Аннотация.
Контрактные спецификации в форме пред- и постусловий широко используются в программной инженерии для формального описания интерфейсов программных компонентов. Такие спецификации, с одной стороны, удобны для разработчиков, поскольку хорошо привязываются к архитектуре системы, с другой стороны, на их основе можно автоматически генерировать тестовые оракулы, проверяющие соответствие поведения целевой системы требованиям, описанным в спецификациях. В работе предлагается использовать контрактные спецификации для автоматизации функционального тестирования моделей аппаратного обеспечения, разработанных на таких языках, как VHDL, Verilog, SystemC, SystemVerilog и др. В статье подробно описаны особенности спецификации аппаратного обеспечения, приводится сравнение предлагаемого подхода с существующими методами спецификации, применяемыми в тестировании аппаратуры. В качестве базового подхода используется технология тестирования UniTESK, разработанная в Институте системного программирования РАН.
Архитектура тестовой системы UniTESK
Архитектура тестовой системы UniTESK [] была разработана на основе многолетнего опыта тестирования промышленного программного обеспечения из разных предметных областей и разной степени сложности. Учет этого опыта позволил создать гибкую архитектуру, основанную на следующем разделении задачи тестирования на подзадачи: построение тестовой последовательности, нацеленной на достижение нужного покрытия; создание единичного тестового воздействия в рамках тестовой последовательности; установление связи между тестовой системой и реализацией целевой системы; проверка правильности поведения целевой системы в ответ на единичное тестовое воздействие.
Для решения каждой из этих подзадач предусмотрены специальные компоненты тестовой системы (Рис. 3): для построения тестовой последовательности и создания единичных тестовых воздействий - обходчик и итератор тестовых воздействий; для проверки правильности поведения целевой системы - тестовый оракул; для установления связи между тестовой системой и реализацией целевой системы - медиатор. Рассмотрим подробнее каждый из указанных компонентов.

Рис. 3.Архитектура тестовой системы UniTESK.
Обходчик является библиотечным компонентом тестовой системы UniTESK и предназначен вместе с итератором тестовых воздействий для построения тестовой последовательности. В основе обходчика лежит алгоритм обхода графа состояний обобщенной конечно-автоматной модели целевой системы (конечного автомата, моделирующего целевую систему на некотором уровне абстракции). Обходчики, реализованные в библиотеках инструментов UniTESK, требуют, чтобы обобщенная конечно-автоматная модель целевой системы, была детерминированной и имела сильно-связный граф состояний.
Итератор тестовых воздействий работает под управлением обходчика и предназначен для перебора в каждом достижимом состоянии конечного автомата допустимых тестовых воздействий. Итератор тестовых воздействий автоматически генерируется из тестового сценария, представляющего собой неявное описание обобщенной конечно-автоматной модели целевой системы.
Тестовый оракул оценивает правильность поведения целевой системы в ответ на единичное тестовое воздействие. Он автоматически генерируется на основе формальных спецификаций, описывающих требования к целевой системе в виде пред- и постусловий интерфейсных операций и инвариантов типов данных.
Медиатор связывает абстрактные формальные спецификации, описывающие требования к целевой системе, с конкретной реализацией целевой системы. Медиатор преобразует единичное тестовое воздействие из спецификационного представления в реализационное, а полученную в ответ реакцию - из реализационного представления в спецификационное. Также медиатор синхронизирует состояние спецификации с состоянием целевой системы.
Трасса теста отражает события, происходящие в процессе тестирования. На основе трассы можно автоматически генерировать различные отчеты, помогающие анализировать результаты тестирования.
Инструмент разработки тестов CTESK
Инструмент CTESK [], который используется в описываемой работе, является реализацией концепции UniTESK для языка программирования C. Для разработки компонентов тестовой системы в нем используется язык SeC (specification extension of C), являющийся расширением ANSI C. Инструмент CTESK включает в себя транслятор из языка SeC в C, библиотеку поддержки тестовой системы, библиотеку спецификационных типов и генераторы отчетов.
Компоненты тестовой системы UniTESK реализуются в инструменте CTESK с помощью специальных функций языка SeC, к которым относятся: спецификационные функции - содержат спецификацию непосредственной реакции целевой системы в ответ на единичное тестовое воздействие, а также определение структуры тестового покрытия; функции отложенных реакций - содержат спецификацию отложенных реакций целевой системы; медиаторные функции - связывают спецификационные функции с тестовыми воздействиями на целевую систему, а также реакции целевой системы с функциями отложенных реакций; функция вычисления обобщенного состояния - вычисляет состояние обобщенной конечно-автоматной модели целевой системы; сценарные функции - описывают набор тестовых воздействий для каждого достижимого обобщенного состояния.
В работах [, ] подробно описано, как базовая архитектура тестовой системы UniTESK может быть расширена для функционального тестирования моделей аппаратного обеспечения, разработанных на языках Verilog и SystemC. Там же приводятся технические детали, связанные с использованием инструмента CTESK для функционального тестирования таких моделей.
Использование CTESK для спецификации аппаратуры
Инструмент разработки тестов CTESK предоставляет достаточно универсальные средства для спецификации систем с асинхронным интерфейсом []. Эти средства были адаптированы для спецификации модулей аппаратного обеспечения. Рассмотрим подробнее процесс разработки спецификаций.
Для каждой операции, реализуемой модулем, пишется спецификационная функция, в которой определяется предусловие операции и структура тестового покрытия. Постусловие спецификационной функции обычно возвращает true, поскольку все проверки, как правило, определяются в постусловиях микроопераций: // спецификация операции specification void operation_spec(...) { // предусловие операции pre { ... } // определение структуры тестового покрытия coverage C { ... } // постусловие операции обычно возвращает true post { return true; } }
Для каждой микрооперации, входящей в состав специфицируемой операции, пишется функция отложенной реакции, в которой определяется ее постусловие: // спецификация микрооперации reaction Operation* micro_return(void) { // постусловие микрооперации\ post { ... } }
Далее определяется функция временнóй композиции микроопераций, которая, во-первых, добавляет стимул (операцию вместе с набором аргументов) в очередь стимулов с указанием времени, необходимого для обработки стимула (time), во-вторых, для каждой микрооперации добавляет соответствующую реакцию в очередь реакций с указанием номера такта (относительно текущего времени), в конце которого следует осуществить проверку реакции (ticki): // временная композиция микроопераций void operation_time_comp(...) { Operation *descriptor = create_operation(...); // добавление стимула в очередь стимулов register_stimulus(create_stimulus(time, descriptor))); // добавление реакций в очередь реакций register_reaction(micro1_return, tick1, descriptor); ... register_reaction(micron_return, tickn, descriptor); }
Очередь стимулов содержит стимулы, обрабатываемые модулем в текущее время. Для каждого стимула в очереди хранится время, которое он уже обрабатывается.
Очередь реакций содержит еще не завершенные микрооперации. Для каждой микрооперации хранится время, через которое микрооперация завершится и можно будет осуществить проверку реакции. Изменение времени осуществляется функцией сдвига времени. После изменения времени вызываются функции обработки очередей стимулов и реакций. Функция обработки очереди стимулов удаляет из очереди полностью обработанные стимулы. Функция обработки очереди реакций регистрирует отложенные реакции для всех завершившихся микроопераций, которые после этого удаляются из очереди. Для иллюстрации синтаксиса языка SeC приведем очень простой пример. Рассмотрим устройство, называемое 8-ми битным счетчиком (Рис. 4).

Литература
| 1.обратно | Statistical Analysis of Floating Point Flaw in the Pentium Processor. Intel Corporation, November 1994. |
| 2.обратно | B. Beizer. The Pentium Bug - An Industry Watershed. Testing Techniques Newsletter (TTN), TTN Online Edition, September 1995. |
| 3.обратно | А. Wolfe. For Intel, It's a Case of FPU All Over Again. EE Times, May 1997. |
| 4.обратно | B. Meyer. Design by Contract. Technical Report TR-EI-12/CO, Interactive Software Engineering Inc., 1986. |
| 5.обратно | B. Meyer. Applying `Design by Contract'. IEEE Computer, vol. 25, No. 10, October 1992. |
| 6.обратно | |
| 7.обратно | IEEE Standard VHDL Language Reference Manual. IEEE Std 1076-1987. |
| 8.обратно | IEEE Standard Hardware Description Language Based on the Verilog Hardware Description Language. IEEE Std 1364-1995. |
| 9.обратно | |
| 10.обратно | |
| 11.обратно | |
| 12.обратно | |
| 13.обратно | I. Bourdonov, A. Kossatchev, V. Kuliamin, and A. Petrenko. UniTesK Test Suite Architecture. FME'2002. LNCS 2391, Springer-Verlag, 2002. |
| 14.обратно | |
| 15.обратно | A. Kamkin. The UniTESK Approach to Specification-Based Validation of Hardware Designs. IEEE-ISoLA'2006: The 2nd International Symposium on Leveraging Applications of Formal Methods, Verification and Validation, November 2006. |
| 16.обратно | |
| 17.обратно | S.A. Edwards. Design and Verification Languages. Technical Report, Columbia University, New York, USA, November 2004. |
| 18.обратно | R. Armoni, L. Fix, A. Flaisher, R. Gerth, B. Ginsburg, T. Kanza, A. Landver, S. Mador-Haim, E. Singerman, A. Tiemeyer, M. Vardi, and Y. Zbar. The ForSpec Temporal Logic: A New Temporal Property-Specification Language. Tools and Algorithms for Construction and Analysis of Systems, 2002. |
| 19.обратно | I. Beer, S. Ben-David, C. Eisner, D. Fisman, A. Gringauze, and Y. Rodeh. The Temporal Logic Sugar. Lecture Notes in Computer Science, 2001. |
| 20.обратно | |
| 21.обратно | OpenVera® Language Reference Manual: Assertions. Version 1.4.1, November 2004. |
| 22.обратно | |
| 23.обратно | |
| 24.обратно | MIPS64™ Architecture For Programmers. Revision 2.0. MIPS Tecnologies Inc., June 9, 2003. |
| 1(к тексту) | Pentium - торговая марка нескольких поколений микропроцессоров семейства x86, выпускаемых компанией Intel с 22 марта 1993 года. |
| 2(к тексту) | Именно такие модели являются предметом исследования настоящей работы. |
| 3(к тексту) | Число транзисторов в современных микросхемах достигает сотней миллионов. Согласно закону Мура (Moore) это число возрастает примерно вдвое через каждые 18-24 месяцев. |
| 4(к тексту) | Мы не рассматриваем здесь разного рода неопределенные значения, часто используемые в моделировании аппаратного обеспечения. |
| 5(к тексту) | В дальнейшем будем называть такие процессы модельными процессами, чтобы отличать их от процессов операционной системы. |
| 6(к тексту) | В начале симуляции активными являются процессы, осуществляющие инициализацию. |
| 7(к тексту) | Для наглядности мы не вводим модель данных и не уточняем сигнатуры пред- и постусловий. |
| 8(к тексту) | Исключение составляет обходчик ndfsm [], позволяющий обходить графы состояний для некоторого класса недетерминированных конечных автоматов. |
| 9(к тексту) | Вариант логики LTL, используемой в ForSpec, называется FTL (ForSpec temporal logic) []. |
| 10(к тексту) | При подсчете числа входов и выходов не учитывался интерфейс JTAG (joint test action group) - стандартный интерфейс, используемый для тестирования аппаратуры с помощью метода граничного сканирования. |
Mодели аппаратного обеспечения
Перед тем как описывать предлагаемый подход, рассмотрим особенности моделей аппаратного обеспечения на таких языках, как VHDL [], Verilog [], SystemC [], SystemVerilog [] и др. Знание этих особенностей позволяет адекватно адаптировать контрактные спецификации в форме пред- и постусловий для функционального тестирования моделей аппаратного обеспечения.
Опыт практического применения подхода
Предлагаемый подход был применен на практике при тестировании буфера трансляции адресов (TLB, translation lookaside buffer) микропроцессора c MIPS64-совместимой архитектурой [, ].
Буфер трансляции адресов, входящий в состав большинства современных микропроцессоров, предназначен для кэширования таблицы страниц - таблицы операционной системы, хранящей соответствие между номерами виртуальных и физических страниц памяти. Использование такого буфера позволяет значительно увеличить скорость трансляции адресов. Буфер представляет собой ассоциативную память с фиксированным числом записей. Помимо интерфейса для трансляции адресов, он предоставляет интерфейс для чтения и изменения содержимого этой памяти.
Трансляция виртуального адреса осуществляется следующим образом. Если буфер содержит запись с нужным номером виртуальной страницы, в выходном регистре модуля формируется соответствующий физический адрес; в противном случае, на одном из выходов модуля устанавливается сигнал, говорящий об отсутствии в буфере требуемой записи.
Особенности моделей аппаратного обеспечения
Модели аппаратного обеспечения представляют собой системы из нескольких взаимодействующих модулей. Как и в языках программирования, модули используются для декомпозиции сложной системы на множество независимых или слабо связанных подсистем. У каждого модуля имеется интерфейс - набор входов и выходов, через которые осуществляется соединение модуля с окружением, и реализация, определяющая способ обработки модулем входных сигналов: вычисление значений выходных сигналов и изменение внутреннего состояния.
Обработка модулем входных сигналов инициируется событиями со стороны окружения. Под событиями в моделях аппаратного обеспечения понимаются любые изменения уровней сигналов. Поскольку обычно рассматриваются двоичные сигналы, выделяются два основных вида событий: фронт сигнала (posedge, positive edge) - изменение уровня сигнала с низкого на высокий - и срез сигнала (negedge, negative edge) - изменение уровня сигнала с высокого на низкий .
Как правило, каждый модуль состоит из нескольких статически созданных параллельных процессов , каждый из которых реализует следующий цикл: сначала осуществляется ожидание одного или нескольких событий из заданного набора событий, затем производится их обработка, после чего цикл повторяется. Набор событий, ожидаемых процессом для обработки, называется списком чувствительности (sensitive list) процесса. Будем называть процесс пассивным, если он находится в состоянии ожидания событий, и активным в противном случае.
Важной особенностью моделей аппаратного обеспечения является наличие в них понятия времени. Время моделируется целочисленной величиной; можно задавать физический смысл единицы времени. Для описания причинно-следственных отношений между событиями, происходящими в одну единицу модельного времени используется понятие дельта-задержки (delta delay). События, между которыми есть дельта-задержка, выполняются последовательно одно за другим, но в одну и ту же единицу модельного времени.
Для выполнения моделей аппаратного обеспечения с целью анализа их поведения обычно используется симуляция по событиям (event-driven simulation).
В отличие от симуляции по интервалам времени (time-driven simulation), в которой значения сигналов и внутренние состояния модулей вычисляются через регулярные интервалы времени, в этом способе модель рассматривается только в те моменты времени, когда происходят некоторые события. Работа событийного симулятора (event-driven simulator) состоит в следующем. В начале симуляции модельное время устанавливается в ноль. Далее в цикле, пока есть активные процессы , выбирается один из них и выполняется до тех пор, пока он не станет пассивным. После того как выполнены все активные процессы, симулятор проверяет, есть ли события, запланированные на текущий момент времени через дельта-задержку или на будущие моменты времени. Если такие события есть, симулятор изменяет модельное время на время ближайшего события, реализует события, запланированные на этот момент времени, перевычисляет множество активных процессов, после чего цикл повторяется. Если таких событий нет, симуляция заканчивается.
Проверка требований
После того как требования к модулю формализованы, проверка поведения модуля на соответствие им может осуществляться в процессе тестирования автоматически.
Предположим, что в некоторый момент времени t тестируемый модуль выполняет m операций f1, …, fm, которые были поданы на выполнение раньше на τ1, …, τm соответственно (τi≥ 1, i=1, …, m). Пусть C1, …, Cm - контракты операций f1, …, fm соответственно, и в моменты подачи операций f1, …, fm были выполнены предусловия preC1, …, preCm; тогда для проверки правильности поведения модуля в момент времени t необходимо проверить выполнимость предиката PostC1(τ1)
Понятно, что для проверки соответствия поведения модуля требованиям также важно уметь строить хорошие тестовые последовательности, но рассмотрение этого вопроса выходит за рамки данной работы.
Разработка спецификаций модуля
Основные требования к буферу трансляции адресов были получены в письменной форме от разработчиков модуля. В процессе формализации требования уточнялись в результате общения с разработчиками и чтения технической документации. Следует отметить, что все сформулированные разработчиками требования были легко представлены в форме пред- и постусловий.
Проект продемонстрировал удобство и сравнительно небольшую трудоемкость разработки контрактных спецификаций для моделей аппаратного обеспечения. Спецификации были разработаны одним человеком за ≈2 недели, а их объем составил ≈2 500 строк кода на SeC. Отметим также, что в результате проекта было найдено несколько ошибок в реализации модуля.
Спецификация и проверка требований
Как отмечалось во введении, для возможности автоматизации проверки соответствия поведения системы требованиям они должны быть представлены в форме, допускающей автоматическую обработку. Такая форма представления требований называется формальными спецификациями или просто спецификациями. Рассмотрим разновидности требований к аппаратному обеспечению.
Спецификация требований
Предлагаемый подход к представлению требований основан на использовании контрактных спецификаций в форме пред- и постусловий. В отличие от классического Design-by-Contract, когда контракты определяются на уровне операций, мы предлагаем определять контракты для отдельных микроопераций, а контракт для операции в целом получать путем временнóй композиции контрактов отдельных микроопераций (Рис. 2.).
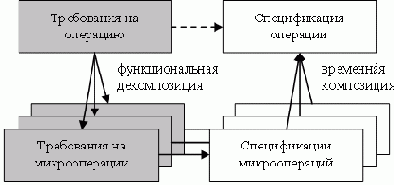
Рис. 2.Построение спецификации отдельной операции.
Здесь под микрооперациями мы понимаем некоторым образом выделенные аспекты функциональности операций, реализуемые за один такт работы модуля, а под временнóй композицией контрактов - спецификацию, в которой для каждой микрооперации указан номер такта, в конце которого должен выполняться соответствующий контракт.
В общих чертах процесс спецификации требований к отдельной операции состоит в следующем. Определяется предусловие, ограничивающее ситуации, в которых операцию можно подавать на выполнение. На основе анализа документации производится функциональная декомпозиция операции на набор микроопераций. Для каждой микрооперации определяется постусловие, описывающее требования к ней. После этого производится временнáя композиция спецификаций - постусловие каждой микрооперации помечается номером такта, в конце которого оно должно быть выполнено. Таким образом, контракт операции f, для которой выделено n микроопераций, формализуется структурой C=(pre, {(posti, τi)i=1,n}) .
Для контракта С=(pre, {(posti, τi)i=1,n}) введем следующие обозначения. Через preC будем обозначать предусловие операции (pre), через postC,i - постусловие i-ой микрооперации (posti), через τC,i - номер такта, в конце которого должно выполняться постусловие i-ой микрооперации (τi), через PostC(τ) - конъюнкцию постусловий микроопераций, помеченных тактом τ, то есть
Сравнение с существующими подходами
В данном разделе приводится сравнение предлагаемого подхода с существующими методами спецификации аппаратуры, поддерживаемыми современными языками верификации аппаратуры (HVL, hardware verification languages). Языки верификации аппаратуры, к которым относятся PSL, OpenVera, SystemVerilog и др. [], включают в себя конструкции языков описания аппаратуры, языков программирования, а также специальные средства, ориентированные на разработку спецификаций и тестов. К последним относятся средства спецификации поведения, определения структуры тестового покрытия и генерации тестовых данных. Мы сравниваем только способы спецификации.
Средства спецификации поведения, используемые в современных языках верификации аппаратуры, базируются на темпоральной логике линейного времени (LTL, linear temporal logic) и/или темпоральной логике ветвящегося времени (CTL, computation tree logic) []. Языки, по крайней мере, по части спецификации, имеют следующие корни: ForSpec (Intel) [] (для языков, использующих логику LTL ) и Sugar (IBM) [] (для языков, использующих логику CTL). Ниже приведена диаграмма, показывающая влияние некоторых языков верификации аппаратуры друг на друга.
Логика CTL используется преимущественно для формальной верификации систем. Для целей симуляции и тестирования больший интерес представляет логика линейного времени LTL. Поскольку все языки верификации аппаратуры, в которых используется LTL, имеют схожие средства спецификации, для сравнения с предлагаемым подходом мы будем использовать только один из них - OpenVera []. Данный язык поддерживается многими инструментами; кроме того, он является открытым.

Рис. 5. Влияние языков верификации аппаратуры друг на друга.
Язык OpenVera был разработан в 1995 году компанией Systems Science. Первоначальное название языка - Vera. В 1998 году System Science была поглощена компанией Synopsys. В 2001 году Synopsys сделала язык открытым и переименовала его в OpenVera. Для спецификации поведения OpenVera предоставляет специальный язык формулирования темпоральных утверждений (temporal assertions), который называется OVA (OpenVera assertions) [, ].
OVA оперирует с ограниченными по времени последовательностями событий, в которых можно обращаться к прошлому и будущему.
Из простых последовательностей можно строить более сложные с помощью логических связок, таких как AND и OR, или используя регулярные выражения. В языке имеются средства объединения темпоральных утверждений в параметризованные библиотеки спецификаций. Проиллюстрируем синтаксис OVA на простом примере.
// тактовый сигнал clock negedge(clk) { // граничные значения счетчика bool cnt_00: (cnt == 8'h00); bool cnt_ff: (cnt == 8'hff);
// событие переполнения счетчика event e_overflow: cnt_ff #1 cnt_00; }
// утверждение, запрещающее переполнение счетчика assert a_overflow: forbid(e_overflow);
В примере определяется событие переполнения счетчика e_overflow, а утверждение a_overflow запрещает возникновение такого события. В подходе OpenVera, как и в других подходах на основе темпоральных логик, упор делается на временнýю декомпозицию операций. Для каждой операции сначала выделяется ее временнáя структура - допустимые последовательности событий и задержки между ними; затем определяются предикаты, описывающие отдельные события; после этого предикаты, относящиеся к одному моменту времени, некоторым образом группируются (Рис. 6).

Структура и функциональность модуля
Рассмотрим устройство тестируемого модуля. Память TLB состоит из 64 ячеек, которые составляют объединенный TLB (JTLB, joint TLB). Кроме того, для повышения производительности модуль содержит дополнительные буферы: TLB данных (DTLB, data TLB) и TLB инструкций (ITLB, instruction TLB). DTLB используется при трансляции адресов данных, ITLB - при трансляции адресов инструкций. Оба буфера содержат по 4 ячейки, содержимое буферов является подмножеством JTLB, обновление происходит по алгоритму LRU (last recently used).
Каждая ячейка TLB условно делится на две секции: секция-ключ и секция-значение. Секция-ключ включает в себя спецификатор сегмента памяти (R), номер виртуальной страницы, деленный на два (VPN2), идентификатор процесса (ASID), бит глобальной трансляции адресов (G) и маску страницы (MASK). Секция-значение состоит из двух подсекций, каждая из которых содержит номер физической страницы (PFNi), бит разрешения чтения (Vi), бит разрешения записи (Di) и политику кэширования страницы (Ci). Какая именно подсекция будет использована при трансляции адреса, определяется младшим битом номера виртуальной страницы.
Интерфейс тестируемого модуля TLB состоит из 30 входов (16 входов общего назначения, 3 входа DTLB, 4 входа ITLB, 7 входов JTLB) и 31 выходов (6 выходов общего назначения, 9 выходов DTLB, 8 выходов ITLB, 8 выходов JTLB) . Функциональность модуля включает операции записи, чтения и проверки наличия ячейки в памяти, а также операции трансляции адресов данных и инструкций. RTL-модель модуля разработана на языке Verilog и составляет ≈ 8 000 строк кода.

Рис. 7.Структура ячейки буфера трансляции адресов.
Технология тестирования UniTESK
В качестве базового подхода в работе используется технология тестирования UniTESK [], разработанная в Институте системного программирования РАН []. Характерными чертами технологии являются использование контрактных спецификаций в форме пред- и постусловий интерфейсных операций и инвариантов типов данных для спецификации требований, а также применение обобщенных конечно-автоматных моделей для построения тестовых последовательностей.
Типичная организация модулей аппаратного обеспечения
В дальнейшем будем считать, что спецификация и тестирование моделей аппаратного обеспечения осуществляется на уровне отдельных модулей.
В типичном случае работа модуля аппаратного обеспечения управляется сигналом тактового импульса, который для краткости будем называть тактовым сигналом или просто часами. Фронты (или срезы) тактового сигнала разбивают непрерывное время на дискретный набор интервалов, называемых тактами. Поведение модуля на текущем такте определяется значениями входных сигналов и внутренним состоянием модуля. Как правило, часть входов модуля определяет операцию, которую модулю следует выполнить; такие входы будем называть управляющими (control). Другая часть входов определяет аргументы операции; такие входы будем называть информационными (informative). Среди операций, реализуемых модулем, обычно присутствует специальная операция NOP (no operation), означающая бездействие модуля.
Модули аппаратного обеспечения могут быть организованы разными способами. В соответствии с длительностью операций, выполняемых модулем, эти операции бывают однотактными и многотактными. По способу организации выполнения операций модули делятся на модули с поочередным выполнением операций, модули с конвейерным выполнением операций и модули с параллельным выполнением операций.
Рассмотрим, как осуществляется выполнение модулем однотактной операции. До начала очередного такта окружение устанавливает на соответствующих входах модуля код операции и аргументы. Выполнение операции начинается модулем с началом такта. За этот такт модуль производит необходимые вычисления, изменяет внутреннее состояние и устанавливает значения выходных сигналов, которые окружение может использовать, начиная со следующего такта (Рис. 1).

Рис. 1.Временнáя диаграмма сигналов для однотактной операции.
В отличие от однотактной операции, результат многотактной операции вычисляется постепенно, такт за тактом. Пусть операция f выполняется модулем за n тактов, тогда на каждом такте τ
Представление многотактовой операции f в виде последовательности микроопераций (f1, …, fn) будем называть временнó й декомпозицией f. Теперь несколько слов о способах организации выполнения операций. В модулях с поочередным выполнением операций, как видно из названия, очередную операцию можно подавать на выполнение только после того, как полностью завершена предыдущая. В модулях с конвейерным выполнением операций операции можно подавать последовательно друг за другом, не дожидаясь завершения предыдущей операции. В модулях с параллельным выполнением операций несколько операций можно подавать одновременно. Модули с поочередным и конвейерным выполнением операций объединим общим термином - модули с последовательным выполнением операций, поскольку и в том, и в другом случае операции подаются на выполнение последовательно одна за другой. В дальнейшем будем считать, что модули организованы таким образом, что одновременно выполняемые операции не вступают в конфликты (hazards), то есть не влияют друг на друга. Если взаимное влияние все-таки возможно, требования должны описывать, как подавать операции на выполнение, чтобы избежать возникновения конфликтов.
Требования к модулям аппаратного обеспечения
В общем случае операции являются многотактными, то есть выполняются модулем за несколько тактов. Требования на такие операции бывают двух основных типов: требования на операцию в целом, которые не накладывают ограничений на то, на каком именно такте выполняется та или иная микрооперация, и требования на временнýю композицию операции, в которых фиксируется, на каких тактах выполняются конкретные микрооперации.
Требования на операцию в целом допускают определенную свободу в реализации модуля. Не важно, на каком такте выполняется некоторая микрооперация, важно, чтобы после завершения всей операции результат этой микрооперации был доступен окружению. В процессе тестирования требования на операцию в целом проверяются после завершения операции.
Требования на временнýю композицию операции являются более жесткими. В них указаны такты, на которых выполняются микрооперации. Обычно при тестировании имеет смысл проверять не то, что микрооперация была выполнена на определенном такте τ0, а то, что в конце этого такта соответствующим выходам модуля были присвоены требуемые значения, неважно на каком именно такте τ
При такой трактовке требования на операцию в целом являются частным случаем требований на временнýю композицию; поэтому в дальнейшем мы не будем различать эти типы требований - просто будем считать, что каждому требованию соответствует номер такта, в конце которого его следует проверять.
Современный мир не мыслим без
Современный мир не мыслим без огромного разнообразия электронных устройств. Мобильные телефоны, цифровые фотокамеры и переносные компьютеры давно стали неотъемлемыми атрибутами жизни человека. Специальные устройства управляют работой бытовой техники, контролируют бортовые системы самолетов и космических спутников, управляют медицинскими системами жизнеобеспечения. В основе практически всех этих систем лежит полупроводниковая аппаратура - кристаллы интегральных схем, состоящие из миллионов связанных друг с другом микроскопических транзисторов, которые, пропуская через себя электрические токи, реализуют требуемые функции. Чтобы убедиться, что аппаратура работает правильно, то есть реализует именно те функции, которые от нее ожидают пользователи, на практике используют функциональное тестирование. Требования, предъявляемые к качеству тестирования аппаратного обеспечения, очень высоки. Это связано не только с тем, что аппаратура лежит в основе всех информационных и управляющих вычислительных систем, в том числе достаточно критичных к сбоям и ошибкам. Большое влияние на формирование высоких требований оказывают также экономические факторы. В отличие от программного обеспечения, в котором исправление ошибки стоит сравнительно дешево, ошибка в аппаратном обеспечении, обнаруженная несвоевременно, может потребовать перевыпуск и замену продукции, а это сопряжено с очень высокими затратами. Так, известная ошибка в реализации инструкции FDIV микропроцессора Pentium [], заключающаяся в неправильном делении некоторых чисел с плавающей точкой, обошлась компании Intel в 475 миллионов долларов [, ]. С другой стороны, требования к срокам тестирования также очень высоки. Важно не затягивать процесс и выпустить продукт на рынок своевременно, пока он не потерял актуальность, и на него существует спрос. Как разработать качественный продукт своевременно, используя ограниченные ресурсы? В настоящее время для проектирования аппаратного обеспечения используются языки моделирования высокого уровня, которые позволяют значительно ускорить процесс разработки за счет автоматической трансляции описания аппаратуры на уровне регистровых передач (RTL, register transfer level) в описание аппаратуры на уровне логических вентилей (gate level).
Такие языки называются языками описания аппаратуры (HDL, hardware description languages), а модели, построенные на их основе - HDL-моделями или RTL-моделями . Языки описания аппаратуры позволяют значительно повысить продуктивность разработки аппаратного обеспечения, но они не страхуют от всех ошибок, поэтому функциональное тестирование по-прежнему остается актуальной и востребованной задачей. При современной сложности аппаратного обеспечения невозможно разработать приемлемый набор тестов вручную за разумное время. Необходимы технологии автоматизированной разработки тестов. В настоящее время разработка таких технологий и поддерживающих их инструментов выделилась в отдельную ветвь автоматизации проектирования электроники (EDA, electronic design automation) - автоматизацию тестирования (testbench automation). Основной задачей тестирования является проверка соответствия поведения системы предъявляемым к ней требованиям. Для возможности автоматизации такой проверки требования к системе должны быть представлены в форме, допускающей автоматическую обработку. Такую форму представления требований называют формальными спецификациями или просто спецификациями. В работе рассматривается определенный вид спецификаций - контрактные спецификации (contract specifications). Контрактные спецификации и процесс проектирования на их основе (DbC, Design-by-Contract) были введены Бертраном Майером (Bertrand Meyer) в 1986 году в контексте разработки программного обеспечения [, ]. Центральная метафора подхода заимствована из бизнеса. Компоненты системы взаимодействуют друг с другом на основе взаимных обязательств (obligations) и выгод (benefits). Если компонент предоставляет окружению некоторую функциональность, он может наложить предусловие (precondition) на ее использование, которое определяет обязательство для клиентских компонентов и выгоду для него. Компонент также может гарантировать выполнение некоторого действия с помощью постусловия (postcondition), которое определяет обязательство для него и выгоду для клиентских компонентов. Почему в своих исследованиях мы выбрали именно контрактные спецификации? Контрактные спецификации, с одной стороны, достаточно удобны для разработчиков, поскольку хорошо привязываются к архитектуре системы, с другой стороны, в силу своего представления стимулируют усилия по созданию независимых от реализации критериев корректности целевой системы [].Основное же их преимущество состоит в том, что они позволяют автоматически строить тестовые оракулы, проверяющие соответствие поведения целевой системы требованиям, описанным в спецификациях. Несколько слов о том, как организована статья. Во втором, следующем за введением, разделе даются общие сведения о моделях аппаратного обеспечения и типичной организации аппаратуры. В третьем разделе описывается предлагаемый подход к спецификации и проверке требований к аппаратному обеспечению. Четвертый раздел содержит краткий обзор технологии тестирования UniTESK и инструмента разработки тестов CTESK. В нем также описан способ использования инструмента для спецификации аппаратуры. В пятом разделе приводится сравнение предлагаемого подхода с существующими методами спецификации аппаратного обеспечения. Шестой раздел описывает опыт практического применения подхода. Наконец, в последнем, седьмом разделе делается заключение и очерчиваются направления дальнейших исследований.
Изначально контрактные спецификации были предложены
Изначально контрактные спецификации были предложены для описания интерфейсов программных компонентов, но при определенной доработке их вполне можно использовать для описания модулей аппаратного обеспечения. Такие спецификации, с одной стороны, удобны для разработчиков, поскольку хорошо привязываются к архитектуре системы, с другой стороны, на их основе можно автоматически генерировать тестовые оракулы, проверяющие соответствие поведения целевой системы требованиям, описанным в спецификациях. Практическая апробация подхода в проекте по тестированию буфера трансляции адресов микропроцессора показала удобство представления требований к аппаратуре в форме пред- и постусловий и продемонстрировала сравнительно небольшую трудоемкость разработки спецификаций. На настоящий момент нами получен определенный опыт использования технологии тестирования UniTESK и инструмента CTESK для спецификации и тестирования моделей аппаратного обеспечения. Опыт показывает, что некоторые шаги разработки тестов могут быть полностью или частично автоматизированы. Детальное исследование этого вопроса и разработка инструментальной поддержки для автоматизации шагов разработки тестов является основным направлением дальнейшей работы.
Аннотация.
В статье излагается метод сокращения набора тестов для регрессионного тестирования, заключающийся в построении модели поведения программы на наборе тестов и последующей фильтрации тестового набора с помощью построенной модели. Модель поведения программы строится в терминах последовательностей системных вызовов, совершенных программой во время своего выполнения.
Экспериментальное исследование метода сокращения набора тестов
Целью проводимого эксперимента являлось определение и оценка параметров метода сокращения набора тестов, предложенного в данной работе, на модельных данных.
При анализе методов сокращения набора тестов важны следующие параметры: Степень сокращения набора. Это один из наиболее существенных параметров работы метода сокращения, так как этот параметр показывает, насколько сокращаются первоначальный набор тестов и связанные с ним затраты. Чем больше степень сокращения набора тестов, тем сильнее уменьшаются затраты на его выполнение, проверку и сопровождение, тем самым, сокращая затраты на проведение регрессионного тестирования в целом []. Уровень обнаружения ошибок. Основной проблемой при сокращении набора тестов является возможное уменьшение его уровня обнаружения ошибок вследствие удаления тестов, обнаруживающих ошибки []. Слишком большие потери в уровне обнаружения ошибок могут привести к нецелесообразности сокращения набора тестов. Поэтому важно, чтобы в результате работы метода его уровень обнаружения ошибок по возможности не уменьшался, а если и уменьшался, то незначительно.
Целью эксперимента являлось решение следующих задач:
определение величины сокращения исходного набора тестов; определение уровня обнаружения ошибок сокращенным набором тестов; сравнение уровня обнаружения ошибок сокращенным набором тестов с уровнем первоначального набора и уровнем, обеспечиваемым методом случайного сокращения набора тестов;
Литература
| 1.обратно | McMaster, S. and Memon, A. M. 2005. Call Stack Coverage for Test Suite Reduction. In Proceedings of the 21st IEEE international Conference on Software Maintenance (ICSM'05) - Volume 00 (September 25 - 30, 2005). ICSM. IEEE Computer Society, Washington, DC, 539-548. |
| 2.обратно | S.Forrest, S.A.Hofmeyr, A.Somayaji, and T.A.Longstaff. A Sense of Self for Unix Processes. In Proceedings of the 1996 IEEE Symposium on Research in Security and Privacy, Los Alamitos, CA, 1996. IEEE Computer Society Press. |
| 3.обратно | S.A.Hofmeyr, S.Forrest, and A.Somayaji. Intrusion Detection using Sequences of System Calls. Journal of Computer Security, 6:151-180, 1998. |
| 4.обратно | C. Warrender, S. Forrest, and B. Pearlmutter, Detecting Intrusions Using System Calls: Alternative Data Models. IEEE Symposium on Security and Privacy, Oakland, CA, 1999, IEEE Computer Society, pp. 133-145. |
| 5.обратно | Eleazar Eskin, Andrew Arnold, Mechael Prerau, Leonid Portnoy, Salvatore J. Stolfo. A Geometric Framework for Unsupervised Anomaly Detection: Detecting Intrusions in Unlabeled Data. Applications of Data Mining in Computer Security, Kluwer, 2002. |
| 6.обратно | Victor R. Basili and Richard W. Selby. Comparing the Effectiveness of Software Testing Strategies. IEEE Transactions on Software Engineering, SE-13(12):1278-1296, December 1987. |
| 7.обратно | E. Kamsties and C.M. Lott, An Emperical Evaluation of Three Defect-Detection Techniques, In: W. Schfer and P. Botella (eds.). Software Engineering - ESEC '95, Springer, 1995, pp. 362-383. |
| 8.обратно | M. Wood, M. Roper, A. Brooks, and J. Miller. Comparing and combining software defect detection techniques:a replicated empirical study. In H. S. Mehdi Jazayeri, editor, Proceedings of The Sixth European Software Engineering Conference, volume 1301, pages 262-277. Lecture Notes in Computer Science, September 1997. |
| 9.обратно | M. Grindal, B. Lindstrom, A.J. Offutt, and S.F. Andler. An Evaluation of Combination Strategies for Test Case Selection, Technical Report. Technical Report HS-IDA-TR-03-001, Department of Computer Science, University of Skovde, 2003. |
| 10.обратно | G. Rothermel, M. J. Harrold, J. von Ronne, and C. Hong. Empirical studies of test-suite reduction. Journal of Software Testing, Verification, and Reliability, V. 12, no. 4, December, 2002. |
| 11.обратно | X. Ma, Z. He, B. Sheng, C. Ye. A Genetic Algorithm for Test-Suite Reduction. 2005 IEEE International Conference on Systems, Man and Cybernetics. 10-12 Oct. 2005, Vol. 1, pp: 133- 139. |
| 12.обратно | J. A. Jones, M. J. Harrold. Test-Suite Reduction and Prioritization for Modified Condition/Decision Coverage. IEEE Transactions on Software Engineering, Vol. 29, No. 3, March, 2003, pp. 195-209. |
| 13.обратно | M. J. Harrold, R. Gupta, and M. L. Soffa. A methodology for controlling the size of a test suite. ACM Transactions on Software Engineering and Methodology, 2(3):270-285, July 1993. |
| 14.обратно | M. Hutchins, H. Foster, T. Goradia, and T. Ostrand. Experiments on the effectiveness of dataflow- and controlflow-based test adequacy criteria. In Proceedings of the 16th International Conference on Software Engineering, pages 191-200, May 1994. |
| 15.обратно | H. Zhu, P. A. V. Hall, and J. H. R. May. Software Unit Test Coverage and Adequacy. ACM Computing Surveys, Vol.29, No.4, pp.366-427, December 1997. |
| 16.обратно | Code Coverage Analysis. http://www.bullseye.com/coverage.html, 2002. |
| 17.обратно | V. Dallmeier. Detecting Failure-Related Anomalies in Method Call Sequences. Diploma Thesis, Universität des Saarlandes, March, 2005. |
| 1(к тексту) | Критерий покрытия ребер похож на критерий покрытия ветвлений (decision coverage), но сформулирован в терминах графа потока управления []. |
| 2(к тексту) | Хотя в данной работе рассматривается случай операционной системы семейства UNIX, в состав которой входит команда мониторинга системных вызовов, предлагаемый метод может быть распространен на любую операционную систему, имеющую аналогичные средства мониторинга. Например, метод также может применяться в операционных системах семейства Linux, где для сбора трасс системных вызовов существует команда strace. |
| 3(к тексту) | Команда ktrace предоставляет такую возможность. |
| 4(к тексту) | Исходный текст и документация к программе доступны на сайте в интернете по этому адресу |
Метод сокращения набора тестов
Идея предлагаемого метода сокращения набора тестов достаточно проста. Можно предположить, что при тестировании функциональности и структуры программы встречаются тесты, которые инициируют одни и те же последовательности системных вызовов. Метод основан на этом предположении и состоит в "отсеивании" тех тестов, которые не генерируют новые последовательности системных вызовов, то есть не инициируют нового поведения программы.
В предлагаемом методе сокращения набора тестов используется модель поведения программы, построенная в предыдущем разделе. Общий алгоритм работы метода выглядит следующим образом (см. Рис.2):
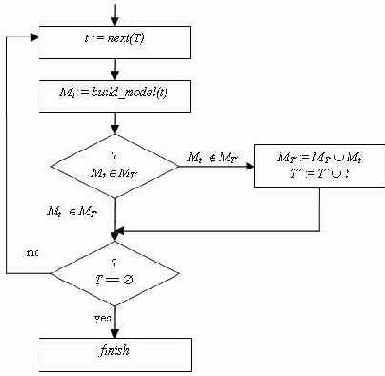
Рис.2Алгоритм работы метода.
Здесь T - первоначальный набор тестов;
T' - сокращенный набор тестов, T'
t - очередной тест из первоначального набора, t
Mt - модель поведения программы на тесте t;
MT' - множество моделей поведения программы на тестах из T'. На первом этапе выбирается очередной тест из сокращаемого набора тестов и на нем выполняется тестируемая программа. Во время выполнения программы строится модель Mt ее поведения на выбранном тесте t. На третьем этапе проверяется, входит ли модель Mt в множество моделей MT' или нет. Если модель Mt не входит в множество моделей MT', то она добавляется в множество MT', и тест t добавляется в сокращенный набор тестов T'. Если набор тестов T не исчерпан, то осуществляется переход к шагу 1, в противном случае сокращенный набор тестов T' считается построенным, и работа метода завершается.
Для того чтобы реализовать метод, необходимо предложить операцию сравнения моделей поведения программы. Такая операция должна показывать, когда модели поведения программы совпадают, а когда нет. Будем считать, что модели поведения программы равны, когда их множества последовательностей совпадают, и различны в противном случае. Тогда операция сравнения моделей будет сводиться к операции сравнения множеств последовательностей системных вызовов.
Надо заметить, что использование в предложенном методе множества последовательностей системных вызовов вместо трасс системных вызовов позволяет решить проблему циклов в тестируемой программе.
Данная проблема изначально возникла при оценке адекватности наборов тестов, основанной на анализе покрытия путей выполнения программы, и состоит в том, что если код программы содержит циклы, то количество различных путей выполнения программы может быть очень большим, что приводит к падению эффективности метода оценки и значительному увеличению затрат на его работу []. Аналогичная проблема возникает и в рассматриваемом методе, если в качестве модели поведения программы рассмотривать трассы системных вызовов. В этом случае, если системные вызовы встречаются внутри циклов программы, различное количество возможных повторений цикла может привести к очень большому количеству разных трасс программы. Такая ситуация может исказить результаты сокращения тестового набора, так как поведения программы, различающиеся только количеством выполненных циклов, будут приняты как различные, хотя фактически они не тестируют новую функциональность или структуру программы. Использование множества последовательностей системных вызовов решает эту проблему, так как, даже при произвольном количестве повторений цикла, множество уникальных поведений программы быстро стабилизируется, и модель перестает изменяться.
Модель поведения программы на тесте
В предлагаемом методе последовательности системных вызовов используются для построения модели поведения программы на тесте. Для начала введем несколько определений.
Трассой системных вызовов программы P для теста t будем называть последовательность системных вызовов, совершенных программой P при выполнении на входных данных тестового случая t. При этом будем подразумевать, что системные вызовы встречаются в трассе в порядке их вызова программой P .
Последовательностью системных вызовов длины K называется любая непрерывная подпоследовательность длины K, встречающаяся в трассе системных вызовов.
Множеством последовательностей системных вызовов длины K, соответствующим поведению программы P на тесте t, называется множество всех возможных последовательностей длины K, встречающихся в трассе системных вызовов программы P для теста t.
Для получения множества последовательностей системных вызовов фиксированной длины используется техника "скользящего окна" [] с размером K (размер окна соответствует длине выделяемых последовательностей). Согласно этому подходу, выделение последовательностей происходит следующим образом: в качестве первой последовательности из трассы выбираются K идущих подряд системных вызовов, начиная с первого вызова в трассе; в качестве второй последовательности выбираются K идущих подряд системных вызовов, начиная со второго вызова; и так далее, пока не будет пройдена вся трасса.
В качестве модели поведения программы P на тесте t принимается определенное выше множество последовательностей.
Рассмотрим пример построения модели поведения программы. Допустим, у нас есть следующая последовательность, состоящая из системных вызовов операционной системы UNIX: open write write open write close write close.
Тогда результатом выделения последовательностей с помощью скользящего окна размера 4 будет следующее множество последовательностей: open write write open write write open write write open write close open write close write write close write close
Полученное таким образом множество последовательностей будет являться моделью поведения программы.
Об одном методе сокращения набора тестов
Д.Ю. Кичигин, Труды Института системного программирования РАН
Описание метода
В этой работе рассматривается тестирование программного обеспечения, работающего под управлением операционной системы семейства UNIX. Предлагаемый метод основывается на построении моделей поведения программы на наборе тестов и последующем использовании их для сокращения набора тестов. Для построения модели поведения программы используются последовательности системных вызовов, выполненные программой во время своей работы. Для мониторинга выполнения системных вызовов используется команда ktrace, входящая в состав операционной системы . Метод не зависит от языка программирования, использованного для разработки тестируемого программного обеспечения, не требует доступа к исходному коду и не предполагает инструментирования кода программного обеспечения.
Проведение эксперимента и результаты
Так как стратегия генерации тестовых наборов оказывает косвенное влияние на исследуемый метод (вследствие того, что индивидуальные тесты выбираются из набора в порядке их следования, и, соответственно, в сокращенный набор тестов будет помещен первый тест, расширяющий множество моделей), то для достижения чистоты эксперимента тесты исходного набора были перенумерованы случайным образом.
После этого тестируемая программа была выполнена на каждом тесте из пула, и для каждого теста была построена модель выполнения программы. Затем из пула сгенерированных тестов методом случайной выборки было сформировано 35 исходных наборов тестов разного размера, начиная с 50 и заканчивая 1700 с шагом 50. В качестве последнего, 35-го набора был принят набор, содержащий все 1715 тестов из пула. Далее, из исходных наборов с помощью исследуемого метода были построены сокращенные наборы, для каждого из которых были вычислены параметры сокращения: размер сокращенных наборов и коэффициент сокращения. После этого были вычислены уровни обнаружения ошибок сокращенными наборами, и затем результаты были сравнены с уровнями исходных наборов и уровнями, получаемыми при использовании метода случайного сокращения. Для этого из исходных наборов методом случайной выборки были построены наборы такого же размера, как и сокращенные, и были вычислены их уровни обнаружения ошибок.
Результаты эксперимента
Результаты работы метода проиллюстрированы на Рис. 3 - 6:
Размер сокращенного набора находился в пределах от 12 до 24 тестов в зависимости от размера исходного набора. Величина сокращения находилась в пределах от 76% до 98.6% в процентном соотношении. По результатам видно, что размер сокращенного набора рос вместе с ростом размера исходного набора и в итоге стабилизировался. Это является закономерной картиной, если учесть, что множество различных путей выполнения программы конечно, и при увеличении числа тестов увеличивается вероятность выполнения всех путей программы.
На модельных данных уровень обнаружения ошибок для сокращенных наборов составил от 95.24% до 100% от уровня исходных наборов, т.е. величина падения уровня обнаружения ошибок для исследуемого метода составила менее 4.8%. Средняя величина падения уровня обнаружения ошибок для исследуемого метода составила 1.5%. При этом исследуемый метод проиграл методу случайного сокращения лишь в одном случае; в большинстве остальных случаев исследуемый метод показал выигрыш на 4.3% - 26%. В среднем сокращенные наборы, построенные с помощью исследуемого метода, при проведении эксперимента обнаруживали на 9.8% ошибок больше, чем соответствующие наборы, полученные с помощью метода случайного сокращения.
Системные вызовы как характеристика поведения программы
Системными вызовами (system call) называются функции, входящие в состав программного интерфейса операционной системы. Изначально последовательности системных вызовов были предложены в качестве характеристики поведения программы при решении задачи обнаружения вторжений [,,,] в области компьютерной безопасности. Последовательности системных вызовов также успешно использовались при поиске потенциальных ошибок в программном обеспечении []. При этом было отмечено, что последовательности системных вызовов, произведенных программой во время своего выполнения, являются достаточно информативной характеристикой выполнения программы и позволяют различать, когда выполнение программы идет по разным путям []. В данной работе это свойство последовательностей системных вызовов используется для анализа поведения программы на наборе тестов.
Мониторинг системных вызовов, вызываемых программой во время своего выполнения, осуществляется командой ktrace, входящей в пакет операционной системы. Результатом работы этой программы является трасса системных вызовов, выполненных программой во время своей работы. На Рис.1 приведен пример трассы для фрагмента программы.

Рис.1Представление поведения программы с помощью системных вызовов.
Существующие решения
Существующие методы сокращения набора тестов [,,,,] объединяет общий подход, который состоит в построении набора тестов меньшего размера, но при этом эквивалентного первоначальному набору в терминах выбранного покрытия кода программы. В результате полученный сокращенный набор тестов замещает собой первоначальный и используется для проведения регрессионного тестирования.
Существующие методы сокращения набора тестов в основном различаются видом используемого покрытия. В работе [] для сокращения набора тестов используется покрытие "всех использований" ("all-uses" coverage). Это покрытие является частным случаем покрытия ассоциаций вида определение-использование (definitions-use associations coverage), основанного на модели потока данных в программе []. Анализ этого покрытия основывается на изучении вхождений переменных в программу и рассмотрении путей выполнения программы от места определения переменной (variable definition) до места ее использования (variable use). В [] рассматривается метод сокращения наборов на основе покрытия ребер гипотетического графа потока управления программы. Для анализа покрытия ребер используется исходный код программы []. В работе [] для сокращения набора тестов используется покрытие MC/DC (Modified Condition/Decision Coverage). Покрытие MC/DC определяется в терминах языка программирования, используемого при написании программы, и является развитием покрытия условий (conditions coverage) []. В [] предлагается метод сокращения набора тестов, основанный на комбинации покрытия блоков программы и ассоциированных с выполнением теста ресурсозатрат. Блоком называется последовательность выражений программы, не содержащая ветвлений; таким образом, покрытие блоков эквивалентно покрытию выражений.
Общей особенностью перечисленных подходов является то, что для их применения необходим доступ и инструментирование исходного либо объектного кода программы, что подвергает эти методы указанным во введении ограничениям. Немного особняком стоит работа [], где авторы в качестве элементов покрытия используют стек вызовов функций программы (call stack) и указывают, что такой подход может применяться и без доступа к исходному коду программы. Однако в эксперименте, проведенном авторами этой работы, для мониторинга стека вызовов функций требуется знать сигнатуры внутренних функций программы, для получения которых используется доступ к исходному тексту программы. Поэтому, по крайней мере, пока также нельзя говорить, что данная методика применима в условиях указанных выше ограничений.
Условия проведения эксперимента: тестовые программы и тестовые наборы
Эксперимент проводился в операционной системе FreeBSD 5.3; для сбора трасс использовалась команда ktrace, входящая в состав операционной системы. Длина K используемых последовательностей составляла 15 системных вызовов.
Для проведения эксперимента в качестве объекта тестирования использовались программа nametbl, входящая в пакет программ, впервые предложенный в [] и впоследствии использовавшийся в [,,] для исследования методов оценки адекватности тестовых наборов. Программа nametbl считывает команды из файла и выполняет их с целью тестирования нескольких функций. Тестируемые функции реализуют работу с таблицей символов для некоторого языка программирования. Таблица символов хранит для каждого символа его имя и тип. Команды, считываемые из файла, позволяют добавить в таблицу новый символ, указать тип ранее введенного символа, осуществить поиск символа и распечатать таблицу символов. Общий объем исходного текста программы составляет 356 строк. Основной причиной выбора этой программы для проведения эксперимента послужило то, что ее исходные тексты и руководство по созданию наборов тестов находятся в открытом доступе , и, таким образом, описываемый эксперимент может быть повторен независимо.
Для построения тестов использовалось разбиение входных данных программы nametbl на домены, предложенное в работе []. В этой работе было предложено 4 "измерения" входных данных, в трех из которых было выделено 7 доменов, а в четвертом - 5 доменов. В данной работе было использовано это разбиение, в каждом домене было выбрано по одному значению, и в итоге был сгенерирован пул из 1715 разных тестов.
Для определения параметров метода были использованы следующие индикаторы:
размер сокращенного набора тестов; коэффициент сокращения набора тестов в процентном выражении:
100 × (1 - Sizereduced/Sizeinitial), где
Sizeinitial означает размер исходного набора тестов,
Sizereduced - размер сокращенного набора тестов; количество обнаруженных ошибок; коэффициент обнаружения ошибок в процентном выражении:
100 × (FaultsDetectedreduced/FaultsDetectedinitial), где
FaultsDetectedinitial означает количество ошибок, обнаруживаемых исходным набором тестов,
FaultsDetectedreduced - количество ошибок, обнаруживаемых сокращенным набором тестов.
Уровень обнаружения ошибок измерялся исходя из следующего принципа эквивалентности тестовых наборов: два набора тестов считаются эквивалентными при обнаружении некоторой ошибки, если каждый набор содержит по крайней мере один тест, обнаруживающий эту ошибку (в англоязычной литературе такой принцип носит название per-test-suite basis []). Такой подход применялся в работах [, ].
Темпы развития современного программного обеспечения
Темпы развития современного программного обеспечения и особенно увеличение количества вносимых в него модификаций приводят к увеличению затрат на проведение регрессионного тестирования. В связи с этим достаточно актуальной является проблема уменьшения стоимости регрессионного тестирования. Сокращение набора тестов [,,] является одним из способов уменьшения затрат на проведение регрессионного тестирования. Целью задачи сокращения набора тестов является создание набора тестов меньшего размера, но при этом, желательно, с таким же уровнем обнаружения ошибок []. Такое сокращение позволяет уменьшить затраты на сопровождение тестового набора и на выполнение на нем тестируемого программного обеспечения [], что, в свою очередь, позволяет сократить затраты на проведение регрессионного тестирования в целом. Традиционный подход к решению задачи сокращения набора тестов заключается в "отсеивании" тестов из первоначального набора таким образом, чтобы сохранялся уровень его адекватности в терминах некоторого выбранного критерия адекватности, и основывается на использовании статического анализа и/или инструментирования исходного текста программного обеспечения (ПО). При таком подходе решение задачи, как правило, состоит из трех основных этапов. На первом этапе происходит инструментирование кода тестируемого ПО и запуск ПО на наборе тестов. На втором этапе собирается информация о достигнутом покрытии кода. Наконец, на третьем этапе происходит сокращение набора тестов на основе собранной информации о покрытии []. Современные тенденции разработки программного обеспечения ставят новые условия для методов сокращения набора тестов и во многом ограничивают область применения существующих методов. Во-первых, растет популярность использования готовых программных компонентов. Такие компоненты, как правило, поставляются без исходного текста, что ограничивает применимость методов, основанных на анализе или инструментировании исходного кода программы []. Во-вторых, программное обеспечение зачастую разрабатывается с использованием разных языков программирования, что ограничивает доступность средств анализа и инструментирования исходного кода, так как многие из них ориентированы на работу с конкретным языком программирования [].
В третьих, возрастающая сложность современного программного обеспечения, особенно увеличение его модульности, делает неудобным и повышает затраты на использование средств инструментирования кода, так как в этом случае увеличивается количество инструментируемых модулей и, соответственно, возрастает сложность анализа покрытия. Рассмотренные обстоятельства делают актуальной разработку новых методов, способных работать в указанных условиях. В данной работе предлагается новый метод сокращения набора тестов, основанный на анализе поведения программы на наборе тестов и использующий для этого короткие последовательности системных вызовов. Предлагаемый метод не зависит от языка программирования, на котором производилась разработка ПО, не требует доступа к исходному коду и не предполагает инструментирования кода ПО, что существенно расширяет область его применения и облегчает использование. Статья организована следующим образом. В разделе 2 рассмотрены основные существующие методы сокращения набора тестов. Раздел 3 посвящен описанию предлагаемого метода сокращения набора тестов. В разделе 4 приводится описание проведенного эксперимента и его результатов. В конце работы делаются выводы и рассматриваются направления будущих исследований.
Заключение и направление будущих исследований
В данной работе был представлен метод решения задачи сокращения набора тестов, возникающей в контексте регрессионного тестирования. Данный метод основан на использовании моделей поведения программы, построенных в терминах системных вызовов, которые производятся программой во время своего выполнения. Работа метода была экспериментально исследована на модельных данных. Были исследованы такие параметры работы метода, как величина сокращения набора тестов и уровень обнаружения ошибок. Результаты работы метода были сравнены с результатами метода случайного сокращения набора тестов, и было показано, что исследуемый метод практически не уступает методу случайного сокращения набора тестов, а в большинстве случаев превосходит его.
В будущих исследованиях планируется развивать предложенный метод и, в частности, сосредоточиться на следующих направлениях. Во-первых, необходимо более четко охарактеризовать класс программ, к которым может быть применен предложенный метод. Интуитивно понятно, что результаты работы метода зависят от внутреннего устройства программы - частоты и характера обращений тестируемой программы к системным вызовам операционной системы. Например, на преимущественно вычислительных программах, где обращения к системным вызовам происходят редко, или в программном обеспечении баз данных, где разнообразность поведения программы характеризуется скорее характером передаваемых данных, нежели разными путями в графе выполнения программы, исследуемый метод может и не показать хороших результатов. Во-вторых, имеет смысл учитывать не только имена системных вызовов, совершенных программой во время своего выполнения, но и передаваемые в них параметры и возвращаемые значения. Такая информация косвенно учитывает потоки данных в программе и будет полезна при построении модели поведения программы. Наконец, планируется сравнить результаты работы предлагаемого метода не только с методом случайного сокращения наборов тестов, но и с остальными методами, используемыми в данной области.
