся в кэш, в процессе выполнения программы изменилось, контроллер автоматически обновляет содержимое соответствующих ячеек кэш-памяти.
Очень упрощенная структура кэш вычислительной системы на базе I80386 и I82385 (да в принципе и любой другой) изображена на рис. 9.7. Причем в вычислительных системах на базе I80386 и I82385 используется объединенный кэш команд и данных.

Как уже отмечалось, пересылка информации из ОП в кэш-память и обратно осуществляется целыми блоками. Для этого ОП также разделяют на блоки от 2 до 16 байт. Если запрашиваемая процессором информация не находится в кэш, то контроллер кэш-памяти обновляет содержимое кэш целым блоком. Размер блока является очень важным параметром, определяющим эффективность работы кэш-памяти. В 32 - разрядных системах контроллер в качестве блока пересылает совокупность данных размером 2-4 слова (4-16 байт). Даже если запрашивается одиночное слово, то все равно осуществляется блочная пересылка. С увеличением блока замедляется модификация кэш, но увеличивается коэффициент попадания. Так, увеличение блока с 4 байт до 8 увеличивает коэффициент попадания на несколько процентов. Однако при этом в кэш размещается меньшее число блоков. А с уменьшением числа блоков растет вероятность операций пересылки блоков между кэш и ОП, поэтому приходится выбирать оптимум (что уже отмечалось). Обычно в вычислительных системах на базе I80386, I82385 работа кэш-памяти организована так, что вероятность удачных обращений достигает 0,95.
При обработке различных классов задач наибольшую эффективность системы кэш-памяти достигают при использовании различных структур, а именно: полностью ассоциативных кэш, кэш с прямым отображением и множественный ассоциативный кэш. Каждая из этих структур имеет свои преимущества и недостатки. В принципе, все эти структуры поддерживаются контроллером кэш I82385 с некоторыми ограничениями. Рассмотрим эти структуры подробнее, полагая, что емкость ОП вычислительной системы составляет 16 Мбайт.
Приведенные ниже схемы организаций кэш и терминология взяты из книги Паппарс К., Марри У. Микропроцессор 80386: Справочник. М.: Радио и связь, 1993.
–
318 с.
Полностью ассоциативный кэш (рис. 9.8)
Концепция полностью ассоциативного кэш основана на том предположении, что процессор обращается к адресам, лежащим в разных частях ОП, поэтому для обеспечения общей эффективности работы механизм кэш должен поддерживать множественные несвязанные блоки данных. Поскольку между блоками нет в этом случае каких-либо определенных взаимосвязей, в кэш должны записываться полный адрес каждого блока и непосредственно сам блок. При обращении к памяти контроллер кэш-памяти сравнивает полученный адрес с адресами, отображенными на кэш.
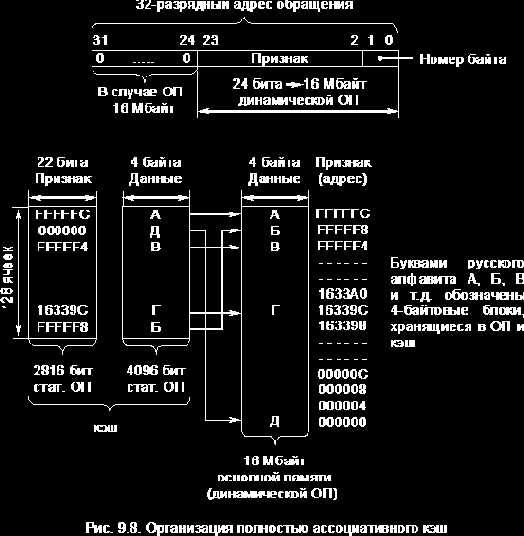
Существенным недостатком полностью ассоциативных кэш является то, что всякий раз при обращении к памяти затрачивается время на сравнение адресов в кэш. Следует отметить, что в стандартной конфигурации вычислительных систем на базе процессора I80386 и контроллера кэш-памяти I82385 структура полностью ассоциативного кэш не используется.
В литературе нет данных о том, как осуществляется контроль ассоциации при использовании контроллера I82385. Судя по всему, происходит последовательное
сравнение ячеек кэш с 22-разрядным полем признака (адресом) без вызова их в контроллер. Такой последовательный процесс сравнения и увеличивает время
поиска.
Известно также, что в ряде устройств ассоциативной памяти контроль ассоциации осуществляется последовательно по битам ассоциативного признака. Применительно к данному кэш это означает, что происходит параллельное сравнение 128 бит в i-м разряде адреса, т.е. необходимо выполнить последовательно 22 сравнения, чтобы проанализировать все поле признака (адреса). В специализированных блоках ассоциативной памяти контроль ассоциации осуществляется параллельно по всем ячейкам памяти (см. п. 4.2.2).
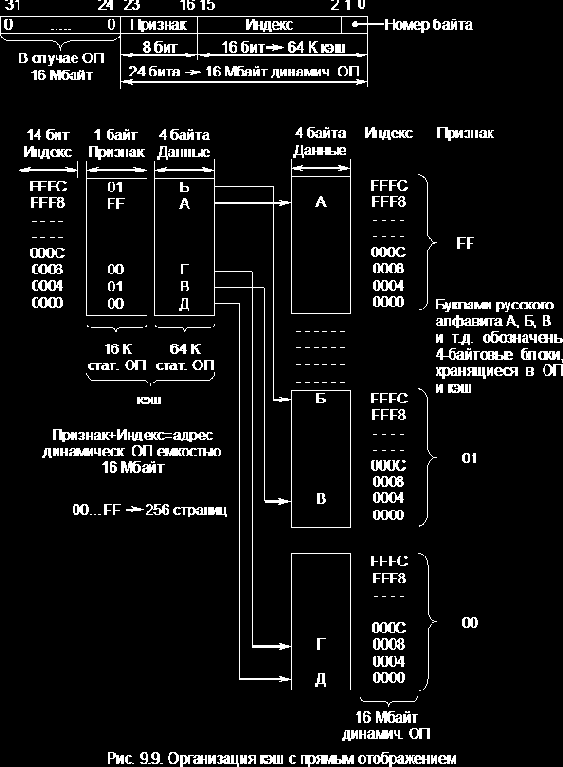
Кэш с прямым отображением (рис. 9.9)
При использовании кэш такого типа ОП условно делится на 256 страниц по
64 Кбайт каждая. Каждая страница имеет свой базовый адрес, задаваемый 8 битами поля признака (старшие разряды адреса ячейки ОП). Объем кэш (банк данных) соответствует объему одной страницы (64 Кбайт).
Поле индекса в адресе занимает 16 бит. Из них 14 используются для выбора одного из 16 Кбайт 4 байтовых блоков (ячеек) кэш или ОП (на странице с соответствующим признаком), а два бита определяют один из 4 байтов в блоке, т.е. индекс является ничем иным, как смещением
относительно базового адреса (признака).
Копии блоков с одинаковыми адресами на всех страницах ОП помещаются в одну и ту же ячейку кэш с аналогичным адресом. Таким образом, на один адрес кэш отображаются 256 адресов ОП (256*64 Кбайта = 16 Мбайт). Сам кэш имеет два уровня. Первый уровень образован банком признаков и содержит адресную информацию. В данном случае это базовые адреса страниц ОП (признаки). В некоторых источниках вместо термина признак употребляют тег. Второй уровень состоит из банка данных, в котором содержатся 4 байтовые копии (блоки) ячеек ОП.
Упрощенный алгоритм обращения процессора к памяти состоит в следующем:
- 14-битный индекс сообщает контроллеру кэш, какую из 16 Кбайт однобайтовых ячеек в банке признаков следует проверить:
- 8-битный признак, находящийся в указанной ячейке банка признаков, сообщает, какой из 256 возможных 4-байтовых блоков находится по этому адресу (индексу) в ячейке банка данных;
- если запрошенный процессором признак совпадает с признаком в банке признаков, возникло совпадение. Если нет, происходит обращение к ОП и осуществляется замена признака и данных в кэш на данные, полученные из ОП.
Рассмотренная структура кэш отличается от предыдущей (полностью ассоциативной) тем, что здесь нет неопределенности в размещении блока данных. Адрес (индекс) указывается непосредственно в запросе процессора, и сравнивать приходится только признак. Это ускоряет процесс обмена.
Недостатком такого типа кэш является то, что на одну ячейку кэш отображается 256 адресов ОП, т.е. одинаковые адреса со всех страниц ОП, поэтому при циклическом обращении процессора к одинаковым адресам хотя бы на двух разных страницах возникает "пробуксовка" кэш.
В этом случае при каждом обращении происходит обновление содержимого соответствующей ячейки кэш. Этой проблемы можно избежать, разрешив любой ячейке в ОП направляться по мере необходимости не в одну, а в две или более ячеек кэш. При этом увеличивается коэффициент попаданий, но и усложняется алгоритм обращения к памяти.
Двухвходовый множественный ассоциативный кэш (рис. 9.10)
Множественный ассоциативный кэш занимает промежуточное положение между полностью ассоциативным кэш и кэш с прямым отображением. Из приведенной структурной схемы следует, что банк признаков и банк данных, используемые в кэш с прямым отображением, в данном случае разбиваются на два блока, в каждом из которых есть свой банк признаков и банк данных емкостью 32 Кбайт. Оба блока кэш имеют одинаковую адресацию, т.е. индекс изменяется от 0000 до 7FFC. При использовании кэш такого типа ОП делится уже не на 256 страниц, а на 512, каждая из которых имеет свой 9-разрядный признак (базовый адрес) от 000 до 1FF (32 Кбайт). Данные из ОП могут быть помещены в любую из двух ячеек с соответствующим индексом (смещением) банков данных, относящимся к разным блокам кэш. В соответствии с принятым алгоритмом контроллер кэш I82385 помещает новый блок данных из ОП в ту из двух ячеек, содержимое которой наиболее долго не использовалось.

Алгоритм обращения к памяти полностью аналогичен описанному ранее для кэш с прямым отображением, за исключением того, что в данном случае контроллеру приходится одновременно проверять две ячейки с одинаковыми индексами (смещением) в обоих блоках кэш. Изменился также формат адресных полей.
Производительность для двухвходового ассоциативного кэш примерно на 1% выше, чем у кэш с прямым отображением. Возможно построение четырёхвходовых и более множественных ассоциативных кэш, состоящих из четырёх и более блоков с одинаковой адресацией. При этом увеличивается производительность, но и усложняется алгоритм обращения к памяти.
В заключение следует отметить, что в вычислительных системах на базе процессора I80386 в стандартной конфигурации контроллер кэш I82385 поддерживает работу двухвходового множественного ассоциативного кэш и кэш с прямым отображением.
В современных ЭВМ, построенных на базе мощных процессоров, происходит дальнейшее расслоение внутренней памяти и, прежде всего, расслоение кэш. Быстродействующий внутрикристальный кэш первого уровня и более "медленный" внешний кэш второго уровня являются обязательными компонентами всех современных IBM PC. Взаимодействие кэш обоих уровней строится по принципам, аналогичным принципам взаимодействия остальных иерархических слоев памяти – минимизация числа обращений более быстродействующего слоя к менее быстродействующему. Дальнейшее увеличение производительности процессоров неизбежно повлечет за собой и дальнейшее расслоение кэш-памяти ЭВМ.
ЦЕПОЧЕЧНАЯ СТРУКТУРА (BUS MASTER DMA)
В соответствии с рис. 11.2 к каждой ШАр (входу арбитра) может быть подключено множество запросчиков ИЗПД. Сигнал РПД распространяется по цепочке ИЗПД, подключенных к одной ЛЗПД (к одной ШАр). Распространение этого сигнала блокируется ИЗПД, выставившим запрос. Пусть это будет ИЗПДi, подключенный к ЩАрn (см. рис. 11.3). Получив сигнал РПД, блок СУМ ИЗПДn,i захватывает магистраль и начинает ею управлять. Таким образом, приоритет подключенных к одной ЛЗПД устройств определяется положением ИЗПД в цепочке распространения сигнала РПД. Это исключает необходимость выполнения процедуры поиска запроса с максимальным приоритетом среди ИЗПД, подключенных к одной ЛЗПД.
Если ШАр несколько, что обычно имеет место в реальных системах bus master DMA цепочечной структуры, в арбитре выполняется процедура поиска возбужденной ЛЗПД с максимальным приоритетом, которая аналогична процедуре поиска запроса с максимальным приоритетом в системе радиальной структуры.
На основании вышеизложенного можно записать обобщенную последовательность основных операций по предоставлению магистрали в распоряжение ведущего устройства (master) для передачи блока информации:
1. В начале функционирования вычислительной системы происходит инициализация арбитра и, если это необходимо, СУМ ведущих устройств магистрали. Эта процедура описана выше и здесь не конкретизируется.
2. Полагаем, что вычислительная система функционирует. Процессоры ведущих устройств выполняют команды соответствующих программ и периодически захватывают магистраль для реализации обмена M-S.
3. При возникновении готовности какого-либо из ведущих устройств магистрали его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по ЛЗПД любой ШАр) в арбитре магистрали происходит анализ сигналов линий ЛПЗ. Наличие сигнала на любой линии означает, что в текущий момент магистраль занята другим устройством, ведущим обмен.
Одновременно выполняется процедура установления приоритета ШАр, с которой поступил запрос (или запросы, если их поступило несколько). Пусть наиболее приоритетным оказался запрос
по ШАрn.
5. Дальнейшие операции зависят от результата анализа линий ЛПЗ (сигналов ПЗ), а именно:
При отсутствии сигналов ПЗ на линиях ЛПЗ (т.е. свободной магистрали) арбитр выставляет сигнал РПДn на линию ЛРПДn наиболее приоритет-
ной ШАр.
При наличии сигнала ПЗ на какой-либо из линий ЛПЗ (т.е. занятой магистрали) арбитр сравнивает приоритет устройства, занимающего магистраль, с приоритетом выделенного запроса (т.е. приоритетом ШАрn):
- Если приоритет поступившего запроса ниже, то арбитр ожидает окончание текущего обмена и снятия сигнала ПЗ. После этого арбитр выставляет сигнал РПДn на линию ЛРПДn наиболее приоритетной ШАрn.
- Если приоритет поступившего запроса выше, то арбитр выставляет сигнал БПД на линии ЛБПД ШАр, т.е. запрещает активным устройствам магистрали bus mastering. Устройство прекращает операции обмена, освобождает магистраль и снимает сигнал ПЗ. Только после этого арбитр выставляет сигнал РПДn
на линию ЛРПДn наиболее приоритетной ШАрn.
6. Поступление сигнала РПДn разрешает устройствам ШАрn
bus mastering, т.е. захват магистрали. Распространение сигнала РПДn
блокируется устройством ИЗПДn,i, выставившим запрос. С этого момента шинами системной магистрали управляет блок СУМ выбранного устройства ИЗПДn,i
(master), который выставляет также сигнал ПЗn,i. Кроме того, в арбитре или самом ИЗПДn,i
запускается внутренний таймер, контролирующий время удержания магистрали.
7. Блок СУМ активного устройства магистрали (master) выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен M-S одним байтом или словом.
8. Блок СУМ активного устройства производит модификацию адреса и счетчика байт.
9. Блок СУМ активного устройства контролирует размер переданного блока данных. Размер блока контролируется обычно по количеству переданных байтов (слов).
10. Контролируется время удержания магистрали устройством, ведущим обмен. Этот контроль может осуществляться как арбитром, так и самим устройством ИЗПДn,i по встроенному таймеру.
11. Дальнейшие действия зависят от результатов операций в п. 9 и 10, а
именно:
Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с п. 7.
Если блок информации передан полностью (обмен закончен), то master освобождает системную магистраль и снимает сигнал ПЗn,i.
Если время удержания магистрали истекло (хотя обмен и не закончен), то master освобождает магистраль либо сам, либо после выставления арбитром сигнала БПД, который запрещает активным устройствам магистрали bus mastering.
12. Начинается процедура захвата магистрали ведущим устройством с меньшим приоритетом (организация канала M-S), если запрос в арбитр уже поступил (см. операции, начиная с п. 4).
В простых системах bus master DMA цепочечной структуры может присутствовать только одна ЛЗПД. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали. Такие системы bus master DMA являются наиболее динамичными, даже при достаточно большом количестве ИЗПД.
CHIPSET
ChipSet – это набор или одна микросхема, на которую и возлагается основная нагрузка по обеспечению центрального процессора данными и командами, а также, по управлению периферией, как-то: видеокарты, звуковая система, оперативная память, дисковые накопители и различные порты ввода/вывода. Они содержат в себе контроллеры прерываний и прямого доступа к памяти. Обычно в одну из микросхем набора входят также часы реального времени с CMOS-памятью и иногда – контроллер клавиатуры. Однако эти блоки могут присутствовать и в виде отдельных чипов. В последних разработках в состав микросхем наборов для интегрированных плат стали включаться и контроллеры внешних устройств. Внешне микросхемы Chipset'а выглядят как самые большие после процессора, с количеством выводов от нескольких десятков до двух сотен. Название набора обычно происходит от маркировки основной микросхемы – i810, i810E, i440BX, I820, VIA Apollo Pro 133A, SiS630, UMC491, i82C437VX и т.п. При этом используется только код микросхемы внутри серии: например полное наименование SiS471 – SiS85C471. Последние разработки используют и собственные имена. В ряде случаев это фирменное название (INTEL, VIA, Viper). Тип набора в основном определяет функциональные возможности платы: типы поддерживаемых процессоров, структура и объем кэш, возможные сочетания типов и объемов модулей памяти, поддержка режимов энергосбережения, возможность программной настройки параметров и т.п. На одном и том же наборе может выпускаться несколько моделей системных плат, от простейших до довольно сложных с интегрированными контроллерами портов, дисков, видео и т.д.
ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ПАМЯТИ ВИРТУАЛЬНАЯ ПАМЯТЬ
Во многих случаях большие исполняемые программы и структуры данных не удается полностью разместить в ОП, поскольку емкости существующих ОП ограничены. Особенно остро эта проблема стоит в мультипрограммных, многопользовательских системах, выполняющих, грубо говоря, несколько программ одновременно. Естественно, в каждый момент времени ЭВМ выполняет команду какой-то одной программы. Однако всякий раз, когда выполнение процессором некоторой программы приостанавливается из-за необходимости произвести, например, операцию ВВ, процессор переходит к обработке другой, готовой для выполнения программы. При этом предполагается, что одновременно в ОП присутствует несколько программ, которые могут находиться в активном состоянии, состоянии готовности или ожидания. Однако нет принципиальной необходимости в том, чтобы все программы целиком (или одна большая программа) находились в ОП, так как в любой момент времени работа программы концентрируется на определенных, сравнительно небольших участках. Таким образом, в ОП следует хранить только используемые в данный период части программ, а неиспользуемые части (программ или программы) могут храниться во внешней памяти ЭВМ (ВП).
Вводя в ЭВМ свою программу, пользователь не знает, в комбинации с какими программами будет выполняться его программа, какое место в памяти отведет ей операционная система, поэтому при подготовке программ используются условные адреса (подготовка – имеется в виду операция компиляции программы). Позднее, в процессе выполнения программы, операционная система выделяет активным частям программы место в памяти, и условные адреса переводятся в исполнительные. Эта процедура получила название динамического распределения памяти.
Осуществление динамического распределения чисто программным путем привело бы к значительным потерям машинного времени, поэтому для этой цели используются также аппаратные средства.
Наиболее распространенный способ динамического распределения памяти основан на использовании базовых регистров. Операционная система каждой пользовательской программе ставит в соответствие свой базовый адрес.
Базовые адреса обрабатываемых программ находятся в общих регистрах процессора. При выполнении программы физический адрес образуется суммированием базового и относительного адресов. При динамическом распределении памяти с помощью базовых регистров программа (или, по крайней мере, та часть ее, адреса которой преобразуются с помощью одного и того же базового адреса) должна располагаться в последовательных ячейках и вводиться в ОП целиком, хотя в ближайшем цикле активности может потребоваться лишь небольшой фрагмент программы.
При рассмотренном способе динамического распределения памяти свободная память может состоять из несвязных областей (фрагментация
памяти) и для ввода нужной программы может понадобиться сдвиг содержимого памяти. Это можно проиллюстрировать примером на рис. 9.11.
Первоначально ОП распределяется между программами A, B, C, D. Программы A и D в данный момент наименее активны и могут рассматриваться как кандидаты на удаление во внешнюю память. Если вновь вводимая программа E больше любой из программ A и D, то для ее размещения в памяти необходимо сдвинуть программы B и C "вверх" или "вниз". Это перемещение связано с потерей времени. Более того, в ряде прежних операционных систем такое перемещение требовало выполнения заново операции редактирования связей в программе и новой загрузки программы.
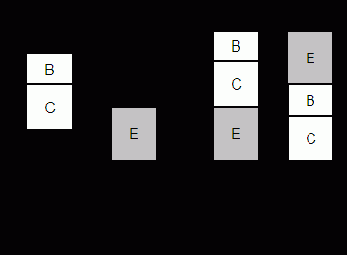
Отмеченные недостатки в распределении ОП отсутствуют в виртуальной
памяти со страничной организацией.
ИНИЦИАЛИЗАЦИЯ СРЕДСТВ ПДП
Любой способ организации обмена в режиме slave DMA предполагает инициализацию контроллера со стороны процессора. Для этого, как уже отмечалось, перед началом обмена с ПУ в режиме ПДП процессор должен загрузить в регистры контроллера для каждого канала ПДП начальные адреса выделенных областей памяти и их размер в байтах или в словах в зависимости от того, какими единицами информации ведется обмен, направление и режим передачи. Кроме того, если конкретный контроллер это позволяет, программа инициализации должна установить дисциплину обслуживания каналов ПДП (арбитража), а также запрограммировать внутренний таймер, контролирующий время удержания магистрали.
Все изложенное выше справедливо для простейшего варианта обмена – slave DMA, при котором всеми операциями обмена управляет контроллер ПДП. При использовании режима bus master DMA в системах как радиальной, так и цепочечной структуры контроллер ПДП отсутствует. Остается только арбитр магистрали, который также требует инициализации. В зависимости от "интеллектуальности" арбитра его инициализация осуществляется либо вручную с помощью переключателей (перемычек), либо программным путем. В последнем случае инициализация осуществляется либо из встроенного ПЗУ, либо одним из ведущих устройств магистрали при запуске вычислительной системы. Дисциплина арбитража в этом случае остается неизменной на все время функционирования вычислительной системы. Однако если предусмотрена возможность изменения дисциплины арбитража, повторная инициализация арбитра может выполняться в процессе обработки текущей программы процессором одного из ведущих устройств магистрали.
В общем случае СУМ интеллектуальных устройств магистрали, которые могут выступать как master, также требуют инициализации, т.е. загрузки адресов и режимов обмена, размеров передаваемых блоков информации и т.д. Однако во многих случаях master ведет обмен, руководствуясь только потребностями собственного программного обеспечения, записанного в локальное ПЗУ.
Рассмотрим упрощенные алгоритмы организации обмена (захвата магистрали) для обеих структур систем ПДП – радиальной и цепочечной.
ЭВМ RISC-АРХИТЕКТУРЫ
Развитие архитектуры ЭВМ, направленное на повышение их производительности, в последние десятилетия шло по пути усложнения процессоров путем расширения системы команд, введения сложных команд, выполняющих процедуры, приближающиеся к примитивам языков высокого уровня, увеличения числа используемых способов адресации и т.д.
Однако расширение и усложнение набора команд порождает и ряд нежелательных побочных эффектов. Расширение набора команд, числа способов адресации, введение сложных команд сопровождается увеличением длины команды и, в первую очередь, кода операции, что ведет к увеличению числа форматов команд. Это вызывает усложнение и замедление процесса дешифрации кода операции и других процедур обработки команд в процессоре. Возрастающая сложность процедур обработки команд заставляет использовать микропрограммные управляющие устройства с управляющей памятью (микропрограммные УУ) вместо более быстродействующих УУ с жесткой логикой. Усложнение процессора делает более трудным и даже невыполнимым реализацию его на одном кристалле БИС. А размещение процессора в одном кристалле за счет сокращения длин межсоединений облегчает достижение высокой производительности.
Сказанное выше объясняет, почему в начале 80-х гг. сформировалось альтернативное по отношению к усложнению архитектуры процессоров направление. При создании относительно дешевых высокопроизводительных ЭВМ оно использует архитектуру с сокращенным набором команд (СНК-архитектура), называемую в зарубежной литературе RISC-архитектурой. Ниже рассматриваются только основные принципы, заложенные в основу классической RISC-архитектуры.
RISC-архитектура предполагает реализацию в ЭВМ сокращенного набора простейших, но часто употребляемых команд. Это позволяет упростить аппаратные средства процессора и получить возможность повысить его быстродействие. При использовании RISC-архитектуры выбор набора команд и структуры процессора направлены на то, чтобы команды набора выполнялись за один машинный цикл процессора. Выполнение более сложных, но редко встречаемых операций обеспечивают подпрограммы.
В RISC- ЭВМ машинным циклом называется время, в течение которого производится выборка двух операндов из регистров, выполнение операции в АЛУ и запоминание результатов в регистре. Большинство команд в RISC являются быстрыми командами типа "регистр-регистр" и выполняются без обращения к ОП. Для того, чтобы это было возможно, процессор должен содержать достаточно большое число общих регистров.
Таким образом, ЭВМ RISC-архитектуры имеют ряд характерных особенностей:
- сокращенный набор команд (обычно не более 50-100);
- небольшое число (обычно 2-3) простых способов адресации;
- небольшое число простых форматов команд с фиксированными размерами и функциональным назначением полей.
Все это упрощает УУ процессора и позволяет обходиться без микропрограммного уровня управления и управляющей памяти, т.е. УУ может быть выполнено на быстродействующей жесткой логике.
Рассмотренные выше особенности, присущие ЭВМ RISC-архитектуры, приводят к столь значительному упрощению процессора, что возникает возможность размещения в одном кристалле не только процессора, но и большого количества общих регистров. В современных БИС МП RISC-архитектуры число общих и специализированных регистров достигает десятков и сотен при существенном сокращении общего числа транзисторов процессора. Так, например, для реализации 32-разрядных процессоров RISC-архитектуры, соответствующих производительности процессоров класса I80386, требуется менее 50 000 транзисторов, в то время как для процессоров традиционной архитектуры (CISC) – более 150 000.
Большое число РОН, особенно при наличии обеспечивающего их эффективное использование "оптимизирующего компилятора", позволяет до предела сократить обращение к ОП. Это достигается:
- за счет того, что промежуточный результат вычисления сохраняется на регистрах;
- передача операндов из одних программ в другие или подпрограммы осуществляется через регистры;
- не требуется передачи на сохранение в ОП содержимого регистров при прерываниях.
Одной из характерных особенностей RISC-архитектуры является широкое использование механизма перекрывающихся регистровых окон. Он предназначен для уменьшения числа обращений к ОП и межрегистровых передач, что способствует повышению производительности ЭВМ.
Процедурам динамически выделяются небольшие группы регистров фиксированной длины (регистровые окна). Окна последовательно выполняемых процедур перекрываются, благодаря чему возможна передача параметров от одной процедуры к другой. При вызове процедуры процессор переключается на работу с другим регистровым окном. При этом не возникает необходимость в передаче содержимого регистров в память.
Окно состоит из трёх подгрупп регистров (рис. 9.5). Полагаем, что вызов процедур идет снизу вверх, т.е. процедура A вызывает процедуру B, причем сама была вызвана некоторой предшествующей процедурой. Первая подгруппа содержит параметры, переданные данной процедуре (A) от ее вызвавшей, и результаты для вызывающей процедуры при возврате в нее. Вторая подгруппа содержит локальные переменные процедуры A. Третья является буфером для двухстороннего обмена между процедурой A и вызываемой ею процедурой B. Процедура A передает B параметры при вызове. При возврате из процедуры B в процедуру A последняя получает через этот буфер результаты работы процедуры B. Таким образом, одна и та же подгруппа для процедуры A является регистрами временного хранения, а для следующей (процедуры B) – регистрами параметров. Отдельное окно, доступное всем процедурам программы, выделяется для ее глобальных переменных.

Следует отметить, что компьютеров, полностью удовлетворяющих определению RISC-архитектуры, относительно немного. В большинстве случаев это компьютеры, близкие к RISC-архитектуре. Например, одним из первых компьютеров такого типа являлся высокопроизводительный РС фирмы IBM PC-RT. Он имел 118 команд, всего два способа адресации и два формата команд, 16 РОН, среднее число циклов на команду – три.
К чисто RISC- архитектуре принято относить процессоры серии "Alpha" фирмы DEC, серию процессоров "Power PC" совместной разработки фирм Motorola, EPL, IBM, серию процессоров "Rxxxx" (R4000, R5000, R10000) фирмы Mips, серию процессоров "РА" фирмы Hewlett Packard, серию процессоров "SPARC" фирмы Sun Microsystems и др.
Несмотря на широкое использование в литературе терминов "RISC" и "CISC", архитектуры современных мощных процессоров трудно поддаются однозначной классификации. Это связано со стремительным усложнением кристаллов процессоров обоих типов архитектур (RISC и CISC), а также с тем, что в целях повышения производительности разработчики объединяют конструктивные решения, характерные для обоих типов архитектур, в одном устройстве. Так, в мощных CISC-процессорах стало обычным использование RISC-ядра, которое позволяет выполнять сложные команды процессора как наборы элементарных команд, реализуемых по принципам RISC-архитектуры.
Следует отметить также, что принципы RISC-архитектуры заложены в идеологию построения транспьютеров, составляющих основу современных матричных процессоров, используемых в суперЭВМ, а также в платах-"ускорителях" для персональных компьютеров.
Несмотря на интенсивное использование RISC-архитектуры в серийных образцах ЭВМ, продолжаются споры вокруг достоинств и недостатков этой архитектуры. К последним, в частности, относят большую длину кода программы после компиляции (объектного кода) по сравнению с длиной кода машин обычной архитектуры. Так, при эмуляции команд ЭВМ типа VAX в среднем на каждую его команду требуется 5-6 команд машин RISC-архитектуры. Однако, как показали исследования, выигрыш в скорости выполнения команд перекрывает проигрыш от удлинения объектного кода
(в общих показателях качества ЭВМ).
ЭВОЛЮЦИЯ ШИННОЙ АРХИТЕКТУРЫ IBM PC
В начале настоящего курса (см. гл.1) было показано, что переход от мэйнфреймов к малым ЭВМ (мини и микро) сопровождался существенным упрощением внутренней структуры компьютера, а именно, переходом к магистрально-модульной структуре, простейший вариант которой представлен на рис. 1.4. Магистрально-модульная структура предполагает наличие в компьютере некоторой общей магистрали, к которой в необходимой номенклатуре и количестве подключены все устройства ЭВМ, выполненные в виде функционально законченных блоков. Эта магистраль получила название системной (см. п. 7.1). Первоначально это был единственный канал связи, по которому внутри ЭВМ передавалась информация между двумя и более компонентами системы. В процессе эволюции мини- и микроЭВМ, а также повышения быстродействия процессоров одной системной магистрали оказалось недостаточно. Однако необходимость преемственности программно-аппаратных средств серийно выпускаемых компьютеров разных поколений не позволила так просто заменить разработанные ранее системные магистрали на более быстродействующие, хотя их производительность не соответствовала производительности новых поколений процессоров. Компромиссным решением этой проблемы оказалось введение помимо основной системной магистрали ряда других, более быстродействующих магистралей, которые получили название локальных шин. В процессе эволюции ЭВМ некоторые из них потеряли свое значение и исчезли (например, VLB), другие продолжали развиваться, принимая на себя все больше функций основной системной магистрали (например, PCI). Ввиду этого в современных компьютерах помимо основной системной магистрали, имеется ряд быстродействующих локальных шин различного назначения.
Прежде чем перейти к рассмотрению основных этапов эволюции шинной архитектуры PC фирмы IBM, необходимо сделать ряд замечаний. Уже отмечалось, что в литературе встречаются различные термины для обозначения системной или общей магистрали. Это прежде всего термины: "общая шина", "системная шина", "шина ВВ" и "шина расширения".
Последний термин отражает тот факт, что системная магистраль позволяет подключать к компьютеру дополнительные ПУ для расширения или изменения его возможностей, т.е. позволяет изменять конфигурацию оборудования. При этом часть устройств ВВ устанавливается непосредственно на системной (материнской) плате и не может быть заменена пользователем, а часть устройств ВВ размещается в слотах, установленных на системной магистрали. При взаимодействии с МП те и другие используют одну и ту же системную магистраль. Количество слотов расширения может быть разным. В первом IBM PC их было пять, а в PC/XT – восемь. В последующих моделях РС, имеющих быстродействующие локальные шины, их число изменялось в зависимости от конкретной конфигурации материнской платы.
При дальнейшем изложении материала будет использоваться термин шина расширения (ШР), поскольку сама системная магистраль уже в первых РС претерпела существенные изменения по сравнению с классическим вариантом структуры простейшей микроЭВМ, изображенным на рис. 1.4.
КОМПОНЕНТЫ МАТЕРИНСКОЙ ПЛАТЫ
В настоящее время появилось очень много компьютерных салонов, и нам с вами, когда возникает необходимость покупки компьютера, представляется сложная дилемма, куда же пойти и что, собственно говоря, купить. В данной статье делается попытка объяснить читателю смысл всех компьютерных сокращений, которые так любят применять торговые менеджеры.
Сердцем современного компьютера, как это ни покажется странным, является не процессор, как принято считать (хотя о нем здесь тоже пойдет речь), а материнская плата. Поэтому разберем, что же это такое и с чем ее едят.

Ну, собственно говоря, вы и сами уже знаете, как выглядит материнская плата, а вот о назначении и различии разъемов, перемычек и микросхем дальше и пойдет речь.
КОНТРОЛЬНЫЕ ЗАДАНИЯ
1. На листах ответа должны быть указаны номер группы, фамилия студента и номер его варианта.
2. Номера вопросов выбираются студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 8.1 аn-1 – это предпоследняя цифра номера, аn – последняя цифра. В клетках таблицы стоят номера вопросов, на которые необходимо дать письменный ответ.
Номера вопросов Таблица 8.1
| an
an-1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||
| 0 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,17 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,17 | |||||||||||
| 1 | 5,9,11,15 | 6,7,12,16 | 2,7,10,17 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,17 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 2 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,17 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,17 | |||||||||||
| 3 | 5,9,11,15 | 6,7,12,16 | 2,7,10,17 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,17 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 4 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,17 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,17 | |||||||||||
| 5 | 5,9,11,15 | 6,7,12,16 | 2,7,10,17 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,17 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 6 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,17 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,17 | |||||||||||
| 7 | 5,9,11,15 | 6,7,12,16 | 2,7,10,17 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,17 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 8 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,17 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,17 | |||||||||||
| 9 | 5,9,11,15 | 6,7,12,16 | 2,7,10,17 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,17 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 |
1. На листах ответа должны быть указаны номер группы, фамилия студента и номер его варианта.
2. Номера вопросов выбираются студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 9.1 аn-1 – это предпоследняя цифра номера, аn – последняя цифра. В клетках таблицы стоят номера вопросов, на которые необходимо дать письменный ответ.
Номера вопросов Таблица 9.1
| an
an-1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |||||||||||
| 0 | 1,5,9, 13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | 2,8,9, 15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 | |||||||||||
| 1 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9, 16,23 | 1,5,11,14,21 | 3,6,9, 14,19 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | |||||||||||
| 2 | 1,6,9, 18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9, 18,22 | 2,7,9, 17,19 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9, 17,21 | |||||||||||
| 3 | 1,5,9, 13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | 2,8,9, 15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 |
Окончание табл. 9.1
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |||||||||||
| 4 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9, 16,23 | 1,5,11,14,21 | 3,6,9, 14,19 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | |||||||||||
| 5 | 1,6,9, 18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9, 18,22 | 2,7,9, 17,19 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9, 17,21 | |||||||||||
| 6 | 1,5,9, 13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | 2,8,9, 15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 | |||||||||||
| 7 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9, 16,23 | 1,5,11,14,21 | 3,6,9, 14,19 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | |||||||||||
| 8 | 1,6,9, 18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9, 18,22 | 2,7,9, 17,19 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9, 17,21 | |||||||||||
| 9 | 1,5,9, 13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | 2,8,9, 15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 |
1. На листах ответа должны быть указаны номер группы, фамилия студента и номер его варианта.
2. Номера вопросов выбираются студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 10.1 аn-1 – это предпоследняя цифра номера, аn – последняя цифра. В клетках таблицы стоят номера вопросов, на которые необходимо дать письменный ответ.
Номера вопросов Таблица 10.1
| an
an-1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||
| 0 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,13 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,14 | |||||||||||
| 1 | 5,9,11,15 | 6,7,12,16 | 2,7,10,15 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,16 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 2 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,13 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,14 | |||||||||||
| 3 | 5,9,11,15 | 6,7,12,16 | 2,7,10,15 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,16 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 4 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,13 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,14 | |||||||||||
| 5 | 5,9,11,15 | 6,7,12,16 | 2,7,10,15 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,16 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 6 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,13 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,14 | |||||||||||
| 7 | 5,9,11,15 | 6,7,12,16 | 2,7,10,15 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,16 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 | |||||||||||
| 8 | 1,7,10,13 | 2,8,11,14 | 3,9,12,15 | 4,7,10,16 | 5,8,11,13 | 6,9,12,14 | 1,8,10,15 | 2,9,11,16 | 3,7,12,13 | 4,8,10,14 | |||||||||||
| 9 | 5,9,11,15 | 6,7,12,16 | 2,7,10,15 | 1,9,10,13 | 2,7,11,14 | 3,8,12,15 | 4,9,10,16 | 5,7,11,13 | 6,8,12,14 | 5,9,12,16 |
1. На листах ответа должны быть указаны номер группы, фамилия студента и номер его варианта.
2. Номера вопросов выбираются студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 11.1 аn-1 – это предпоследняя цифра номера, аn – последняя цифра. В клетках таблицы стоят номера вопросов, на которые необходимо дать письменный ответ.
Номера вопросов Таблица 11.1
| an
an-1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||
| 0 | 1,7, 10,13 | 2,8, 11,14 | 3,9, 12,15 | 4,7, 10,16 | 5,8, 11,13 | 6,9, 12,14 | 1,8, 10,15 | 2,9, 11,16 | 3,7, 12,13 | 4,8, 10,14 | |||||||||||
| 1 | 5,9, 11,15 | 6,7, 12,16 | 2,7, 10,15 | 1,9, 10,13 | 2,7, 11,14 | 3,8, 12,15 | 4,9, 10,16 | 5,7, 11,13 | 6,8, 12,14 | 5,9, 12,16 | |||||||||||
| 2 | 1,7, 10,13 | 2,8, 11,14 | 3,9, 12,15 | 4,7, 10,16 | 5,8, 11,13 | 6,9, 12,14 | 1,8, 10,15 | 2,9, 11,16 | 3,7, 12,13 | 4,8, 10,14 | |||||||||||
| 3 | 5,9, 11,15 | 6,7, 12,16 | 2,7, 10,15 | 1,9, 10,13 | 2,7, 11,14 | 3,8, 12,15 | 4,9, 10,16 | 5,7, 11,13 | 6,8, 12,14 | 5,9, 12,16 | |||||||||||
| 4 | 1,7, 10,13 | 2,8, 11,14 | 3,9, 12,15 | 4,7, 10,16 | 5,8, 11,13 | 6,9, 12,14 | 1,8, 10,15 | 2,9, 11,16 | 3,7, 12,13 | 4,8, 10,14 | |||||||||||
| 5 | 5,9, 11,15 | 6,7, 12,16 | 2,7, 10,15 | 1,9, 10,13 | 2,7, 11,14 | 3,8, 12,15 | 4,9, 10,16 | 5,7, 11,13 | 6,8, 12,14 | 5,9, 12,16 | |||||||||||
| 6 | 1,7, 10,13 | 2,8, 11,14 | 3,9, 12,15 | 4,7, 10,16 | 5,8, 11,13 | 6,9, 12,14 | 1,8, 10,15 | 2,9, 11,16 | 3,7, 12,13 | 4,8, 10,14 | |||||||||||
| 7 | 5,9, 11,15 | 6,7, 12,16 | 2,7, 10,15 | 1,9, 10,13 | 2,7, 11,14 | 3,8, 12,15 | 4,9, 10,16 | 5,7, 11,13 | 6,8, 12,14 | 5,9, 12,16 | |||||||||||
| 8 | 1,7, 10,13 | 2,8, 11,14 | 3,9, 12,15 | 4,7, 10,16 | 5,8, 11,13 | 6,9, 12,14 | 1,8, 10,15 | 2,9, 11,16 | 3,7, 12,13 | 4,8, 10,14 | |||||||||||
| 9 | 5,9, 11,15 | 6,7, 12,16 | 2,7, 10,15 | 1,9, 10,13 | 2,7, 11,14 | 3,8, 12,15 | 4,9, 10,16 | 5,7, 11,13 | 6,8, 12,14 | 5,9, 12,16 |
Учебное издание
Хмелевский Игорь Васильевич
Битюцкий Валерий Петрович
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
ОДНОПРОЦЕССОРНЫЕ ЭВМ
ЧАСТЬ 3
Редактор издательства И.Г.Южакова
Компьютерный набор авторский
Подписано в печать 20.06.2005 Формат 60 х 84 1/16
Бумага типографская Офсетная печать Усл. печ. л. 6,84
Уч.-изд. л. 9,25 Тираж 150 Заказ Цена «С»
Редакционно-издательский отдел ГОУ ВПО УГТУ-УПИ
620002, Екатеринбург, ул. Мира, 19
Ризограф НИЧ ГОУ ВПО УГТУ-УПИ
620002, Екатеринбург, ул. Мира, 19
КОНВЕЙЕР КОМАНД
Более подробно вопросы конвейеризации процесса обработки информации в ЭВМ рассматриваются в последних разделах настоящего курса – "Многопроцессорные системы". Здесь же будут рассмотрены только основные принципы конвейеризации процедур цикла выполнения команды (рабочего цикла машины).
Ранее, при рассмотрении принципов функционирования УУ процессоров, уже упоминалось о конвейерном способе выполнения микрокоманд, когда процедура выполнения i-й микрокоманды в АЛУ совмещалась по времени с процедурой вызова из управляющей памяти i+1 микрокоманды. Этот принцип распространяется и на выполнение команд машины. Еще в 1956 г. академик Лебедев С.А. предложил повышать производительность машин, используя принцип совмещения во времени отдельных этапов рабочего цикла, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды.
В современных ЭВМ очень широко используются различные варианты конвейерного способа выполнения операций, что существенно повышает их производительность. Не вдаваясь в подробности, рассмотрим простейший пример конвейерного способа выполнения микропроцессором операции сложения двух операндов, находящихся в ОП. Для этого необходимо выполнить две команды: 1-я – вызов первого операнда в аккумулятор; 2-я – вызов второго операнда и сложение. В процессе выполнения 1-й команды можно использовать ресурсы МП во время ожидания ответа ОП (например, в МП КР580 это такт Т2 каждого машинного цикла). Для этого необходимо, чтобы вместо пассивного режима ожидания МП инициировал новый цикл обмена с ОП для вызова 2-й команды. По соответствующим сигналам готовности ОП последовательно заканчиваются 1-й и 2-й циклы обращения к памяти и выполняется операция сложения. При этом время каждого обращения к ОП не уменьшается, но суммарное время выполнения двух команд оказывается меньше за счет их перекрытия во времени. Практика показала, что использование конвейера в той или иной форме существенно повышает в среднем
скорость обмена процессор – ОП. При этом, естественно, усложняется программное и аппаратное обеспечение ЭВМ в целом
(а не только одного МП).
В общем случае конвейерный принцип позволяет процессору параллельно выполнять множество команд. Однако в этом случае как единое устройство процессор функционировать уже не может. Последовательность выполнения каждой команды разделяется в процессоре на основные операции. Для выполнения операций каждого типа служат специализированные исполнительные устройства.
Наиболее общий прием конвейеризации заключается в том, что во время выполнения предыдущей команды с упреждением производится выборка из памяти очередной команды. Тем самым достигается рациональное использование времени работы шины, которое при обычной архитектуре процессора затрачивалось впустую, и сокращается длительность выполнения программы, хотя длительность цикла выполнения отдельных команд может даже несколько увеличиться.
Совмещение во времени этапов цикла выполнения команды давно и широко используется в процессорах, которые в этом случае представляют собой совокупность специализированных исполнительных блоков, управляемых одним УУ. Так, например, в МП фирмы Zilog Z80000 использован шестиступенчатый конвейер, а цикл выполнения команды состоит соответственно из шести этапов:
- выборки команды;
- декодирования команды;
- вычисления адреса операнда;
- выборки операнда;
- собственно выполнения операции;
- запоминания результата.
Когда в конвейере заканчивается выполнение определенного этапа предыдущей команды, высвобождается соответствующий исполнительный блок и может быть начато выполнение аналогичного этапа следующей команды. В идеальной ситуации очередная команда должна поступать на конвейер в тот момент, когда предыдущая команда с него сходит. Это соответствует шестикратному повышению производительности.
Однако при исполнении реальных программ максимальная производительность никогда не достигается по ряду причин. Это, прежде всего:
- различные продолжительности этапов выполнения команды, что вынуждает выбирать такт работы конвейера соответствующим продолжительности выполнения самого "медленного" этапа. Это приводит к некоторому увеличению длительности цикла выполнения отдельной команды (времени прохождения команды через конвейер) по сравнению с потенциально возможной;
- использование не в каждой команде всех исполнительных блоков, что требует дополнительных временных затрат на работу специальных переключающих схем;
- нарушение последовательности выполнения команд программы, которое имеет место при наличии команд передачи управления или прерываниях.
Нарушение строго последовательного выполнения команд программы вызывает необходимость очистки конвейера от команд, выполнение которых началось после команды, нарушившей эту последовательность (торможение конвейера), и повторного заполнения конвейера командами с новой точки программы (разгон конвейера). Доля команд, на которых естественная последовательность выполнения программы нарушается, обычно составляет 15-30% от общего количества команд. При этом вызываемое процентное снижение производительности превышает вероятность их появления в программе.
Наличие команд передачи управления и, в частности, команд условных переходов оказывает самое существенное влияние на производительность конвейера команд, поэтому разработчики идут на существенное усложнение архитектуры процессоров в целях уменьшения этого влияния. Основные пути уменьшения влияния команд условных переходов на производительность конвейера команд состоят в следующем:
- прогнозировании направления перехода по косвенным признакам;
- одновременной обработке команд по обоим направлениям перехода (в более простом случае – создание очередей команд);
- выборе направления перехода на основании анализа статистики ранее совершенных аналогичных переходов в теле цикла;
- выборе случайного направления перехода;
- методе "отложенных переходов", при котором на этапе компиляции после команды условного перехода размещаются команды, не связанные с направлением перехода (число таких команд равно числу ступеней конвейера).
Для уменьшения влияния различной продолжительности этапов цикла выполнения команды на производительность разработчики искусственно увеличивают число ступеней конвейера, разбивая этапы на подэтапы, продолжительность выполнения которых примерно одинакова. Однако увеличение числа ступеней конвейера ведет к увеличению времени разгона, которое может существенно понизить общую производительность конвейера при обработке программ с короткими линейными участками. Виду этого число ступеней конвейера команд должно быть оптимальным.
Опыт построения конвейеров команд показывает, что полностью исключить влияние перечисленных выше факторов на производительность конвейера команд не удается. Максимальная производительность возможна только при обработке программ, имеющих длинные линейные участки, с использованием всех ступеней конвейера.
Существуют методы грубой оценки повышения производительности ЭВМ за счет использования конвейера, но они справедливы только для конкретного типа задач и в данном разделе не рассматриваются.
При рассмотрении метода конвейеризации обмена был проигнорирован тот факт, что реальные устройства ОП не допускают одновременного обращения к нескольким ячейкам (имеются в виду реальные БИСы памяти, охваченные общим полем адресов). Выйти из этого положения позволяет следующий метод.
ЛОКАЛЬНАЯ ШИНА PCI
В начале 1992 года на фирме Intel была организована группа, перед которой была поставлена задача разработать новую шину. В результате в июне 1992 года появилась шина PCI (Peripheral Component Interconnect bus), в апреле 1993 она была модернизирована. Ее создатели отказались от традиционной концепции, введя еще одну шину между МП и обычной шиной ВВ. Вместо того чтобы подключаться непосредственно к шине процессора, чувствительной к подобным вмешательствам
(о чем сказано выше), новый комплект ИС (чипсет) позволял создавать новую архитектуру шин IBM PC. Первые компьютеры с шиной PCI появились в середине 1993 года, и вскоре она стала неотъемлемой частью компьютеров класса high end.
Новая локальная шина существенно превосходила своих предшественниц по функциональным возможностям, производительности, надежности. Наличие чипсета делает шину PCI процессорно-независимой, что позволяет ее использовать с платформами не только на Intel-подобных процессорах. Это является очевидным преимуществом с точки зрения производителей плат расширения (адаптеров), которые стараются избегать разных версий одной и той же платы. Кроме того, наличие чипсета позволяет шине PCI работать параллельно с шиной процессора, не обращаясь к ней со своими запросами. Это даёт возможность процессору работать с данными, находящимися во внешнем кэш, в то время как по шине PCI может происходить обмен между ПУ и ОП в режиме ПДП (DMA).
Первоначально в IBM PC использовалась только версия 2.0 шины PCI, поддерживаемая чипсетами малой интеграции (5-6 микросхем) типа Neptun или Saturn. Однако с появлением чипсетов большей интеграции типа Intel 430 (Triton), Intel 440, Intel 810 в IBM PC стала использоваться новая версия шины PCI-2.1, которая вскоре была заменена версией PCI-2.2 (например, чипсет Intel 815). Эта версия используется и в настоящее время (чипсеты Intel 850, Intel 860, VIA KT 266 для процессоров AMD и др.). Версии 2.0, 2.1 и 2.2 имеют обратную совместимость на тактовой частоте 33 МГц. Основные возможности шины PCI следующие:
Синхронный 32- или 64- разрядный обмен данными. Для уменьшения числа линий шины и контактов слота (а следовательно, и стоимости) используется мультиплексирование ША и ШД, т.е. для передачи адресов и данных используются одни и те же линии шины. Следует отметить, что 64-разрядная PCI, судя по всему, в обычных IBM PC пока не используется.
Поддержка режима пакетных передач (linear burst), позволяющего не расходовать время шины на установку адреса каждого элемента данных при обмене блоком информации. Адрес автоматически модифицируется чипсетом для каждого последующего элемента данных. Это существенно повышает производительность шины при обмене ядра ЭВМ с видеосистемами и жесткими дисками большими блоками информации.
Тактовая частота шины 33 МГц или 66 МГц (только для версий выше 2.0). Это позволяет обеспечить следующие максимальные пропускные способности шины с использованием пакетного режима:
ü 132 Мбайт/с при 32-бита/33 МГц;
ü 264 Мбайт/с при 32-бита/66 МГц;
ü 264 Мбайт/с при 64-бита/33 МГц;
ü 528 Мбайт/с при 64-бита/66 МГц.
Работа на тактовой частоте 66 МГц возможна, если все адаптеры шины поддерживают эту частоту.
Поддержка внешнего кэш с обратной и сквозной записью (write back и write through).
Автоматическое конфигурирование карт расширения при включении питания.
Полная поддержка режима multiply bus master, при котором на шине одновременно могут работать, например, несколько контроллеров жестких дисков.
Установка запросов прерывания осуществляется по уровню (а не по фронту, как в шинах ISA и VLB), что делает систему прерывания более надежной и позволяет использовать одну линию прерывания для обслуживания нескольких ПУ.
Спецификация шины позволяет комбинировать до восьми функций на одной плате (например, видео + звук + и т.д.).
Шина позволяет устанавливать до четырех слотов расширения, конструкция которых существенно отличается от конструкции слотов шины ISA (EISA).
Для увеличения числа подключаемых устройств (необходимость в этом возникает обычно в мощных серверных платформах) предусмотрено использование двух и более шин PCI, соединяемых одноранговыми мостами (peer-to-peer bridge). Следует отметить, что с разработкой нового поколения чипсетов (например, Intel 850, Intel 845, Intel 815, VIA KT 266 и др.) число слотов расширения, устанавливаемых на одной шине PCI, увеличилось до 5-6.
Шина PCI имеет версии с питанием 5 В и 3.3 В. Разъемы для плат с питанием 5 В и 3.3 В различаются расположением ключей. Существуют и универсальные платы с переключаемым напряжением питания. Тактовая частота 66 МГц поддерживается только логикой питания 3.3 В.
Наличие в устройстве шины PCI таймера, используемого для определения максимального интервала времени, в течение которого устройство может занимать шину при передаче блока информации.
Рассматривая возможности шины PCI, необходимо иметь в виду, что чипсет является не просто согласующим элементом между различными шинами PC. Он основное связующее звено между всеми компонентами системной платы. Набор решаемых им задач очень обширен и во многом определяет характеристики конкретной модели компьютера, поэтому рассмотрение функциональных возможностей PCI-архитектуры в отрыве от функций чипсета весьма затруднительно. Так, например, возможность выполнения обмена данными между процессором и ОП одновременно с обменом между другими устройствами шины PCI (concurrent PCI transferring), предусмотренная в спецификации шины, реализована не во всех типах
чипсетов.
В общем случае чипсет можно разделить на две функциональные части. Одна часть чипсета обеспечивает взаимодействие шины PCI с локальной системной шиной (т.е. с шиной процессора и шиной памяти). Эту часть принято называть главным мостом (host bridge). Вторая часть обеспечивает взаимодействие шины PCI с ШР ISA и ряд других функций. Эту функциональную часть чипсета принято называть мостом PIIX (PCI, IDE, ISA Xcelerator bridge).
Такому функциональному делению соответствует и разделение набора задач, решаемых чипсетом.
В функции главного моста входит решение следующих задач:
Обслуживание управляющих и конфигурационных сигналов процессора.
Мультиплексирование адреса и формирование управляющих сигналов динамической памяти (ОП), связь шины данных памяти с локальной шиной.
Формирование управляющих сигналов внешнего кэш, сравнение его тегов с текущим адресом обращения на локальной шине (т.е. выполнение функций контроллера кэш-памяти).
Обеспечение когерентности (согласования) данных в обоих уровнях кэш-памяти и ОП при обращении как со стороны процессора, так и контроллеров устройств шины PCI.
Связь мультиплексированной шины адреса и данных шины PCI с шиной процессора и шиной ОП.
Формирование управляющих сигналов шины PCI, арбитраж контроллеров устройств шины (т.е. выполнение функций арбитра шины PCI).
Поддержка магистрального интерфейса AGP (Accelerated Graphic Port), предназначенного для подключения мощных графических адаптеров.
Мост PIIX также является многофункциональным устройством и решает следующие задачи:
Организацию моста между шинами PCI и ISA, EISA, MCA с согласованием частот синхронизации этих шин.
Реализацию высокопроизводительного (обычно двухканального) интерфейса IDE, подключенного к шине PCI.
Реализацию стандартных системных средств ВВ – двух контроллеров прерываний, двух контроллеров ПДП, трехканального системного таймера, канала управления динамиком, логики немаскируемого прерывания.
Коммутацию линий запросов прерывания шин PCI и ISA, а также встроенной периферии на линии запросов контроллеров прерываний, управление их чувствительностью (по перепаду или уровню), обслуживание прерывания от сопроцессора.
Коммутацию каналов ПДП.
Поддержку режимов энергосбережения.
Реализацию моста с внутренней шиной X-Bus, используемой для подключения микросхем контроллера клавиатуры, BIOS, CMOS RTC, контроллеров гибких дисков и интерфейсных портов.
Реализацию контроллера магистрали USB.
Микросхемы чипсета при инициализации во время начального тестирования (POST) программируются по многим параметрам, основная часть которых находится в BIOS.
Таким образом, системные платы, выполненные даже на одном и том же чипсете, могут иметь различные производительности и диапазоны поддерживаемых устанавливаемых компонентов (процессоров, DRAM, кэш). Соответственно и шины PCI, реализованные в различных моделях РС (особенно у разных производителей), могут несколько отличаться по своим функциональным возможностям.
Очень упрощенная структура шин IBM РС (с учетом функций чипсета) при наличии шины PCI представлена на рис. 10.3.
Обозначенные на схеме интерфейсы для подключения высокоскоростных ПУ (AGP, SCSI, IEEE 1394, IDE, USB) в настоящем разделе не рассматриваются. Отметим только, что многие модели современных IBM PC имеют еще ряд других (не обозначены на схеме) специализированных интерфейсов для подключения разнообразных типов ПУ.
Для устройств промышленного назначения в начале 1995 года был принят стандарт Compact PCI, разработанный на основе версии PCI 2.1. Шины Compact PCI и PCI имеют электрическую совместимость и одинаковые протоколы обмена по шине, хотя и имеют некоторые отличия в механизме автоконфигурации системы. В отличие от стандарта PCI стандарт Compact PCI позволяет устанавливать на одной шине до восьми слотов расширения, конструкция которых существенно отличается от конструкции слотов PCI и предназначена для работы компьютера в тяжелых условиях – пыль, вибрация, влажность и т.д.
В заключение следует отметить, что появление шины PCI положило начало полному вытеснению из РС фирмы IBM, в общем-то, устаревшей ШР ISA. В настоящее время шина ISA оказалась практически вытесненной из архитектуры IBM PC и все ее функции выполняет шина PCI, которая из локальной превратилась в основную ШР современных IBM PC.

В качестве дополнения к материалу настоящего раздела ниже приводится сокращенный вариант статьи из интернет-издания "Internet Zone", 2001 г. –http://www.izcity.com/.
ЛОКАЛЬНАЯ ШИНА VESA (VLB)
В своем первоначальном варианте слоты локальной шины использовались почти исключительно для установки видеоадаптеров. К концу 1992 года было разработано несколько локальных шин. Исключительными правами на них обладали только фирмы-изготовители. Отсутствие стандартов сдерживало распространение локальных шин.
Приемлемое решение предложила ассоциация VESA (Video Electronics Standards Association), которая разработала конструкцию стандартной локальной шины, названной VESA Local Bus или просто VLB. Как и в первых конструкциях локальной шины, через слот VLB можно было получить непосредственный доступ к системной памяти, а ее быстродействие равнялось быстродействию самого процессора. По VLB можно было производить 32-разрядный обмен данными между МП и совместимым видеоадаптером, т.е. ее разрядность соответствовала разрядности данных процессора I80486. Максимальная пропускная способность VLB составляла
132 Мбайт/с.
Использование VLB позволяло изготовителям интерфейсных плат жестких дисков устранить еще одно ограничение: низкую скорость обмена данными между жестким диском и МП. Обычный 16-разрядный IDE-накопитель и его интерфейс могут обеспечить скорость передачи данных не выше 5 Мбайт/с, а адаптеры жесткого диска для VLB позволяли увеличить ее до 8 Мбайт/с. В реальных условиях пропускная способность этих адаптеров несколько ниже, тем не менее VLB существенно повышала быстродействие накопителей на жестких дисках.
VLB – стандартизованная 32-битная шина расширения, практически представляющая собой линии шины процессора I80486, выведенные на дополнительные слоты системной (материнской) платы. Конструктивно шина VLB выполнена в виде добавочных слотов, расположенных позади уже существующих системных слотов ШР ISA-16, EISA, МСА (по продольной оси) вблизи процессора. Таким образом, платы адаптеров одновременно вставлялись и в слоты ШР, и в слоты VLB. Слоты шины VLB обычно использовались для подключения графического адаптера и адаптера жесткого диска. Однако существуют системные платы, которые имеют встроенный графический и дисковый интерфейсы с шиной VLB, но сами слоты VLB отсутствуют.
С точки зрения надежности и совместимости такой вариант наиболее оптимален, поскольку проблемы совместимости адаптеров и согласования нагрузок для шины VLB стоят очень остро.
При всех своих достоинствах шина VLB имеет ряд недостатков, основными из которых являются:
Ориентация на процессор I80486. Уже отмечалось, что VLB является по существу продолжением шины процессора I80486, хотя возможно ее использование и с процессором I80386. Для процессоров Pentium была разработана спецификация 2.0 шины VLB, в которой число линий данных было увеличено до 64. Кроме того, спецификация включала аппаратный преобразователь шины Pentium в VLB. Однако дальнейшего развития эта версия не получила.
Ограниченное быстродействие. Стандарт VLB допускает работу с тактовыми частотами до 66 МГц, но частотные характеристики разъемов VLB ограничивают ее на уровне 50 МГц. Если в компьютере установлен переключатель для повышения тактовой частоты процессора (например, для увеличения ее в два раза), то VLB продолжает использовать в качестве тактовой основную час-
тоту МП.
Схемотехнические ограничения. К качеству импульсных сигналов, передаваемых по шине процессора, предъявляются очень жесткие требования, причем они могут быть разными для различных типов ИС процессоров. Соблюсти их можно только при определенных параметрах нагрузки каждой из линий шины, т.е. к шине процессора должен быть подключен вполне конкретный "набор" элементов, например внешний кэш и ИС контроллера шины. При добавлении новых плат нагрузка на линии шины возрастает. Если не принять соответствующих мер, это может привести к искажениям импульсных сигналов ("звонам", завалу фронтов, изменениям логических уровней), а в результате – к потерям данных, нарушениям синхронизации и другим сбоям как самого процессора, так и адаптеров VLB.
Ограничение количества плат. По указанным в предыдущем пункте соображениям количество одновременно используемых адаптеров VLB ограничено. Стандарт VLB допускает одновременную установку трех плат, но это возможно только при тактовой частоте до 40 МГц и малой нагрузке на шину.При ее увеличении и повышении тактовой частоты возможное количество адаптеров уменьшается. При частоте 50 МГц и большой нагрузке разрешается устанавливать всего одну плату VLB.
Указанные недостатки оказались настолько существенными, что в современных IBM PC шина VLB не используется.
ЛОКАЛЬНАЯ СИСТЕМНАЯ ШИНА
Быстродействие ШР первых IBM PC (8 МГц) вполне соответствовало быстродействию процессора I8088, на базе которого они были построены. Между тем для оптимизации процесса обмена между ОП и МП разработчики пошли на усложнение структуры РС и ввели две добавочные шины – шину процессора и шину памяти. Таким образом, обмен внутри ядра ЭВМ (т.е. между ОП и МП) осуществлялся не по ШР, а по автономной магистрали, состоящей из двух шин, которую некоторые авторы называют локальной системной шиной. Этот термин будет использоваться при дальнейшем изложении материала. Взаимодействие шины процессора и шины памяти, а также их взаимодействие с ШР осуществлялось через набор специализированных микросхем (чипсет), которые условно можно назвать контроллером шины. Очень упрощенная структура шин первых IBM PC приведена на рис. 10.1.

Шина процессора является самой быстродействующей и предназначается для передачи данных, команд, адресов и сигналов управления между МП и контроллером шины, который связывает ее с ОП и ШР. Шина процессора первых IBM PC работала на той же тактовой частоте, что и процессор, поэтому слово данных или адрес могли быть переданы по ней в течение одного – двух периодов тактовой частоты процессора (в современных РС тактовая частота шины процессора всегда ниже тактовой частоты процессора). К этой же шине подключался внешний кэш, что позволяло вести обмен процессор – кэш с максимальной скоростью. Число физических цепей в шине процессора существенно различно для различных поколений процессоров. Так, в компьютере с процессором I80286 шина процессора имела 24 линии адреса, 16 линий данных и 12 линий сигналов управления, а в компьютере с процессором Pentium было уже 32 линии адреса, 64 линии данных и почти в три раза больше сигналов линий управления.
Скорость передачи данных по шине процессора (как и по любой другой шине) определяется произведением разрядности шины на тактовую частоту шины, деленному на число тактов, необходимое для передачи одного бита. Так, для первых моделей процессора Pentium с тактовой частотой 66 МГц, совпадающей с тактовой частотой шины процессора, максимальная скорость передачи данных составляет
66 МГц ´ 64 бита = 4224 Мбит/с ® 4224 Мбит/с : 8 = 528 Мбайт/с.
При этом предполагается, что передача машинного слова происходит за один период тактовой частоты шины. Эта скорость передачи данных называется пропускной способностью шины и является максимальной. Она всегда выше средней рабочей производительности шины примерно на 25%. Таким образом, для рассмотренного примера средняя рабочая производительность шины будет составлять около
400 Мбайт/с.
Шина памяти предназначена для передачи информации между ОП и МП, а также ОП и ПУ в режиме ПДП. Информация по шине памяти передается с существенно меньшей скоростью, чем по шине процессора. Это связано с тем, что шина памяти содержит меньше линий данных. Их число определяется шириной выборки. Кроме того, как уже отмечалось, быстродействие микросхем памяти всегда отстает от быстродействия процессора, поэтому процесс передачи информации по шинам памяти и процессора (т.е. по локальной системной шине) требует обязательной синхронизации, которая осуществляется контроллером шины. Уже в первых моделях IBM PC ОП выполнялась в виде отдельных модулей (SIMM), которые размещались в специальных слотах, расположенных на шине памяти, аналогично слотам на ШР. Этот принцип сохранен и в современных PC, хотя сами слоты и модули памяти (DIMM) несколько видоизменились.
ЛОКАЛЬНЫЕ ШИНЫ РАСШИРЕНИЯ
Рассмотренные выше разновидности ШР (ISA, MCA, EISA) имеют общий недостаток – сравнительно низкое быстродействие. Быстродействие и разрядность процессоров и микросхем памяти (а следовательно, и локальной системной шины) возрастали, а характеристики ШР улучшались "экстенсивно", в основном за счет увеличения их разрядности. Для ряда ПУ, быстродействие которых определяется "человеческим фактором", например, клавиатуры, «мыши», высокого быстродействия ШР и не требуется. Однако при наличии таких ПУ, как жесткие диски, видеосистемы и т.д., низкое быстродействие ШР оказывает самое непосредственное влияние на производительность системы в целом. Проблема быстродействия ШР встала наиболее остро с появлением графических пользовательских интерфейсов, таких как Windows, при работе с которыми возникает потребность в передаче и обработке очень больших массивов данных.
Достаточно очевидным решением этой проблемы является осуществление обмена между наиболее быстродействующими ПУ и ядром ЭВМ не через ШР, а через дополнительную быстродействующую магистраль, выходящую непосредственно на шину процессора. В этом случае ПУ получают доступ к самой быстродействующей шине компьютера наряду с внешним кэш. Такая конфигурация получила название локальной шины расширения или просто локальной шины
(local bus). Подключение локальной шины такого типа иллюстрируется упрощенной схемой на рис. 10.2.
Первая локальная шина появилась в 1992 году в результате совместных усилий фирм Dell Computer и Intel. Хотя система оказалась поначалу весьма дорогостоящей, она продемонстрировала преимущества подключения видеосистемы к той точке, где можно было воспользоваться высоким быстродействием шины процессора. Этот первый вариант локальной шины был официально назван локальной шиной ввода/вывода I486 (I486 local bus I/O). К концу 1992 года стоимость компьютеров с локальной шиной стала снижаться, и многие фирмы начали производить аналогичные системы.
Для организации в компьютере локальной шины необязательно устанавливать слоты расширения: адаптер устройства, использующего локальную шину, можно смонтировать непосредственно на системной плате.
В первых компьютерах с локальной шиной использовался именно такой вариант.

Локальная шина не заменяла собой прежние стандарты, а дополняла их. Основными шинами расширения в компьютере по-прежнему оставались ISA или EISA, но к ним добавлялся один или несколько слотов локальной шины. При этом сохранялась совместимость со старыми платами расширения, а быстродействующие адаптеры устанавливались в слоты локальной шины, реализуя при этом все свои возможности.
Компьютеры с локальной шиной стали особенно популярны среди пользователей Windows и OS/2, поскольку в слоты локальной шины можно было установить
32-разрядные платы так называемых видеоускорителей, которые значительно увеличивали быстродействие системы при работе с графическими изображениями. Производительность Windows и OS/2 существенно снижалась из-за ограничений, существующих даже в лучших платах VGA, подключаемых к шинам ISA или EISA. Обычные платы VGA могли выводить на экран до 600 000 точек в секунду, в то время как видеоадаптеры, соединенные с локальной шиной, по утверждениям изготовителей, за то же время выводили 50-60 млн. точек. В реальных условиях быстродействие, конечно, ниже, но разница все равно оказывалась существенной.
МЕТОД ГРАНИЧНЫХ РЕГИСТРОВ
Идея метода состоит в том, что вводят два граничных регистра, указывающих верхнюю и нижнюю границы области памяти, куда программа имеет право доступа. Схема функционирования такой системы защиты изображена на рис. 9.16.
При каждом обращении к памяти проверяется, находится ли используемый адрес в установленных границах. При выходе за границы обращение к памяти подавляется и формируется запрос прерывания, передающий управление операционной системе. Содержание граничных регистров устанавливается операционной системой перед тем, как для очередной целевой программы начнется активный цикл. Если для динамического распределения памяти используется базовый регистр, то он одновременно определяет и нижнюю границу. Верхняя граница подсчитывается операционной системой в соответствии с длиной программы в ОП.

РгН – регистр нижней границы;
РгВ – регистр верхней границы;
a – адрес нижней границы допустимой зоны обращений;
N – количество ячеек разрешенной зоны памяти.
Таким образом, рассмотренный метод позволяет предотвратить выход программы из отведенной ей зоны памяти, что оказывается удобным при решении небольших задач в режиме линейной адресации внутри сегмента, т.е. когда исполняемая программа целиком входит в сегмент ОП и располагается в последовательных адресах единой области памяти.
МЕТОД КЛЮЧЕЙ ЗАЩИТЫ
По сравнению с предыдущим данный метод является более гибким. Он позволяет организовывать доступ программы к областям памяти, расположенным не
подряд.
Память в логическом отношении делится на блоки (этот вопрос достаточно подробно рассматривался в п. 9.4). Каждому блоку памяти ставится в соответствие код, называемый ключом защиты памяти. При этом каждой программе, принимающей участие в мультипрограммной обработке, присваивается код ключа программы. Доступ программы к данному блоку памяти для чтения и записи разрешен, если ключи совпадают или один из них имеет код 0.
Метод ключей защиты не исключает использование метода контрольного разряда для защиты отдельных ячеек памяти и метода граничных регистров для защиты отдельных зон памяти. В современных ЭВМ эти методы часто используются совместно и тесно переплетаются.
Рассмотрим очень коротко методы защиты памяти, используемые в вычислительных системах, построенных на базе микропроцессора I80386. Блоками памяти, подлежащими защите в таких системах, являются сегменты и страницы. Система защиты построена на принципах, широко используемых в микропроцессорах, а именно:
- Проверка атрибутов доступа (ключей защиты) перед предоставлением возможности обращения к памяти.
- Кольцевая структура иерархических уровней привилегированности (приоритетов), организованная так, чтобы предотвратить искажение наиболее важных программ, находящихся в центре, ошибками, имеющими место на внешних уровнях, где вероятность их возникновения наиболее высока. Механизм на базе уровней привилегий обеспечивает достаточно надежную защиту. При этом уровень привилегии задачи равен уровню привилегии активного на текущий момент программного сегмента или активной страницы.
Дескриптор сегмента или страницы включает в себя битовое поле, определяющее один из четырех допустимых уровней привилегий для соответствующего сегмента (см. рис. 9.3). Нулевой уровень является наиболее
привилегированным, т.е.
с наиболее ограниченным доступом к сегменту или странице. Уровень привилегии 3 является самым низким и характеризует наиболее доступные сегмент или страницу. Программы могут иметь доступ к данным или программным сегментам только с таким же уровнем привилегий или с менее ограниченным доступом (т.е. с более высокими номерами уровня привилегий).
С помощью этих четырех уровней защиты и системы проверки атрибутов доступа в процессоре организуется многозадачный режим за счет обособления программ друг от друга и от операционной системы. Механизм защиты предотвращает аварийную ситуацию в какой-либо программе при возникновении сбоя в системе. Систему защиты памяти посредством задачно-пользовательских атрибутов и уровней приоритетов, используемую в процессоре I80386, можно изобразить схемой, приведенной на рис. 9.17.
Функционирование изображенной структуры можно проиллюстрировать следующим примером. Пусть данные хранятся на уровне P=2. Тогда доступ к ним возможен для программ, находящихся на уровнях P=2, 1 или 0. Для программ с P=3 они недоступны. Аналогично программа прикладного сервиса с P=2 может быть вызвана сегментами или процедурами, находящимися на уровнях P=2, 1 или 0, но не на уровне P=3.
Выше речь шла о непосредственном обращении к данным или программам. Однако команда CALL может вызывать сегменты программ с более высоким, чем текущая программа, уровнем привилегий, используя для этого специально установленные точки входа. Эти точки входа называются шлюзами (или вентилями) вызова.
Таким образом, менее привилегированная процедура может вызвать более привилегированную, обращаясь к ней через дескриптор шлюза вызова, определяющий доступную точку входа. Этот способ обращения использовался также в процессорах I80286 и I80486. Он позволяет программам пользователя обращаться за обслуживанием к ОС. При этом допускаются обращения только к определенным процедурам, которые санкционируются путем введения в систему соответствующего шлюза. Тем самым исключается возможность несанкционированного обращения менее привилегированных процедур к более привилегированным, что позволяет защитить их от возможных искажений.
Аппаратная внутрикристальная реализация механизма иерархической защиты памяти и проверка атрибутов доступа, предусматриваемая в составе операционной системы, позволяют предотвращать подавляющее большинство аварийных ситуаций (в соответствии с одной из оценок, приведенной в литературе, до 95% отказов, происходящих в многопользовательских многозадачных системах из-за некорректной работы с памятью).
МЕТОДЫ ОПТИМИЗАЦИИ ОБМЕНА ПРОЦЕССОР-ПАМЯТЬ
Вначале очень коротко рассмотрим причины, вынуждающие инженеров непрерывно совершенствовать аппаратную и идеологическую основы процессов обмена данными между процессором и памятью.
Как уже отмечалось, память современных ЭВМ имеет иерархическую, многоуровневую структуру. Чем выше уровень, тем выше быстродействие и тем меньше емкость. К верхнему уровню относятся ЗУ, с которыми процессор непосредственно взаимодействует в процессе выполнения программы. Это, прежде всего, основная или оперативная память (ОП), а также сверхоперативная внутренняя память процессора. Последняя имеет очень малую емкость и во внимание приниматься не будет, т.е. речь пойдет только об обмене процессор – ОП. К нижнему уровню памяти относятся внешние ЗУ, обладающие большой емкостью и малым быстродействием. Во всех современных ЭВМ вычислительный процесс строится так, чтобы число обращений к ВП было минимальным. В отличие от ВП современные ОП имеют достаточно высокое быстродействие (цикл обращения составляет десятки наносекунд и менее). Однако при организации взаимодействия процессор – ОП возникает много проблем, связанных с несоответствием пропускной способности процессора и
памяти.
Непрерывный рост производительности (скорости работы) ЭВМ, вызываемый потребностями их применения, проявляется, в первую очередь, в повышении скорости работы процессоров. Это достигается использованием более быстродействующих электронных схем, а также специальных архитектурных решений (конвейерная и векторная обработка данных и др.). Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора. Это происходит прежде всего потому, что одновременно идет опережающий рост ее емкости, что делает более трудным уменьшение времени цикла работы памяти.
Результаты, к которым приводит такой разрыв в быстродействии процессора и ОП, можно проиллюстрировать на простейшем примере. Рассмотрим типичный цикл обращения микропроцессора к ОП, состоящий из ряда тактов Т1
Т2 ... Т5, например МП КР580.
В такте Т1 МП выставляет на ША адрес ячейки памяти, к которой будет произведено обращение. В такте Т2 МП ожидает приход сигнала READY от модуля памяти. Количество тактов Т2 в общем случае не ограничено. Такт Т3
наступает только после поступления сигнала READY. Из этого примера становится понятным, почему увеличение тактовой частоты не всегда приводит к увеличению скорости выполнения программ, так как МП просто "топчется на месте" в ожидании ответа ОП.
Из всего сказанного следует, что существует, по крайней мере, два направления оптимизации процессов обмена процессора и ОП.
Первое направление – это совершенствование их аппаратной базы. Но, как оказалось, на этом направлении есть ряд серьезных препятствий как технологических, так и принципиальных. Одно из них связано со скоростью распространения электрического сигнала в проводнике. При низкой скорости обмена явление запаздывания сигнала не заметно. Однако оно становится заметным при повышении этих скоростей до величин, пропорциональных 109
обр./с. При дальнейшем увеличении частоты обращений становится невозможным гарантировать правильность работы ОП, так как время получения данных будет существенно зависеть от места их расположения в ОП.
Второе направление – это оптимизирующие алгоритмы взаимодействия процессора и ОП, которые, естественно, также требуют аппаратной поддержки. Ниже, очень коротко, рассматриваются наиболее распространенные методы этого направления, используемые при создании современных ЭВМ.
НЕКОТОРЫЕ ВОПРОСЫ РАЗВИТИЯ АРХИТЕКТУРЫ ЭВМ
В самом начале курса было оговорено, что предметом нашего изучения является цифровое устройство переработки информации, построенное в соответствии с классической пятиблочной структурой фон Неймана, или, иными словами, – ЭВМ. Таким образом, речь шла только об ЭВМ, в которой информация перерабатывается в одном процессорном устройстве (центральном процессоре) последовательно, без распараллеливания вычислительного процесса, которое имеет место в многопроцессорных и многомашинных вычислительных системах (о них речь пойдет в последних разделах настоящего курса). Отмечалось, что в процессе эволюции классическая структура ЭВМ претерпела некоторые изменения, в частности, изменилось устройство памяти, организация которого стала иерархической. Однако это далеко не все изменения, которые произошли с классической пятиблочной структурой ЭВМ и ее основными принципами функционирования, сформулированными фон Нейманом.
Ниже очень коротко рассматриваются некоторые элементы архитектуры современных ЭВМ четвертого поколения, которые выходят за рамки классических структур и принципов функционирования первых ЭВМ различных классов. Материал раздела, по возможности, иллюстрируется примерами построения упрощенных элементов вычислительных устройств на базе процессора I80386, структуры которых достаточно прозрачны.
ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ ВВ
В каждой ЭВМ применяются особые способы ВВ, различные конфигурации схем и типы устройств. Однако для большинства ЭВМ можно выделить следующие общие принципы:
Передача данных осуществляется по общей системной магистрали (что характерно для микроЭВМ) либо по специальной магистрали ВВ (что характерно для мини- и больших ЭВМ). Иногда отдельная быстродействующая магистраль ВВ выделяется только для обмена в режиме ПДП.
Подключение ПУ к системному интерфейсу осуществляется с помощью промежуточного интерфейса, поддерживаемого со стороны микроЭВМ и ПУ соответствующими адаптерами (см. п. 7.2).
Операции ВВ инициируются только в случае готовности ПУ к обмену. При наличии нескольких ПУ и обмене в режиме прерывания или ПДП вводится система приоритетов, позволяющая избежать конфликтов. В соответствии с этой системой контроллер прерываний или ПДП среди ПУ, готовых к обмену, в первую очередь обслуживает ПУ с высшим приоритетом (см. гл. 6 и гл. 11).
Передача данных осуществляется двумя способами:
- отдельными битами, и тогда промежуточный интерфейс называется последовательным;
- полными словами (например, целым байтом), и тогда промежуточный интерфейс называется параллельным.
Информация, передаваемая в процессе ВВ, подразделяется:
- на собственно данные (обозначим D);
- управляющие данные (обозначим U).
Управляющие данные от процессора называются также командными словами или приказами. Они инициируют действия, не связанные непосредственно с передачей данных (запуск устройства, запрещение прерываний, установка режимов и т.д.).
Управляющие данные от ПУ называются словами состояния. Они содержат информацию об определенных признаках (о готовности устройства к передаче данных, о наличии ошибок при обмене и т.д.). Состояние обычно представляется в декодированной форме – один бит для каждого признака.
С учетом всего изложенного можно изобразить наиболее общую программную модель адаптера промежуточного интерфейса (ППУ), связывающего системную магистраль микроЭВМ и внутреннюю магистраль ПУ.
Такая обобщенная программная модель ППУ представлена на рис. 8.1. Каждый из указанных регистров должен иметь адрес, который может идентифицироваться дешифратором адреса.
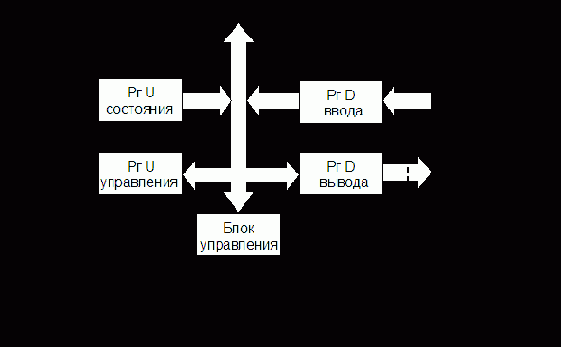
Естественно, что конкретная модель адаптера может отличаться от обобщенной схемы, например, регистр состояния и управления могут быть объединены в один регистр, вместо двух однонаправленных портов используют один двунаправленный, регистров управления может быть несколько. Однако при этом логические функции указанных четырех регистров остаются.
В соответствии с рассмотренными ранее различными структурами системной магистрали возможны два способа организации операций ВВ.
Изолированный ВВ
(соответствует структуре с изолированными шинами)
Изолированный ВВ предполагает наличие специальных команд ВВ. В МП КР580 это команды IN и OUT. Адресное пространство регистров ППУ изолировано от адресного пространства ячеек памяти, т.е. регистры ППУ и ячейки памяти могут иметь одинаковый адрес. Команды IN и OUT – двухбайтовые. Первый байт – КОП, а второй несет информацию о номере адресуемого ППУ и номере адресуемого в нем регистра. При этом в МП КР580 предусмотрена возможность обмена данными по командам IN, OUT только между аккумулятором и адресуемыми регистрами.
ВВ по общей шине
(соответствует структуре с общими шинами)
В этом случае адресация к регистрам ППУ осуществляется как к обычным ячейкам памяти, т.е. ячейки памяти и регистры ППУ имеют единое адресное пространство. Можно использовать все команды обращения к ячейкам памяти. Это удобно, однако часть адресного пространства памяти используется для адресации регистров ППУ, что может вызвать трудности, если программа большая и много ПУ.
ПУ и микроЭВМ могут обмениваться достаточно большими объемами информации, которые невозможно поместить только в регистрах процессора. Ввиду этого часто операции ВВ являются операциями обмена данными между ОП и ПУ. Как уже отмечалось, для повышения гибкости всей вычислительной системы в микроЭВМ предусмотрено три режима выполнения операций ВВ.Рассмотрим эти режимы подробнее.
ОРГАНИЗАЦИЯ ОБМЕНА В РЕЖИМЕ ПДП
Использование любого варианта ПДП порождает ряд проблем, связанных с использованием общей магистрали несколькими устройствами. Даже при использовании простейшего варианта ПДП (slave DMA), который и рассматривается ниже, возникает проблема совместного использования магистрали двумя устройствами – процессором и контроллером ПДП. Для получения максимальной скорости обмена желательно, чтобы ПУ через контроллер ПДП имело непосредственную связь с ОП ЭВМ, т.е. имело бы специальную магистраль, как это и делается в ряде случаев. Однако такое решение существенно усложняет и удорожает ЭВМ, особенно при подключении нескольких ПУ, поэтому в большинстве простейших микроЭВМ для реализации обмена в режиме ПДП (организации каналов ПДП) используются шины системной магистрали. Именно этот вариант и рассматривается ниже. Кроме того, предполагается, что кэш-память отсутствует и данные (как и команды) поступают в процессор непосредственно из ОП. Последнее означает, что в течение всего периода обмена, т.е. пока магистралью управляет контроллер ПДП (master), процессор вынужден простаивать, поскольку не имеет доступа к ОП.
Несмотря на то что такой способ организации обмена в режиме ПДП характерен только для самых простейших микроЭВМ, на его примере можно достаточно наглядно проиллюстрировать основные принципы прямого управления магистралью со стороны ведущего устройства. Изучение механизма функционирования средств bas mastering более сложных вычислительных систем всегда требует достаточно детального рассмотрения сигналов конкретной системной магистрали, используемого процессора, особенностей архитектуры ведущих устройств и т.д.
Проблема совместного использования шин системного интерфейса процессором и контроллером ПДП в общем случае имеет два основных способа решения – ПДП с захватом цикла и ПДП с блокировкой процессора.
ПДП с захватом цикла
Этот способ ПДП предназначен для обмена короткими блоками информации в виде байта или слова и имеет два варианта.
Вариант 1. Для обмена используются те интервалы времени машинного цикла процессора, в которые он не обменивается данными с памятью или регистрами ПУ.
В этом варианте контроллер ПДП никак не мешает работе процессора. Однако возникает необходимость выделения таких интервалов для исключения временного перекрытия обмена контроллера ПДП и процессора. В некоторых случаях процессоры формируют специальные сигналы, указывающие такты, в которых процессор не ведет операций обмена. В других случаях применяют специальные схемы, внешние по отношению к процессору, которые идентифицируют такие "свободные" интервалы времени.
Применение подобного варианта организации ПДП не снижает производительность процессора, но передача данных происходит только в случайные моменты времени. Это понижает общую скорость обмена. Кроме того, для некоторых ПУ, такой режим обмена вообще неприемлем.
Вариант 2. На время, необходимое для обмена одним байтом или словом данных (что составляет несколько тактов), процессор принудительно отключается от шин системной магистрали. Такой способ организации ПДП с захватом цикла является наиболее распространенным.
Когда ПУ готово к обмену, оно формирует сигнал ЗПД, который поступает в контроллер ПДП. Он, в свою очередь, вырабатывает аналогичный управляющий сигнал (ОЗПД), который поступает в процессор. Сигнал ОЗПД формируется контроллером при появлении сигнала (сигналов) ЗПД на любой линии (линиях) ЛЗПД и заставляет процессор на несколько тактов отключиться от системной магистрали. Получив этот сигнал, процессор заканчивает операции обмена на магистрали. Затем, не дожидаясь завершения текущей команды (или машинного цикла), выдает в контроллер ПДП сигнал РПД и отключается от шин системной магистрали. При этом внутренние операции в процессоре по завершению текущей команды (или машинного цикла) продолжаются и могут быть совмещены по времени с операциями ПДП.
С этого момента времени всеми шинами системной магистрали управляет контроллер ПДП. Используя системную магистраль, он осуществляет обмен между ПУ и ОП одним байтом или словом, а затем, сняв сигнал ОЗПД, возвращает управление системной магистралью процессору.
Как только ПУ вновь будет готово к обмену, оно формирует сигнал ЗПД, контроллер ПДП захватывает магистраль, и цикл обмена повторяется. В промежутках между сигналами ЗПД процессор продолжает выполнять команды текущей программы.
Таким образом, в отличие от режима прерывания, который вводится только после завершения текущей команды, режим ПДП вводится, не дожидаясь ее завершения. Это связано с тем, что в режиме ПДП внутренние регистры процессора не используются, их содержимое не модифицируется, а следовательно, и не требует запоминания в стеке.
Естественно, что применение такого способа организации ПДП замедляет выполнение программы, но в меньшей степени, чем при обмене в режиме прерывания. Кроме того, в отличие от варианта 1 обмен происходит в те моменты времени, в которые это требует ПУ, что особенно важно при работе микроЭВМ в режиме реального времени.
Следует отметить, что такой вариант ПДП используется только тогда, когда интервалы времени между моментами готовности ПУ к обмену достаточно велики и позволяют выполнить процессору несколько операций.
ПДП с блокировкой процессора
Этот режим отличается от ПДП с "захватом цикла" тем, что управление системным интерфейсом передается контроллеру ПДП не на время обмена одним байтом или словом, а на все время обмена блоком данных. В этом случае все вопросы, связанные с синхронизацией работы ПУ и ОП, также решаются контроллером ПДП
(в режиме "захвата цикла" их фактически решал процессор). Такой режим ПДП особенно необходим в тех случаях, когда процессор не успевает выполнить хотя бы одну команду между очередными операциями обмена в режиме ПДП.
Режим ПДП с блокировкой процессора в современных ЭВМ является основным, поскольку современные ПУ, такие как жесткие и оптические диски, видеосистемы, принтеры, сканеры и т.д., всегда ведут обмен блоками информации существенного объема. Однако для их передачи контроллер ПДП должен удерживать магистраль достаточно продолжительное время, в течение которого процессор будет простаивать.Это существенно понизит производительность рассматриваемой простейшей микроЭВМ в целом.
Между тем, как уже отмечалось, процессоры большинства современных ЭВМ работают с ОП через кэш-память. При наличии кэш-памяти достаточного объема (особенно многоуровневой) процессор может продолжать некоторое время обработку команд текущей программы – до тех пор, пока необходимая информация присутствует в кэш и не требует обновления. Это время достаточно ограничено, поэтому арбитр должен следить за тем, чтобы время удержания магистрали контроллером ПДП не превышало некоторой, наперед заданной величины и простои процессора были сведены к минимуму.
Следует отметить, что реальные контроллеры ПДП, как правило, могут работать в различных режимах организации ПДП, зачастую комбинированных, поэтому рассмотренная выше классификация способов организации ПДП является весьма условной (особенно ПДП с блокировкой процессора и вариант 2 ПДП с захватом цикла).
ПДП С БЛОКИРОВКОЙ ПРОЦЕССОРА
Этот режим отличается от ПДП с "захватом цикла" тем, что управление системным интерфейсом передается контроллеру ПДП не на время обмена одним байтом, а на время обмена блоком данных. В этом случае все вопросы, связанные с синхронизацией работы ПУ и ОП, также решаются контроллером ПДП (в режиме "захвата цикла" их фактически решал процессор). Такой режим ПДП особенно необходим в тех случаях, когда процессор не успевает выполнить хотя бы одну команду между очередными операциями обмена в режиме ПДП. В этом случае контроллер ПДП обязательно должен иметь средства для модификации адресов обмена и контроля объема переданного блока информации. Этот режим ПДП в современных ЭВМ является основным, поскольку современные ПУ, такие как жесткие и оптические диски, видеосистемы, принтеры, сканеры и т.д., всегда ведут обмен блоками информации существенного объема.
Следует отметить, что реальные контроллеры ПДП, как правило, могут работать в различных режимах организации ПДП, зачастую комбинированных, поэтому рассмотренные выше варианты организации ПДП являются весьма условными (особенно ПДП с блокировкой процессора и вариант 2 ПДП с захватом цикла).
Конкретные технические реализации каналов ПДП весьма разнообразны и определяются особенностями организации ЭВМ, используемого в ней процессора, обслуживаемого набора ПУ и т.д. Между тем можно сформулировать основные принципы работы большинства каналов ПДП и построить обобщенный алгоритм их функционирования. В частности, применение в ЭВМ обмена в режиме ПДП требует предварительной подготовки со стороны процессора:
Для каждого ПУ необходимо выделить область памяти, используемой при обмене, и указать ее размер, т.е. количество записываемых в память или читаемых из памяти байтов (слов) информации. Следовательно, контроллер ПДП должен обязательно иметь в своем составе регистры адреса и счетчик байтов (слов).
Перед началом обмена с ПУ в режиме ПДП процессор должен выполнять программу загрузки (инициализации). Эта программа обеспечивает запись в указанные регистры контроллера ПДП начального адреса выделенной области памяти (для данного ПУ) и ее размера в байтах или в словах в зависимости от того, какими единицами информации ведется обмен.
Вышеизложенное не относится к начальной загрузке программ в память микроЭВМ в режиме ПДП. В этом случае содержимое регистров адреса и счетчика байтов устанавливается перемычками или переключателями, т.е. принудительно заносится каким-либо способом.
Упрощенный алгоритм обмена блоком информации в режиме ПДП при наличии нескольких ПУ представлен на рис. 8.3, причем в скобках указано устройство, выполняющее операцию.
Структура представленного алгоритма достаточно проста и не требует дополнительных пояснений. Все операции, выполняемые устройствами в процессе передачи блока данных, рассматривались выше. Если в контроллер ПДП одновременно поступило два или более запросов, то после обслуживания наиболее приоритетного ПУ произойдет обслуживание остальных ПУ в порядке уменьшения приоритетов. Для этого контроллер ПДП опять выставит процессору сигнал HLD, и цикл обмена повторится для другого ПУ.

Следует отметить, что контроль за окончанием цикла обмена (объемом переданного блока информации) может осуществляться не только по количеству переданных байт или слов, но и по конечному адресу зоны памяти, отведенной для обмена с данным ПУ. Кроме того, в реальных системах время удержания магистрали контроллером ПДП при обслуживании одного ПУ всегда ограничено и контролируется, поэтому завершение цикла обмена может произойти также по сигналу специального таймера. Более подробно этот вопрос рассматривается в гл. 11.
Как уже отмечалось, в МП комплект КР580 входит специализированная БИС программируемого контроллера ПДП КР580ВТ57. Этот контроллер может управлять работой четырех независимых каналов ПДП с учетом приоритетов ПУ. Для процессора контроллер представляется несколькими 8-битными регистрами с соответствующими номерами. После инициализации контроллер может управлять передачей блока данных до 16 Кбайт по каждому каналу без вмешательства процессора.
ПДП С ЗАХВАТОМ ЦИКЛА
Этот способ ПДП предназначен для обмена короткими блоками информации в виде байта или слова и имеет два варианта:
Вариант 1
В этом случае для обмена используются те интервалы времени машинного цикла процессора, в которых он не обменивается данными с памятью и ПУ. Таким образом, контроллер ПДП никак не мешает работе процессора. В МП КР580 такими интервалами являются такты T4 и Т5 машинного цикла (сразу следует отметить, что контроллер КР580ВТ57 не работает в таком режиме). Однако возникает необходимость выделения таких интервалов для исключения временного перекрытия обмена ПДП и процессора. В некоторых МП формируются специальные сигналы, указывающие такты, в которых процессор не ведет операций обмена. В других случаях применяют специальные схемы, идентифицирующие "свободные" интервалы времени.
Применение такого способа организации ПДП не снижает производительность МП, но передача данных происходит только в случайные моменты времени. Это понижает общую скорость обмена. Кроме того, для некоторых ПУ такой режим обмена вообще неприемлем.
Вариант 2
В этом случае на время, необходимое для обмена одним байтом или словом данных (что составляет несколько тактов), процессор принудительно отключается от шин системной магистрали. Такой способ организации ПДП с захватом цикла является наиболее распространенным.
Когда ПУ готово к обмену, оно формирует сигнал "требование ПДП", который поступает в контроллер ПДП. Он, в свою очередь, вырабатывает аналогичный управляющий сигнал, который заставляет процессор на несколько тактов отключиться от системной магистрали. В МП КР580 это сигнал HLD (HOLD). Получив этот сигнал, процессор приостанавливает выполнение очередной команды, не дождавшись ее завершения, выдает сигнал "подтверждение ПДП" (в МП КР580 это сигнал HLDA) и отключается от шин системной магистрали. МП КР580 освобождает системную магистраль после такта Т3
текущего машинного цикла, причем внутренние операции в процессоре (такты Т4
и Т5) продолжаются и могут быть совмещены по времени с операциями ПДП.
Таким образом, в отличие от режима прерывания, который вводится только после завершения текущей команды, режим ПДП вводится до ее завершения. Это связано с тем, что в режиме ПДП внутренние регистры процессора не используются, их содержимое не модифицируется, а следовательно, и не требуется запоминания в стеке.
С этого момента времени (такт Т4) всеми шинами системной магистрали управляет контроллер ПДП. Используя системную магистраль, он осуществляет обмен между ПУ и микроЭВМ одним байтом или словом, а затем, сняв сигнал HLD, возвращает управление системной магистралью процессору. Как только ПУ будет готово к обмену, оно вновь захватывает магистраль и т.д. В промежутках между сигналами HLD процессор продолжает выполнять команды текущей программы.
Естественно, что применение такого способа организации ПДП замедляет выполнение программы, но в меньшей степени, чем при обмене в режиме прерывания, хотя бы потому, что не требуется операций со стеком. Кроме того, в отличие от варианта 1 обмен происходит в те моменты времени, в которые это требует ПУ, что особенно важно при работе микроЭВМ в режиме реального времени.
Следует отметить, что такой вариант ПДП используется только тогда, когда интервалы времени между моментами готовности ПУ к обмену достаточно велики и позволяют выполнить процессору несколько операций.
ПРИНЦИПЫ ОРГАНИЗАЦИИ АРБИТРАЖА МАГИСТРАЛИ
Нормальное функционирование системы ПДП любой структуры очень во многом зависит от правильного выбора дисциплины обслуживания устройств магистрали, т.е. от правильного выбора системы приоритетных соотношений. Особенно остро эта проблема стоит в вычислительных системах, использующих bus mastering, поскольку общая производительность системы существенно зависит от равномерности загрузки всех ведущих устройств магистрали. Последнее можно обеспечить только рациональным выбором дисциплины арбитража (в дальнейшем просто арбитража). Существуют многочисленные варианты арбитража, каждый из которых имеет свои преимущества и недостатки, причем ни один из них не может быть назван идеальным для любых вычислительных систем. Оптимальный вариант арбитража всегда зависит от конкретной конфигурации вычислительной системы и ее целевого назначения, типа используемых процессоров, конфигурации и назначения ведущих устройств магистрали, способов взаимодействия с системой прерывания и многих других факторов. Способ арбитража определяет и название арбитра, используемого в конкретной вычислительной системе.
Наиболее популярными вариантами арбитров в настоящее время являются: одноуровневый, с фиксированными приоритетами, с циклическим изменением приоритетов, круговой. Рассмотрим их более подробно.
Одноуровневый арбитр
Это простейший вариант арбитра, который используется в простых системах bus master DMA цепочечной структуры, изображенной на рис. 11.3. В соответствии со своим названием он обслуживает только один уровень запроса и предоставляет магистраль, используя одну линию ЛРПД, т.е. в системе используется только одна ШАр. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали, поэтому термин "одноуровневый арбитр" не совсем уместен, так как реальным арбитражем он не занимается. Каждое ИЗПД само принимает решение принимать или пропускать сигнал РПД. Такие системы bus master DMA, как уже отмечалось, являются наиболее динамичными, даже при достаточно большом количестве ИЗПД, и могут быть построены с минимальной аппаратной поддержкой.
Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, расположенные в слотах с малыми номерами, т.е. близкие к слоту "0".
Арбитр с фиксированными приоритетами
Это также достаточно простой вариант арбитра, который предполагает, что за каждым входом ШАр (система bus master DMA) или ЛЗПД (система slave DMA) закреплен определенный уровень приоритета, который не может быть изменен в процессе обслуживания устройств магистрали. В большинстве случаев количество входов в арбитр или контроллер ПДП не превышает 4-8. Для увеличения количества входов, особенно в контроллерах систем slave DMA, обычно допускается их каскадное включение. Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, использующие вход арбитра с максимальным приоритетом.
Арбитр с циклическим изменением приоритета
Этот вариант арбитра является развитием варианта арбитра с фиксированными приоритетами. Алгоритм функционирования такого арбитра состоит в следующем. Пусть арбитр имеет четыре входа, к которым подключены четыре ШАр – ШАр0, ШАр1, ШАр2, ШАр3. После инициализации входам арбитра присваиваются фиксированные приоритеты (например, ШАр0 – высший, а ШАр3 – низший). Однако после обслуживания устройств одной из ШАр ей автоматически назначают низший приоритет, а приоритеты остальных ШАр изменяются в круговой последовательности. Например, после обслуживания ШАр2 приоритеты остальных ШАр убывают в таком порядке: ШАр3, ШАр0, ШАр1, ШАр2. Такой режим позволяет выровнять приоритеты всех ШАр и не допустить преимущественное использование магистрали устройствами одной ШАр. Возможны и другие схемы выравнивания приоритетов.
Основной недостаток такого арбитра состоит в том, что невозможно жестко зафиксировать наивысший приоритет какой-либо ШАр или устройства.
Круговой арбитр
Этот вариант арбитра предоставляет равный приоритет всем ШАр, подключенным к его входам. Пусть, как и в предыдущем случае, к арбитру подключены четыре ШАр.
Тогда арбитр предоставляет магистраль в распоряжение устройств каждой ШАр на основе круговой диспетчеризации подобно круговому переключателю на четыре позиции. После запуска вычислительной системы "переключатель" может установиться либо на фиксированную, либо на случайную позицию (вход ШАр). Все зависит от конкретной технической реализации арбитра. Пусть это будет вход ШАр0. Когда одно из ведущих устройств ШАр0 осуществит обмен и освободит магистраль, "переключатель" повернется на следующую позицию и предоставит возможность захвата магистрали ведущим устройствам ШАр1. Если на входе ШАр1 его не ожидает запрос, арбитр пропустит этот вход и переключится на следующий, т.е. на вход ШАр2. Таким образом, ведущие устройства всех ШАр обеспечиваются равными правами на захват магистрали.
Основной недостаток такого арбитра аналогичен предыдущему.
Рассмотренные выше варианты, как уже отмечалось, не исчерпывают всего многообразия арбитров, используемых в реальных вычислительных системах. Кроме того, следует помнить, что многие арбитры являются сложными перепрограммируемыми устройствами и могут, после соответствующей инициализации, поддерживать не только различные варианты арбитража, но и использовать комбинированные варианты, наиболее оптимальные для конкретной вычислительной системы.
ПРИНЦИПЫ ОРГАНИЗАЦИИ СИСТЕМ ПРЯМОГО ДОСТУПА К ПАМЯТИ
Материал, изложенный в предыдущих разделах, предполагал, что передача данных между ОП и ПУ, как правило, осуществляется с помощью процессора. Это так называемая программно-управляемая передача данных (программно-управляемый ввод/вывод), которая осуществляется при непосредственном участии и под управлением процессора. В англоязычной литературе – Programmed Input/Output (PIO). Процессор при этом выполняет соответствующую процедуру ввода/вывода (ВВ), являющуюся либо частью основной программы, либо оформленную как подпрограмма. Данные между ОП и ПУ пересылаются через процессор. Операции ВВ инициируются текущей командой программы или запросом прерывания от ПУ. Это соответствует принципам функционирования классической неймановской машины, описание которой приведено в гл.1. Более подробно процедура программно-управляемой передачи данных (программно-управляемого ВВ) рассмотрена в гл. 9.
Между тем такой вариант обмена между ОП и ПУ во многих случаях является далеко не самым оптимальным, а иногда вообще невозможным. Причин тому несколько. Рассмотрим очень коротко основные из них.
При программно-управляемом ВВ процессор "отвлекается" от выполнения основной программы решения задачи. Операции ВВ достаточно просты, чтобы эффективно загружать логически сложную быстродействующую аппаратуру процессора. В результате при использовании программно-управляемого ВВ снижается производительность ЭВМ в целом.
При пересылке любой единицы данных (байт, слово) процессор выполняет достаточно много команд, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных единиц данных, формирование адресов памяти и регистров ПУ. В результате скорость передачи данных при программно-управляемом ВВ (т.е. через процессор) может оказаться недостаточной для работы с высокоскоростными ПУ, например с накопителями на жестких дисках, видеосистемами, быстродействующими аналого-цифровыми и цифро-аналоговыми преобразователями различного назначения, и т.д.
Большинство современных сложных ПУ, таких как видеосистемы, сетевые карты, жесткие диски и т.д., осуществляют обмен с ОП целыми блоками информации.
В этом случае перечисленные выше непроизводительные временные затраты процессора становятся особенно существенными.
Обмен в режиме прерывания, несмотря на все свои достоинства (см. гл. 6), требует еще помимо перечисленных выше непроизводительных временных затрат время на сохранение вектора состояния текущей программы в стеке и его последующего восстановления. Кроме того, прерывание в большинстве случаев возможно только после завершения текущей команды.
Несмотря на широкое использование программно-управляемого ВВ, для ускорения операций обмена данными между ОП и ПУ и разгрузки процессора от управления этими операциями в современных ЭВМ используется специальный режим обмена, получивший название режим прямого доступа к памяти или просто прямой доступ к памяти (ПДП). В англоязычной литературе – Direct Memory Access (DMA). Ниже, в зависимости от контекста излагаемого материала, будут употребляться обе аббревиатуры – ПДП и DMA.
Прямым доступом к памяти называется режим, при котором обмен данными между ОП и регистрами ПУ осуществляется без участия центрального процессора за счет специальных, внешних по отношению к нему, электронных схем. Простейший вариант такого обмена рассмотрен в гл. 9.
Введение режима ПДП (реализация каналов ПДП) всегда усложняет аппаратную часть ЭВМ, однако позволяет повысить скорость выполнения операций обмена ОП-ПУ, разгружает центральный процессор от обслуживания операций ВВ, повышает общую производительность ЭВМ. При наличии кэш-памяти достаточного объема режим ПДП в ряде случаев позволяет реализовать параллельное выполнение операций обмена и обработку команд текущей программы процессором, что также повышает общую производительность ЭВМ. Более того, наличие механизма прямого доступа к памяти позволяет поддерживать многопроцессорность вычислительной системы. На последнем моменте необходимо остановиться более подробно.
Дело в том, что термин ПДП (как и DMA), используемый при изложении материала настоящего раздела, в общем случае не совсем точно отражает суть процессов, происходящих в ЭВМ.
Точнее, прямой доступ к памяти ( к ОП) является только частным случаем организации процедур доступа к системной магистрали со стороны множества устройств, в том числе и процессоров. Под доступом к системной магистрали понимается возможность какого-либо устройства, имеющего соответствующее аппаратно-программное обеспечение (ведущее устройство, интеллектуальное устройство магистрали), занимать на какое-то время системную магистраль и полностью управлять ею, вырабатывая все необходимые управляющие сигналы. При этом могут осуществляться связи не только ОП-ПУ, но и ПУ-ПУ. Между тем смысл понятия "память" можно расширить и понимать под памятью не только ОП, но и адресуемые регистры ПУ. В этом случае использование термина ПДП (как и DMA) будет вполне корректно.
Следует иметь в виду, что термин "периферийное устройство (ПУ)" здесь используется достаточно условно. В англоязычной литературе ведущее устройство магистрали, инициирующее обмен, принято называть master. Устройство, к которому обращается master, является подчиненным, и его принято называть slave. Таким образом, более правильно говорить о реализации связей master-slave (M-S), а не ПУ-ПУ или ОП-ПУ. Мастером может быть только интеллектуальное устройство, имеющее средства управления магистралью (СУМ), которые, как минимум, должны "уметь" формировать и модифицировать адреса обращения, вести контроль за размером переданного блока информации и генерировать управляющие сигналы магистрали. Между тем в зависимости от текущего состояния вычислительного процесса одно и то же интеллектуальное устройство магистрали может выступать и как master, и как slave. Устройства магистрали, не имеющие СУМ, всегда являются подчиненными, т.е. slave.
Естественно, что предоставление магистрали в распоряжение того или иного устройства (захват магистрали) может происходить только на приоритетной основе. Эта процедура получила название арбитраж магистрали, а устройство, ее реализующее, – арбитр магистрали. В ряде случаев арбитр может строиться как отдельное устройство, размещенное на системной магистрали.В других случаях арбитраж магистрали выполняет сам процессор. Наличие процедуры арбитража позволяет размещать на системной магистрали несколько интеллектуальных устройств, в том числе и процессоров. В соответствии с принятой дисциплиной обслуживания (арбитража) каждое из них будет получать в свое распоряжение системную магистраль и устанавливать связи как с ОП, так и с регистрами других устройств магистрали. Следует отметить при этом, что в процедуре арбитража всегда предусматриваются средства, предотвращающие монопольный захват магистрали одним устройством. Часть этих средств может быть сосредоточена в арбитре, другая часть может быть распределена между устройствами магистрали, использующими режим ПДП.
ПРИНЦИПЫ ОРГАНИЗАЦИИ ВВОДА / ВЫВОДА ИНФОРМАЦИИ В МИКРОЭВМ
Вводом/выводом (ВВ) называют передачу данных между ядром ЭВМ, включающим в себя процессор и ОП, и периферийными устройствами (ПУ).
Система ВВ – это единственное средство общения ЭВМ с внешним миром. Ее возможности в серийных ЭВМ представляют собой один из важнейших параметров, определяющих выбор машины для конкретного применения.
Несмотря на разнообразие ПУ, в настоящее время разработано несколько стандартных способов их подключения к ЭВМ и программирования ВВ. Существует три режима ВВ:
Программный ВВ (нефорсированный).
ВВ по прерыванию (форсированный).
Прямой доступ к памяти (ПДП).
Реализация ВВ в каждом из этих режимов отличается программно-аппаратными затратами и, самое важное, скоростью выполнения операций обмена и непроизводительными затратами времени процессора. Суть каждого из трех режимов состоит в следующем.
Программный ВВ. Инициирование и управление ВВ осуществляет процессор по командам прикладной программы. ПУ играют пассивную роль и только сигнализируют о своем состоянии, в частности о готовности к операциям ВВ.
ВВ по прерыванию. Операции ВВ инициирует ПУ, генерируя сигнал запроса прерывания, при этом процессор переключается на подпрограмму обслуживания данного ПУ, вызвавшего прерывание. В результате выполнения подпрограммы (обработчика) осуществляется обмен данными. Действия, выполняемые обработчиком, определяются пользователем, а непосредственно операциями ВВ управляет процессор.
Таким образом, как при программном ВВ, так и при ВВ по прерываниям операциями обмена управляет процессор, поэтому очень часто эти два варианта обмена не разделяют и рассматривают их как программный ВВ. В англоязычной литературе – Programmed Input/Output (PIO). Однако в настоящем курсе эти варианты обмена рассматриваются отдельно.
Прямой доступ к памяти. Процессор в передаче данных не участвует. Он отключается от системной магистрали, а все операции обмена данными идут под управлением специального управляющего устройства – контроллера ПДП. Этот режим используется для быстродействующих ПУ, когда пропускной способности процессора недостаточно.
Следует отметить, что общие принципы организации систем прерывания уже рассмотрены в гл. 6. Организация систем ПДП подробно рассмотрена в гл. 11. Ниже рассматривается простейший случай организации радиальных систем прерывания и ПДП для микроЭВМ на базе МП КР580, поэтому материал настоящего раздела частично перекрывается с материалом, изложенным в гл. 6 и в гл. 11.
ПРОГРАММНЫЙ ВВ
В этом режиме все действия, связанные с операциями ВВ, реализуются командами прикладной программы, причем возможны два вида обмена – синхронный и асинхронный, которые целесообразно использовать в различных ситуациях.
Синхронный ВВ
Такой ВВ можно использовать для связи с ПУ, которые "всегда готовы", например светодиодные индикаторы, либо для ПУ, в которых известно точно время выполнения операций, например, максимальное время, необходимое для печати одного знака.
В первом случае команды ВВ ставятся в произвольных точках программы. Во втором случае программа должна быть составлена так, чтобы команды на обмен шли с интервалами не меньшими, чем время выполнения одной операции обмена (т.е. максимальное время выполнения операции в ПУ).
Это наиболее простой вид обмена, требующий минимум программно-аппаратных затрат (он называется еще безусловным ВВ). Однако при работе с медленными ПУ, как правило, не удается оптимальным образом загрузить процессор на период времени между пересылками данных.
Асинхронный ВВ
В этом случае интервал между операциями обмена задается самим ПУ. Информацию о готовности ПУ к операциям обмена процессор получает периодически, анализируя содержимое регистра состояния ППУ, поэтому процесс обмена состоит из двух фаз:
- проверки готовности ПУ к обмену;
- реализации непосредственно операций ВВ.
Первая фаза обмена в большинстве случаев реализуется путем циклического вызова содержимого регистра состояния ППУ в аккумулятор, сравнения его с некоторой маской и анализа полученного результата, т.е. происходит реализация цикла ожидания готовности ПУ. На реализацию цикла ожидания затрачивается время, иногда весьма значительное. Это является существенным недостатком такого вида обмена, поскольку в период ожидания процессор не может выполнять полезной работы, т.е. фактически простаивает.
РАДИАЛЬНАЯ СТРУКТУРА (BUS MASTER DMA)
В соответствии с рис. 11.1, б все запросы от ИЗПД поступают в арбитр магистрали (контроллер ПДП отсутствует) и в общем случае фиксируются там каким-либо образом, например аналогично тому, как это делается в контроллере прерываний (см. гл. 6). Следует помнить, что в системе bus master DMA "ЦП" рассматривается как одно из ведущих устройств магистрали со своим приоритетом, т.е. как одно из ИЗПД. Последовательность операций по предоставлению магистрали в распоряжение одного из ведущих устройств (master) для передачи блока информации в общем случае следующая:
1. В начале функционирования вычислительной системы происходит инициализация арбитра и, если это необходимо, СУМ ведущих устройств магистрали. Эта процедура описана выше и здесь не конкретизируется.
2. Полагаем, что вычислительная система функционирует. Процессоры ведущих устройств выполняют команды соответствующих программ и периодически захватывают магистраль для реализации обмена M-S.
3. При возникновении готовности какого-либо из ведущих устройств магистрали его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по любой ЛЗПД) в арбитре магистрали происходит анализ сигналов линий ЛПЗ. Наличие сигнала на любой линии означает, что в текущий момент магистраль занята другим устройством, ведущим обмен. Одновременно выполняется процедура установления приоритета поступившего запроса (или запросов, если их поступило несколько). Пусть наиболее приоритетным оказался запрос от ИЗПДi.
5. Дальнейшие операции зависят от результата анализа линий ЛПЗ (сигналов ПЗ), а именно:
При отсутствии сигналов ПЗ на линиях ЛПЗ (т.е. свободной магистрали) арбитр выставляет сигнал РПДi
на линию ЛРПДi наиболее приоритетного устройства ИЗПДi.
При наличии сигнала ПЗ на какой-либо из линий ЛПЗ (т.е. занятой магистрали) арбитр сравнивает приоритет устройства, занимающего магистраль, с приоритетом выделенного запроса (т.е. приоритетом ШАрi).
- Если приоритет поступившего запроса ниже, то арбитр ожидает окончание текущего обмена и снятия сигнала ПЗ. После этого арбитр выставляет сигнал РПДi на линию ЛРПДi наиболее приоритетного устройства ИЗПДi.
- Если приоритет поступившего запроса выше, то арбитр снимает сигнал РПД с линии ЛРПД устройства, ведущего обмен, т.е. запрещает ему bus mastering. Устройство прекращает операции обмена, освобождает магистраль и снимает сигнал ПЗ. Только после этого арбитр выставляет сигнал РПДi
на линию ЛРПДi наиболее приоритетного устройства ИЗПДi.
6. Поступление сигнала РПД разрешает устройству bus mastering, т.е. захват магистрали. С этого момента шинами системной магистрали управляет блок СУМ выбранного устройства ИЗПДi (master), который выставляет также сигнал ПЗi. Кроме того, в арбитре или самом ИЗПДi
запускается внутренний таймер, контролирующий время удержания магистрали.
7. Блок СУМ устройства ИЗПДi (master) выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен M-S одним байтом или словом.
8. Блок СУМ активного устройства производит модификацию адреса и счетчика байтов.
9. Блок СУМ активного устройства контролирует размер переданного блока данных. Размер блока контролируется обычно по количеству переданных байтов (слов).
10. Контролируется время удержания магистрали устройством, ведущим обмен. Этот контроль может осуществляться как арбитром, так и самим устройством ИЗПДi по встроенному таймеру.
11. Дальнейшие действия зависят от результатов операций в п. 9 и 10, а
именно:
Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с п. 7.
Если блок информации передан полностью (обмен закончен), то master освобождает системную магистраль и снимает сигнал ПЗi.
Если время удержания магистрали истекло (хотя обмен и не закончен), то master освобождает магистраль либо сам, либо после снятия арбитром сигнала РПДi.
12. Начинается процедура захвата магистрали ведущим устройством с меньшим приоритетом (организация канала M-S), если запрос в арбитр уже поступил (см. операции, начиная с пункта 4).
Следует отметить, что в общем случае возможны системы bus master DMA радиальной структуры, в которых арбитр выступает как подчиненное устройство по отношению к ЦП. В этом случае перед предоставлением магистрали в распоряжение какого-либо ИЗПД арбитр запрашивает ЦП, монопольно использующий магистраль, т.е. как в случае slave DMA. Однако этот вариант DMA в настоящем разделе не рассматривается.
РАДИАЛЬНАЯ СТРУКТУРА (SLAVE DMA)
В соответствии с рис. 11.1, а все запросы от ИЗПД поступают в арбитр магистрали контроллера ПДП и в общем случае фиксируются там каким-либо образом, например аналогично тому, как это делается в контроллере прерываний (см. гл. 6). Последовательность операций по предоставлению магистрали в распоряжение контроллера ПДП при передаче блока данных в общем случае следующая:
1. Перед началом обмена происходит инициализация контроллера ПДП со стороны процессора. Эта процедура описана выше и здесь не конкрети-
зируется.
2. Процессор продолжает выполнять команды текущей программы до поступления запроса от какого-либо ИЗПД.
3. При возникновении готовности какого-либо из инициализированных ПУ его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр контроллера ПДП.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по любой ЛЗПД) арбитр контроллера ПДП формирует сигнал ОЗПД, который транслируется в процессор. При этом в контроллере инициализируется процедура поиска запроса с максимальным приоритетом, если одновременно поступило несколько запросов. Эта процедура выполняется обычно аппаратным способом, например с помощью дейзи-цепочек (см. п. 6.3.1) или логических схем.
5. Процессор заканчивает операции обмена на магистрали, посылает в контроллер сигнал РПД и отключается от шин системной магистрали. С этого момента шинами системной магистрали управляет контроллер ПДП (master). Кроме того, в контроллере запускается внутренний таймер, контролирующий время удержания магистрали.
6. Блок СУМ контроллера ПДП выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен между ОП и наиболее приоритетным ПУ одним байтом или словом.
7. Блок СУМ контроллера ПДП производит модификацию адреса обмена и счетчика байт.
8. Блок СУМ контролирует размер переданного блока данных. Контроль может происходить как по количеству переданных байтов (слов), так и по конечному адресу области обмена.
9. Блок СУМ контролирует время удержания магистрали контроллером ПДП по внутреннему таймеру.
10. Дальнейшие действия зависят от результатов операций в гл. 8 и 9, а именно:
Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с гл. 6.
Если блок информации передан полностью (обмен закончен), то контроллер ПДП снимает сигнал ОЗПД и освобождает системную магистраль.
Если время удержания магистрали истекло (хотя обмен и не закончен), то контроллер ПДП освобождает магистраль и снимает сигнал ОЗПД.
11. Процессор продолжает выполнение текущей программы, либо, если запрос уже поступил, начинается процесс обслуживания канала ПДП с меньшим приоритетом (см. операции, начиная с п. 4).
Возможна ситуация, при которой в процессе обслуживания одного из устройств магистрали в арбитр контроллера ПДП поступит запрос от устройства с большим приоритетом. В этом случае контроллер ПДП, не снимая сигнал ОЗПД, прекращает обслуживание устройства с меньшим приоритетом и переключается на обслуживание более приоритетного устройства.
РАССЛОЕНИЕ ПАМЯТИ
Известны два основных метода расслоения памяти. Суть этих методов состоит в том, что память строится на основе нескольких модулей. Но в одном случае модули памяти имеют раздельные адресные пространства (независимая адресация), а в другом – модули охвачены общим полем адресов и образуют единое адресное пространство. Оба метода предложены достаточно давно, но широко используются и в современных ЭВМ, причем в ряде случаев совместно. Рассмотрим их очень
коротко.
Метод 1
Метод разделения памяти на два модуля с независимой адресацией был предложен и опробован еще в конце 50-х гг. лабораториями Гарвардского университета. Один модуль памяти использовался для хранения команд программы, другой – данных. Оба модуля имели собственные контроллеры памяти и раздельные магистрали доступа. Такой принцип построения ОП оказался во многих случаях очень эффективным и был успешно использован при разработке компьютеров различного назначения. Возник даже термин "Гарвардская архитектура".
Этот принцип сохранен и в современных вариантах ЭВМ (процессорах) Гарвардской архитектуры. Он позволяет совместить во времени циклы обмена с обоими модулями памяти и оказывается эффективным при обработке любых типов программ. В настоящее время Гарвардская архитектура широко используется при построении кэш-памятей (см. п. 9.3.3) мощных процессоров.
Метод 2
В простейшем случае используют два модуля с "веерной" (чередующейся) адресацией, при которой смежные адреса информационных единиц, соответствующих ширине выборки (слово, двойное слово и т.д.), принадлежат разным модулям (т.е. четные адреса принадлежат одному модулю, а нечетные – другому). Это позволяет процессору инициировать второй цикл обмена до завершения первого, поскольку адреса лежат в разных модулях, либо обращаться одновременно двум устройствам к разным модулям памяти. В результате за счет перекрытия во времени обращений к разным модулям пропускная способность ОП в среднем повышается.
Следует отметить, что веерная адресация, как и конвейер команд, оказывается эффективной только при наличии в программе достаточно длинных участков с последовательным выбором команд, т.е.
когда вероятность появления команд передачи управления мала. Выигрыш в быстродействии оказывается максимальным, когда необходимо осуществить множество последовательных обращений к ОП в ходе пакетных пересылок в режиме ПДП. В этом режиме в качестве параметров пересылки блока данных указывается начальный адрес и количество слов, подлежащих пересылке.
Двунаправленное расслоение ОП не может предотвратить появления циклов ожидания поэтому были разработаны системы с 4- и более кратным расслоением ОП, в которых контроллер памяти обеспечивает распределение последовательно вырабатываемых адресов между несколькими модулями памяти.
Проблема повышения пропускной способности характерна для всех уровней иерархии внутренней памяти ЭВМ. Наиболее остро эта проблема стоит перед разработчиками динамических ОП, которые благодаря максимальной информационной емкости и низкой стоимости занимают ведущее место в составе внутренней памяти компьютера. В последнее время предложен ряд вариантов ОП повышенного быстродействия. Это FPM, MDRAM, EDORAM, SDRAM, BEDORAM, RDRAM и многие другие типы памятей.
Методы повышения быстродействия таких памятей основаны на предположении о "кучности" адресов обращения к ОП, т.е. на предположении о том, что адреса последующих обращений к ОП, вероятнее всего, расположены рядом с адресом текущего обращения. Внутренние механизмы реализации этих методов схожи с механизмами конвейеризации процесса выполнения команд в процессоре, расслоения памяти, кэширования (см. п. 9.3.3) только на уровне отдельных БИСов и модулей памяти.
РАЗЪЕМЫ ДЛЯ ПОДКЛЮЧЕНИЯ ДИСКОВЫХ УСТРОЙСТВ
FDD (Floppy Disk Drivers – накопитель на гибких магнитных дисках) конструктивно представляет собой 12х2-контактный игольчатый разъем с возможностью подключения двух дисководов. Устройство, подключенное к перевитому шлейфу, является диском A:, к прямому – B:. Реализовано одновременное обращение только к одному устройству.
HDD (Hard Disk Drivers – накопитель на жестких магнитных дисках) – конструктивно может быть выполнен в нескольких вариантах. Обычно это IDE или SCSI.
IDE (Integrated Drive Electronics) – более дешевый и в настоящее время самый распространенный интерфейс. Конструктивно представляет собой 2х20-контактный игольчатый разъем. Стандартно контроллер IDE имеет один такой разъем, к которому можно подключить до двух дисковых устройств. Стандартно на материнской плате собраны 2 IDE контроллера Primary и Secondary. Существуют также несколько протоколов обмена данными: UDMA/33 – 33 Мбайт/с и UDMA/66 – 66 Мбайт/с. Протокол UDMA/66 обладает вдвое большей скоростью передачи данных за счет того, что данные передаются по обоим фронтам тактирующего сигнала в отличие от UDMA/33. Для реализации интерфейса необходим шлейф, в котором бы отсутствовали помехи от двух параллельно идущих проводников. Для решения этой проблемы применяется 80-жильный шлейф, каждый второй проводник которого соединен с общим проводом для уменьшения помех.
SCSI (Small Computer System Interface) – более дорогой и в настоящее время менее распространенный интерфейс. Один контроллер может обслуживать от 1 до 32 устройств в зависимости от конструкции. Контроллер SCSI внешне представляет собой либо плату расширения, либо устройство, встроенное в материнскую плату. В последнем случае мы можем видеть лишь 25х2-контактный игольчатый разъем. Скорость обмена по каналу SCSI до 20 Мбайт/с.
UWSCSI (Ultra Wide SCSI) является модификацией интерфейса SCSI. Внешне также представляет собой плату расширения или устройство, встроенное в материнскую плату, и тогда мы можем видеть 34х2-контактный трапецеидальный разъем плюс для поддержки SCSI 25x2-контактный игольчатый разъем. Скорость обмена по каналу UWSCSI до 80 Мбайт/с.
РАЗЪЕМЫ ДЛЯ ПОДКЛЮЧЕНИЯ ВНЕШНИХ УСТРОЙСТВ

USB (Universal Serial Bus – универсальная последовательная магистраль) – один из современных интерфейсов для подключения внешних устройств. Предусматривает подключение до 127 внешних устройств к одному USB-каналу. Принципы построения USB аналогичны принципам построения общей шины. Аппаратные реализации обычно имеют по два канала на контроллер. Обмен по интерфейсу – пакетный, скорость обмена до 12 Мбит/с.
LPT (Line Printer) – первоначально был предназначен для подключения к нему принтера, но в дальнейшем появился ряд устройств, способных работать через LPT- порт (сканеры, Zip-приводы и т.д.). LPT-порт конструктивно представляет собой параллельный 8-разрядный порт плюс 4 разряда состояния.
Режимы работы параллельного LPT порта
SPP (Standard Parallel Port – стандартный параллельный порт) осуществляет 8-разрядный вывод данных с синхронизацией по опросу или по прерываниям. Максимальная скорость вывода – около 80 Кбайт/с. Может использоваться для ввода информации по линиям состояния. Максимальная скорость ввода – примерно вдвое меньше.
EPP (Enhanced Parallel Port – расширенный параллельный порт) – скоростной двунаправленный вариант интерфейса. Изменено назначение некоторых сигналов. Введена возможность адресации нескольких логических устройств и 8-разрядного ввода данных. Используется 16-байтовый аппаратный FIFO-буфер. Максимальная скорость обмена – до 2 Мбайт/с.
ECP (Enhanced Capability Port – порт с расширенными возможностями) – интеллектуальный вариант EPP. Реализованы возможность разделения передаваемой информации на команды и данные, а также поддержка DMA и сжатия передаваемых данных методом RLE (Run-Length Encoding – кодирование повторяющихся серий).
COM порт – последовательный порт. Скорость обмена до 115 Кбит/с. Возможно подключение лишь одного устройства к порту. В основном используется для подключения манипулятора типа «мышь» или модема. Стандартно в материнскую плату встроено два последовательных порта.
PS/2 порт – последовательный порт. Является функциональным аналогом COM- порта, но имеет дополнительно линии для питания подключаемых устройств. Служит для подключения клавиатуры или манипулятора типа «мышь».
РАЗЪЕМЫ ПРОЦЕССОРОВ
Собственно говоря, процессор как раз то устройство, которое производит все вычисления и управляет всеми контроллерами. Так как же определить, какой процессор вы сможете поставить в ту материнскую плату, которую выбрали? На данный момент существует достаточно много типов разъемов для установки процессора. Это Socket 7, Socket 370, Socket FC-PGA, Slot I, Slot A. Среди такого количества несложно и запутаться, но не волнуйтесь, сейчас все подробно разберем.
Тип разъемов Socket-ZIF (Zero Input Force – вставляй, не прикладывая сил) конструктивно представляет пластиковый разъем с зажимающей защелкой, расположенной сбоку корпуса разъема, предназначенной для предотвращения самопроизвольного выпадения процессора. При установке процессора защелка должна быть максимально поднята вверх.
Разъем Socket 7 – стандартный ZIF (Zero Input Force) – разъемом с 296 контактами, использующийся всеми процессорами класса Р5 – Intel Pentium, AMD K5 и K6, Cyrix 6x86 и 6x86MX и Centaur Technology IDT-C6.
Разъем Socket 8 – нестандартный ZIF– имеет 387 контактов и несовместим с Socket 7, предназначен для установки в него процессора класса Р6 – Pentium Pro. Поскольку ядро процессора и кэш были объединены на одном кристалле, то и форма его получилась прямоугольной, а не квадратной, как у Socket 7.
Разъем Socket 370 – нестандартный ZIF– несовместим ни с Socket 7, ни с
Socket 8, предназначен для установки в него более дешевого прототипа P6 Celeron, за исключением последней модели Celeron II, построенной по технологии Coppermine.
Разъем Socket FC-PGA (Flip Chip Pin Grid Array) внешне напоминает Socket 370. В отличие от 370 на FC-PGA заводится два питания 1,5В и 1,6В, и предназначен он для установки в него процессоров, произведенных по технологии Coppermine.
Тип разъема Slot конструктивно представляет пластиковый разъем с двумя рядами контактов, в него вставляются процессоры с ножевым разъемом. Фирма INTEL пошла на это в связи с тем, что для удешевления стоимости процессора кэш был вынесен с кристалла и стал располагаться на плате процессора, которая имеет ножевой двухсторонний разъем.
Тип разъема Slot I предназначен для установки в него процессора
P6 Pentium II, Pentium III и процессора P6 Celeron Slot I.
Тип разъема Slot 2 отличается от Slot I по коммерческим причинам, так как в него ставятся более дорогие модели процессоров Xeon, стоимость которых во много раз превышает стоимость процессоров Pentium II и Pentium III.
Тип разъема Slot A практически тот же самый Slot I, только перевернутый наоборот. Предназначен для установки процессора Athlon от AMD.
РАЗНОВИДНОСТИ СЛОТОВ
Слотом называются разъемы расширения, расположенные на материнской плате (на картинке слева). Они бывают следующих типов: ISA, EISA, VLB, PCI, AGP.
ISA (Industry Standard Architecture – архитектура промышленного стандарта) – основная шина на компьютерах типа PC AT (другое название – AT-Bus). Разрядность шины – 16/24 бита, тактовая частота – 8 МГц. Предельная пропускная способность составляет 5.55 Мбайт/с. Разделение IRQ невозможно (т.е. на каждый слот заведены все каналы IRQ). Конструктив – 62-контактный разъем XT-Bus с прилегающим к нему 36-контактным разъемом расширения.
EISA (Enhanced ISA – расширенная ISA) – функциональное и конструктивное расширение ISA. Внешне разъемы имеют такой же вид, как и ISA, и в них могут вставляться платы ISA, но в глубине разъема находятся дополнительные ряды контактов EISA. Платы EISA имеют более высокую ножевую часть разъема с двумя рядами контактов, расположенных в шахматном порядке: одни чуть выше, другие чуть ниже. Разрядность – 32/32 бита, работает также на частоте 8 МГц. Предельная пропускная способность – 32 Мбайт/с. Предусмотрена возможность разделения каналов IRQ и DMA.
VLB (VESA Local Bus – локальная шина стандарта VESA) – 32-разрядное дополнение к шине ISA. Конструктивно представляет собой дополнительный разъем (116-контактный) при разъеме ISA. Разрядность – 32/32 бита. Тактовая частота составляет 25..50 МГц. Электрически выполнена в виде расширения локальной шины процессора – большинство входных и выходных сигналов процессора передаются непосредственно VLB-платам без промежуточной буферизации.
PCI (Peripheral Component Interconnect – соединение внешних компонент) – PCI является дальнейшим шагом в развитии локальных шин. Разрядность – 32/32 бита (расширенный вариант – 64/64). Тактовая частота – до 33 МГц (PCI 2.1 – до 66 МГц). Пропускная способность – до 132 Мбайт/с (264 Мбайт/с для 32/32 на 66 МГц и
528 Мбайт/с для 64/64 на 66 МГц). Сегментов может быть несколько. Они соединяются друг с другом посредством мостов (bridge).
Сегменты могут объединяться в различные топологии (дерево, звезда и т.п.). Это самая популярная шина, которая в настоящее время используется также на других компьютерах. Разъем похож на MCA/VLB, но чуть длиннее (124 контакта). Разъем на 64 разряда имеет дополнительную 64-контактную секцию с собственным ключом. Все разъемы и карты к ним делятся на поддерживающие уровни сигналов 5 В, 3.3 В и универсальные. Первые два типа должны соответствовать друг другу, универсальные карты ставятся в любой разъем. Существует также расширение Media Bus шины PCI, введенное фирмой ASUSTek для подключения звуковых карт, – дополнительный разъем, находящийся за PCI слотом и содержащий сигналы шины ISA.

AGP(Accelerated Graphic Port – ускоренный графический порт) является дальнейшим развитием PCI, нацеленным на ускоренный обмен с графическими акселераторами. Отличие от PCI состоит в физическом расположении слота на материнской плате и его конструкции. Поскольку AGP – слот конструировался для установки видеокарт, которые не нуждаются в двухстороннем скоростном обмене, в нем предусмотрена скоростная передача данных только в память видеокарт. Обратная связь достаточно медленная. Пропускная способность на видеокарту составляет
528 Мбайт/с, а с видеокарты на системную шину до 132 Мбайт/с. Существует также новый стандарт AGP Pro. Кратко, суть его отличий от привычного AGP заключается в том, что к обычному разъему AGP по краям добавлены выводы для подключения дополнительных цепей питания 12 В и 3.3 В. Эти цепи призваны обеспечить повышенное энергопотребление видеокарты.
СЕГМЕНТНО-СТРАНИЧНАЯ ОРГАНИЗАЦИЯ ПАМЯТИ
До сих пор предполагалось, что виртуальная память, которой располагает программист, представляет собой непрерывный массив с единой нумерацией байтов. Такое логическое адресное пространство называют еще плоским
или линейным. Между тем программа обычно состоит из нескольких массивов-подпрограмм, одной или нескольких секций данных. При программировании длина таких массивов (программных модулей) получается произвольной (различной), поэтому удобно, чтобы каждый массив имел свою собственную нумерацию байтов, начинающуюся с нуля. Желательно также, чтобы составленная таким образом программа могла работать при динамическом распределении памяти, не требуя от программиста усилий по объединению различных ее частей в единый массив. В современных вычислительных системах эта задача решается путем использования особого метода преобразования виртуальных адресов в физические, называемого сегментно-страничной
организацией памяти.
Виртуальная память каждой программы делится на части, называемые сегментами, с независимой адресацией байтов внутри каждой части. При этом к виртуальному адресу добавляются дополнительные разряды левее номера страницы. Эти разряды определят номер сегмента.
Возникает определенная иерархия в организации программ, состоящая из четырех ступеней: программа-сегмент-страница-байт. Этой иерархии программ соответствует иерархия таблиц, служащих для перевода виртуальных адресов в физические. Программная таблица для каждой программы, загруженной в систему, указывает начальный адрес соответствующей сегментной таблицы. Сегментная таблица перечисляет сегменты данной программы с указанием начального адреса страничной таблицы, относящейся к данному сегменту. Страничная таблица определяет расположение каждой из страниц сегмента в памяти. Страницы сегмента могут располагаться не подряд – часть страниц данного сегмента может находиться в ОП, остальные во внешней памяти.
Следует отметить, что страничная организация памяти, сегментация памяти и разнообразные их комбинации и сочетания возникли в ранних универсальных вычислительных машинах, таких как IBM 360/370.
Это будет способствовать достаточно простой реализации механизмов, обеспечивающих защиту отдельных модулей, разделение информации между сегментами, а также совместную или раздельную их обработку.
Виртуальную память можно поделить также на страницы. В отличие от сегментов, для которых допускаются переменные размеры и размещение в ОП, наиболее приемлемые для программных модулей страницы имеют фиксированный размер
4 Кбайт и жесткую привязку к адресам памяти. Страничная организация памяти придает алгоритмам перекачки данных в процедурах размещения, запоминания и поиска более рациональную форму благодаря равномерности распределения блоков памяти в адресном пространстве. В любой программе можно объединить основные принципы каждого из рассмотренных способов управления памятью, если, допустим, логическое адресное пространство разделить на сегменты, а для управления физической памятью применить методы страничной организации. Размер страницы
4 Кбайт хорошо подходит для функционирования операционных систем и для подсистем ВВ дисков, а также обеспечивает хороший коэффициент удачных обращений для внутрикристального кэш страниц. Следует отметить, что с появлением процессоров Pentium возникла возможность поддержки страниц размером 4 Мбайт. Однако при дальнейшем изложении материала размер страницы подразумевается 4 Кбайт.
Следует, однако, иметь в виду, что виртуальной памяти
как физического объекта не существует (в отличие от кэш-памяти), хотя она и имеет определенную аппаратную поддержку. Виртуальная память является "порождением" операционной системы, поэтому и законы ее функционирования зависят от конкретного типа операционной системы.
Кроме того, фирмы-изготовители в процессе совершенствования аппаратной части стремятся сохранить преемственность поколений процессоров. Это позволяет использовать в новых моделях программное обеспечение, уже написанное для вычислительных систем, построенных на базе более ранних моделей процессоров, но делает алгоритмы обращения к памяти более консервативными.
Такая преемственность достигается в основном двумя путями:
- Созданием новых моделей процессоров, расширенные системы команд которых "накрывают" системы команд прежних моделей. Так, все процессоры фирмы Intel семейства I80х86, в том числе 32-разрядные (I80386, I80486, Pentium, Pentium Pro), включают в себя как подмножество системы команд и архитектуры нижестоящих моделей, начиная с базовой модели I8088;
- Созданием новых операционных систем, поддерживающих возможность эмуляции прежних структур логического адресного пространства памяти. Так, все версии операционной системы MS-DOS, включая последние (например,
MS DOS 6.22), поддерживали реальный режим, эмулирующий фактически адресное пространство PC/XT.
Для иллюстрации изложенного очень коротко рассмотрим процесс эволюции первых поколений IBM PC.
Как уже отмечалось, первые МП фирмы Intel появились в конце 60-х годов. Затем появились процессоры I8086 и I8088, положившие начало целому семейству МП. Они имели 20-разрядную ША и совершенно идентичную внутреннюю структуру, т.е. имели 16-разрядное АЛУ, но I8086 подключался к 16-разрядной ШД, а I8088 – к
8-разрядной. В 1981 году фирма IBM выпустила свою первую модель IBM PC, построенную на базе процессора I8088. Она имела ОП емкостью 256 Кбайт и два floppy-диска (f-диска) по 160 Кбайт. IBM PC работал под управлением первой версии операционной системы MS DOS-1.00, созданной с расчетом более широких возможностей процессора, в частности прямоадресуемой памяти объемом 1 Мбайт. Под прямоадресуемой памятью понимается то адресное пространство, которое доступно процессору при данной разрядности ША.
Уже в 1981 году фирма IBM начала выпуск более совершенной модели компьютера IBM PC/XT, построенной на базе процессора I8086. Эта модель выпускалась до 1984 года. Она имела ОП емкостью 640 Кбайт, винчестер емкостью 10 Мбайт и два
f-диска по 360 Кбайт. Для модели XT была написана вторая версия операционной системы MS DOS-2.00, полностью поддерживающая указанную конфигурацию устройств PC.
Эта версия операционной системы явилась "родоначальницей" всех последующих версий MS DOS, под управлением которых работали все последующие модели PC фирмы IBM.
Именно с появлением на рынке модели IBM PC/XT началось массовое внедрение PC в хозяйственную и научную деятельность человека. В результате было наработано огромное количество прикладных программ, возможность использования которых необходимо было предусмотреть в более поздних моделях PC фирмы IBM.
Упрощенная структура прямоадресуемой памяти компьютера IBM PC/XT, работающего под управлением MS DOS-2.00, изображена на рис. 9.14.
Из структуры следует, что для пользователя была доступна только область прямоадресуемой памяти объемом 640 Кбайт (ОП), из которой непосредственно под прикладные программы отводился участок между адресами 70 Кбайт и 640 Кбайт, т.е. не более 570 Кбайт памяти. Верхняя зона прямоадресуемой памяти между адресами 640 Кбайт и 1024 Кбайт объемом 384 Кбайт отводилась под системные нужды и к ОП не относилась.

Однако очень скоро, особенно с появлением электронных таблиц, такой объем ОП перестал удовлетворять пользователей. Частичное решение проблемы расширения объема ОП было найдено посредством использования плат EMS-памяти,
или expanded memory. Первоначально это было физическое устройство в виде отдельной платы с БИС памяти (обычно общим объемом от 2 до 30 Мбайт), устанавливаемой в слот расширения шины ISA. Но процессор не мог обращаться с ней напрямую – не позволяла разрядность ША и существующая операционная система, поэтому для общения процессора с EMS-памятью были использованы свободные от системных программ участки прямоадресуемой памяти в зоне адресов
640К-1024 Кбайт, называемые окнами. При этом процессор не мог общаться с участками EMS-памяти, размер которых превышал размер окна, что было существенным ограничением. Между тем использование EMS-памяти решало многие проблемы, связанные с недостаточным объемом ОП (всего 640 Кбайт).
Так, например, в одной из конфигураций вычислительных систем роль прохода ко всей EMS-памяти играло окно размером 64 Кбайт.
Данное окно, называемое также страничным кадром EMS, делилось на страницы
размером 16 Кбайт. Страницы такого окна (страничного кадра) могли располагаться в несвязных свободных областях системной памяти (объемом не менее 16 Кбайт) между адресами 640 Кбайт и 1024 Кбайт. Таким образом, окно размером 64 Кбайт содержало в себе 4 страницы. Условно отображение адресного пространства на страницы EMS-памяти можно изобразить схемой, приведенной на рис. 9.15 (для упрощения рисунка все страницы окна расположены подряд в одной общей свободной зоне системной памяти).
Совершенствование технологии производства СБИС привело к тому, что необходимость в специальной плате EMS-памяти со временем исчезла, поскольку разработанные БИС памяти имели объемы, существенно превышающие объемы плат EMS-памяти, используемые в IBM PC/XT. При этом понятие EMS-памяти сохранилось в последующих моделях компьютеров.
Процессор I80386 имеет 32-разрядную ША и может напрямую обращаться к ОП емкостью 4 Гбайт. Однако вследствие отмеченной уже необходимости использования наработанного ранее программного обеспечения на компьютерах более поздних моделей операционные системы, в частности MS DOS-6.22, предоставляют процессору для прямой адресации только участок ОП размером 1 Мбайт с адреса 0 Кбайт до 1024 Кбайт. Логическая структура такого участка рассматривалась выше. Таким образом, MS DOS-6.22 фактически эмулировала
адресное пространство компьютера IBM PC/XT и предоставляла в распоряжение пользователя ОП объемом
только 640 Кбайт. Вся остальная часть физического ОП компьютера (выше адреса
1024 Кбайт) считалась extended memory, на которой средствами MS DOS можно эмулировать EMS (expanded memory) необходимого объема. Общение процессора с EMS-памятью возможно только через окна, расположенные в поле адресов от
640 Кбайт до 1024 Кбайт. Такой подход позволял решать задачи, которые написаны для более ранних моделей компьютеров и "привыкли" использовать EMS-память. Режим процессора в этом случае называется реальным и означает, что в память компьютера, работающего под управлением, например, MS DOS-6.22, невозможно ввести программу, размер которой превышает 640 Кбайт, и она требует сегментации.

Между тем столь жесткие ограничения на объем ОП в базовых версиях
MS DOS совершенно не устраивали многих пользователей, тем более, что в других операционных системах (Unix, OS/2, Windows) их не было. Поэтому для MS DOS разрабатывались дополнительные пакеты программ, расширяющие ее возможности, например DOS для графических библиотек (DOS 4GL).
ШИНА РАСШИРЕНИЯ
Как уже отмечалось, ШР позволяет МП и ОП взаимодействовать с различными ПУ. За время, прошедшее после появления первых IBM PC, было разработано достаточно много вариантов ШР, поскольку появление новых быстродействующих поколений процессоров и ПУ (особенно видеосистем) требовало и более производительных ШР. Между тем одной из главных причин, сдерживающих интенсивное внедрение новых ШР, явилась их несовместимость со старыми стандартами, по которым множество фирм уже выпустили сотни тысяч единиц электронных компонентов PC и которые становились совершенно ненужными в случае использования новых ШР. В связи с этим эволюция ШР происходит достаточно медленно, без резких скачков. Ниже рассматриваются основные моменты в процессе эволюции архитектуры ШР IBM PC.
ШИНА РАСШИРЕНИЯ EISA
Стандарт EISA (Extended Industry Standard Architecture) появился в 1988 году в ответ на разработку фирмой IBM шины МСА и требование ее лицензировать (см.
п. 10.2.2). Конкуренты сочли излишним платить задним числом за давно используемую шину ISA и, проигнорировав новую разработку IBM, создали свою. В этой работе приняли участие практически все ведущие изготовители компьютеров (за исключением, естественно, IBM) и крупнейшие фирмы по производству программных продуктов. Первые компьютеры с шиной EISA появились в 1989 г. Это единственное жестко стандартизированное расширение ISA до 32 бит и количеством слотов расширения до восьми.
Шина EISA разрабатывалась как преемница ISA, а не как альтернатива ей, поэтому различия между ними связаны лишь с появлением дополнительных возможностей. В шине EISA предусмотрены 32-разрядные слоты для компьютеров с процессорами 386DX и последующими моделями. Слот шины EISA построен так, что позволяет разрабатывать устройства, обладающие многими возможностями адаптеров МСА, но при этом может работать и с платами, созданными в старом стан-
дарте ISA.
Несмотря на существенное увеличение числа линий в шине EISA (55 новых сигналов), 32-разрядный слот EISA выглядит почти так же, как и 16-разрядный слот ISA. Между тем слот шины EISA сдвоенный. Два ряда контактов соответствуют
16-разрядному слоту ISA, остальные расположены в глубине разъема и относятся к расширению EISA, поэтому контакты кромкового разъема старых плат ISA, не имеющих специального ключа, попадают только на верхние контакты слота.
По шине EISA можно передавать до 32 бит данных одновременно при тактовой частоте шины 8,33 МГц. В большинстве случаев передача данных осуществляется, как минимум, за два такта, хотя возможна и большая скорость передачи. Максимальную производительность шины реализует пакетный режим (burst mode) – скоростной режим пересылки пакетов данных без указания текущего адреса внутри пакета. В пакете очередные данные могут передаваться в каждом такте шины, т.е.
максимальная пропускная способность шины EISA составляет
8,33 МГц ´ 32 бита = 266,56 Мбит/с ® 266,56 Мбит/с : 8 = 33,32 Мбайт/с.
Длина пакета может достигать 1024 байта. Передача данных по "неполной шине" (при работе с 8- или 16-разрядными платами адаптеров в стандарте ISA) осуществляется соответственно с меньшими скоростями.
В шине EISA (как и в МСА) предусмотрена возможность передачи управления шиной одной из плат адаптеров (bus mastering) для реализации режима ПДП или обмена между двумя адаптерами. Работу адаптеров координирует устройство, называемое арбитром шины (CACP), которое иногда еще называют периферийным контроллером (ISP – Integrated System Peripheral). Арбитр временно предоставляет всю систему в полное распоряжение той или иной плате адаптера в соответствии с четырехуровневой системой приоритетов, расположенных в следующем порядке (по убыванию):
- регенерация систем памяти;
- прямой доступ к памяти (DMA);
- процессор;
- адаптер шины (bus-master).
В компьютерах с шиной EISA предусмотрена самонастройка прерываний и адресов расположения адаптеров. В компьютерах с шиной ISA и несколькими платами адаптеров при неправильной установке перемычек и переключателей недоразумения практически неизбежны. Программа самонастройки EISA обнаруживает возможные конфликты и конфигурирует систему так, чтобы их исключить. Однако пользователь может и сам установить желаемую конфигурацию с помощью перемычек и переключателей, что бывает необходимо, например, при поиске неисправностей.
EISA – дорогая, но оправдывающая себя архитектура, применяющаяся в многопроцессорных системах, на файл-серверах и везде, где требуется высокоэффективная, надежная ШР.
ШИНА РАСШИРЕНИЯ ISA
Шина ISA (Industrial Standard Architecture) была использована в первых IBM PC, построенных на процессоре I8088, в 1981 г. Она имела 8 линий данных, 20 линий адреса, позволяла адресовать до 1 Мбайта памяти и тактовую частоту 8 МГц. Для передачи данных требовалось от двух до восьми тактов. Эта же ШР была использована и в следующей модели – PC/XT, построенной на процессоре I8086.
Шина ISA считается достаточно простой, но фирма IBM никогда не публиковала ее полной спецификации, поэтому при создании плат адаптеров для первых IBM-совместимых компьютеров разработчикам приходилось самим разбираться в ее работе.
Появление в 1984 году процессора второго поколения I80286, оперирующего уже 16-разрядными данными, поставило проблему замены или модернизации ШР ISA. Фирма IBM пошла по второму пути, и появился компьютер PC/AT со сдвоенными слотами расширения на модернизированной шине ISA. Вторая версия шины ISA имела 16 линий данных, 24 линии адреса, позволяющих адресовать до 16 Мбайт памяти, и тактовую частоту 8 МГц. Для передачи данных также (как и в первой версии) требовалось от двух до восьми тактов. Первая и вторая версии шины ISA были полностью совместимы, а сдвоенные слоты позволяли использовать старые
8-разрядные платы адаптеров, которые можно было вставлять в переднюю часть слота. Новые же (16-разрядные) платы адаптеров вставлялись в обе части сдвоенного слота. Пропускная способность новой версии шины ISA составляла
8 МГц ´ 16 бит : 2 такта = 64 Мбит/с ® 64 Мбит/с : 8 = 8 Мбайт/с.
Соответственно, пропускная способность первой версии шины ISA вдвое меньше, т.е. 4 Мбайт/с. Как уже отмечалось, это теоретическая, максимальная скорость передачи данных. Однако достаточно сложный протокол обмена существенно снижает реальную пропускную способность шины. Считается, что реальная пропускная способность ШР составляет примерно половину от максимальной.
Впоследствии с появлением 32-разрядных процессоров некоторые фирмы начали разрабатывать свои собственные версии расширения шины ISA, но сколько-нибудь заметного распространения они не получили. Дополнительные линии этих шин обычно использовались только при работе с платами расширения памяти и видеоадаптерами. Их параметры и разводки разъемов существенно отличаются от стандартных.
ШИНА РАСШИРЕНИЯ МСА
Появление 32-разрядного процессора I80386 привело к тому, что 16-разрядная ISA перестала соответствовать возможностям нового поколения МП. Фирма IBM не стала вновь модернизировать шину ISA, а разработала новую – МСА (Micro Channel Architecture). Шина МСА полностью несовместима с шиной ISA и не позволяет использовать старые платы адаптеров, однако по всем параметрам превосходит
16-разрядную шину ISA. Это достаточно дорогая шина, разработанная в пику конкурентам для своих компьютеров PS/2, начиная с модели 50. Состав управляющих сигналов, протокол и архитектура ориентированы на асинхронное функционирование шины и процессора, что снимает проблемы согласования скоростей процессора и ПУ. В процессе работы шина МСА может передавать управление отдельным подключенным к ней адаптерам (bus mastering), для реализации режима ПДП или обмена между двумя адаптерами. Все запросы на захват шины поступают в специализированное устройство, называемое арбитром шины (CACP – Central Arbitration Control Point). Арбитр обеспечивает доступ к шине всем устройствам в соответствии с системой приоритетов, предотвращая конфликты и монополизацию шины одним из них. Более подробно понятия “bus mastering”, “арбитр шины”, а также режим ПДП (DMA) обсуждаются в гл. 11. Архитектура шины позволяет эффективно и автоматически конфигурировать все устройства программным путем (в МСА PS/2 нет переключателей ни на системной плате, ни на адаптерах). В шине МСА предусмотрено 6 типов слотов:
- 16-разрядные;
- 32-разрядные;
- 16- и 32-разрядные с дополнением для плат памяти;
- 16- и 32-разрядные с дополнениями для видеоадаптеров.
Фирма IBM хотела не просто заменить старый стандарт ISA на новый, но и сделать на этом деньги. IBM потребовала от всех производителей, желающих получить лицензию на использование новой шины МСА, заплатить за использование шины ISA во всех ранее выпущенных компьютерах. Это непомерное требование привело к разработке конкурентами фирмы IBM альтернативной шины EISA (см. п. 10.2.3), что существенно замедлило распространение шины МСА.
Эта причина, а также полная несовместимость с массовыми ISA-устройствами привели к тому, что новая шина МСА при всей прогрессивности архитектуры (относительно ISA) не пользуется популярностью из-за узости круга пользователей МСА-устройств. Между тем МСА еще находит применения в мощных файл-серверах, где требуется обеспечить высоконадежный производительный ВВ.
СОПРОЦЕССОРЫ
Расширение диапазона возможного применения процессоров с традиционной фон-неймановской архитектурой привело к тому, что наборы команд МП стали весьма громоздкими. Дальнейшее расширение наборов команд наталкивается на проблемы, связанные с поиском компромисса между добавлением команд, которые способствовали бы повышению производительности для конкретных областей применения, и усложнением кристалла ИС. Распространенный метод введения относительно более специализированных команд, применение которого не приводит к повышению сложности и стоимости базового МП, заключается в использовании сопроцессоров. Сопроцессоры
– это дополнительные процессорные устройства, обеспечивающие выполнение дополнительных команд, в которых нуждается тот или иной пользователь.
Наиболее распространенной разновидностью дополнительного процессорного устройства (ДПУ) является сопроцессор для обработки чисел с плавающей запятой. Это достаточно сложное устройство. Его сложность сопоставима со сложностью самого процессорного устройства. Однако использование таких ДПУ позволяет примерно в 100 раз увеличить скорость выполнения команд обработки чисел с плавающей запятой и значительно повысить точность получаемых результатов. Особенности технической реализации ДПУ различны у различных изготовителей, но многие основные принципы их построения не зависят от конкретной реализации.
Для использования команд, реализуемых сопроцессором в современных процессорах (в частности, 32-разрядных), предусматривается командная маска. Она представляет собой группу резервных кодов операции, которая идентифицируется процессором по заданному набору значений определенных битов кода. В остальных битах кода операции определяется конкретная дополнительная операция.
Обычно ДПУ подключается к линиям адресов и данных процессора и в нужный момент декодирует масочный код операции. Однако возможен и другой подход, при котором для работы с отдельным кодовым пространством ДПУ необходимы внешние логические схемы, так как ДПУ не способно само декодировать масочные коды операции.
Некоторые сопроцессоры имеют возможность брать на себя управление процессорной шиной для прямого обращения к памяти. Другие же прибегают к услугам основного процессора, который предоставляет им адреса для чтения или записи данных в память. Последний вариант характерен для однокристальных ДПУ (в частности, 32-разрядных). Возможность непосредственного обращения к памяти предусмотрена в некоторых одноплатных сопроцессорах, предназначенных для обработки матриц и ВВ аналоговой информации.
В системе, где сопроцессор не установлен, его функции должен иметь возможность эмулировать центральный процессор. В его управляющем регистре может быть предусмотрен бит, который устанавливается в состояние 1 при наличии сопроцессора. Если этот бит не установлен в состояние 1, то для реализации масочной операции, входящей в расширенный набор команд, центральный процессор переходит к определенной подпрограмме, при выполнении которой эмулируются соответствующие действия ДПУ.
Некоторые сопроцессоры работают в непараллельном (синхронном) режиме, при котором центральный процессор вынужден дожидаться завершения ДПУ-команды сопроцессором, для того чтобы начать выполнение очередной команды. Другие сопроцессоры работают в параллельном (асинхронном) режиме, позволяющем центральному процессору выполнять другие команды одновременно с реализацией ДПУ-команды сопроцессором. Очевидно, что параллельная работа сопроцессора и процессора позволяет повысить производительность системы в целом. Однако при этом возникают проблемы, связанные с изменением содержимого памяти центральным процессором до того, как соответствующие данные считаны сопроцессором, а также изменением содержимого памяти сопроцессором без уведомления об этом центрального процессора. Одним из путей решения этих проблем является запрещение прямого доступа к памяти со стороны сопроцессора при работе в параллельном режиме.
Для микропроцессора I80386 ДПУ, выполняющего действия над ЧПЗ, является сопроцессор I80387, имеющий быстродействие 1.8×106 операций в секунду и функционирующий параллельно с центральным процессором (I80386) в асинхронном
режиме.
СПОСОБЫ ОРГАНИЗАЦИИ ДОСТУПА К СИСТЕМНОЙ МАГИСТРАЛИ
Конкретные варианты процедур доступа ведущих устройств к магистрали (организации каналов ПДП) в различных ЭВМ очень разнообразны. Между тем существуют некоторые общие принципы их реализации. В общем случае для устройств, использующих ПДП (DMA), выделяют два основных принципа организации доступа, в соответствии с которыми выделяют два типа систем ПДП (DMA).
Пассивный доступ или slave DMA. При этом способе доступа все устройства, использующие режим DMA, являются slave и обслуживаются одним специальным контроллером DMA (ПДП), размещенным на системной магистрали, т.е. одним ведущим устройством, – master. Такой способ доступа позволяет реализовать только связи ПУ-ОП. Контроллер DMA включает в себя арбитр магистрали и соответствующие СУМ. В этом случае ПУ играют пассивную роль и осуществляют обмен с ОП по сигналам, формируемым контроллером DMA, т.е. аналогично тому, как это происходит при обмене через процессор.
Как уже отмечалось выше, контроллер DMA обслуживает несколько ПУ, т.е. поддерживает несколько каналов ПДП. Перед началом обмена контроллер должен быть инициализирован. Для этого в его регистры необходимо загрузить начальный адрес области ОП, с которой ведется обмен, размер передаваемого блока информации для каждого канала, направление и режим передачи, дисциплину арбитража. В общем случае инициализация контроллера может осуществляться по мере необходимости (многократно) в процессе обработки текущей программы. Однако установка дисциплины арбитража в абсолютном большинстве случаев осуществляется один раз, при запуске вычислительной системы на решение конкретной задачи.
Таким образом, slave DMA не требует существенного усложнения аппаратуры устройств магистрали, а следовательно, и увеличения их стоимости. Каждое устройство, использующее такой режим обмена, должно иметь только аппаратуру формирования сигнала запроса ПДП (запросчик). При этом контроллер DMA является достаточно сложным и дорогим устройством, которое можно считать сопроцессором ввода/вывода, разгружающим центральный процессор от рутинных операций обмена (т.е.
контроллер ПДП является очень упрощенным вариантом канальных процессоров мэйнфреймов, описанных в гл. 1).
Исторически системы slave DMA появились первыми. В частности, система ПДП такого типа использовалась первоначально на магистрали ISA в компьютерах PC/XT фирмы IBM. Многочисленные варианты систем slave DMA используются и в настоящее время в универсальных и управляющих ЭВМ самой разной архитектуры, назначения и производительности.
Активный доступ, или bus master DMA. При этом способе доступа предполагается, что устройства, использующие режим DMA, имеют программно-аппаратные средства, способные управлять магистралью (осуществлять прямое управление магистралью, или bus mastering), а следовательно, и реализовывать любые связи типа master-slave (M-S). Такие устройства магистрали могут выступать как master, поэтому единый контроллер DMA отсутствует. Остается только арбитр магистрали, который по определенной дисциплине предоставляет магистраль в распоряжение того или иного устройства. Арбитр может быть выполнен как отдельное устройство, размещенное на магистрали, либо арбитражем магистрали может заниматься процессор. В современных IBM PC процедуры арбитража магистрали включены в функции чипсета. При наличии нескольких процессоров арбитром может быть назначен один из них.
Следует иметь в виду, что любое современное интеллектуальное устройство управляется процессором (процессорами), находящимся на системной магистрали и имеющим собственную шину расширения. Такое устройство фактически является специализированной микроЭВМ, функционирующей по программе, обычно хранящейся в собственном ПЗУ. Этим оно, в сущности, только и отличается от "центрального процессора (ЦП)", также находящегося на системной магистрали и обрабатывающего команды текущей программы, хранящейся в ОП или системном ПЗУ. Такой подход позволяет рассматривать "ЦП" как одно из интеллектуальных устройств магистрали, причем "ЦП" может быть несколько. Исходя из этого, в вычислительных системах, использующих bus mastering, можно говорить о множестве интеллектуальных устройств, приоритеты которых на использование системной магистрали для обмена (захват магистрали) определяются только дисциплиной обслуживания, загруженной в арбитр при инициализации, т.е.
можно говорить о многопроцессорных вычислительных системах.
Таким образом, bus master DMA требует существенного усложнения устройств магистрали (наличие СУМ, более сложный запросчик), а следовательно, и увеличения их стоимости. Однако он дает возможность ускорить процессы обмена, особенно в многозадачном режиме, и реализовать многопроцессорные варианты вычислительных систем, имеющих магистрально-модульную архитектуру.
Примером устройств с активным DMA являются контроллеры АТА (AT Attachment for Disk Drivers), расположенные в современных IBM PC на магистрали PCI, в частном случае контроллеры IDE. Активный DMA использует хост-адаптер шины SCSI (Small Computer System Interface), связывающий шину с какой-либо внутренней магистралью компьютера, а также контроллеры графических систем и средства их подключения, например порт AGP (Accelerated Graphic Port) и ряд других устройств. Примером устройств, использующих только bus master DMA (bus mastering), являются устройства вычислительных систем, построенных на базе магистрали VME (Versa Module Eurocard).
Следует отметить, что в реальных вычислительных системах иногда используют оба варианта систем DMA одновременно (для разных устройств магистрали). При этом контроллер может поддерживать несколько каналов DMA и работать в комбинированном режиме. Для одних устройств магистрали (slave) он может выполнять функции контроллера DMA, а для других устройств (master) он являются только арбитром магистрали. Именно такой вариант функционирования системы DMA был реализован в PC/AT фирмы IBM.
ТЕГИ И ДЕСКРИПТОРЫ САМООПРЕДЕЛЯЕМЫЕ ДАННЫЕ
Одним из эффективных средств совершенствования архитектуры современных ЭВМ является теговая организация памяти, при которой каждое хранящееся в памяти или регистре слово снабжается тегом. Тег определяет тип данных – целое число, ЧПЗ, десятичное число, адрес, строку символов, дескриптор и т.д. В поле тега обычно указывают не только тип, но и длину (формат) и некоторые другие его параметры. Теги формируются компилятором. Формат данных, хранимых в памяти, при этом имеет вид, изображенный на рис. 9.1.

Наличие тегов придает хранящимся в машине данным свойство самоопределяемости. Это принципиальная особенность в функционировании ЭВМ.
Следует отметить, что ЭВМ с теговой памятью выходят за рамки модели вычислительной машины фон Неймана именно в результате самоопределяемости данных. Классическая модель фон Неймана исходит из того, что тип (характер) данного, хранящегося в памяти, определяется только в контексте выполнения программы, а точнее, команды, использующей данное в качестве операнда. В обычных ЭВМ, соответствующих классической модели фон Неймана, тип данных-операндов и их формат задаются кодом операции команды, а в ряде случаев размер (формат) операндов определяется специальными полями команды.
Например, в IBM-360/370 команда десятичное сложение
самим своим кодом операции определяла, что адресуемые ею операнды являются десятичными числами. Специальные четырехразрядные поля в этой команде задавали число десятичных цифр в 1-м и 2-м операндах. Таким образом, в IBM-360/370 имелось 256 кодов только одной команды десятичное сложение.
Теговая организация памяти позволяет достигнуть инвариантности команд относительно типов и форматов операндов, что приводит к значительному сокращению набора команд машины. Это упрощает и делает более регулярной структуру процессора. Кроме того, такая организация памяти дает еще ряд преимуществ, а именно:
- облегчает работу программиста, в том числе при отладке программ;
- сокращает затраты времени на компиляцию (отпадает необходимость выбора типа команды в зависимости от типа данных);
В качестве примера рассмотрим один из видов дескрипторов – дескриптор данных в машине B6700 фирмы Burroughs (рис. 9.2).

Дескриптор содержит специфический тег ТДс, указывающий, что данное слово является дескриптором определенного вида, группу указателей и два поля A и L/X. Поле A указывает адрес начала массива данных. В зависимости от значения указателя I дескриптор описывает массив данных (I = 0)– и в соответствующее поле помещается длина массива L, или описывает элемент массива (I = 1)– и тогда в поле находится индекс X. Этот индекс указывает смещение элемента относительно начала массива. Указатель P определяет, находится массив в оперативной памяти или ВП, т.е. его можно назвать "Указатель присутствия". В последнем случае (нахождение в ВП) поле A указывает местоположение массива во внешней памяти. Остальные указатели имеют следующий смысл:
D – одинарная или двойная точность представления данных;
T – описывается слово или строка;
R = 1 – данные можно только читать;
S – указывает на непрерывное или фрагментарное расположение массива в памяти;
C – определяет, является ли дескриптор копией другого дескриптора.
Процессоры фирмы Intel, начиная с модели I80386, снабжены средствами, позволяющими реализовать механизм разделения логического адресного пространства памяти на страницы (4 Кбайт) и сегменты разного размера (сегменты программ, данных, системные сегменты и т.д.). Более подробно этот вопрос обсуждается в
п. 9.4. Все сегменты рассматриваются как массивы, и для их описания и адресации используются дескрипторы. Каждая задача может иметь системное и индивидуальное логическое адресное пространство. Эти пространства описываются соответственно глобальной (GDT) и локальной (LDT) таблицами дескрипторов сегментов, каждая из которых может содержать максимум 8192 дескриптора. На рис. 9.3 представлен формат дескрипторов сегмента программ и сегмента данных процессо-
ра I80386.

Назначение полей дескриптора приведено на рис. 9.3, однако необходимо сделать некоторые пояснения:
- "16-разрядный режим" – это режим полной эмуляции процессора I80286.
- "Базовый адрес" – 32-битное поле (из трех фрагментов), определяющее положение сегмента в адресном пространстве 4 Гбайт.
- "Предел" – 20-битное поле (из двух фрагментов), определяющее размер сегмента. В зависимости от значения бита гранулярности G предел вычисляется либо в байтах (G = 0), либо в страницах по 4 Кбайта (G = 1). В первом случае размер сегмента не превышает 1 Мбайт, во втором – может достигать 4 Гбайт.
Использование в архитектуре ЭВМ дескрипторов подразумевает, что обращение к информации в памяти производится через дескрипторы, которые при этом можно рассматривать как дальнейшее развитие аппарата косвенной адресации. Адресация информации в памяти может осуществляться с помощью цепочки дескрипторов. При этом реализуется многоступенчатая косвенная адресация. Более того, сложные многомерные массивы данных (таблицы и т.п.) эффективно описываются древовидными структурами дескрипторов. Это можно проиллюстрировать упрощенной схемой на рис. 9.4.

Термины "тег" и "дескриптор" достаточно широко используются в технической литературе при обсуждении вопросов организации ЭВМ и вычислительных процессов. Однако трактовка этих терминов во многих случаях достаточно неоднозначна, особенно в технических описаниях конкретных процессоров и ЭВМ различных производителей, поэтому необходимо всегда учитывать контекст, в котором используются указанные термины.
ТИПЫ РАЗЪЕМОВ ОПЕРАТИВНОЙ ПАМЯТИ

На данный момент существует также несколько типов разъемов для установки оперативной памяти. Такие как: SIMM, DIMM, RIMM.
SIMM (Single In line Memory Module – модуль памяти с одним рядом контактов) – модуль памяти, вставляемый в зажимающий разъем. Помимо компьютера используется также во многих адаптерах, принтерах и прочих устройствах. SIMM имеет контакты с двух сторон модуля, но все они соединены между собой, образуя как бы один ряд контактов. Модули SIMM бывают двух видов (30 и 72 pin). Основное различие в количестве контактов на модуле. Но 30 pin'овые модули уже достаточно давно сняты с производства и вероятнее всего, вы их не встретите.
DIMM (Dual In line Memory Module – модуль памяти с двумя рядами контактов) – модуль памяти, похожий на SIMM, но с раздельными контактами (168 pin, т. е. 2 ряда по 84 pin). Контакты расположены с двух сторон, но гальванически разделены в отличие от SIMM модулей. За счет этого увеличивается разрядность или число банков памяти в модуле. Также применены разъемы другого типа, нежели для модулей SIMM.
CELP (Card Egde Low Profile – невысокая карта с ножевым разъемом на краю) – модуль внешней кэш-памяти, собранный на микросхемах SRAM (асинхронный) или PB SRAM (синхронный). По внешнему виду похож на 72-контактный SIMM, имеет емкость 256 или 512 Кбайт.
ВИРТУАЛЬНАЯ ПАМЯТЬ
Принцип виртуальной памяти предполагает, что пользователь при подготовке своей программы имеет дело не с физической ОП, действительно работающей в составе ЭВМ и имеющей некоторую фиксированную емкость, а с виртуальной
(т.е. кажущейся) одноуровневой памятью, емкость которой равна всему адресному пространству, определяемому размером адресных полей в форматах команд и базовых регистров. Так, например, процессор I80386 может управлять виртуальной памятью до 64 Тбайт (терабайт). Это потенциально возможный объем виртуальной памяти, которой может управлять процессор с 32-разрядной ША. Между тем объем виртуальной памяти реальных компьютеров существенно меньше потенциального. Он определяется объемом ВП (жесткого диска), а точнее той ее части, которая выделяется операционной системой для реализации механизма виртуальной памяти. Объем ОП в данном случае не учитывается, поскольку он существенно меньше выделенного объема дисковой памяти (ВП).
Пользователь имеет в своем распоряжении все адресное пространство ЭВМ независимо от объема ее физической памяти (ОП) и объемов памятей, необходимых для других программ, участвующих в мультипрограммной обработке. При этом достигается гибкое динамическое распределение памяти, устраняется ее фрагментация и создаются значительные удобства для работы программиста. В современных ЭВМ все это достигается без заметного снижения производительности компьютера, ценой усложнения аппаратуры, операционной системы и процессов их функционирования.
На всех этапах подготовки программы, включая загрузку в ОП, программа представляется в виртуальных адресах, и лишь при самом исполнении машинной команды производится преобразование виртуальных адресов в реальные адреса физической памяти ЭВМ (их называют еще физическими
адресами или исполнительными).
Преобразование виртуальных адресов в физические упрощается, а также устраняется фрагментация памяти, если физическую и виртуальную память разбить на блоки небольшого размера, содержащие одно и то же число байт.
Такие блоки называются страницами. Страницам виртуальной и физической памяти присваивают номера, называемые номерами соответственно виртуальных и физических страниц. Каждая физическая страница способна хранить одну из виртуальных страниц. Нумерация байт в виртуальной и физической страницах сохраняется одной и той же.
Вновь загружаемая в ОП программа может быть направлена в любые свободные в данный момент физические страницы, независимо от того, расположены они подряд или нет. Не требуется перемещения информации в остальной части памяти. Страничная организация позволяет более рационально
осуществлять обмен информацией между ВП и ОП, так как страница программы не должна загружаться до тех пор, пока она действительно не понадобится (имеется в виду, что обмен небольшими блоками информации между ВП и ОП можно осуществить без заметного снижения производительности процессора). Сначала в ОП загружается начальная страница программы, и ей передается управление. Если в процессе обработки программы делается попытка выборки слов из другой страницы, то производится автоматическое обращение к операционной системе, которая осуществляет загрузку требуемой страницы. Так происходит в процессе выполнения всей программы, при этом ненужные модифицированные страницы программы перемещаются из ОП в ВП. (Алгоритмы замены страниц в ОП рассматриваются в п. 9.6). Операция замены (замещения) страниц в ОП называется свопингом (swapping), а часть диска, выделенная на нужды виртуальной памяти, – файлом подкачки
(swap file). Размер этого файла, а следовательно, и максимальный объем виртуальной памяти конкретной ЭВМ зависят от общего объема жесткого диска и типа установленной операционной системы.
Соответствие между виртуальными и физическими памятями устанавливается страничной таблицей, причем физические страницы могут содержаться в текущий момент времени как в ОП, так и в ВП.
Упрощенная схема страничной организации памяти изображена на рис. 9.12.
Страничная таблица для каждой программы формируется операционной системой в процессе распределения памяти и перерабатывается ею каждый раз, когда в распределении памяти производятся изменения.
Процедура обращения к памяти состоит в том, что номер виртуальной страницы извлекается из адреса и используется для входа в страничную таблицу, которая указывает номер соответствующей физической страницы. Этот номер вместе с номером байта, взятым непосредственно из виртуального адреса, представляет собой физический адрес, по которому происходит обращение к ОП. Процесс формирования физического адреса можно изобразить схемой, представленной на рис. 9.13, причем под номером физической страницы понимается ее базовый адрес.

Если страничная таблица указывает на размещение требуемой информации во внешней памяти (ВП), то обращение к ОП не может состояться немедленно, так как операционная система должна организовывать загрузку в ОП из ВП нужной
страницы.
Для каждой из программ, обрабатываемых в мультипрограммном режиме, организуется своя виртуальная память и создается своя страничная таблица, при этом все программы делят между собой одну физическую память (ОП и ВП).
Страничные таблицы программ хранятся в ОП, и обращение к нужной строке активной страничной таблицы в ОП происходит по адресу, который определяется номером активной программы и номером виртуальной
страницы.
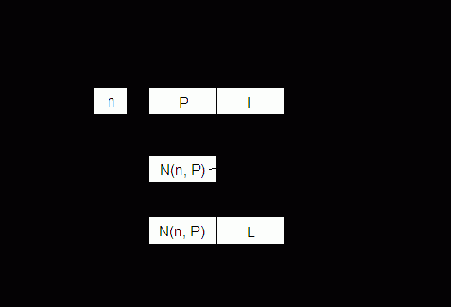
Следует иметь в виду, что механизм организации страничной адресации в реальных вычислительных системах, даже на процессорах поколения I80386, существенно сложнее описанного выше. В частности, для обращения к страничной таблице соответствующей программы операционная система должна первоначально обратиться к каталогу, в котором хранятся базовые адреса страничных таблиц соответствующих программ. Перемещение модифицированных страниц из ОП в ВП в большинстве случаев осуществляется не напрямую, а через кэшированную область ОП (дисковый кэш), поскольку велика вероятность обращения к недавно удаленной странице. Такой механизм позволяет ускорить процесс подкачки страницы при повторном обращении.
Для ускорения преобразования адресов обычно используется небольшая сверхоперативная память, куда передается из ОП страничная таблица активной программы.Кроме того, во внутренней памяти процессора обычно формируется сводная таблица, содержащая сведения о номерах виртуальных и соответствующих физических страниц для нескольких недавно использовавшихся страниц, в том числе принадлежащих разным программам. Так, внутрикристальный кэш процессора I80386 содержит информацию, необходимую для доступа к 32 страницам памяти, к которым недавно выполнялось обращение. В этом варианте сверхоперативная память, используемая при преобразовании адресов, строится как ассоциативная. Обращение к ней идет не по адресу, а по содержанию хранимой в ячейке информации – номеру программы и номеру виртуальной страницы.
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1. Перечислите режимы ВВ.
2. Общие принципы организации ВВ.
3. Когда лучше использовать синхронный ВВ?
4. Чем асинхронный ВВ отличается от синхронного?
5. Как осуществляется обмен данными по прерыванию?
6. Приведите алгоритм обслуживания прерываний.
7. Какое устройство управляет обменом в режиме ПДП?
8. Назовите возможные варианты обмена в режиме ПДП с захватом цикла и кратко их охарактеризуйте.
9. Чем отличается режим ПДП с блокировкой процессора от режима ПДП с захватом цикла?
10. Перечислите основные этапы обмена информацией в режиме ПДП.
11. Какие режимы последовательного обмена информацией бывают?
12. В чем преимущества передачи данных в последовательном формате?
13. Опишите программную модель адаптера КР580ВВ51.
14. Адаптер параллельного интерфейса. Основные режимы его функционирования.
15. Основные особенности функционирования адаптера параллельного интерфейса в режиме 0.
16. Основные особенности функционирования адаптера параллельного интерфейса в режиме 1.
17. Основные особенности функционирования адаптера параллельного интерфейса в режиме 2.
1. Какие преимущества дает теговая организация памяти?
2. Для чего используются дескрипторы?
3. Приведите формат дескрипторов сегмента программ или сегмента данных.
4. Как происходит обращение к памяти через дескрипторы?
5. ЭВМ RISC-архитектуры. Ее основные особенности.
6. Для чего предназначен механизм перекрывающихся регистровых окон?
7. Какие существуют направления оптимизации процессов обмена процессора и ОП?
8. Основные принципы конвейеризации процедур цикла выполнения команды.
9. Перечислите пути уменьшения влияния команд условных переходов на производительность конвейера команд.
10. В чем суть метода расслоения памяти?
11. Опишите метод "буферизации памяти".
12. Приведите алгоритм взаимодействия кэш-памяти и ОП при перемещении блоков информации.
13. На чем основана концепция полностью ассоциативного кэш?
14. Опишите принципы построения кэш с прямым отображением.
15. Опишите принципы построения двухвходового множественного ассоциативного кэш.
16. Процедура динамического распределения памяти. Как она осуществляется?
17. В чем заключается принцип построения виртуальной памяти?
18. Приведите схему страничной организации памяти.
19. Сегментно-страничная организация памяти.
20. Какие преимущества дает страничная организация памяти?
21. Перечислите варианты защиты памяти.
22. Какие бывают алгоритмы управления многоуровневой памятью?
23. Сопроцессоры. Их назначение и использование.
1. Почему в процессе эволюции ЭВМ оказалось недостаточным использование одной системной магистрали?
2. Что понимается под термином "шина расширения"?
3. Опишите назначение локальной системной шины.
4. Для чего предназначена шина процессора?
5. Чем определяется скорость передачи данных по шине?
6. Из чего складывается пропускная способность шины?
7. Для чего предназначена шина памяти?
8. Опишите стандарт шины расширения ISA.
9. Чему равна пропускная способность шины ISA?
10. Шина расширения МСА. Ее назначение и основные характеристики.
11. Почему ШР МСА не получила распространение?
12. В чем сходство и отличия ШР ISA и EISA?
13. Что такое "локальная шина"?
14. Локальная шина VLB. Ее особенности.
15. Перечислите возможности шины PCI.
16. Назовите функции главного моста.
1. Приведите и кратко охарактеризуйте основные недостатки программно-управляемого ВВ.
2. Дайте определение режима прямого доступа к памяти (ПДП). В чем преимущества этого режима?
3. Объясните, что понимается под термином "master". Что должны "уметь" эти устройства?
4. Объясните, что понимается под термином "slave".
5. Основные принципы организации доступа для устройств, использующих ПДП. Опишите пассивный доступ (slave DMA).
6. Основные принципы организации доступа для устройств, использующих ПДП. Опишите активный доступ (bus master DMA).
7. От чего зависят конкретные технические реализации систем ПДП?
8. Основные базовые структуры систем ПДП. Назовите характерные особенности каждой. В чем их отличие?
9. Перечислите достоинства и недостатки цепочечной и радиальной струк-
тур ПДП.
10. Основные способы решения проблемы совместного использования шин системного интерфейса процессором и контроллером ПДП. Опишите ПДП с захватом цикла.
11. Основные способы решения проблемы совместного использования шин системного интерфейса процессором и контроллером ПДП. Опишите ПДП с блокировкой процессора.
12. Радиальная структура ПДП (slave DMA). Последовательность операций по предоставлению магистрали в распоряжение контроллера ПДП.
13. Радиальная структура ПДП (bus master DMA). Последовательность операций по предоставлению магистрали в распоряжение одного из ведущих устройств для передачи блока информации.
14. Приведите схему обобщенной цепочечной структуры системы bus mas-
ter DMA.
15. Опишите структуру шины арбитража "n" системы bus master DMA цепочечного типа.
16. Принципы организации арбитража магистрали. Наиболее распространенные варианты арбитров.
ВОЗМОЖНЫЕ СТРУКТУРЫ СИСТЕМ ПДП
Конкретные технические реализации систем ПДП имеют множество вариантов. Они зависят от типа системной магистрали, архитектуры ЭВМ в целом, типа используемого процессора, целевого назначения ЭВМ, количества устройств на магистрали и т.д. В то же время они являются сложными комбинациями небольшого количества базовых структур систем ПДП. Ниже рассматриваются две основные базовые структуры – радиальная и цепочечная.
Радиальная структура
Упрощенные варианты обобщенных структур систем ПДП радиального типа представлены на рис. 11.1.
Характерной особенностью радиальной структуры является то, что каждый ИЗПД (в частном случае ПУ) подключен к отдельному входу контроллера ПДП
(рис. 11.1, а) или арбитра (рис. 11.1, б). Отличие двух структур состоит в том, что в случае slave DMA для подключения ИЗПД достаточно одной линии ЛЗПД, по которой устройство выставляет запрос на обслуживание. В системе bus master DMA для подключения устройства к арбитру необходимы, как минимум, три линии – ЛЗПД, ЛПЗ и ЛРПД, которые можно назвать шиной арбитража (ШАр), имеющей собственный вход в арбитр. Каждый вход (в контроллер, в арбитр) обладает определенным уровнем приоритета. Число подключаемых ИЗПД определяется числом входов в контроллер или арбитр. При обслуживании устройств, использующих slave DMA
(рис. 11.1, а), всем обменом управляет контроллер ПДП, обязательными компонентами которого являются блок СУМ и арбитр магистрали. Устройства магистрали пассивны и должны содержать только запросчик.
При обслуживании устройств, использующих bus master DMA (рис. 11.1, б), контроллер ПДП, как таковой, отсутствует и централизованно выполняется только арбитраж магистрали. Устройства магистрали активны, поэтому их обязательными компонентами являются запросчик и блок СУМ (как уже отмечалось, "ЦП" в системах bus mastering рассматривается как одно из ИЗПД). После захвата магистраль управляется блоком СУМ конкретного устройства, ведущего обмен (master). В качестве арбитра магистрали используется либо специализированное устройство, либо контроллер ПДП, в котором функции блока СУМ отключены.
Линии ЛРПД, присутствующие в системе bus master DMA, предназначены для передачи сигнала РПД, позволяющего активному устройству захватить магистраль. Кроме того, в системе bus master DMA обязательно присутствуют линии ЛПЗ, сигналы которых информируют арбитр о захвате магистрали тем или иным устройством. Сигнал ПЗ всегда выставляет master и удерживает его на линии все время, пока осуществляет обмен (управляет магистралью), поэтому сигнал всегда представлен потенциалом.
В системах радиальной структуры контроллер ПДП может работать, как было отмечено выше, и в комбинированном режиме, т.е. поддерживать как систему slave DMA, так и систему bus master DMA (см. окончание п. 11.1). Запросы от ИЗПД в обеих системах DMA могут быть представлены как уровнем потенциала, так и его перепадом, поскольку поступают в контроллер или арбитр по отдельным линиям. Однако представление запроса потенциалом более предпочтительно, поскольку система DMA становится более устойчивой как к помехам, так и к сбоям аппаратуры. Это существенно снижает вероятность пропуска запроса от ИЗПД.
Основным преимуществом радиальной структуры является то, что упрощается аппаратура арбитра магистрали, поскольку каждый ИЗПД имеет собственную ЛЗПД. Кроме того, несколько упрощается аппаратура ИЗПД и конструкция слота даже в случае bus master DMA, поскольку все активные устройства магистрали имеют отдельную шину арбитража (ШАр). Все это удешевляет радиальную систему по сравнению с цепочечной, рассматриваемой ниже.
Цепочечная структура
Упрощенный вариант обобщенной структуры системы ПДП цепочечного типа представлен на рис. 11.2.

Характерной особенностью цепочечной структуры является то, что множество активных устройств магистрали (ИЗПД), обязательными компонентами которых являются блок СУМ и запросчик, подключены к одной или нескольким шинам арбитража (ШАр). На рис. 11.2 присутствуют две ШАр. После захвата магистраль управляется блоком СУМ конкретного устройства, ведущего обмен (master).
Контроллер ПДП отсутствует, и централизованно выполняется только арбитраж магистрали. На
рис. 11.2 арбитр изображен как отдельное устройство магистрали, хотя, как отмечено выше, арбитраж может осуществлять и процессор (один из процессоров). Каждая ШАр соответствует одному входу в арбитр и обладает собственным уровнем приоритета. Таким образом, ИЗПД, подключенные к разным ШАр, обладают различным приоритетом. Пассивные устройства магистрали (slave) к ШАр не подключены. Кроме того, приоритет устройств, подключенных к одной ШАр, определяется также их положением в цепи распространения сигнала разрешения прямого доступа (РПД).
Рассмотрим этот момент более подробно на примере одной ШАрn
системы bus master DMA, упрощенная структура которой приведена на рис. 11.3.
Из рисунка следует, что ШАр (для упрощения обозначений здесь и ниже индекс "n" опущен) в такой системе содержит, как минимум, четыре линии – ЛЗПД, ЛРПД, ЛПЗ и ЛБПД. В отличие от радиальной структуры, ИЗПД магистрали подключены к трем линиям ШАр (ЛЗПД, ЛПЗ и ЛБПД) параллельно, поэтому запросы от ИЗПД (сигналы ЗПД) всегда представлены уровнем потенциала. Выходные каскады аппаратных средств формирования запросов в каждом ИЗПД представляют собой ключи с открытым коллектором, объединенные по схеме монтажного "или". Это позволяет исключить потерю запросов, одновременно выставленных запросчиками разных ИЗПД на одну ЛЗПД.

Сигнал РПД распространяется последовательно через все устройства, пока его распространение не будет заблокировано запросчиком ИЗПДi, выставившим запрос прямого доступа (сигнал ЗПДi). Таким образом, приоритет ведущего устройства магистрали определяется его положением в цепи распространения сигнала РПД. Пусть арбитр расположен в слоте с номером "0". Тогда приоритет устройств, расположенных в последующих слотах, будет убывать с ростом номера слота. При отсутствии устройства в слоте необходимо принять меры для того, чтобы цепь распространения сигнала РПД не разрывалась. Это обеспечивается либо специальной конструкцией контактов слота, либо установкой перемычки на системной плате.
Сигнал линии ЛПЗ, как и в радиальной системе bus master DMA, информирует арбитр о захвате магистрали тем или иным устройством. Этот сигнал всегда выставляет master и удерживает его на линии все время, пока осуществляет обмен (управляет магистралью), поэтому сигнал всегда представлен потенциалом.
Линия ЛБПД – общая для всех ШАр и предназначена для передачи от арбитра сигнала блокировки прямого доступа (БПД), который запрещает bus mastering всем интеллектуальным устройствам магистрали. Необходимость в этом может возникнуть, например, при появлении запроса на линии ЛЗПД ШАр более высокого приоритета (при наличии нескольких ШАр) или в случае удержания магистрали одним устройством недопустимо долгое время.
Следует иметь в виду, что системы цепочечной структуры практически работают только в режиме bus master DMA, поскольку арбитр магистрали может идентифицировать только ЛЗПД, с которой поступил запрос, и определить его приоритет. При реализации режима slave DMA контроллеру DMA необходимо будет идентифицировать конкретное ИЗПД на данной линии. Такую операцию контроллер может выполнить только путем последовательного опроса устройств линии, что существенно увеличит время арбитража и усложнит аппаратуру устройств. Между тем техническая реализация таких систем возможна.
Основным преимуществом цепочечной структуры является практически неограниченное количество ИЗПД, подключаемых к одному входу арбитра (одной ШАр) без снижения быстродействия. Однако сложность и объем аппаратуры поддержки системы bus mastering в каждом ИЗПД увеличиваются, что ведет к увеличению стоимости системы.
ВВ ПО ПРЕРЫВАНИЯМ
Для сокращения непроизводительных потерь времени процессора за счет циклов ожидания при программном обмене, т.е. когда процессор не может заниматься ничем, кроме программы ВВ, используют обмен по прерыванию.
При готовности к обмену ПУ посылает в процессор запрос на обслуживание – сигнал INT (запрос прерывания). Этот сигнал появляется в произвольные моменты времени, а следовательно, и в произвольной точке текущей программы. Поскольку заранее неизвестно, в какой точке программы и какие ПУ инициируют прерывания, непосредственно в программе команды ВВ использовать нельзя.
Общие вопросы организации системы прерываний в ЭВМ рассмотрены ранее
в гл. 6. Некоторые вопросы, связанные с обслуживанием прерываний, рассмотрены при изучении команд RST и RET. Между тем использование конкретного процессора вносит свои особенности в последовательность операций по обслуживанию прерывания. Для микроЭВМ, построенной на базе МП комплекта КР580, эта последовательность выглядит следующим образом:
1. Контроллер ПУ или адаптер промежуточного интерфейса генерирует сигнал запроса прерывания, который подается на вход INT процессора непосредственно (если ПУ одно) или через контроллер прерываний (если ПУ много) в виде общего сигнала прерывания.
2. При наличии нескольких ПУ в контроллере прерывания осуществляется идентификация прерывающего устройства (т.е. выясняется, откуда поступил сигнал INT, и его приоритет).
3. Процессор завершает текущую команду и, если прерывание разрешено, формирует сигнал INTA (подтверждение прерывания), который выдается во внешнюю цепь (в частности, в системный контроллер), а также сбрасывает внутренний триггер разрешения прерываний, состояние которого идентифицируется сигналом INTE.
4. Содержимое PC (счетчик команд) автоматически запоминается в стеке.
5. Происходит переход к подпрограмме обслуживания данного ПУ (обработчику), при этом выполняются следующие операции:
- запоминание состояния прерванной программы, которое должно быть предусмотрено пользователем, т.е.
составителем подпрограммы ( это слово состояния процессора PSW º (A) (РгП), а также содержимое РОН, используемых в подпрограмме обслуживания прерывания); обычно для запоминания используют стек. В ряде современных процессоров PSW автоматически сохраняется в стеке, как и содержимое счетчика PC;
- выполнение собственно программы обслуживания процесса ВВ;
- восстановление состояния прерванной программы (т.е. извлечение и загрузка в соответствующие регистры PSW и содержимого РОН из стека).
6. Возобновляется выполнение прерванной программы по команде RET, являющейся обязательной последней командой обработчика.
Следует отметить, что реакция процессора на прерывание очень похожа на вызов подпрограммы, несмотря на то, что обращение к подпрограмме происходит в фиксированных точках программы, а прерывания возникают в случайных точках программы. Однако внешняя аналогия реакции на прерывание и вызов подпрограммы позволяют считать прерывание аппаратным вызовом подпрограммы (с помощью сигнала INT).
Поскольку сигнал на вход INT может поступить в произвольной точке программы, процессору необходимо проверять наличие сигнала запроса прерывания до перехода к следующей команде. В МП КР580 анализ входа INT осуществляется в такте Т2 последнего машинного цикла каждой команды.
Действия процессора по обслуживанию запросов прерывания можно пояснить следующим упрощенным алгоритмом, представленным на рис. 8.2.
Следует отметить, что внутренний триггер разрешения прерываний INTE называется также маской прерывания. Состояние этого триггера идентифицирует сигнал с такой же мнемоникой. Если INTE = 0, то прерывания запрещены (замаскированы) и процессор не реагирует на сигнал INT = 1. Этот триггер управляется программно с помощью команд EI (разрешение прерывания) и DI (запрещение прерывания).
Идентификация прерывающего устройства осуществляется с учетом приоритетов либо программными, либо аппаратными методами, рассмотренными ранее
в гл. 6.
В МП - комплекте КР580 аппаратный полинг реализуется специальной БИС программируемого контроллера прерываний КР580BH59, обеспечивающей прием и обработку восьми сигналов прерывания. Возможно совместное использование восьми БИС, что увеличивает число сигналов до 64. С каждым входом сигнала прерывания ассоциируется адрес памяти, который выдается на шину данных в ответ на сигнал

адреса загружаются в регистр контроллера командой инициализации, а младшие биты A4-A0 формируются в контроллере. Разряд A5
программирует интервал в 4 или 8 байт для каждого вектора прерывания.
Контроллер КР580BH59 является законченным устройством, позволяющим реализовывать достаточно сложные многоуровневые системы прерывания. При этом его программирование, т.е. формирование приказов инициализации и рабочих приказов, представляет определенные трудности.
Однако во многих случаях от контроллера прерываний не требуется такой многофункциональности. Простой контроллер прерываний можно построить на обычных логических схемах или с использованием специальной БИС приоритетных прерываний К589ИК14 и многорежимного буферного регистра К589ИР12. В этом случае для формирования адреса вектора прерывания используется 1-байтовая команда RST (ее исполнение уже рассматривалось). Адреса, соответствующие всем входам запросов прерываний, располагаются равномерно через 8 байт от 0000H до 0038H, т.е.под векторы прерываний зарезервированы первые 64 ячейки ОП.
ВВ В РЕЖИМЕ ПДП
В этом режиме обмен данными между ПУ и ОП микроЭВМ происходит без участия процессора. Обменом в режиме ПДП управляет не программа (или прерывающая подпрограмма), а электронные схемы, внешние по отношению к процессору.
Необходимость реализации режима ПДП в современных ЭВМ достаточно подробно будет рассмотрена в п. 11. Здесь же отметим коротко только основные причины реализации режима ПДП в простейших микроЭВМ.
При программном обмене или обмене в режиме прерывания для передачи одного слова данных (в частном случае – байта) затрачивается несколько (2-3) команд процессора, суммарное время выполнения которых может оказаться недопустимо большим для обмена с конкретным ПУ. Это может быть связано с тем, что период поступления данных определяется внешними по отношению к процессору факторами, например скоростью движения носителя информации или периодом выборки значений какой-либо функции в реальном масштабе времени, если ЭВМ занимается сбором и обработкой информации. Необходимость в скоростном обмене большими объемами информации возникает также при работе микроЭВМ с контроллерами видеосистем. Кроме того, в простейших микроЭВМ иногда возникает необходимость начальной загрузки программ в ОП из ПУ.
Для получения максимальной скорости обмена желательно, чтобы ПУ через контроллер ПДП имело непосредственную связь с ОП микроЭВМ, т.е. имело бы специальную магистраль. Однако такое решение существенно усложняет и удорожает микроЭВМ, особенно при подключении нескольких ПУ. В большинстве микроЭВМ для реализации обмена в режиме ПДП используются шины системной магистрали. Именно этот вариант и рассматривается ниже. При этом возникает проблема совместного использования шин системного интерфейса процессором и контроллером ПДП, которая имеет два основных способа решения – ПДП с захватом цикла и ПДП с блокировкой процессора.
ЗАЩИТА ОТДЕЛЬНЫХ ЯЧЕЕК ПАМЯТИ
В небольших управляющих вычислительных устройствах, работающих, например, в составе АСУ ТП, необходимо обеспечить возможность отладки новых программ параллельно с функционированием находящихся в памяти рабочих программ, управляющих технологическим процессом. Этого можно достичь выделением в каждой ячейке памяти специального разряда защиты. Установка 1 в этот разряд запрещает производить запись в данную ячейку. Это так называемый метод контрольного разряда.
В системах с мультипрограммной обработкой и сегментацией памяти защищают не отдельные ячейки, а области памяти или блоки, на которые делится память. При этом часто предусматривают возможность указывать для различных программ различные допустимые режимы обращения к отдельным областям или блокам памяти (сегментам).
ЗАЩИТА ПАМЯТИ
Если в памяти одновременно могут находиться несколько независимых программ, необходимы специальные меры по предотвращению или ограничению обращений одной программы к областям памяти, используемым другими программами. Аналогичная проблема возникает и при выполнении отдельных модулей больших программ. Причинами несанкционированного обращения к чужим зонам памяти могут быть внезапное прекращение выполнения процессором программы в результате сбоя в аппаратуре ЭВМ, вхождение в бесконечный командный цикл, ошибки в пользовательской программе, особенно при ее отладке. Последствия таких сбоев в нормально функционирующих ЭВМ особенно опасны, если разрушению подвергаются программы операционной системы, поскольку после этого вычислительная система может начать вести себя непредсказуемо.
Для того, чтобы воспрепятствовать разрушению одних программ другими, достаточно защитить область памяти данной программы от попыток записи в нее со стороны других программ, а в некоторых случаях и своей программы (защита от записи). При этом допускается обращение других программ к этой области памяти для считывания данных.
В других случаях, например, при ограничениях на доступ к информации, хранящейся в системе, необходимо иметь возможность запрещать другим программам производить как запись, так и считывание в данной области памяти. Такая защита от записи и считывания помогает отладке программы. При этом осуществляется контроль каждого случая выхода за область памяти своей программы.
Для облегчения отладки программ желательно выявлять и такие характерные ошибки в программах, как попытки использования данных вместо команд (или наоборот) в собственной программе, хотя эти ошибки могут и не разрушать информацию.
Можно выделить следующие варианты дифференцированной защиты при различных операциях с памятью:
Задается отношение к области памяти чужой программы, определяющее, относится защита памяти только к операции записи или к любому обращению
в память.
Задается одно из следующих отношений к области памяти собственной программы:
- разрешается доступ к данному блоку как для записи, так и для считывания;
- разрешается только считывание;
- разрешается обращение любого вида, но по адресу, взятому только из счетчика команд;
- разрешается обращение по адресу из любого регистра, кроме счетчика команд.
Если нарушается защита памяти, исполнение программы приостанавливается и вырабатывается запрос прерывания по нарушению защиты памяти.
Защита от вторжения программы в чужие области памяти может быть организована различным образом. При этом реализация защиты не должна заметно снижать производительность процессора и требовать слишком больших аппаратных затрат. Рассмотрим наиболее распространенные способы реализации защиты памяти.
